基于GoogLeNet Inception V3的遷移學習研究
2020-03-04 03:40:22薛晨興邢家源
無線電工程 2020年2期
薛晨興,張 軍,邢家源
(天津職業技術師范大學 電子工程學院,天津 300222)
0 引言
隨著計算機領域的迅速發展,機器學習在實際應用和理論探討2個方面都取得了巨大進步[1-3]。為了保證分類模型的訓練結果具有可信的分類效果,傳統的機器學習方法一般假設數據的特征結構不隨環境改變[4],即要求源域的數據和目標域的數據具有相同的分布。然而在實際應用領域中,如交通、人機交互、生物信息和自動控制等,這一假設通常由于嚴格的機制而不成立。遷移學習(Transfer Learning,TL)[5-8]的出現打破了這一局限,只要源領域和目標領域之間有一定相關性,分類模型訓練時就可以借助從源領域的數據中提取的特征知識,實現已學習知識在相似或相關領域間的復用和遷移,使傳統的從零開始學習變成可積累學習,不僅可以縮減訓練模型的成本,而且可以高效地實現目標分類。本文主要基于Inception V3參數的遷移學習對圖像分類,通過TensorFlow框架對Inception V3遷移學習的過程和結果分析
1 卷積神經網絡與遷移學習
1.1 卷積神經網路的發展
1986年,反向傳播算法(BP)算法[9]提出,幾年后LeCun利用BP算法訓練神經網絡識別手寫郵政代碼,成為卷積神經網絡(CNN)的開山之作,1998年LeNet5模型提出,CNN面世。2012年,AlexNet模型在ImageNet比賽中,取得第一的成績,在此之后更多更深的CNN模型提出。2014年,GoogLeNet模型在2014年圖像網絡大型視覺識別比賽(ILSVRC)獲得冠軍,成為CNN 分類器發展史上的一個重要里程碑。本文主要基于此模型系列的Inception V3進行遷移學習 。
1.2 GoogLeNet
GoogLeNet的核心思想在于增加網絡深度和寬度,來提高CNN網絡性能。在增加神經網絡寬度方面主要采用深度卷積網Inception,如圖1所示,這一特色網絡結構即保持網絡結構的稀疏性,又利用了密集矩陣的高計算性能。
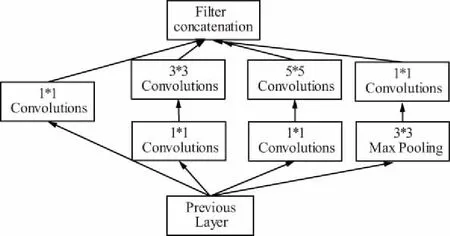
圖1 Inception 結構圖Fig.1 Structure diagram of Inception
Inception V1是Inception網絡的第一個版本,作者提出的這深度卷積神經網絡Inception,該架構的主要特點是更好地利用網絡內部的計算資源,此外該設計允許增加網絡的深度和寬度,同時保持計算預算不變。為了優化質量,架構決策基于赫布原則和多尺度處理[10]。
2015年作者通過一系列能增加準確度和減少計算復雜度的修正方法,在論文[11]提出了Inception V2 和 Inception V3。其中inception V2將5*5的卷積分解為2個3*3卷積運算提升計算速度,如圖2所示。
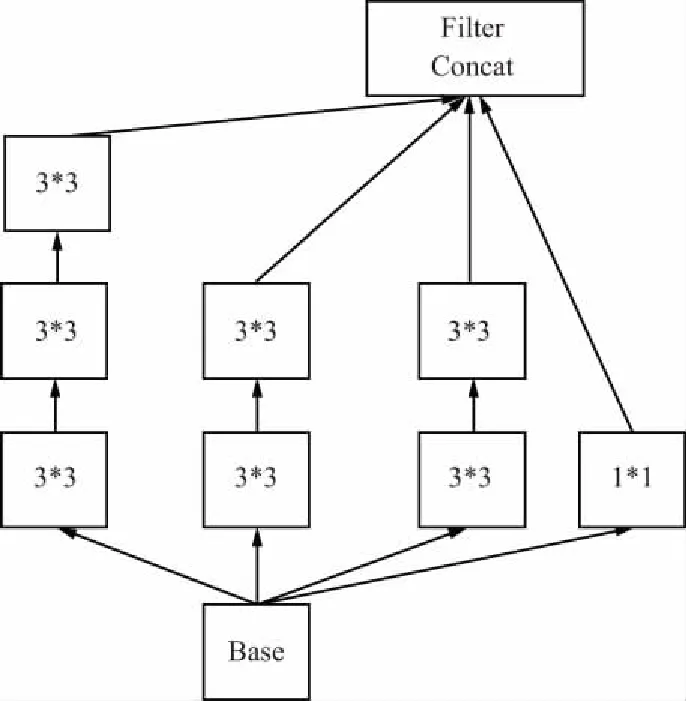
圖2 Inception2 結構圖Fig.2 Structure diagram of Inception2
此外作者將n*n卷積核尺寸分解為1*n和n*1兩個卷積,使濾波器的組變得更寬,已解決表征性瓶頸。
Inception V3整合了inception V2的所有優勢,與V2對比,其最主要的不同就是提出了Batch Normalization,目的主要在于加快訓練速度。Inception V3使用了RMSProp優化器,此優化器是Geoff Hinton 提出的一種自適應學習率的方法,參數更新方式如下所示,其中學習率η一般設為0.001。
梯度更新規則:
(1)
式中,E的計算公式為:
(2)
1.3 遷移學習
在文獻[12]中,pan等人準確的定義遷移學習,如下:
2 基于GoogleNet Inception V3的參數遷移學習模型
2.1 Inception V3的模型簡介
本文主要是在Inception V3的模型上進行參數遷移學習,其模型如圖3所示,其中mixed模塊就是Inception網絡的結構。
本次實驗基于Inception V3 的參數偏移學習是只替換訓練分類層而保留源模型的全部特征提取能力。由于圖像的底層紋理特征通用的特點,在進行遷移學習時可以相對保留卷積模塊的參數與結構,并設置一些深度卷積層或者全連接層可訓練狀態。將數據放入目標域中的重構模型中進行再次訓練時,由于可訓練參數繼承自源模型,因此模型在微調時并不是從隨機初始值開始梯度下降,通常模型經過小幅度的步伐調整后就可以達到適用于重構模型的最優值,使重構模型可針對目標樣本自適應地調整高層的參數從而提高目標檢測能力[14]。

圖3 Inception3 結構圖Fig.3 Structure diagram of Inception3
2.2 模型改進方法
為了擴展網適用性,如圖4所示。
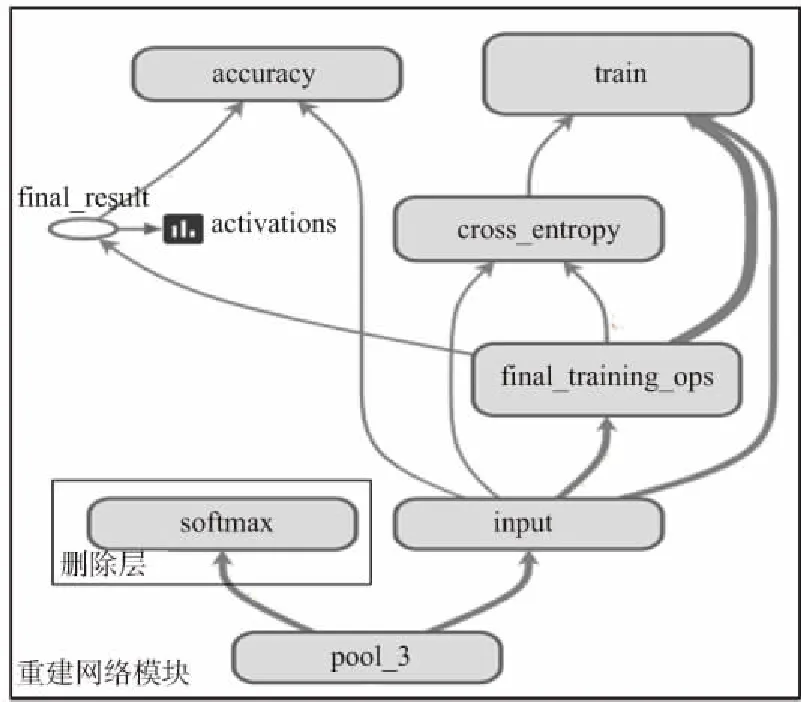
圖4 模型修改圖Fig.4 Modified map of the model
本文加入了一個新的網絡模型替換了原來的分類模塊,這個新模型由前向傳播和反向傳播兩部分組成。前向傳播主要是將通過遷移學習的策略保留了pool_3及以下的卷積層和池化層參數等提取的特征傳遞給輸入層,隨后分類的值與標簽(Label)差值求loss值,而反向傳播主要是為了更新全連接層的參數,盡量減少loss值。其中本次模型將交叉熵代價函數[15]作為損失函數loss,其公式為:
(3)
式中,C為代價函數;x為樣本;y為實際值,a為輸出值;n為樣本總數。在圖像分類時,Softmax函數表示將圖片識別為特定類的概率,其公式如下:
(4)
整體模型如圖5所示,首先將數據喂入特征提取模塊,該模塊使用的是經過大量數據訓練好的參數,隨后將提取特征模塊輸送到分類層(重建網絡模塊),僅僅需要更新全連接層的參數進行分類。圖5上半部分可壓縮高度,下半部分那兩行方框可左右對齊,這樣圖字就不擠了。
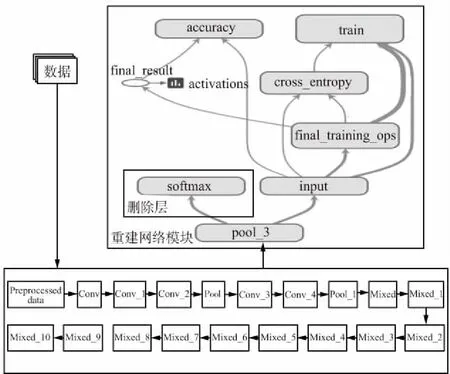
圖5 整體流程圖Fig.5 Overall flow chart
3 實驗結果與分析
本文所有實驗均在TensorFlow框架上實現,硬件平臺為 Intel(R) Core(TM) i3-4010 cpu,主頻為1.7 GHz,內存為6 GB。
3.1 實驗數據集和參數設置
本文是在TensorFlow框架上實現基于Inception V3的參數遷移學習,實驗所用數據集為飛機、狗、貓和吉他,其數量為每類各300張圖片。選用RuLu作為激活函數,RMSProp作為模型優化器,初始學習率為0.001。
3.2 結果分析
由于實驗數據較小且采用遷移學習策略,模型整體收斂較快,且在本實驗的硬件配置下訓練,說明不需要大算力的支持。模型參數評估圖如6所示,圖6中x軸為迭代步數,y軸為函數值,展示了訓練過程中準確率和交叉熵損失函數隨網絡的迭代步數變化的趨勢,可以看出,迭代次數還較小的時候,準確率已經達到了0.9以上,其loss值也是在前200次迭代過程中呈指數下降,最終loss值也是達到了0.080。此外,我們隨機從網上找了一些圖片來驗證模型,部分結果如圖7所示,每張圖都有這四類的判斷概率,我們的模型能夠準確地分類,并有較高的識別率。
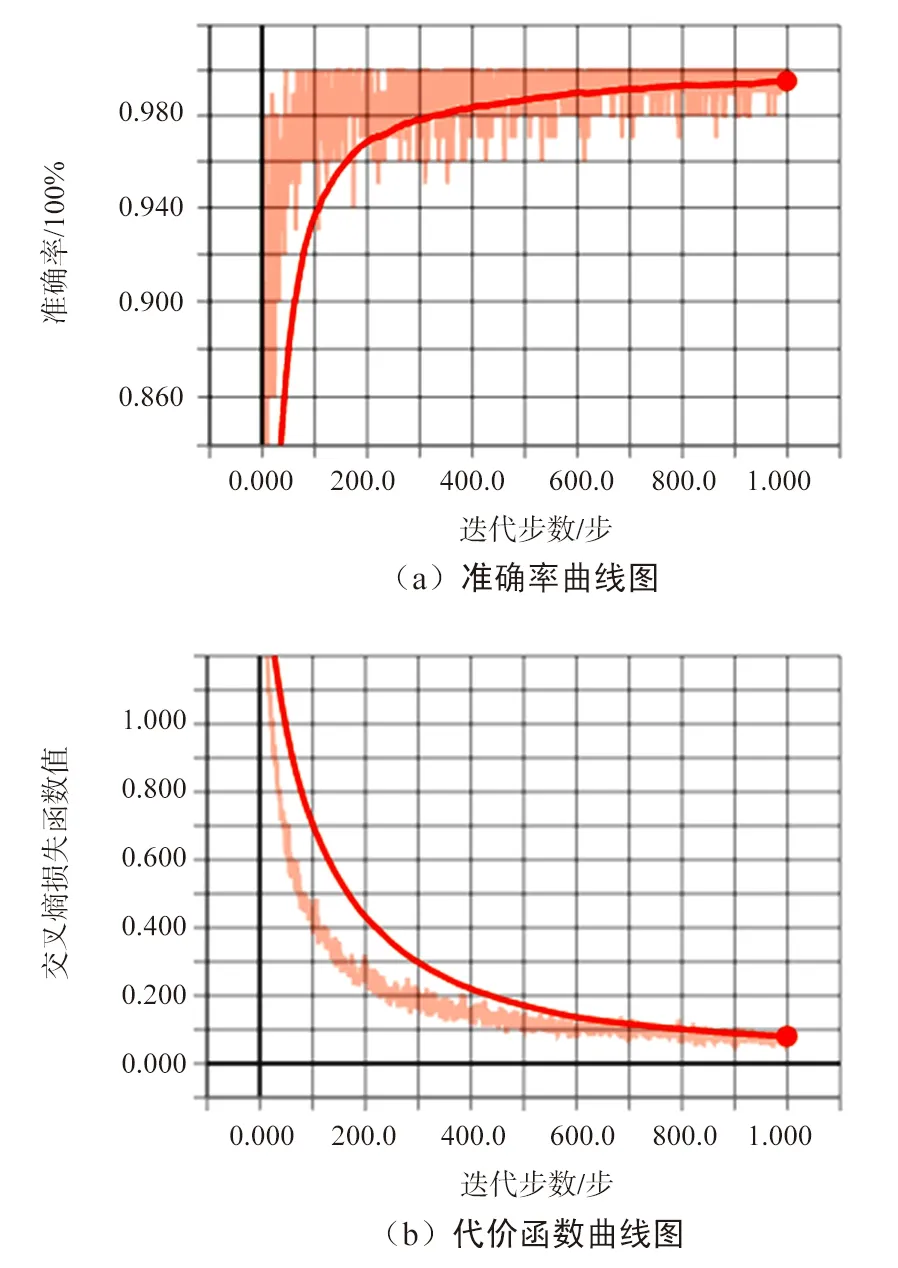
圖6 模型參數評估圖Fig.6 Model parameter evaluation diagram

圖7 部分結果展示Fig.7 Partial results show
4 結束語
本文引入了遷移學習策略,以Inception V3 為基礎框架,驗證了遷移學習的優勢。在實驗中,實驗硬件較差,訓練數據集較小,訓練次數僅為1 000,此模型就能快速地收斂。所以,對模型的遷移學習可以更快更好地幫助目標領域學習。隨著深度學習的快速發展,各式各樣的模型層出不窮,而針對這一現狀,遷移學習作為一個新興領域也必將成為未來研究的主題之一[16]。通過上述實驗,分析了Inception V3的結構和遷移學習的優點,對于Inception V3遷移學習的模型實際應用是下一步研究的重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
