基于“神威太湖之光”的Caffe分布式擴展研究
2020-01-14 06:03:26朱傳家方佳瑞
計算機應用與軟件 2020年1期
關鍵詞:進程
朱傳家 劉 鑫* 方佳瑞
1(江南計算技術研究所 江蘇 無錫 214083)2(清華大學計算機科學與技術系 北京 100084)
0 引 言
隨著機器學習技術的快速發展,深度學習已經在圖像識別、語音識別、自然語言處理等領域進行了成功的應用[1]。隨著訓練數據規模成倍的增長和深度學習模型越來越復雜,訓練這些網絡非常耗時,訓練時間通常幾天甚至數周,如何提高訓練效率成為研究的熱點。分布式擴展技術是一種有效的方法。分布式擴展方式分類的方式有多種,按網絡通信的內容是參數還是數據劃分可以分為數據并行和模型并行;按網絡通信的時序劃分可以分為同步方式和異步方式。常用的分布式擴展方式有參數服務器分布式擴展方式和去中心化的分布式擴展方式兩種。為了更好地使用深度學習方法,工業界推出了多款開源的深度學習框架,影響比較廣泛的有伯克利大學推出的Caffe[2]、Google開發的Tensorflow[3]、微軟開發的CNTK[4]、Torch[5]等框架。其中,Caffe完全由C++編寫,具有代碼結構清晰、模塊化好、運算效率高、可移植性好的特點。
本文基于國產超級計算平臺“神威太湖之光”對開源深度學習框架Caffe進行了分布式擴展研究,對比了同步方式下參數服務器分布式擴展方式和去中心化分布式擴展方式在大規模并行時的性能。本文雖基于國產超算平臺,但對大規模分布式擴展有借鑒意義。
1 背景介紹
1.1 “神威太湖之光”簡介
“神威太湖之光”是世界上首臺峰值運算速度超過十億億次量級的超級計算機,也是中國第一臺全部采用自主技術構建的世界第一的超級計算機[6]。“神威太湖之光”計算機系統采用基于高密度彈性超節點和高流量復合網絡的高效能體系結構,由高速計算系統、輔助計算系統、高速計算互聯網絡、輔助計算互聯網絡、高速計算存儲系統、輔助計算存儲系統和相應的軟件系統等組成。系統總體架構如圖1所示。

圖1 “神威太湖之光”系統架構圖
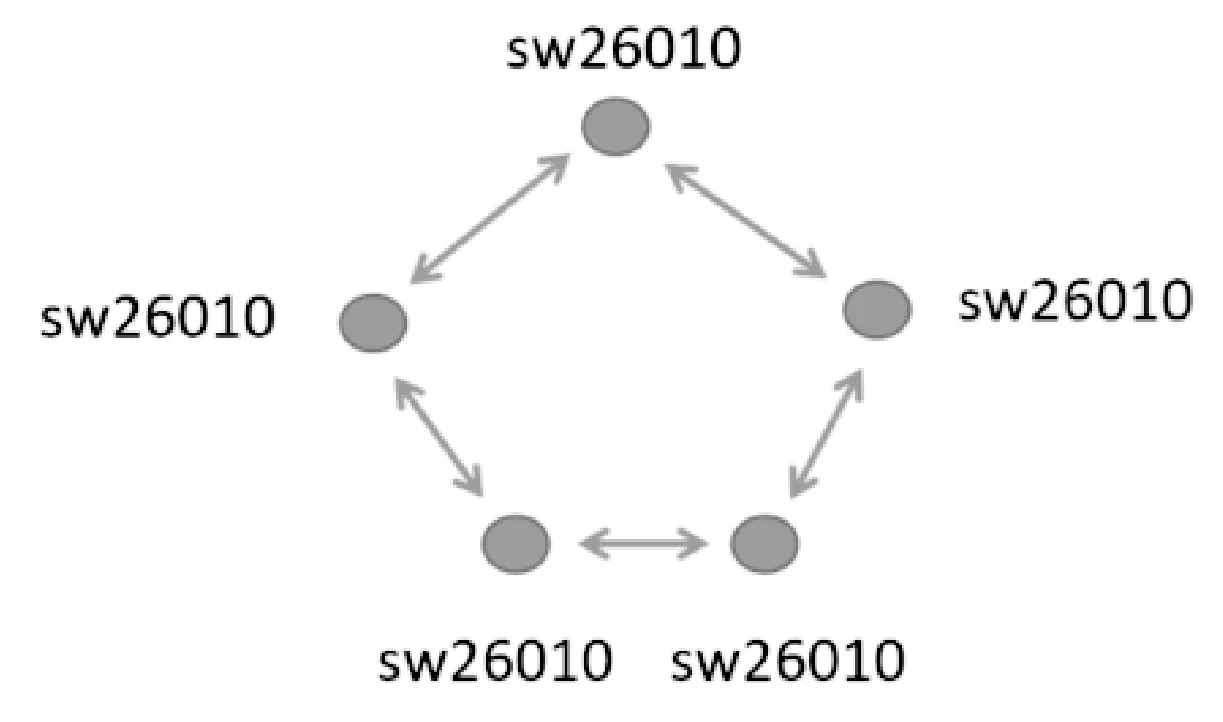
系統峰值運算性能125.436 PFLOPS,實測LINPACK持續運算性能為93.015 PFLOPS,LINPACK系統效率達到74.153%,內存總容量1 024 TB,訪存總帶寬4 473.16 TB/s,互聯網絡的網絡鏈路帶寬14 GB/s,I/O聚合帶寬341 GB/s,網絡對分帶寬70 TB/s。系統功耗15.371 MW,性能功耗比6 051.131 MFLOPS/W。系統采用40 960個SW26010異構眾核處理器[7]。SW26010處理器采用片上計算陣列集群和分布式共享存儲相結合的異構眾核體系結構,使用64位自主神威指令集,全芯片260核心,芯片標準工作頻率1.5 GHz,峰值運算速度3.168 TFLOPS。SW26010處理器的架構如圖2所示。

圖2 SW26010異構眾核處理器架構
1.2 深度神經網絡
深度神經網絡是一種能夠從高維數據中提取信息的神經網絡,卷積神經網絡(CNN)是經典的深度學習算法。
CNN由輸入層、輸出層和卷積層、池化層等多個隱藏層組成。輸入層一般為一個二維向量。卷積層是CNN的核心,用于從輸入層或較低級別的特征圖提取更高層次的特征。池化層的作用是簡化卷積層的輸出。輸出層完成對結果的預測,一般為一個Softmax函數。CNN組成如圖3所示。

圖3 CNN組成圖
CNN需要為給定的訓練數據調整和更新其卷積核參數或權重。反向傳播是計算神經網絡中權重梯度優化所需梯度的有效方法[8]。反向傳播算法包括正向傳播和反向傳播。正向傳播過程中順著網絡結構依次計算,最后得到網絡的輸出結果;反向傳播過程遵從鏈式法則,計算損失函數相對于權重的梯度。最后采用優化算法對權重進行更新。
隨機梯度下降算法(SGD)[9]具有結構簡單、收斂速度快、效果好的優點,因此在深度神經網絡算法中得到了廣泛應用。在大數據背景下,深度神經網絡的數據并行更多的是通過分布式隨機梯度下降算法。對于該算法中參數更新方式的選擇,目前主要有同步SGD和異步SGD兩種機制。同步SGD需要利用所有節點上的參數信息,而慢節點所帶來的同步等待使得數據并行時的加速比并不理想。異步SGD雖然單次訓練速度快,但是其固有的隨機性使得網絡在訓練過程中達到相同收斂點耗費的時間更長,且在訓練后期可能會出現震蕩現象。
隨機梯度下降算法的并行算法[10]如下:
Wt+1=Wt-ηE(ΔWt)
(1)
式中:Wt為第t次迭代的權重值;η為學習率;ΔWt為第t次迭代W關于損失函數的梯度;E(ΔWt)為第t次迭代各節點W關于損失函數的梯度的均值。
1.3 Caffe深度學習框架
Caffe是伯克利視覺和學習中心(BVLC)推出的一款深度學習框架[2]。它具有以下優點:(1) 完全基于C++代碼,且結構清晰,層次分明,具有非常好的效率和可移植性;(2) 采用了模塊化的架構,可以實現新的數據格式、網絡層、損失函數等的方便擴展;(3) 具有非常完善的開發交流社區等。
Caffe模型[11]包括Solver、Nets、Layers和Blobs。Solver是求解器,負責協調模型的優化;Nets、Layers和Blobs組成一個具體的模型。Nets是網絡,通過逐層定義的方式定義,從數據輸入層到損失層自上而下的定義整個模型。一次迭代可以看作Net的一次正向和反向傳播。Layer是層,也是計算的基本單元,可以進行很多運算,比如卷積、池化、內積等。blobs是Caffe的標準數組結構,它提供了統一的內存接口。
BVLC版Caffe對多GPU并行有很好的支持,但不支持CPU的分布式擴展。國家超級計算無錫中心已經成功地將Caffe移植到“神威太湖之光”超級計算平臺上,并針對申威異構眾核處理器開發出針對卷積、矩陣乘等深度學習核心計算模塊的算法庫swDNN[12]。swDNN的性能相比K40M圖形處理器上的cuDNN算法庫具有1.91~9.75倍的雙精度浮點數性能優勢[6]。
2 相關工作
隨著數據規模的急劇增大和模型的日趨復雜,采用分布式擴展技術降低深度神經網絡的訓練時間成為研究熱點。Google的DistBelief[13]和微軟的Adams[14]項目都是利用數據并行和模型并行訓練大規模模型的分布式框架。文獻[15]提出了基于GPU集群的模型并行系統,文獻[16]提出了基于異步交互的參數服務器方式用于解決分布式機器學習問題。Disha Shrivastava等提出了一種基于Apache Spark平臺的數據并行和模型并行混合的分布式方案。
上述的分布式擴展方案在速度和精度方面展示了比較好的性能,然而,由于它們對通信的要求很高且大部分研究基于GPU平臺,因此,我們不能在國產超算平臺上照搬上述的研究。我們提出了兩種基于同步方式的數據并行方式進行Caffe的分布式擴展,分別是參數服務器分布式擴展方式和去中心化分布式擴展方式。
3 參數服務器分布式擴展設計
參數服務器分布式擴展方式由一個或多個參數服務器節點和多個計算節點組成。參數服務器節點(Parameter Server)存儲和更新全部的網絡參數W。計算節點進行網絡的前向特征計算和反向梯度計算。反向傳播時,每個網絡層從下到上依次計算損失函數相對權重的梯度,并將所在層的梯度傳遞給參數服務器節點。參數服務器接收到所有層梯度信息后進行參數更新操作,并將更新后的參數傳遞給計算節點。參數服務器分布式擴展方式的架構示意如圖4所示。

圖4 參數服務器方式架構示意圖
我們將一個SW26010處理器作為一個節點,采用基于MPI的并行編程語言。選用一個節點(通常為0號進程)作為參數服務器節點,其他節點(非0號進程)作為計算節點。計算節點的數量根據分布式擴展規模確定。
在一次迭代中,Caffe中算法實現流程為:
(1) 0號進程向其他進程廣播網絡參數。
(2) 非0號進程進行正向計算,從上向下依次計算每層的特征。
(3) 非0號進程進行反向計算。從下向上依次計算每層的網絡參數相對于損失函數的梯度。對層j,計算出該層網絡參數的梯度信息后,0號進程對該層梯度信息進行聚集操作。每層依次進行,直至反向傳播完成。
(4) 所有層的梯度信息聚集操作完成后,0號進程利用梯度信息進行網絡參數的更新。
算法語言如算法1所示。
算法1參數服務器方式分布式擴展算法
for(i=0; i { 0號進程向其他進程廣播網絡參數W; for(j=0; j { 非0號進程 forward_cpu(); } for(j=Net_depth; j > 0; j--) { 非0號進程計算層j梯度ΔW 0號進程聚集ΔW } 0號進程進行梯度平均和參數更新; } 通過理論分析,我們發現第3節中參數服務器方式的分布式擴展方式具有實現簡單的特點,但是也存在一些不足,具體表現在兩方面:一是參數服務器節點和多個計算節點之間存在一對多或多對一的通信,容易產生通信瓶頸;二是反向傳播過程中,每一層立刻對梯度信息進行聚集操作,通信延遲比較大。針對這兩個問題,我們提出了去中心化方式的分布式擴展框架。 去中心化方式的分布式擴展中所有的節點都是計算節點,且節點之間不分主次。計算節點擁有完全相同的完整的初始網絡參數。在網絡優化時,每個計算節點進行獨立的網絡計算,即正向計算和反向計算。在完整的網絡計算完成后,計算節點對所有網絡層的梯度信息進行聚集平均操作。計算節點自主進行參數更新。 與參數服務器分布式擴展算法相同,去中心化方式的分布式擴展算法實現時,也將一個SW26010處理器作為一個節點,采用基于MPI的并行編程語言。具體的算法實現可以分為兩部分,即網絡參數初始化和網絡參數優化。網絡參數初始化完成所有節點初始網絡參數的同步,整個訓練過程只需要一次網絡參數初始化操作;網絡參數優化通過數萬次的迭代優化實現。 初始化時,任意節點(通常為0號進程)進行網絡參數廣播,完成所有節點的網絡參數同步;后面為上萬次的網絡參數優化迭代。在一次迭代中,去中心化方式的分布式擴展的操作為: (1) 進程從上向下對網絡中每層進行特征計算; (2) 進程從下向上對網絡中每層計算梯度ΔW; (3) 進程計算出所有網絡層ΔW后,所有進程進行梯度信息聚集平均操作,聚集平均操作完成后,所有進程擁有相同的梯度信息; (4) 所有進程自主進行網絡參數更新。 算法語言如算法2所示。 算法2去中心化分布式擴展設計 0號進程向其他進程廣播網絡參數W for(i=0; i { for(j=0; j { 所有進程 forward_cpu(); } for(j=Net_depth; j > 0; j--) { 所有進程計算層j梯度ΔW 所有進程聚集平均ΔW } 所有進程進行參數更新操作; } 由于BVLC版Caffe中每個網絡層梯度信息在內存中的存放地址是不連續的,因此,去中心化方式的進程梯度信息聚集操作具體實現時需要先將網絡層的梯度信息拷貝到連續的地址空間再進行聚集操作。聚集操作完成后,再將梯度信息從連續的地址空間拷貝回各網絡層的梯度存放地址空間。這會浪費大量的時間,特別是在迭代次數非常大時。因此,我們從Caffe框架層面對Caffe的梯度信息存放方式進行了重構,將各層分散的梯度信息內存分布方式改進為連續的內存存放方式,如圖5所示。 圖5 Caffe梯度信息內存重分配 傳統的MPI_Allreduce算法是為低延遲的網絡設計的,在高性能計算中,MPI_Allreduce的效率比較低。我們將一種環狀的聚集算法引入到國產超級計算平臺上,如圖6所示。 圖6 SW26010 ringAllreduce 其具體步驟為:(1) scatter-reduce;(2) allgather。在第1步中,CPU將交換數據,使得每個CPU最終都有一個最終結果的數據塊。在第2步中,CPU將交換那些塊,使得所有CPU最終得到完整的最后結果。 RingAllreduce和MPI_Allreduce在神威太湖之光的性能對比如圖7和圖8所示。可以看到,在常用的深度學習模型下,512個節點上RingAllreduce相比MPI_Allreduce的性能提升可達2.3~4.1倍的加速效果。 圖7 RingAllreduce和MPI_Allreduce性能 對比圖(通信數據量為60.97 MB) 圖8 RingAllreduce和MPI_Allreduce性能對比圖 我們進行了兩組實驗以驗證分布式擴展算法的正確性(精度)和性能。 正確性測試主要測試分布式擴展后的訓練精度是否和單節點的訓練精度一致。我們選取Cifar10模型對Cifar10數據集進行訓練,分別比較單節點、參數服務器分布式擴展方式、去中心化分布式擴展方式的訓練精度。訓練迭代次數為40 000次。具體參數及結果如表1所示。 表1 Caffe單節點及分布式訓練精度表 參數服務器分布式擴展方式和去中心化分布式擴展方式中,網絡的前向計算和后行計算過程是相同的,不同的部分在于前者在每次迭代優化中需要進行一次網絡參數廣播操作和多次梯度信息聚集操作,后者只需要進行一次梯度信息聚集操作。因此節點間的通信時間是衡量兩種分布式擴展方式性能優劣的評價標準。 我們在“神威太湖之光”超算平臺上進行實驗,一個SW26010處理器作為一個節點,處理器選用大共享模式。選擇三個經典的深度學習模型Alexnet、GoogleNet和ResNet進行實驗。數據集采用Imagenet數據集。分布式擴展規模最大為512個計算節點。測試結果如圖9-圖11所示。 圖9 Alexnet模型下兩種分布式擴展通信性能對比圖 圖10 Googlenet模型下兩種分布式擴展通信性能對比圖 圖11 Resnet模型下兩種分布式擴展通信性能對比圖 5.3.1正確性測試分析 參數服務器分布式擴展方式和去中心化的分布式擴展方式訓練精度與單節點的訓練精度相比,僅下降了0.1%和0.2%,在正常波動范圍內。這說明參數服務器分布式擴展方式和去中心化的分布式擴展方式的實現是正確的,得到的結果也是正確的。 5.3.2性能測試分析 對Alexnet網絡,當并行規模小于16時,參數服務器方式和去中心化方式通信時間差別不大;當并行規模大于16時,去中心化方式通信時間隨著并行規模的擴大增長緩慢,參數服務器方式的聚集時間卻隨著并行規模的增加而急劇增長;當并行規模為256時,參數服務器方式所需通信時間是去中心化方式的10倍。 對GoogleNet網絡,當并行規模小于8時,參數服務器方式和去中心化方式梯度聚集時間差別不大;當并行規模大于8時,去中心化方式梯度聚集時間隨著并行規模的擴大增長緩慢,而參數服務器方式的通信時間隨著并行規模的增加而急劇增長;當并行規模為32時,參數服務器方式所需通信時間是去中心化方式的77倍。 對ResNet網絡,當并行規模小于8時,參數服務器方式和去中心化方式通信時間差別不大;當并行規模大于8時,去中心化方式通信時間隨著并行規模的擴大增長緩慢,參數服務器方式的聚集時間卻隨著并行規模的增加而急劇增長;當并行規模為32時,參數服務器方式所需通信時間是去中心化方式的98倍。 去中心化的分布式擴展方式相比參數服務器方式的分布式擴展方式在節點間通信指標上可以加速最多達98倍。這個結果是合理的,因為去中心化的分布式擴展與參數服務器分布式擴展相比,在每次迭代中少了網絡參數的廣播操作,并將多次的梯度信息聚集操作變為一次梯度信息聚集操作,這減少了網絡間通信的次數以及因為同步而引起的時延。 基于上述的設計和實驗結果可得出結論,去中心化的分布式擴展方式明顯優于參數服務器分布式擴展方式。因此,我們將在基于“神威太湖之光”平臺的Caffe上采用去中心化的分布式擴展方式。 本文在“神威太湖之光”平臺上對深度學習框架Caffe進行了基于同步梯度更新方式的分布式擴展方式研究。首先實現了基于同步梯度更新方式的參數服務器分布式擴展方式;其次實現了去中心化的分布式擴展方式,對Caffe梯度信息存放內存、梯度信息聚集算法等進行了改進。實驗結果表明,兩種分布式擴展方式均能很好地對Caffe框架進行擴展,但是去中心化的分布式擴展方式在節點間的通信效率方面更有優勢,是更好的分布式擴展算法。4 去中心化方式的分布式擴展設計
4.1 Caffe梯度內存存放位置的重構

4.2 梯度信息聚集算法的優化


5 實 驗
5.1 正確性驗證

5.2 性能測試



5.3 結果分析
6 結 語
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58中國外匯(2019年8期)2019-07-13 06:01:06電腦愛好者(2018年15期)2018-08-23 17:24:06民主與科學(2014年3期)2014-02-28 11:23:03教育與職業(2014年7期)2014-01-21 02:35:04計算機與網絡(2013年1期)2013-06-05 05:31:50電腦迷(2012年24期)2012-04-29 00:44:03中華女子學院學報(2012年6期)2012-03-25 13:52:27俄羅斯問題研究(2012年1期)2012-03-25 09:54:45杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
