供應鏈溯源場景的區塊鏈存儲模型研究
2020-03-05 06:06:22張登平許亮
現代計算機 2020年1期
關鍵詞:模型
張登平,許亮
(四川大學計算機學院,成都610065)
0 引言
2008 年Bitcoin:A Peer-to-Peer Electronic Cash System[4]的發表標志著區塊鏈技術的誕生。2009 年1 月4日比特幣的第一個區塊誕生,時至今日,比特幣已經走過了10 年,其底層的區塊鏈技術更是獲得了社會各界的廣泛關注和研究。2019 年10 月24 日下午,中共中央政治局就區塊鏈技術發展現狀和趨勢進行第十八次集體學習,并指出把區塊鏈作為核心技術自主創新重要突破口。區塊鏈技術儼然已經成為互聯網的又一個風口,各種“區塊鏈+”模式的創新型應用層出不窮。
隨著公眾對食品安全,假冒偽劣產品等問題的關注度升高,供應鏈管理問題逐漸進入了公眾視野,并演變成了國家政策。當前供應鏈的管理主要為中心化的方式,物流數據人為上傳,并存儲在中心化的數據庫中。傳統中心化的供應鏈管理方式存在諸多問題,其中最為突出的是數據可篡改,溯源困難和數據不透明。區塊鏈作為一種分布式賬簿,多方共同參與維護,天然具備數據不可篡改、去中心化、可追溯等特點。區塊鏈技術與供應鏈管理相結合是一種比較具有說服力的方案,也是當前區塊鏈應用領域的研究熱點。
然而,區塊鏈技術本身存在可擴展性差,交易吞吐量低下,數據持續增長等問題,這些問題限制了其在非數字貨幣交易以外的應用。本文著眼于區塊鏈數據持續增長的問題,對現有的區塊鏈數據存儲模型進行了研究,并根據供應鏈溯源場景下的需求,提出了一種適用于供應鏈溯源場景的區塊鏈數據存儲模型。
1 研究現狀
2017 年3 月7 日,丹麥航運巨頭馬士基成功完成了“區塊鏈+商品追溯”應用的測試,該應用能夠實時跟蹤集裝箱在供應鏈中的位置,從而保證了供應鏈數據的透明度和安全性,降低了供應鏈管理成本。此后,國內外“區塊鏈+供應鏈管理”的實例不斷涌現。國外比較有代表性的應用有IBM 與哥倫比亞物流解決方案提供商AOS 合作完成的“區塊鏈與沃森物聯網(Blockchain & Watson IoT)”、IBM 與沃爾瑪合作完成的沃爾瑪商品物流、Everledger 自主研發的鉆石防偽驗證數字賬本等;國內主要有京東防偽溯源平臺、京藍科技的區塊鏈農產品溯源、螞蟻區塊鏈等。諸多供應鏈管理與區塊鏈結合的成功案例說明區塊鏈在供應鏈管理應用方面的巨大價值。
比特幣底層的區塊鏈數據存儲模型為鏈式數據結構(如圖1)的存儲模型,所有礦工節點存儲完整的區塊鏈數據,該模型的數據量隨著系統的運行逐漸增加,截至2019 年10 月,比特幣底層的區塊鏈數據量已超250G,使得新加入節點的同步時間變得很長,同時網絡中礦工節點的存儲壓力不斷上升。針對區塊鏈數據量不斷增長的問題,相關學者進行了深入研究[5-7]。
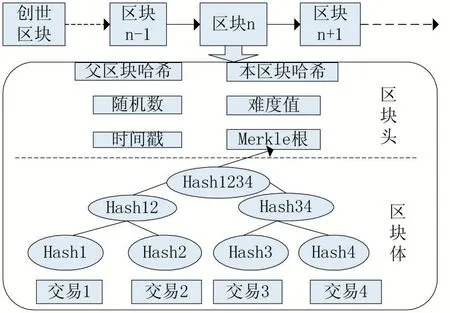
圖1 比特幣的區塊鏈數據存儲模型
迷你區塊鏈模型[5]使用賬戶樹,迷你區塊鏈和證明鏈三個組件構建了一條可以丟棄舊區塊的區塊鏈,使用賬戶樹代替比特幣的UTXO 來保證資產所有權,使用證明鏈保證了數據的可信。該模型因為只保存近一段時間的所有區塊,所以能有效減少節點存儲區塊鏈的數據量。但是由于該模型會剔除舊交易,在交易溯源和交易驗證方面的性能不能滿足溯源場景的需求。
區塊鏈存儲容量可擴展模型[6]使用分布式分片存儲的方法,先將區塊鏈數據按照安全性能算法進行分片,然后分布式存儲在一定比例的節點中,同時使用P鏈和POR 鏈來定位區塊存儲位置及其證明。該模型中,所有節點都沒有完整的區塊鏈數據,因此在一定程度上優化了區塊鏈數據存儲模型,減小了節點的存儲壓力。但是該模型在驗證交易的時候,節點需要請求本節點沒有的區塊,該過程增加了驗證的時長和復雜性;此外,數據的存儲依靠驗證節點的數據來決定數據存儲的位置,一定程度上會造成數據的中心化存儲,減少區塊鏈的去中心化程度。
聯盟區塊鏈的容量優化模型[7]采用基于位置的分組設計,組建了聯盟鏈。在每個分組中根據一個節點評價算法選取一個可靠且高性能的節點來存儲完整的區塊鏈數據,組內其他節點根據分布式一致性算法共同存儲完整的區塊鏈數據;組內存儲節點還存儲完整區塊鏈的區塊頭鏈數據,用于當全節點宕機的時候下載完整的區塊鏈數據,替代全節點。該模型因為只有一個節點存儲所有的區塊數據,其他組內節點存儲部分區塊鏈數據,降低了組內節點的存儲壓力,但是關于節點的可靠性評價算法尚有不足;同時由于組內節點不存儲完整的區塊鏈數據,在交易驗證的時候受限于網絡帶寬,同樣不適用于供應鏈溯源場景的應用。
2 供應鏈溯源場景下的數據存儲模型
供應鏈溯源場景下,物流數據隨供應鏈環節的增加呈指數級增加,因此要求底層的區塊鏈系統有較高的交易吞吐能力。同時因為數據體量大,減少節點的存儲壓力的需求更為迫切。
本模型為基于網絡分區的區塊鏈數據存儲模型,同一分區內的節點有主節點和普通節點兩種角色,主節點負責存儲整個區塊鏈數據并參與區塊鏈的共識過程,普通節點相當于比特幣和以太坊中的輕節點,只存儲少量的區塊頭鏈數據,不參與區塊鏈數據的存儲和共識過程,僅僅只是發送包含供應鏈數據的交易至全網。這里的網絡分區是指抽象意義上的網絡分區,即根據普通節點選擇跟從的主節點劃分區域。從全網來看,整個網絡仍是P2P 的組網形式。
主節點的選取可以由大型企業,監管部門等提供,這個過程可以保證主節點的可信和高性能;普通節點則經過監管部門的審核,然后隨機連接到不同的主節點,該連接過程可以對普通節點不可見以保證主節點的安全。
本模型的組網形式可見圖2,該模型在供應鏈溯源場景下的普通節點占絕大部分,而這些節點都是輕節點,不存儲所有的區塊鏈數據,因此大幅降低了整個系統的存儲壓力。而主節點之間沿用了比特幣等數字貨幣應用的組網形式,其抗惡意攻擊的性能已經得到了驗證,故而整個系統的魯棒性可以得到保證。
3 模型運行過程與性能分析
3.1 模型的數據存儲過程
本模型的工作流程如下。其中第二步,主節點收到分區內普通節點的交易后并不立即轉發,主要是考慮到主節點可靠性比較高,如果交易轉發出去之后再進行驗證,則可能轉發無效的交易浪費網絡帶寬。
(1)普通節點將供應鏈數據以交易的形式向全網廣播;
(2)其他普通節點轉發收到的交易;主節點收到交易后先驗證,再將通過驗證的交易向其他主節點轉發;
(3)主節點將一段時間內的合格交易打包成區塊,并開始參與共識過程;
(4)主節點將共識生成的區塊記錄在本地,并向全網廣播區塊頭數據;
(5)普通節點將收到的區塊頭數據保存在本地。
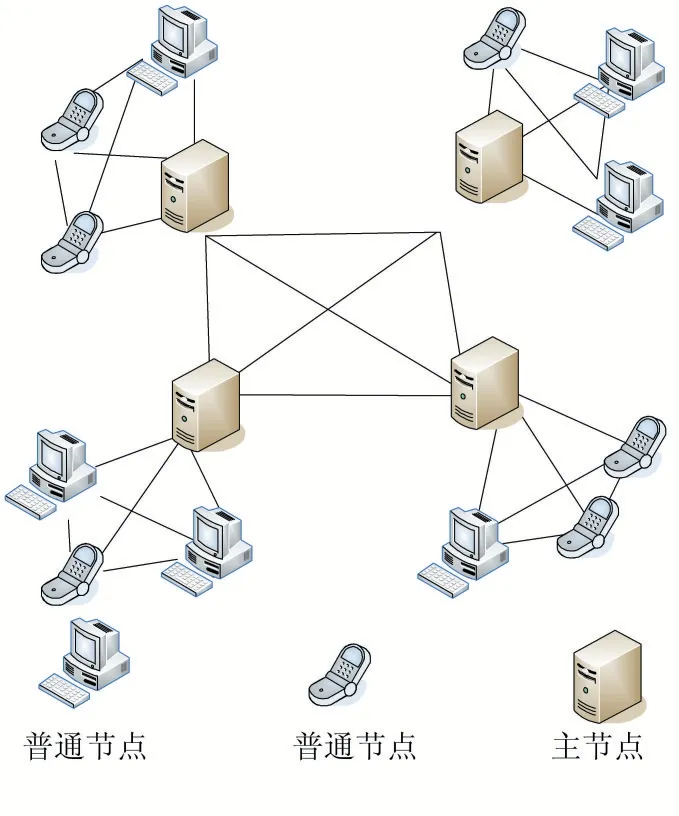
圖2 基于網絡分區的區塊鏈存儲模型的節點組網形式
3.2 性能分析
由于比特幣等傳統數字貨幣區塊鏈采用公有鏈的形式,節點間不互信,節點只能存儲整個區塊鏈的數據才能保證整個系統的高可信度,故而系統存儲壓力大,單個節點的物理存儲浪費嚴重,并不適用于數據體量更大的供應鏈溯源場景;迷你區塊鏈模型保證了節點只存儲最近一段時間的一部分區塊,但是增加了證明鏈以及賬戶樹的存儲,雖然該模型降低了整個系統的存儲壓力,但隨著時間增長,該模型的數據量仍是線性增長的,且因為對區塊鏈數據的剪枝操作,使得交易的追溯變得不可行,也不適用于供應鏈溯源場景;區塊鏈存儲容量可擴展模型和聯盟區塊鏈的容量優化模型都大幅降低了系統的存儲壓力,在數字貨幣領域有一定的應用價值,但因為驗證交易占用了網絡帶寬,提高了交易驗證時長,對于交易吞吐量要求較高的溯源場景是不適用的。本模型跟聯盟區塊鏈的容量優化模型類似,都大幅降低了普通節點的存儲壓力,不同的是,本模型采用監管更為有力的聯盟鏈形式,于是可以使普通節點不必參與到區塊鏈的共識過程中來,解決了聯盟區塊鏈的容量優化模型的交易驗證問題,更加適用于溯源場景的使用。各種模型間的性能對比情況見表1。
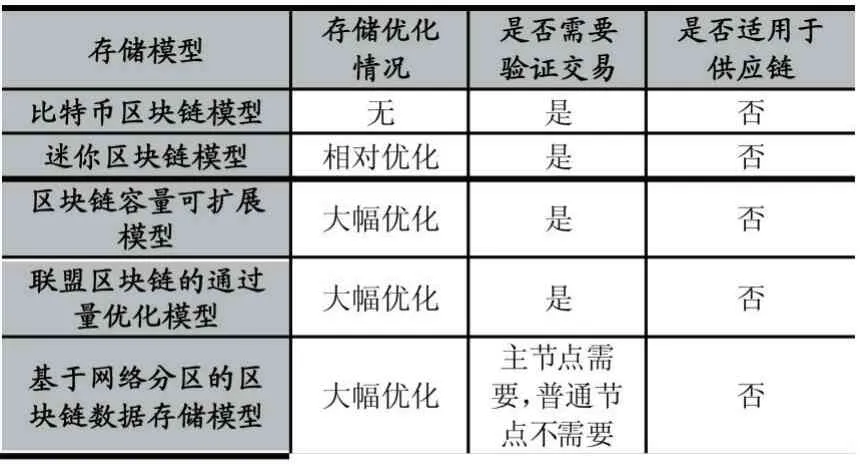
表1 各種模型間的性能對比情況
4 結語
本文在文獻研究的基礎上,通過對已有的區塊鏈存儲優化模型的對比分析,結合供應鏈溯源場景需求,提出了基于網絡分區的區塊鏈數據存儲模型。通過分析,本模型能大幅降低系統和普通節點的存儲壓力,達到了區塊鏈數據存儲優化的目的,同時本模型因為去除普通節點的交易驗證過程,節省了交易驗證時間,提高了系統交易吞吐量,因此更加適用于溯源場景的應用。但是由于本模型參與共識過程的節點較少,一定程度上降低了系統的去中心化程度。未來的工作可以從兩方面著手,一方面研究該模型下的共識算法的選擇,以進一步提高系統的安全性和交易吞吐量;另一方面,可以考慮增加同一分區內主節點的個數及同一分區內主節點間的協調性,增強去中心化的程度,提高系統的可靠性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
