基于多目標蟻群優(yōu)化的單類支持向量機相似重復記錄檢測
2020-03-05 07:52:16呂國俊曹建軍鄭奇斌常宸翁年鳳彭琮
兵工學報 2020年2期
呂國俊, 曹建軍, 鄭奇斌, 常宸, 翁年鳳, 彭琮
(1.陸軍工程大學 指揮控制工程學院, 江蘇 南京 210007;2.國防科技大學 第六十三研究所, 江蘇 南京 210007)
0 引言
隨著科技、經(jīng)濟的迅速發(fā)展,日益增長的數(shù)據(jù)給人們的生活帶來便利,與此同時,數(shù)據(jù)質(zhì)量問題也日漸突顯。數(shù)據(jù)清洗是通過檢測、分析和修正數(shù)據(jù)中的錯誤或不一致來提高數(shù)據(jù)質(zhì)量的有效途徑[1]。由于字符錯誤、重復錄入等原因,同一個數(shù)據(jù)源中可能包含多個相似重復記錄,導致數(shù)據(jù)質(zhì)量降低。針對相似重復記錄的普遍性、復雜性以及對后續(xù)數(shù)據(jù)利用的影響,如何檢測和消除相似重復記錄一直是數(shù)據(jù)清洗研究關注的熱點[2]。
現(xiàn)有的相似重復記錄檢測算法主要包括基于屬性相似度的方法和基于關聯(lián)關系的方法。其中基于屬性相似度的方法根據(jù)屬性信息的相似程度進行記錄對的匹配。宋國興等[3]提出一種基于關鍵屬性組的相似重復記錄檢測方法,該方法首先通過屬性間的互信息進行屬性選擇,然后將屬性值用內(nèi)碼表示,根據(jù)內(nèi)碼序值進行聚類,最后由同一類中的內(nèi)碼之間的相似度進行相似重復記錄匹配,該方法有效解決了記錄屬性維度過高帶來的問題。針對高維數(shù)據(jù)噪聲對檢測造成的影響,宋國興等[4]又對傳統(tǒng)的基于空間距離的相似性度量進行改進,將屬性值的接近程度作為相似性度量的依據(jù),實驗證實了該度量方法具有較高的穩(wěn)定性。曹建軍等[5]采用有監(jiān)督的學習算法,利用支持向量機(SVM)對記錄對之間的屬性相似度向量進行分類,判定是否為相似重復記錄,實驗表明該方法具有較高的查準率和查全率,但該方法未考慮到真實數(shù)據(jù)集中相似重復記錄樣本稀少的問題。針對大數(shù)據(jù)來源多、維度高、體量大的特點,宋人杰等[6]對傳統(tǒng)SimHash算法進行改進,利用倒排索引算法提高相似重復記錄的匹配效率,并用MapReduce模型在云環(huán)境下實現(xiàn)大數(shù)據(jù)相似重復記錄的并行檢測和直接輸出。Elziky等[7]將N-Gram索引字符串使用相應的ASCII碼轉(zhuǎn)化為數(shù)值,在保證相似重復記錄檢測準確性的條件下提高了檢測效率。Samiei等[8]提出一種基于聚類的排序近鄰算法,該算法解決了對于動態(tài)記錄進行相似重復檢測的效率問題。
基于關聯(lián)關系的方法相比基于屬性相似度的方法,還利用了屬性間的關聯(lián)關系信息(如作者和單位2個屬性之間的隸屬關系),擁有更高的準確性[9]。馬平全等[10]利用N-Gram語言模型對記錄間的潛在聯(lián)系計算N-Gram值并進行排序,根據(jù)排序結(jié)果計算記錄間的相似度完成相似重復記錄檢測。Rabia等[11]提出基于訓練數(shù)據(jù)的自適應學習模型,學習了訓練數(shù)據(jù)中的關系類型,增強了對問題模型的適應性;在此基礎之上,譚明超等[12]提出了一種基于關系類型自適應學習方法,將權(quán)重放在關系類型上,并給出一種基于有監(jiān)督學習的權(quán)重學習模型,用于降低權(quán)重學習對訓練數(shù)據(jù)的要求,進一步提高準確性。
盡管當今的數(shù)據(jù)總量龐大,增長迅速。但在某些領域,數(shù)據(jù)稀缺問題仍然是大數(shù)據(jù)質(zhì)量面臨的重大挑戰(zhàn)之一[13],上述相似重復記錄檢測算法能夠完成在大數(shù)據(jù)背景下的相似重復記錄檢測工作,但這些算法并未考慮到真實數(shù)據(jù)源中相似重復記錄稀缺的問題。不同于經(jīng)典SVM分類器采用兩類訓練樣本“間隔最大”訓練超平面實現(xiàn)最優(yōu)分類,基于支持向量的單類分類器模型的特殊性在于只有一類訓練樣本,這對于一些由于復雜性高,獲取樣本的代價高昂,數(shù)據(jù)稀缺等原因只能獲取其中的一類樣本的分類問題具有重要意義,如異常檢測、故障診斷等[14]。
基于支持向量的單類分類器有單類支持向量機(OCSVM)和支持向量域描述(SVDD)兩個經(jīng)典模型[15],Scholkopf等[16]提出的OCSVM算法將特征空間零點設置為非目標類唯一的實例來構(gòu)建超平面并使零點到超平面的距離最大化。Xue等[17]通過對比該分類器和經(jīng)典二分類SVM的分類性能驗證了OCSVM算法在進行故障診斷中的優(yōu)越性。Tax等[18]提出一種軟間隔的最小超球SVDD方法,該方法從特征空間中找到能夠?qū)⑺杏柧殬颖景谄渲械淖钚〕蛎妫^而通過測試樣本和超球面的位置關系進行分類。針對SVDD對非球型目標樣本包裹緊湊性的問題,Wei等[19]利用超橢球代替SVDD中的超球以適應目標樣本映射到特征空間后的結(jié)構(gòu)信息。Burnaev等[20]對OCSVM和SVDD等兩種方法在訓練目標樣本、構(gòu)建松弛變量時引入額外的信息(如圖像分類時的文本描述信息、惡意軟件檢測時的源代碼信息等)來細化分離邊界的位置、提高異常檢測的準確性。
針對真實數(shù)據(jù)源中相似重復記錄稀缺的問題,使用OCSVM實現(xiàn)對相似重復記錄的分類檢測。其中考慮到記錄的特征個數(shù)對于分類效果的影響,利用多目標蟻群算法進行特征選擇,實現(xiàn)分類效果優(yōu)化。
本文第1節(jié)介紹OCSVM單類分類器模型的方法并給出相似重復記錄檢測問題描述;第2節(jié)結(jié)合單類訓練樣本特點,設計了求解最優(yōu)屬性子集的多目標蟻群優(yōu)化算法,實現(xiàn)了對記錄屬性的特征選擇;第3節(jié)實驗部分給出該重復記錄檢測方法的效果和效率驗證;第4節(jié)進行總結(jié)。
1 方法描述
1.1 基于OCSVM的單類分類器模型
OCSVM通過實現(xiàn)該類樣本與特征空間零點之間的“間隔最大”構(gòu)造分離超平面,并且最大化分離超平面到零點的距離。模型如(1)式:
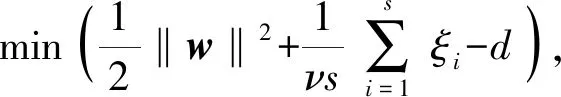
(1)
ξi≥0,
式中:w為高維空間分離超平面的法向量;Φ(xi)為一個將特征向量xi映射到高維特征空間中的特征投影函數(shù);d為空間零點到分離超平面的距離;ξi為松弛變量;s為樣本總數(shù);ν為正則化系數(shù)。采用拉格朗日乘子法對模型進行求解,將核函數(shù)帶入得到最終函數(shù)模型:
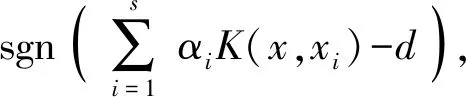
(2)
式中:αi為拉格朗日乘子;K(x,xi)為核函數(shù)。本文采用徑向基核函數(shù)(RBF),2個樣本xi和xj之間的核函數(shù)定義為
K(xi-xj)=exp (-γ‖xi-xj‖2),γ>0,
(3)
式中:γ為設置的內(nèi)核傳播參數(shù)。
OCSVM創(chuàng)建了一個參數(shù)為w和d的超平面,該超平面與特征空間中的零點距離最大,并且將零點與所有的訓練數(shù)據(jù)點分開,如圖1所示。圖1中:O為空間內(nèi)坐標零點;l為OCSVM創(chuàng)建的超平面,能夠?qū)⒘泓c與訓練樣本分開且保證零點到超平面的距離最大;l1、l2為其他超平面。

圖1 OCSVM超平面構(gòu)造圖Fig.1 OCSVM hyperplane structure
利用基于OCSVM的單類分類器模型能夠在缺少負類樣本情況下進行有效分類的特性,結(jié)合真實數(shù)據(jù)源中相似重復記錄樣本稀少的實際,將不相似重復記錄對的屬性相似度向量作為正類樣本,輸入到分類器中進行訓練,學習到不相似重復記錄對的統(tǒng)一特征,并具備對于不相似重復記錄對的分類能力。然后用訓練好的分類器對樣本對的相似度向量進行分類,相似重復記錄對的向量由于不符合學習到的統(tǒng)一特征,會被分類到超平面的另一側(cè),因此完成對相似重復記錄的有效檢測。
1.2 問題描述
對2條記錄進行相似重復記錄檢測,首先計算2條記錄對應屬性值的相似度,再根據(jù)各屬性值的相似度計算2條記錄的相似程度,并判斷它們是否相似重復(匹配或不匹配)。文獻[5]將該過程看成一個二分類的過程,以一個記錄對的屬性相似度向量作為傳統(tǒng)二分類SVM的輸入,將其分為相似重復(匹配)和不相似重復(不匹配)兩類。但該方法需要足夠的相似重復記錄樣本對進行訓練,而真實數(shù)據(jù)集中相似重復記錄數(shù)量稀少,制約了傳統(tǒng)SVM的訓練效果及分類檢測性能。根據(jù)1.1節(jié)的單類分類器模型只需要一類樣本參與訓練的分類特點,結(jié)合真實數(shù)據(jù)集中,相似重復記錄數(shù)量遠小于不相似重復記錄數(shù)量的實際,提出基于OCSVM單類分類器的相似重復記錄檢測方法。相似重復記錄檢測流程如圖2所示。
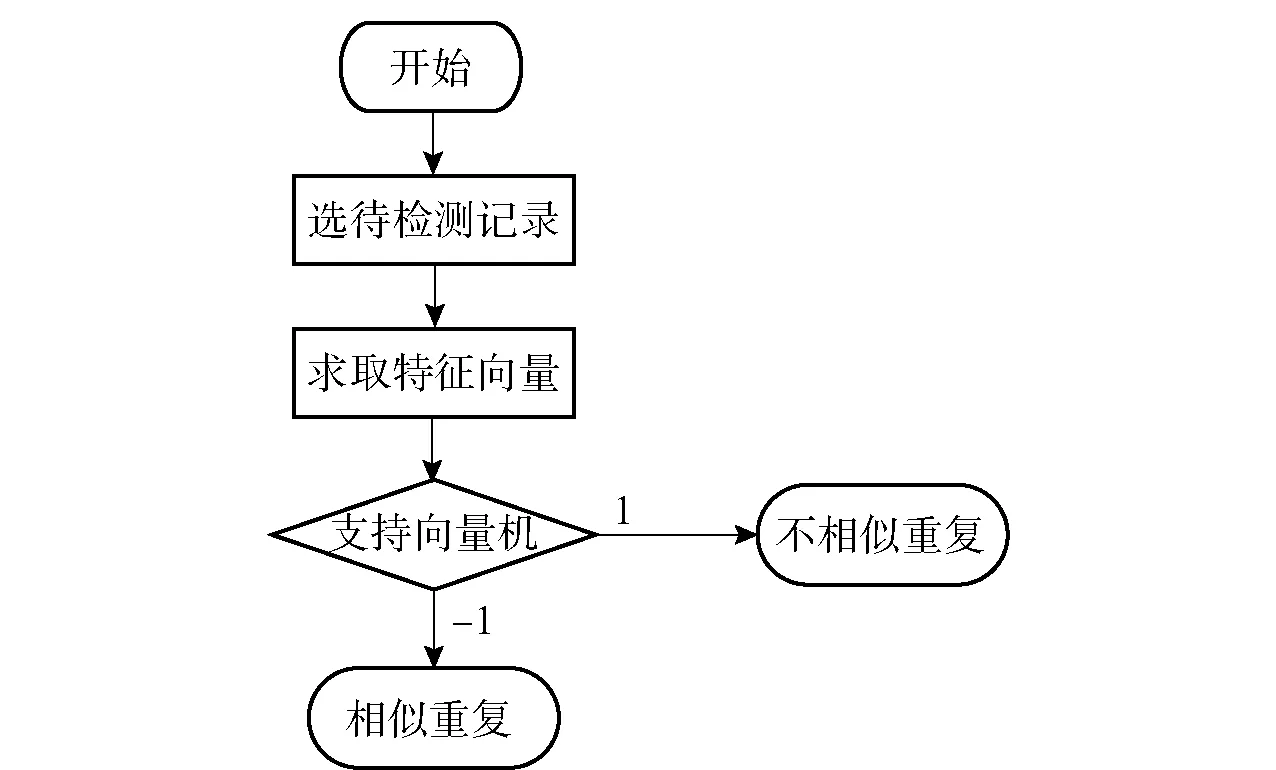
圖2 相似重復記錄檢測流程圖Fig.2 Flow chart of similar duplicate record detection
本文提出的方法和文獻[5]的方法流程區(qū)別在于分類器的選擇,文獻[5]使用的是傳統(tǒng)二分類SVM進行分類,訓練時需要相似重復記錄對和不相似重復記錄對兩類樣本;本文考慮到真實數(shù)據(jù)集中相似重復記錄個數(shù)稀少的實際,采用OCSVM進行分類,只需不相似重復記錄對這一類樣本進行訓練。
2 多目標蟻群算法特征選擇
2.1 特征選擇模型
在高維度的特征集中,冗余特征的存在往往嚴重影響著分類效率和效果[21]。在相似重復記錄檢測中亦是如此,冗余的屬性信息的存在給相似重復記錄的準確分類造成困難。特征選擇通過構(gòu)建最優(yōu)特征子集來消除數(shù)據(jù)中的冗余信息,減小運算復雜度,實現(xiàn)分類效率效果最優(yōu)。
對于相似重復記錄檢測算法效果的評價指標主要有4個:查準率P、查全率R、分類正確率A和F1指標。分別為
(4)
(5)
(6)
(7)
式中:TN為檢測出的真的相似重復記錄對數(shù);TP為檢測出的真的不相似重復記錄對數(shù);FN為檢測出的假的相似重復記錄對數(shù);FP為檢測出的假的不相似重復記錄對數(shù)。
通常,查準率和查全率不能同時達到最優(yōu),對采用查準率和查全率為主要評價指標的相似重復記錄分類檢測算法,可以將特征選擇問題描述為:從屬性集A中選擇一個基數(shù)為q的屬性子集Aq,使由Aq所包含屬性生成的相似特征向量的相似重復檢測查準率和查全率綜合達到最優(yōu),同時Aq規(guī)模最小。即對相似特征向量的特征進行選擇的過程,其數(shù)學模型為
(8)
(9)
minq,
(10)
s.t. |Aq|=q,1≤q≤q′,
式中:Λ(Aq)表示以屬性子集Aq生成的相似特征向量為輸入的分類器Λ的分類結(jié)果,根據(jù)(8)式和(9)式,由測試樣本計算可得;q′表示屬性集A中的屬性總數(shù)。(8)式~(10)式表示基于Aq的相似重復記錄檢測結(jié)果的查全率和查準率最大,同時使Aq的規(guī)模最小,其中(8)式和(9)式的優(yōu)先級大于(10)式。因此,相似重復記錄的特征選擇是一個多目標的子集問題。
2.2 模型的蟻群算法求解
多目標問題通常并不存在各目標都為全局最優(yōu)的解的情況,而存在一非劣解集,稱為Pareto最優(yōu)解集,多目標優(yōu)化的目的是力求找出一組解,盡可能全面地逼近Pareto解集,決策者可按需求進行評價,選出適用的滿意解[22]。
一類基于元啟發(fā)式算法全局搜索的次優(yōu)子集求法得到了快速發(fā)展與應用,如蟻群算法、模擬退火算法、遺傳算法、人工免疫算法、粒子群算法、蝙蝠算法、螢火蟲算法等[23]。
蟻群算法是一種元啟發(fā)式算法,由于其具有很強的求解較好解的能力、較好的魯棒性、信息正反饋、并行分布式計算及易于與其他啟發(fā)式方法相結(jié)合等優(yōu)點[24],在短期內(nèi)得到迅速發(fā)展,應用領域也不斷擴大,特別是在求解復雜多目標組合優(yōu)化問題方面顯示了其優(yōu)越性。Dorigo等[25]將蟻群算法與模擬退火、進化規(guī)劃、遺傳算法、模擬- 遺傳算法進行了比較,發(fā)現(xiàn)蟻群算法在解決經(jīng)典的組合最優(yōu)化問題——旅行商問題時優(yōu)于其他算法。
本節(jié)中以相似重復記錄檢測的查準率和查全率作為優(yōu)化目標,對于給定的q值,求出(8)式、(9)式模型的滿意解,采用多目標蟻群算法求解,步驟如下:
步驟1引入基于圖的螞蟻系統(tǒng)[26],根據(jù)相似重復記錄檢測特征選擇問題構(gòu)造有向圖。螞蟻根據(jù)有向圖邊上的信息素值與靜態(tài)啟發(fā)式信息構(gòu)建可行解。如圖3所示的特征選擇問題的構(gòu)造圖中,在t時刻v1處生成M只螞蟻。每只螞蟻根據(jù)邊的信息素和啟發(fā)式信息獨立的選擇某一條路徑向下一個節(jié)點移動,其中c為特征總數(shù),n為螞蟻在一次搜索中尋找解的個數(shù),eij表示螞蟻在第j步選擇第i個特征。
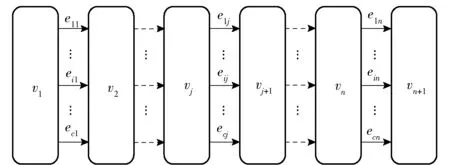
圖3 特征選擇問題構(gòu)造圖Fig.3 Construction diagram of feature selection
步驟2引用文獻[5]中螞蟻選擇路徑的路徑轉(zhuǎn)移概率公式來實現(xiàn)圖3中螞蟻的概率轉(zhuǎn)移,如(11)式所示,
(11)
式中:ebj表示螞蟻在第j步選擇第b個特征;禁忌表tabum為第m只螞蟻走過的邊,即螞蟻已經(jīng)選擇的特征;α和β分別為信息素重要程度和啟發(fā)式信息重要程度的系數(shù);τij(t-1)為在t-1(t=1,2,3,…)時刻的邊eij上的信息素量;τbj(i-1)為在t-1(t=1,2,3,…)時刻的邊ebj上的信息素量;ηb為選擇第b個特征的期望程度。由于需要同時優(yōu)化查準率和查全率2個目標,對其分別設置信息素矩陣,在計算轉(zhuǎn)移概率中的τij(t-1)時,采用(12)式2個信息素矩陣進行聚合:
(12)

(13)
式中:σi為不相似重復類內(nèi)第i個相似特征值的標準差。在只有一類樣本的條件下,無法像線性判別分析那樣通過度量多類情況中利用類間信息選擇特征,(13)式表明,只通過類內(nèi)散度的最小化來選擇特征,即算法優(yōu)先選擇最小化單類訓練樣本離散程度(即標準差小)的特征。
步驟3當螞蟻每次迭代完畢后,按照(14)式和(15)式分別對查準率信息素矩陣和查全率信息素矩陣進行更新:
(14)
(15)
式中:ρ為信息素揮發(fā)系數(shù);tabut為t時刻選擇的特征路徑;Δ′(tabut)為信息素更新增量,計算公式為
(16)
F(tabut)為對應更新的信息素矩陣的目標函數(shù)值,Q為常數(shù)(根據(jù)ρ值確定,主要調(diào)節(jié)信息素增量的大小)。
通過對于不同q值求得的Pareto解集進行比較更新,移除支配解,在最后的Pareto解集中選取特征個數(shù)最少的解,保證特征規(guī)模的最小化。
求解多目標蟻群算法優(yōu)化模型的算法描述如下:
算法1. 多目標蟻群算法進行特征選擇
輸入:候選特征集,待求特征子集中特征個數(shù)范圍、蟻群算法相關初始化參數(shù)
輸出:特征子集的Pareto解集
Begin
初始化
forq=1∶10
{fori=1:ite
{生成M只螞蟻用于搜索
form=1∶M
{根據(jù)(11)式計算轉(zhuǎn)移路徑概率,選擇特征;
用被選的特征進行OCSVM訓練和測試;
保存解;
}
移除非支配解
fornum=1∶2
{根據(jù)(14)式和(15)式更新信息素矩陣;
}
}
Pareto解集存儲
}
不同q值的Pareto解集比較更新,移除非支配解
輸出Pareto解集
End.
3 實驗仿真
3.1 實驗數(shù)據(jù)及預處理
本文的實驗數(shù)據(jù)來源于文獻[5]中的某信息系統(tǒng)的人員基本情況表pst和UCI機器學習數(shù)據(jù)庫中的adult數(shù)據(jù)集。按照相似重復記錄的比例不同,對這兩個數(shù)據(jù)集分別以10%、5%、2%的相似重復記錄占比進行數(shù)據(jù)集劃分。
對數(shù)據(jù)集進行預處理,引用文獻[5]中對記錄內(nèi)字符串型、枚舉型、日期型等不同類型屬性的相似度計算方法,計算數(shù)據(jù)集中記錄對之間的相似特征向量。
3.2 仿真結(jié)果及分析
3.2.1 參數(shù)設置
實驗中所用各個算法的參數(shù)信息如表1所示。

表1 參數(shù)信息表Tab.1 Algorithm parameters
注:k為訓練數(shù)據(jù)的特征個數(shù)。
3.2.2 實驗設置及結(jié)果分析
為選擇較好的分類方式,實驗對比OCSVM[16]和SVDD[18]這兩種基于支持向量的單類分類算法的相似重復記錄檢測結(jié)果,其中,不相似重復記錄對為正類樣本,相似重復記錄對為負類樣本。實驗采用5重交叉檢驗取均值的方法[27],以消除由于訓練集和測試集劃分所得結(jié)果的偶然性,有助于評估模型的穩(wěn)定性。評價指標為F1值、查準率、查全率和分類正確率。對于兩個單類分類器模型,通過采用網(wǎng)格搜索的方法得到各算法的參數(shù)如表1所示,確保OCSVM和SVDD算法能夠在實驗過程中達到較優(yōu)的分類效果。
表2中的實驗結(jié)果均為5重交叉檢驗后的均值。對其進行分析,發(fā)現(xiàn)數(shù)據(jù)集不同,得到的F1值的結(jié)果也不一樣,對比發(fā)現(xiàn),使用OCSVM分類效果略好于使用SVDD的分類效果,每一個數(shù)據(jù)集測試結(jié)果的查準率和查全率能夠同時取得較優(yōu)的結(jié)果。但是,對于數(shù)據(jù)集pst5%而言,SVDD的結(jié)果略好于OCSVM,尤其在查準率指標上,SVDD能夠得到最優(yōu)的結(jié)果1.000 0,可能是因為該數(shù)據(jù)集具有更特殊的數(shù)據(jù)分布(正類樣本更趨于球體分布)。
通過對比不同相似重復比率進行數(shù)據(jù)劃分后的分類結(jié)果,可以發(fā)現(xiàn),數(shù)據(jù)中正負類的不平衡程度對于OCSVM和SVDD這樣的單類分類器分類結(jié)果影響不大,各個指標上的小幅波動是由于劃分后的數(shù)據(jù)集中數(shù)據(jù)分布不同所導致。
為測試單類分類器OCSVM、SVDD在解決相似重復記錄檢測問題的有效性,實驗對比了OCSVM、SVDD和在訓練數(shù)據(jù)中不同正負類樣本數(shù)目比例下的傳統(tǒng)二分類SVM的分類結(jié)果。在pst數(shù)據(jù)集上,采用5重交叉檢驗取均值的方法,其中OCSVM、SVDD采用80個正類樣本進行訓練,傳統(tǒng)SVM在此基礎上隨機加入不同比例個數(shù)的負類樣本進行訓練。所得分類結(jié)果的F1值對比如圖4所示。圖4中:橫坐標N表示傳統(tǒng)SVM訓練樣本中正負類樣本的比率,N越大表示訓練樣本中正負類的數(shù)目越不平衡(負類樣本的數(shù)目相比正類樣本越少);縱坐標表示(7)式中的F1值;F1值越大說明分類效果越好。從圖4中可以看出:OCSVM的分類效果要優(yōu)于SVDD的分類效果;其次,當N≥8時,OCSVM和SVDD的分類效果要優(yōu)于傳統(tǒng)SVM的分類效果,且這個優(yōu)勢在N=16,N=20時更加明顯,而當N=40,N=80時,由于訓練時負類樣本數(shù)目過少,不能分類出負類樣本,才出現(xiàn)F1值最小的情況。結(jié)果表明,當對數(shù)據(jù)進行分類時,如果能夠用于訓練的負類樣本數(shù)很少,采用OCSVM、SVDD的單類分類器的分類效果要遠好于采用傳統(tǒng)SVM的二分類器的分類效果。有效彌補了文獻[5]中在用傳統(tǒng)SVM分類解決真實數(shù)據(jù)集時負類樣本少,難獲取的問題。

表2 OCSVM對比SVDD仿真結(jié)果Tab.2 Comparison of simulated results of OCSVM and SVDD
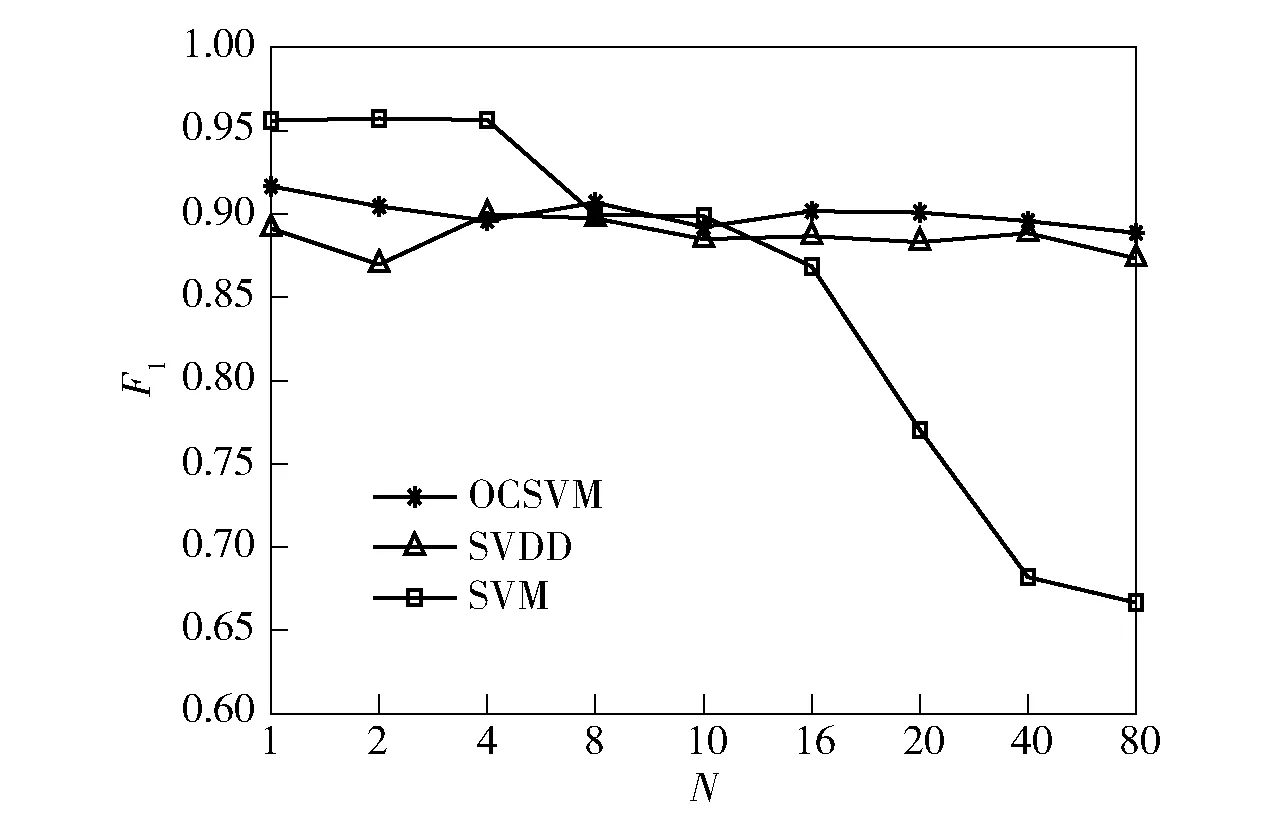
圖4 OCSVM、SVDD和傳統(tǒng)SVM的F1值比較Fig.4 Comparison of F1 values of OCSVM, SVDD and traditional SVM
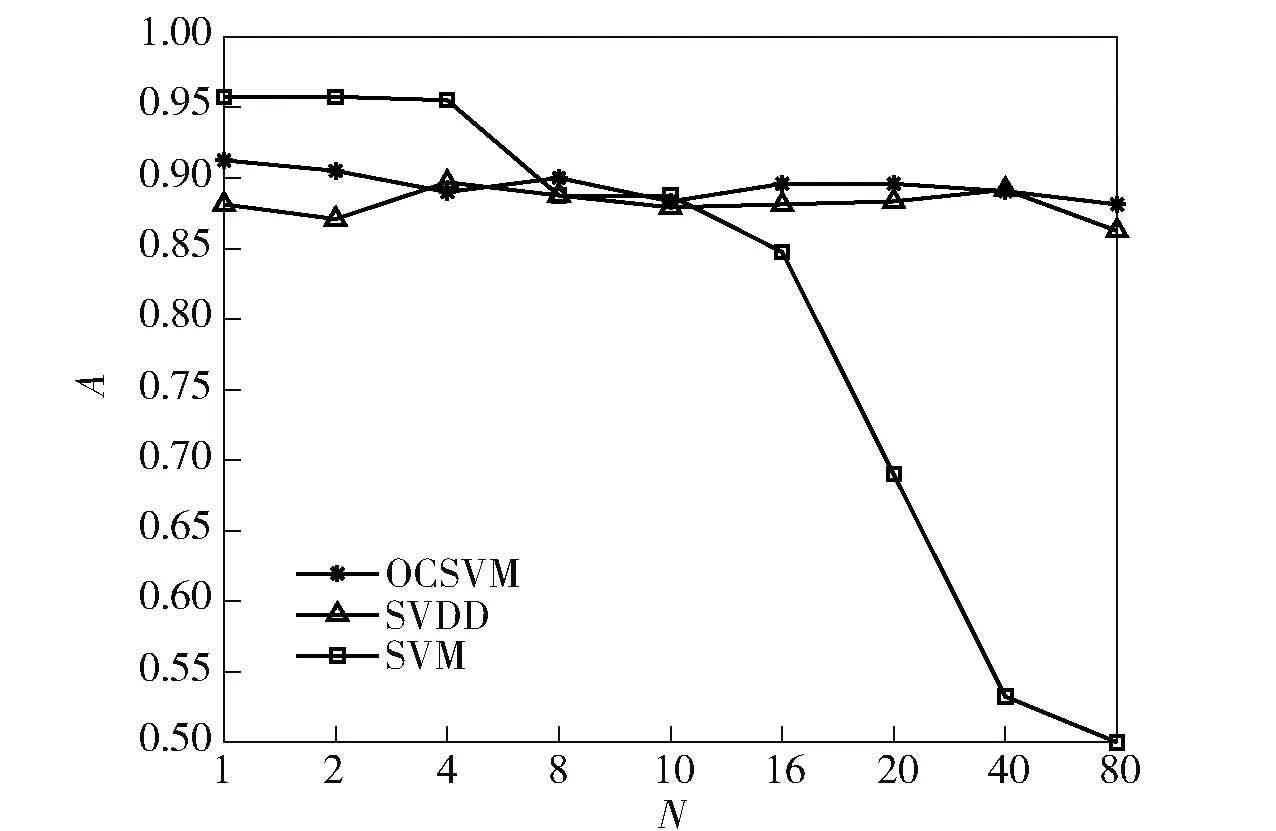
圖5 OCSVM、SVDD和SVM的正確率比較Fig.5 Comparison of classification accuracies of OCSVM, SVDD and traditional SVM
類似的結(jié)論從圖5中也可以得出,相較于F1值,圖5的縱坐標為分類正確率。當N≥8時,OCSVM的分類正確率要優(yōu)于傳統(tǒng)SVM;當N=40,N=80時,由于缺少負類信息,導致傳統(tǒng)SVM不能分類出負類樣本。
3種算法的時間效率由圖6給出,從圖6中可以看出,OCSVM算法的時間效率要小于SVDD,N越小時,傳統(tǒng)SVM的訓練時間越大,這是因為N越小時,訓練樣本的總個數(shù)越大,算法所消耗的時間也越大。
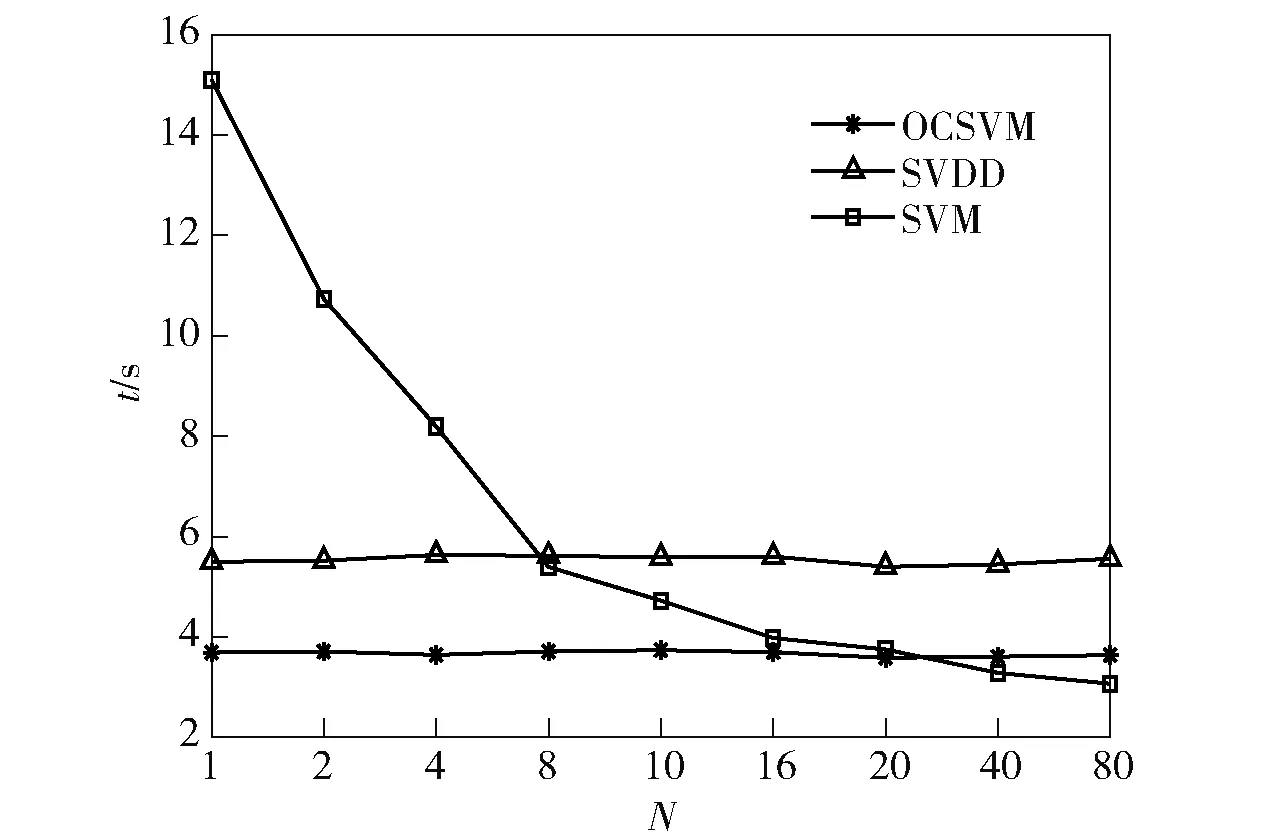
圖6 OCSVM、SVDD和傳統(tǒng)SVM的時間效率比較Fig.6 Comparison of time efficiencies of OCSVM, SVDD and traditional SVM
針對相似重復記錄的樣本數(shù)遠小于不相似重復記錄的樣本數(shù)N≥8,采用傳統(tǒng)SVM分類需要一定量的相似重復類樣本,不符合真實數(shù)據(jù)集中相似重復記錄個數(shù)稀少的實際,故使用OCSVM、SVDD分類相比傳統(tǒng)SVM分類更行之有效。
4 結(jié)論
本文根據(jù)數(shù)據(jù)源中樣本記錄對是否相似,將相似重復記錄檢測看成二分類問題,針對相似重復記錄樣本稀少的實際,利用OCSVM單類分類器分類,并使用多目標蟻群算法進行特征選擇優(yōu)化。得到主要結(jié)論如下:
1)利用OCSVM單類分類器進行分類,解決了真實數(shù)據(jù)源中相似重復記錄樣本少、難獲取的問題。
2)設計啟發(fā)式因子為類內(nèi)散度最小化約束的多目標蟻群算法特征選擇優(yōu)化模型,綜合考慮算法的查準率、查全率和特征規(guī)模,得到了較優(yōu)的分類效果。
3)本文方法在數(shù)據(jù)源中相似重復記錄樣本稀少情況下的效果優(yōu)于傳統(tǒng)二分類SVM分類方法,具有更好的適用性。
在當今大數(shù)據(jù)發(fā)展的背景之下,數(shù)據(jù)稀缺問題仍然是大數(shù)據(jù)質(zhì)量不可忽視的挑戰(zhàn)之一。本文提出的方法能有效解決數(shù)據(jù)源中相似重復記錄樣本稀缺的問題,實現(xiàn)相似重復記錄檢測。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
