使用計量數據和聚類算法檢測非技術損失
2020-01-05 05:37:53矯真王兆軍郭紅霞郭紅梅趙曦
計算技術與自動化 2020年4期
矯真 王兆軍 郭紅霞 郭紅梅 趙曦


摘? ?要:減少非技術損失(NTL)是實施智能電網所帶來的潛在利益的重要組成部分。提出了一種基于智能電表數據的聚類算法來檢測竊電和其他原因所導致的非技術性損失。通過對智能電表采集的數據進行聚類,提取正常用電行為的數據原型。然后對待檢測數據樣本和正常數據的聚類中心之間的距離進行計算,如果距離明顯,則將其分類為NTL數據樣本。最后對四種不同的異常用電指標進行空間分析,使分類結果更易于可視化。實驗表明,基于GA聚類算法的NTL檢測方法具有優于同類檢測方法的性能。
關鍵詞:智能電表;聚類;非技術損失
中圖分類號:TP391? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼:A
Using Measurement Data and Clustering Algorithms to Detect NTL
JIAO zhen1,WANG zhao-jun2,GUO hong-xia2,GUO hong-mei3,ZHAO xi2
(1. Wucheng Power Supply Company,State Grid Shandong Electric Power Company,Dezhou,Shandong 253300,China;
2. State Grid Shandong Electric Power Research Institute,Jinan,Shandong 250000,China;
3. Jiyang Power Supply Company,State Grid Shandong Electric Power Company,Jinan,Shandong 251400,China)
Abstract:Reducing NTL is an important part of the potential benefits of implementing a smart grid. This paper proposes a clustering algorithm based on smart meter data to detect non-technical losses caused by electricity theft and other causes.By synthesizing the data collected by the smart meter,the data prototype of the normal power usage behavior is extracted. The distance between the test data sample and the cluster center of the normal data is then calculated,and if the distance is significant,it is classified as an NTL data sample. Finally,spatial analysis of four different abnormal power consumption indicators makes the classification results easier to visualize. Experiments show that the NTL detection method based on GA clustering algorithm has better performance than similar detection methods.
Key words:smart meter;clustering;non-technical loss
電網系統的非技術損失NTL(Non-Technical Loss)等于供電量減去用電量和線損、變壓器等電力設備損耗之和。由于智能電表的日益普及,使得計量數據在用戶端和電力計量系統之間實現網絡傳輸,同時也拓寬了竊電行為的攻擊面。通過電表黑客、計量數據操縱和通信欺騙等手段所實施的錯誤數據和不良數據注入攻擊,給采用傳統手段的NTL檢測帶來挑戰。因此基于數據挖掘技術來檢測NTL勢在必行。
已有研究測試了多種基于數據分類和機器算法技術來檢測NTL,如狀態估計[1]、聚類[2]、神經網絡[3]、支持向量機(SVM)[4]和決策樹[5]。這些研究大多聚焦與通過數據挖掘來確定存在電力盜竊行為的可能,但是沒有進一步對導致NTL的來源進行深入分析[6,7]。為此,提出了一種通過對智能電表計量數據進行聚類分析來發現NTL來源的方法。首先,從采集到的電表計量數據中計算出異常用電指標。其次,對一組正常電力用戶的計量數據進行聚類分析,以發現正常用電行為的數據原型,這些數據原型代表了不同模式的正常用電行為。隨后,基于距離檢測方法將計算出的異常用電指標與正常數據原型進行對比。來自被分析電力用戶的數據與正常數據原型的距離越遠,其NTL得分越高,表明其可能為NTL數據點。最后通過實驗驗證了該方法在NTL檢測方面的良好效果。
1? ?威脅模型
所提出的威脅模型能夠檢測可能的攻擊載體和與智能電網竊電相關的主要系統漏洞。攻擊載體指的是惡意影響電力系統,使其支付的電費低于其所使用的全部用電量。只要是導致智能電表發送給數據采集系統(SCADA)的計量數據發生變化或不正常的NTL都可以使用該模型加以識別。
首先對智能電網攻擊面進行了分析。如果竊電行為、假數據攻擊或設備故障等導致的NTL出現在NTL檢測開始的第一天,則這種情況就被視為第一天NTL,否則就是非第一天NTL。考慮這種情況的原因是,在第一天NTL情況下,無法通過歷史計量數據分析實現NTL檢測,只能通過類似用戶對比來發現該NTL行為。
用戶端點所安裝的智能電表具有通信功能,能夠自動將計量數據發送到SCADA系統。智能電表的大規模部署會增加智能電網的安全漏洞,例如增加發送錯誤計量讀數的可能性。不同的NTL來源和攻擊載體如圖1所示。帶圓圈的點表示不同的可能的攻擊載體。
通過對計量數據的分析,可以檢測到NTL。所提出的處理方法導致消費模式改變或不規則的NTL類型(例如,如果消費者將用電設備連接到饋線前端則其計量數據將減少)。不同攻擊載體所導致的計量數據變化或異常的情況如表1所示。
(1)供電饋線;(2)智能電表;(3)電表通信;(4)電力用戶;(5)用戶與電力公司的關系;(6)電力公司對數據的操縱;(7)電力公司的SCADA系統
通過諸如斜率分析和基于規則的系統等簡單方法,可以檢測出導致計量數據持續減少的情況,如電表斷開或使用強磁鐵干擾電表。如果竊電手段足夠隱蔽,如發送看似合法的虛假計量數據,則使用上述數據分析手段則難以發現這些竊電行為。此外,如沒有從竊電發起的第一天開始檢測,則無法檢測到計量數據的減少或異常,只有與類似的電力用戶進行比較才能有效檢測出這些竊電行為。
對表1的NTL類型進行總結,歸納出以下8種NTL竊電類型。其中每種竊電類型都有兩個版本:第一天NTL和非第一天NTL,最終形成16種NTL類型的集合:1)隨機減少計量數據(h1和h10為零);2)在一天中的隨機時間段內(h2和h20),計量數據降至零;3)每小時隨機減少計量數據(h3和h80);4)每小時計量數據呈現隨機模式,但是平均計量數據減少(h4和h40);5)每小時計量數據恒等于平均值(h5和h50);6)反轉小時計量數據:將第1個小時與第24個小時的計量數據進行切換(h6和h60);7)計量數據從高峰時間轉移到一天中的其余時間(h7和h70);8)將消耗數據轉移到具有較低電力需求的合法用戶(h8和h80)。其中h1 ~ h8是非第一天NTL,而h10 ~ h70表示第一天NTL。
使用具有N個電力用戶的智能電表計量數據集M。mi是用戶i的電表讀數。mi的維數是n = r × nd,其中nd是天數,r是每天的電表讀數。電表讀數是以小時為單位,因此每天有24個讀數。電表讀數表示為md,ti? ?,即用戶i在第d天中第t小時的用電量。用戶i在第d天的所有電表計量讀數的向量形式為mdi = (md,1i? ? ?,md,2i? ? ?,…,md,24i? ? ? )。
為了比較用戶的相似度,使用了用戶屬性S的數據集。si是用戶i的屬性,其維數p等于屬性數。用戶屬性包括年齡、就業、家庭人數等等。
描述第d天開始的影響用戶i計量數據的8種竊電方式的數學模型如下所示。其中μ表示平均值函數。
1)h1(md,ti? ? ?) = αmd,ti? ? ?,α = random(0.1,0.8);
2)h2(md,ti? ? ?) = βh md,ti? ? ?,βt = 0,tstart < t < tend1,tstart ≥ t且t ≥ tend,
tstart = random(0,19),δ = random(4,24),tend = tstart+δ;
3)h3(mde,ti? ? ?) = γt md,ti? ? ,γt = random(0.1,0.8);
4)h4(mde,ti? ? ?) = γt? μ(mdi? ),γt = random(0.1,0.8);
5)h5(md,ti? ? ) =? ?μ(mdi? );
6)h6(md,ti? ? ) =? ?md,24-ti? ? ? ? ? ;
7)h7(md,ti? ? ) = md,ti? ? - λmd,ti? ? ,Pstart < t < Pendmd,ti? ? + ε/21,eles,是三個小時內用電量峰值的開始時間Pend = Pstart + 3,ε = ■md,pstart+ j-1i? ? ? ? ? ? ? ? ? ;
8)h8(md,ti? ? ) = md,tr? ? ,其中r為隨機消費者,符合μ(md,tr? ? ) < μ(md,ti? ? )。
2? ?異常用電指標
當檢測異常用電行為模式和當前未知的NTL威脅時,說明為什么用戶會被標記對電力公司來說非常重要。為此提出四個異常用電行為模式指標,使所提出的檢測方法更容易被理解和解釋。
第一個類型的指標是用戶個體用電量的變化。第二個類型的指標是用戶個體與其他類似用戶用電行為的比較。這兩種類型的指標分別應用于累積電力消耗數據或每小時的電力消耗,則形成四個異常用電指標。
異常用電指標是根據用戶i在某一天d的計量數據計算出來的。如果攻擊發生在第d天,則用電行為模式的變化應反映在與過去相比用電行為的變化上。如果攻擊在第d天之前就開始了,那么就應該與類似用電的用電行為相比。
所制定的四個異常用電指標表示如下:1)用電量變化指標Il表示當前用電量與過去用電量的比率;2)單位小時用電模式變化的指標I e2,I c2;3)與具有相似特征的用戶相比的用電量差異指標I3;4)與具有類似特征的用戶相比,單位小時用電模式差異的指標I e4,I c4。
用電量變化的指標I1是最近α天的用電量與最近β天的用電量之間的比率。
I1(i,d) = ■? ? (1)
每小時用電模式變化的指標I v2將一天的單位小時用電模式與前α天的平均每小時用電模式相關聯。如果ν是歐氏距離(ν = e),則絕對用電量的變化與該指標最相關。如果ν是皮爾遜相關性(ν = c),則可以檢測到動態變化。
I v2(i,d) = v(mdi? ,μ(md-1-αi? ? ? ? ?,…,md-1i? ? ? ))? ? ? (2)
I3是衡量用電量差異的指標,用于比較在用戶集合R中具有最大的相似性的用戶r(r∈R)。該指標將最近α天的平均用電量與具有最相似特征的用戶的同一天的平均用電量進行比較。電力用戶r和i之間的相似性是由v(sr,si)計算的,其中v是歐氏距離。
I3((i,d) = ■? ? (3)
與具有最大相似性的電力用戶相比,I e4和I c4是表示單位小時用電模式差異的指標。I v4表示最近α天所有用戶平均每小時用電量。
I v4(i,d)=v(μ(md-αi? ? ?,…,mdi? ),μ({(md-αr? ? ?,…,mdi? )}))
(4)
3? ?檢測方法
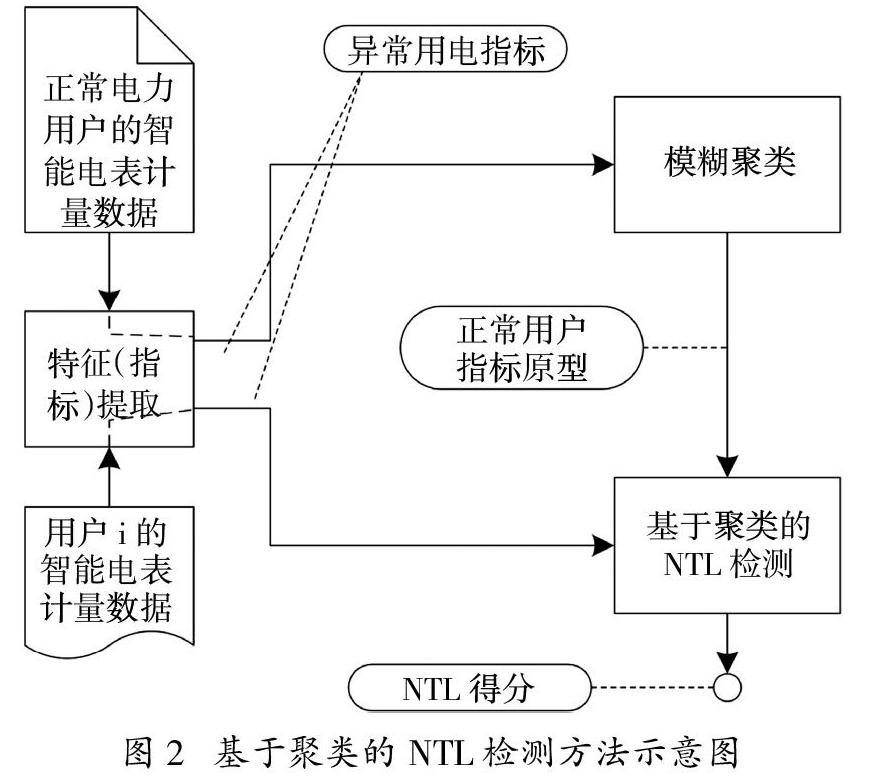
提出的NTL檢測方法如圖2所示。圖2中的特征提取用于以異常用電指標來轉換分析正常用電數據集和用戶i的用電數據樣本。將模糊聚類應用于正常的數據集,以產生表示“正常用電行為”的數據原型。基于聚類的NTL檢測算法使用式(6)推斷用戶i的NTL得分。該得分是通過比較來自用戶i數據樣本和正常用電行為原型來完成的。以下詳細說明如何基于異常用電指標,通過NTL檢測算法推斷用戶的NTL得分。
3.1? ?NTL檢測算法
NTL檢測是通過對過去用電計量數據結構和分布的學習來檢測新的計量數據樣本。所使用的正常用電數據模型來自一組正常用電數據,通過該模型能夠將輸入的數據點分類為來自“正常”和“異常”。
本研究以NTL檢測算法為框架,將從電力用戶端點采集的計量數據分類為正常和異常(即NTL的來源)。NTL檢測算法采用了一種基于距離的聚類檢測方法。在基于距離的方法中使用一個或多個正常數據的原型,如果來自電力用戶計量數據遠離原型,則會導致其NTL得分較高。
3.2? ?基于聚類的檢測
一般而言,不同的正常用電行為模式之間很大區別(例如,與退休夫婦相比,擁有全職工人的家庭在用電量、用電高峰等方面都會有較大不同)。因此需要使用聚類算法在電表計量數據集中提取不同的具有正常用電行為的數據原型。
Xid是在某一天d中與用戶i相關聯的特征向量。向量Xid = (I1,I e2,I c2,I3,I e4,I c4)由上述的8個異常用電指標組成。X∈R6是N個電力用戶的屬性數據集,由nd天的指標組成:
X=(x11,x12,…,x 1nd,x21,…,x 2nd,…,xN1,…,x Nnd)
(5)
采用模糊C聚類算法將分區X劃分為C個集群Al…Ac。分區是由分區矩陣U = {uki}所定義,其中uki表示點i的屬于集群k,稱之為隸屬度。每個聚類由原型或中心vk表示,維度等于數據點,所有中心點的集合為V。
聚類中心V代表正常用電數據,本研究對不適合任何C聚類的數據點賦予較高的NTL評分。在提出的檢測方法中,對于某個數據點i,NTL得分 y(xid | V)等于其到聚類中心的最小距離,計算公式如式(6)所示。
y(xij | V) = ■d(xij,vk)? ? ? ?(6)
y(xid | V)是第j天用戶i的NTL得分。基于該分數使用閾值ζ進行二分類,當y(xid | V) < ζ時,用戶不存在異常用電行為,為正常用戶;如果y(xid | V) ≥ ζ則表明用戶i 是NTL的來源。
該檢測方法能夠從一組從未用于提取正常用電行為原型的電力用戶中對其計量樣本進行NTL評分。聚類方法在一組正常用戶空間中提取多個正常用電行為原型,然后用于與待檢測用戶進行比較。將電力用戶的用電行為與正常用戶進行比較,而不是與其自己的過去用電數據進行比較,因此能夠檢測到第一天NTL。下面介紹模糊GK聚類算法以及用于性能對比的其他聚類算法。
1)模糊C-均值聚類算法
模糊C-均值聚類算法(FCM)可迭代地最小化點與聚類中心之間的距離之和[8,9]。距離由點到每個集群的隸屬度加權,并且模糊器參數m調整分區的“模糊性”。FCM一般使用歐氏距離作為其目標函數[10]。
J(U,V) = ■■(uij)m d2(xi,vk)? ? ? (7)
λ2(xid,vk) = (xi - vk)T I(xi - vk)? ? ?(8)
2)模糊Gustafson-Kessel聚類算法
模糊Guastafson-Kessel(GK)聚類算法使用模糊馬哈拉諾比斯距離來代替歐氏距離[11]。
λ2(Xid,νk) = (Xi - νk)⊥ ∑ -1k(Xi - νk)? ? ?(9)
∑k表示聚類的模糊協方差矩陣。這種差異性度量會導致橢圓形集群。不同的集群可以采取不同的形狀。與FCM算法相比,GK算法在可以在數據中找到的集群的形狀方面提供了更大的靈活性。模糊協方差矩陣使用下式計算:
∑k = ■? ? (10)
3)用于性能對比的其他聚類算法
將所提出的檢測方法與以下檢測方法進行性能對比:使用K均值(KM)和高斯混合模型(GMM)的檢測方法、DBSCAN聚類和支持向量機(SVM)NTL檢測方法。
KM聚類算法是FCM算法的模糊器m趨于1的一種特殊情況。GMM從訓練數據中估計出一組分布的密度。使用期望最大化算法,通過最大似然擬合不同高斯分布的參數。SVM是一種常用的機器學習方法,主要用于數據分類[12]。
DBSCAN是一種基于密度的聚類算法。該算法將聚類定義為密度相連的點的最大集合,能夠把具有足夠高密度的區域劃分為集群,并可在噪聲的空間數據庫中發現任意形狀的聚類。基于DBSCAN的NTL檢測方法將聚類中心 的集合替換為從正常計量數據集合中確定的核心點集合,于是用戶的NTL分數與其數據到最近的正常計量數據核心點的距離成反比[13]。
3.3? ?NTL分數的應用
為了將檢測方法給出的NTL分數應用于確定NTL來源,基于評估指標將得分較高用戶的用電數據與正常數據原型進行分析。使用正常電力用戶聚類的計量均值和歸一化標準差作為NTL打分指標。歸一化標準差Δ定義為:
Δl(xij | V,δ) = ■,k = argmink d(xij,vk)
(11)
式11中l表示一個異常用電指標,xij表示數據點,vlk表示正常數據原型,δlk是標準偏差來,k是最接近的聚類中心。
4? ?實驗結果
4.1? ?數據集
所使用的實驗數據來自大約四千個家庭用戶,這些數據是在一年半(2017-2018年)內收集的,是國網公司科技項目進行智能電表試驗的一部分。假設這些家庭用戶不受威脅模型中考慮的NTL來源類型的影響。采集的數據包括每30分鐘記錄一次的用電量。實驗以小時為基本單位對用電進行匯總,以方便使用本文所提出的檢測方法。
實驗在一組正常用電計量數據上訓練所提出的檢測方法,然后在另一組數據上對其進行測試。這些數據包括正常數據樣本和為每個正常數據樣本構造的16個合成NTL攻擊。實驗選擇將用于訓練和測試的用戶分開,以減少結果的偏差。實驗在每個季節隨機選擇5天的數據,按照以下步驟構造完整的實驗數據集:1)每個季度隨機抽取5個工作日;2)對于所有實驗對象用戶:生成威脅模型中由合成攻擊產生的16條曲線;計算正常攻擊和合成攻擊的異常用電指標。
對家庭用戶的年齡、社會階層、就業狀況、家庭中的成年人數量、兒童數量和家庭類型等屬性進行調查以確定用戶之間的相似性程度。本實驗只使用沒有任何計量數據或調查數據缺失的家庭,最終實驗數據集由2515名家庭組成實驗只對一半的消費者使用正常數據,對另一半使用正常和NTL攻擊的合成數據,因此實驗中的數據樣本總數為:1258×5×4+1257×17×5×4=452540。實驗數據集包括6%的陰性樣本,這是由每個正常樣本產生16個合成數據的結果。訓練數據集根據提出的無監督分類方案的要求,呈現100%陰性數據樣本的平衡。
4.2? ?參數
表2列出了用于計算的指標及其含義的參數。I1中的參數α的值為1,以表示在所考慮的威脅模型下可能發生的小的用電量變化。其余參數值范圍為:β(I v2,I3),α(I v2,I v4)∈[1,5,10,15],τ∈[5,10,15,20]。找到的最佳配置是兩組參數都等于10,這意味著將當前用電量與過去兩周的用電量進行比較,并使用十個最接近的用電量進行比較。
通過對訓練集和測試集中的數據進行隨機劃分,對所提出的方法和用于對比的不同技術進行了性能評估。訓練集用于聚類和推導支持向量機模型,該模型由一組隨機選擇的用戶(占用戶總數的50%)的正常數據樣本組成。其余用戶(50%)用于性能評估。測試集呈現6%的負樣本(來自正常用戶),訓練集呈現100%的非監督分類所需的負樣本。使用以下評價指標:1)真陽性率(TPR):被識別為攻擊的樣本數除以所有攻擊樣本數;2)假陽性率(FPR):錯誤識別為攻擊的樣本數除以良性樣本數;3)ROC曲線下方的面積(AUC):該曲線表示檢測算法在TPR和FPR范圍內的閾值。該指標對不平衡數據具有很強的適應性。
為了確定第4節所述方法和技術的最佳參數,使用AUC作為評價指標進行了參數搜索。參數搜索從值的集合中測試所有可能的參數組合:集群數量的取值范圍在2到36之間,模糊參數m的取值范圍為[0.5,0.6,…,1.9,2],v的取值范圍為[0.1,0.2,…,0.9,1],γ的取值范圍為[0.5,0.6,…,1.4,1.5],eps的取值范圍為[0.5,1,3,6,12,24],mins的取值范圍為[25,50,100,200,400,800]。表3列出了最終選擇的算法參數。
4.3? ?結果與討論
設置所有第一天和非第一天NTL、只有非第一天NTL和只有第一天NTL三種實驗方案,對六種檢測算法進行對比實驗的結果如表4所示。
對表4的數據進行分析可知,在所有聚類算法中,GK的性能明顯優于其他算法,而FCM和GMM的性能非常相似。對于非第一天攻擊,FCM的性能最好,GK和KM稍差。對于第一天攻擊,GK和GMM的性能類型。總體上GK聚類的整體性能較好。
在數據不平衡的情況下,僅有聚類準確度一個度量指標是不夠的。例如,如果一個數據集包含95%的陰性類數據樣本,而模型將所有樣本都歸為陰性,那么準確度仍然是95%。實際中用于檢測NTL的數據集是不平衡的,即NTL數據樣本只占少數。為此重新構造一個平衡的實驗數據集(正常數據和異常數據之比為2:1),并基于該數據集對上述集中聚類檢測方法進行重新測試。基于AUC指標的實驗結果如圖3所示。
在平衡數據集中所有算法的聚類數量統一為2(C=2)。由圖4可知,除了GK算法,其他算法在平衡數據集中采用兩個集群數量的測試結果都較差。這說明GK算法在數據集和聚類數量兩個方面都具有較好的適應性。
4.4? ?應用測試
對所提出的檢測方法進行應用測試。隨機選擇一個正常計量數據樣本和一個h1類型的NTL計量數據樣本。采用本檢測技術給出的分數如圖5所示。如果樣本被歸類為NTL,則條形圖為紅色;如果樣本被歸類為正常,則條形圖為藍色。如果分類正確,沒有NTL的數據樣本應該是淺色的,NTL數據樣本應該是深色的。
(a)異常用電指標
(b)從樣本到最近的聚類中心的指標值
(指標值越小表明數據越接近聚類中心)
正常樣本的NSTD測試結果如圖5所示。數據樣本的指標值和平均值如圖5a所示。正常數據樣本接近大多數指標的平均值。其中I e2和I e4的值較低,因為這兩個指標值代表了用戶與過去和類似用戶的用電差距。使用四種聚類檢測方法所得出的到最近的聚類中心偏差的NSTD如圖5b所示。除了I e2和I e4之外,GK聚類算法的指標值靠近聚類中心,這表明所使用的GK聚類技術能夠更好地捕獲正常計量數據集的形狀。
h1類型NTL數據樣本的NSTD測試結果如圖6所示。與正常樣本的平均值相比,圖6a的I1和I3的值異常低,表明與過去和類似用戶相比,用電量值顯著減少。圖6b表明,I1是NTL數據樣本與最近中心之間距離增加的主要原因。
(a)異常用電指標
(b)從樣本到最近的聚類中心的指標值
(指標值越小表明數據越接近聚類中心)
5? ?結? ?論
提出了一種檢測智能電網中NTL的聚類檢測方法。該方法通過對從智能電表收集的高分辨率計量數據進行聚類分析,得出NTL來源等的有效消息。該方法使用異常用電指標以減少數據的維數,并有助于實現檢測結果的可視化。實驗中使用了兩千多個家庭的真實電表計量數據,涵蓋了正常計量數據的多種可能的復雜變化。實驗結果表明,該方法實現了高達0.741 AUC的性能,63.6%的真實陽性率和24.3%的假陽性率,優于同類研究中提出檢測算法。下一步,將致力于把該方法應用于大數據和高性能計算框架中,以實現分析電網不同層級的損耗。
參考文獻
[1]? ? 李植鵬,侯惠勇,蔣嗣凡,等. 基于人工神經網絡的線損計算及竊電分析[J]. 南方電網技術,2019,13(02):7-12.
[2]? ? 李梓欣,李川,李英娜. 用電特征指標降維與極限學習機算法的竊電檢測[J]. 計算機應用與軟件,2018,35(12):179-186.
[3]? ? 吳迪,王學偉,竇健,等. 基于大數據的防竊電模型與方法[J]. 北京化工大學學報(自然科學版),2018,45(06):79-86.
[4]? ? 李寧,尹小明,丁學峰,等. 一種融合聚類和異常點檢測算法的竊電辨識方法[J]. 電測與儀表,2018,55(21):19-24.
[5]? ? 竇健,劉宣,盧繼哲,等. 基于用電信息采集大數據的防竊電方法研究[J]. 電測與儀表,2018,55(21):43-49.
[6]? ? 曹敏,鄒京希,魏齡,等. 基于RBF神經網絡的配電網竊電行為檢測[J]. 云南大學學報(自然科學版),2018,40(05):872-878.
[7]? ? 史玉良,榮以平,朱偉義. 基于用電特征分析的竊電行為識別方法[J]. 計算機研究與發展,2018,55(08):1599-1608.
[8]? ? 王慶寧,張東輝,孫香德,等. 基于GA-BP神經網絡的反竊電系統研究與應用[J]. 電測與儀表,2018,55(11):35-40.
[9]? ? 鄧明斌,徐志淼,鄧志飛,等. 基于多特征融合的竊電識別算法研究[J]. 計算機與數字工程,2017,45(12):2398-2401.
[10]? 康寧寧,李川,曾虎,等. 采用FCM聚類與改進SVR模型的竊電行為檢測[J]. 電子測量與儀器學報,2017,31(12):2023-2029.
[11]? 劉盛,朱翠艷. 應用數據挖掘技術構建反竊電管理系統的研究[J]. 中國電力,2017,50(10):181-184.
[12]? 陳文瑛,陳雁,邱林,等. 應用大數據技術的反竊電分析[J]. 電子測量與儀器學報,2016,30(10):1558-1567.
[13]? 趙磊,欒文鵬,王倩. 應用AMI數據的低壓配電網精確線損分析[J]. 電網技術,2015,39(11):3189-3194.
