采用最大修改字節(jié)重定向?qū)懭氩呗缘南嘧兇鎯?chǔ)器延壽方法
2019-12-18 07:23:46汪東升王海霞
計(jì)算機(jī)研究與發(fā)展 2019年12期
高 鵬 汪東升 王海霞
1(北京大學(xué)工學(xué)院 北京 100871)2(清華大學(xué)計(jì)算機(jī)系 北京 100084)3(北京信息科學(xué)與技術(shù)國家研究中心(清華大學(xué))北京 100084)(gaopeng1982@pku.edu.cn)
相變存儲(chǔ)器(phase change memory,PCM)是一種新興的非易失性存儲(chǔ)器件,具有存儲(chǔ)密度高和靜態(tài)功耗低等優(yōu)點(diǎn).這在低功耗時(shí)代無疑是一個(gè)顯著的優(yōu)勢(shì).然而,基于PCM的存儲(chǔ)技術(shù)仍存在寫入壽命較低的缺點(diǎn),使其難以被應(yīng)用于實(shí)際系統(tǒng),更難以對(duì)抗惡意程序.因此,如何延長(zhǎng)PCM存儲(chǔ)系統(tǒng)的寫入壽命,成為該領(lǐng)域研究中的一個(gè)關(guān)鍵性問題.
一個(gè)典型的PCM存儲(chǔ)單元被認(rèn)為可以承受105至109次寫入操作,遠(yuǎn)低于目前廣泛使用的DRAM器件(通常可以承受大于1014次寫入)[1].而且一旦采用了多層化技術(shù),PCM單元的壽命還會(huì)繼續(xù)降低.一個(gè)實(shí)用的PCM存儲(chǔ)系統(tǒng)包含了上百萬個(gè)存儲(chǔ)單元,因此決定其壽命的因素不僅應(yīng)該包括單個(gè)存儲(chǔ)單元的寫入次數(shù)上限,還應(yīng)考慮存儲(chǔ)系統(tǒng)的內(nèi)部結(jié)構(gòu)以及應(yīng)用的特性.
現(xiàn)代內(nèi)存系統(tǒng)普遍的構(gòu)成方式為:多片存儲(chǔ)芯片并聯(lián)、共享訪問地址線.因此,一個(gè)PCM內(nèi)存系統(tǒng)的使用壽命問題需要考慮內(nèi)存系統(tǒng)的結(jié)構(gòu)的影響.一個(gè)由多片PCM并聯(lián)而成的內(nèi)存系統(tǒng)而言,其壽命取決的因素有:不同地址間的磨損分布和同一地址內(nèi)的磨損分布.前者指不同地址間的寫入頻繁程度的差別;而后者指在同一個(gè)地址內(nèi)不同的存儲(chǔ)位置,特別是不同存儲(chǔ)芯片間的寫入頻繁程度的差別本文稱為片間磨損局部性.
為討論片間磨損局部性對(duì)PCM內(nèi)存的壽命影響,本文首先收集實(shí)際應(yīng)用的內(nèi)存寫入數(shù)據(jù),并分析其在各個(gè)存儲(chǔ)芯片間的磨損分布的模式.實(shí)驗(yàn)結(jié)果顯示,各存儲(chǔ)芯片的修改頻度存在一定的不平衡性,且因程序而異.這種局部性會(huì)造成某些存儲(chǔ)芯片過快達(dá)到其寫入次數(shù)上限而出現(xiàn)故障,進(jìn)而影響整個(gè)存儲(chǔ)系統(tǒng)的可用性.
為了解決由這一局部性帶來的壽命衰減問題,本文提出了一種稱為最大磨損轉(zhuǎn)移(redirecting the most modified byte,RMB)的壽命延長(zhǎng)方法.該方法的核心在于保護(hù)當(dāng)前承受最多磨損的存儲(chǔ)芯,避免其被進(jìn)一步的寫入.通過為每個(gè)存儲(chǔ)芯片添加數(shù)據(jù)比較器和寫入計(jì)數(shù)器,可以識(shí)別出在寫入時(shí)發(fā)生了修改的芯片和當(dāng)前承受了最多寫入的芯片.然后,關(guān)閉承受了最多寫入的芯片的寫入,并將未來對(duì)該芯片的寫入導(dǎo)向到額外添加的長(zhǎng)壽命的輔助芯片中.
通過動(dòng)態(tài)的最大磨損轉(zhuǎn)移策略,RMB方法不僅可以減少PCM存儲(chǔ)器上的總寫入量,而且還可以平衡各PCM芯片之間的寫入量差別,從而在整體上延長(zhǎng)PCM內(nèi)存的壽命.此外,相比于廣泛使用的磨損均衡方法,RMB方法不會(huì)將寫入量均攤給那些原本只應(yīng)該承受較低寫入量的存儲(chǔ)芯片,從而使其免受額外磨損.
此外,為了測(cè)試RMB方法的效能,本文提出了一種基于該方法的混合內(nèi)存設(shè)計(jì)方案,稱為HPS(hybrid PCM system).該方案采用磁性隨機(jī)存儲(chǔ)器(magnetic RAM,MRAM)作為長(zhǎng)壽命的輔助存儲(chǔ)芯片.實(shí)驗(yàn)結(jié)果顯示,該設(shè)計(jì)對(duì)于典型測(cè)試程序具有良好表現(xiàn).相比未使用任何壽命延長(zhǎng)方法的內(nèi)存系統(tǒng),HPS可以最多延長(zhǎng)7.9倍的壽命;相比于經(jīng)典的寫減少方法PRES,也可以延長(zhǎng)5.14倍的壽命.
本文的貢獻(xiàn)包括2個(gè)方面:
1)提出了片間磨損局部性是導(dǎo)致相變內(nèi)存系統(tǒng)壽命衰減的重要原因.
2)提出了一種兼具寫減少和磨損均衡效果的方法,可有效對(duì)抗因片間磨損局部性引起的磨損.
1 相關(guān)工作
延長(zhǎng)相變內(nèi)存的壽命一般可以通過2種途徑:平衡存儲(chǔ)單元間的寫入量差異和減少寫入量.平衡存儲(chǔ)單元間的寫入量差異防止了某些單元被過快磨損而導(dǎo)致的壽命迅速下降問題.Joo等人[2]和Zhou等人[3]分別采用數(shù)據(jù)周期位移和數(shù)據(jù)段交換的方案達(dá)到這一目標(biāo).而Wu等人[4]和Seong等人[5]分別采用地址重映射技術(shù),避免了對(duì)某些地址的集中寫入,實(shí)現(xiàn)了一種可以對(duì)抗惡意寫入行為的存儲(chǔ)系統(tǒng).Start-Gap以及Region Based Start-Gap[6]方法采用環(huán)狀隊(duì)列實(shí)現(xiàn)了地址-數(shù)據(jù)間進(jìn)行重映射,進(jìn)而延長(zhǎng)了基于PCM的存儲(chǔ)系統(tǒng)的壽命.
寫減少方法通過減少存儲(chǔ)單元的改變次數(shù)來降低總的寫入量.DCW[7],FNW(Flip-N-Write)[8],Min-shift[9],FlipMin[10],PRES[11-12]是5種典型的寫減少方法.其中,DCW僅使用待寫入數(shù)據(jù)作為唯一的一個(gè)候選向量來與目標(biāo)地址已有數(shù)據(jù)進(jìn)行比較,并寫入相異位.而其他4種方法通過采用位移或編碼技術(shù),提供了更多的候選向量,進(jìn)一步降低了相異位的數(shù)量.
為了發(fā)揮不同存儲(chǔ)器件各自的優(yōu)勢(shì),越來越多的研究開始轉(zhuǎn)向混合使用異質(zhì)存儲(chǔ)器件的設(shè)計(jì)方案.Dhiman等人[13]、Park等人[14]提出了將DRAM和PCM混合的方案,將小容量的DRAM芯片作為PCM存儲(chǔ)系統(tǒng)的緩存,用以緩存經(jīng)常讀寫的數(shù)據(jù),從而降低存儲(chǔ)系統(tǒng)整體的延遲和功耗,延長(zhǎng)PCM部分的使用壽命.Joo等人[15]使用了STT-RAM作為PCM的cache,延長(zhǎng)了系統(tǒng)的寫入壽命.張德志等人[16]實(shí)現(xiàn)了一種基于DRAM和PCM的混合內(nèi)存模擬器,為研究異構(gòu)存儲(chǔ)器的使用提供了便利條件.吳煬等人[17]提出了一種高效的DRAM-PCM混合內(nèi)存模型及布局機(jī)制,并通過使用糾刪碼提高了系統(tǒng)的可靠性.
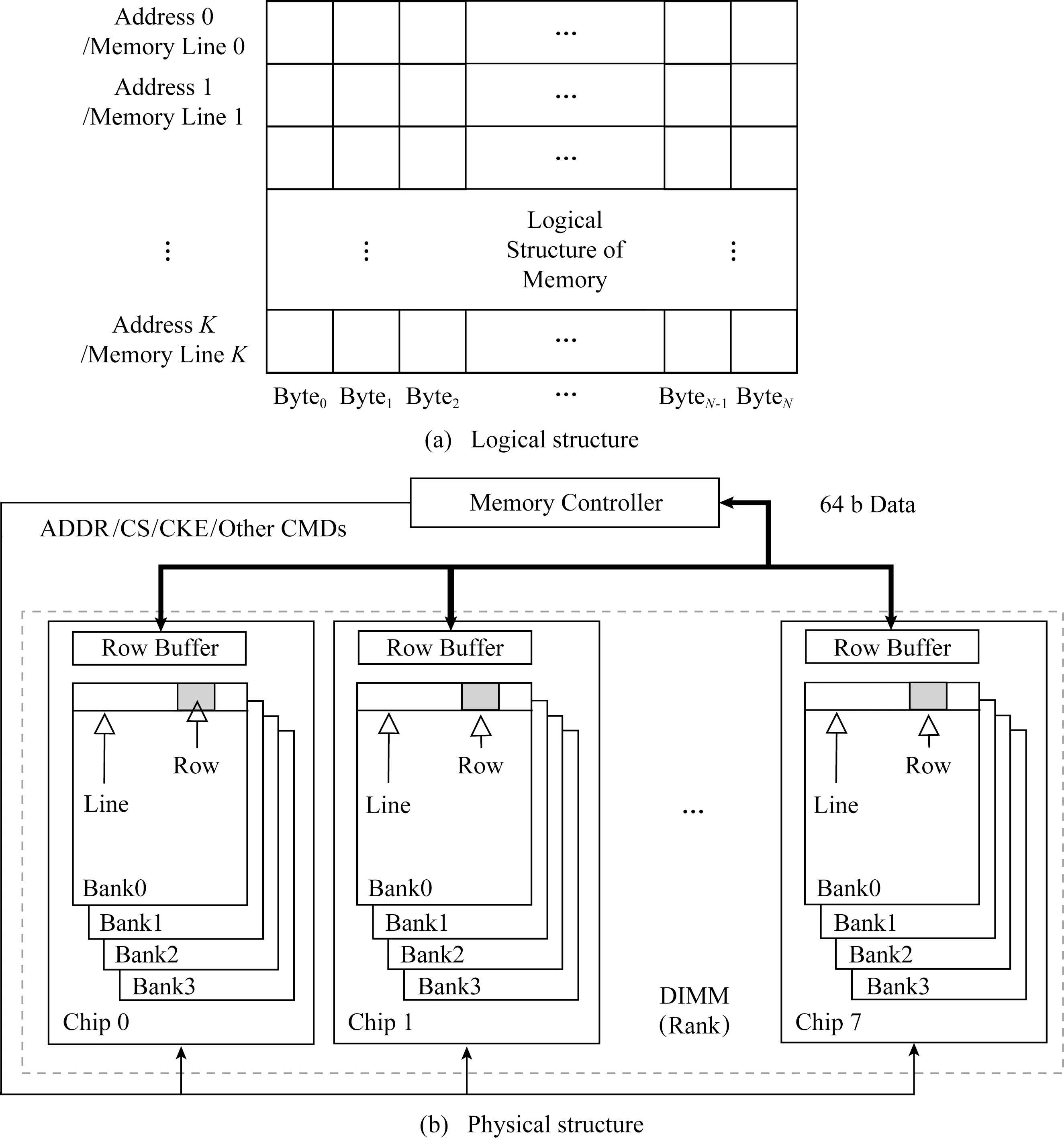
Fig.1 Logical and physical structures of the main memory圖1 內(nèi)存的邏輯結(jié)構(gòu)和物理結(jié)構(gòu)
2 研究動(dòng)機(jī)
2.1 內(nèi)存的邏輯結(jié)構(gòu)與物理結(jié)構(gòu)
內(nèi)存負(fù)責(zé)存儲(chǔ)運(yùn)行時(shí)處理器需要的數(shù)據(jù)及其產(chǎn)生的數(shù)據(jù).從中央處理器/操作系統(tǒng)的角度來看,內(nèi)存可以被抽象為1個(gè)2維表.每次讀寫操作的最小原子單位是這個(gè)表的1行.本文將其稱為1個(gè)內(nèi)存行(memory line,ML).每個(gè)內(nèi)存行通常包含32 b或64 b.每個(gè)內(nèi)存行對(duì)應(yīng)1個(gè)地址(address),用于訪問該行中的數(shù)據(jù).整個(gè)內(nèi)存包含上百萬條內(nèi)存行,所有內(nèi)存行的地址構(gòu)成系統(tǒng)可用的物理地址空間.
從構(gòu)成的角度來看,內(nèi)存分為存儲(chǔ)控制器和存儲(chǔ)單元.前者一般集成于中央處理器中,對(duì)處理器/操作系統(tǒng)提供一個(gè)抽象的內(nèi)存訪問界面;后者負(fù)責(zé)實(shí)際存儲(chǔ)數(shù)據(jù).存儲(chǔ)單元一般由1條或多條DIMM(dual in-line memory module)形式的內(nèi)存條組成.一條DIMM內(nèi)存條包含了8或16個(gè)存儲(chǔ)芯片.這些存儲(chǔ)芯片共享地址線,同時(shí)進(jìn)行讀取或?qū)懭氩僮?每個(gè)內(nèi)存芯片讀寫時(shí)的數(shù)據(jù)位寬一般為8 b,即單次訪問時(shí)的最小讀寫位數(shù)為8 b.此外,基于DRAM的內(nèi)存存儲(chǔ)單元的內(nèi)部結(jié)構(gòu)還有更精細(xì)的結(jié)構(gòu),包括Rank,Bank,Column,Row,RowBuffer等,但這些結(jié)構(gòu)和本文沒有直接聯(lián)系,在此不做贅述.內(nèi)存的邏輯結(jié)構(gòu)和物理結(jié)構(gòu)如圖1所示:
2.2 問題的提出
現(xiàn)代內(nèi)存系統(tǒng)通常采用多片存儲(chǔ)芯片通過共享地址總線并聯(lián)而成.因此,當(dāng)一個(gè)數(shù)據(jù)被寫入內(nèi)存時(shí),每個(gè)存儲(chǔ)芯片只負(fù)責(zé)存儲(chǔ)該數(shù)據(jù)的一部分.由于數(shù)據(jù)的數(shù)值分布是非均勻的,因此,各數(shù)據(jù)分段被改變的概率也不會(huì)完全相同.例如當(dāng)存儲(chǔ)大量數(shù)值接近零的小整數(shù)時(shí),負(fù)責(zé)存儲(chǔ)低位的存儲(chǔ)芯片將更加活躍;負(fù)責(zé)存儲(chǔ)高位的存儲(chǔ)芯片因幾乎總是存儲(chǔ)零值而受到相對(duì)較少的修改.
數(shù)據(jù)值分布的不均勻性導(dǎo)致了存儲(chǔ)這些數(shù)值的存儲(chǔ)芯片的改變概率不同.這對(duì)于寫入壽命近乎無限的DRAM器件而言,并不構(gòu)成問題.然而,對(duì)于寫入壽命有限的存儲(chǔ)器件如PCM而言,這種和存儲(chǔ)位置相關(guān)的磨損不平衡性,將會(huì)導(dǎo)致負(fù)責(zé)存儲(chǔ)變化頻率較大的數(shù)據(jù)段的芯片承受更多的磨損,縮短其使用壽命,進(jìn)而導(dǎo)致整個(gè)存儲(chǔ)系統(tǒng)陷入故障狀態(tài).
應(yīng)對(duì)非均衡分布的常用方法是采用磨損均衡技術(shù).這一技術(shù)將寫入時(shí)發(fā)生的磨損盡可能均攤到所有存儲(chǔ)單元上,從而降低對(duì)某個(gè)存儲(chǔ)單元壽命的集中損耗,進(jìn)而增加系統(tǒng)的總體可用性.然而,值得注意的是,磨損均衡方法對(duì)于承受較少寫入的存儲(chǔ)單元來說是不公平的.具體而言,本應(yīng)該承受較少寫入的單元將被迫承受從其他負(fù)擔(dān)較重單元轉(zhuǎn)移出的寫入負(fù)荷.
因此,如果能夠構(gòu)造一種方法,使其可以將額外的寫入從負(fù)擔(dān)較重的存儲(chǔ)單元中轉(zhuǎn)移出來并加以記錄,而又不必將其寫入到寫入負(fù)擔(dān)較輕的存儲(chǔ)單元中,那么這種方法可以同時(shí)降低所有存儲(chǔ)單元的寫入量,以及各個(gè)存儲(chǔ)單元之間的寫入量差異,進(jìn)而提升整個(gè)存儲(chǔ)系統(tǒng)的壽命,這就是本文提出的方法的核心思想.
2.3 片間磨損局部性
本文將這種發(fā)生在多芯片存儲(chǔ)器中的非平衡磨損現(xiàn)象稱為片間磨損局部性.常用的時(shí)空局部性和數(shù)據(jù)內(nèi)容無關(guān),僅和內(nèi)存行對(duì)應(yīng)的地址重用性有關(guān).因此,在圖1(a)中,片間磨損局部性體現(xiàn)在水平方向,各個(gè)字節(jié)間的訪問熱度不同.而時(shí)空局部性,表現(xiàn)的是在垂直方向,內(nèi)存訪問地址(memory address,MA)之間的訪問頻度分布.
片間磨損局部性本質(zhì)上是由數(shù)據(jù)值分布的非均衡性以及內(nèi)存的物理結(jié)構(gòu)所共同引起的.例如頻繁使用數(shù)值較小的二進(jìn)制數(shù)據(jù),將會(huì)導(dǎo)致存儲(chǔ)低位數(shù)據(jù)的存儲(chǔ)單元頻繁發(fā)生變化;而存儲(chǔ)高位數(shù)據(jù)的存儲(chǔ)單元變化較慢.為了展示數(shù)據(jù)值和片間磨損局部性之間的聯(lián)系,本文首先通過數(shù)值模擬給與展示,如圖2所示.
首先,本文定義一個(gè)數(shù)據(jù)集合D,包含106個(gè)定長(zhǎng)二進(jìn)制整數(shù),并假設(shè)這些整數(shù)服從高斯分布(高斯分布的平均值用mean表示,方差用sigma表示.通過設(shè)定均值和方差的關(guān)系,可以保證數(shù)據(jù)集D內(nèi)99%以上的整數(shù)非負(fù),而此時(shí)D中的負(fù)數(shù)所占比例很小,在模擬中被忽略).之后,這些整數(shù)將被依次寫入到1個(gè)8 b的存儲(chǔ)單元中,用以觀察在不同均值和方差的組合條件下寫入數(shù)據(jù)集D時(shí),各個(gè)存儲(chǔ)位的磨損情況.如圖2所示,磨損分布的變化與數(shù)據(jù)均值的變化緊密相關(guān),并出現(xiàn)了一定的周期性.當(dāng)均值為2的冪次時(shí),各個(gè)存儲(chǔ)芯片幾乎被均勻磨損,方差sigma幾乎沒有影響.當(dāng)數(shù)據(jù)均值不是2的冪次時(shí),對(duì)于方差sigma較小的數(shù)據(jù)集,片間磨損局部性更加明顯,這是因?yàn)楦〉姆讲顚?dǎo)致數(shù)據(jù)更加集中于某些數(shù)值附近,數(shù)值間的變化更多地表現(xiàn)為少數(shù)幾個(gè)低位的變化.當(dāng)方差sigma變大時(shí),數(shù)據(jù)集合中將出現(xiàn)更多種類的數(shù)值,數(shù)值之間的差別也會(huì)變大,因此整體磨損分布呈現(xiàn)為較為平緩的分布,表明片間磨損局部性較弱.當(dāng)呈現(xiàn)均勻分布時(shí),即為極限情況.

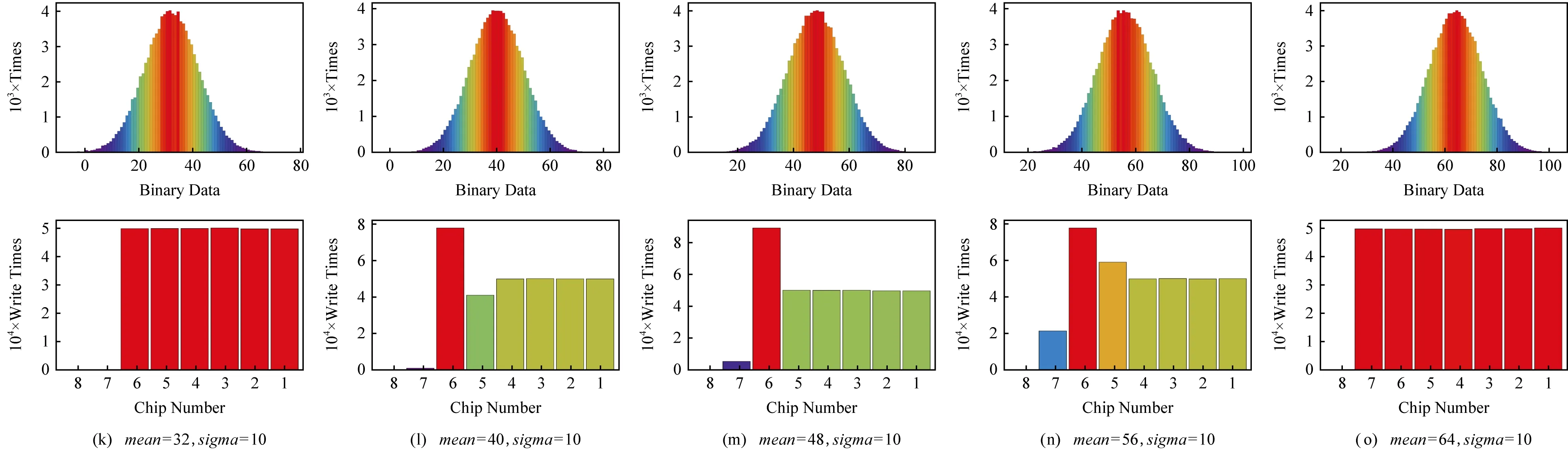
Fig.2 Chips modification with different mean and variation圖2 帶有不同均值和方差的數(shù)據(jù)集下芯片間磨損的分布情況
為進(jìn)一步研究實(shí)際應(yīng)用中片間磨損局部性的情況,本文使用GEM5模擬器運(yùn)行并收集了12個(gè)典型應(yīng)用的訪存蹤跡(假設(shè)內(nèi)存是由8個(gè)8 b的存儲(chǔ)芯片構(gòu)成,任何1 b發(fā)生改變,那么存儲(chǔ)該位的存儲(chǔ)芯片就被認(rèn)為發(fā)生了1次改寫,每個(gè)存儲(chǔ)芯片的修改概率可以從修改次數(shù)和總的寫入次數(shù)中得到),并統(tǒng)計(jì)了各芯片的修改概率.其結(jié)果如圖3所示.在某些測(cè)試程序如libquantum,其芯片1發(fā)生修改的概率為芯片3的30倍以上.模擬和測(cè)試程序均顯示,在多芯片并聯(lián)構(gòu)成的內(nèi)存中,不同存儲(chǔ)芯片之間的修改頻繁程度,存在著較大的差別,而這一差別必然會(huì)影響到由PCM構(gòu)成的內(nèi)存壽命.
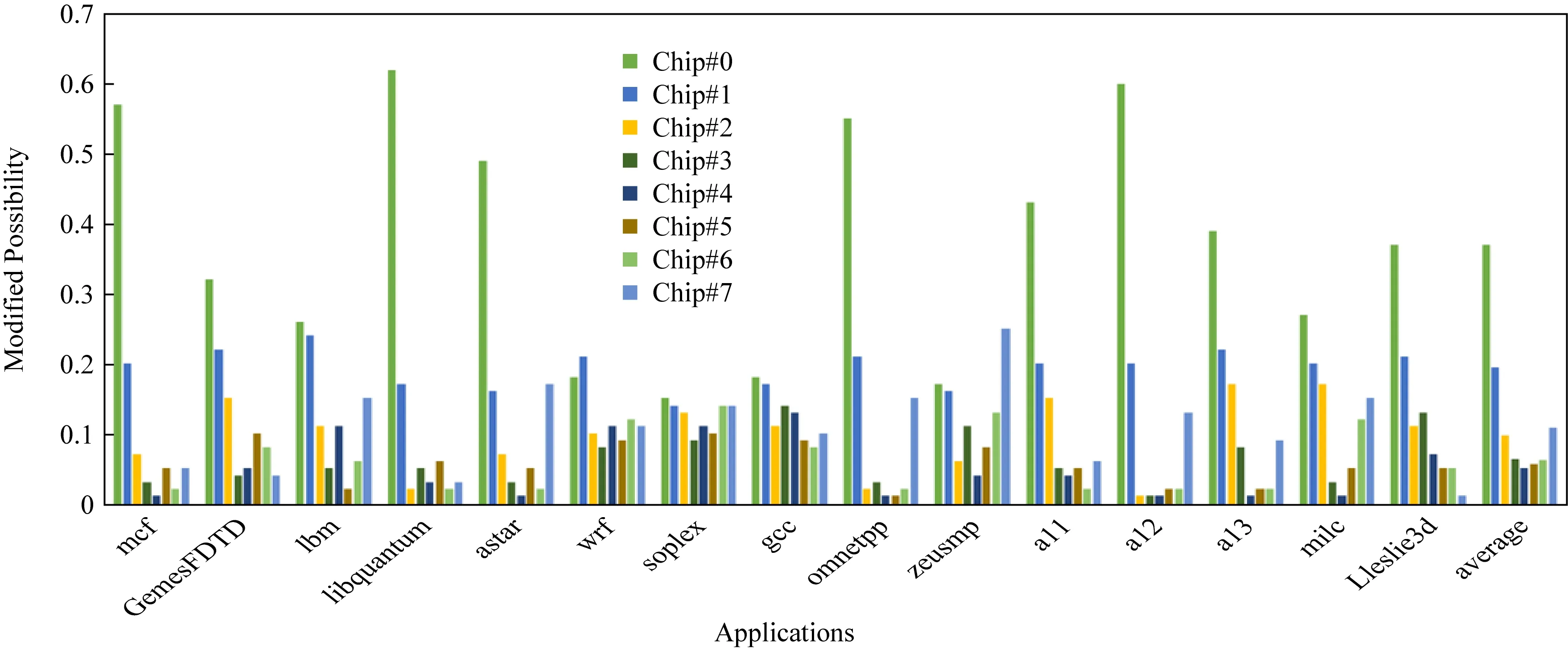
Fig.3 Variance of modification possibilities across chips with benchmarks圖3 測(cè)試程序中各芯片間的修改頻率的變化示意圖
3 RMB方法的設(shè)計(jì)與分析
3.1 基本思想
片間磨損局部性會(huì)導(dǎo)致多個(gè)存儲(chǔ)芯片磨損程度的差異,進(jìn)而導(dǎo)致某些存儲(chǔ)芯片過快用盡寫入壽命.對(duì)這一問題的一種解決方法是將這些寫入量從受到較多磨損的芯片上轉(zhuǎn)移出來.但是被轉(zhuǎn)移出的這部分寫入量仍然需要存儲(chǔ)器件來保存.針對(duì)轉(zhuǎn)移出的數(shù)據(jù)的存放問題,磨損均衡方法將其分配給其他輕負(fù)載單元.而RMB方法的核心在于將這部分?jǐn)?shù)據(jù)轉(zhuǎn)移并存儲(chǔ)到附加的長(zhǎng)壽命存儲(chǔ)器件中,從而同時(shí)減少存儲(chǔ)器件的總寫入量和各存儲(chǔ)芯片之間的寫入量差異.因此,RMB方法可以被認(rèn)為是一種兼具寫減少和磨損均衡能力的壽命延長(zhǎng)方法.
3.2 RMB方法的結(jié)構(gòu)
一個(gè)采用了RMB方法的存儲(chǔ)系統(tǒng)包含主存儲(chǔ)芯片(main storage chip,MSC)、輔助存儲(chǔ)芯片(auxiliary storage chip,ASC)、芯片修改次數(shù)計(jì)數(shù)器(modification counter,MC)以及最多被修改芯片指針(most-modified chip index,MCI),其組成框圖如圖4所示.每個(gè)MC負(fù)責(zé)記錄每個(gè)對(duì)應(yīng)的MSC的修改次數(shù).每當(dāng)一個(gè)MSC中的某個(gè)位置發(fā)生了一次修改(寫入值與已有值不同),那么該MSC對(duì)應(yīng)的MC就被加1.MCI用于存儲(chǔ)目前被最多修改的MSC的編號(hào).ASC包含了數(shù)據(jù)域(data zone,DZ)、標(biāo)志域(tag zone,TZ)和有效域(valid zone,VZ).數(shù)據(jù)域(以ASC.Data表示)用于存放被轉(zhuǎn)移的數(shù)據(jù),標(biāo)志域(以ASC.Tag表示)用于指示被轉(zhuǎn)移的數(shù)據(jù)屬于哪一個(gè)MSC,有效域(以ASC.Valid表示)則表示相應(yīng)的標(biāo)志域和數(shù)據(jù)域是否有效.

Fig.4 Block diagram of RMB method圖4 RMB方法框圖
3.3 讀寫過程
當(dāng)給出讀取地址后,ASC和各個(gè)MSC的同一地址行內(nèi)的數(shù)據(jù)都將被讀取到內(nèi)存控制器中.此時(shí),如果ASC行中的有效域被設(shè)置,那么其所屬的標(biāo)志域?qū)?huì)被檢查,用以發(fā)現(xiàn)MSC行中過時(shí)的數(shù)據(jù)字節(jié),這樣的字節(jié)將被ASC中數(shù)據(jù)域的對(duì)應(yīng)行的數(shù)據(jù)代替.如果有效域未被設(shè)置,那么說明該ASC行處于無效狀態(tài),各MSC字節(jié)均為最新數(shù)據(jù).此時(shí),內(nèi)存控制器將讀取到的MSC數(shù)據(jù)轉(zhuǎn)發(fā)出去完成讀取.
當(dāng)寫入開始時(shí),MSC和ASC中給定地址上的行數(shù)據(jù)將首先被載入到內(nèi)存控制器中.根據(jù)MCI的內(nèi)容,以及ASC中有效域和標(biāo)志域的信息,存在2種可能:
1)如果有效域未被設(shè)置,那么ASC中該行的數(shù)據(jù)域無效.此時(shí),MCI指向的MSC上的待寫入數(shù)據(jù),將會(huì)被寫入ASC的數(shù)據(jù)域,而不是寫入對(duì)應(yīng)的MSC中.而標(biāo)志域也將被修改為當(dāng)前被映射的MSC的標(biāo)號(hào).除此之外的各個(gè)字節(jié)將正常寫入各MSC.
2)如果有效域被設(shè)置,那么標(biāo)志域的內(nèi)容有效,此時(shí),將存在2種分支狀況.
① 如果標(biāo)志域的值等于MCI的值,那么要寫入標(biāo)志域所指向的MSC的字節(jié),將被寫入ASC的數(shù)據(jù)域中,作為更新.除此之外的標(biāo)志域、MCI以及負(fù)責(zé)該MSC的MC,均保持不變.
② 如果標(biāo)志域的值不等于MCI的值,那么標(biāo)志域所存儲(chǔ)的MSC標(biāo)號(hào),在過去某個(gè)時(shí)刻曾經(jīng)是受磨損最多的,而當(dāng)前已經(jīng)不再是這樣.由于待寫入的數(shù)據(jù)包含了該地址上最新的內(nèi)容,因此,可以將數(shù)據(jù)域和標(biāo)志域視為無效,然后向ASC的數(shù)據(jù)域直接寫入MCI所指向的字節(jié)的新數(shù)據(jù).而原來標(biāo)志域所指向的MSC,可以直接用當(dāng)前最新數(shù)據(jù)覆蓋即可,最后對(duì)相應(yīng)的MC+1.
最后當(dāng)數(shù)據(jù)與芯片之間的分配關(guān)系確定后,各個(gè)MSC和ASC將按照分配的結(jié)果完成各自的寫入.
3.4 寫入過程實(shí)例
為了更清晰地展示寫入過程,圖5給出了1個(gè)寫入例程.在該例子中,多個(gè)數(shù)據(jù)被連續(xù)寫入1個(gè)應(yīng)用了RMB系統(tǒng)的某一個(gè)內(nèi)存行.該系統(tǒng)包含2個(gè)MSC、1個(gè)ASC、2個(gè)MC和1個(gè)MCI.該例程展示了使用RMB之后的結(jié)果之外,還給出了使用理想均衡方法(ideal levelling method,ILM)和不使用任何壽命延長(zhǎng)方法(RAW)時(shí)的結(jié)果.
首先,所有的MSC,ASC,MC都被置為0.
1)當(dāng)寫入數(shù)據(jù)0x0A之后,MSC#1被修改為0xA,MC#1的值加1,MCI指向MSC#1,如狀態(tài)1所示.
2)當(dāng)數(shù)據(jù)0x0B被寫入時(shí),由于此時(shí)MCI指向MSC#1,因此該寫入將被轉(zhuǎn)移到ASC的DZ中,ASC的Tag也因此指向MSC#1,如狀態(tài)2所示.
3)當(dāng)寫入數(shù)據(jù)0xCC時(shí),MSC#2被修改為0xC,而低位數(shù)據(jù)則由于MCI的導(dǎo)向作用,被寫入ASC的DZ中,MSC#1再次得到保護(hù),如狀態(tài)3所示.
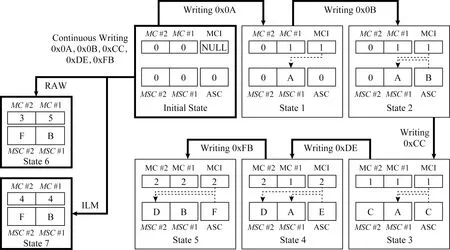
Fig.5 A writing example for the RMB method圖5 RMB方法的寫入實(shí)例
4)狀態(tài)4與狀態(tài)3類似,但MCI的值發(fā)生了改變.
5)狀態(tài)5中,數(shù)據(jù)0xFB被寫入,ASC的DZ被修改為0xF,而MSC#1被更新為0xB.最終狀態(tài)5顯示,每MSC都被寫入了2次.
不采用任何抗磨損方法的寫入結(jié)果如狀態(tài)6所示,狀態(tài)7顯示了采用理想均衡方法的結(jié)果.狀態(tài)5、狀態(tài)6、狀態(tài)7的對(duì)比顯示,MSC的總寫入次數(shù)得以減少,而且每個(gè)MSC的寫入量也得到了均衡.究其原因,在RMB方法中當(dāng)任意一個(gè)MSC受到了集中式的寫入時(shí),其寫入計(jì)數(shù)就會(huì)一直增大,直到大于其他所有MSC的計(jì)數(shù),從而引發(fā)保護(hù)機(jī)制,使其未來的寫入被導(dǎo)入ASC,從而避免進(jìn)一步的磨損.不僅總體寫入量得到削減,而且各個(gè)MSC之間的磨損差異也得以縮小.因此,RMB方法可以被視為是一種特殊的、兼具寫入量減少和寫入平均能力的壽命延長(zhǎng)方法.
4 性能評(píng)估
4.1 PCM-MRAM混合內(nèi)存結(jié)構(gòu)
本文提出了一種實(shí)用的內(nèi)存系統(tǒng)方案HPS,用以作為RMB方法的實(shí)現(xiàn).該方案混合使用了PCM和MRAM作為存儲(chǔ)芯片.MRAM與PCM類似,速度較快且具有更長(zhǎng)的寫入壽命,但存儲(chǔ)密度較低,因此MRAM適合小規(guī)模的部署于關(guān)鍵位置.
HPS系統(tǒng)的結(jié)構(gòu)分為控制器和存儲(chǔ)芯片2個(gè)部分,如圖6所示.控制器部分包含8個(gè)64 b的修改計(jì)數(shù)器作為MC的實(shí)現(xiàn),1個(gè)3 b的寄存器作為MCI的實(shí)現(xiàn).此外,8個(gè)8 b的PCM芯片將被作為MSC,1個(gè)12 b位寬的MRAM技術(shù)構(gòu)成ASC,包括8 b的數(shù)據(jù)域、3 b的標(biāo)志域和1 b的有效域.為了鑒別被修改的字節(jié),該方案使用了比較后寫入的方法DCW.該方法在寫入前會(huì)比較待寫入數(shù)據(jù)和目標(biāo)地址已有數(shù)據(jù),并僅寫入相異位.
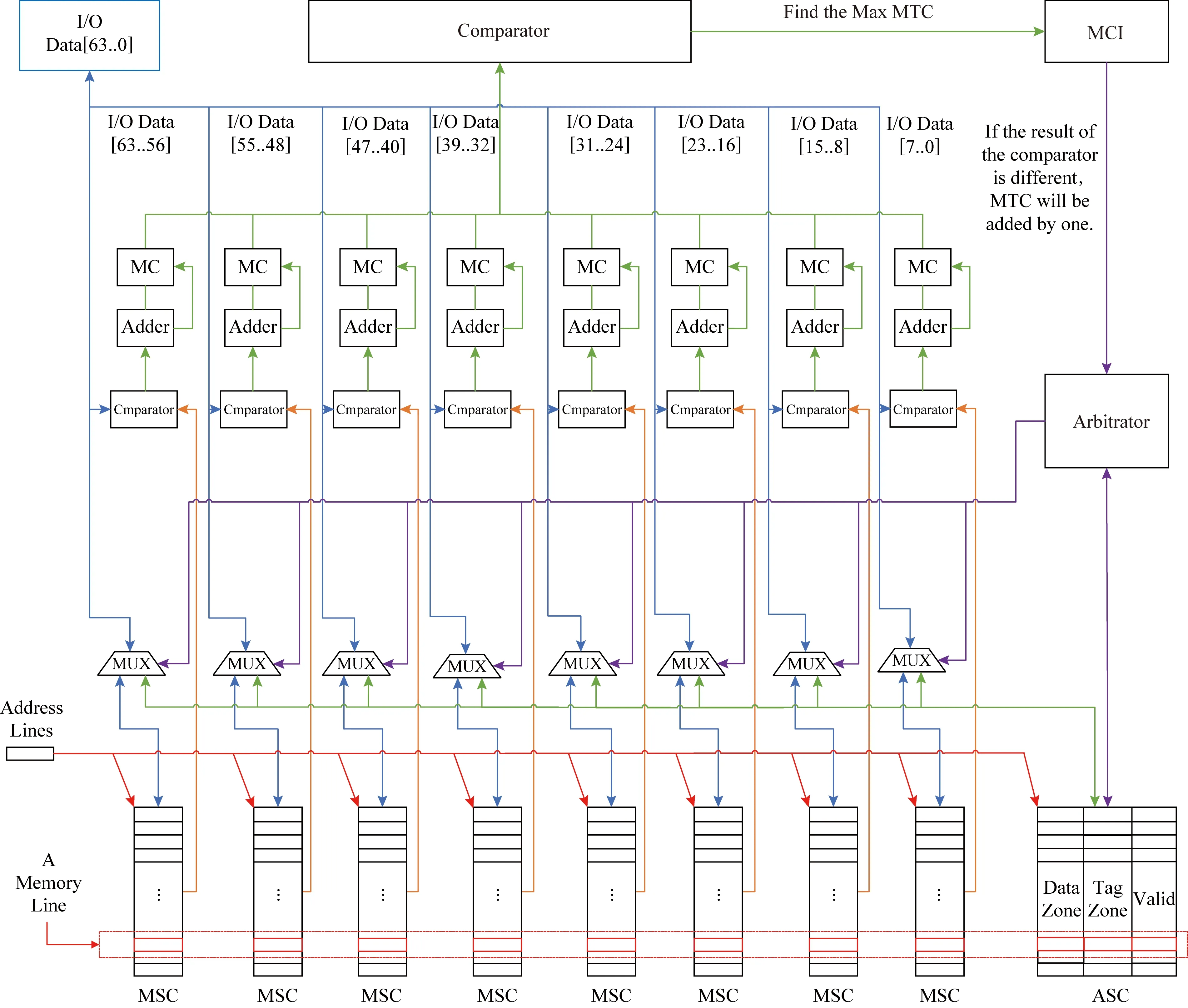
Fig.6 Hardware structure of HPS圖6 HPS的硬件結(jié)構(gòu)
4.2 測(cè)試配置
通過在GEM5模擬器中運(yùn)行測(cè)試應(yīng)用,并記錄其讀寫請(qǐng)求,可以獲得這些應(yīng)用的內(nèi)存訪問蹤跡,包括訪問地址和新/舊數(shù)據(jù).在獲得這些數(shù)據(jù)后,HPS系統(tǒng)可以計(jì)算出每個(gè)存儲(chǔ)芯片的修改次數(shù).本文采用SPEC2006[18]應(yīng)用來測(cè)試HPS的性能.各應(yīng)用的特性如表1所示,且均使用默認(rèn)配置.PCM芯片默認(rèn)可以承受106次寫入操作,而MRAM默認(rèn)可以承受1012次寫入操作.測(cè)試平臺(tái)的主要配置參數(shù)如表2所示.此外,存儲(chǔ)核心的制造差異在本文中不作考慮,并假定整個(gè)內(nèi)存的可用性取決于每一個(gè)存儲(chǔ)位的可用性,即:如果任何一個(gè)存儲(chǔ)位到達(dá)寫入上限,則整個(gè)內(nèi)存被認(rèn)為進(jìn)入了故障狀態(tài).
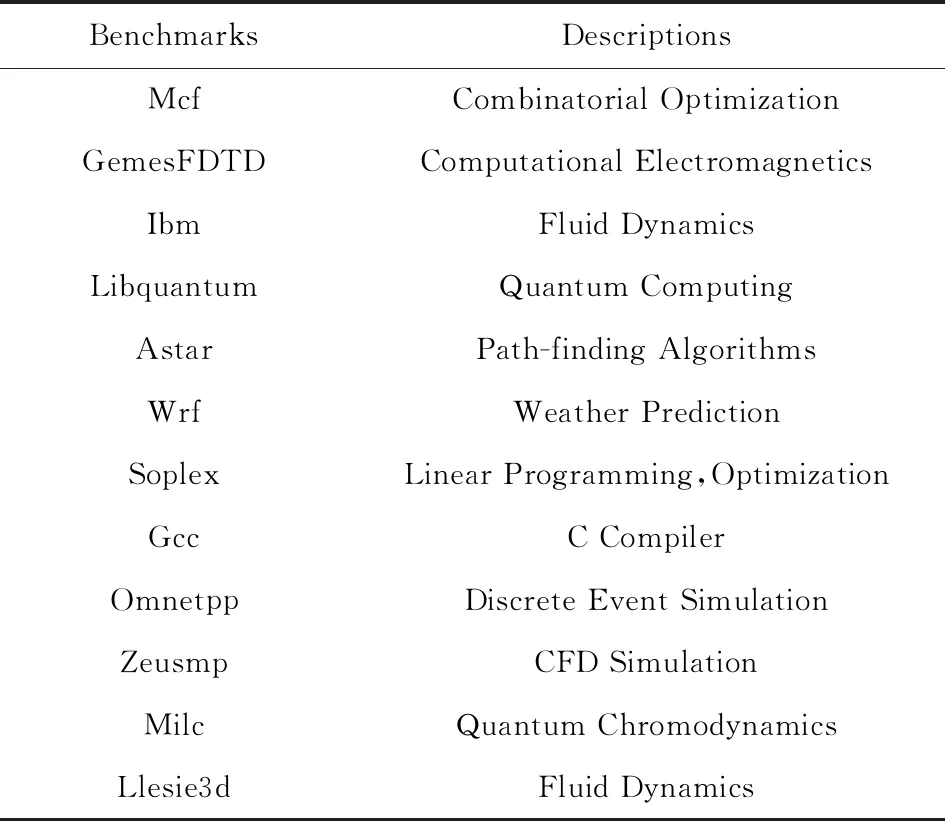
Table 1 SPEC2006 Benchmarks Introduction[18]表1 SPEC2006測(cè)試程序介紹[18]

Table 2 Configuration表2 測(cè)試平臺(tái)配置
為了衡量HPS的寫入均衡能力,本文采用理想均衡方法ILM和Start-Gap,與HPS系統(tǒng)進(jìn)行對(duì)比.理想均衡方法代表了磨損均衡方法的理論上限,Start-Gap方法則是一種易于實(shí)現(xiàn)的經(jīng)典磨損均衡方法.為了公平比較,本文在Start-Gap方法的思想上進(jìn)行了一定的修改.原始Start-Gap方法在內(nèi)存地址之間留了一個(gè)移動(dòng)數(shù)據(jù)用的間隙(gap),而本文實(shí)現(xiàn)的Start-Gap方法,為每個(gè)內(nèi)存行定義了一個(gè)循環(huán)隊(duì)列,該隊(duì)列包含各個(gè)存儲(chǔ)芯片的對(duì)應(yīng)行.因此,該方法需要一個(gè)和ASC的數(shù)據(jù)域同樣大小的存儲(chǔ)空間作為Gap,需要和ASC的標(biāo)志域同樣大小的存儲(chǔ)空間存放Gap的位置標(biāo)號(hào).采用Start-Gap方法將和HPS系統(tǒng)的實(shí)現(xiàn)代價(jià)非常接近,因此兩者的對(duì)比是公平合理的.
為了衡量RMB方法的寫減少效果,本文使用典型的寫減少方法FNW和PRES作為對(duì)比方案.為了保持硬件開銷的公平性,F(xiàn)NW方法的翻轉(zhuǎn)狀態(tài)標(biāo)志位為8 b,即每8 b的數(shù)據(jù)對(duì)應(yīng)1個(gè)翻轉(zhuǎn)狀態(tài)標(biāo)志位.PRES方法的編碼向量編號(hào)為8 b,即使用28個(gè)候選向量.
比較壽命時(shí),本文采用的方法:將采集的各個(gè)測(cè)試程序的訪存蹤跡模擬寫入PCM存儲(chǔ)單元,記錄其被改變的次數(shù).此時(shí),某個(gè)存儲(chǔ)單元上的最高改變次數(shù)被認(rèn)為是該程序造成的最大寫入計(jì)數(shù),并以其倒數(shù)作為壽命.同樣的過程應(yīng)用于不同的壽命延長(zhǎng)方法,包括RAW等參考系統(tǒng).然后,以RAW方法下的壽命為1,對(duì)所有數(shù)據(jù)做歸一化處理能得到各個(gè)方法的歸一化壽命延長(zhǎng)結(jié)果.
4.3 與經(jīng)典磨損均衡方法的對(duì)比
與不采用任何壽命延長(zhǎng)方法的內(nèi)存相比,HPS系統(tǒng)可以延長(zhǎng)其壽命多達(dá)7.9倍,如圖7所示.特別是對(duì)于片間磨損局部性較強(qiáng)的應(yīng)用,如mcf,libquantum,HPS的表現(xiàn)甚至優(yōu)于ILM.然而,對(duì)于芯片間的修改概率差別較小的應(yīng)用,如lbm,soplex,gcc,HPS系統(tǒng)比ILM略有差距.但理想均衡方法是此類方法的理論上限,一般的磨損均衡方法是無法達(dá)到這一性能的.因此,在大多數(shù)情況下,HPS系統(tǒng)優(yōu)于Start-Gap方法.
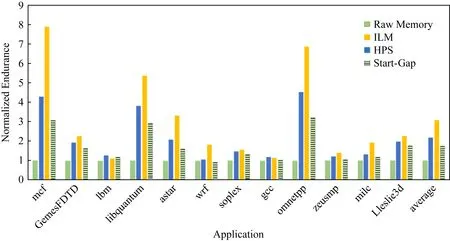
Fig.7 Endurance comparison among 4 methods圖7 4種方法下的相變內(nèi)存壽命比較結(jié)果
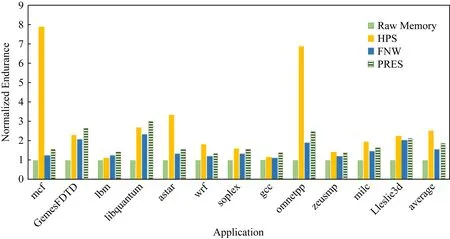
Fig.8 Endurance comparison among 4 methods圖8 4種方法下的相變內(nèi)存壽命比較結(jié)果
4.4 與經(jīng)典寫減少方法的對(duì)比
對(duì)于那些片間磨損局部性較強(qiáng)的程序,如mcf,libquantum,omnetpp而言,HPS系統(tǒng)的表現(xiàn)優(yōu)于FNW方法,對(duì)比結(jié)果如圖8所示,其原因在于FNW的起效條件.FNW方法僅在相鄰寫入數(shù)據(jù)的相異位數(shù)量超過字長(zhǎng)一半的情況下才會(huì)生效,否則該方法將等同于DCW方法.因此,對(duì)每次翻轉(zhuǎn)位數(shù)較少的程序而言,F(xiàn)NW方法難以奏效.
HPS系統(tǒng)也優(yōu)于經(jīng)典的寫減少方法PRES.究其原因,對(duì)于片間磨損局部性較強(qiáng)的程序,前后相繼的2個(gè)寫入數(shù)據(jù)一般也具有較少的相異位.由于PRES方法只能保證無偏數(shù)據(jù)集上的平均寫入量減少效果最優(yōu),而無法保證在數(shù)據(jù)集有偏的條件下,特別是相鄰寫入數(shù)據(jù)相異位較少時(shí)的效果.在這種情況下,PRES的隨機(jī)映射機(jī)制,可能反而會(huì)增加相鄰寫入數(shù)據(jù)的相異位.如圖8所示,HPS系統(tǒng)比經(jīng)典的PRES方法可以最多延長(zhǎng)達(dá)5.14倍的壽命.
4.5 實(shí)現(xiàn)代價(jià)分析
本文以存儲(chǔ)芯片數(shù)量作為衡量各方法實(shí)現(xiàn)代價(jià)的指標(biāo),并采用相對(duì)值進(jìn)行比較.一個(gè)典型的、不帶有任何壽命延長(zhǎng)方法的內(nèi)存系統(tǒng),通常是由8個(gè)8 b的存儲(chǔ)芯片構(gòu)成,即每個(gè)內(nèi)存行為64 b.以該系統(tǒng)將作為對(duì)比基礎(chǔ),其實(shí)現(xiàn)代價(jià)定為100%.
HPS系統(tǒng)在基礎(chǔ)系統(tǒng)之上,為每個(gè)內(nèi)存行添加8 b的存儲(chǔ)空間、3 b標(biāo)志域和1 b作為有效位.因此,其相對(duì)存儲(chǔ)代價(jià)為(64+8+3+1)/64×100%=118.75%.除此之外,HPS系統(tǒng)還需要8個(gè)64 b的全局修改計(jì)數(shù)寄存器,1個(gè)3 b的寄存器作為MCI,以及8個(gè)64 b的加法器對(duì)MC執(zhí)行加法操作.
Start-Gap方法同樣需要一個(gè)額外的存儲(chǔ)芯片作為Gap.因此每行內(nèi)存需要額外的8 b存儲(chǔ)空間作為Gap,以及3 b的Gap位置指針.因此,其存儲(chǔ)代價(jià)為(64+8+3)/64×100%=117.2%,略低于HPS系統(tǒng).
FNW和PRES方法同樣需要額外的存儲(chǔ)空間.這2種方法均采用每64 b的存儲(chǔ)空間附加8 b標(biāo)志位的方式實(shí)現(xiàn),因此其對(duì)應(yīng)的存儲(chǔ)代價(jià)為112.5%.
4.6 讀寫時(shí)間影響分析
RMB方法的讀操作比其它正常的讀取流程來說,多加了一個(gè)ASC有效域的檢查步驟,即單個(gè)位是否為1的檢查.鑒于PCM存儲(chǔ)器的讀取時(shí)間比DRAM要長(zhǎng)得多,因此,這一檢查步驟完全可以利用讀取延遲隱藏.之后的數(shù)據(jù)選擇傳輸過程可以采用多個(gè)2選1選擇器實(shí)現(xiàn).如圖6所示,RMB方法的讀取過程,額外需要1個(gè)選擇器.而由其帶來的延遲遠(yuǎn)小于PCM器件的讀取延遲,幾乎可以忽略.
RMB方法的寫入過程稍顯復(fù)雜.最長(zhǎng)的寫入路徑包括了ASC的標(biāo)志域和有效域的2次檢查、MCI、標(biāo)志域和有效域的寫入.但是PCM技術(shù)的寫入延遲更大,幾乎可達(dá)讀取延遲的10倍左右.因此,增加的寫入時(shí)間延遲,在總的時(shí)間延遲中所占的比例很小.
5 對(duì)RMB方法的進(jìn)一步討論
本文介紹了RMB方法的工作流程、實(shí)現(xiàn)、性能以及實(shí)現(xiàn)代價(jià).為了更好地研究這一方法,本節(jié)將對(duì)其做進(jìn)一步的討論.
RMB方法可以類比于cache系統(tǒng).cache系統(tǒng)基于時(shí)空局部性,根據(jù)訪問地址的被訪問頻度決定是否緩存該地址內(nèi)的數(shù)據(jù),且緩存的最小單位是本文中定義的一個(gè)內(nèi)存行;而RMB方法是建立在片間磨損局部性的基礎(chǔ)上,根據(jù)被修改芯片的寫入計(jì)數(shù)來決定是否緩存該位置,且緩存的最小單位是一個(gè)字節(jié).
RMB也是一種使用緩存的方法,本文提出的RMB方法,僅設(shè)計(jì)為跟蹤一個(gè)存儲(chǔ)芯片,這是基于實(shí)現(xiàn)代價(jià)的考慮.因此其必然存在由于容量限制而導(dǎo)致的替換發(fā)生.對(duì)發(fā)生在同一內(nèi)存行的多個(gè)位置上的寫入,這一設(shè)計(jì)處理能力是不足的.但如果放寬實(shí)現(xiàn)代價(jià)限制,那么RMB方法完全可以擴(kuò)展為采用多個(gè)ASC芯片的實(shí)現(xiàn)方式,且其主要組成和工作流程非常相似.這種擴(kuò)展的RMB方法稱為RMBK,其中參數(shù)K代表采用了K個(gè)ASC芯片.RMBK方法盡管代價(jià)較高,但可以跟蹤并轉(zhuǎn)移同一內(nèi)存行中K個(gè)存儲(chǔ)位置發(fā)生的改變,從而更好地提高PCM內(nèi)存的壽命.
此外,RMB方法對(duì)2個(gè)存儲(chǔ)芯片交替寫入而導(dǎo)致的顛簸現(xiàn)象也有一定的防御能力.首先,顛簸現(xiàn)象實(shí)際上在RMB系統(tǒng)中也是不容易出現(xiàn)的.其原因是:1)要達(dá)到顛簸狀態(tài),先要求2個(gè)存儲(chǔ)芯片的總寫入計(jì)數(shù)完全一樣,否則只會(huì)繼續(xù)磨損那個(gè)計(jì)數(shù)值較小的芯片;2)交替寫入的內(nèi)容必須出現(xiàn)在同一內(nèi)存行中,否則,會(huì)被2個(gè)不同行上的ASC分別吸收.之后,某一內(nèi)存行的頻繁寫入操作會(huì)導(dǎo)致該內(nèi)存行被長(zhǎng)期緩存在上級(jí)cache中,也就是說這些寫入操作事實(shí)上都是發(fā)生在cache中,而幾乎不會(huì)發(fā)生在內(nèi)存一級(jí).綜上所述,以上這些條件限制了顛簸出現(xiàn)的可能性,因此避免了在實(shí)際程序中遇到這類問題.而且,即使在出現(xiàn)顛簸的情況下,RMB方法也仍然能夠使用ASC芯片來吸收至少一半的寫入量.
6 結(jié) 論
針對(duì)相變內(nèi)存寫入壽命不足的問題,本文首先在結(jié)合內(nèi)存系統(tǒng)結(jié)構(gòu)的基礎(chǔ)上,分析并提出了片間磨損局部性的概念,并指出該局部性是導(dǎo)致相變內(nèi)存壽命損失的一個(gè)重要原因.為了解決這一局部性帶來的問題,本文提出了一種稱為RMB的相變內(nèi)存壽命延長(zhǎng)方法.通過關(guān)閉已承受最多磨損芯片上的未來寫入,并將這些寫入轉(zhuǎn)移到附加的長(zhǎng)壽命存儲(chǔ)芯片中,該方法兼具了寫減少和磨損均衡的效果.實(shí)驗(yàn)證明,其壽命延長(zhǎng)的能力在某些情況下甚至優(yōu)于理想磨損均衡算法.此外,該方法也可以方便地與其他壽命延長(zhǎng)方法相互結(jié)合,更好地延長(zhǎng)存儲(chǔ)器的寫入壽命.
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
