動態(tài)模糊粗糙特征選取算法*
2020-02-20 03:42:04劉陽明趙素云李翠平
計算機(jī)與生活 2020年2期
倪 鵬,劉陽明,趙素云+,陳 紅,李翠平
1.中國人民大學(xué) 數(shù)據(jù)工程與知識工程教育部重點實驗室,北京 100872
2.中國人民大學(xué) 信息學(xué)院,北京 100872
1 引言
近年來,粗糙集理論因不需要太多額外的知識且容易理解,而獲得了較多的關(guān)注。大量的基于粗糙集的挖掘技術(shù)被提出[1-10]。其中,大部分的方法基于同一個前提:數(shù)據(jù)是靜態(tài)的。一旦數(shù)據(jù)隨著時間和空間動態(tài)地更新,這些靜態(tài)方法的學(xué)習(xí)結(jié)果已不適用,需要重新掃描更新后的數(shù)據(jù)集重新計算。顯然,重新掃描整個數(shù)據(jù)集的操作導(dǎo)致時間與空間的浪費,甚至數(shù)據(jù)規(guī)模較大時,這些靜態(tài)方法不再適用[11]。
增量學(xué)習(xí)是一種適用于增量數(shù)據(jù)的數(shù)據(jù)挖掘方法,該方法通過分析新增數(shù)據(jù)與已有數(shù)據(jù)的結(jié)構(gòu)及關(guān)系來更新已有的學(xué)習(xí)結(jié)果,避免重新掃描整個數(shù)據(jù)集,從而大大降低了計算量,提高了計算效率[12-17]。近年來,為了解決數(shù)據(jù)的動態(tài)增長,已有很多學(xué)者將增量學(xué)習(xí)的思想引入粗糙集的應(yīng)用研究中[4,11,18-22]。
目前,基于粗糙集的增量學(xué)習(xí)方法分為三種:知識表示的更新、規(guī)則約簡的更新和特征選擇的更新。首先,知識表示的更新方法是指在動態(tài)數(shù)據(jù)集中快速有效地更新粗糙近似表示。比如,一些學(xué)者探索了基于不同粗糙集擴(kuò)展模型的更新上下近似的方法:粗糙集[20,23]、緊鄰粗糙集[24]、優(yōu)勢關(guān)系粗糙集[25]、貝葉斯粗糙集[26]、決策粗糙集[11]和粗糙模糊集[18,27]等。以上這些更新方法針對數(shù)據(jù)示例的逐個更新、數(shù)據(jù)示例的批量更新、特征的增減更新等不同的情況,分別討論分析了粗糙近似知識表示的相應(yīng)增量學(xué)習(xí)機(jī)制。其次,一些學(xué)者在規(guī)則約簡更新中提出了增量的更新方法。其中,一些增量的方法只考慮了在一個個添加示例的情況下規(guī)則的更新方法[28-30]。考慮到數(shù)據(jù)更新多是批量更新的,一些學(xué)者研究了一組組添加示例的過程中學(xué)習(xí)規(guī)則的更新[31-32]。此外,有一些規(guī)則學(xué)習(xí)的增量方法針對的是屬性集的更新[11,25,33]。
相較于其他兩種方法,特征選擇的動態(tài)更新的研究較少。一些學(xué)者提出了增量約簡算法針對數(shù)據(jù)集中數(shù)據(jù)一個個的增加的情況[22];還有一些學(xué)者提出的增量算法解決數(shù)據(jù)一組組增量的情況[21]。然而這兩種方法只考慮離散值數(shù)據(jù)集的動態(tài)變化情況。雖然有學(xué)者提出的增量算法針對的連續(xù)值數(shù)據(jù)集[34],但是該算法針對的是屬性集更新的情況。
通過以上分析可以看出,目前尚沒有針對連續(xù)值數(shù)據(jù)示例動態(tài)改變的屬性約簡的算法。考慮到模糊粗糙集技術(shù)是處理連續(xù)數(shù)據(jù)的有效工具,本文提出了一個基于模糊粗糙集的增量屬性約簡算法,來解決動態(tài)連續(xù)值數(shù)據(jù)集上的屬性約簡問題。當(dāng)前,主要關(guān)注在數(shù)據(jù)集示例的動態(tài)增加。
首先,通過分析添加示例前后模糊正域的變化,提出了模糊正域計算的增量機(jī)制。基于這個增量機(jī)制可以通過避免在動態(tài)數(shù)據(jù)集上的冗余計算,顯著地減少計算時間。然后,基于嚴(yán)格的理論推導(dǎo)發(fā)現(xiàn)了已有約簡的辨識能力改變的關(guān)鍵數(shù)據(jù)。這些關(guān)鍵數(shù)據(jù)的發(fā)現(xiàn)使得在有限的數(shù)據(jù)上快速更新已有約簡變得可行。最后,提出了一個增量屬性約簡算法。數(shù)據(jù)實驗表明了該增量算法是有效且高效的,特別是在高維數(shù)據(jù)集上效果更加突出。
2 模糊粗糙集相關(guān)研究
本章簡單回顧一些模糊粗糙集及其經(jīng)典的約簡算法。關(guān)于該理論的更多細(xì)節(jié),可以參考文獻(xiàn)[35-38]。
2.1 模糊粗糙集簡介
數(shù)據(jù)集可以描述成一個決策表,表示成一個三元組DT=<U,R,D>。這里U是一個非空示例集{x1,x2,…,xn}。每個示例由一組條件屬性R={a1,a2,…,am}以及一組決策屬性D來描述。決策屬性將論域劃分為q個決策類U/D={D1,D2,…,Dq},這里U=,且任意兩個決策類相交為空。
如果R是可以模糊化的(如連續(xù)值屬性),那么決策表DT=<U,R,D>表示一個模糊決策表。在模糊決策表上,粗糙集被推廣為模糊粗糙集。模糊粗糙集是融合了粗糙集和模糊集的概念而提出的理論。模糊粗糙集不僅將近似對象從離散集擴(kuò)展到了模糊集,而且將等價關(guān)系擴(kuò)展到了模糊相似關(guān)系。
定義1對于P?R以及給定的三角模T,屬性子集P的模糊相似關(guān)系可定義為P(?,?)。對于任意x,y,z∈U,P(?,?)滿足:(1)自反性(P(x,x)=1);(2)對稱性(P(x,y)=P(y,x));(3)T-傳遞性(P(x,y)≥T(P(x,z),P(z,y)))。
例如,模糊相似關(guān)系可以按照如下方式計算得到:r∈P,?x,y∈U,P(x,y)=minr∈P(r(x,y)),這 里r(x,y)=1-(max(r(x),r(y))-min(r(x),r(y)))。此時,P(?,?)即為屬性子集P所描述的模糊相似關(guān)系,它滿足自反性、對稱性和TL=max{0,x+y-1}三角傳遞性。
模糊粗糙集定義了模糊上下近似概念,如下。
定義2給定模糊決策表DT=<U,R,D>,對于A?U,那么模糊上、下近似定義如下:

在模糊粗糙集中,整個論域上的粗糙度量方式之模糊正域定義如下。
定義3給定模糊決策表DT=<U,R,D>,示例x∈U的模糊正域定義如下:
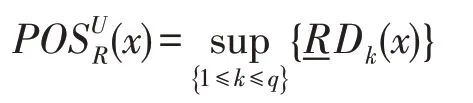
繼而,決策屬性D對條件屬性子集P?R的依賴度可以定義如下。
定義4給定模糊決策表DT=<U,R,D>和?P?R,決策屬性D對于屬性子集P的依賴度定義如下:
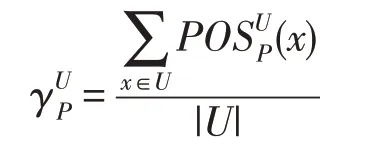
該定義度量了屬性子集P?R相對于決策屬性的依賴程度。
2.2 模糊粗糙集基本性質(zhì)討論
本節(jié)深入討論了模糊粗糙集的一些性質(zhì)。
性質(zhì)1依據(jù)定義2,給定模糊決策表DT=<U,R,D>和?A?U,示例x∈U相對于A的下近似定義可以簡化為:
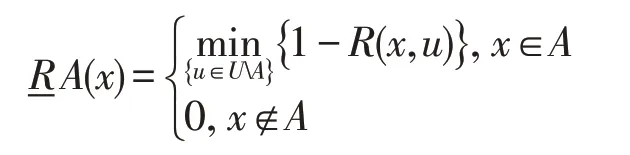
證明具體證明,請參考文獻(xiàn)[38]。 □
性質(zhì)1給出了下近似的幾何意義。即x屬于它所在的決策類的,下近似為離x最近的異類示例點u的距離;x屬于其他決策類的,下近似為0。基于此,可以得到性質(zhì)2。
性質(zhì)2依據(jù)定義3,給定模糊決策表DT=<U,R,D>,示例x∈U的正域可以簡化為。這里,[x]D={u∈U|D(x)=D(u)},即[x]D表示與x屬于同一決策類的示例集。
證明根據(jù)性質(zhì)1和定義3易得。 □
性質(zhì)2表明了模糊正域和下近似之間的關(guān)系。下面的性質(zhì)進(jìn)一步討論了依賴度隨著屬性的增加是如何變化的。
性質(zhì)3給定模糊決策表DT=<U,R,D>,如果P?Q?R,那么。
證明對于P?Q?R,有:
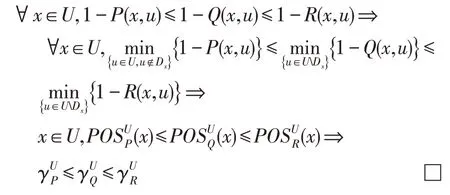
性質(zhì)3表明了依賴度函數(shù)隨著屬性的增加是單調(diào)不減的。這一結(jié)論是設(shè)計屬性約簡啟發(fā)式算法的理論根據(jù)。
2.3 基于依賴度的屬性約簡
約簡的核心思想是找到一個最小的屬性子集,該子集保持了全屬性集的辨識能力。約簡的定義如下,更多的細(xì)節(jié)可以參考文獻(xiàn)[33,37-38]。
定義5給定模糊決策表DT=<U,R,D>和?P?R,當(dāng)P滿足條件:(1)?a∈P,時,稱P是模糊決策表的一個約簡。
基于依賴度經(jīng)典的非增量屬性約簡算法,簡寫為CAR(classical attribute reduction),已被提出,并得到廣泛的應(yīng)用。
算法1經(jīng)典約簡算法(CAR)
輸入:DT=<U,R,D>
輸出:red。

3 模糊粗糙集上的增量機(jī)制
給定一個動態(tài)的模糊決策表DT=<U∪ΔU,R,D>,其中U={x1,x2,…,xn} 為原始實例,ΔU={xn+1,xn+2,…,xn+s}。基于第1章的概念和算法,針對增量數(shù)據(jù),需要重新計算模糊正域,既費時又存在重復(fù)的計算。因此,本章提出了幾個基本概念的增量機(jī)制,從而實現(xiàn)動態(tài)快速更新模糊正域。
3.1 模糊正域增量機(jī)制
首先,在動態(tài)數(shù)據(jù)集上計算更新后的模糊正域POSU∪ΔU(x)很有必要。這是計算依賴度的先決條件。
定理1給定模糊決策表DT=<U,R,D>,如果一些新示例ΔU={xn+1,xn+2,…,xn+s}加入進(jìn)來,那么:
(1)如果x∈U,則:
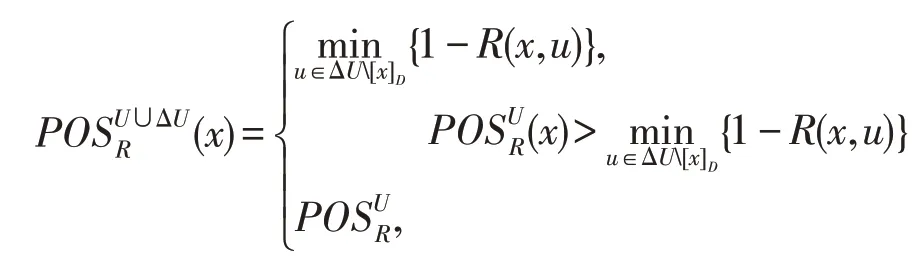
(2)如果x∈ΔU,則:
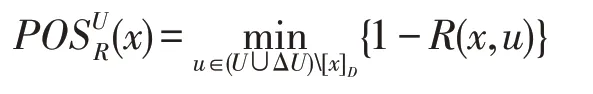
證明依據(jù)性質(zhì)2,對于x∈ΔU的情況,很顯然成立。
對于x∈U的情況:
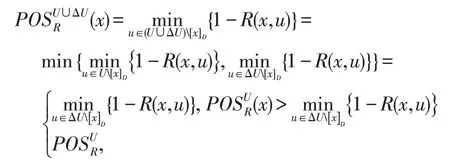
由此,定理1得證。 □
定理1理論分析并給出了一個快速更新模糊正域的方法,從而避免了遞增動態(tài)數(shù)據(jù)集上的模糊正域的冗余計算。
3.2 增量關(guān)鍵示例集
基于定理1,可以很快地得到POSU∪ΔU(x)。并且發(fā)現(xiàn),對于模糊正域來說,存在一個增量關(guān)鍵集。
定義6給定模糊決策表DT=<U,R,D>和P?R如果一些新示例ΔU={xn+1,xn+2,…,xn+s}加入進(jìn)來,那么令,稱之為增量關(guān)鍵示例集。
由定義6可知,如果x?ΔS,那么。這意味著已經(jīng)達(dá)到最大。因此,只需要在x∈ΔS如何選擇屬性。
4 基于模糊粗糙集的增量屬性約簡
本章基于以上增量機(jī)制,設(shè)計了一個增量約簡算法,簡寫為IAR(incremental attribute reduction),見算法2。
算法2基于依賴度的增量約簡算法(IAR)


5 實驗分析
本章構(gòu)造了一些對比實驗。使用的數(shù)據(jù)集來自UCI數(shù)據(jù)庫(https://archive.ics.uci.edu),數(shù)據(jù)的詳細(xì)信息見表1。實驗環(huán)境為Ubuntu release 16.0,Intel?CoreTMi7-4790 CPU@3.60 GHz,8 GB內(nèi)存。編程語言為C++。

Table 1 Description of datasets表1 數(shù)據(jù)集信息描述
實驗中對比了一種非增量的Naive依賴度算法,它在新數(shù)據(jù)到來時并不更新經(jīng)典依賴度算法,而只是利用之前的約簡作為新約簡的候選,這個算法簡寫為NonIAR,在本章中NonIAR和CAR均被用來與IAR進(jìn)行對比。實驗中每個數(shù)據(jù)集被平分為兩份。一份看作是原始數(shù)據(jù),另一份看作是新增的示例集。
NonIAR算法設(shè)計如下:
算法3非增量的Naive依賴度算法(NonIAR)

5.1 執(zhí)行時間對比分析
三種算法的執(zhí)行時間(單位:s)的比較結(jié)果見圖1、圖2。
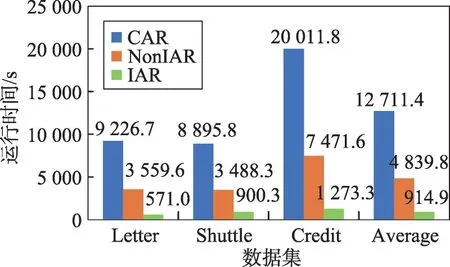
Fig.1 Execution time on low dimensional data圖1 低維數(shù)據(jù)上的運行時間圖
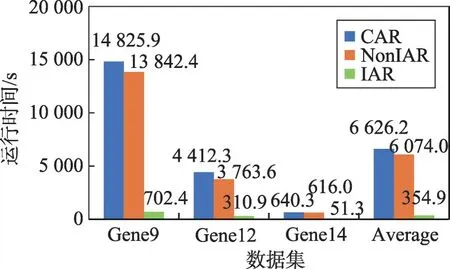
Fig.2 Execution time on high dimensional data圖2 高維數(shù)據(jù)上的運行時間圖
從圖1和圖2中可以觀察到NonIAR相比CAR已經(jīng)快了不少,但I(xiàn)AR更快。這說明IAR明顯加速了基于依賴度的約簡算法的速度。
進(jìn)一步分析圖2,發(fā)現(xiàn)在高維數(shù)據(jù)上IAR加速更加明顯,這表明IAR更適合高維數(shù)據(jù)的屬性約簡。
5.2 約簡效率對比分析
在本節(jié)中,將比較CAR、NonIAR和IAR的約簡效率。比較的結(jié)果呈現(xiàn)在表2與表3中。在表2與表3中,這三個算法的約簡率都是相似的。在低維數(shù)據(jù)上,例如在表2的數(shù)據(jù)集上平均約簡率依次為0.532/0.532/0.569;在高維數(shù)據(jù)上,例如在表3的數(shù)據(jù)集上平均約簡率依次為0.004/0.005/0.003。這說明這三個算法有著相近的降維能力,甚至在高維數(shù)據(jù)上,增量算法表現(xiàn)出的能力更強(qiáng)。

Table 2 Comparison of reduction rates on low dimensional data表2 低維數(shù)據(jù)上約簡率的比較
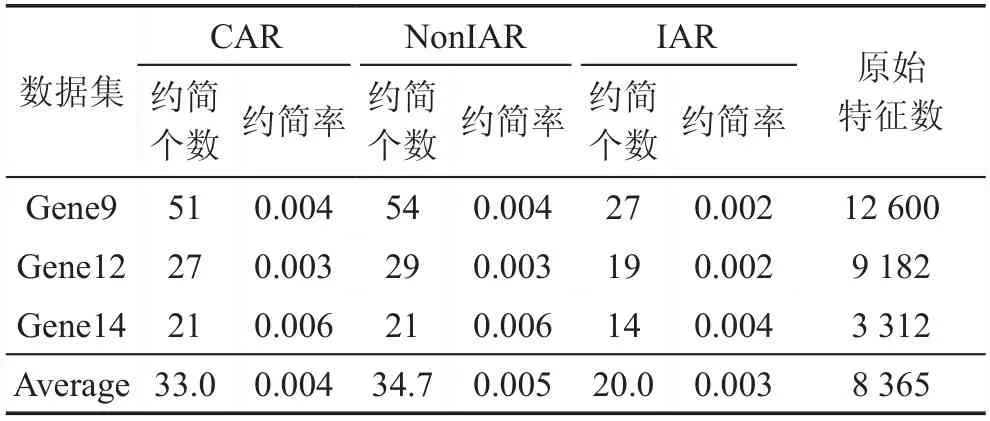
Table 3 Comparison of reduction rates on high dimensional data表3 高維數(shù)據(jù)上約簡率的比較
5.3 約簡分類能力對比分析
本節(jié)應(yīng)用KNN(K取3)分類算法來檢驗CAR、NonIAR和IAR的約簡分類能力[39],其中采取五折交叉驗證來確保分類結(jié)果的公平性與穩(wěn)定性。分類比較的結(jié)果在表4、表5中。
在表4和表5中,很容易看出來,這些算法有著相近的平均分類準(zhǔn)確度。比起全集屬性來說,差別并不是很大。
綜上所述,本文提出的增量約簡算法可以在節(jié)省時間的同時,獲得與非增量算法相近分類性能的約簡。
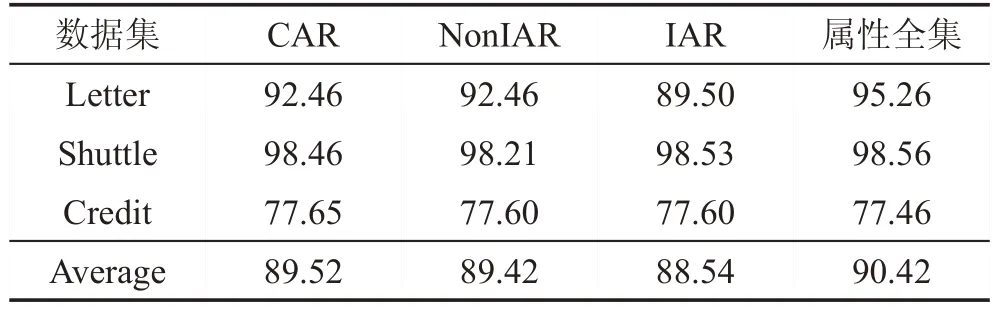
Table 4 Comparison of classification accuracy on low dimensional data表4 低維數(shù)據(jù)上分類準(zhǔn)確度的比較 %
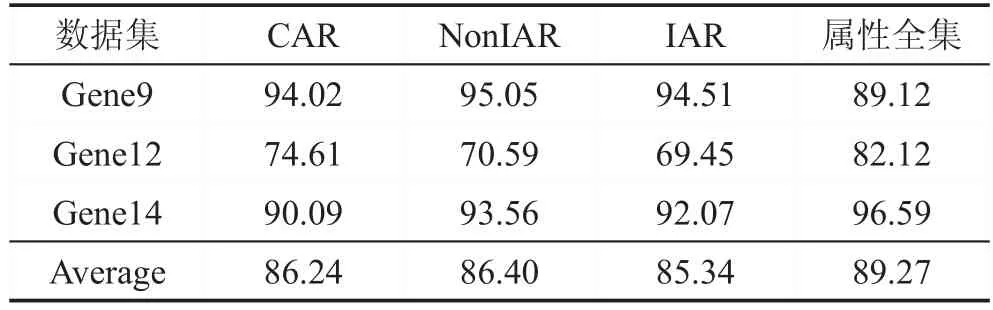
Table 5 Comparison of classification accuracy on high dimensional data表5 高維數(shù)據(jù)上分類準(zhǔn)確度的比較 %
6 結(jié)束語
本文提出了基于模糊粗糙集增量屬性約簡算法,本文主要有以下特點:
(1)提出了模糊粗糙集中的一些概念的增量機(jī)制,并且有著嚴(yán)格的理論推導(dǎo),這是設(shè)計增量屬性約簡算法的基礎(chǔ)。
(2)基于增量機(jī)制,提出了一個增量約簡算法。算法有效地利用已獲得學(xué)習(xí)結(jié)果,比如模糊正域與約簡,避免大量重復(fù)的計算。
(3)實驗結(jié)果驗證了提出的增量算法的高效性和有效性,特別是在高維數(shù)據(jù)集上增量算法表現(xiàn)更為高效。
