基于語義分割的草場生長狀態分析
2020-02-02 03:37:16土登達杰普布旦增仁青諾布
電子技術與軟件工程 2020年16期
土登達杰 普布旦增 仁青諾布
(西藏大學信息科學技術學院 西藏自治區拉薩市 850000)
草地退化是當前草原生態系統面臨的主要問題;鼠蟲、農牧民過度放羊等問題對草原植被造成極大破壞,而且由于對地表的破壞往往造成大面積風蝕和水土流失。草原毛蟲以牧草莖葉為食,嚴重時牧草被采食殆盡。自然場景下的草地生長狀態目標小、背景干擾復雜等因素增加了草地區域檢測的難度。傳統的區域檢測算法不能準確的檢測出圖像中草地所在的具體位置,而且較多的超參會導致算法泛化能力差。
近年來,隨著深度學習技術[1][2][3]的快速發展,神經網絡在多個計算機視覺任務上展示出了驚艷的效果,學者們相繼使用神經網絡替換原始的一些圖像處理算法。卷積神經網絡(CNN)[4][5][6]在圖像處理領域得到了廣泛應用。圖像語義分割[7][8][9]是一個基礎研究問題,學者們相繼提出了多種性能優異的語義分割算法。同時學者門提出了FCN[10]、U-Net[11]、Deeplabv1[12]、Deeplabv2[13]、Deeplabv3[14]、Deeplabv3+[15]、PSPNet[16]、ICNet[17]、HRNet[18]、Fast-SCNN[19]等算法,這些成果對語義分割、多尺度分割操作、語義分割算法的魯棒性和運行效率、快速且高質量分割等問題的解決帶來很好效果。
本文主要工作是獲取圖像中草地所占區域的大小。傳統的圖像處理算法并不能很好的解決這個問題,受到卷積神經網絡的啟發,本文嘗試使用語義分割算法來解決,首先使用標注好的數據訓練一個語義分割模型,同時在訓練過程中對HRNet 網絡的架構和損失函數進行了改進;使用訓練好的模型在新的測試圖片上進行推理,從而獲得圖像中草地所在的具體像素點;最后對圖像中的像素點進行統計并計算出草地所占面積和整個圖像面積的比值,當這個比值大于設定的閾值時,則認為這塊草地的生長狀態比較良好,否則認為這片草地的生長狀態比較差,應該對其加以保護。
1 基于語義分割的草地生長狀態分析方法
基于語義分割的草地分割算法具有精度高、泛化性能好、抗干擾能力強等優點,用戶僅僅需要提供少量帶有標簽的圖像就可以獲得一個草地分割模型,它不僅可以獲得很高的分割精度,而且可以很好地應用到其它類似場景中。通過語義分割算法我們可以準確獲取到圖像中屬于草地的每一個像素點,從而完成更加精準的統計和計算。綜上所述,與傳統算法相比,基于語義分割的草坪區域獲取方法具有更多優點,能夠更好滿足待測試場景的需求。
1.1 模型結構簡介
本文實現的語義分割算法的基本網絡架構如表1所示。整個網絡包含4 個階段,每一個階段包含一些重復的子模塊,重復的次數分別為1、1、4、3 次。在階段1 中,子模塊包含1 個分支;在階段2 中,子模塊包含2 個分支;在階段3 中,子模塊包含3 個分支;在階段4 中,子模塊包含4 個分支。每一個分支對應于一個不同的分辨率,它由4 個殘差單元和一個多分辨率融合單元塊構成。表中‘[]’表示相應的殘差單元,其中第二個數字表示這個殘差單元的重復次數,最后一個數字表示整個模塊的重復次數,C 表示通道個數。本文使用的殘差塊與ResNet 網絡中的殘差塊相同,它不僅可以在一定程度上抑制網絡發生梯度消失,而且可以協助網絡獲得更魯棒的特征表示。除此之外,為了保持特征映射的分辨率不變,本文采用了類似HRNet 網絡的思路,在網絡搭建過程中,從高分辨率到低分辨率的過程中并行連接多個子網路,從而保證了網絡在加深的同時,特征映射的大小保持不變。為了使網絡獲取到更加魯棒的特征表示,能夠獲取更加豐富的語義和細節信息,在搭建網絡的過程中不斷交換不同分辨率的設備。由于本文關注的分割對象是草地,而很多現實場景中拍攝的圖片中,草地比較雜亂,呈現不均勻分布,而且會遇到大量的干擾物,為了更好地捕獲到草地的細節信息,本文改變了階段1 和階段2 的網絡架構,網絡的運行速度并沒有受到影響,但是網絡層之間的變換更加多樣,實驗結果表明這種改變可以更好地獲取到草地的一些紋理信息,可以在一定程度上改善語義分割算法的效果。
1.2 模型訓練
通常訓練語義分割模型的數據包含每個圖像中的標注多邊形及其所屬的類別信息。由于標注質量會極大影響模型的最終效果,因而本文使用labelme 對圖像進行了嚴格的標注,并將這些標簽轉換為不同的顏色映射,方便后續的可視化。本文所實現的語義分割模型在訓練過程中包含很多超參,這些超參會對模型的精度產生較大的影響。表1展示了一些關鍵參數。
語義分割任務,可以被看作一個像素點分類問題,語義分割網絡的輸入是一個512×512×3 的彩色圖像,網絡通過一個特定大小的特征映射將其映射到特定的特征空間,最后再通過一個函數將其映射為一個概率值。我們通常使用softmax 損失函數來完成輸出到概率值的映射,具體計算公式如式(1)所示。其中y 表示相應的標簽,p 表示網絡的預測輸出,s 表示softmax loss。

表1:語義分割網絡架構

大量實驗結果表明,雖然softmax 可以完成模型訓練的任務,但是在有些情況下使用該損失函數并不能獲得好的訓練結果。為了獲得較高的精度,本文實現了多種損失函數,具體包括Weighted softmax loss、Dice loss、Lovasz hinge loss 等。Weighted softmax loss按照不同類別設置不同的權重,可以在一定情況下抑制類別不均衡的問題,本文動態設置不同類別的權重,即根據每個batch 中各個類別的數目動態調整類別權重。
針對草地分割問題,我們需要分割的類別包括草地和背景兩類,而在大多數圖片中都會出現類別分布不均勻的問題,即背景所占的區域一般遠大于草地所占的區域。本文使用Dice loss 和Lovasz hinge loss 來解決這個問題。Dice loss 的定義如式(2)所示,其中Y 表示相應的標簽,P 表示模型預測結果,||表示矩陣元素之和,|S|表示Y 和P 的共有元素數,d 表示Dice loss。

Lovasz loss 是基于子模損失的凸Lovasz 函數,該損失函數可以針對網絡的mean IoU 損失進行優化。該損失函數的表達形式如式(3)所示:

通過大量實驗,本文最終選擇使用Lovasz hinge loss 和Dice loss 作為最終的損失函數,這兩個函數分別包含一個超參
1.3 區域統計與狀態分析
通過上面的方法我們可以獲取到圖像中草地所在的具體位置,在獲取到圖像中草地所屬的像素之后,我們可以快速統計出圖像中屬于草地的像素點個數。具體計算公式如式(4)所示,其中n 表示圖像中草地像素點的個數,img(i,j)表示圖像中第i 行第j 列位置上的像素點,grassn表示最終的統計結果。

圖1:數據樣本

獲取到圖像中草地所占據的像素點后,我們就可以獲取到草地在整個圖像中所占據的比例值,再將計算獲得的比例值和設置的閾值比較,如果該比例值大于該閾值,則表明這塊草地的生長狀態良好;如果該比例值小于該閾值,則表明這塊草地的生長狀態較差,應該對其加以保護。具體計算方法如式(5)所示,其中area(img)表示img 圖片的面積,即整個圖像總共包含多少個像素點,0.8 表示設置的閾值,good 表示當前草地的生長狀態良好,不需要進行人為干預;bad 表示當前草地的生長狀態較差,需要進行適當的人為保護。

2 實驗分析
2.1 數據來源
本實驗所使用的訓練數據均來自項目組在拉薩、山南等地拍攝的真實圖片。如圖1所示,真實場景獲取到的圖像中的草地顏色雜亂、分布不均勻、周圍會有很多干擾信息:圖1(a)中的草地周圍有一些干擾的干草和石塊,草地的形狀各式各樣;圖1(b)中的草地比較稀疏,不同草地之間沒有連接,草的顏色各不相同;圖1(c)中的草地包含大量的雜草和一些間隙和干擾物。通過上面的觀察,我們可以發現輸入數據具有較大挑戰,對語義分割算法提出了很高的性能要求。為了提升算法的魯棒性,我們在互聯網中找了部分草地圖片,具體效果如圖1(d)所示,這些圖片中的草地比較干凈,僅存在一些其它的干擾,可以進一步提升語義分割算法的泛化能力。我們把真實拍照和網上獲取一起組成的106 張圖片構成了數據集,84張作為訓練集實驗數據、12 張作為驗證集、12 張作為測試集。整個數據集采用Labelme 標注工具進行標注,并采用腳本將該數據集調整為Pascal VOC 數據集的格式。整個數據集中包含各種不同時間段、不同地方和不同角度拍攝的草地圖片,圖像中包含大量干擾信息,如干草、石塊、垃圾、大理石等。
整個實驗過程均在一臺配有一塊R7-4800H 顯卡、一顆GTX2060 處理器、內存大小為16G 的Ubuntu 服務器上進行,使用百度開源的PaddlePaddle 深度學習訓練框架完成網絡的訓練和網絡的推理。

表2:不同語義分割算法客觀指標展示

表3:不同損失函數效果展示

圖2:算法效果展示
2.2 性能分析指標
為了對本文實現的針對草地的語義分割算法進行性能評估,實驗中使用了多種常用性能分析指標,具體包括MPA、MIoU 和Kappa。MPA,即所謂的平均像素精度,它是對像素精度指標的一種提升,用來計算每一個類內被正確分類的像素數的比例,最后將所有類的平均值作為最終結果,具體計算公式如式(6)所示。MIoU 即平均交并比,它是在IoU 的基礎上提出的一種評價指標,計算兩個集合的交集和并集之比,即計算算法預測結果和標簽之間的比值,首先計算出每一個類的IoU,然后對所有類的結果進行平均即可,具體計算公式如式(7)所示。Kappa 系數是一個用于一致性校驗的指標,該系數的計算是基于混淆矩陣的,取值范圍為[-1,1],該值越大表示語義分割的效果越好,具體計算公式如式(8)所示。
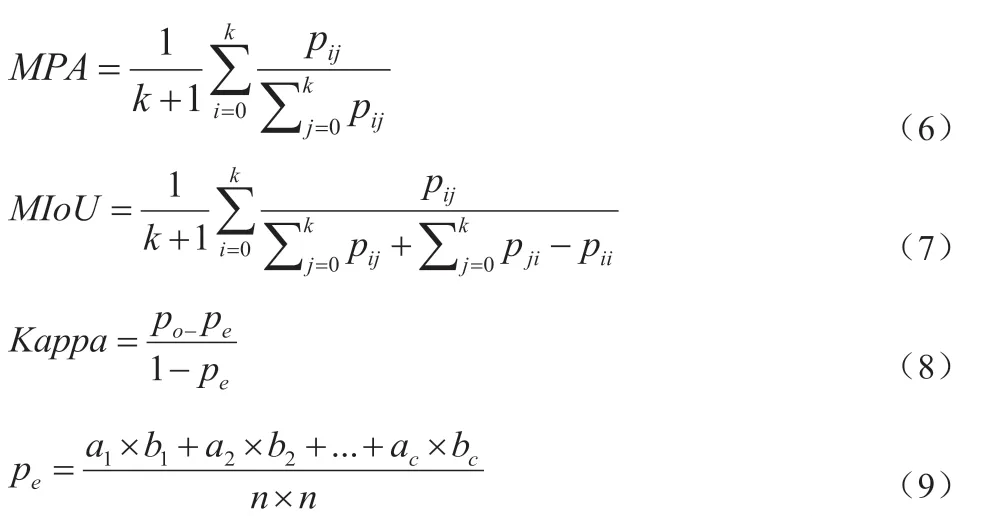
其中k 表示k 個類別,1 表示背景類,pij表示本來是i 類被預測為j 類的像素數量;pji表示本來是j 類被預測為i 類的像素數量;pii表示本來i 類被預測為i 類的像素數量。po表示每一類正確分類的樣本數量之和除以總樣本數,pe的計算公式如式2-4 所示。a1,a2,a3表示每一類的標簽樣本個數,b1,b2,b3表示每一類的預測樣本個數,n 表示總體樣本個數。
2.3 實驗結果分析
本文實現的語義分割算法進行性能評估,經過大量實驗,具體包括該語義分割算法和其它性能優異的語義分割算法的性能比較、不同損失函數的分割效果。具體評估方法包括主觀指標評價和客觀指標評價,我們不僅將不同語義分割算法在同樣的測試圖片上面的效果進行展示和分析,而且計算出不同模型的MPA、MIoU 和Kappa 數值。
表2展示了語義分割算法使用不同語義分割模型在測試圖片上的效果,所有分割算法均采用相同的超參,batch_size=4,epoch=30。表中紅色、綠色和藍色結果分別表示第一名、第二名和第三名。通過觀察我們可以發現,與其它state-of-the-art 算法相比,本文實現的語義分割算法能夠在草地數據集上獲得最好的分割結果,在MPA、MIoU 和Kappa 等多項指標中均獲得了最佳的效果。
表3展示了語義分割算法使用不同損失函數訓練之后的效果,在訓練過程中除了更換不同的損失函數之外,所有的模型均保持相同的超參,batch_size=4,epoch=30。表中紅色、綠色和藍色結果分別表示第一名、第二名和第三名。通過觀察我們可以發現,使用Weighted lovase 損失函數可以有效提升分割算法的精度,在MAP、MIoU 和Kappa 等指標中都取得了最好的結果。
圖2是實現的草地語圖像義分割算法和其它5 個語義分割算法在測試圖片上的測試效果。通過觀察我們可以發現,本文實現的草地圖像語義分割算法可以在同樣的訓練參數下獲得更高的分割精度,更魯棒的分割性能。該算法分割出的結果更加接近真實標簽文件,含有更少量的空洞區域,能夠更好地區分一些干擾目標,達到了本文預期的要求。
3 結語
為了對高原地區草地生長狀態進行評估,針對傳統圖像處理算法存在的精度低、魯棒性差、抗干擾能力弱等缺點,本文嘗試使用語義分割算法來解決整個草地圖像分割問題和草地生長狀態評估問題。首先使用一個改進網絡架構和損失函數的語義分割算法獲得草地圖像分割結果;然后在該結果基礎上對草地區域進行統計并計算草地的面積比;最后通過閾值比較確定這塊草地當前的生長狀態。該方法具有精度高、泛化能力強、抗干擾能力好等優點,可以廣泛應用到草地生長狀態分析的相關任務中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
