分布式JS解析在Web信息采集系統中的應用
2020-02-01 08:57:30梁元
電子技術與軟件工程 2020年10期
梁元
(中國航發貴州黎陽航空動力有限公司 貴州省貴陽市 550014)
隨著互聯網信息技術的飛速發展,網絡影響力已經逐漸滲透在我國的各個領域,而Web 技術更是以其具備的方便直觀、豐富表達等特點,逐漸作為Internet 最重要信息發布傳輸的關鍵方式。隨著Web 信息的不斷膨脹,不僅給人們帶來了豐富的資源,同時也使得人們在應用過程中面臨巨大挑戰[1]。所以Web 信息采集正充分發揮其自身作用,運用于站點數據分析、安全檢測、Web 圖進化、獲取個性信息或挖掘用戶興趣等服務中。在傳統HTML 網頁內可以通過標簽嵌入式向用戶靜態化呈現頁面內容,但是這種傳統的網頁視覺效果,已無法順應目前用戶對于網頁信息的顯示所需,需要及時彌補發生動態化網頁語言的技術弊端。在網頁動態語言領域研究的逐漸深入,JavaScript 腳本語言已經逐漸被廣泛運用于網頁開發技術領域。本文提出Web 信息采集系統應用分布式JS 解析技術的特點,實現動態網頁信息采集系統,可以與分布式計算技術相結合,實現更加高效、快速、直觀的運行。
1 JS解析技術概述
1.1 JS腳本語言
JS 技術是基于LiveScript 語言基礎之上優化提出的,為了解決當時服務器端程序運行中的速率緩慢,頻繁服務器交互時間過久問題,將JS 加入瀏覽器中能夠向訪問頁面用戶展示最終的瀏覽器運行結果[2]。經過展開對JS 技術語言的學習研究,在JS 語腳本語言主要包括以下核心優勢特點:
(1)基于對象,能夠結合需要來動態化創建、改變對象屬性;
(2)事件驅動,能夠實現JS 函數綁定特定瀏覽器操作;
(3)實時性,基于瀏覽器客戶端執行JS 腳本程序;
(4)動態性,JS 技術對客戶端諸多事件類型加以界定,實現比較豐富的網頁功能交互;
(5)跨平臺,該技術可以不受平臺局限;
(6)安全性,能夠有效預防客戶端用戶信息泄露丟失。總體正由于JS 語言具有以上特性,所以可以突破傳統信息采集系統的技術弊端,應用Web 信息采集系統中。
1.2 JS腳本解析引擎
在JS 腳本執行中對于JS 解析引擎十分依賴,也正是實現瀏覽器內置引擎,才能夠執行JS 解析。如今多數瀏覽器在實現JS 腳本解析都擁有專門解析引擎,目前比較常用的幾類包括如下:
(1)SpiderMonkey,作為C 語言完成編寫能夠編譯、分析、執行JS 腳本的嵌入式引擎;
(2)Chrome V8 作為如今比較流行的瀏覽器之一,高效JS 解析引擎作為網頁打開速度方面出色技術;
(3)Rhino 作為一種能夠在Java 運行環境中執行JS 腳本程序。
2 Hadoop分布式計算
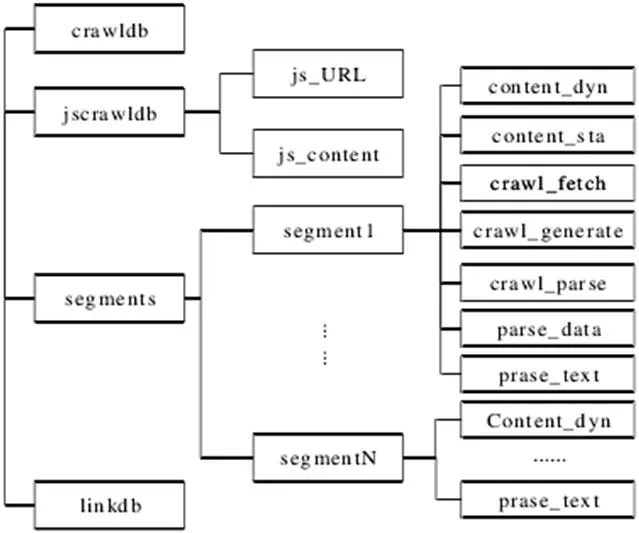
圖1:數據文件存儲結構
分布式計算屬于云計算一類在應用中較其他計算方法,能夠實現更低的各計算機通信程度,能夠實現系統長期穩定運行,且可以結合實際問題情況,綜合考量計算機集群異構特點加以確定。劃分問題為小塊每一臺計算機都可以處理自己所負責的數據。并且結合了分布式存儲技術、分布式非結構數據庫、半結構數據庫及任務調度、集群計算等優勢[3]。本文通過建立Hadoop 分布式計算框架,能夠結合JS 解析技術,從而在應用于Web 信息采集系統獲得更加高效穩定的技術效果。
3 動態頁面腳本提取解析及任務調度
3.1 Web信息采集系統架構
Web 信息系統通過基于Hadoop 分布式架構平臺,成功建立涵蓋基礎平臺模塊、信息采集功能模塊,以及信息服務以上三大模塊。通過這三大子系統功能模塊,能夠實現爬取網頁信息、提取解析腳本、并抽取信息。基于Hadoop 該平臺還能夠提供Web 信息采集技術支撐,實現數據采集,能夠提供信息服務模塊的所需數據。經過Nutch 爬蟲系統,完成對網頁原始信息文件的爬取后,腳本提取解析轉化原本腳本包含在內的網頁信息原文件,從而實現向靜態網頁文件的成功轉化,并完成有關動態網頁的抽取轉化形成數據存儲結構,在信息服務模塊中運用實現系統交互,經過分析處理結構化數據,可以提供用戶所需信息服務[4]。
3.2 腳本提取解析
提取Web 網頁腳本的工作流程如下:
(1)進行DOM 解析,運用HTML 文檔解析工具能夠實現不同Filter 的針對性提供,從而成功提取HTML 文檔內的DOM 元素,保證了DOM 元素的文檔提取便捷性,形成嵌入式HTML 文檔內容,并執行腳本文檔重構原DOM 樹。
(2)提取JS 腳本。解析HTML 腳本文檔后,便可以結合JS文檔腳本的DOM 元素方式,對HTML 文檔是否含有腳本程序進行判斷。如果包含則會跳轉JS 腳本至解析環境中,如果不包含就會跳轉至保存文件。
(3)構建腳本環境,完成JS 腳本抽取后自然需要構建解析環境執行腳本,運用Rhino 引擎來實現。
(4)運行腳本重構DOM 樹。
(5)保存文件,在完成DOM 樹重構后,轉化HTML 文檔即可實現動態頁面轉化為靜態頁面,并在HTFS 中儲存HTML 文檔,從而提供給網頁信息抽取子系統應用。
3.3 調度算法
Hadoop 集群能夠實現單個或多個作業同時處理,并存放于統一隊列內,劃分作業為多個Map、Reduce 任務。Hadoop 調度器能夠實現分配這些任務至集群節點內,有效完成作業,且滿足不同作業任務需求,對于任務調度的整體難度很大程度增加。在執行Hadoop 算法調度策略中,MapReduce 編程模型能夠達到良好容錯性,在其中工作點的任務執行整體進度較其他任務節點更慢時,則存在軟硬件配置差異、故障、調度不當等原因。而Hadoop 可以以任務進度值來實現落后任務確定,確定相應的任務進度值。任務處理落后則會對響應時間有所延長,一旦發生落后任務,那么Hadoop 自然就會對該落后任務重新完成節點分配,該機制即推測執行,能夠推測執行機制,成功對落后任務產生的執行效率影響有效減少。在調度算法采用的評價指標中,主要以作業任務的響應時間、平均作業響應時間、并行拓展及公平性為主。
3.4 腳本提取解析調度算法設計
假設第i 個選中節點,該節點的可使用網絡集、空閑節點集分別用Vi、Ei表示,考慮到對于調度算法效率產生的因素影響,主要表現在Vi節點的信息處理能力,需要完成數據信息處理的Split 大小、自身與所需處理數據二者之間的存儲間隔距離。調度算法的階段選擇公式如下:
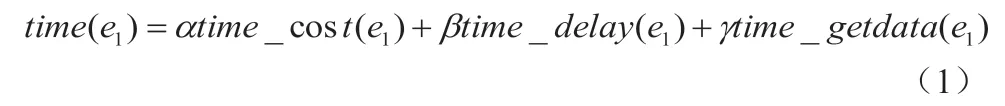
結合以上建立腳本提取解析調度算法,能夠成功構建異構集群環境,確定Hadoop 調度算法的慢任務,并且根據具體的推測執行,提出相應的改進優化策略。
4 腳本提取解析系統
4.1 系統整體架構
結合以上分析建立Web 網頁爬取Nutch 子系統,作為整個信息采集系統的關鍵起始端,腳本提取解析系統需要銜接,形成均為HDFS 的數據文件系統,建立數據文件系統結構(見圖1)。基于Nutch 文件存儲結構基礎實現,在Crawl 文件夾中又包括了Crawldb、linkdb、segments 子文件夾。在三個文件夾中最后一個文件夾,想要成功抓取網頁數據文件,只能需要通過content 文件夾進行存儲。在設計該系統中需要完成動態化網頁信息抓取,并轉化為靜態網頁,所以進一步拆分content 文件夾為兩個,分別為content_dyn 動態頁面、content_sta 文件夾靜態頁面。
根據圖1 建立的數據文件存儲結構框架中,分別包括了以下三個子系統實現,各系統實現功能如下:
首先頁面爬取子系統中,能夠成功爬取相關頁面信息,并實時更新URL 信息,在完成首層數據爬取時,對于1 鏈接深度URL 對應頁面,能夠完成URL 信息從種子文件中進行爬取。
其次在腳本提取解析系統中,能夠爬取content_dyn 動態頁面相關信息,實現JS 自動腳本提取解析,最終成功生成靜態頁面存儲于content_sta 文件夾中。
最后在頁面信息抽取系統中,針對最終生成存儲的content_sta文件夾,進行文件內容腳本解析,經過實現元數據、頁面外部鏈接、內部文檔的分別解析后,在URL 數據庫中更新封裝,以信息抽取規則為依據最終抽取相應信息至最終的關系數據庫內。
4.2 數據文件格式
在Web 信息采集系統中實現JS 提取解析存儲的數據文件,主要包括了三種:
(1)原始網頁庫,作為原本Web 網頁所爬取的鏈接對應原始網頁信息文件,涵蓋了網頁URL、源URL、網頁的內容以及具體的爬取時間;
(2)JS 文件庫,作為完成原始數據成功爬取后,以外部鏈接侵入式JS 腳本信息數據庫文件,涵蓋了網頁URL、網頁的內容以及具體的爬取時間;
(3)靜態網頁庫,作為處理存儲網頁動態信息腳本提取解析后,獲得的靜態化網頁信息文件,涵蓋了網頁URL、源URL、網頁的內容、編碼方式和生成時間。
5 結語
通過本文研究探討在Web 信息采集系統中,運用分布式JS 解析技術實現了信息采集系統設計,并提出了整個信息采集系統的設計整體說明,包括了頁面爬取子系統、腳本提取解析系統、頁面信息抽取系統。通過JS 解析結合Hadoop 分布式計算,提取解析系統的實際運行所處異構集群環境,并在原本Nutch 系統文件的存儲結構基礎之上,設計整體系統文件數據結構及存儲格式,分別為原始網頁庫、JS 文件庫、靜態網頁庫三種,并實現文件結構數據文件格式和該系統的不同模塊信息采集功能細節。發現設計的該分布式JS解析應用于Web 信息采集系統思路,能夠動態化、高效且準確的實現Web 信息采集,為該領域提出出信息采集技術新思路。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
工業設計(2022年8期)2022-09-09 07:43:20
保健醫苑(2022年1期)2022-08-30 08:39:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
