基于特征模型和遺傳算法的測試用例自動生成?
2019-12-27 06:32:30江志強王金波王曉華
計算機與數字工程 2019年12期
江志強 王金波 王曉華
(中國科學院空間應用工程與技術中心 北京 100094)
1 引言
測試是軟件開發的關鍵一環,測試用例生成是測試過程的重要環節。測試用例是否有效、快速地生成,影響了整個測試的效率[1]。一個好的測試用例集,能以較低的測試開銷保障較高的測試性能[2]。現有常見的測試用例生成方法有基于UML模型[3],向量機[4]等方法。它們注重測試性能的同時并不能有效減小測試開銷。因此,本文選用了特征模型。特征模型作為一種功能性的模型,可對功能模塊實現高可復用性,從而有效降低測試開銷。
當前,特征模型的應用主要運用于產品線領域的測試開發。它使用特征表征功能,同一產品線中不同的產品以不同的特征組合方式表達,而每個特征又通過UML等模型方法建立測試用例[5]。因此,這些產品的測試用例,是通過復用這些選擇特征的測試用例進行組合得到。與之相比,本文對被測產品進行特征建模,并將特征與被測件輸入關聯,不需要將特征與其他模型相結合。由于使用組合測試策略能夠進一步提高復用率[6],因此本文采用組合策略對特征模型進行選擇,得到較優的測試用例集。
2 特征模型基本概念
特征模型[7]是在產品線分析的領域分析中誕生的,通常被視為一個產品與其它產品不同的地方,它關注的是產品系列中的需求和功能,并且通過需求分析構建產品。
特征模型被視作一個四元組[8]:(F,?,λ,Φ)。其中F代表一組有限的特征節點,?代表各特征節點的關系,通常是以樹狀圖的形式體現,λ代表了特征的四類分配規則,分別是必選特征mandato?ry和三類非必須的特征:可選擇特征optional,多選一特征alternative,和至少選取一個的特征or規則。Φ則代表了特征節點集合中可能的約束,通常包括兩類約束條件:其一是依賴性約束require,也就是某個特征的存在必須以另一個特征存在為前提;其二是互斥性約束exclude,也就是兩者不能同時出現在同一個產品中。
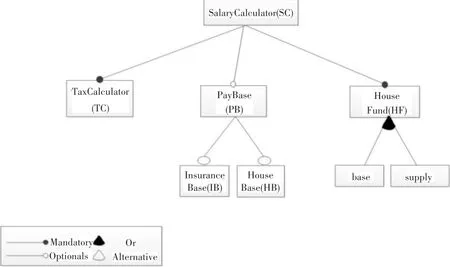
圖1 工資計算器的特征模型
本文用于說明的實例是一個網頁應用工資計算器 SalaryCalculator(SC)[9]。它的特征模型如圖 1所示。其中,根特征SC有三個功能,對應三個特征:分別是稅率計算TaxCalculator(TC),繳納基數PayBase(PB)和住房公積金計算 HouseFund(HF)。其中,PB特征含有兩個不同的特征:保險基數InsuranceBase(IB)和公積金基數HouseBase(HB)。它們都是optional規則特征。而HF下有兩個滿足or規則的特征:代表基本公積金的Base和補充公積金的Supply。
3 模型構建
3.1 模型細化
圖1中特征都對應了被測軟件的一個功能模塊。相對于傳統的特征模型,對每個特征不再建立諸如UML等對應的實體關系模型。而是將特征繼續細化,對應測試的輸入值,建立子特征。
特征與輸入之間存在相互映射的關系。對特征的測試是通過一組輸入得到相應的反饋,根據反饋結果檢查特征對應的功能是否符合預期[10],因此特征與輸入就存在相互影響。這種關系通常都不是一對一的關系。子特征則是特征的一部分,指該功能在部分輸入下得到相同反饋或者同一性質的反饋的部分功能。根據特征與輸入的關系,子特征的建立按如下方式進行。
第一,如果一個特征中受多個輸入影響,則每一個輸入都作為該特征的一個子特征。這些子特征會根據特征分配規則,被賦予四類分配規則的中的一種。
第二,如果一個輸入影響多個特征,該輸入受到特征組合的影響,其生成通過后文特征組合實現。
第三,當特征或子特征中只含有一個輸入且反之亦然時,此時分為兩類情況:
第1類:布爾型特征:該特征是一個布爾型變量。具體表現為此輸入只會對特征對應的子功能產生兩種互斥的狀態。例如開關的開啟和關閉;該特征自身就是其子特征。在特征選擇中,選擇與不選擇兩個狀態分別對應其互斥的兩個結果,并根據其選擇狀態表征其測試輸入值。
如圖1中的Base,Supply特征,它們各自都只有一個輸入,表現為選項框,因此只有選擇和非選擇兩個輸入狀態表示該功能是否激活。而IB和HB,它們也是選項框輸入,選擇與非選擇分別代表該特征輸入值為系統設置的默認值或最小值兩個狀態。這四個特征符合布爾型特征。
第2類:非布爾型特征:該特征與第一類不同,隨著其對應輸入值的變化,子功能反饋兩種以上的結果。因此,該特征可以視作以分段函數,輸入值變化區間是該分段函數的定義域,可以劃分為多個子區間,不同輸入區間對應分段函數的不同的子函數,每個子函數都可被視作一個子特征。這些子特征之間是互斥的,對應了特征模型中的Alternative特征。在測試用例中,該類子特征可以使用邊界值或者等價類直接表示。在特征選擇中,被選中的子特征的值作為其父節點的值輸出,沒有被選擇的其他子特征的值被舍棄。
例如圖1中的TC特征,它的輸入是一個數值,隨著數值的變化,對應的計算稅率的函數會發生變化,因此符合非布爾型特征,可以按照測試文檔說明按稅率變化分為圖2中TC下的8個子特征,分別是無稅率noTax,第一等稅率Tax_1,直到第七等Tax_7。這些子特征按照非布爾型特征規則,應該滿足optional規則。
將特征模型通過樹形圖表示,在細分子特征之后,每個葉子節點都對應一個值。而通過選取葉子節點,就可以得到一個特征組合并形成測試用例[11]。因此在實際運用中,只選取所有的葉子節點作為全部特征列表。為了描述測試用例生成,首先有以下定義:

圖2 建立子特征的測試特征模型
定義1:特征模型中所有的葉節點特征構成的集合被稱為特征列表(Feature List,FL)。
如圖1中,所有葉子節點構成的集合{noTax,Tax_1,Tax_2,Tax_3,Tax_4,Tax_5,Tax_6,Tax_7,HB,IB,base,supply}就是一個特征列表FL。
定義2:特征配置(FeatureConfigure,fc)是一組滿足特征模型規范和約束的特征組合,定義為fc={sel,},其中 sel?FL,sel代表該選定的特征,而都是未選定的特征,它們都是FL的子集,
如圖2中,存在一特征配置fc1={{Tax_1,IB,base},{noTax,Tax_2,Tax_3,Tax_4,Tax_5,Tax_6,Tax_7,HB,supply}},其中 fc1.sel={Tax_1,IB,base},代表了特征 Tax_1,IB 和 base被選取,={noTax,Tax_2,Tax_3,Tax_4,Tax_5,Tax_6,Tax_7,HB,supply},代表這些特征未被選擇。因為所有的葉子節點都對應一個值,它們根據選取或未選取的狀態返回相應的值,或者舍棄該子特征,返回值會根據特征和輸入的相互關系反向獲得測試用例的輸入,并根據測試需求得到預期結果,組成測試用例[12]。因此一個特征組合就能對應一個測試用例。
定義3:特征配置fc構成的集合被稱為特征配置集(Feature Configure Set)FCS。其中,特征列表FL中滿足特征模型規范和約束的全部特征配置構成的集合被稱為完全特征配置覆蓋集。
完全特征配置覆蓋集代表了該被測件所有可能的特征配置形式,即全部的測試路徑。但一般來說這是一個較大的值。例如圖2中,12個葉節點就構成了96個特征配置。
3.2 組合測試
完全特征配置覆蓋通常意味著龐大的測試用例集和大量測試開銷。而好的測試用例集,是選取一個較小的特征配置集合,實現特征覆蓋。測試用例的生成就轉化為了特征選取的問題。本文采用組合測試策略解決該問題[13],并通過遺傳算法實現。研究表明,在特征模型中,采用組合測試的方式能夠實現更小的組合配置,并且有更好的檢錯能力以保障其測試性能[14]。
本文在特征模型中采用二元組合策略實現特征配置,相關定義如下:
定義4:二元組合配置是一個二元組c,定義為的特征和非選擇的特征,并且有
相對于一般特征模型只覆蓋全部特征的方法,二元組合的特征配置集合需要對RC進行完全覆蓋。由前文可知,測試用例對應的一個特征組合。目標測試用例集所滿足的特征配置集應該實現對RC全覆蓋。這樣的特征配置集合被稱為結果集合(Result Set,RS)。為了定義RS,首先引入定義5。
因此結果集合RS如下定義:
定義6:存在一個特征配置集合CFS={fc1,fc2,… fcm},其中 ?fci∈CFS,fci的二元覆蓋集合為cfci,對所有 fsi∈CFS,使二元組合覆蓋集RC=該 CFS被稱為結果集合(Result Set,RS)。其中,在所有的RS中,m最小的RS是最優的結果集合。
因此測試用例的生成就從組合特征和選取特征轉化為尋找最優的RS,也就是尋找一個足夠小的特征配置集合,使得其能夠實現對RC的完全覆蓋。
4 算法描述
一般來說,組合測試覆蓋問題是一個NP難問題,常見的解法有貪心算法和啟發式算法[15]。前者雖然運算速度快,但是作為一種近似算法,貪心算法只是近似解。而以遺傳算法為代表的啟發式算法相對于貪心算法可以跳出局部最優陷阱,能夠得到更好的近似解。因此文本采取了遺傳算法[16]實現組合測試策略。計算流程如圖3所示。
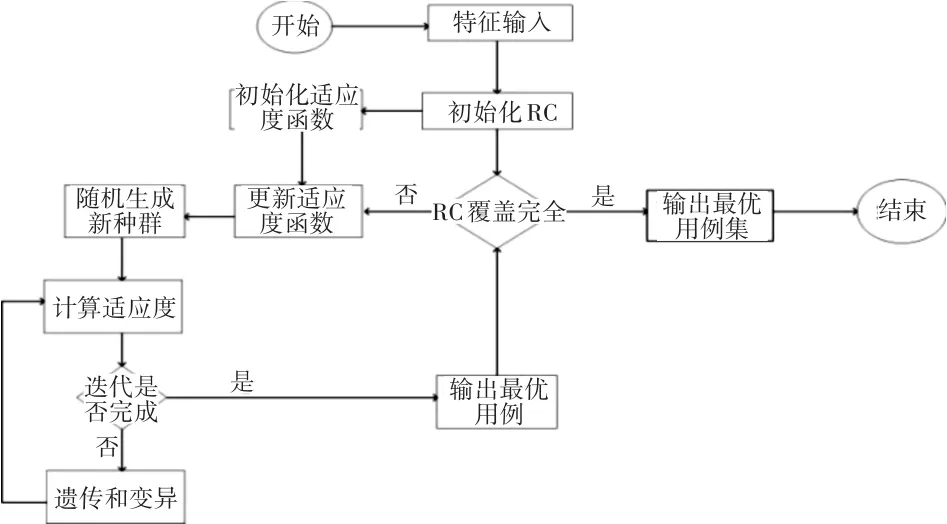
圖3 基于組合測試的遺傳算法框架
在初始化RC之后,開始對組合測試進行遺傳算法運算。每一次遺傳算法初始種群都采用隨機選擇產生。并不斷調整適應度函數尋找最優解。本文中適應度函數主要有兩部分構成。
第一項:判斷個體是否符合特征模型規則。所有不符合特征需求的個體都會被淘汰,在遺傳中被遺棄;
第二項:判斷個體對當前RC的覆蓋情況。RC的覆蓋率再每一次輸出一個最優用例的后都收到一個反饋,對當前的RC進行修正。其中每個個體的RC覆蓋率RCcover計算如下:
其中,RCcover代表RC覆蓋率值。此外,三個覆蓋集合被定義,分別是所有的二元組合覆蓋集AllCover,已經被覆蓋的集合RubCover,有效地覆蓋集合 VaildCover;其中 AllCover=RubCover∪ Vaild?Cover;RubCover∩ VaildCover=? ;每個個體所包含的二元組合覆蓋定義為ChroCover;
根據上述定義,式(1)被修改為
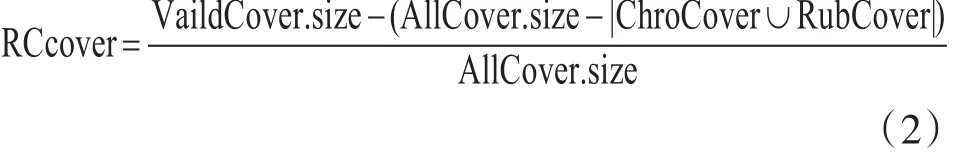
每個個體的適應度函數通過上面兩個項確定,因此,在每進行一次遺傳算法后,選取一個適應度最高的個體,該個體是一個特征配置fc,它是當前種群中擁有最高RC覆蓋率的個體。將其保存在結果集合RS中,并且從RC中刪去該最優解所覆蓋的二元組合。經過多次運算,當RC變為空集的時候,意味著RC已經被完全覆蓋,此時得到的RS就是實現了對RC的完全覆蓋的用例集,是通過遺傳算法求得的最優解。
在運算結束以后,最終得到的一個輸出結果是一個由特征配置fc構成的集合FC,FC的所有元素都是相互獨立且不相關的。根據前文中在子特征分解中所述,對每一個特征組合,都可按照其對應的功能關系和特征模型關系反向得到相應的被測軟件輸入數據以及期望結果,該輸入數據和期望結果構成測試用例,進而獲得所需要的測試用例集。
5 實驗驗證
為應用本文中提出的測試用例自動生成的設計方法,本文對三個被測系統進行了運用,其中第一個被測件SalaryCalculator是前文特征模型圖建立的被測系統,該系統是一個運算模塊,它擁有一個數字輸入和四個參數調節項,包含12個特征;第二個被測件Blog[17]是另一個有一個輸入項和多個可選擇組合的被測項目,包含18個特征;第三個被測件WebLogin[18]是一個有兩個輸入項和多個可選組合的被側項目,包含25個特征。三個被測件都被注入了10個錯誤。
由于遺傳算法在產生初代種群的時候采取的是隨機生成,因此我們對每個被測件進行10次運算,將其反映在表1中。
表1中,pp是該測試用例覆蓋全部測試用例的比例,全部測試用例數量是窮舉所有滿足特征模型的特征配置得到。其中,SalaryCalculator被測件一共有96個測試用例,Blog被測件有55520個測試用例,WedLogin被測件包含451584個測試用例。從表1中可得,三個被測件均以較小的開銷實現二元組合的覆蓋,而且錯誤的驗證率都在70%以上,尤其是后兩項產品,它們相對于第一個被測軟件,全路徑分支的測試用例數更大,但是生成的最小用例集合更小,而且保持了較高的錯誤檢測率,分別有87.8%和94.4%。因此,可以驗證得到,本文提出的測試用例自動生成方法能夠大幅度降低了測試開銷,也可以保持一個高效的錯誤檢測率。
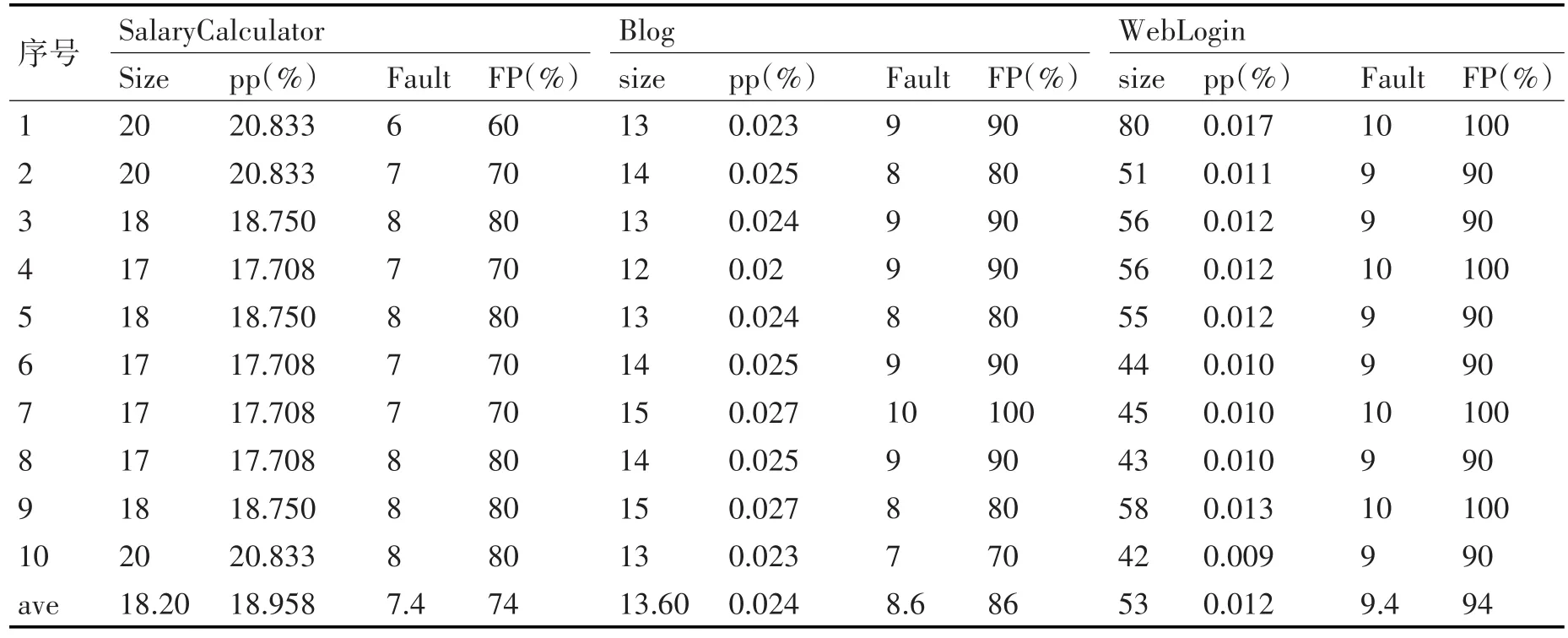
表1 被測系統測試用例生成表
Size為生成的測試用例集大小;pp為測試用例集對全部測試用例的比例。
Fault為發現的錯誤;FP:檢查錯誤的百分比=發現的錯誤/注入的總錯誤。
6 結語
本文提出的基于特征模型的組合測試用例自動生成,結合了當前特征模型測試和組合測試方法的優勢,是一種模型簡易易用,可靠性強的測試方法。該方法繼承了特征模型的分析方法,并在此基礎上將特征層次深入到測試數據輸入;組合測試和特征模型的結合進一步優化測試空間。在實驗中,也驗證了該方法能有效降低測試開銷,保障測試性能,生成良好的測試用例集。
但是遺傳算法隨著迭代次數的增加,在后期容易出現收斂速度下降的問題,延長了測試用例生成的時間。當前在已經有很多學者對加快遺傳算法收斂速度進行了研究[17],在未來的工作中,可以考慮這些算法改進策略,優化測試用例生成速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
山東青年(2016年1期)2016-02-28 14:25:25
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2014年3期)2014-01-21 02:30:44
