大數(shù)據(jù)分析與計(jì)算系統(tǒng)設(shè)計(jì)
2020-01-16 10:50:00張啟濤張洪瀚李俊玲
經(jīng)濟(jì)技術(shù)協(xié)作信息 2020年2期
◎張啟濤 張洪瀚 李俊玲
一、系統(tǒng)概述
大數(shù)據(jù)分析系統(tǒng),通過數(shù)據(jù)收集采集功能,將生產(chǎn)業(yè)務(wù)數(shù)據(jù)進(jìn)行收集和清洗。按照資源前置庫以及交易數(shù)據(jù)資源庫進(jìn)行數(shù)據(jù)收集和清洗。數(shù)據(jù)通過數(shù)據(jù)交換平臺實(shí)現(xiàn)從各平臺到中心前置庫。
交易信息資源庫主要包括交易平臺運(yùn)行過程中涉及到的各類數(shù)據(jù)信息,如交易信息庫、主體信息庫、專家信息庫、信用信息庫、監(jiān)管信息庫等。
數(shù)據(jù)采集、數(shù)據(jù)分類后實(shí)現(xiàn)統(tǒng)計(jì)分析、交易動(dòng)態(tài)分析、專題分析和智能分析。
各業(yè)務(wù)應(yīng)用系統(tǒng)提供基礎(chǔ)的數(shù)據(jù)源,通過ETL過程實(shí)現(xiàn)數(shù)據(jù)源的抽取、轉(zhuǎn)換、加載等進(jìn)入ODS數(shù)據(jù)庫中,基于ODS數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)一步的進(jìn)行ETL,數(shù)據(jù)進(jìn)行數(shù)據(jù)倉庫中進(jìn)行數(shù)據(jù)的加工,實(shí)現(xiàn)數(shù)據(jù)集市、主題模型的建立等處理,最后以應(yīng)用的形式進(jìn)行對外的展示,如圖1所示。
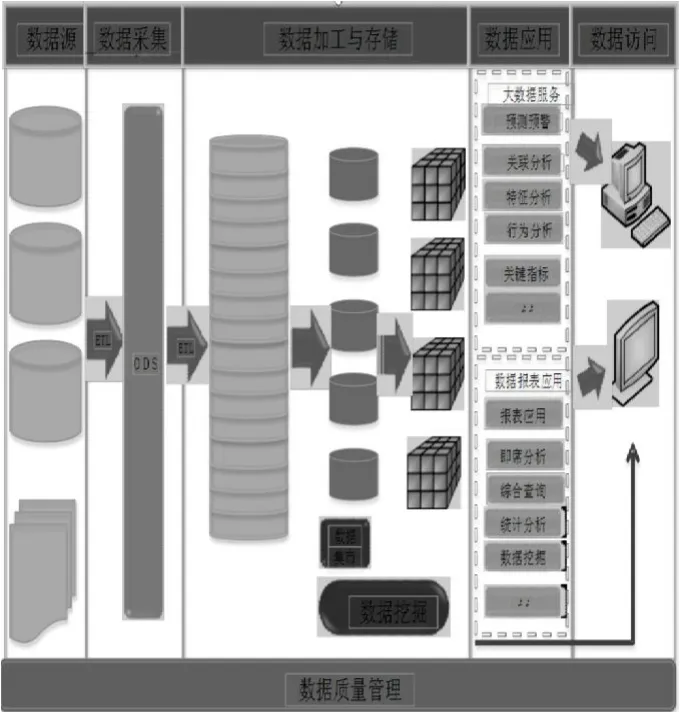
圖1 系統(tǒng)設(shè)計(jì)圖
二、結(jié)構(gòu)設(shè)計(jì)
大數(shù)據(jù)分析子系統(tǒng)將數(shù)字化招采平臺、其他業(yè)務(wù)系統(tǒng)、外部系統(tǒng)等進(jìn)行統(tǒng)一的數(shù)據(jù)采集,建立共享資源目錄,并提供統(tǒng)一的數(shù)據(jù)共享能力,使數(shù)據(jù)得到有效利用。再針對不同類型數(shù)據(jù)采用靈活的存儲技術(shù),搭建端到端數(shù)據(jù)治理體系,實(shí)現(xiàn)數(shù)據(jù)的全流程管控,按交易信息庫、主體信息庫、專家信息庫、信用信息庫、監(jiān)管信息庫等不同的主題整合數(shù)據(jù)采購數(shù)據(jù)倉庫,支撐上層應(yīng)用。結(jié)合業(yè)務(wù)需求,利用大數(shù)據(jù)技術(shù)對業(yè)務(wù)數(shù)據(jù)監(jiān)控預(yù)警、建模和專題分析,為采購決策提供精準(zhǔn)且有效的支撐,如圖2所示。
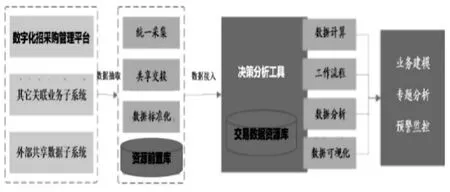
圖2 總體結(jié)構(gòu)設(shè)計(jì)圖
三、數(shù)據(jù)資源處理
1.數(shù)據(jù)處理。數(shù)據(jù)處理過程主要負(fù)責(zé)將數(shù)據(jù)采集后的數(shù)據(jù)抽取到數(shù)據(jù)源,然后對數(shù)據(jù)源進(jìn)行清洗轉(zhuǎn)換,同時(shí)對歷史數(shù)據(jù)進(jìn)行沉淀,形成基礎(chǔ)數(shù)據(jù)層,再對基礎(chǔ)數(shù)據(jù)層的數(shù)據(jù)進(jìn)行匯總計(jì)算得到數(shù)據(jù)模型層和數(shù)據(jù)指標(biāo)層的數(shù)據(jù),總體流程通過統(tǒng)一流程調(diào)度模塊進(jìn)行調(diào)度和銜接,如圖3所示。
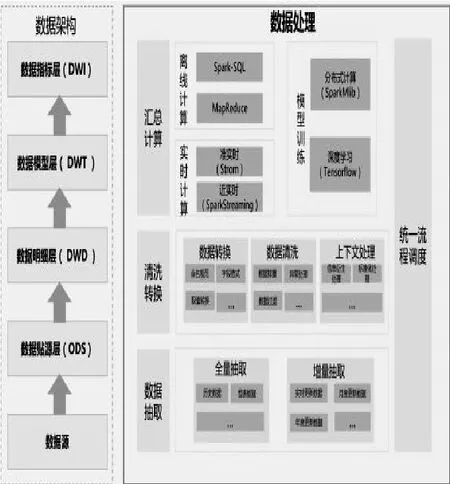
圖3 數(shù)據(jù)處理示意圖
2.清洗轉(zhuǎn)換。數(shù)據(jù)清洗轉(zhuǎn)換是對不符合標(biāo)準(zhǔn)規(guī)則的數(shù)據(jù)進(jìn)行格式、取值、類型等方面的過濾或轉(zhuǎn)換。例如對企業(yè)數(shù)據(jù)中的各個(gè)行業(yè)的單位進(jìn)行統(tǒng)一轉(zhuǎn)換,對從不同口徑接入的企業(yè)數(shù)據(jù)中的名稱進(jìn)行清洗和統(tǒng)一,對爬蟲數(shù)據(jù)進(jìn)行過濾和去除重復(fù)。
數(shù)據(jù)清洗轉(zhuǎn)換包括三部分:上下文信息處理、數(shù)據(jù)轉(zhuǎn)換和數(shù)據(jù)清洗。
上下文信息處理:在數(shù)據(jù)源中存在大量的上下文信息,生產(chǎn)系統(tǒng)只有這類信息的原始信息,將原始信息內(nèi)含的豐富的分析信息內(nèi)容通過信息衍生處理和標(biāo)準(zhǔn)化處理,形成形成基礎(chǔ)數(shù)據(jù)層的數(shù)據(jù)。
數(shù)據(jù)轉(zhuǎn)換:通過對數(shù)據(jù)進(jìn)行字段命名規(guī)范化、時(shí)間字段的統(tǒng)一和特殊字段的格式或取值轉(zhuǎn)換等操作,形成基礎(chǔ)數(shù)據(jù)層的數(shù)據(jù)。在通過對源數(shù)據(jù)信息的梳理,異常數(shù)據(jù)情況的識別,建立從源數(shù)據(jù)到目標(biāo)數(shù)據(jù)的映射規(guī)則,做一定的計(jì)算、合并和拆分等轉(zhuǎn)換操作。
數(shù)據(jù)清洗:通過對數(shù)據(jù)進(jìn)行排重,異常字段處理和無效數(shù)據(jù)過濾等操作,形成基礎(chǔ)數(shù)據(jù)層的數(shù)據(jù),使基礎(chǔ)數(shù)據(jù)層的數(shù)據(jù)更精確更有意義的過程。數(shù)據(jù)清洗是數(shù)據(jù)整合中的一個(gè)重要環(huán)節(jié),數(shù)據(jù)清洗直接影響了數(shù)據(jù)裝載到數(shù)據(jù)庫中的清潔度與準(zhǔn)確度,關(guān)系到前端數(shù)據(jù)統(tǒng)計(jì)分析的可靠性及可信賴程度,如圖4所示。
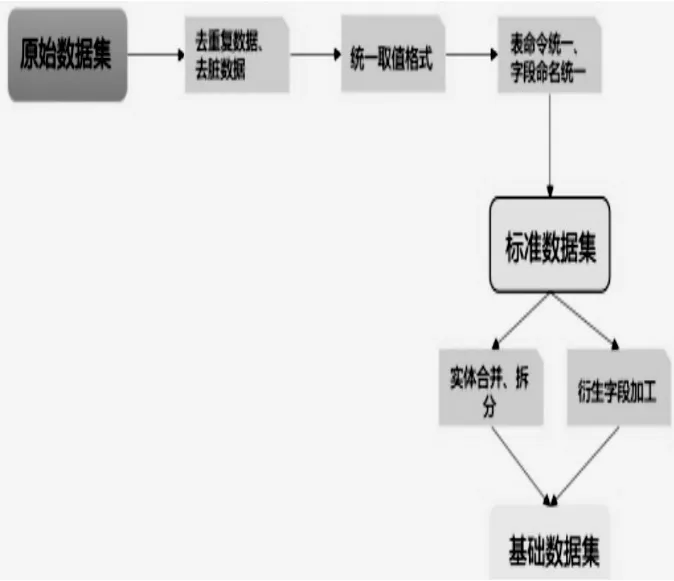
圖4 數(shù)據(jù)清洗示意圖
去重復(fù)數(shù)據(jù)、去臟數(shù)據(jù):去掉原始數(shù)據(jù)集里的重復(fù)數(shù)據(jù)以及臟數(shù)據(jù)。例如某條記錄里,如果年齡字段的值小于零,則該條記錄就是臟數(shù)據(jù),需要予以剔除。
統(tǒng)一取值格式:統(tǒng)一字段的取值格式。例如當(dāng)字段為時(shí)間類型時(shí),那么統(tǒng)一格式為YYYY-MM-DDhi24:mi:ss;如果字段是數(shù)值型,如收入數(shù)據(jù),則統(tǒng)一保留六位小數(shù)。
表命名統(tǒng)一、字段命名統(tǒng)一:統(tǒng)一表的命名方式,表字段的命名方式。比如收入字段,原始數(shù)據(jù)集里可能命名為income、fee、charge等等,可統(tǒng)一為其中一種命名方法。
實(shí)體合并、拆分:實(shí)體合并,是將不同系統(tǒng)里相同的實(shí)體進(jìn)行合并,形成統(tǒng)一的數(shù)據(jù)實(shí)體;實(shí)體拆分,是將同一個(gè)實(shí)體里,代表不同的業(yè)務(wù)或者范圍的內(nèi)容拆分成多個(gè)實(shí)體,比如,將操作流水表的內(nèi)容進(jìn)行拆分。
衍生字段加工:將用途范圍廣、使用頻繁、基礎(chǔ)性強(qiáng)的指標(biāo),加工到基礎(chǔ)數(shù)據(jù)集里,從而提高數(shù)據(jù)的使用效率以及同一數(shù)據(jù)口徑。
數(shù)據(jù)清洗轉(zhuǎn)換通過配置進(jìn)行管理,生成對應(yīng)清洗、轉(zhuǎn)換規(guī)則關(guān)系映射表,系統(tǒng)通過調(diào)用、匹配該關(guān)系映射表,實(shí)現(xiàn)對原數(shù)據(jù)的自動(dòng)清洗和自動(dòng)轉(zhuǎn)換,生成標(biāo)準(zhǔn)數(shù)據(jù)集,從而完成數(shù)據(jù)清洗轉(zhuǎn)換整體流程操作。
3.數(shù)據(jù)抽取。統(tǒng)一流程調(diào)度模塊依據(jù)觸發(fā)規(guī)則觸發(fā)數(shù)據(jù)從數(shù)據(jù)裝載層進(jìn)行抽取。數(shù)據(jù)抽取過程是針對數(shù)據(jù)裝載層中不同的數(shù)據(jù)源進(jìn)行全量或增量的抽取的過程。全量抽取是針對歷史數(shù)據(jù),維表數(shù)據(jù)等需要一次性獲取全量的數(shù)據(jù)的抽取方法;增量抽取是針對源系統(tǒng)每天產(chǎn)生的增量數(shù)據(jù)進(jìn)行抽取,增量抽取以源系統(tǒng)記錄的發(fā)生時(shí)間做為增量的標(biāo)志,每次抽取之前首先判斷記錄最大的時(shí)間,然后根據(jù)這個(gè)時(shí)間取大于這個(gè)時(shí)間所有的記錄。例如對采購信息相關(guān)數(shù)據(jù)等按照實(shí)時(shí)更新或按照月度更新的數(shù)據(jù)需要采用定時(shí)增量抽取的方式進(jìn)行抽取。
四、數(shù)據(jù)計(jì)算
數(shù)據(jù)計(jì)算就是依據(jù)不同的數(shù)據(jù)模型,根據(jù)數(shù)據(jù)實(shí)效性要求和不同的計(jì)算復(fù)雜度采用不同的計(jì)算工具和方法對數(shù)據(jù)進(jìn)行計(jì)算,最終得到主題模型所需的數(shù)據(jù)。根據(jù)主題模型可分為離線計(jì)算、實(shí)時(shí)計(jì)算、模型計(jì)算,如圖5所示。
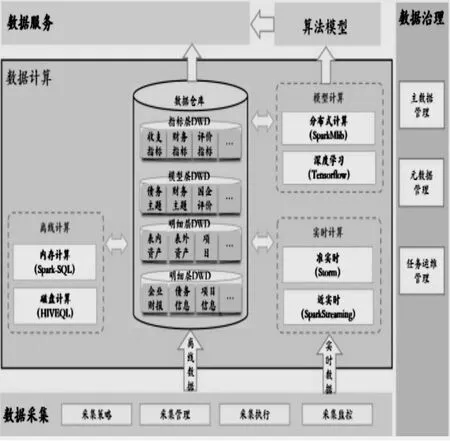
圖5 數(shù)據(jù)計(jì)算示意圖
1.離線計(jì)算。離線計(jì)算:主要是針對數(shù)據(jù)量較大,但實(shí)時(shí)性要求不高的數(shù)據(jù),智慧采購系統(tǒng)中月度、季度、年度等數(shù)據(jù)需大量數(shù)據(jù)匯聚運(yùn)算及信用評價(jià)等模型需要迭代式運(yùn)算,可通過封裝HQL/SparkSql語句,基于MapReduce/Spark分布式計(jì)算框架進(jìn)行數(shù)據(jù)模型計(jì)算,通過azkaban任務(wù)調(diào)度工具對計(jì)算任務(wù)進(jìn)行編排和統(tǒng)一調(diào)度管理,實(shí)現(xiàn)多種類型和數(shù)據(jù)體量較大的數(shù)據(jù)的批量運(yùn)算。
2.實(shí)時(shí)計(jì)算。對于準(zhǔn)實(shí)時(shí)應(yīng)用,可采用開源Storm流式技術(shù)框架來實(shí)現(xiàn)。Strom可以方便的在一個(gè)計(jì)算機(jī)集群中編寫與擴(kuò)展復(fù)雜的實(shí)時(shí)計(jì)算,每秒可以處理數(shù)以萬記的消息。基于其本身的技術(shù)特點(diǎn)和業(yè)務(wù)場景實(shí)效性要求,可以用來處理互聯(lián)網(wǎng)爬蟲數(shù)據(jù),實(shí)時(shí)的計(jì)算處理爬蟲獲取的即時(shí)數(shù)據(jù),不會(huì)出現(xiàn)大量數(shù)據(jù)積攢的延遲,保證整個(gè)系統(tǒng)向提供用戶極好的應(yīng)用體驗(yàn)。
3.模型計(jì)算。針對數(shù)據(jù)模型計(jì)算,可利用基于Tensorflow和SparkMlib等成熟的計(jì)算框架進(jìn)行實(shí)現(xiàn)。其中SparkMlib已實(shí)現(xiàn)部分?jǐn)?shù)據(jù)挖掘算法,已解決分布式計(jì)算問題。
總結(jié):在實(shí)際應(yīng)用場景中針對趨勢預(yù)測,分類等需求,首先用歷史數(shù)據(jù)進(jìn)行模型訓(xùn)練和校準(zhǔn),訓(xùn)練好的模型存入模型庫,在新的批次數(shù)據(jù)到來時(shí),統(tǒng)一流程調(diào)度模塊逐一調(diào)用模型庫中的模型,對新的數(shù)據(jù)進(jìn)行計(jì)算。從數(shù)據(jù)建模系統(tǒng)中提取對應(yīng)的模型代碼,應(yīng)用于模型計(jì)算。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
