404 Not Found
404 Not Found
基于大數據的機動車環污檢測系統的研究與應用
李劍 曹文雅
(河北云聯網絡科技有限公司 河北省石家莊市 050000)
1 引言
隨著經濟社會發展和國家環保工作的縱深推進,機動車排氣污染排放占大氣污染物排放比重越來越大,導致空氣中各種污染物的數量和濃度呈逐年上升趨勢,嚴重危及人類的健康。雖然各市、省都在建立機動車污染大氣防止系統,但由于各類系統數據較為分散,無法形成統一的數據格式,并且隨著時間的推移,數據量呈現爆炸式增長,這也大大的為管理人員造成了數據準確性、及時性的困擾。本文從機動車環污檢測系統出發,在原有數據收集基礎上建立以Hadoop 為集群的大數據集群,在數據收集時進行數據處理,并直接將數據灌入大數據集群中,在短時間內將大量數據進行預計算,最終為領導層提供全省機動車現狀及污染物排放數據支撐。
2 相關工作
2.1 Hadoop平臺簡介
Hadoop 由HDFS、MapReduce、YARN、Common 四個模塊組成,HDFS:高吞吐量的分布式文件系統;MapReduce:分布式的離線并行計算框架;YARN:任務調度與資源管理;Common:為其它模塊提供基礎設施。如圖1所示。
2.2 Hadoop核心設計
Hadoop 核心設計如圖2所示。
2.2.1 HDFS
是Hadoop 中數據存儲管理的基礎,是一個高度容錯的系統,能檢測和應對硬件故障。它以流式訪問模式訪問應用程序的數據,這大大提高了整個系統的數據吞吐量,因而非常適合用于具有超大數據集的應用程序中。
HDFS 架構采用主從架構(master/slave)。一個典型的HDFS集群包含一個NameNode 節點和多個DataNode 節點。HDFS 通過NameNode、DataNode 和Client 來進行文件系統的管理,NameNode 是分布式文件系統中的管理者,主要負責文件系統中的命名空間、集群配置信息和存儲塊的復制等;DataNode 是文件存儲的基本單元,它將文件塊存儲在本地文件系統中,并且周期性地將所有存在的文件塊信息發送給NameNode;Client 是需要獲取分布式系統文件的應用程序。
MapReduce 是一個高性能的分布式計算框架,用于對海量數據進行并行分析和處理。與傳統的數據倉庫和分析技術相比,MapReduce 更適合處理結構化、半結構化和非結構化數據。MapReduce 任務運行在多個服務器上,指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。把一堆雜亂無章的數據按照某種特征歸納起來,然后處理并得到最后的結果。Map 面對的是雜亂無章的互不相關的數據,它解析每個數據,從中提取出數據的特征(Key 和Value)。經過MapReduce的Shuffle 階段之后,在Reduce 階段看到的都是已經歸納好的數據。
2.3 ETL工具Kettle簡介
Kettle 是一個組件化的集成系統,包括如下幾個主要部分:
(1)Spoon:圖形化界面工具(GUI 方式),Spoon 允許你通過圖形界面來設計Job 和Transformation,可以保存為文件或者保存在數據庫中。也可以直接在Spoon 圖形化界面中運行Job 和Transformation。
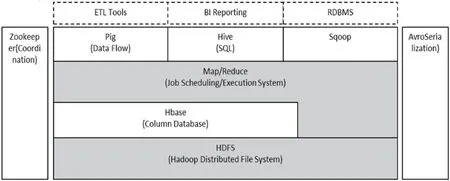
圖1
(2)Pan:Transformation 執行器(命令行方式),Pan 用于在終端執行Transformation,沒有圖形界面。
(3)Kitchen:Job 執行器(命令行方式),Kitchen 用于在終端執行Job,沒有圖形界面。
(4)Carte:嵌入式Web 服務,用于遠程執行Job 或Transformation,Kettle 通過Carte 建立集群。
(5)Encr:Kettle 用于字符串加密的命令行工具,如:對在Job 或Transformation 中定義的數據庫連接參數進行加密。
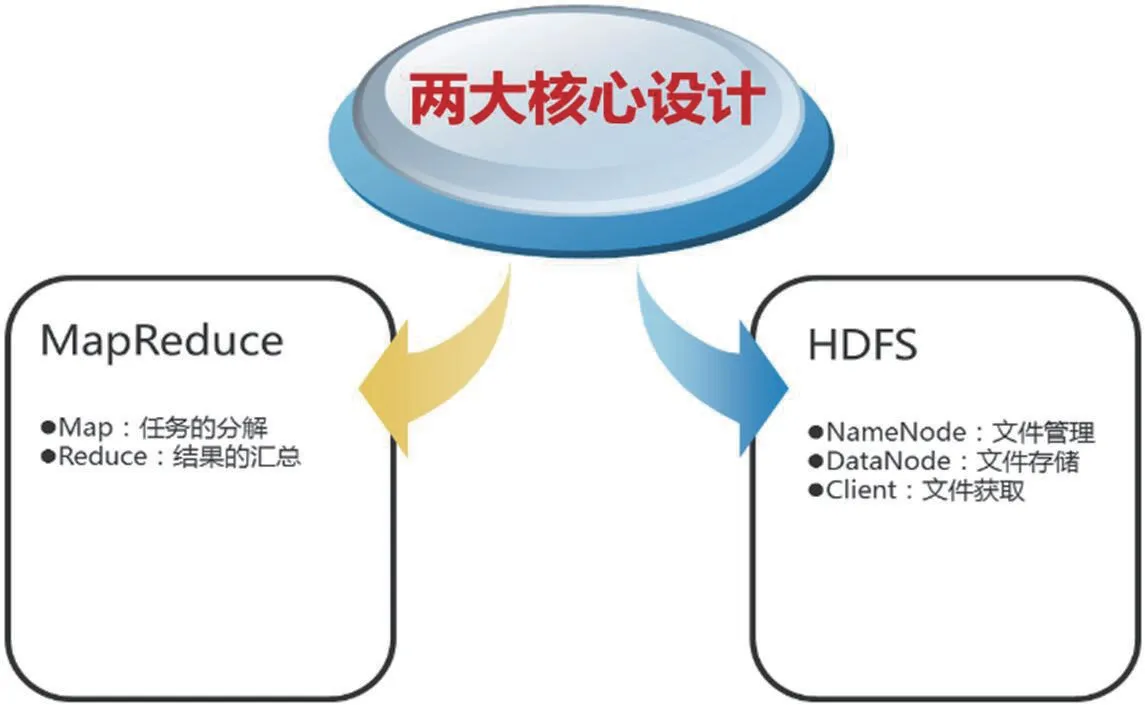
圖2
3 研究概況
此次研究數據來源主要包含:車輛定期檢驗數據、車輛遙感抓拍數據、車輛路檢路查數據、車輛黑煙車抓拍數據、車輛OBD 遠程在線監控車輛數據。此次研究采用以上五類數據進行數據融合,采用Hadoop 集群對數據進行ETL 數據清洗、轉換、歸類,形成統一的數據資源池,供系統進行數據調取及展示,通過一系列數據處理后,查看系統在保證數據一致性、完整性、實時性的基礎上進行數據調取時性能指標是否滿足日常需求,為領導層提供決策支撐。
心怡說:“我們的爺爺奶奶,外公外婆,他們是50后或60后,他們剩下的日子不是很多了,我的外公外婆身體也不好了,我很難受。”這時,教室里一片沉默。
4 詳細描述
此次研究涉及到的五類數據量級依次為:定期檢驗數據、遙感抓拍數據、路檢路查數據、黑煙車抓拍數據采取2018年-2019年兩年(4TB)的全省數據進行研究;OBD 遠程在線監控車輛數據采用2019年1-6月份(10TB)的數據進行研究。
此次研究搭建的系統采用Hadoop 分布式系統的基礎架構;采用Hbase 對數據進行分布式存儲;采用Hive 數據倉庫工具對數據進行提取、轉化、加載、查詢、分析等;采用sqoop 在Hive 與傳統數據庫之間進行數據傳遞,采用zookeeper 為整個分布式應用提供一致性服務,包含配置維護、分布式同步等。集群采用1 主節點5 從節點及1 主節點10 從節點的兩種方式進行。
依次將五類數據灌入到Hadoop 集群中,車輛信息以定期檢驗數據為準,建立基于一車一檔的車輛基本信息,將定期檢驗、遙感抓拍、路檢路查、黑煙車抓拍數據中的超標數據建立超標數據資源庫,按照汽油、柴油對車輛進行分類,柴油車中按照車輛總質量進行詳細分類,對于重型柴油車篩選出高排放車輛并建立高排放車輛資源池,進行重點監控。將OBD 遠程在線監控車輛進行車輛信息匹配,獲取各個車輛的排放階段以及上傳的實時數據,以國標為依據進行超標數據篩選,對OBD 遠程在線監控車輛進行ETL 數據提取、轉化、加載后存入至正式資源庫中,并對數據進行預計算,供數據匹配及查詢分析。將高排放車輛匹配OBD 遠程在線監控車輛,進行車輛運行軌跡數據篩選,并耦合至地圖中,根據排放因子對高排放車輛污染物計算,在地圖中標注出污染較為嚴重的主要國道、省道、高速、鄉道等。以黑煙車數據抓拍為基礎,匹配定期檢驗、遙感抓拍、路檢路查數據,進行匹配溯源,以車輛品牌、車輛型號、發動機型號等為粒度,進行數據分類展示。
在進行OBD 遠程在線監控車輛時,系統首次引用了污染管控及環境參數,在天氣晴朗及重污染天氣下,分別對某地區環境污染物濃度進行監測。同一環境參數下,過往車輛對于此地區的環境污染物濃度影響較大。
在系統滿足以上所有指標的基礎上,生成以上五類數據,數據總量為1TB,作為系統實時性性能指標測試的基礎,在以上14TB數據處理后,對系統進行查看,是否滿足目前應用與管理的要求,并對系統進行優化測試。將1TB 實時數據灌入集群中,查看集群負載及運行狀況,在系統中查看數據實時展示效果,是否滿足需求。
5 預期結果
5 節點集群對于上述15TB 數據處理上能基本滿足應用需要,但在實時性上無法保證是否滿足系統性能要求;10 節點集群則能完全滿足上述15TB 數據處理,并且在實時性上可以滿足系統性能要求,對于節點數量的不同,主要差別在于數據容量及數據處理能力上,經過大量實驗后,實驗表明在以上數據量級的基礎上,1 主節點10 從節點完全滿足管理部門日常需要并且在數據容量擴展上也基本滿足數據存儲要求,數據完整性、一致性、實時性上能做到快速處理并呈現的要求。
6 總結
通過Hadoop 集群對15TB 的數據進行處理及展示,發現系統在性能要求上,10 節點的集群相較于5 節點的集群,數據處理能力上有很大的提升,數據實時性上面,最大延遲在90 秒之內,符合目前應用與管理的要求。溯源的超標數據及高排放數據,經過應用系統及視頻監控系統確認后,均為可利用的超標數據,此類數據進行分類歸檔,為后續業務檢查及執法提供數據來源及執法依據。
在進行OBD 遠程在線監控車輛時,對某地區進行環境污染物濃度監測,發現在同一環境參數下,過往車輛對于地區的環境污染物濃度影響較大,系統在這一基礎上,即會采取重污染天氣應急污染管控措施,對重污染區域采用限行,工業企業減排等手段。對于發現高排放車輛連續使用排放超標的情況,可進行設置道路卡口的方式對此類車輛進行攔截,并指定維修點進行維修,為防治大氣污染提供有力的數據支撐。
