基于PSENet和CRNN的身份證識別
2020-02-01 15:23:26趙龍李飛王偉峰
現(xiàn)代計算機 2020年34期
趙龍,李飛,王偉峰
(安徽科大國創(chuàng)云網(wǎng)科技有限公司,合肥230088)
0 引言
隨著互聯(lián)網(wǎng)以及智能手機的飛速發(fā)展,無論是企業(yè)還是個人對文字識別的要求越來越多、越來越高。本文主要講述文字識別技術在身份證識別方面的應用。身份證文字識別在更行各業(yè)有著廣泛的應用:對于各類App,特別是通信和金融服務類的App基本都需要實名認證才能進行交易的以實現(xiàn)更過通過無紙化辦理業(yè)務的企業(yè)信息化,實名認證有的是通過人臉認證,也有很多是通過身份證識別來實名認證。同時,現(xiàn)在越來越多的車站、海關、酒店、公安部門等也需要對身份證信息進行采集和登記來實名認證。通過OCR(Optical Character Recognition)識別技術,可以極大地提高實名認證的效率,使得用戶有更好的體驗。
身份證OCR文字識別主要是對身份證上的姓名、性別、地址、身份證號碼和有效期等信息進行識別,將識別的結果轉成文本的格式。首先,就文字檢測方法而言,總體分為基于圖像分割的方法和基于回歸的方法。基于回歸的方法主要是Faster R-CNN、SSD模型等。這種基于回歸方法的文本檢測方法不但性能不好、訓練過程較長,而且對于拍攝效果不佳的歪曲形狀的文本不能很好地處理。PSENet屬于基于圖像分割的方法,其能夠檢測任意形狀的文字。尤其對于身份證這種文字位置歪曲的文本,PSENet能夠達到很好的效果。
1 基于PSENet的身份證文字檢測方法
本文采用PSENet文字檢測算法,結合文字識別技術CRNN進行身份證圖片文字識別。本文首先對從CRM系統(tǒng)中提取的身份證圖片進行旋轉、去水印等預處理,去除輸入圖片的噪音干擾,然后將處理后的結果傳入PSENet中進行文字檢測,接著用CRNN進行文字識別,最后對識別的結果進行后處理,最終得到身份證文字識別的結果。
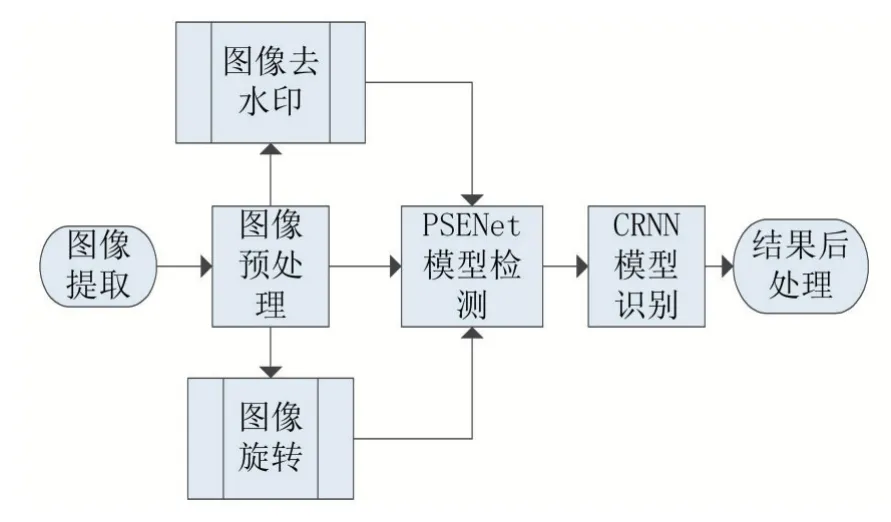
圖1
1.1 身份證圖像預處理
(1)身份證圖像旋轉
由于身份證圖片傾斜會影響檢測的效果,所以首先要對身份證圖片進行旋轉矯正其至水平角度,經(jīng)過水平矯正后的身份證圖片識別效果更好。本文是利用人臉識別庫dlib庫[13]進行矯正:首先是找到身份證圖片上的人臉,然后找到人的眼睛的特征點,由于兩只眼睛在一條水平線上的身份證圖片一定是水平的,所以只需要計算兩只眼睛的傾斜的角度,然后根據(jù)眼睛傾斜的角度來確定旋轉的角度。
(2)身份證圖片水印去除
在身份證圖片的主對角線上打了“僅供****使用”的字樣,這八個字符遮擋了身份證中的部分信息,對后續(xù)模型識別造成干擾,所以本文首先對原始身份證圖片進行去水印操作。本文采用SIFT(尺度不變特征檢測器)算法[14]和FLANN算法[15-16]對身份證圖片進行去水印。SIFT算法具有良好的光照穩(wěn)定性,同時,其還具有視角、旋轉、尺度、仿射的特性。首先要構造要去除的水印的模板,然后通過CV2.SIFT()方法得到身份證圖片的特征信息點和水印模板的特征信息點,根據(jù)里面特征信息點找出身份證和身份證模板的位置。最后,根據(jù)其位置可將水印去除。
1.2 身份證圖像檢測
對于身份證文字檢測,本實驗采用文字檢測算法PSENet[1]進行檢測。PSENet是在2018年Shape Robust Text Detection with Progressive Scale Expansion Network中提出的一種圖片文字檢測算法,PSENet在各項文字識別比賽中都得了不錯的成績,其主要是用來解決其他文字檢測算法存在的文字檢測不準確、文字檢測遺漏、文字間距離較近無法分開識別、彎曲類本文無法識別和文字距離較近識別錯誤的問題。PSENet是一種漸進式網(wǎng)絡,其能有效對不同“稠密”程度的問題進行準確分割,把每一塊文本分成不同大小的區(qū)域,然后對這些小的區(qū)域進行檢測,這種漸進式的網(wǎng)絡能有效地解決這種問題,而且這種基于網(wǎng)絡分割的算法對于任意角度拍攝的身份證圖片都能準確定位,同時,對于相鄰文本實例也能較好的識別。
PSENet文字檢測的流程分為特征提取、特征融合、像素分類和文字后處理得到檢測結果,如下圖(圖片來源于PSENet)詳細實現(xiàn)流程如圖2。

圖2 PSENet實現(xiàn)流程
(1)首先,用ResNet提取4層特征P2,P3,P4,P5進行提取,得到4層特征圖;
(2)將得到的特征圖進行融合,得到特征圖F,通過下面方式進行融合:

融合公式中,“||”是concatenation連接操作,分別采用2倍、4倍、8倍的方式進行上采樣;
(3)將上一步得到的特征圖作為3×3的卷積的輸入,得到256個通道數(shù)的特征圖,再以此特征圖為1×1的卷積層中,得到Sn,Sn-1,…,S1,總共n個圖像分割的輸出結果;
(4)通過PSENet后處理算法得到文字檢測的結果。
本文采用liuheng92在GitHub上開源的tensor?flow_PSENet項目[3],該項目基于PSENet算法[1]進行訓練,并且采用PSENet提供的參數(shù)作為訓練參數(shù),訓練數(shù)據(jù)采用ICDAR 2015數(shù)據(jù)集[7]和ICDAR 2017數(shù)據(jù)集[7]。
如圖3-圖6是PSENet對身份證圖片檢測的結果(身份證圖片已進行過打碼脫敏處理),PSENet對于身份證要素信息基本都能檢測到,第一張圖片里面的姓名、性別、民族、住址、出生、公民身份證號碼都得到準確的檢測。
1.3 基于CRNN的身份證文字識別方法
本文首先嘗試通過Tesseract[2,9]進行文字識別,由于Tesseract是基于模板的文字識別算法,其對于身份證文字識別錯誤率較高,特別是對于身份證號碼這類的數(shù)字識別效果不甚理想。CRNN[4]不僅能夠解決身份證地址不定長識別問題,還能結合CNN和RNN分別進行特征提取和字符序列的推理任務。對于其他算法而言,CRNN有著明顯的優(yōu)點:CNN在輸入網(wǎng)絡之前需要進行序列PADDLE,而CRNN不需要,它能夠對不同長度的待識別序列進行識別。同時,由于CRNN參數(shù)不多,所以通過CRNN訓練來的模型體積很小,這樣,訓練好的模型部署在普通的CPU機器上即可得到很高的性能效果:模型對于身份證的識別效率得到很大的提高。CRNN在很多場景中的識別都得到了不錯的效果,所以本文采用CRNN對PSENet檢測到的文字進行識別。

圖3

圖4

圖5

圖6
CRNN算法是華中科技大學白翔老師在2015年在An End-to-End Trainable Neural Network for Imagebased Sequence Recognition and Its Application to Scene Text Recognition[6]提出的一種基于CNN、CTC、BiLSTM方法組合在一起的文字識別算法,其對于特定場景的文字識別效果較好。本文以身份證圖片文字識別為場景,通過CRNN訓練識別模型對身份證上的姓名、性別、民族、出生日期、住址和身份證號碼要素進行識別。
為了驗證CRNN的效果,本文結合使用YOLOv3+CRNN[11]、CTPN+CRNN[12]、CTPN+DenseNet+CTC[12]組 合方法進行對比。
CRNN識別身份證圖片文字分為以下3步:檢測文字特征提取、序列預測識別、輸出結果矯正處理。
(1)特征提取
為了加快訓練過程中模型網(wǎng)絡的收斂性,首先,將圖片統(tǒng)一歸一化到[230,50]大小。通過CNN網(wǎng)絡進行特征提取。圖片歸一化代碼如下:
import numpy as np
image =(image- np.min(image))/(np.max(image)- np.min(image))
(2)序列預測識別
由于身份證地址是不定長的序列,CRNN利用雙向LSTM很好地解決了這個問題。
(3)輸出結果矯正處理
對于識別的結果,通過一定的規(guī)則整合成結構化的形式。對于身份證中文信息(人名、性別、地址、民族)中具有同樣讀音但識別錯誤的問題,通過以下方式進行處理:
①首先通過構造正確文字(百家姓、中國各個省份地址等)和常見錯誤文字的字典映射,然后結合Python的pypinyin工具包[8]組成三元組對返回的結果進行更正,如圖7中的“男”字被識別成“果”字,圖8中的出生日期“1988年12越3日”被識別成“1988年12月38日”,這種日期的異常可通過設定的規(guī)則進行排查,圖9識別完全正確(由于身份證信息涉及到個人隱私,所以各個圖中的身份證是偽身份證號碼,不作為實際實驗中的真實數(shù)據(jù))。
②對于身份證是否識別正確,通過身份證號碼各個部分和省份、各個市縣的對應關系的組成的詞典進行判斷糾正。
③對于識別出來的文字中存在歧義的問題的文字,本實驗通過Word2Vec基于5000張身份證圖片的標注結果訓練的詞向量,通過這個詞向量來發(fā)現(xiàn)歧義字符或者單詞的近似替代。
(4)生成識別結果
如圖7-圖10是生成的結果。

圖7

圖8

圖9
2 實驗結果及分析
本實驗從CRM系統(tǒng)中抽取了5000張身份證圖片對模型進行驗證,計算出準確率、召回率和F值。為了驗證檢測方法的優(yōu)越性,以YOLOv3+CRNN、CPTN+Tesseract、Tesseract單獨檢測組合作為對比組,實驗結果表明,PSENet和CRNN的組合對文字識別的效果更佳:PSENET+CRNN對文字識別的算法在準確率、召回率、F值方面相對于其他的算法及組合都更勝一籌。

表1
3 結語
本文主要以身份證要素識別為場景,用PSENet和CRNN結合的方式進行文字識別。在識別之前對身份證圖片通過SIFT和FLANN算法進行去水印、通過dlib人臉庫對身份證圖片角度進行矯正等數(shù)據(jù)預處理操作。對于本文實驗后續(xù)的優(yōu)化方向,主要從以下幾個方面進行優(yōu)化。
(1)在CRNN的后續(xù)識別過程中加入attention機制,即網(wǎng)絡中通過GRU+CNN的方式,對GRU的輸出做Attention;
(2)增加對身份證圖像的預處理步驟,如身份證圖片腐蝕、灰度二值化、膨脹等預處理,優(yōu)化訓練和測試圖片。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
