基于動態主元分析和極限學習機的分解爐出口溫度預測
2020-01-08 02:23:08
測控技術 2019年12期
關鍵詞:模型
(合肥工業大學 電氣與自動化工程學院,安徽 合肥 230009)
水泥工業是我國國民經濟建設的重要基礎材料產業,也是高能源消耗和高污染排放的行業之一[1],所以節能環保的生產方式尤為重要。預分解是新干法水泥生產技術的核心步驟[2],而分解爐出口溫度是反映分解爐運行工況優劣的關鍵指標,對水泥生產的質量、產量及能耗起著至關重要的作用,所以對分解爐出口溫度的研究具有重要意義[3]。近年來,許多學者圍繞分解爐溫度的預測和控制展開研究。文獻[4]提出基于遺傳算法優化的BP網絡出口溫度預測模型,并進行了仿真驗證;文獻[5]在極限學習機與回歸分析的基礎上,建立了出口溫度的T-S模糊模型;文獻[6]和文獻[7]分別運用神經網絡與自適應PID的方法,實現了對分解爐溫度的控制;文獻[8]提出一種基于參數優化的支持向量回歸的方法預測分解爐溫度,取得了預期的預測效果。但是上述研究在關于影響分解爐溫度的變量選擇上,大都是采用傳統的經驗法,以風(三級風)、料(生料量)、煤(喂煤量)等主要變量對分解爐系統進行研究。由于分解爐內部結構復雜、變量眾多、理化反應交織,人為經驗法選取的少數變量難以全面概括分解爐系統的內部規律,易造成預測精度不高,模型的泛化能力較弱等問題。而將多元統計分析方法與神經網絡算法相結合的數據驅動建模方法,由于包含可能影響系統的全部變量,又具有神經網絡強大的計算擬合能力,所以能夠更為科學準確地把握系統特性,因此更適用于多變量、非線性和不確定性的分解爐出口溫度建模預測。
本文提出基于動態主元分析(Dynamic Principal Component Analysis,DPCA)與極限學習機(Extreme Learning Machine,ELM)相結合的DPCA-ELM預測模型對分解爐出口溫度進行預測。利用DPCA消除變量之間的相關性,計算出各輸入變量在不同時序下對輸出的影響,降低數據的冗余和噪聲,減少ELM的輸入維度。然后將降維所得的主元作為極限學習機的輸入層,再通過PSO粒子群尋優算法求得ELM網絡的最優權值和偏置,再由方程組計算確定隱含層至輸出層的權值,經訓練、調參,從而完成對出口溫度的建模預測。經仿真驗證表明,基于DPCA-ELM的分解爐出口溫度預測模型具有良好的預測精度,同時也為其他復雜、非線性、多變量工業系統建模提供參考。
1 理論分析
1.1 主元分析法與動態主元分析法
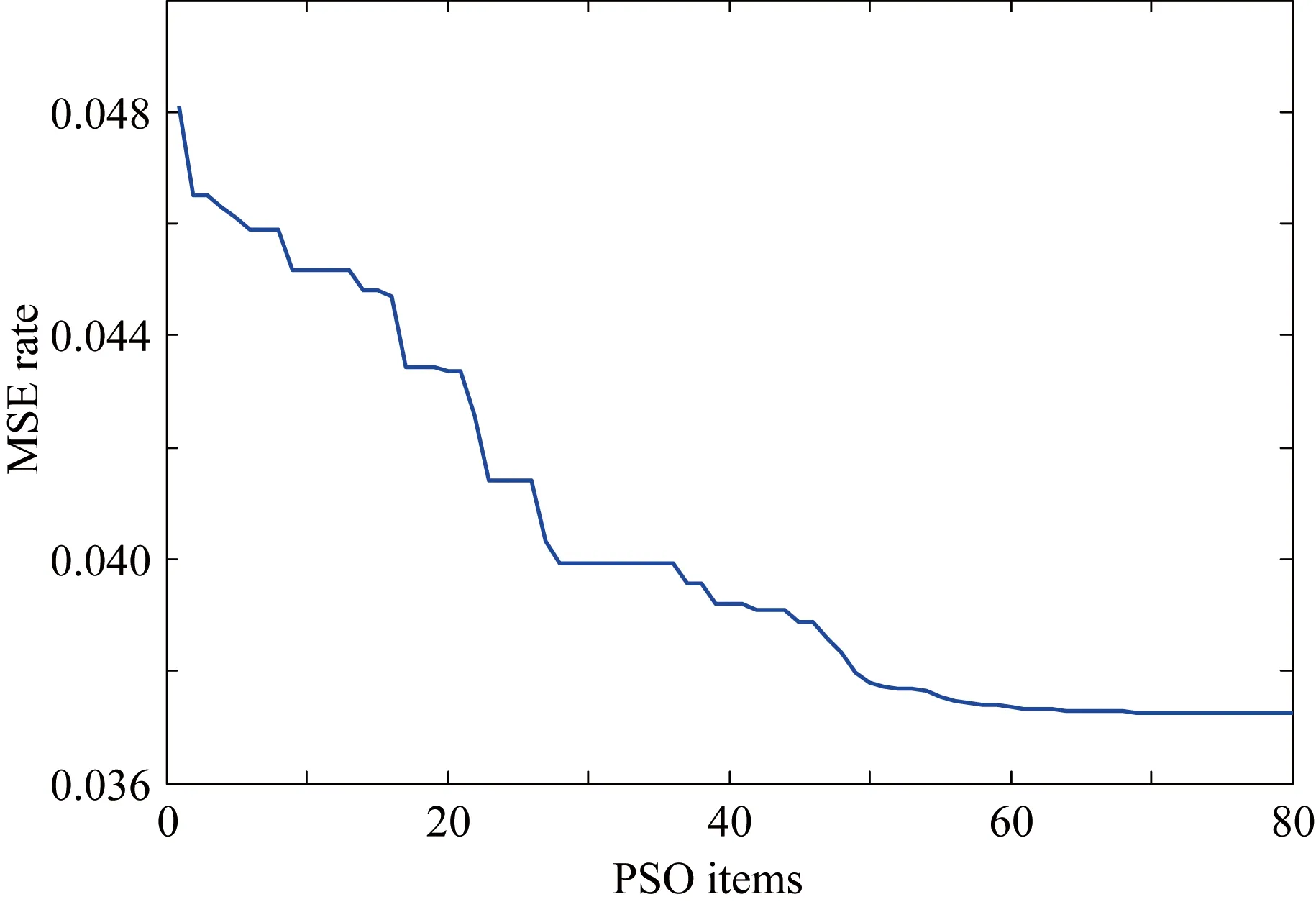
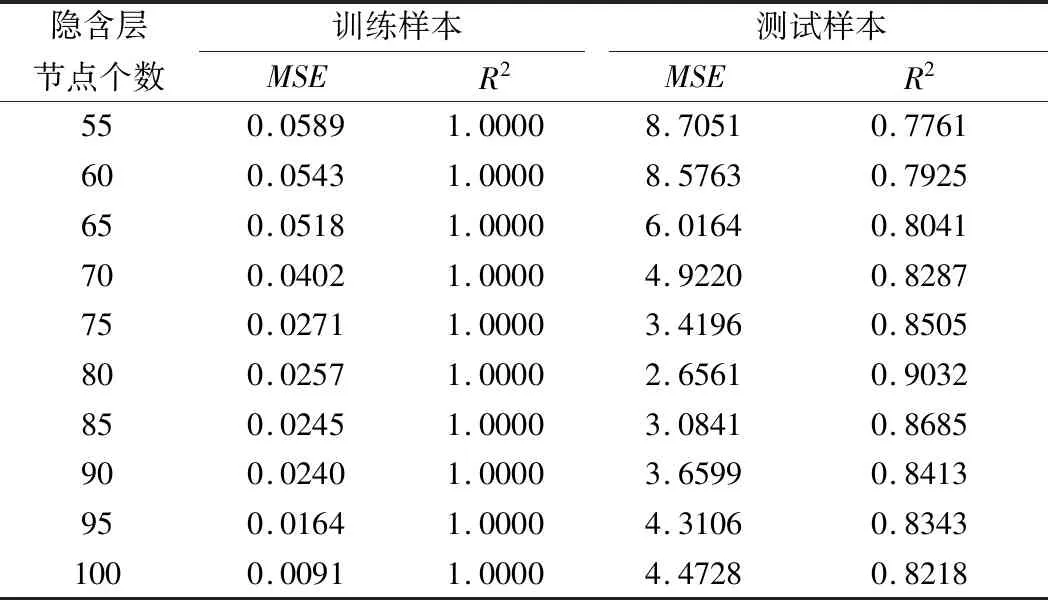
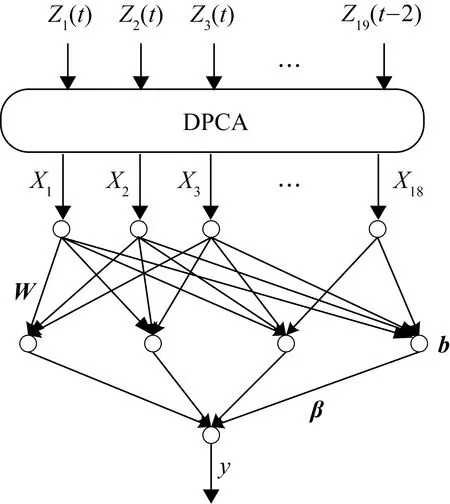
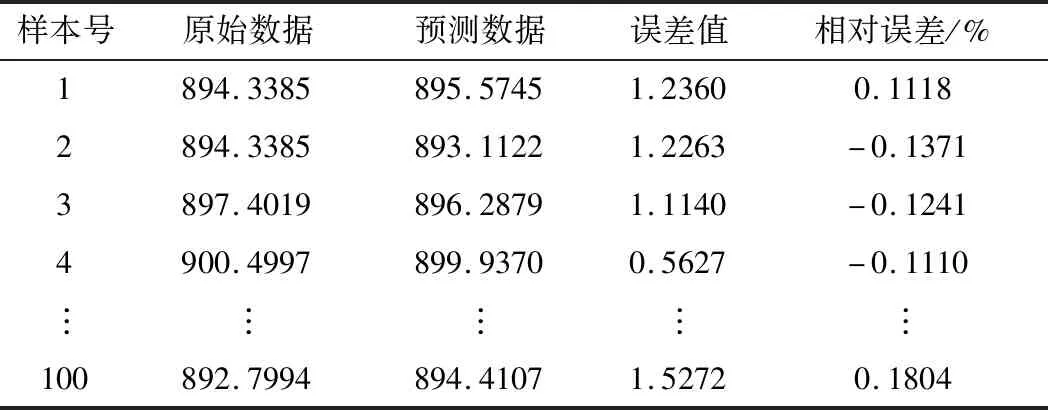
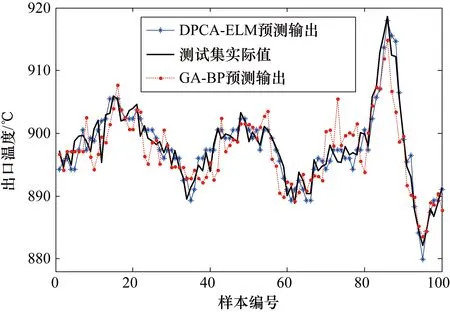
主元分析(PCA)的基本原理就是將多維的線性相關的原始數據Xn×m轉化為低維且線性無關的新數據Tn×k,其中k (1) X的標準化S又可以表示為得分矩陣和相關系數矩陣的外積形式: S=Tn×mRm×m (2) 式中,矩陣R=(r1,r2,…,rm)為S的相關系數矩陣;T=(t1,t2,…,tm)為S的得分矩陣。若‖t1‖>‖t2‖>…>‖tm‖,則t1即為第一主元,代表X在其對應方向的投影最大。 取前k個主元,可得S=TkRk+E,式中E為殘差矩陣,主元Tn×k=(t1,t2,…,tk)即為降維后的新數據。 雖然傳統的PCA算法可以降低變量維度,減少數據冗余,但是對于有時序的系統模型,傳統的PCA會忽略某些變量對模型輸出的動態影響,從而影響模型的可靠性,而DPCA可以通過添加前h時刻的增廣矩陣彌補傳統PCA的靜態不足的問題。增廣矩陣為 (3) 式中,x為t時刻在訓練集中的m維觀測向量對于滯后因子h的確定,由遞推公式(4)遞推至rn(h)>0: (4) 經計算當h=2時,rn(h)>0,故確定滯后因子為2。 極限學習機算法是由新加坡學者黃廣斌等人在2004年提出的一種單隱含層前饋神經網絡學習算法,具有預測精度高,訓練速度快等優點。 對于單隱含層神經網絡,設有n組多變量輸入樣本Xi=[xi1,xi2,…,xin]T∈Rn,多變量輸出樣本Ti=[ti1,ti2,…,tim]T∈Rm。則網絡的輸出可以表示為 (5) 式中,j=1,2,…,n;L為隱含層節點數;βi為輸出權值;f(x)為網絡的激活函數;Wi=[wi,1,wi,2,…,wi,n]T為輸入層到隱含層權值;Xj為網絡輸入;bi為第i個隱含層節點的偏置。網絡學習的目的是實際輸出Oj與目標的誤差盡可能的逼近于0,可以表示為 (6) 等價于存在βi,Wi和bi,使得式(7)成立。 (7) 式(7)又可以等價表示為Hβ=T,其中,H是隱含層節點的輸出,β為輸出層的權值,T為網絡期望輸出。式中,β、T、H可以表示為[12] (8) (9) (10) 式中,i=1,2,…,L,求解式(10)等價于求解損失函數的最小值: (11) (12) 水泥分解爐作為新干法水泥生產的核心部分,承擔了燃燒加熱、氣固換熱、物料反應與分解等多個步驟。因此機理建模預測在水泥分解爐系統中的建立顯得尤為困難。故本文采用數據驅動建模的方法,建立了基于水泥生產過程中所采集的生產數據的DPCA-ELM分解爐出口溫度預測模型,并在Matlab環境下,完成仿真驗證。 本文數據來自2014年6月,某水泥公司6000 t/d水泥生產線的現場數據,采集數據的時間間隔為1 min。從穩定工況下選取400組作為訓練樣本,再選取100組測試樣本用來測試模型的有效性。水泥分解爐的系統結構復雜,其內部理化反應眾多,故本文參考水泥生產實際過程和文獻確定與模型輸出相關的輸入變量,其中包括:生料量、喂煤量、三級風風溫和風壓、各級旋風筒出口溫度以及氣壓、高溫風機電流、轉速等。訓練樣本原始數據見表1。 表1 訓練集樣本原始數據 選取如上輸入變量中生料量、喂煤量等19個變量,經計算滯后因子h=2,故添加前兩個時刻的數據構成主元分析的增廣矩陣,再采用DPCA算法對輸入變量進行降維,以簡化ELM網絡輸入單元個數。 在進行主元分析前,首先要判斷各變量之間是否存在相關性,以檢驗主元分析的適用與否。所以本文采用KMO統計檢驗方法,KMO的值δ越接近1,數據越適宜采用主元分析。其檢驗公式如下: (13) 式中,rij為所有變量的簡單相關系數;aij為所有變量的偏相關系數。經檢驗計算,篩選后變量的KMO值δ=0.9518,故篩選后的變量非常適宜使用主元分析進行降維。 將篩選后的數據標準化,消除因量綱不同所產生的不利影響。再求出相關系數陣的特征值λ1,λ2,…,λi,…,λ57,及其對應的特征向量p1,p2,…,pi,…,p57,并將特征向量按其對應特征值由大到小排列。計算特征值累積貢獻率(Cumulative Percent Variance,CPV)其公式為 (14) 式中,分母為所有特征值的累加值;分子為主元的累加值。設定CPV的期望值為85%,經計算得k為18時,CPV的值達到85.8077%,故取主元個數為18,其特征值及主元貢獻率見表2。 表2 特征值及主元貢獻率 最后由原始數據X和主元的特征向量的乘積求得降維后的主元Tn×k=(t1,t2,…,ti,…,t43),式中,ti=Xpi。 將主元作為極限學習機網絡的輸入層,即網絡有18個輸入節點。選取激活函數為sigmoid函數,其表達式為 (15) 選取性能函數為均方誤差MSE(Mean Squared Error)與擬合優度R2(R-square),其表達式為 (16) (17) 在ELM中,輸入權值與隱含層偏置隨機產生,無需迭代,輸出權值由式(12)確定。但由此產生的參數隨機性較大,且所需隱含層節點數過多,易導致模型復雜度加大,泛化能力下降。故本文采用粒子群尋優算法(PSO)代替ELM權值偏置隨機產生。 PSO優化算法的參數設置參考文獻[14]所述,并驗證其在本模型的可行性。其具體設置為:粒子數30;最大和最小慣性權重分別為0.9和0.4;學習因子c1,c2同為1.4961;最大迭代次數為80次;激活函數為sigmoid函數;適應度函數為MSE。 PSO算法適應度隨迭代次數變化曲線如圖1所示,當迭代次數在70次左右時,適應度值穩定在0.0373不再變化,訓練收斂,權值和偏置尋優過程結束。 圖1 適應度隨迭代次數變化曲線 對于ELM隱含層節點個數的確定,參考文獻[15],設定初始隱含層節點數為20,再以5為增幅進行訓練預測,每個節點重復預測20次,并對所得性能指標取平均值。不同隱含層節點個數預測的平均性能指標如表3所示。 表3 不同隱含層節點個數性能指標 由表3看出,隨著隱含層節點個數的增加,訓練樣本預測效果越好,測試樣本預測效果在節點數為80時預測效果最佳,當隱含層節點個數由80繼續增加時,測試樣本預測效果變差。其性能函數隨節點數變化趨勢如圖2所示。 圖2 預測效果隨節點個數變化趨勢 由圖2可以看出,在節點個數為80時,測試集MSE最小,擬合優度R2最大,對測試樣本數據的預測結果最佳。故確定隱含層節點數為80時,模型預測與泛化能力最佳,其訓練時間為50.8255 s。出口溫度預測模型如圖3所示。 圖3 DPCA-ELM預測模型 其中,Zi為時滯h為2的原始變量,Xi為動態主元分析降維所得的18個主元,即ELM的輸入層,W為輸入層權值,bi為第i個隱含層節點的偏置,βi為第i個隱含層節點的輸出權值,y為輸出的預測出口溫度。 將選取的100組測試集樣本變量數據導入DPCA-ELM預測模型,100組測試集樣本如表4所示。 表4 測試集樣本原始數據 經DPCA-ELM模型預測后,得到測試集預測輸出。100組出口溫度預測結果與實際數據對比及誤差如表5所示。由表5可以看出測試集預測效果良好且穩定。 經計算,DPCA-ELM模型預測的最大誤差約為5.1294 ℃,平均預測誤差約為1.2013 ℃,相對誤差平均值約為0.1285%。 表5 測試樣本預測結果與誤差 為了進一步驗證DPCA-ELM模型的有效性與優勢,將其與文獻[4]所提出的GA-BP模型的預測效果進行對比。 設置遺傳算法參數:進化代數:100;種群規模:50;交叉概率:0.7;變異概率:0.1。 重復試驗觀察后,設置BP神經網絡的隱含層數為45;激活函數設置為動量梯度下降法(Gradient Descent with Momentum)函數traingdm;迭代次數為200;學習步長為0.01;性能函數為MSE;目標值為0.001。 GA-BP模型的訓練時間為21.7242 s。經訓練后,建立了遺傳算法優化的BP網絡的出口溫度預測模型,將測試樣本數據導入模型,得到測試樣本預測輸出。DPCA-ELM模型和GA-BP模型預測結果與測試樣本實際對比如圖4所示。 由圖4可以看出,基于DPCA-ELM模型的出口溫度預測效果良好,GA-BP模型預測效果稍差。其預測結果與誤差對比如表6所示。 由表6可以得出:基于DPCA-ELM的出口溫度預測模型具有精度高、擬合度好、訓練速度快等優勢。基于GA-BP網絡的預測模型,由于輸入維度高,遺傳算法編碼復雜,所需迭代參數較多,故訓練速度較慢,泛化能力較弱,影響對出口溫度預測的精度。 圖4 測試樣本預測效果對比 模型MSER2EmaxEmeanGA-BP10.57910.63257.08122.8773DPCA-ELM2.36750.91315.12941.2013 本文提出了一種數據驅動建模方法:首先進行KMO統計檢驗,驗證PCA的適用性,然后計算出滯后因子,使用DPCA降低影響分解爐出口溫度變量的維度,消除變量之間的相關性。在此基礎上,構建以低維數據為輸入層的ELM預測模型,再使用PSO算法優化參數,通過訓練、調參,最終求得最優DPCA-ELM出口溫度預測模型,并使用該模型對測試樣本進行預測。最后通過與GA-BP神經網絡預測模型的對比分析,體現DPCA-ELM預測模型良好的預測精度和泛化能力。1.2 極限學習機
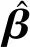

2 出口溫度建模預測
2.1 數據來源與變量篩選

2.2 KMO檢驗與PCA降維

2.3 DPCA-ELM預測模型參數設置與訓練
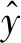

3 仿真驗證
3.1 測試數據及預測

3.2 預測結果對比分析

4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
