基于自適應Siamese網絡的無人機目標跟蹤算法
2020-03-02 11:42:56劉芳楊安喆吳志威
航空學報 2020年1期
關鍵詞:模型
劉芳,楊安喆,吳志威
北京工業大學 信息學部,北京 100124
相比于載人飛機,無人機因其體積小、隱蔽性強、反應快速、對作戰環境要求低和能迅速到達現場等優勢,被廣泛應用于軍事和民用領域。而無人機的廣泛應用需要目標跟蹤技術,它能極大增強無人機的自主飛行和監控能力,使得無人機能夠完成更多種類的任務,并且適應更復雜多變的環境[1]。因此,研究有效而穩定的目標跟蹤算法對于無人機的應用具有重大的意義[2]。
無人機在飛行過程中拍攝視角和飛行速度經常會發生改變,導致目標易發生形變、遮擋等情況,經典跟蹤算法效果較差。近年來,基于相關濾波的跟蹤算法如KCF(Kernelized Correlation Filters)[3]、SAMF[4]和MUSTer[5]等在跟蹤精度和跟蹤速度上有著較好的效果,相關濾波逐漸成為跟蹤領域的重要研究方向之一[6]。目標的特征表達是影響其性能的重要因素之一,傳統的人工特征對目標狀態變化不魯棒,而無人機在很多實際應用中往往要面對復雜的環境,基于傳統特征算法的跟蹤效果不理想。深度網絡因其具有良好的特征表達能力,研究人員采用深度特征代替手工特征,比較有代表性的跟蹤方法有DeepSRDCF[7]、SiamFC[8]、CFNet[9]和DCFNet[10]等。盡管上述跟蹤算法在跟蹤成功率和精度上取得了顯著的提升,但是在目標發生形變、遮擋等情況下,仍然容易發生漂移現象,導致算法的準確度降低。Danelljan等[11]提出一種生成模型提升了訓練樣本的多樣化,并對目標函數進行了完善和改進,優化了樣本分布,減輕了形變情況對性能的影響,但由于更新過程計算較為復雜,跟蹤速率較低。Liu等[12]提出了一種新穎的模板匹配式跟蹤算法,使用K近鄰法從以往的跟蹤結果中找出最準確的結果,但算法只是使用簡單機器學習算法對樣本進行分類,導致算法的性能不理想、準確率較低。
綜上所述,針對無人機視頻中目標易受到遮擋、形變等問題,提出一種基于自適應Siamese網絡的無人機目標跟蹤算法(SiamRAT)。首先,利用兩個全卷積網絡構建Siamese網絡,將2個網絡的輸出特征進行卷積得到響應圖(Response map)從而預測目標位置,采用神經網絡模擬相關濾波的整個過程,能夠有效提升跟蹤精度和速度。然后,利用高斯混合模型對以往的預測結果進行聚類并建立目標模板庫。高斯混合模型擁有強大的數據描述能力,能夠將相似的數據聚集到一起,并且不同類別之間擁有較大的差異性,從而保證模板的多樣性。經過此模型得到的模板庫能夠讓網絡充分學習到目標的多種狀態信息,提升特征的有效性。其次對每一幀的預測結果進行判別,當模板庫中存在類似的樣本可以直接替換Siamese網絡中模板分支的輸入,讓算法從以往的跟蹤結果中挑選出最可靠的目標狀態,以應對目標的外觀變化,同時可以避免重復的計算操作。最后,引入回歸模型進一步精確目標位置,提升跟蹤算法的精確率。仿真實驗結果表明,該算法有效降低了形變、遮擋等情況對算法性能的影響,有效提高了跟蹤算法的準確度。
1 自適應Siamese網絡模型與跟蹤算法
針對無人機視頻中目標易發生形變、遮擋等問題,提出一種基于自適應Siamese網絡的無人機目標跟蹤算法。網絡共有2個分支,如圖1所示。其中網絡上半部分為模板分支,下半部分為檢測分支,并通過學習相似度函數f(z,x)在空間φ中比較目標模板圖像z和當前幀圖像x,從中找出與目標模板圖像最相似的樣本作為預測目標,表達式為
f(z,x)=φ(z)*φ(x)+b
(1)
式中:*表示將兩個特征圖矩陣進行互相關計算;b為一個偏置,并在每個位置都是相同的。
為了構造有效的損失函數,對響應圖的位置點進行了正負樣本的區分,即目標一定范圍內的點作為正樣本,范圍外的點作為負樣本。對于響應圖中每個點的損失函數為
l(y,v)=lg(1+exp(-yv))
(2)
式中:v為每個點的真實值;y∈{+1,-1}為這個點所對應的標簽。
對于響應圖的整體損失則采用全部點的損失均值,即
(3)
式中:u∈D為響應圖中的位置;y(u)表示為

(4)
其中:k為網絡步長;c為中心點;R為搜索區域半徑。
卷積網絡的參數θ使用SGD(Stochastic Gradient Descent)優化去計算:
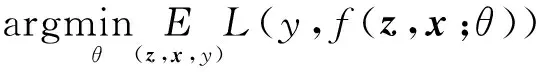
(5)
網絡的具體參數如表1所示。最大池化層分別部署在前兩個卷積層之后,ReLU非線性激活函數部署在除了最后一層外的每個卷積層之后,BN(Batch Normalization)[13]層被嵌入每個線性層之后,網絡中沒有填充操作。網絡分為2個輸入,一個輸入目標圖像,大小為127×127×3,另一個輸入當前幀搜索區域圖像,大小為255×255×3,搜索區域為上一幀目標大小的4倍,并將余弦窗添加到響應圖中以懲罰最大位移。

圖1 自適應Siamese網絡模型Fig.1 Adaptive Siamese network model
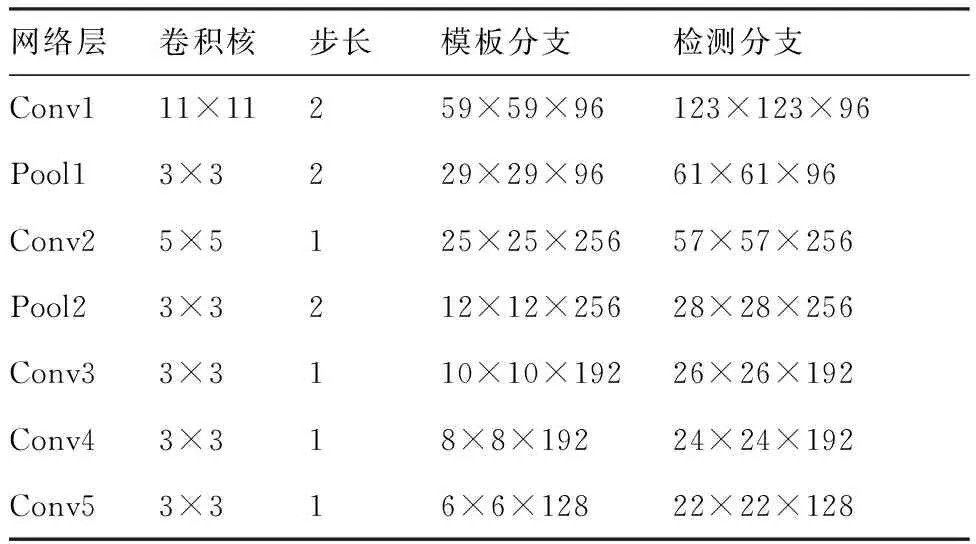
表1 網絡參數Table 1 Network parameters
1.1 自適應模板更新策略
無人機在飛行過程中,背景是不斷變化的,目標也是運動的,當無人機自身姿態和攝像頭視點發生變化時,容易造成拍攝視頻中的目標發生形變、遮擋等情況。目前基于Siamese網絡的跟蹤算法未能將跟蹤過程中代表目標各種狀態的多個實例樣本考慮在內,面對形變、遮擋情況時跟蹤準確度還有待提升[14]。由于Siamese網絡跟蹤算法是基于相似度匹配的跟蹤算法,當匹配模板不足以表達當前時間段的目標狀態時,就會造成跟蹤性能的下降,這就需要對匹配的模板進行更新,以適應跟蹤目標的變化。如果每一幀都更新網絡的輸入模板,不僅會大幅提升計算量,而且會造成模板冗余的情況。針對此問題,提出一種自適應模板更新策略,如圖2所示。利用目標在跟蹤過程中的多個狀態建立實例模型,在時間序列上構建多個實例樣本模型,模型之間相互獨立,既能重
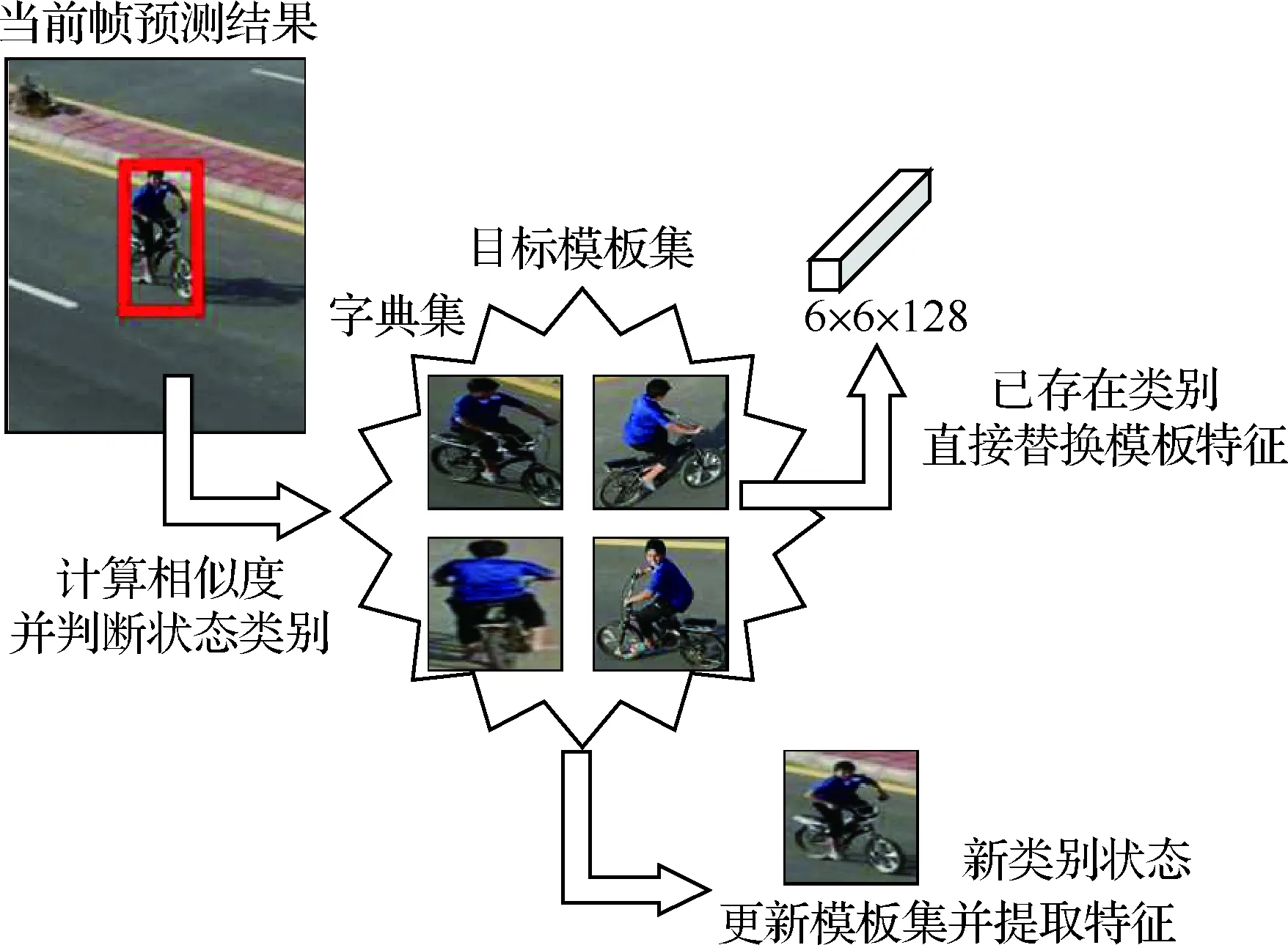
圖2 自適應更新策略Fig.2 Strategy of adaptive update
復表征目標的最新狀態,又降低了模型漂移對跟蹤算法的影響。
在跟蹤過程中,目標不可避免地會發生多種形態變化或者被障礙物遮擋。當發生這種情況時,如果不及時對網絡的匹配模板進行更新將會導致算法性能的降低。這就要求跟蹤算法能夠保存目標的多種狀態信息,當目標發生變化時能夠及時進行更新,從而保證網絡能夠適應目標的變化。為了保存跟蹤過程中目標的多種狀態信息,本文采用高斯混合模型對目標的狀態進行建模,高斯混合模型(GMM)是一種廣泛使用的聚類算法,該算法使用多個高斯分布作為參數模型并刻畫數據分布。相比K-Means,高斯混合模型算法能夠提升更強的描述能力,不同類別之間具有較大的差異性,而同一類別的數據相似性大,如圖3所示。

圖3 不同樣本集對比Fig.3 Comparison of different sample sets
設隨機變量x,則高斯混合模型可以表示為
(6)
式中:N(x;μk;I)為高斯混合模型中的第k個類型,若有K種類型需要聚類,則可以用K個高斯分布來表示,μk∈X為均值,協方差矩陣被設置為單位矩陣I以避免高維樣本空間中復雜計算;πk為混合系數,相當于每個類型的權重,且滿足:
(7)
為了提升算法的計算速度,根據Declercq和Piater的方法[15],使用一個簡易算法去更新GMM。當得到一個新的預測圖像xj,如果為新的類別,則初始化一個新類型樣本集m和其中的2個參數πm=γ和μm=xj。當樣本類型的數量大于所設定的閾值K時,去掉權值πk最小的那一類,保留當前圖像作為新的一類,并設置其權值為中間值,防止漂移現象。如果存在相似模板,則把這兩個類型k和l合并為一種類別樣本集n,合并方法為
(8)
式中:距離的計算是將其變換到頻域中并使用Parseval公式來計算,大大減少時間損耗。
對Siamese網絡的匹配模板進行更新可以讓網絡在跟蹤過程中適應目標的變化,提升跟蹤的可靠性。若每一幀都更新模板分支的特征,會導致算法每一幀都要進行兩個卷積網絡的特征提取步驟,這樣勢必會增加很多計算負擔,造成算法速率下降。如何在提升算法性能的條件下,盡可能減少速率的損耗是當前亟待解決的問題。
為了判別當前幀狀態是否與之前保存過的狀態類似,使用一種感知哈希算法進行簡單的狀態類別判斷。圖像中的高頻信息可以提供圖像的細節內容,低頻信息可以描述圖像中物體的框架,感知哈希算法(Hash)就是利用圖像的低頻信息去檢測圖像相似度的方法。首先將圖像通過下采樣方法縮小到8×8的尺寸,去除圖像的高頻信息,同時摒棄不同尺寸圖像帶來的差異性;其次將圖像轉化為灰度圖像,并計算其灰度平均值;之后將圖像中每個像素的灰度值與平均灰度值進行比較,大于等于則記為1,小于則記為0;將這64個比較值組合在一起就構成了這幅圖像的Hash指紋。這種計算方法快速高效,不受圖像大小尺度的影響。
通過計算兩幅圖像的Hash指紋,可以快速有效計算兩幅圖像的相似度,并判斷出當前預測圖像是否為目標的新狀態,將每種狀態信息保存下來,不僅可以使網絡模型自適應目標的變化,同時可以一定程度上降低模型的冗余度。主要過程為將預測的目標圖像從原圖像中裁剪下來,計算此圖像與模板集中每個模板圖像的Hash指紋。由于Hash指紋個數只有64個,當兩幅圖像的Hash指紋差值<10%時,即兩個Hash指紋不同位的個數<6.4,可以認為兩幅圖像相似度較高;當差值>20%時,即兩個Hash指紋不同位的個數>12.8,可以認為兩幅圖像相似度較低。實驗中采用以下判別數值:當兩個Hash指紋不同位的個數<5時說明兩張圖像相似度較高,可以認為是同一狀態圖像,2個Hash指紋不同位的個數>5且<10時說明兩幅圖像有些不同,但比較相近,說明是目標的新狀態圖像,2個Hash指紋不同位的個數>10則說明圖像距離較遠,相似性程度低,可以判斷為是遮擋或跟蹤錯誤的情況,不進行更新操作。
跟蹤過程中不可避免地會遇到相似目標的干擾,由于相鄰兩幀目標的移動距離不會過大,若當前響應圖中較大的響應值離中心較遠,這時會通過余弦窗進行懲罰,降低該響應值的干擾,從而處理相似目標干擾的情況。
通過狀態類別判斷和建立模板集2個部分操作之后,可以生成最適合當前幀的精確目標模板,因而將此模板替換網絡中模板分支的輸入,可以使網絡自適應目標的各種狀態變化,提升網絡性能。自適應模板更新策略的主要過程如下:
1) 使用第1幀目標圖像建立高斯混合模型,并定義為第1類目標狀態。
2) 計算每一幀預測結果與所有模板圖像的Hash指紋,計算其不同位的個數。
3) 如果不同位的個數<5,則認為與此模板類似,直接將此模板特征作為下一幀的模板特征。
4) 如果不同位的個數>5且<10,則建立或更新高斯混合模型,并利用模板分支提取此特征。
5) 如果不同位的個數>10,則不考慮此圖像。
1.2 區域建議回歸模型
基于Siamese網絡的跟蹤算法僅僅考慮響應圖中最大響應點,而忽略了其他響應點重要性,沒有對其進行綜合考慮,這樣可能會降低對目標位置預測的精確性。同時在尺度方面,大多數算法只取幾個不同的系數對目標尺度進行預測或借鑒R-CNN[16]中的回歸思想對目標周圍截取大量圖像進行回歸預測來定位目標的精確位置。前者算法只是對目標尺度乘以不同的尺度系數,并找出響應值最高的尺度框作為目標的最終位置,當目標發生較大尺度變化時缺少相應的尺度系數,預測能力顯著降低;后者算法在回歸預測環節提取大量圖像樣本特征,增加算法的運算量,降低算法效率。針對以上問題,提出一種基于區域建議的回歸模型,提取響應圖中高于一定閾值的響應點,得到包含目標信息的候選圖像,并放入訓練好的回歸模型進行位置預測,能夠在不損失過多性能下降低算法復雜度,提升算法效率,同時還能提升目標位置準確性。
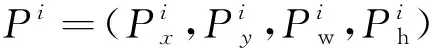
傳統的回歸模型在回歸預測階段也會提取大量的樣本圖像做回歸預測得到最終目標框,大量的樣本圖像導致算法的計算量大幅增加,降低算法效率。針對此問題提出一種基于區域建議的回歸模型。首先,使用視頻中第1幀圖像的Conv5層特征訓練回歸模型并得到回歸函數,之后提取Siamese網絡的目標實例特征和當前幀的圖像特征進行互相關計算,得到17×17大小的響應圖,提取響應圖中高于閾值的響應點作為待預測的目標中心點,根據上一幀的目標尺度大小得到每個中心點的目標框,之后把每個目標框內的圖像送入回歸模型進行預測,最終得到目標的精確位置信息,如圖4所示。此模型與傳統回歸模型中在預測環節提取目標周圍大量的樣本圖像相比,降低了預測環節中輸入圖像的數量,降低了算法的計算量,在不損失過多性能的條件下提升了算法效率。

圖4 基于區域建議的回歸模型Fig.4 Regression model based on region proposals
1.3 跟蹤算法步驟
步驟1利用模板分支提取第1幀目標圖像特征fe,之后提取目標周圍N個樣本圖像的Conv5特征訓練回歸模型。
步驟2利用檢測分支提取當前幀圖像中搜索區域的圖像特征fi。
步驟3對特征fe和fi進行互相關計算得到響應圖。
步驟4提取響應圖中高于閾值的響應點圖像作為預測回歸的樣本圖像,利用區域建議回歸模型得到回歸后的目標圖像。
步驟5計算當前幀預測結果與模板庫圖像的相似度,建立或更新高斯混合模型,并得到最適合當前目標狀態的模板圖像。
步驟6若當前狀態為新狀態則通過模板分支提取目標特征作為新的fe,若為舊狀態則直接替換Siamese網絡的模板特征。
步驟7重復步驟2~6直到視頻結束。
跟蹤算法流程如圖5所示。
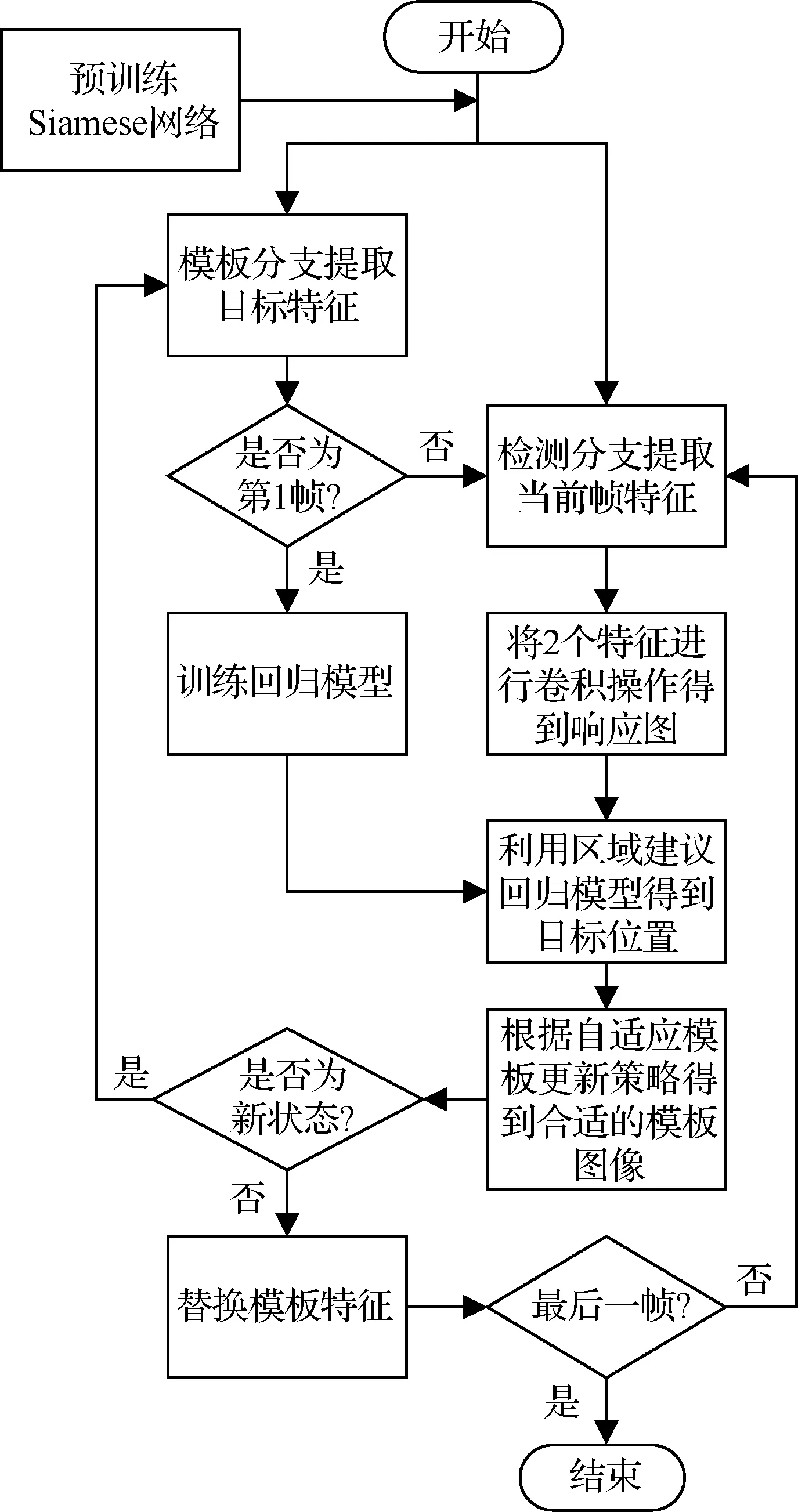
圖5 跟蹤算法流程圖Fig.5 Flowchart of tracking algorithm
2 仿真實驗
2.1 實驗數據
為驗證本文算法的有效性,選取UAV123數據集和無人機實際采集的視頻圖像序列作為測試數據集。UAV123[17]數據集包含123個視頻序列,涉及12種屬性變化,主要涉及無人機在低空環境下對目標的拍攝場景,由于無人機拍攝的角度與高度不一致,導致目標角度多變及尺度多變,挑戰難度也很大。實驗采用跟蹤成功率和跟蹤精確率2個通用的評價指標來進行定量分析。跟蹤成功率反映跟蹤得到的目標框和給定的實際目標框的重疊程度大于給定閾值的視頻幀數占總視頻幀數的比例,因此,隨著對重疊程度的要求越高,即閾值越大,反而成功率曲線不斷下降。跟蹤精確率反映跟蹤得到的目標中心位置和給定的實際目標中心位置的距離小于給定的某個閾值的視頻幀數占總視頻幀數的比例,因此,隨著閾值的增大,精確率曲線不斷上升。其中圖例中的數字分別表示中心位置誤差取值為20時對應的跟蹤精確率和覆蓋率取值為0.5時對應的跟蹤成功率。
實驗中,訓練數據集為ILSVC-2015_VID,包含4 500個視頻,100萬張有標注信息的圖像。實驗平臺為Inter core i7-7700K CPU 4.2 GHz,GPU為GeForce GTX 1070 8 G,訓練采用MatConvNet工具,迭代50次,每次迭代包含5 000個樣本對,每次迭代的mini-batch設置為8,學習率為10-2~10-5,算法跟蹤速率約為20幀/s。其中所對比算法的結果均為其論文中的結果或其開源程序在上述實驗平臺上的結果。
為了降低網絡過擬合的影響,在網絡訓練階段使用ILSVC-2015[18](ImageNet Large Scale Visual Recognition Challenge)目標檢測數據集。ILSVC-2015數據集中包含一些目標占據整個畫面的視頻,而這些視頻不符合真實場景的跟蹤任務,所以對這些視頻進行篩選,最終選出4 500個視頻,大約包含100多萬標注過的視頻幀圖像。這個數據集不僅擁有龐大的規模,而且與標準跟蹤數據集中的目標和場景不同,所以可以盡量減少過擬合的影響。
2.2 實驗結果與分析
為驗證所提算法(SiamRAT)在目標發生遮擋、形變等情況下的有效性,將所提算法與SiameseFC、STRCF[19]和EAST[20]算法進行對比,其中STRCF和EAST是針對形變、遮擋情況而改進的跟蹤算法。實驗數據采用UAV123@10fps數據集中發生遮擋、形變的視頻,共60個。實驗結果如表2所示。在形變、遮擋場景下,相比于單實例模型的SiameseFC跟蹤算法,所提算法能夠有效提升22.65%和31.51%的精確率,同時優于其他改進算法。這其中的原因一方面是跟蹤算法建立在多個狀態實例樣本之上,相比于建立在單個實例樣本之上的SiameseFC跟蹤算法,抓住了跟蹤目標特有的狀態信息,能夠更好地適應目標的形變;另一方面,通過對狀態信息的判別,有效降低了遮擋情況對跟蹤性能的影響,相比于利用時間正則化對遮擋情況處理的STRCF算法,所提算法避免了多次的參數更新,利用哈希感知算法有效判別遮擋情況,故能提升算法速率并有效減輕遮擋對算法性能的影響。
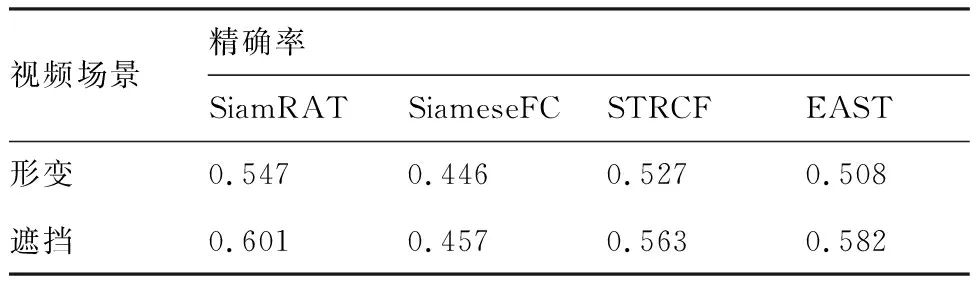
表2 針對形變、遮擋情況的算法精確率對比
為驗證所提算法在實際任務中的有效性,在實際采集的4個無人機視頻中使用了4種算法進行對比分析,結果如圖6所示。前2個視頻中跟蹤目標為大巴車和黑色小轎車,在跟蹤的過程中被遮擋物遮擋,影響了部分算法性能,當目標離開遮擋物時,所提算法能夠穩定跟蹤目標;后2個視頻中跟蹤目標為騎車的人和卡車,由于目標行徑方向發生改變,造成視頻中目標狀態發生了變化,使得當前狀態與第1幀的目標狀態有很大區別,而所提算法由于在跟蹤過程中動態更新模板,使得算法依然能夠穩定跟蹤目標。
為驗證自適應更新策略的有效性,在所提算法(SiamRAT)的基礎上去掉自適應更新部分,使用UAV123數據集進行測試分析,如圖7所示。其中2種算法分別為所提算法和不自適應更新目標狀態的算法(Not Updated)。結果表明:所提算法能夠有效提升15.24%的成功率和7.26%的精確率,從而可以證明自適應更新的Siamese網絡模型是有效的。不論從精確率還是從成功率來看,不加入自適應模板更新策略的算法性能都下降很大,說明模板的更新對跟蹤性能至關重要。

圖6 部分視頻仿真結果圖Fig.6 Results for partial video simulations

圖7 對比分析Fig.7 Comparative analysis
2.3 算法比較
為了驗證所提算法(SiamRAT)的有效性,選取UAV123數據集中的123個視頻序列作為測試序列,對所提算法進行測試,并與文獻[21-29]中主流跟蹤算法進行實驗效果對比,對比算法包含ECO、ECO-HC、SRDCF[21]、MEEM[22]、SiameseFC、MUSTER、SAMF、Struck[23]、DSST[24]、TLD[25]、ASLA[26]、CSK[27]、SiamRPN[28]、DSiam[29]。分別采用跟蹤成功率和跟蹤精確率的評價指標來進行定量分析,不同場景下跟蹤性能比較結果如圖8所示,比較場景分別為攝像機移動、視角變化、部分遮擋、完全遮擋、寬高比變化、尺度變化,在UAV123數據集下整體性能比較如圖9所示,場景名稱后的數字代表此場景的視頻序列數量。
面對這些較為復雜的場景,通過對圖8中的對比結果進行分析可以發現:所提算法在視角變化、遮擋、形變、尺度變化等場景下具有較好的性能,能夠較好地處理這些視頻,并對于其他場景下的測試視頻,所提算法的性能也是較好的,這也充分驗證所提算法在跟蹤準確性、穩定性和魯棒性方面具有優異的整體性能。其中的主要原因是采用了基于自適應Siamese網絡結構,跟蹤算法在不同時期建立在不同的實例樣本之上,抓住了跟蹤目標在不同狀態下特有的狀態信息,相比于只建立在單個實例模板上的SiameseFC算法,能夠更好地適應目標的各種變化,整體效果提升大約18%。從圖9也可以看出所提算法(SiamRAT)整體的跟蹤成功率為0.725,精度為0.771,其原因主要是由于采用了回歸模型進行目標位置預測,極大地提高了跟蹤精度和目標位置的準確性,同時基于區域建議的回歸模型能夠在不損失過多性能的情況下減小計算量,提高跟蹤速率。所提算法在所有算法的比較中性能只略低于SiamRPN算法,其原因主要是訓練集的大小相差過大,若使用更大的數據集進行訓練,算法性能會有一定的提升。
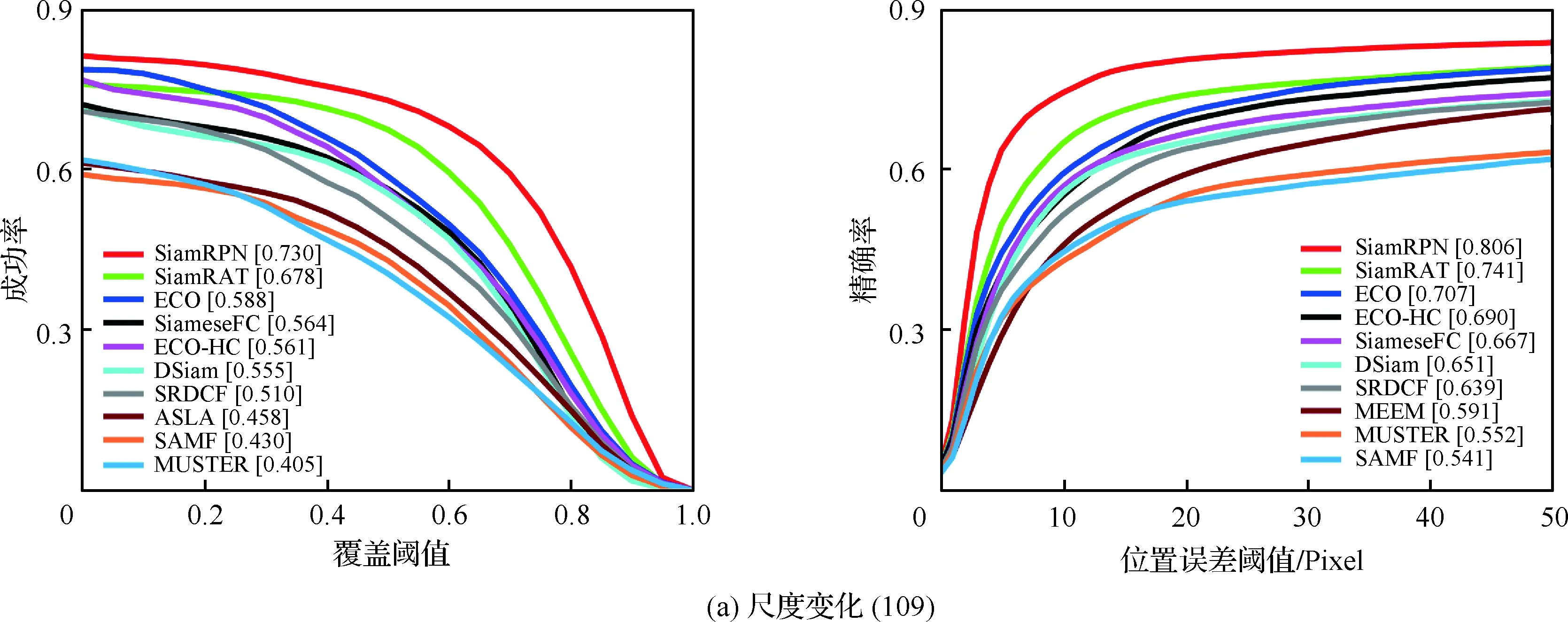
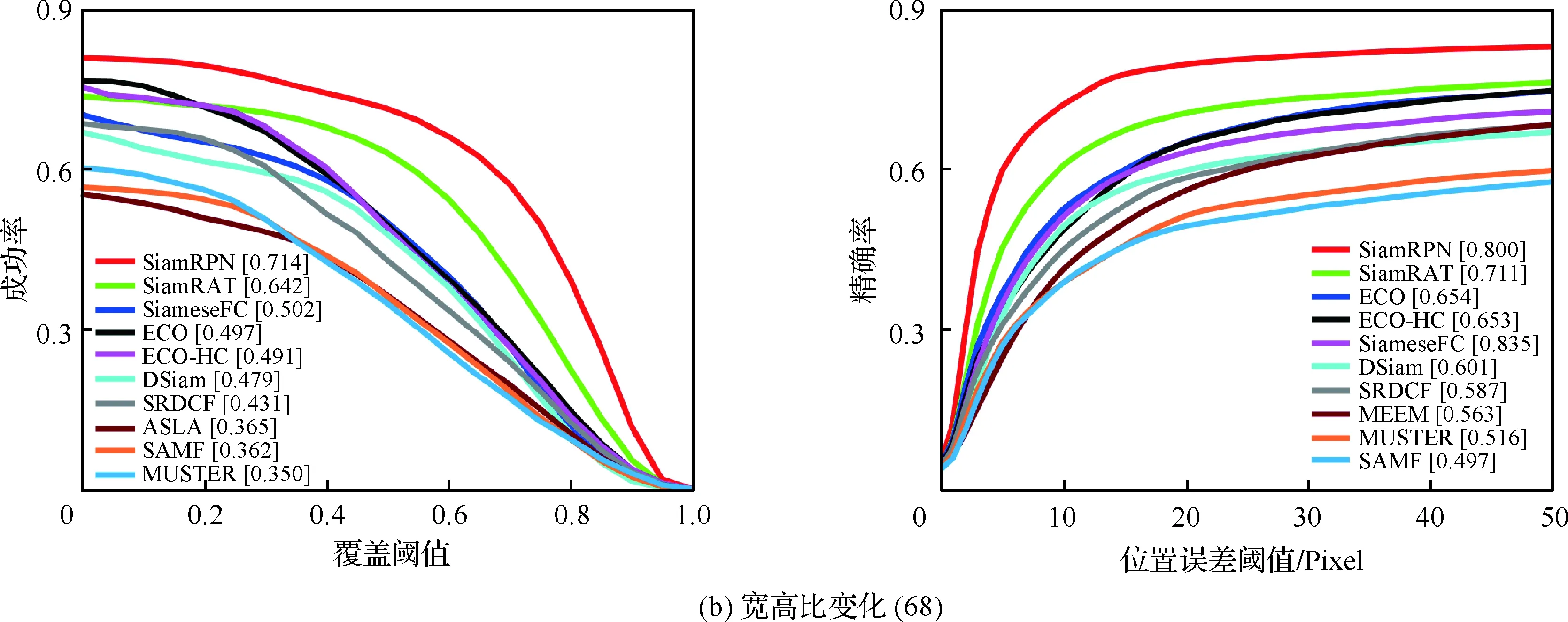
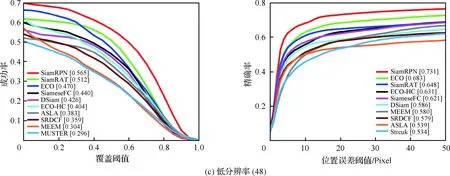
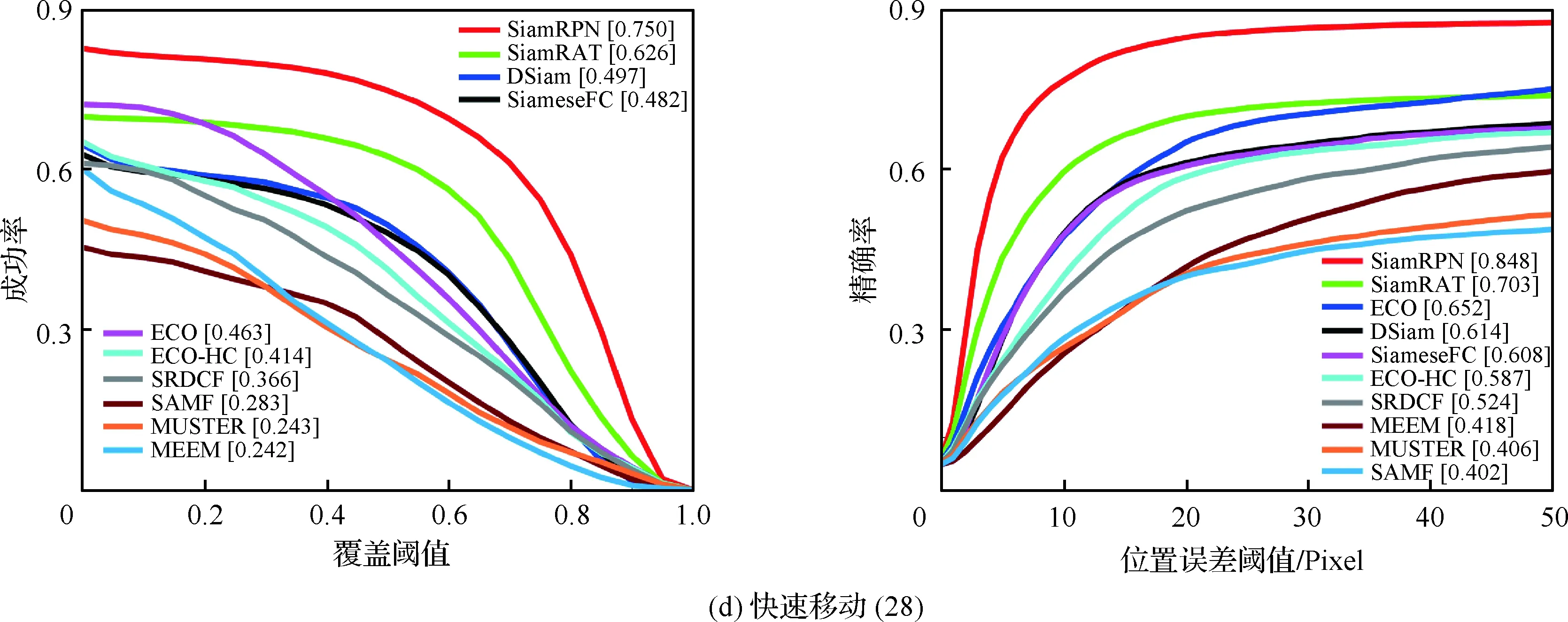
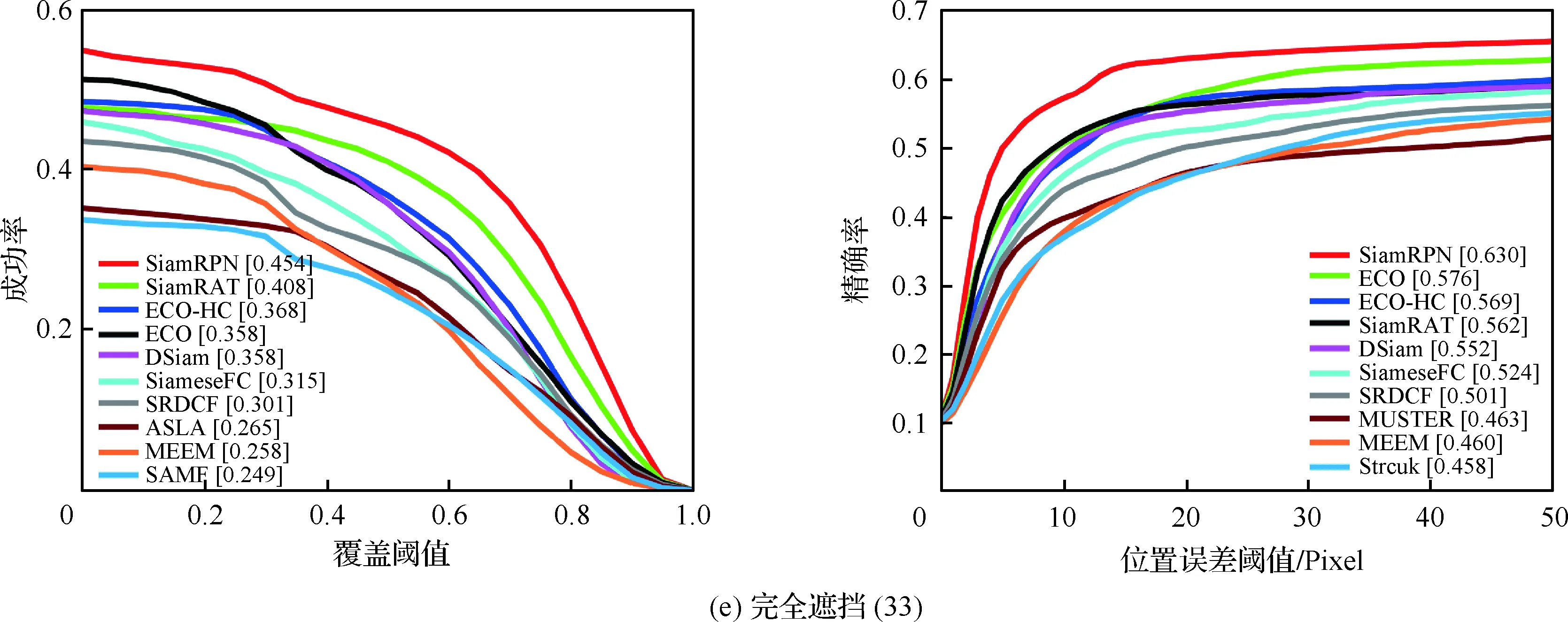
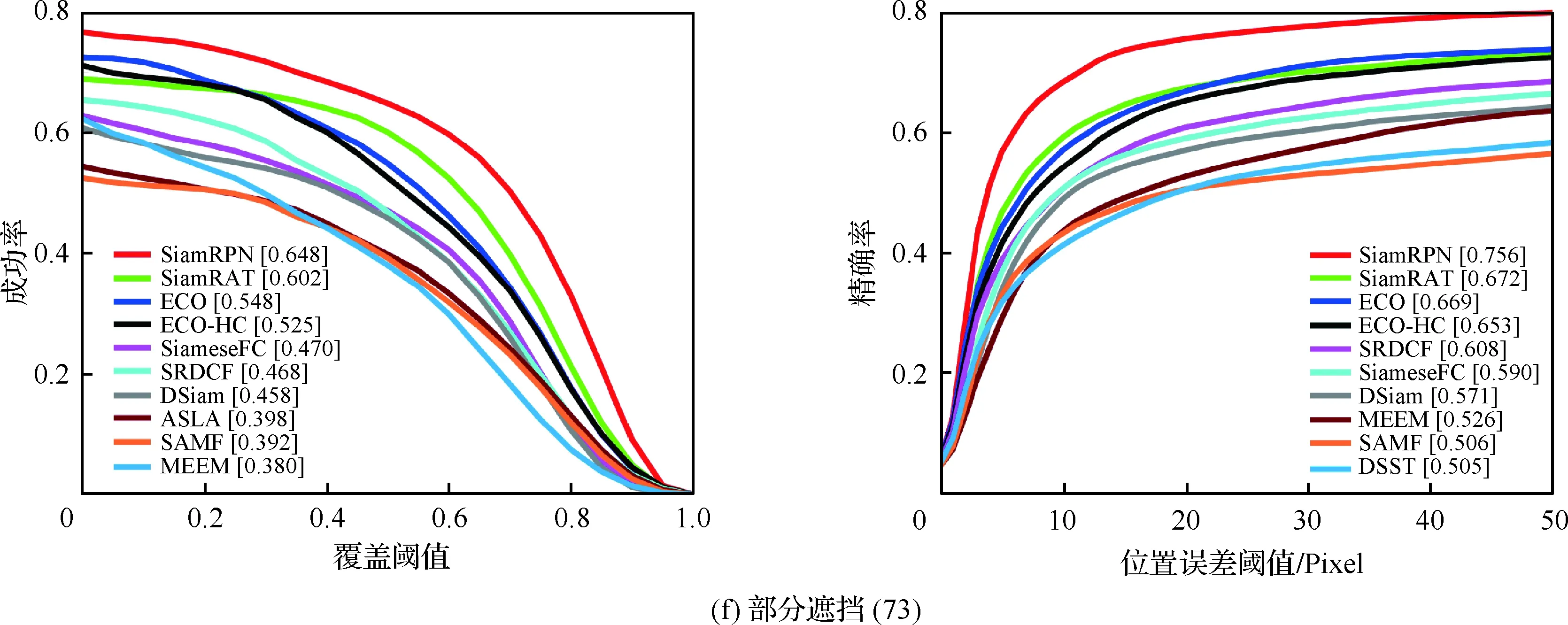
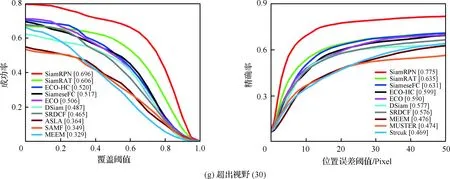

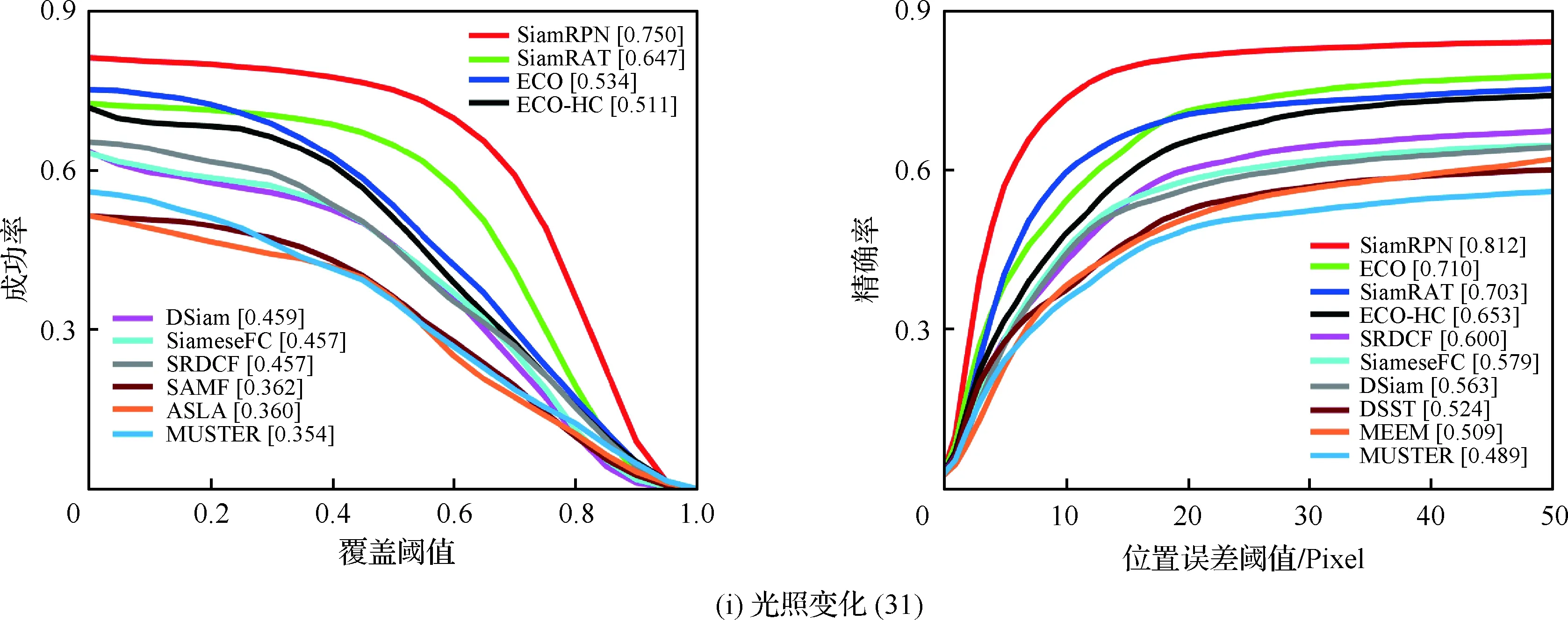
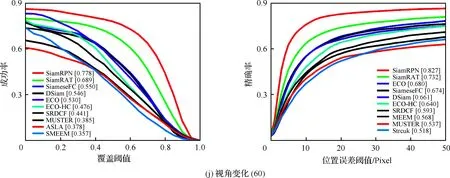
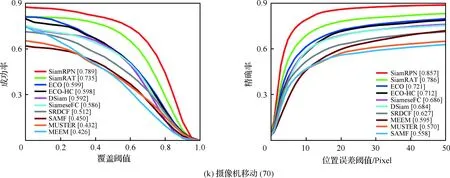
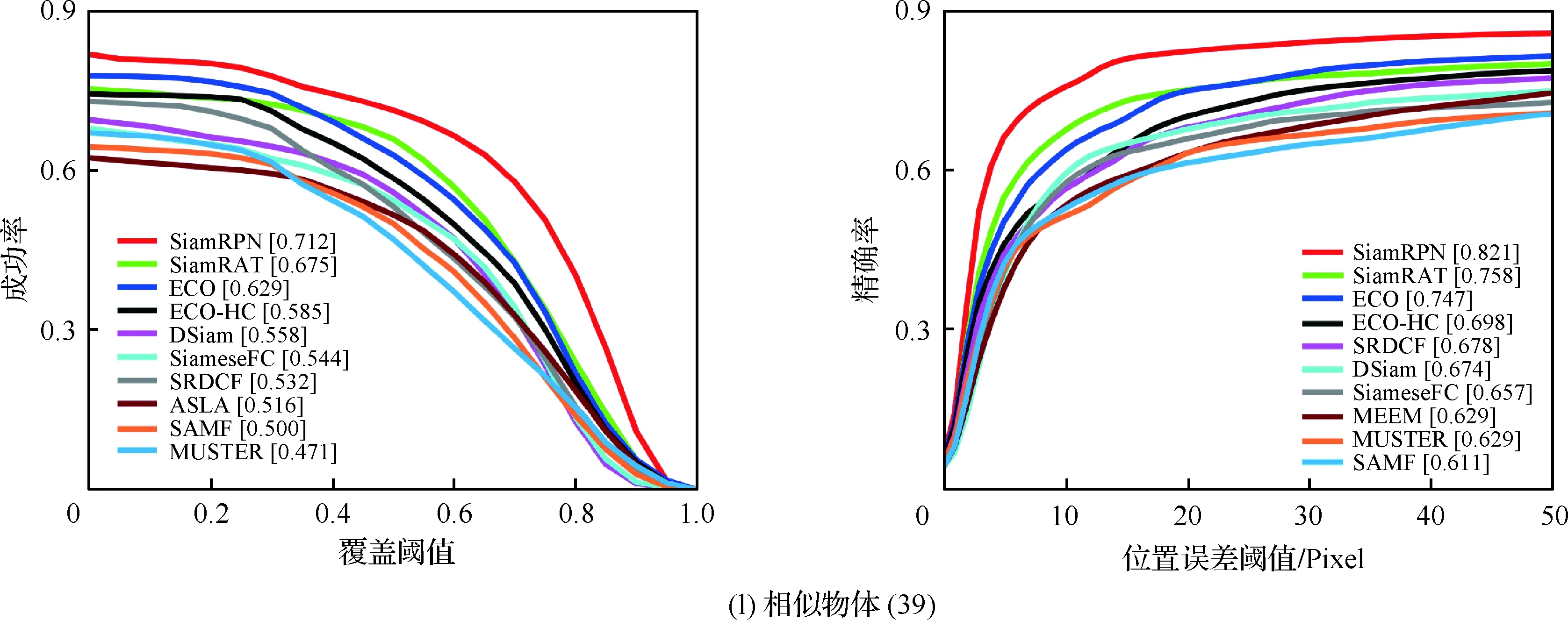
圖8 不同場景下的性能比較Fig.8 Comparison of performance in different scenarios
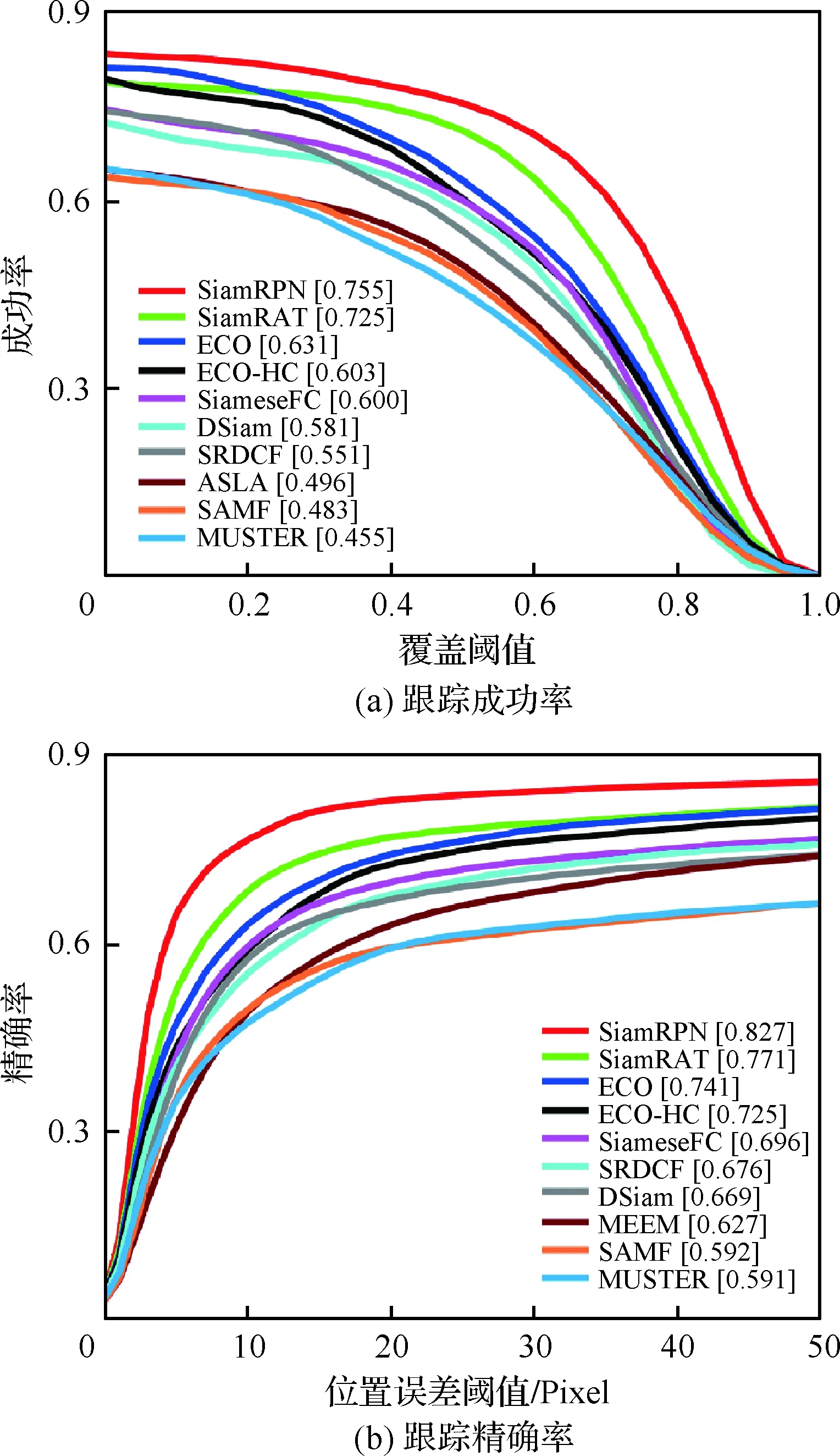
圖9 整體性能比較Fig.9 Overall performance comparison
3 結 論
針對無人機視頻中目標易發生形態變化、易被遮擋等問題,提出了一種基于Siamese網絡的無人機視頻目標跟蹤算法。
1) 針對無人機視頻中目標易發生形態變化、易被遮擋等問題,需要較準確的目標模板信息以供算法預測目標,結合Siamese網絡和自適應策略構建了自適應Siamese網絡模型。
2) 根據所構建的模板圖像集對每一幀所預測的目標進行處理優化,得到較為精確的目標模板,代替網絡中第1個分支的模板圖像,較好地提升了網絡對目標變化的適應性,同時引入回歸模型提升了預測準確度和精確度,降低了周圍背景對網絡性能的影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
