作戰目標數據質量評價體系和模型構建?
2019-12-26 11:33:06賀文紅
艦船電子工程 2019年12期
賀文紅
(海軍裝備部 北京 100071)
1 引言
作戰數據質量評價是作戰數據工程建設與實踐應用的重要組成部分。隨著我海軍戰略從近海防御向遠海防衛跨越式的調整,在軍事作戰和演習過程中,作戰海域范圍將明顯擴展,作戰環境更為復雜,海戰場的作戰面積廣闊,敵我雙方的作戰單位分布稀疏,交戰距離多發生在視距外,同時還存在需要使用聲吶進行探測的水下戰場。因此海戰場上的作戰單位自身不僅需要具備探測目標的能力,還需要具備自主計算分析和超視距協同作戰的能力。復雜戰場環境下,各種干擾層出不窮,如有源電子干擾、反輻射導彈、隱身與反隱身技術等等,此外,大量的背景噪聲和測量誤差的存在,使得測量系統獲取的目標數據帶有大量的模糊性和不確定性,為構建目標特性數據庫以及目標特性數據庫的數據質量帶來嚴峻的考驗[1,4]。
2 作戰數據評價體系建設需求
2.1 預警探測目標識別精準化需要
未來信息化戰爭中,對前端探測設備探測目標的精準需求越來越突出,而作為支撐目標識別的探測目標特性數據庫建設顯得尤為重要。海戰場環境復雜而多變,僅僅依靠當前實時探測信息已無法滿足作戰需求,通過目標特性數據庫進行匹配分析識別,其識別結果的可信度依賴于目標特性數據庫的數據質量。
2.2 多源異構情報數據綜合識別能力需要
依據海戰場目標來源的特點將目標特征數據分為三類,分別包括探測獲取數據、計算獲取數據、情報獲取數據。探測獲取數據主要包括雷達、聲吶、紅外、電子戰、衛星目標等需要通過傳感器設備探測獲取的目標數據,主要包括目標的運動特征數據,聲光電特征數據;計算獲取數據主要包括作戰系統、傳感器系統根據自身接收到的探測數據、導航信息以及其他作戰信息計算出的數據,主要包括目標數據,電子對抗特征數據、輻射特征信息、歷史航跡軌跡信息等信息;情報獲取數據主要包括其他作戰節點、岸基指揮所通過數據鏈通過指揮文電發送的目標動向信息、敵情信息。
2.3 目標特性數據庫形成有效產品需要
目標特性數據庫的建設和管理對目前我軍提升現有裝備作戰效能有著非常重要的作用。為了保障目標特性數據庫的發布和共享,支撐目標特性工程建設任務,需要提出一套權威可行的目標特性數據質量評價體系作為目標特性數據庫的信息數據質量評價的原則、準則、流程、指標和方法,最終形成支撐數據產品的生產和評估[1]。
3 美軍作戰數據質量評價體系現狀分析
美國等西方海軍強國,長期高度重視數據庫及其數據質量建設,各國對非合作目標特性的獲取和研究都非常重視,特別是美、俄等軍事強國,起步早,投入大。如蘇聯早在20世紀50年代專門研制用于偵測非合作目標物理場特性的測量裝置,布放于一定的水域,記錄大量的非合作目標物理場數據,美國經常在海上投放浮標或建造測量船,偵察非合作目標特性數據,正是對于非合作目標的充分了解,美國對一些國家的潛艇能做到單個識別,英國某型水雷經過精心的引信設計專攻特定目標。在數據庫建設方面,美軍為了建立數據共享基礎設施,國防部早在20世紀90年代就啟動了數據工程,創建了國防數據詞典系統(DDDS)、數據共享環境(SHADE)和聯合公共數據庫(JCDB),為美軍在C4I系統之間實現數據重用和數據共享奠定了基礎。聯合公共數據庫是多個數據庫的公共部分,綜合了國防情報局(DIA)軍事情報數據庫(MIDB)中有關敵軍的信息以及海、空軍數據庫中有關聯合作戰的部分信息。該數據庫是用于支持三軍共享的基礎數據庫。此外,在聯合公共數據庫的體系結構下,美國每年都投入大量經費建設業務數據庫。目前已在世界各大洋及中國周邊海域建立了海洋環境立體監測系統,搜集、調查海洋環境參數,開展海洋環境特性方面的研究工作,已具備全球和局部海域的多尺度、多要素業務化保障能力,并建立了相當規模的數據庫系統。如海洋學和氣象學數據庫(OAML)、聲學數據庫、美國國家氣象資料中心(NCDC)海洋氣候數據庫、艦隊任務規劃地球物理數據庫系統(GFMPL)等。依托上述數據庫建設,采用多種(類)技術、手段和裝備來增強艦艇編隊的目標識別能力,海灣戰爭結束后,美國專門成立了聯合目標識別計劃辦公室,組織和指導建立以信息融合為核心的C4I系統。已裝備的識別系統達百余種,如非合作性目標識別(NCTR)、多傳感器目標識別系統(MUSTRS)、作戰識別(CID)、聯合戰斗識別(CCID)等。其他西方國家也研制出一批具有代表性的系統,如英國的飛機敵我識別系統(ZFFF)、歐洲的BETA系統(戰場維護與目標探測系統)等[1,3]。
4 作戰數據質量評價體系和模型構建
4.1 作戰數據質量評價體系構建
由于作戰數據來源于不同系統間作戰數據的有效集成,各子系統在數據存儲、傳輸與集成過程中,必須符合某種評估指標,形成統一標準,再經過數據清洗剔除無關數據或壞數據,確保作戰數據的有效性與可靠性。靜態作戰數據質量主要是作戰數據質量本身所固有的、本征指標,即上述所提到的評估標;而動態作戰數據質量主要是從作戰數據的整個生命周期來展開研究的,是作戰數據在實際應用中數據質量的價值體現,包括作戰數據的采集、傳輸、存儲、處理、集成、使用和開發質量,每一個環節的質量高低都直接關系著整個作戰數據質量的好壞,都會直接或間接的影響著整個作戰的結果[2]。作戰數據質量評估指標體系如圖1所示。
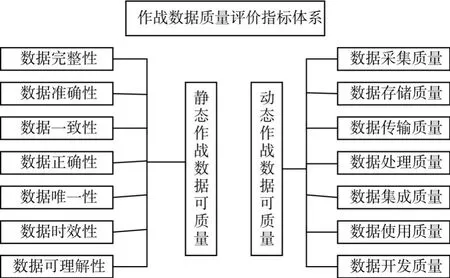
圖1 作戰數據質量評價指標體系
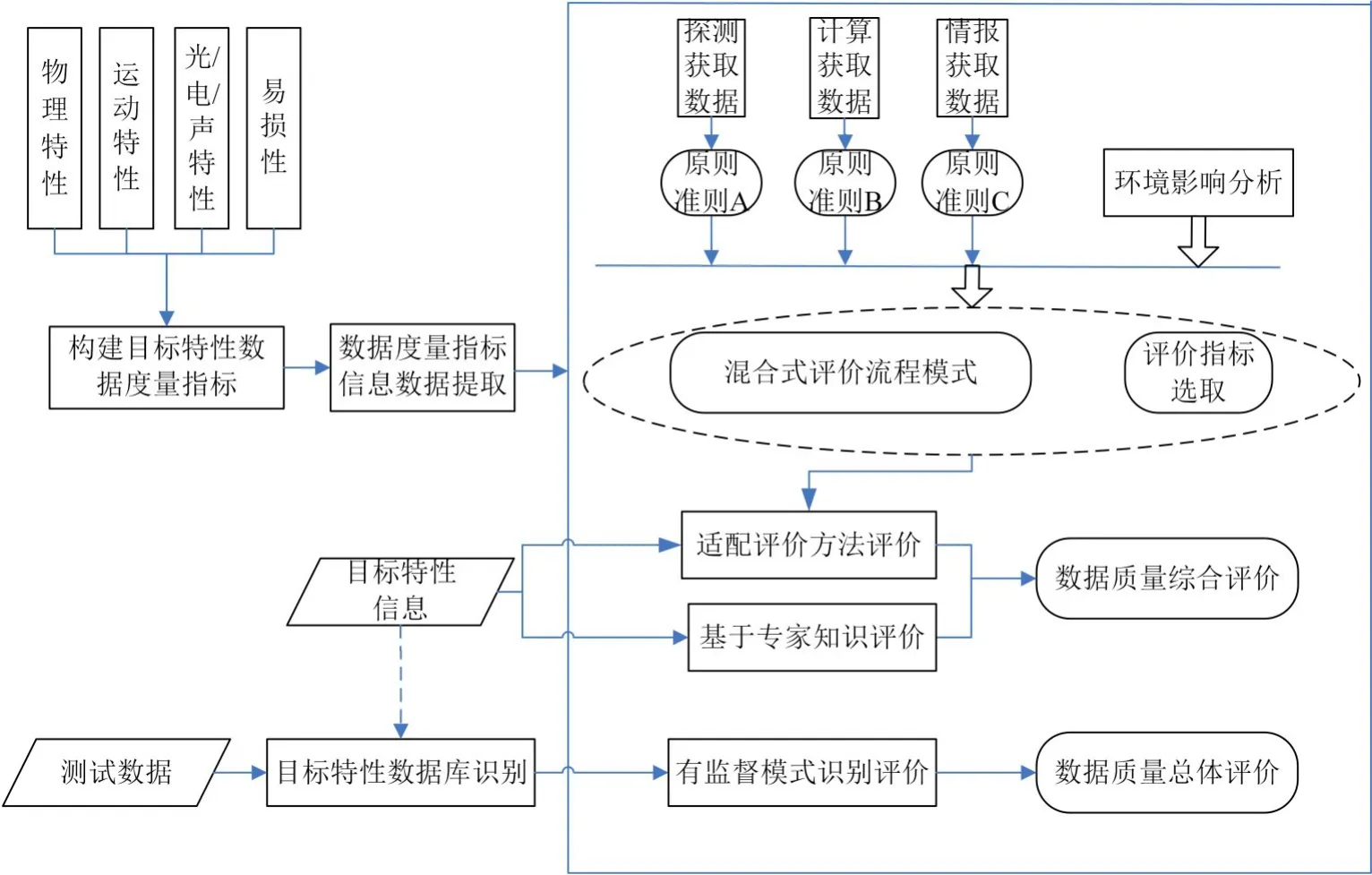
圖2 作戰目標數據質量評價體系總體框架圖
在數據質量評價體系方面,以美國麻省理工學院、美國國防部為代表的研究機構,建立數據質量評價和管理的綜合數據質量管理體系(TDQM),以及數據質量管理成熟度模型。TDQM是以“計劃-執行-檢查-處理”(PDCA)管理過程4階段循環方式為基礎,其主要特點是專注于數據質量的目標達成和過程控制[3,6]。
4.2 評價體系總體方案
依據目前數據質量評價的基礎研究,結合目標特性的特點,采用“面向場景動態評價、面向對象個性定制”的設計思想,從數據質量問題的產生環節著手,建立全過程評價指標。根據評價結果,推動目標特性數據庫的建設管理;依據數據清洗,推動前端數據產品的生產為目標綜合識別和武器打擊提供信息保障需求[6,9]。
結合目標識別和武器打擊的軍事要求,對目標特性數據信息要素進行提取獲得物理特性、運動特性、光/電/聲特性、易損性等度量指標;針對探測數據、計算數據、情報數據制定不同的原則和準則。在此基礎上,結合目標特性要素,構成混合式的評價流程模式;同時分析外部環境對目標特性數據的影響,選取適應的評價指標。
依據前期分析目標特性的原則/準則/流程/指標,依托大數據平臺,對提取的目標特性要素數據進行評價方法適配并進行評價;同時結合專家知識庫的評價,形成目標特性數據庫信息的綜合評價。
最后通過目標特征數據產品庫對各類目標的識別程度,進行數據質量的總體評價,促進目標特征數據產品庫的建設完善及后續產品發布。
通過建立目標特性數據信息的數據質量綜合評價和總體評價構成對目標特性數據的數據質量評價全要素全過程覆蓋。
4.3 作戰目標數據質量評價流程
數據質量評價流程,實際是針對數據質量問題的生成過程進行評價。
為了實現保證全面數據質量分析,多層次評估數據質量性質,我們提出了如圖2所示的混合型數據質量評估分析模型。
通過這種多層次的多維度指標的評估準則,可以建立完善的針對不同場景的目標特性數據質量的數據質量評估流程模型。
數據質量問題包括單數據源和多數據源。單數據源分析更多處理單個數據集合的數據質量分析問題,多數據源分析問題滿足本項目要求的數據多樣化融合的要求。
4.3.1 單一數據(源)的評價流程
單一數據(源)的評價流程研究主要是針對單一數據或單一數據源本身的評價流程進行分析,建立不同類別的評價流程模式,構筑整體目標特性數據質量評價流程的基石。
4.3.2 多數據(源)的評價流程
多數據(源)的評價流程研究主要是針對數據與數據之間以及不同來源數據之間的評價流程進行分析,建立綜合評價流程模型,形成目標特性數據質量評價流程范式。
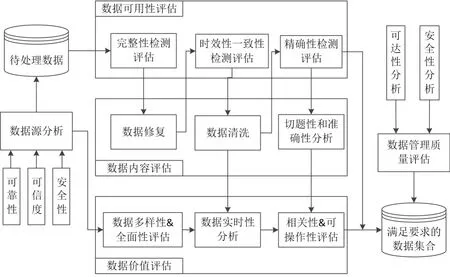
圖3 作戰數據質量評估流程圖
4.4 作戰數據質量評價模型構建
4.4.1 基于矩陣式的目標特性數據質量評價指標模型
作戰目標數據質量可以從數據源質量、數據可用性、數據內容、數據管理、數據價值等幾個維度指標上進行質量的評估。考慮到在不同場景、不同類型的目標特性數據存在著較為明顯的差異,因此需要研究出一套基于多維度指標的矩陣式的目標特性數據質量評價指標模型。該模型可以完成對目標特性數據質量的指標確定,提供權威的數據質量評價結果支撐[4~5]。
考慮到在不同場景、不同類型的目標特性數據存在著較為明顯的差異,對于數據質量評價也隨之不同。因此需要研究出一套針對這類特點的評價指標模型,稱之為基于矩陣式的目標特性數據質量評價指標模型。該模型可以完成對目標特性數據質量的指標確定,提供權威的數據質量評價結果支撐。模型示意如下:

Ak表示某類目標的評價指標集,aij表示在i項條件下,第j項指標的是否可用。
4.4.2 基于有監督模式識別的數據質量總體評價模型
數據質量是“滿足應用需求的程度”,目標特性數據庫的建立主要是用于目標識別,因此需要針對經過目標特征原始數據庫信息篩選而獲得的目標特征產品數據庫的數據質量進行總體性評價,通過某類個體的目標特征信息在目標特征產品數據庫識別后得到識別結果的程度,對整個數據庫的數據質量整體進行評價研究。先用一組已知類別的化合物作為訓練集,建立判別模型,再用建立的模型根據相似性原則來對未知樣本進行識別,稱為判別分析。判別分析是在事先知道類別特征的情況下建立判別模型對樣本進行識別歸屬,是一種有監督模式識別。
目標特征數據庫中一共有n個個體實例,可以表示為S={D1,D2,…,Dn},其中Di為每一個個體實例,該對象中一共有mi個特征,可以表示為Ci={<K1,V1>,<K2,V2>,…,<Kmi,Vmi>}。
其中,K表示該特征的屬性,V表示該特征的值,由于獲取信息存在不全面,每個個體的mi可能是不一樣的。
BP神經網絡是一種基于有監督的學習,使用非線性可導函數作為傳遞函數的前饋神經網絡。
BP神經網絡由輸入層、隱含層、輸出層組成。以多屬性指標訓練數據作為神經網絡的輸入,訓練過程分為網絡輸入信號正向傳播和誤差信號反向傳播,按有監督學習方式進行訓練[7~8]。

圖4 BP神經網絡結構圖
step 1:相鄰層之間結點的連接有一個權重Wij;
step 2:每一個神經單元都有一定量的能量,我們定義其能量值為該結點j的輸出值Oj;
step 3:除輸入層外,每一層的各個結點都有一個輸入值,其值為上一層所有結點按權重傳遞過來的能量之和加上偏置;
step 4:除輸入層外,每一層都有一個偏置值,其值在[0,1]之間;
step 5:除輸入層外,每個結點的輸出值等該結點的輸入值作非線性變換;
基于神經網絡的回歸分析,根據全局誤差極小來判定學習完成,從而確定網絡結構參數。
根據樣本數據訓練得到的權值參數,對新的目標特性數據進行質量評估,可以對最終的數據質量評估設置一個閾值,在神經網絡中輸入目標特性數據多維度評價指標的數值,自適應地利用神經網絡學習,從模型的輸出得到目標特性數據的評價結果,根據設置的閾值可以初步評估該數據的質量。
4.4.3 大數據環境下的數據質量評價模型
在大數據環境下,對于矩陣式的數據質量評價指標模型,針對不同場景維度,需要對多維度指標引入權重要素并研究自適應調整上述指標權重的方法;針對目標特性數據源的特點,開展基于時空序列數據、關聯數據、多源異構數據等數據質量評價方法研究,建立融合情境與類別的評價方法體系,支持精準化和個性化的數據質量評價,提供更為準確的數據質量評估。
面對海量的目標特性數據資源,數據質量評價同樣面臨著大數據帶來的挑戰。對于“大數據”(Big data)研究機構Gartner給出了這樣的定義:“大數據”是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力來適應海量、高增長率和多樣化的信息資產。大數據為數據質量評價問題帶來了存儲、計算和通信方面的挑戰,這與大數據在其他領域帶來的挑戰具有共性,而同時由于數據質量評價方法的獨特性,大數據對這些方法的可擴展性帶來了獨特的挑戰。
并行與分布式是解決大數據問題的主要思路,并行計算(Parallel computing)是指同時使用多種計算資源解決計算問題的過程,而分布式計算(Distributed computing)則是將計算過程分配到集群中的不同節點執行。大數據問題在工業界已經存在比較成熟的解決方案,一些大的互聯網公司和組織構建了一系列的基礎架構,比如Hadoop、Spark和Kafka等項目,結合這些技術和數據質量評價問題我們構建了大規模數據質量評價的方法。大數據具有以下四大特征:數據量大、數據類型繁多、流動速度快、價值密度低。針對大數據質量評價數據訪問量大和大數據本身的“海量化”特性,我們設計分布式存儲訪問系統以滿足數據存儲和快速訪問的需求。針對大數據“多樣化”的特性,擬采用多維度關聯分析實現數據的統一管理和使用。針對大數據“流動速度快”的特點,擬采用流式數據處理框架(比如Apache Storm)實現數據傳輸過程不落地進行實時數據質量評價。針對數據“價值密度低”的特點,擬采用PCA等降維方法去除數據噪音保留關鍵屬性[9~10]。
以大規模序列數據質量評價為例,基于概率后綴樹模型進行數據質量評價的方法難以實現對大規模數據的處理,而基于Apache Spark平臺的STALK算法能夠利用大規模序列數據高效建立生成模型,并根據生成模型對查詢序列的數據質量進行快速評價。
因此基于當前已建立的大數據處理平臺和并行與分布計算的思路,可以構建多種面向大數據的數據質量評價方法,應對大數據對數據質量評價帶來的挑戰。
4.4.4 基于專家知識庫的數據質量評價模型
在目標特性數據庫的數據質量研究中,不可缺少專業背景知識的支持,不可脫離領域知識實現數據質量評價。開展基于專家知識庫的數據質量評價方法研究主要基于專家知識面向數據質量工作構建專家知識庫,通過定量指標閾值、邏輯組合和推理,以及定量指標的語義化規范表達等方式進行評價。
知識庫系統是知識管理的工具和平臺,借助于這個平臺,各單位、部門可以更好的進行經驗的積累、組織間的學習、知識的更新和共享,提高對不同數據生成場景下的應變能力。“知識庫”不僅僅是狹義的存放知識的機構,它同時包括了知識庫的管理系統、用戶接口、知識獲取接口等部件,相當于一個知識庫系統平臺。平臺上的應用服務包括數據集成、數據挖掘、數據質量在線分析等[11,13]。
數據集成和數據挖掘,按一定規則共享或合并分布在各個主體數據庫的信息,系統化、有序化進行分類存儲,用戶可按不同的需求提取平臺數據庫中的信息。數據質量在線分析以平臺數據質量知識庫為支持,把智能技術引入事故的分析處理工作中,重組基于平臺的數據質量處理流程,用戶可實現事故處理的在線專家支持。用戶把數據相關信息錄入,在平臺質量控制設置知識庫的支持下,完成數據質量的初步分析,最后再根據特定的要求進行相應修訂和調整,并為用戶提供數據質量報告的參考方案。質量管理原則中提到:基于事實的決策方法,即對數據和信息的邏輯分析或直覺判斷是有效決策的基礎。要對數據進行分析判斷,首要的問題就是要解決大量數據和信息的收集問題。因此,對分布在各責任主體內部的廣泛質量信息的采集是質量控制平臺的基礎。數據集成就是共享或者合并兩個或多個應用間的數據,平臺中的數據集成是平臺質量信息采集的實現方式。數據分布的各個主體,其內部管理信息系統的結構、平臺各異,交換的數據結構、格式和要求也不一樣,要實現各主體間的數據信息交換、共享和集成,擬通過XML實現數據庫之間的數據交換。除了平臺主體的相互交互外,平臺上的數據倉庫和數據集市也以同樣的方式向平臺內的各責任主體采集和調用后期進行數據挖掘所需的數據[12~13]。
大量廣泛的數據集成到了平臺上的數據倉庫中,數據的豐富帶來了對強有力的數據分析工具的需求,決策者迫切需要從海量數據中提取有價值的信息和知識。有針對性地進行數據提煉,數據挖掘技術在一些事實或觀察數據的集合中尋找模式的決策支持,發現模型和數據間關系;統計一定時期內質量驗收合格率、優良率統計信息,也是為了把握質量發展的整體趨勢。知識庫通過數據集成,把數據和信息從不同的數據源取出來,然后轉換成公共的數據模型和數據倉庫中已有的數據集成在一起,當各責任主體和用戶按不同的需求進行數據的分析挖掘時,需要的信息已經準備好了,數據沖突、表達不一致等問題得到解決,這使得各主體的決策查詢更容易、更有效。
基于知識庫的質量分析處理流程的目標,是質量責任主體將數據信息輸入計算機,質量處理知識庫系統自動分析數據質量,并提供相關的處理措施,達到智能化的專家支持。數據質量的知識推理是知識庫依據對質量的定量和定性的描述而推導出結論的過程[14]。
5 結語
數據質量評價的指標計算、獲取難度大,對于數據質量評價在不同環境下的理論方法的研究程度并不相同,需要進行全局的綜合考慮;采用多層次數據質量評價體系,進行統一的形式化定義,采用有監督模式識別、專家知識庫體系與BP神經網絡理論相結合的方法對作戰數據質量進行評估。在評估模型構建上,依次確定評估指標,組建評估網絡。該方法增強了評估的科學性與客觀性,評估誤差性較小,評估模型與評估方法簡單實用。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中外會展(2014年4期)2014-11-27 07:46:46
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
