面向智慧中臺的多源數據集成技術研究
2020-02-03 02:39:04馬耀家曹揚陳駿曾藝坤陳珊珊
電子技術與軟件工程 2020年19期
馬耀家 曹揚 陳駿 曾藝坤 陳珊珊
(江蘇蘇星資產管理有限公司 江蘇省南京市 210000)
多源數據集成是指通過運用不同數據工具,將不同來源的數據源集成到所用平臺或系統內,成為所用平臺或系統能夠識別的數據形式[1]。由于數據在采集過程中具有明顯的差異,導致數據源形式不一,需對此類多源數據實施集成處理。當前與數據集成相關的體系架構主要包含數據復制及模式集成等。數據復制是通過復制不同數據源,對數據源整體的統一性實施維護實現多源數據集成;模式集成是通過轉化各個局部概念模式,實現多源數據集成。但上述方法未能有效解決數據集成的數據源添加與語義等問題。為此,本文運用SOA 構建多源數據集成技術架構,對不同數據源實施集成處理后用于智慧中臺內,實施相應的操作與管理等,提升操作與管理的時效性。
1 面向智慧中臺的多源數據集成技術
1.1 多源數據集成技術總體架構
運用SOA 體系結構構建包含數據源服務層與應用服務層的多源數據集成技術總體架構,其中數據源服務層主要針對智慧中臺的現實數據實施管理,智慧中臺的數據源主要為關系數據庫與半結構化數據源XML 文件等;應用服務層針對數據源服務層內各個數據源內源數據實施集成處理[2]。ESB 經服務注冊、調用及查詢等對應用服務層的不同服務實施集中管理,ESB 不但可實現動態管理服務,同時可經數據查詢優化模塊與數據訪問模塊等提升智慧中臺的性能與安全性。
1.2 語義模塊功能
智慧中臺運用了全局模糊本體,對通過消息服務模塊向語義模塊所傳遞的標準格式源數據實施更正。若用戶定義的擴展參數表與模糊本體創建均表明需實施語義查詢擴展,即對源數據實施對應的調整,同時基于語義擴展查詢,提升查全率與查準率[3]。以查詢源數據為依據,創建匹配規則,將本體映射文件生成,通過全局本體庫將查詢結果部分轉化為通用模式,可以有效解決智慧中臺的語義問題。
1.3 數據存儲
1.3.1 基于MC 算法的防御攻擊處理
將執行任務所得結果內不同歸檔文件的副本冗余數量設為r,當有攻擊發生時,運用RS 編碼(Reed-solomon codes,RS codes)冗余副本與冗余信息,不能恢復歸檔文件中不同RS 分組fi的概率上限可表示為:
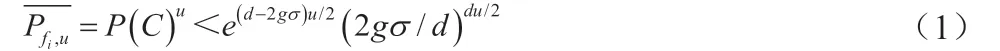
式中,RS 編碼碼距以d 表示;碼組長度與大規模數據塊數量分別以g 和n 表示;RS 分組事件以C 表示;數據塊損壞比例以σ表示。
將通過RS 冗余編碼擴展之后的不同RS 碼組內容設為 (F1,F2,K,Gg),將不同Fi元素視作單獨隨機變量。Fi可取為1 或0,當Fi為1 時,代表數據塊損壞;當Fi為0 時,代表數據塊完整,記為E(Fi)=σ。當存在隨機變量時,可得到:

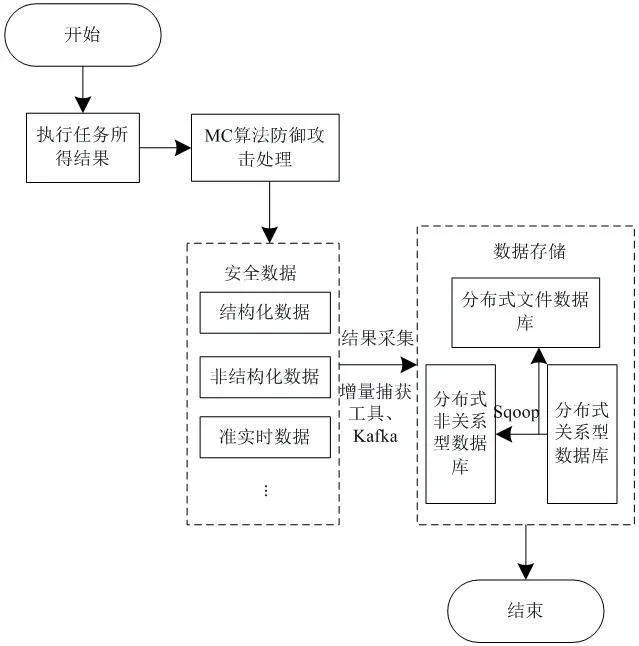
圖1:數據存儲過程圖
將不能恢復的第i 個具備錯誤的RS 分組事件通過Ci表示,已知分組內具備錯誤的數據塊比閾值高,則事件Ci的Chernoff 上界式為:
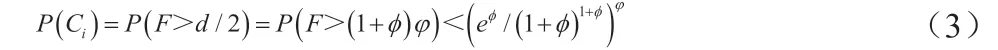

在歸檔內不同RS 編碼分組為相互獨立關系,當歸檔D 內存在n 塊數據塊時,在遭受到攻擊破壞時,無法恢復的概率式可表示為:

所獲得的數據恢復概率式可表示為:

綜上所述,當執行任務所得結果內待存儲源數據遭受攻擊行為時,MC 算法具備的數據糾錯能力較高,執行任務所得結果的副本冗余數據、大規模數據塊數量以及RS 編碼碼距均對MC 算法的糾錯性能具有決定性作用。
1.3.2 數據存儲過程
經MC 算法對執行任務所得結果內源數據實施防御攻擊處理后,運用增量捕獲工具、Sqoop 及Kafka 等數種技術方式,接入執行任務所得結果安全數據,依據統一數據規范標準化格式儲存不同類別數據庫[4]。數據存儲過程如圖1所示。
運用Hadoop 的并行加載機制,對線上與線下的消息實施統一處理,提升數據向Hadoop 集群內存儲的便利性[5];同時可將數據通道格式規范化,且準許智慧中臺各實施一次數據獲取與寫入,有效降低數據通道的操作用時與繁瑣性。

圖2:應用本文技術前后智慧中臺語義識別精度對比

圖3:應用本文技術前后智慧中臺各項操作用時對比
1.4 冗余數據處理
為提升已存儲執行任務所得結果內源數據的有效性,應將異常數據剔除掉。其中異常數據重點有重復數據、錯誤數據及不完整數據等,各種異常數據的清洗處理方式為:
(1)重復數據:導出重復數據的全部字段,選擇性地實施剔除;
(2)錯誤數據:針對與全角字符相似及數據前后存在不可見字符等問題,可采用SQL 語句書寫方式找尋出,并在業務系統更正后抽取出;
(3)不完整數據:過濾出此類不完整數據,分別依據缺失內容向各個文件寫入,需在設定時間之內全部補全,待補全之后即可向數據庫內寫入。
通過建立多源數據集成技術架構,采用MC 算法防御攻擊處理數據,獲得安全存儲數據,生成統一的XML 格式集成數據,由此完成多源數據集成。
2 應用結果分析
以江蘇蘇星資產管理有限公司的智慧中臺作為實驗對象,將本文技術應用于此智慧中臺內,檢驗本文技術的實際應用效果。
2.1 語義識別精度檢測
以人事調度信息、車輛管理信息、餐飲服務信息、工程維護信息以及會務接待信息為例,通過實驗公司智慧中臺實施語義識別,檢測應用本文技術前后智慧中臺的語義識別精度,檢測結果如圖2所示。
通過圖2 能夠看出,在對不同信息實施語義識別過程中,應用本文技術前智慧中臺的語義識別一致度值在54.5%~74.6%之間,而應用本文技術后智慧中臺的語義識別一致度值在74.5%~89.6%之間。由此說明,本文技術的語義識別一致度較高,可提升實驗公司智慧中臺的語義識別精度。
2.2 操作效率檢測
記錄應用本文技術前后的智慧中臺實施操作操作所用時間并對比,結果如圖3所示。
分析圖3 可得出,應用本文技術后智慧中臺實施五項操作的總用時為88.5ms,而應用本文技術前智慧中臺實施五項操作的總用時為124.8ms,應用本文技術后智慧中臺實施五項操作的總用時比應用本文技術前降低了29.09%。說明本文技術可提升實驗公司智慧中臺的操作效率,提高了實驗公司的服務響應時效性。
3 結論
本文通過構建集成技術整體架構,實現對數據源服務層內多源數據的集成處理,將本文技術應用于智慧中臺內,能夠有效提升語義識別精度,本文技術應用后更具時效性,并以此提升該公司的服務水平與服務效率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
小天使·一年級語數英綜合(2014年6期)2014-07-22 23:32:38
智慧與創想(2013年7期)2013-11-18 08:06:04
外語學刊(2011年1期)2011-01-22 03:38:33
