基于Python的電影數據爬取與數據可視化分析研究
2019-12-23 09:28:13成文瑩李秀敏
電腦知識與技術 2019年31期
關鍵詞:可視化
成文瑩 李秀敏
摘要:該文借助Python功能完備的標準庫、強大的第三方庫requests、BeautifulSoup以及正則表達式,編寫程序快速實現中國票房網頁及豆瓣電影TOP250數據的抓取,通過matplotlib圖形庫以圖形化的方式直觀地展示數據結果,并加以分析,得出相關結論。該文研究為培養學生數據處理能力和可視化分析能力奠定了基礎。
關鍵詞:數據爬取;Python;可視化
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2019)31-0008-03
1背景
隨著大數據和人工智能時代的到來,人們在數據的價值上逐漸取得共識,而獲得數據是數據挖掘與分析的首要工作。論文利用Python豐富的標準庫,研究網絡爬蟲的原理并實現電影網絡數據的獲取,并將獲得的數據進行可視化顯示和數據分析。
Python語法簡潔清晰,易學,可擴展性強,具有豐富的標準庫和第三方庫供程序員使用。Python爬蟲工具包使用方便,對數據抓取提供了可能嘲。
2數據爬取與可視化方法分析
網絡爬蟲是一個從Web上自動下載網頁的計算機程序。爬蟲技術是一個可以連接數據和解析數據,并將這些數據進行分析并將分析結果利用圖表進行展示的工具。Python具有豐富的網絡爬蟲模塊,具有很強的可擴展性與可嵌人性。
可視化分析可以提高科研人員對數據隱藏信息的洞察力。可視化分析是一種綜合利用可視化界面和分析理論來幫助用戶解釋復雜數據的技術。可視化是用戶與數據交互的接口,表現形式通常有直方圖、餅圖、散點圖等。
2.1數據采集
數據采集的執行過程分為:第一,分析網址信息找到網頁頁面并分析網頁源代碼結構;第二,根據網址抓取網頁并將網頁內容分離開來;第三,處理數據且將抓取后的數據寫人到數據庫中。上述三步重復執行直至數據采集結束。抓取網頁內容,一般有兩種方法,一種是使用python庫,另外一種是使用正則表達式去提取相關內容。
2.2分析及解析網頁
論文使用Python中的requests庫進行數據采集。Beautiful-Soup是一個HTML/XML的解析器,來解析URL的文本信息。通過確定每個數據對應的元素及Class名稱后,使用find,find_all,select等方法進行標簽的定位,進行數據提取。
2.3正則表達式提取數據
使用正則表達式對豆瓣電影TOP250進行數據采集。正則表達式(re)可匹配、搜索、替代高級文本模式,并為其他的一些功能提供基礎。正則表達式描述了字符與字符之間的某一種重復方式,是由字符以及特殊符號組成的,所以能按照某種已經設定好的模式和有類似特征的字符串集合進行匹配,依次讀取每個需要爬取的字段名稱和提取規則。
2.4數據整理
采用Python中的pandas庫對采集到的數據進行必要的整理,采用mean、loc、sort_values、groupby、merge等方法進行數據的統計與處理。將爬取的數據組合成DataFrame表格格式。pandas的基本功能是對數據進行索引查找、過濾和函數應用,除此之外,還有數據匯總和統計等功能,是實際數據分析中應用最為廣泛的模塊。
2.5數據存儲與可視化輸出
爬蟲獲取的數據可以將數據存儲為txt、xls、esv格式,也可存儲在數據庫中(包括MySQL關系數據庫和MongoDB數據庫)。論文數據存儲為CSV格式,具有方便導人數據庫的特點。除此之外,還可以存儲成pdf格式的文件。然后,采用Python中的matplotlib庫以散點圖、餅狀圖、條形圖等形式進行數據的可視化輸出。
2.6數據結果分析
對數據清洗和預處理后的票房、評論文本進行描述性數據統計分析。
3電影數據爬取與分析
3.1提取數據
打開中國票房網頁頁面并分析網頁源代碼結構。分析代碼過程中,可利用開發者工具確定每個數據對應的元素及Class名稱。例如用語句soup.find_all('table',{id:'tbContent'1},找到表格,id名稱為tbContent。下載并解析中國票房網頁,提取想要的數據信息,通過BeautifulSoup庫提取了電影名、電影類型、上映地點以及電影票房并且將每個數據用DataFrame放人對應列表中,見表1和表2,然后生成數據圖,分析數據。name,types,place,boxoffices字段分別是電影名,電影類型,上映地點,票房。
3.2數據分析
從網頁中提取數據后,將數據保存成csv文件。然后采用Python的統計方法對數據進行簡單的統計和分析。
3.2.1統計各電影類型在中國電影市場的平均票房
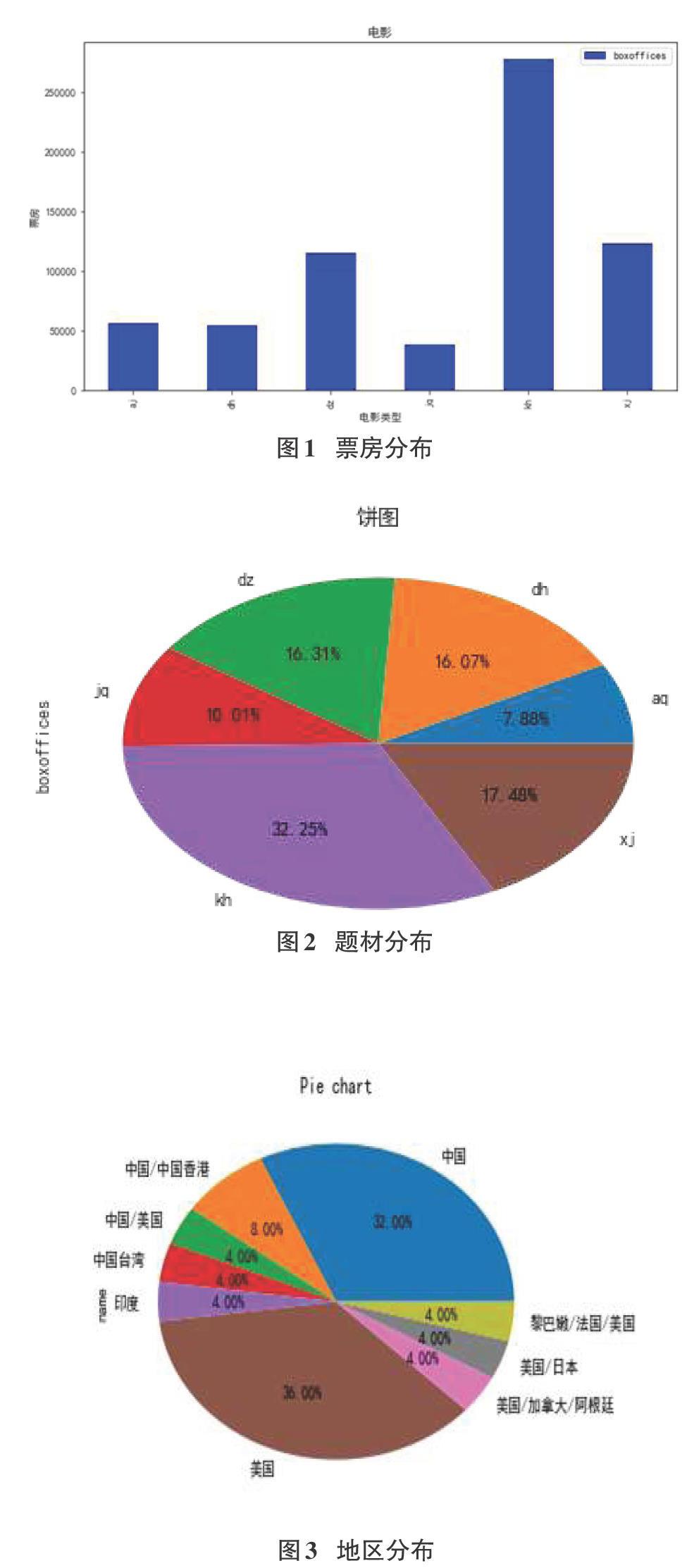
通過groupby方法按照類型分組,統計相應類型電影的總個數以及各個類型的電影票房的平均數和總數,并使用mat-plotlib.pyplot庫作條形圖和餅圖,結果一目了然,見圖3和圖4。
如圖1所示:橫軸為電影類型,從左到右依次為愛情、動畫、動作、劇情、科幻、喜劇,豎軸為票房。從圖中我們不難看出,科幻類型的電影更受人們的青睞,喜劇和動作電影大眾喜歡程度相差不大。
從圖2中我們也可以清楚的看到某種類型的平均電影票數占總平均票數的比例。我們不難得出結論,科幻類型的電影的平均票房占了絕大部分,具體數值為32.25%。
3.2.2各地區在中國電影市場上映電影數量
圖3可以分析出每個地區在中國電影市場的活躍度,從圖3中可以看出美國在中國電影市場活躍度最高,中國緊迫其后。
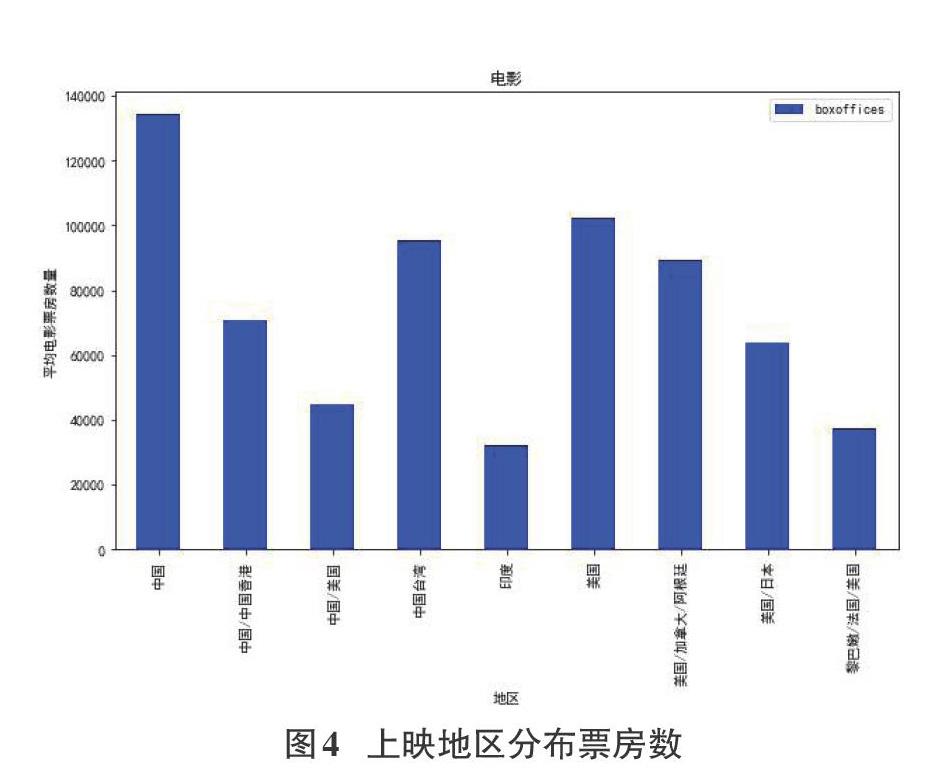
3.2.3各個上映地區在中國電影市場上的平均電影票房數
同樣,我們通過groupby按照地區分組,統計在中國各地區上映的電影平均票房。如圖4所示:橫軸為地區,豎軸為平均電影票房數量,從圖4中我們可以分析出人們對各地區在中國電影市場的認可度。從圖4中我們可以直觀地看到中國上映的電影的平均票房數量最多,這也與國人對國產電影的支持和國產電影類型和數量在這些年不斷陜速發展有關。
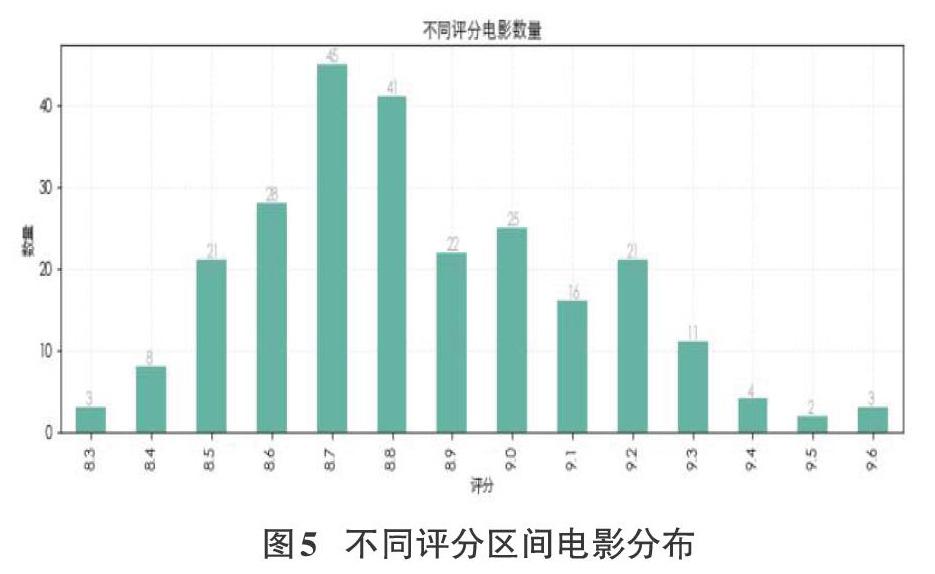
3.2.4不同評分電影的數量
下載并用正則表達式解析豆瓣TOP250網頁,如圖5所示:橫軸為評分,豎軸為數量,該圖可表示出豆瓣網前250名電影評分主要分布的范圍,從圖中可以看出,8.7評分的電影數量最多。評分主要分布中8.5到9.2之間。由此可見,大眾對電影類型喜好雖然不同,但是有一定包容性。
4結束語
大數據時代下,人類社會的數據正以前所未有的速度增長。編寫爬蟲程序獲取到的海量數據更為真實、全面,在信息繁榮的互聯網時代更為行之有效。因此編寫爬蟲程序成為大數據時代信息收集的必備技能。
Python作為一門腳本語言,它靈活、易用、易學、適用場景多,實現程序快捷便利。課題主要采用Python,結合正則表達式、BeautifulSoup等豐富且強大的庫,探討構建模塊化的web數據采集、Html解析及抓取鏈接數據的方法,深入研究爬蟲的基本原理與數據挖掘的算法。通過爬蟲獲取的海量信息,我們可以對其進行進一步的分析:市場預測、文本分析、機器學習方法等。
對于衛生信息化方向的信息管理與信息系統的專業學生而言,掌握Python數據抓取的方法、熟悉搜索引擎和網絡爬蟲相關技術以及檢索算法,為將來從事數據收集與處理的醫療信息化相關工作打下良好基礎。
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
