基于深度學習的錄音回放檢測
2020-02-02 03:37:32楊家輝朱镕潔
電子技術與軟件工程 2020年16期
楊家輝 朱镕潔
(寧波大學 浙江省寧波市 315211)
1 引言
聲紋識別是生物識別中的一種。相比于指紋識別和面部識別,語音的采集和識別成本更低,因而國內外已經有不少公司引入聲紋識別系統來提升客戶密碼認證的體驗感。聲紋識別的所面臨的安全性的挑戰之一則是說話人的錄音回放攻擊。但語音采集成本低同時也意味著盜取錄音的成本也不高。況且當下主流智能手機的聲音錄制和播放的質量不斷增強,其作為入侵設備的成本以及攻擊便捷性的優勢遠高于其他生物識別。
在對市場上有聲紋識別的常用手機應用程序的錄音回放攻擊測試中發現,微信的聲音鎖登錄功能中,在正常不吵鬧環境下用手機錄制使用聲音鎖成功登錄的說話人聲音,說話人的錄音回放可成功登錄微信。故對錄音回放檢測的研究十分必要。
2011年,王志鋒[1]等人對錄音回放數據和原始語音數據的信道噪聲的差異進行研究,對信道特征分析以識別是否為錄音回放。2016年,陳亞楠[2]等人提出基于低頻區信息分布的錄音回放檢測方法,實驗結果表明該方法對不同入侵設備都能很好的識別出錄音回放,是對錄音回放特征的有效提取。
2 錄音回放數據集的設計與構建
本次實驗的數據集是基于《AISHELL-ASR0009-OS1 開源普通話語料庫》(后文簡稱AISHELL-1),隨機抽取若干人聲進行錄音回放。AIshell-1 包含了400 名來自中國不同口音區域的參與錄制,整個錄音被放置在安靜的室內環境中。我們隨機選取了四百多個不同的中文短句音頻,不少于兩百五十種聲音,單個音頻時長為3-7秒。取其中111 個音頻錄制回放,并將原音頻刪除。將這些音頻隨機分成兩部分,其數量分布如表1所示。
回放設備使用的是華碩筆記本電腦,入侵設備使用的是華為智能手機,錄制空間為相對安靜的室內環境中,入侵設備與回放設備間隔一米。文件儲存標準均為48000HZ、16 位深度、雙聲道的wav文件。儲存文件夾如圖1所示。
3 梅爾頻率倒譜系數(MFCC)
聲紋識別之所以具有可行性,是因為人說話時的發聲器官在尺寸和形態上大有不同。只要獲得發聲器官工作時的信息,就可以準確描述出說話人獨有的音素特征。梅爾頻率倒譜系數就是可以準確描述聲音在短時功率譜的包絡特征。以下即是對梅爾頻率倒譜系數的提取過程。
提取MFCC 特征參數過程如圖2所示。
將語音信號以2048 的幀長、512 的幀移分幀得到s(n)。我們將每一幀加窗,使全局更加連續,避免出現吉布斯效應。每一幀聲音信號加窗后為:
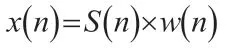
其中w(n)選取漢明窗:


表1:數據集音頻數量分布

表2:最優模型驗證結果
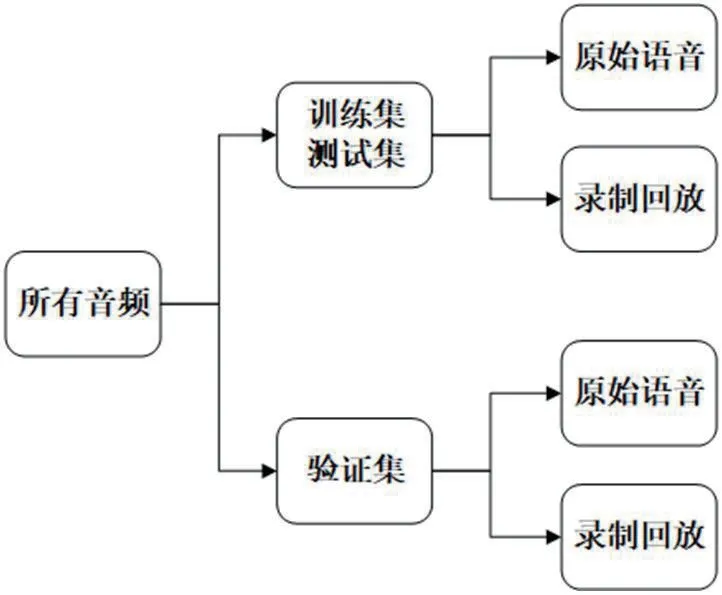
圖1:數據集文件存放分類
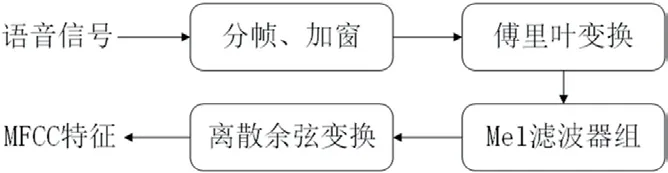
圖2:MFCC 特征參數提取過程
對x(n)進行傅里葉變換得到信號頻譜X(k):
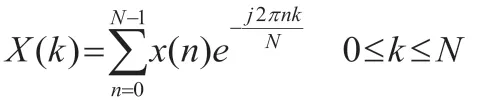
對信號頻譜取絕對值在平方以后得到能量譜,將能量譜通過Mel 濾波器組得到更接近人耳的梅爾頻率。
梅爾頻率可以反映人耳與聽到的聲音頻率之間的非線性關系。其與物理頻率的關系式為:
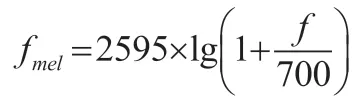
由于人耳對聲音響度的有“對數式”特性,故我們可以得到每個Mel 濾波器輸出的對數能量譜:
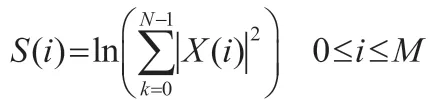
其中M 為通過的Mel 濾波器數量。
最后對對數能量譜作離散余弦變換即得到MFCC 特征參數C(n)。
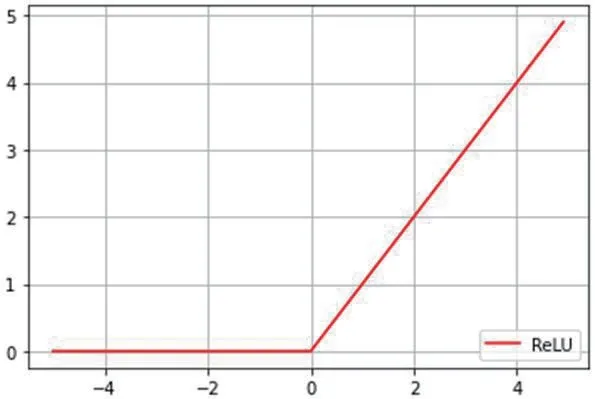
圖3:ReLU 函數

圖4:訓練集和測試集在100 次迭代中的準確率
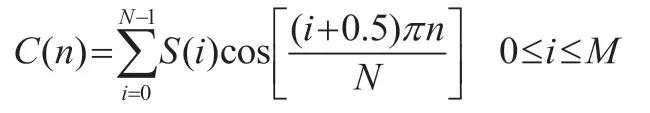
我們將所有的音頻轉換為MFCC 特征參數C(n),以C(n)作為輸入數據進參與深度學習運算。
4 BP神經網絡
BP 神經網絡是一種十分常用的深度學習模型,它可以擬合任何復雜非線性函數。BP 神經網絡包括輸入層、中間層和輸出層。本次實驗使用三層中間層,每層都以ReLU 函數作為激活函數。

ReLU 函數圖像如圖3。
ReLU 函數具有相當好的性質,任何函數都可以近似地采用ReLU 函數的組合表示。而且ReLU 會使一部分神經元的輸出為0,這樣就造成了網絡的稀疏性,減少了參數之間互相依存的關系,緩解了過擬合的發生。
在輸出層將神經元數量減少到2,并采用softmax 函數得到音頻分類的概率,即

softmax 函數十分適合用于分類模型的輸出層。其計算得到的函數值h(x,y)即為音頻是錄音回放的概率,1-h(x,y)則為音頻是原始錄音的概率。
損失函數選擇交叉熵損失。當預測是錄音回放的概率為h,標簽值為p,交叉熵損失即為:

預測概率越偏離標簽值,損失函數值越大,反之則越小。
當損失函數較大時,輸出層就將交叉熵損失反向傳播到中間層,并分攤給所有中間層的神經單元。中間層的神經單元通過調整自身權重和閾值以使得交叉熵損失沿梯度方向下降。經過反復學習,確定最小的交叉熵損失,并記錄下所有神經單元的權重和閾值。
5 仿真實驗極其結果分析
在BP 神經網絡中,將迭代次數設定為100 次。由于每次學習的其隨機的初值不同,因而每次得到的結果均有差異。故多次將模型初始化后重新學習,直到獲得較好的結果。
本次實驗采用誤識率和拒識率對模型進行評價,表2是實驗中運行結果最優的模型的結果。
表2表明,該模型能準確識別出所有的錄音回放,對原始語音的拒識率有2.33%。
但對于實驗仍有改進空間。首先是語音數據集不夠完善。錄音回放數據僅有111 條,錄音噪聲較為單一,即僅在一個入侵環境、一個入侵設備下獲得錄音回放數據。在樣本數據不充分的情況下錄音回放識別的魯棒性有待觀察。其次對于噪聲環境更復雜的回放錄音,需要更多的ReLU 激活函數的中間層去擬合。
由于采用了ReLU 激活函數,加快了收斂的速度,使模型在迭代20 次左右的時候就達到了過擬合狀態,如圖4訓練集和測試集在100 次迭代中的準確率。
6 結論
本次實驗的語音數據集還不夠充分和完善。一是數據量,沒有充分的訓練集和驗證集使得最后得到的實驗結果誤差較大;二是環境因素,在安靜的環境下獲得的說話人原始音頻和入侵音頻,沒有考慮到噪聲干擾和實際應用場景下的實現;三是入侵設備單一,基于單一的入侵設備獲得的數據集無法判斷本實驗采用的算法是對入侵設備源檢測,還是對聲音本質特征的有效提取。
以ReLU 為激勵函數的BP 神經網絡訓練得到的模型對錄音回放的檢測的準確率很高,同時對原始語音的拒識率僅2.33%。故在對不約束檢測文本內容的情況下,BP 神經網絡的學習效果顯著,對深入研究有一定參考價值。
雖然本次實驗有一定的局限性,但對于聲紋系統防錄音回放攻擊的角度上提出了較為簡單、計算量較少的實現的思路。且作為獨立的模型,可以較容易的疊加到聲紋識別系統中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
