基于輪廓系數的參數無關空中交通軌跡聚類方法
2019-12-23 07:19:04孫石磊王超趙元棣
計算機應用 2019年11期
孫石磊 王超 趙元棣


摘 要:為消除專家經驗的主觀性、避免依賴軌跡特征并且減輕實驗調參的負擔,提出一種基于輪廓系數的參數無關聚類分析(PICBASIC)算法。首先,比較了現有基于歐氏距離的航跡配對方法,并且建立基于動態時間彎曲(DWT)距離和高斯核函數的軌跡相似度計算模型;其次,利用譜聚類對空中交通軌跡進行聚類劃分;最后,提出一種基于輪廓系數的最佳簇數尋優方法,并且其具有對聚類結果量化評價功能。利用真實進場軌跡進行實驗驗證,PICBASIC判斷將28L跑道的365條軌跡聚為5個簇,28R跑道的530條軌跡聚為6個簇時聚類質量最佳,平均輪廓系數分別為0.809-9和0.805-6。相同實驗數據條件下,PICBASIC與MeanShift聚類的平均輪廓系數差異率分別為-1.23% 和0.19%。實驗結果表明:PICBASIC包容軌跡的速度和長度差異,全程無需人工指導或實驗調參,而且能夠篩除異常軌跡對聚類質量的不利影響。
關鍵詞:空中交通軌跡;聚類分析;輪廓系數;譜聚類;動態時間彎曲;高斯核函數;參數無關
中圖分類號: TP181
文獻標志碼:A
Parameter independent clustering of air traffic trajectory based on silhouette coefficient
SUN Shilei*, WANG Chao,ZHAO Yuandi
Research Base of Air Traffic Management, Civil Aviation University of China, Tianjin 300300, China
Abstract:
In order to eliminate the subjectivity of expert experience, get rid of the dependence on trajectory characteristics and reduce the burden of experimental parameter tuning, a Parameter Independent Clustering BAsed on SIlhoutte Coefficient (PICBASIC) algorithm was proposed. Firstly, existing Euclidean distance based track pairing methods were compared, and a trajectory similarity calculation model based on Dynamic Time Warping (DWT) distance and Gaussian kernel function was established. Secondly, the air traffic trajectories were partitioned and clustered by spectral clustering. Finally, a cluster number optimization method based on silhouette coefficient was proposed, and it had the function of quantitative evaluation of clustering results. Experiments were carried out by using real arrival trajectories to verify the validity of the proposed algorithm. PICBASIC judged that the clustering quality would be respectively optimum if the 365 trajectories of runway 28L were clustered into 5 clusters and the 530 trajectories of runway 28R were clustered into 6 clusters. The average silhouette coefficients in the two situations were respectively 0.809-9 and 0.805-6. Under the same experimental conditions, the difference rates of average silhouette coefficient between PICBASIC and MeanShift clustering were respectively -1.23% and 0.19%. The experimental results demonstrate that PICBASIC can tolerate the speed and length differences of trajectories, dispense with manual guidance or experimental parameter tuning and filter out the adverse impact of abnormal trajectories on the clustering quality.
Key words:
air traffic trajectory; clustering analysis; silhouette coefficient; spectral clustering; Dynamic Time Warping (DTW); Gaussian kernel function; parameter independent
0?引言
針對空中交通軌跡的聚類分析是提高進離場程序的管制適用性、增強空域扇區劃分科學性的有效技術手段[1]。但是,當前絕大多數聚類算法都需要一個甚至多個顯式或隱式的輸入參數,它們的聚類結果通常嚴重依賴于這些參數[2]。確定合理的參數是困難的,一般需要根據專家經驗[3]、軌跡數據特點[4-6]或者多次實驗[1,6-9]獲得,其中:專家經驗判斷參數依賴于專家主觀經驗,缺乏客觀的量化分析指標;基于軌跡數據特點設定參數,受軌跡訓練樣本的飛行速度、交通流量、空域特征等影響,算法局限性強,普適性難以保證;多次實驗的方法顯然加重了用戶的負擔,而且實驗參數的候選值一般在某個指定范圍和變化步長內選取,并不是理論最優值。
針對以上問題,本文提出一種基于輪廓系數的參數無關聚類分析(Parameter Independent Clustering BAsed on SIlhouette Coefficient,PICBASIC)算法。首先,分析空中交通軌跡的數據結構; 然后,將軌跡作為一個整體,通過局部縮放時間維求出軌跡間的動態時間彎曲(Dynamic Time Warping,DTW)距離,再應用高斯核函數變換獲得軌跡相似度矩陣;接下來,利用譜聚類提取出相似度矩陣的特征子空間,并對聚類結果基于輪廓系數進行量化評價,進而確定最佳簇數;最后,通過終端區真實空中交通軌跡樣本對模型和方法進行驗證和分析。
1?空中交通軌跡的特征與表示
根據文獻[5]的定義,航跡(track)是指某時刻監視設備記錄的某航空器的某個空間位置、速度、航向等特征。軌跡(trajectory)是指在一段時間內,航空器飛行經過的歷史痕跡,由一系列按照時序順序排列的離散航跡組成。
通常,軌跡集可表示為:
TS={T1,T2,…,Ti,…,Tn}
式中:Ti為第i條軌跡,n為軌跡總數。
軌跡Ti可用航跡的數據集表示為:
Ti={pi1,pi2,…,pij,…,pim}
式中:pij表示第i條軌跡中第j個航跡,m為航跡總數。
每一個航跡pij定義為一個4維向量,即:
pij={x,y,z,t}
式中:x、y、z、t分別表示航跡pij的空間位置橫坐標、空間位置縱坐標、飛行高度和記錄時間。
2?參數無關空中交通軌跡聚類
2.1?定義軌跡的DTW距離
空中交通軌跡聚類分析關鍵是選擇合適的不同軌跡間的相似性度量方法[10]。本文采用歐氏距離來度量軌跡間的相似性,因為它直觀性最強,最易被理解與接受。
在求解軌跡間距離過程中,首先需要將不同軌跡的航跡按照某種規則配對,然后以航跡點對的歐氏距離作為軌跡間的距離。圖1表示了三種基于航跡點對歐氏距離的軌跡相似性度量方法。
圖1(a)方法直接使用兩條軌跡順序航跡點對之間的距離和除以配對的航跡數[11]。該方法完全沒有考慮航空器速度的差別,順序航跡點對的歐氏距離有可能成為兩條軌跡之間的斜距,增大了空間位置相似的軌跡的距離。圖1(b)方法在圖1(a)基礎上進行改進,在計算每一對航跡距離時,同時選取其前后最相近的兩個航跡進行計算,獲取在此位置附近的5段距離之間的最短歐氏距離[3]。圖1(b)方法考慮了航空器速度的差別,但是速度差大小與選取最相鄰航跡個數的關系沒有深入研究,在兩條軌跡的航跡疏密具有顯著區別時,仍然無法完全避免圖1(a)的問題。圖1(c)方法在圖1(b)基礎上進一步改進,計算局部航跡點與線的法向距離作為兩條軌跡間的距離[12]。圖1(c)方法直觀上縮短了圖1(b)方法的局部歐氏距離,但是同樣存在圖1(b)的問題。而且,三種方法均期望進行比較的兩條軌跡的航跡數目相同,否則較長的軌跡會在無法配對的航跡處被截斷,信息損失較高。
現實中,大部分空中交通軌跡都不等長,而且由于機型和飛行性能的區別,航空器飛行的速度不同導致不同軌跡的航跡疏密不同。所以,本文利用動態時間彎曲距離的特性來表示軌跡間的距離。首先,DTW距離對相比較的兩條軌跡的長度不作要求,即兩條軌跡的長度既可以是相等的也可以是不相等的[13]。其次,在保證航跡順序不變的前提下,基于DTW距離的方法通過重復部分航跡來完成時間維的局部縮放,尋找兩條軌跡之間的最佳對齊方式。軌跡間計算DTW距離的航跡配對原理如圖2[14]所示。
DTW距離計算方法[14]為:
DTW(Ti,Tj)=
0,mi=mj=0
∞,mi=0ormj=0
dist(pi1,pj1)+min{DTW(Rest(Ti),Rest(Tj)),
DTW(Rest(Ti),Tj),DTW(Ti,Rest)Tj))},
mi≠0,mj≠0 (1)
式中:DTW(Ti,Tj)表示兩條軌跡Ti與Tj間的DTW距離;mi和mj分別代表軌跡Ti與Tj的航跡個數;dist(pi1,pj1) 表示兩個航跡pi1和pj1之間的歐氏距離;Rest(Ti)和Rest(Tj)分別表示軌跡Ti與Tj去掉第一個航跡pi1和pj1所得的剩余軌跡區間。
根據式(1),如果兩條軌跡均存在航跡,則采用遞歸的方式求取最小歐氏距離作為DTW距離,在這個過程中會產生航跡的最優對應關系。
實踐中,航跡空間位置的橫、縱坐標與高度坐標的數值范圍可能存在較大差異,若不做處理直接計算歐氏距離,則數值范圍小的坐標對航跡空間距離的影響程度會降低。此時可將三維坐標逐個歸一化,再計算航跡間歐氏距離。例如,高度坐標的歸一化,如式(2)所示:
znorm=z-zminzmax-zmin(2)
進一步構建軌跡集TS的距離矩陣R,其元素rij表示軌跡Ti和Tj之間的距離,計算方法如式(3)所示。R為對稱方陣。
rij=0,i=j2×DTW(Ti,Tj)mi+mj,i≠j (3)
2.2?基于高斯核函數構造相似度矩陣
軌跡間的距離越小,相似度越高;反之,相似度越低。從距離矩陣到相似度矩陣的轉化采用高斯核函數,因為它能夠突出軌跡的差異性,顯著降低空間距離遠的軌跡相似度,有利于提高聚類質量。高斯核函數的基本形式如式(4)所示:
K(xi,xj)=exp(-‖xi-xj‖2β)(4)
式中:‖xi-xj‖2為xi和xj的2范數,β為帶寬參數,控制著高斯核函數的局部作用范圍。
高斯核函數的結果對參數β敏感,本文利用文獻[15]的方法選擇β,計算方法如式(5)所示,無需任何領域知識或試錯實驗,僅僅取決于數據樣本集自身特征。
β≈σ2/2.6,λ≤0.01σ2L(λ),0.01<λ<100λσ2=μ2,λ≥100 (5)
式中:σ2是數據樣本集的方差, μ是均值,參數λ=(μ/σ)2,L(λ)是關于λ的函數。
構建相似度矩陣S,其元素sij表示軌跡Ti和Tj的相似度,計算方法如式(6)所示:
sij=0,i=jexp[-r2ij/β],i≠j(6)
S為對稱方陣,且已歸一化。重構距離矩陣,記為R′, 其元素rij′表示軌跡Ti和Tj的距離,計算方法如式(7)所示:
rij′=1-sij(7)
2.3?構造譜聚類的拉普拉斯矩陣
譜聚類的聚類質量一般優于傳統聚類算法[16],而且,譜聚類只需確定“聚類簇數”這唯一的參數,所以,本文采用譜聚類構造參數無關的空中交通軌跡聚類方法PICBASIC。
譜聚類算法建立在圖論中的譜圖理論基礎上,其本質是將聚類問題轉化為圖的最優劃分問題。首先構造無向加權圖G=(V,E),其中每個頂點vi代表一條軌跡,每條邊eij賦予權重為軌跡Ti和Tj的相似度sij。于是,軌跡聚類轉化為對該圖頂點的劃分問題,使不同子圖之間的邊具有低權重(即不同簇的軌跡相似度低),而子圖內的邊具有高權重(即同簇內軌跡相似度高)。
然后構造度矩陣D,D為對角矩陣,對角線元素
dii=∑nj=1sij
最后構造正則化的拉普拉斯(Laplacian)矩陣L[16]:
L=D-12(D-S)D-12
2.4?基于輪廓系數確定最佳簇數
經典譜聚類算法需要知曉最終聚類的簇數,設為k; 然后對L求前k個最小特征值及對應的特征向量,構造特征子空間; 最后調用Kmeans聚類算法對特征子空間進行聚類。
文獻[5,16]利用特征向量最大譜系值所對應的下標作為簇數k,但是,若數據集之間存在較多相互重疊部分,會出現有2~3個數值相差不大的較大譜隙值,較難確定合理的簇數,需要結合領域知識或者專家經驗判斷。
最佳的簇數本質上要求的是最佳的聚類質量,使得簇內的對象相似度最高,不同簇的對象相似度最低。驗證聚類結果的方法包括分析、實驗、評價和舉例[10]。本文利用輪廓系數[17]作為對空中交通軌跡聚類結果的評價。軌跡間的距離由式(7)計算。每條軌跡的輪廓系數取值在-1~1,值越大表示該條軌跡所在簇越緊湊,且遠離其他簇。為了度量在完整軌跡集上的聚類質量,計算所有軌跡的輪廓系數的平均值,如式(8)所示:
savg=1n∑ni=1s(Ti)(8)
式中:savg為當簇數為k時的軌跡集平均輪廓系數,s(Ti)為軌跡Ti的輪廓系數,n為軌跡總數。
直觀上,增加簇數似乎有助于降低每個簇內的軌跡平均距離,因為有機會形成更多稠密的簇,簇中軌跡更為相似。然而由于邊際效應,劃分太多的簇會導致降低簇內軌跡平均距離的效果下降。因此,PICBASIC預先設定一個充分大的簇數kmax,然后計算從2~kmax范圍內各個候選簇數k的平均輪廓系數savg。利用肘方法(elbow method)思想,使用savg關于k的曲線的拐點作為最佳簇數[18]。
實際情況下,空中交通軌跡樣本集中常包含航空器脫離標準進離場航線而形成的異常軌跡。當候選簇數k不合理時,異常軌跡會被錯誤分類到某正常軌跡簇中,導致savg顯著降低。除非異常軌跡被單獨聚類為一個簇或幾個簇,savg才會增大。所以,應用輪廓系數作為聚類結果的評價量化指標,能夠有效篩除將異常軌跡混入正常軌跡簇的情況,提高聚類質量。
2.5?PICBASIC算法步驟
輸入?空中交通軌跡集TS,充分大的簇數kmax。
輸出?最佳簇數kopt,最佳聚類Copt,最大平均輪廓系數smax。
程序前
1)
歸一化TS的每個航跡pij;
2)
計算每兩條軌跡Ti和Tj之間的DTW距離;
3)
計算rij,構建距離矩陣R;
4)
計算R的方差σ2、均值μ、參數λ、L(λ),進而計算β;
5)
計算sij,構建相似度矩陣S;
6)
計算rij′,重構距離矩陣R′;
7)
初始化kopt=0;
8)
初始化smax=-1;
9)
for k=2 to kmax
10)
聚類C=spectral_clustering(TS, k);
11)
計算平均輪廓系數savg;
12)
if savg>smaxthen
13)
smax=savg;
14)
kopt=k;
15)
Copt=C;
16)
end if
17)
end for
程序后
3?實例分析
為驗證PICBASIC的合理性,選擇舊金山國際機場連續48h 的真實進場空中交通軌跡[19]進行實驗,其中28L跑道共365條軌跡,28R跑道共530條軌跡,未剔除任何異常軌跡,運用Matlab軟件進行聚類分析。
3.1?高斯核函數的參數尋優
由軌跡距離矩陣R,根據式(5)或文獻[20],可確定高斯核函數的帶寬參數β。相關參數如表1所示。
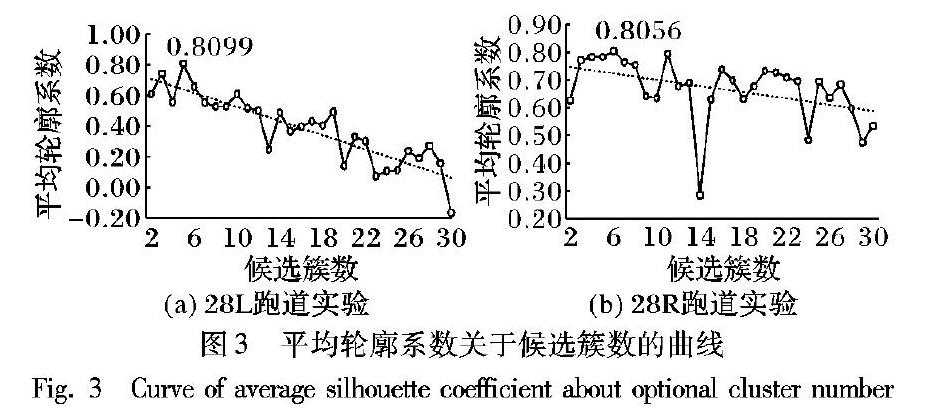
3.2?確定最佳簇數
初選設定充分大的候選簇數范圍為2到30,繪制平均輪廓系數關于候選簇數的曲線,如圖3所示。可見,增加簇數并不能增大平均輪廓系數,反而隨簇數增加,平均輪廓系數呈明顯下降趨勢。當簇數不合理時,會極大降低平均輪廓系數。由圖3(a)可知,當簇數為5時,平均輪廓系數達到最大值0.809-9,故確定最佳簇數kopt為5。同理,由圖3(b)可知,kopt為6,此時smax達到0.805-6。
應該指出,由于Kmeans算法具有一定的隨機性,每次聚類的結果會存在部分差異。但經多次實驗驗證,平均輪廓系數關于候選簇數的變化趨勢是穩定的,最佳簇數與最大平均輪廓系數也是穩定的。即使由于Kmeans算法的隨機性,導致某次聚類產生了不佳的結果,由于PICBASIC利用輪廓系數同時對聚類結果進行量化評價,能夠幫助用戶有效地識別和剔除該次不佳聚類。
通常終端區內空中交通軌跡的盛行流會符合該機場的標準儀表進離場程序,個別情況由于惡劣天氣和流量控制會出現等待、繞飛、返航或備降,所以最佳簇數一般不會與原有進離場飛行程序數量相差很大[5]。如果結合空域結構知識,參考機場跑道的標準儀表進離場程序數量,可適當縮減最佳簇數尋優范圍,提高算法運行效率。
3.3?聚類結果與分析
28L和28R跑道進場空中交通軌跡聚類結果如圖4所示,每個簇用不同線形區分。
由圖4(a)可見28L跑道所有進場軌跡被聚類為5個簇,其中進場方向分別為西南、正南、東北的軌跡被劃分為同一個簇,區分度明顯,但西北方向進場軌跡卻被劃分為2個簇。再參考圖4(b)可知西北方向進場軌跡的起始進場飛行高度存在高低之分,因此被劃分為2個簇。28R和28L跑道進場軌跡的走向、飛行高度和形態等具有較高的相似度,聚類結果也相似。由圖4(c)和圖4(d)可見,28R跑道所有進場軌跡被聚類為6個簇,其中少數幾條低飛行高度的異常軌跡被聚為一簇,該種聚類方式避免了異常軌跡對其他簇聚合度的破壞,能有效提高平均輪廓系數。
4?與其他聚類算法對比
在使用相同實驗數據的情況下,選取文獻[1]中MeanShift聚類與PICBASIC進行對比分析。文獻[1]方法非參數無關,無法識別最佳簇數,為了方便比較,人為指定其簇數與PICBASIC按照最大平均輪廓系數確定的最佳簇數相同。此外,文獻[1]方法包括3個重要的參數需要設定,分別是采樣點數、主成分個數、帶寬。為獲得滿意的聚類結果,多次實驗調參后具體參數值詳見表2。
聚類結果如圖5所示。與圖4相比,相似之處在于稠密的、大致相同進場方向的軌跡均被聚為一簇。但兩次聚類結果也存在些許差異。由圖5(a)和圖5(b)可見,文獻[1]方法將28L跑道西北方向高低兩個飛行高度進場的軌跡劃分為同一個簇; 由圖5(c)和圖5(d)可見,文獻[1]方法依然將28R跑道西北方向高低兩個飛行高度進場的軌跡劃分為同一個簇,而且把東側進場軌跡劃分為正東和東北兩個簇。此外,個別異常軌跡被兩種方法劃分到不同的簇。
為比較兩種方法的聚類質量,統一采用平均輪廓系數進行評價,結果如表3所示。
PICBASIC與文獻[1]方法的平均輪廓系數差異很小,證明應用PICBASIC得到的聚類結果具有較高的可信度,而且聚類質量較好。但由于PICBASIC參數無關,可避免文獻[1]方法中人工指導聚類簇數和多次實驗調參,具有更強的客觀性、普適性和更低的用戶負擔。
5?結語
本文從分析空中交通軌跡的相似性度量出發,針對其聚類問題展開研究,提出一種基于輪廓系數評價的參數無關聚類方法,得到如下結論:
1)PICBASIC基于DTW距離定義軌跡間的相似度,具有歐氏距離直觀性強、可信度高的優點,而且包容軌跡的速度和長度差異。
2)PICBASIC運算全程無需領域知識或人工經驗確定任何參數,提高了算法普適性,增強了聚類結果客觀性。
3)PICBASIC對每次軌跡聚類的結果提供量化評價指標,有利于比較聚類質量,降低Kmeans算法隨機性的影響。
未來的研究工作包括在軌跡相似性度量中增加時間(航班繁忙時段或空閑時段)維度、剔除異常軌跡、以機型為指定條件進行更細粒度的軌跡聚類分析等,并在此基礎上進一步評估和優化終端區飛行程。
參考文獻 (References)
[1]趙元棣,王超,李善梅,等. 基于重采樣的終端區飛行軌跡可信聚類方法[J]. 西南交通大學學報, 2017, 52(4):817-825.(ZHAO Y D, WANG C, LI S M, et al. Dependable clustering method of flight trajectory in terminal area based on resampling[J]. Journal of Southwest Jiaotong University, 2017, 52(4): 817-825.)
[2]HOU J, LIU W. Parameter independent clustering based on dominant sets and cluster merging[J]. Information Sciences, 2017, 405: 1-17.
[3]王超,徐肖豪,王飛. 基于航跡聚類的終端區進場程序管制適用性分析[J]. 南京航空航天大學學報, 2013, 45(1):130-139. (WANG C, XU X H, WANG F. ATC serviceability analysis of terminal arrival procedures using trajectory clustering[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2013, 45(1): 130-139.)
[4]王莉莉,彭勃. 基于LOFC時間窗分割算法的航跡聚類研究[J]. 南京航空航天大學學報,2018,50(5):661-665. (WANG L L, PENG B. Track clustering based on LOFC time window segmentation algorithm[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2018, 50(5): 661-665.)
[5]王超,韓邦村,王飛. 基于軌跡譜聚類的終端區盛行交通流識別方法[J]. 西南交通大學學報, 2014, 49(3):546-552. (WANG C, HAN B C, WANG F. Identification of prevalent air traffic flow in terminal airspace based on trajectory spectral clustering[J]. Journal of Southwest Jiaotong University, 2014, 49(3): 546-552.)
[6]KALAYEH M M, MUSSMANN S, PETRAKOVA A, et al. Understanding trajectory behavior: a motion pattern approach[EB/OL]. [2019-01-01]. https://arxiv.org/pdf/1501.00614.pdf.
[7]王超,鄭旭芳,卜寧. 基于小波聚類的終端區進場軌跡模式識別[J].計算機應用與軟件, 2016, 33(11):112-116. (WANG C, ZHENG X F, BU N. Pattern recognition of approach landing trajectories in terminal airspace based on wavelet clustering[J]. Computer Applications and Software, 2016, 33(11): 112-116.)
[8]石陸魁,張延茹,張欣. 基于時空模式的軌跡數據聚類算法[J]. 計算機應用, 2017, 37(3):854-859. (SHI L K, ZHANG Y R, ZHANG X. Trajectory data clustering algorithm based on spatiotemporal pattern [J]. Journal of Computer Applications, 2017, 37(3): 854-859.)
[9]ZHANG D, LEE K, LEE I. Hierarchical trajectory clustering for spatiotemporal periodic pattern mining[J]. Expert Systems with Applications, 2018, 92: 1-11.
[10]YUAN G, SUN P, ZHAO J, et al. A review of moving object trajectory clustering algorithms[J]. Artificial Intelligence Review, 2017, 47(1): 123-144.
[11]REHM F. Clustering of flight tracks[C]// Proceedings of the 2010 American Institute of Aeronautics and Astronautics Infotech and Aerospace. Reston, VA: AIAA, 2010: 1-9.
[12]徐濤,李永祥,呂宗平. 基于航跡點法向距離的航跡聚類研究[J]. 系統工程與電子技術, 2015, 37(9):2198-2204. (XU T, LI Y X, LYU Z P. Research on flight tracks clustering based on the vertical distance of track points[J]. Systems Engineering and Electronics, 2015, 37(9): 2198-2204.)
[13]AGRAWAL R, LIN K I, SAWHNEY H S, et al. Fast similarity search in the presence of noise, scaling, and translation in timeseries databases[C]// Proceedings of the 21th International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann Publishers, 1995:490-501.
[14]龔璽,裴韜,孫嘉,等. 時空軌跡聚類方法研究進展[J]. 地理科學進展, 2011, 30(5):522-534. (GONG X, PEI T, SUN J, et al. Review of the research progresses in trajectory clustering methods[J]. Progress in Geography, 2011, 30(5): 522-534.)
[15]LEI J, YIN J, SHEN H. GFO: a data driven approach for optimizing the Gaussian function based similarity metric in computational biology[J]. Neurocomputing, 2013, 99: 307-315.
[16]von LUXBURG U. A tutorial on spectral clustering[J]. Statistics and Computing, 2007, 17: 395-416.
[17]ROUSSEEUW P J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis[J]. Journal of Computational and Applied Mathematics, 1987, 20: 53-65.
[18]HAN J, KAMBER M, PEI J.數據挖掘: 概念與技術[M]. 范明,孟小峰,譯. 3版. 北京: 機械工業出版社, 2015:317. (HAN J W, KAMBER M, PEI J. Data Mining: Concepts and Techniques[M]. FAN M, MENG X F, translated. 3rd edition. Beijing: China Machine Press, 2015: 317.)
[19]OZO N. Flight tracks, Northern California TRACON[DB/OL]. [2019-01-01]. https://c3.nasa.gov/dashlink/resources/132.
[20]SHEN H. On optimizing Gaussian function based similarity metric in computational biology[EB/OL]. [2019-04-01]. http://www.csbio.sjtu.edu.cn/bioinf/GFO/.
This work is partially supported by the Foundation of Research Base of Air Traffic Management of Civil Aviation University of China (KGJD201702).
SUN Shilei, born in 1982, M. S., lecturer. His research interests include machine learning, data mining.
WANG Chao, born in 1971, Ph. D., professor. His research interests include air traffic system simulation and analysis, transportation planning and management.
Zhao Yuandi, born in 1983, Ph. D., research assistant. His research interests include air traffic management information processing.
