基于特征選擇的飛灰含碳量影響因素分析
2020-01-06 08:27:44王建峰郄英杰趙文杰
儀器儀表用戶 2020年1期
王建峰,郄英杰,喬 源,趙文杰
(1.山西漳山發電有限責任公司,山西 長治 046021;2.華北電力大學 控制與計算機工程學院,河北 保定 071003)
0 引言
鍋爐飛灰含碳量是反映火力發電廠燃煤鍋爐燃燒效率的一項重要指標,較低的飛灰含碳量代表著鍋爐燃燒具有較高的效率。精確和實時監控飛灰含碳量,有利于提高鍋爐的燃燒控制水平,降低發電成本,提高機組運行的經濟性[1]。但是由于測量儀表的局限性,傳統的測量鍋爐飛灰含碳量的儀表并不能很準確地實現數據測量,從而不能有效地通過控制策略對鍋爐燃燒過程進行準確控制,降低飛灰含碳量,提高燃燒效率[2]。在火電機組的燃燒過程中,影響飛灰含碳量的生成因素較為復雜,文獻[3-5] 針對不同火電機組飛灰含碳量的生成機理進行分析,根據鍋爐燃燒原理對影響飛灰含碳量的因素進行提取;由于影響飛灰含碳量的影響因素較多,文獻[6]提出飛灰含碳量的主成分分析法對分析所得因素進行選取,運用選取之后的特征量進行模型建立,會提升建模的。
本文提出燃燒系統的飛灰含碳量影響因素選擇的方法,得到較為準確且具有參考價值的動態飛灰含碳量影響因素。數據選擇為山西某火電機組DCS 取得的原始運行數據,通過特征選擇的方法得到影響燃燒飛灰含碳量的因素,對影響因素進行數據處理并建立對應的軟測量模型。通過上位機WinCC 結合機組的運行方式以實現飛灰含碳量系統的遠程監控,監測選擇得到的特征量是否準確。上位機界面進行監測,可以看出建立的模型具有較高的實時性和準確性。故經過特征選擇得到的影響飛灰含碳量的因素建立的模型使之在工業現場能夠穩定、精確運行,對于飛灰含碳量的測量和燃燒效率的控制具有重要的意義。
1 飛灰含碳量生成機理
1.1 燃燒機理分析
飛灰在爐膛內的燃燒過程包含物理和化學變化,具體過程如下所示:首先,煤粉通過送風機混合一次風吹入鍋爐。其中,氣化溫度低的物質先燃燒,這個過程中揮發分轉化為液體和氣體外逸,煤粉結合揮發分形成表面有很多小孔煤粉顆粒,隨著燃燒煤粉顆粒轉化成為焦炭[7,8]。煤粉中包含有機物和無機物,其中有機物是可燃燒的,而無機物就會被剩下,所以焦炭等煤粉中的碳成分燃燒完后,無化物的結合煤粉燃燒保持原來的形狀,形成了多孔玻璃體。隨著燃燒繼續進行,形成的多孔玻璃體繼續融化進一步收縮,小孔的間隙也相應的再減小,導致其密度變大,灰粒的半徑也在持續變小,以至于最后形成密度高體積小的密實玻璃體[9]。在煤粉燃燒充分的情況下,形成密實玻璃體;當不充分燃燒時,就會形成多孔玻璃體形狀,還有多孔的碳粒以及焦炭,其中焦炭是飛灰含碳量主要成分[10]。
1.2 生成機理分析
磨煤機將煤塊磨成煤粉,由一次風將煤粉送入鍋爐爐膛進行燃燒,燃燒過程是否充分是導致飛灰含碳量大小的主要原因。當煤粉混合著一次風進入爐膛進行燃燒時,如果燃燒速度較慢,會使煤粉來不及完全燃燒就被吹離爐膛,排出爐膛的煙氣中含有一定比例未燃燒充分的煤粉,即飛灰含碳量較高。所以,影響鍋爐燃燒過程中的變量都將是影響飛灰含碳量的因素[11]。
1)煤質
煤質指爐膛燃燒燃料的品質,影響煤質的主要因素有灰分、水分、揮發分等因素。其中,灰分是燃料燃燒之后的殘留物,灰分越高,燃燒生成的殘留物會吸收燃燒產生的熱量,導致煤粉燃燒變慢,不能充分燃燒,飛灰含碳量升高。
2)煤粉細度
煤塊經過磨煤機磨成煤粉,煤粉細度也是影響燃燒是否充分的重要因素。煤粉越細,煤粉與火焰接觸的面積越大,燃燒速度越快,燃料中揮發分和水分的析出也就越快,有利于燃燒過程的充分進行,降低飛灰含碳量。
3)一次風壓
一次風濃度影響送風機吹入爐膛的煤粉的濃度,對飛灰含碳量也有著一定的影響。一次風量越大,煤粉濃度越低,會導致鍋爐的燃燒狀態不穩定,爐內的燃燒溫度相對較低導致飛灰含碳量增大;一次風量如果太小,會導致煤粉濃度較大,煤粉濃度會導致一次風與二次風托粉不穩定,使燃燒過程不穩定,飛灰含碳量上升。所以,適當的一次風量是保證燃燒穩定的必要條件。
4)二次風門開度
二次風就是助燃風,由送風機送出,主要作用是供給燃料燃燒所需要足夠的氧量。二次風門的開度影響鍋爐中的燃料和風量的比值,二次風量增大使得燃燒所需的氧量充足,燃燒充分飛灰含碳量減小;同時二次風的溫度低于火焰的溫度,混入二次風量較大會導致爐膛溫度下降,導致燃燒不充分,飛灰含碳量增大。所以二次風門的開度并非越大越好,需要根據燃燒過程適度變化,才能提高鍋爐燃燒效率。
5)氧量
燃料完全燃燒的必要條件是適量的空氣燃料比,當燃料燃燒時得不到充足的氧氣,燃料無法充分地燃燒,飛灰含碳量就會增加;當送入爐膛的氧量較為充足時,燃料燃燒充分,煙氣中攜帶的未燃燒的燃料較少,飛灰含碳量降低[12]。
2 特征選擇
2.1 數據處理
1) 數據去重
數據去重又稱重復數據刪除,找出重復的數據并將其刪除,只保存唯一的數據單元。在刪除的同時,要考慮數據重建,即雖然文件的部分內容被刪除,但當需要時,仍然將完整的文件內容重建出來,這就需要保留文件與唯一數據單元之間的索引信息。

圖1 數據預處理后的飛灰含碳量Fig.1 Carbon content of fly ash after data pretreatment
2) 去異常值
對數據進行去除異常值,目的是把數據中由于噪聲干擾等因素引起的輸出值超出正常范圍的數據去掉。
3)數據濾波
為了消除噪聲的干擾,提高曲線的光滑度,需對采樣數據進行平滑處理。一般的數據濾波采用的就是“五值平均法”。此外,也可以通過滯后環節進行濾波。
圖1 為數據處理之后的飛灰含碳量曲線。
2.2 互信息選擇
本次飛灰含碳量模型建立所選取的數據為山西某火電機組DCS 系統取得的運行數據,對DCS 采集點進行綜合分析之后,將可能對飛灰含碳量產生的影響因素進行采集并繪制,其中可能的影響因素共有28 個,分別為負荷、總風量、總煤量、總蒸汽量、氧量、A 側氧量、B 側氧量、A側一次風壓、B 側一次風壓、空預器出口二次風溫(2 個)、爐膛出口溫度(2 個)、二次風門開度(9 個)、磨煤機出口溫度(6 個)等。
互信息是信息論中的一個基本概念,通常用于描述兩個系統間的統計相關性,或者是一個系統中所包含另一個系統中信息的多少[13]。其中,要從28 個影響因素中提取影響飛灰含碳量的主要因素,即確定飛灰含碳量模型中所包含的每一種影響因素所占的信息量多少,可以采用互信息的方法進行數據特征量的提取,分別找到飛灰含碳量模型中各影響因素的權重。
在概率論中,兩個隨機變量A 和B 邊緣概率分布為pA(a) 和pB(b),他們的聯合概率分布為pAB(a,b)。當pAB(a,b)=pA(a)·pB(b)時,隨機變量A 與B 是相互獨立的。互信息I(A,B)通過計算pAB (a,b)和pA(a)·pB(b)的差距來得到A和B 的依賴程度。所以,兩個離散隨機變量A 和B 的互信息可以定義為:
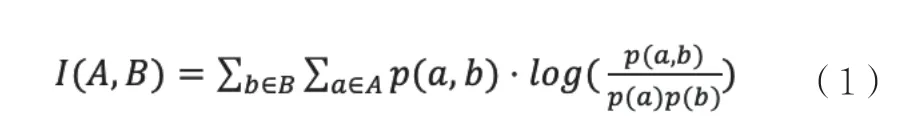
式(1)中,p(a,b)是A 和B 的聯合概率分布函數,而p(a)和p(b)分別是兩個隨機變量A 和B 的邊緣概率分布函數。
在特征選擇的過程中,一般通過熵進行互信息的表達。熵指的是一個系統的不確定性,分別進行兩個離散隨機變量A 和B 的系統熵、兩個系統的條件熵、兩個系統的聯合熵計算,通過推導可以得到互信息的計算結果。推導過程如下:
離散隨機變量A 的系統熵:
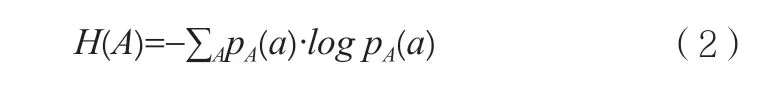
離散隨機變量B 的系統熵:
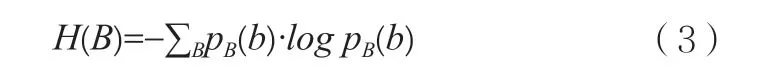
兩個系統的聯合熵:
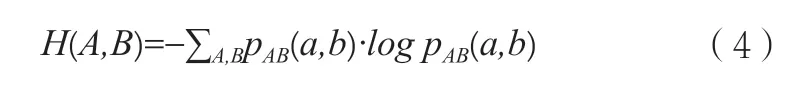
兩個系統的條件熵:

由以上所計算的系統熵值,可得互信息為:

在子函數VectorMI 中,分別計算概率pAB(a,b)、pA(a)、pB(b),并分別計算離散變量A、B 的系統熵、兩個系統的聯合熵、兩個系統的條件熵,通過熵值計算得到兩個輸入系統最終的互信息值。表1 為28 個影響因素對應的互信息值。
選取互信息值較大的變量,相關變量篩選之后共有10個,分別為:二次風溫B、二次風溫A、總蒸汽流量、B 側氧量、A 側氧量、A 側一次風量、總煤量、氧量、負荷、B側一次風量。
2.3 方差選擇法
方差選擇法是通過計算各個特征的方差,然后根據閾值,選擇方差大于閾值的特征。若該特征的方差越大,則表明該特征值對結果的影響更大;反之則對結果的影響較小。假設某特征的特征值只有0 和1,并且在所有輸入樣本中,95%的實例的該特征取值都是1,那就可以認為這個特征作用不大。如果100%都是1,那這個特征就沒有意義了。當特征值都是離散型變量的時候這種方法才能用,如果是連續型變量,就需要將連續變量離散化之后才能用。而且實際當中,一般不太會有95%以上都取某個值的特征存在,所以這種方法雖然簡單但是不太好用。可以把它作為特征選擇的預處理,先去掉那些取值變化小的特征,然后再從以下提到的兩種方法中選擇合適的,做進一步的特征選擇。
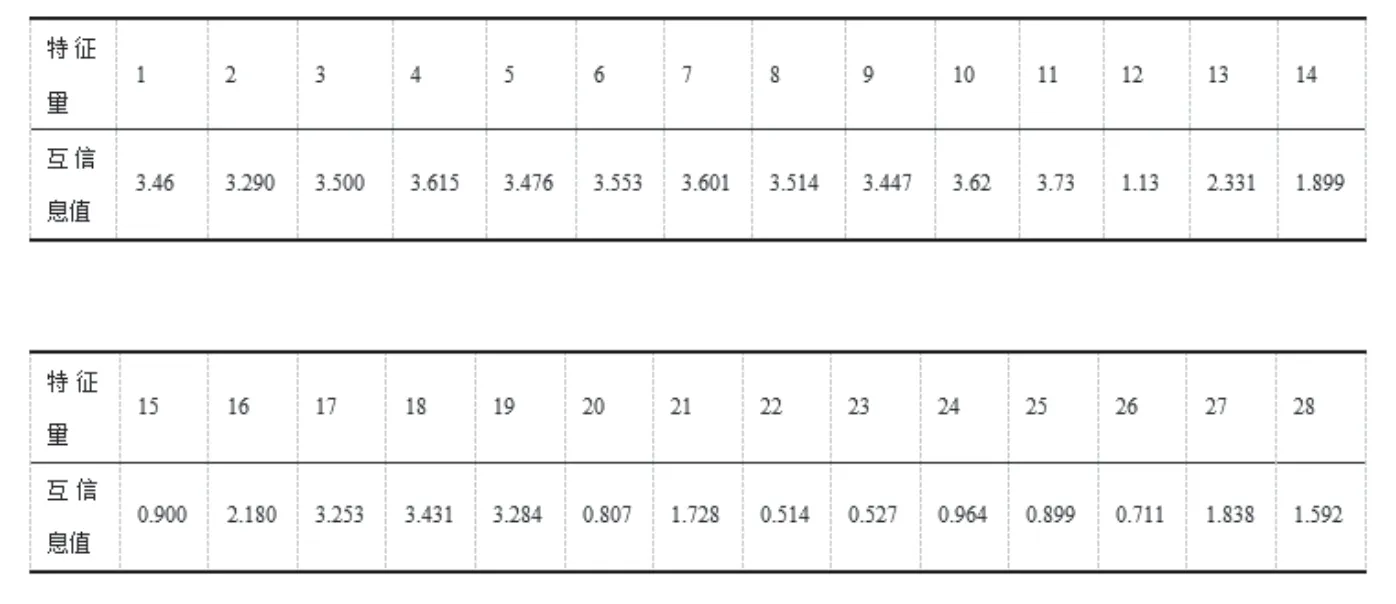
表1 互信息值Table 1 Mutual information
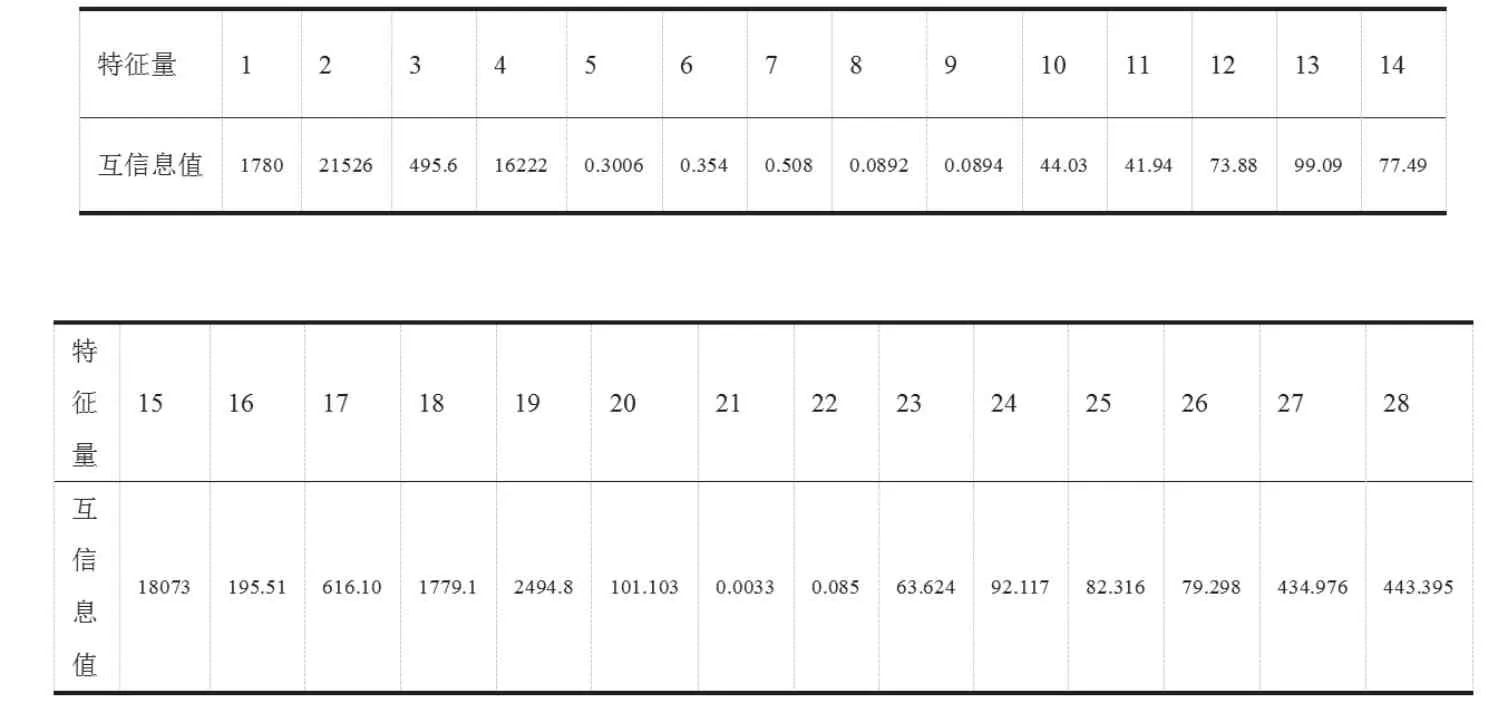
表2 特征量及方差Table 2 Characteristic quantity and variance
通過函數var,調用格式為:fangcha(i)=var(C(:,i));其中,矩陣C 為輸入待計算的特征值數組,返回值為每一個特征量的方差,計算各個特征向量之間的方差,通過比較16 個特征向量之間的方差大小,確定該特征對飛灰含碳量的影響程度。每個特征計算所得的方差越大,該特征量對最終的飛灰含碳量影響越大;相關系數越小,該特征量產生的影響越小。本次方差選擇法中,設定方差閾值為0.05,方差大于該閾值的特征作為飛灰含碳量的主要因素,小于該閾值方差所對應的特征為非主要因素。
本次進行方差選擇的影響因素共有28 個,表2 為方差選擇法的結果。其中,第1 列為特征量,將各特征量分別編號為1 ~28,第2 列為所求得的各特征的方差,第3 列為方差從小到大的排序,第4 列為與第3 列相對應的特征方差排序及其索引。
從排序結果來看,特征量與飛灰含碳量方差最大的是總風量,影響飛灰含碳量的主要因素有:總風量、總蒸汽量、B 側氧量、A 側氧量、氧量、負荷、二次風溫B、二次風溫A。
2.4 相關系數法
相關系數法是一種簡單的,能幫助理解特征和響應變量之間關系的方法,該方法衡量的是變量之間的線性相關性,結果的取值區間為[-1,1],-1 表示完全的負相關(這個變量下降,那個變量就會上升),+1 表示完全的正相關,0 表示沒有線性相關。
當兩個變量的標準差都不為零時,相關系數才有定義,相關系數法的適用范圍為[3]:
1)兩個變量之間是線性關系,都是連續數據。

表3 特征量及相關系數Table 3 Characteristic quantity and correlation coefficient
2)兩個變量的總體是正態分布,或接近正態的單峰分布。
3)兩個變量的觀測值是成對的,每對觀測值之間相互獨立。
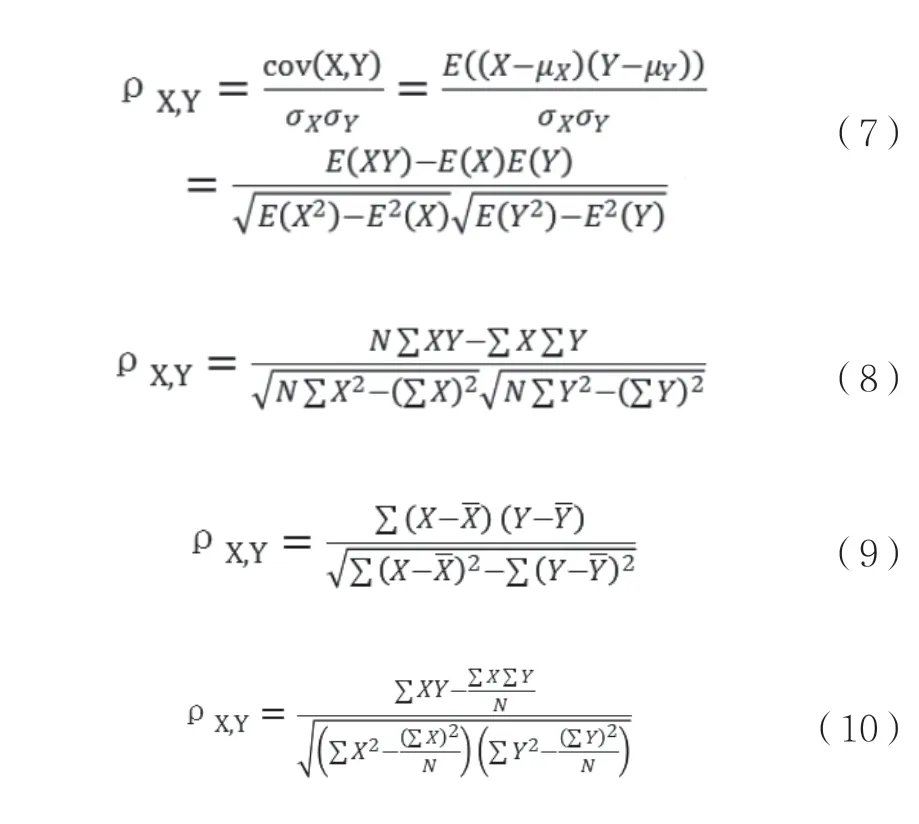
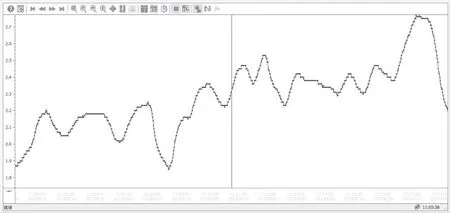
圖2 WinCC組態畫面Fig.2 WinCC configuration screen
相關系數法的4 種形式分別如式(7)~式(10)所示:表3 為相關系數法的結果。其中,第1 列為特征量,將其分別編號為1 ~28,第2 列為所求得的各特征的相關系數。
從排序結果來看,特征量與飛灰含碳量方差最大的是總風量。影響飛灰含碳量的主要因素有總風量、總蒸汽量、A 側出口溫度、B 側出口溫度、負荷、B 側氧量、A 側氧量、氧量、二次風溫B、二次風溫A。
通過函數corr,調用格式為:coeff(i) = corr(C(:,i),B(:,5));其中,矩陣C 為輸入待計算的特征值數組,矩陣B 為輸入飛灰含碳量數組,返回值為每一個特征量的相關系數。計算各個特征向量與飛灰含碳量的相關系數,通過比較28 個特征向量與飛灰含碳量之間的相關系數,確定該特征對飛灰含碳量的影響程度。相關系數越大,該特征量對最終飛灰含碳量產生的影響越大,即該特征為重要因素;相關系數越小,該特征量產生的影響越小,即該特征為影響飛灰含碳量的非重要因素。本次相關系數法選擇中,選擇相關系數大于0.8 的特征作為影響飛灰含碳量的主要因素。
本次進行相關系數法進行選擇的原始數據共有28 種,
3 結果驗證
經過特征選擇之后,得到影響鍋爐燃燒飛灰含碳量的主要因素分別為總風量、總蒸汽量、負荷、B 側氧量、A側氧量、氧量、二次風溫B、二次風溫A,并建立對應的飛灰含碳量軟測量模型,通過PLC 對運用選擇之后的主要影響因素所得的模型遠程監控。本套飛灰含碳量測量系統上位機采用WinCC 作為組態軟件,圖2 為WinCC 飛灰含碳量趨勢窗口,可以實現飛灰含碳量實時在線監測。在趨勢窗口可以看出,通過特征選擇得到的主要影響因素建立的模型具有較高的預測精度,說明特征選擇的準確性和必要性。
4 結論
本文提出基于特征的飛灰含碳量影響因素,并通過硬件形式對其準確性進行驗證。此外,基于特征選擇的影響因素并沒有選擇機理分析中的煤質和煤粉細度。一方面,該火電機組的燃燒所采用煤質和煤粉細度趨于固定,雖然對于燃燒過程有著一定的影響,但是該電廠的煤質和煤粉細度對飛灰含碳量的產生影響較小;另一方面,該火電機組DCS 系統并沒有煤質和煤粉細度的數據采集點,經過特征選擇之后沒有將煤質和煤粉細度作為主要的影響因素,因為各個電廠之間的燃燒情況不同導致因素的選擇有一定的差別。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
媽媽寶寶(2017年3期)2017-02-21 01:22:28
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
