基于相鄰和語義親和力的開放知識圖譜表示學習
2019-12-18 07:22:22杜治娟杜治蓉
計算機研究與發展 2019年12期
杜治娟 杜治蓉 王 璐
1(內蒙古大學計算機學院 呼和浩特 010021)2(北方工業大學信息學院 北京 100144)3(中國科學技術信息研究所 北京 100038)(nmg-duzhijuan@163.com)
知識圖譜[1](knowledge graph,KG)是一種多關系圖,節點由實體組成,邊由不同類型的關系構成.邊的實例是事實三元組〈頭實體,關系,尾實體〉(表示為〈h,r,t〉).例如〈愛因斯坦,作者,相對論〉表示“愛因斯坦是相對論的作者”.作為大數據時代最重要的知識表示方式和驅動力,KG可以打破不同場景下的數據隔離,為查詢、推薦、預測等實際應用提供基礎支持[2].隨著應用對語義計算的青睞,將KG中實體和關系轉換到低維向量空間的表示學習方法也備受青睞[3-4].典型的方法如TransE[5],ComplEx[6],ConvE[7],它們存在2個共同的缺陷:
1)前提假設與現實不符.大多數方法假定KG滿足閉合世界假設(closed-world assumption,CWA)[8].這就要求所有實體一次性都出現,這對于真實世界的KG來說是不實際的.現實中每天都會有新實體出現,比如DBpedia每天都會有超過200個新實體出現[9].對于這一問題目前有2種解決方案[4].第1種是當新實體出現時重新訓練所有數據,顯然效率低下和不切實際,特別是遇到大規模KG時;第2種是利用文本知識輔助實體學習,但并非每個實體在現實中都有相應的文本知識.
2)采用復雜的語義交互提高準確性.通常,準確性高的模型,語義交互方式也比較復雜.例如對于圖1,TranR[10]認為實體t1,t2,t4語義相似,t5,t6語義不同,為同一關系鏈接的所有實體設置一個投影矩陣(如Mr1t1,Mr1t2,Mr2t5)來聚攏語義.TransD[11]認為投影矩陣也與實體本身有關,為每個實體也建立了一個投影向量.ConvE[7]認為所有的實體都可能相關,采用二維CNN來捕捉實體和關系之間的語義交互.雖然它們可以提高模型的精度,但矩陣向量乘法或卷積運算也大大增加了訓練時間.
為了解決以上問題,首先分析表示學習原理:表示學習模型通過更新實體和關系的初始隨機向量來學習它們的向量表示.因此,任何新的實體只能用初始隨機向量表示,因為新實體未經過訓練,不會通過其他任何實體推理得到.一個自然的想法是用實體間的鏈接結構推斷新實體(1)本文所說的新實體是指僅有新實體本身不在KG中,它所在的任意三元組中的其他2個元素都在KG中的情況.,例如圖1中的新實體IsaacNewton用它的鄰居(關系,實體)對(work_place,RoyalSociety),(occupation,Physicist)和(live_in,London)聯合表示.實際上是可行的,如表1所示.
在數據庫表中,一行代表一個實體、一列代表一個屬性.圖1中如果對實體enew(表1行2)操作,相當于把t1,e1,t6看作是enew的屬性,輔助enew;如果對表1中r1列操作,對應到圖1,即固定r1求與r1鏈接的所有尾實體.可以看出,屬性可以幫助解釋推理實體.這啟發我們用鄰居(實體,關系)來推斷新實體.然而,并非每個鄰居都能提供幫助,例如在研究physicist時,doctor degree的貢獻很小,但the representative work theory of relativity起著決定性的作用.因此,鄰里關系是非常重要的.
在建模時為了增強語義交互而采用的矩陣映射和卷積運算是利用了實體的鏈接結構對實體進行了語義聚焦.與這一功能等價的操作在模型學習(基于邊界的排序準則)過程中也有,即負例采樣(將給定三元組中的頭或尾實體替換為其他實體,構成新的三元組).從圖1的觀察來看,一個關系鏈接的頭/尾實體只能屬于特定的語義域.當替換的實體來自其他語義域時,模型很容易產生零梯度,進而阻礙實體關系向量表示的學習,而不是優化算法.如圖2所示,在訓練過程中,傳統負例采樣時通常會選擇點線橢圓圈中的三元組,很容易超出邊界,產生零梯度.因此,忽略了邊界內的一些負例三元組,如實線橢圓圈所示.為此,可以將語義交互轉化為基于語義的負例采樣方法,即根據語義級別選擇負例,如圖1中的t1和t2處于一個語義級別,t1和t4在另一個語義級別,語義級別表示為語義親和力.

Fig.2 A running example of the vanishing gradient圖2 梯度消失運行示例
基于上述觀察結果,我們提出了一種基于鄰居和語義親和力感知的開放KG表示學習方法——TransNS.其主要貢獻總結有4個方面:
1)針對開放KG表示學習任務,設計了相應的表示學習方法TransNS;
2)選取相關的鄰居作為實體的屬性來解釋推斷新實體,相關性由關注機制保證;
3)提出語義親和力的概念,并采用基于語義親的負例采樣方法SA代替語義矩陣映射和卷積;
4)為了評估所提方法,設計了8個新數據集和1個新的評估任務-解釋性可視化.
1 問題形式化定義
在本文中,一個新的實體意味著它不可能在KG中或者訓練數據集中出現.在閉合KG中永遠不會有新實體;在開放KG中肯定會有新實體,且新實體與KG中至少1個實體和1個關系有直接鏈接關系.表示學習(representation learning)也叫做嵌入(embedding),即符號表示向量化.面向閉合KG的表示學習記為CKGE(closed knowledge graph embedding).面向開放KG的表示學習記為OKGE(open knowledge graph embedding).文本被描繪成一系列的詞.有文本參與的KG表示學習稱為文本輔助的KG表示學習.與給定實體直接鏈接的(關系,實體)對稱為該實體的鄰居.本文使用的基本數學符號如表2所示:

Table 2 Mathematical Notations Used in the Paper表2 文中使用的數學符號
表2中〈h,r,t〉表示三元組,e={h,t}表示實體,即頭實體h和尾實體t都是實體,可以統一同e表示,r表示關系,它們的列向量用黑斜體小寫字母表示,矩陣用黑斜體大寫字母表示,下標p表示映射.
形式化定義如定義1~5.
定義1.知識圖譜G.知識圖譜(knowledge graph,KG)是一個有向圖,記為G={E,R,T},節點是實體,邊對應于〈h,r,t〉三元組事實.〈h,r,t〉的每條邊r表示存在從h到t的關系r.E和R分別表示實體集合和關系集合,T表示一組事實三元組.
因此,知識圖譜KG也可以表示為G={E,R,T}={〈h,r,t〉|h,t∈E,r∈R}.
定義2.新實體enew.如果實體enew不在KG中,或者不在訓練數據集Δtrain中,但在測試集Δtest中,則實體enew={e|e?G∪(e?Δtrain∩e∈Δtest)}稱為新實體.
新實體有時也叫缺席實體或者零樣本實體.
定義3.閉合KG.給定KGGC={E,R,T},如果!?enew或者?e={e|e∈E∪(e∈Δtrain∩e∈Δtest)},則GC稱為閉合KG,記為CKG(closed knowledge graph).
根據定義2,閉合KG也可以寫為GC={〈h,r,t〉|h,t≠enew,h,t∈E,r∈R,〈h,r,t〉∈T}.
定義4.開放KG.給定KGGO={E,R,T},e∈{〈e,rG,eG〉,〈eG,rG,e〉},rG∈R,eG∈E,如果?e={e|e=enew∪e?E∪(e?Δtrain∩e∈Δtest)},則GO稱為開放KG,記為OKG(open knowledge graph).
根據定義2,開放KG也可以寫為GO={〈h,r,t〉|?(〈hr,t〉∈T∩((h=enew∩t∈E∩r∈R)∪(t=enew∩h∈E∩r∈R)))}
閉合KG基于閉合世界假設(closed-world ass-umption,CWA)的;開放KG基于世界假設(open-world assumption,OWA).
定義5.語義映射SP.給定一個KGG={E,R,T},r∈R,e∈E,與實體e直接鏈接的關系r表示為r→e.關系r的頭實體h表示為h→r,關系r的尾實體t表示r→t.ri,rj和ei,ej,i≠j表示不同的關系和實體.語義投射是對語義相似的實體進行語義聚攏操作.語義聚攏也叫投影,是一種線性變換.對于每個實體e={ei|ei→ri∪ri→ei},投影實體表示為eip=Mriei.每個關系ri都有一個投影矩陣Mri.鏈接到同一關系ri的所有實體e={ei|ei→ri∪ri→ei}共享矩陣Mri.
2 相關工作
KG表示學習中最經典的方法是TransE[5]和RESCAL[12].TransE[5]的核心思想是向量空間中詞匯語義的平移不變性,而RESCAL[12]則基于向量的雙線性組合,如圖3所示:
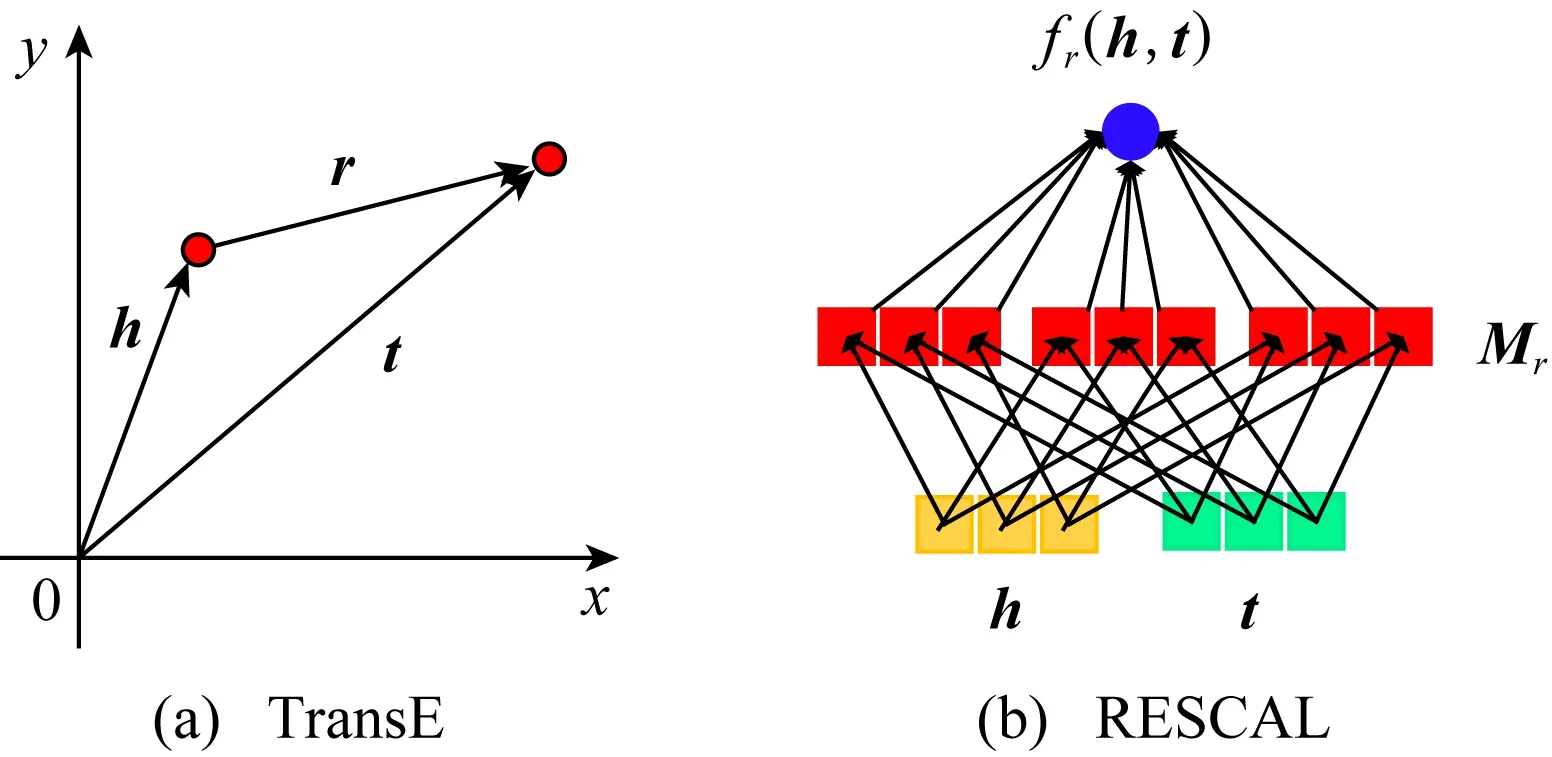
Fig.3 The modeling principles of TransE and RESCAL圖3 TransE和RESCAL的建模原理
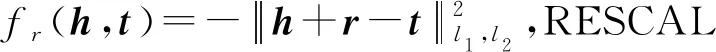
2種模型的原理都很簡單,但兩者都有缺點.TransE[5]非常擅長建模1-to-1關系,但在處理1-to-n,n-to-1和n-to-n復雜關系方面沒有優勢(2)對于每個關系r,平均鏈接的頭實體h(或者尾實體t)的平均個數低于1.5,則參數被標記為1,否則為n..因為,當一個關系r鏈接多個實體ek,k=1,2,…,i,…,j,…時會出現多個實體重合的情況,即ei=ej,i≠j.同理,當2個實體間有多重關系時,多個關系也會重合.RESCAL[12]有很多參數,因為它有矩陣向量乘法,且優化整個Mr.為了打破這些限制,它們有許多變種.
基于RESCAL[12],LFM[15]僅優化非零元素,DistMult[16]使用Mr的對角矩陣來減少參數,但這種方法只能建立對稱關系.為了解決這個問題,ComplEx[7]用復數代替實數,并在計算雙線性映射之前采用尾實體嵌入的共軛,三元組的得分是雙線性映射輸出的實數部分.ComplEx[7]的等價物是HolE[17],它使用點積代替張量積,并采用h和t之間的循環相關來表示實體對,即
HolE[17]在非交換關系和等價關系上優勢很大,并且可以通過快速傅里葉變換加速計算.
此外,還有繼承了平移原理與雙線性原理優勢的EAE[18];利用神經網絡原理的SME[19],SLM[20],NTN[20],ProjE[21]和ConvE[7],它們需要大量三元組參與訓練,并不適合稀疏的KG[5];利用路徑知識輔助學習的PTransE[22],PaSKoGE[23],Gaifman[24],CKRL[25],它們需要選擇合適的路徑;利用文本知識輔助學習的方法DKRL[26],TEKE[27],SSP[28],它們需要額外的文本知識,這一點實際中實現起來較困難,因為并非每個實體在現實中都有相應的文本知識.
3 TransNS方法論
為了適應新實體和降低語義交互的代價,我們選取相關的鄰居作為實體的屬性來推斷新實體,并在學習階段利用實體之間的語義親和力選擇負例三元組來增強語義交互能力,而不是在建模時執行語義投影和卷積操作.這種方法被命名為TransNS,模型框架和評分原則如圖4和5所示:
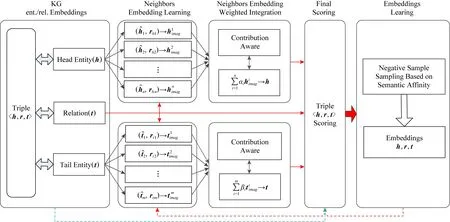
Fig.4 TransNS embedding learning framework圖4 TransNS表示學習框架
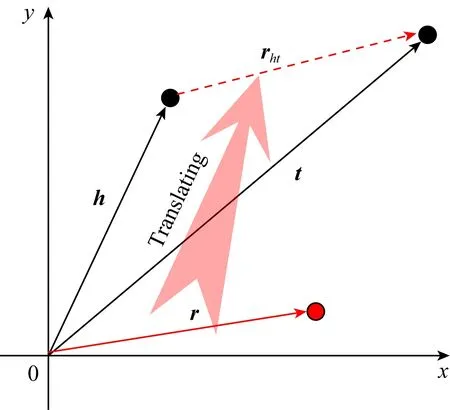
Fig.5 Scoring principle of SAL圖5 SAL打分原則
圖4包括2個關鍵組件:1)基于語義親和力的負例三元組采樣;2)將鄰居集成到實體嵌入學習過程.這2個組件不是獨立的,而是相互驅動的.前者貫穿始終,直到后者完成為止.后者分為2個階段:1)依據鄰居解釋學習實體的表示;2)度量待測三元組的可信度.
3.1 基于語義親和力的嵌入
圖1表明,實體之間的語義距離可以通過實體之間的鏈接結構來粗略區分,這種粗略的語義距離被定義為語義親和力(semantic affinity,SA).SA分為5個級別,即L1-SA,L2-SA,L3-SA,L4-SA,L5-SA,如圖6和定義6~10所示.

Fig.6 An example of the five levels of semantic affinity圖6 語義親和力的5個級別示例
鏈接結構表示為:給定一個KGG={E,R,T}={〈h,r,t〉|h,t∈E,r∈R}.直接鏈接被表示為r→e,否則表示為r↑e.(e1,r)直接鏈接到e2表示為(e1,r)→e2,否則表示為(e1,r)↑e2.ri,rj和ei,ej,i≠j表示不同的關系和實體;h→r→t表示關系r鏈接的頭尾實體.
定義6.一級語義親和力L1-SA.給定2個三元組:〈hi,ri,ti〉,〈hi,ri,tj〉∈G,?(hi,ri)→ti∩(hi,ri)→tj,如圖6(a)所示,則稱ti和tj滿足一級語義親和力L1-SA.
定義7.二級語義親和力L2-SA.給定2個三元組:〈hi,ri,ti〉,〈hj,ri,tj〉∈G,?hi→ri→ti∩hj→ri→tj,如圖6(b)所示,則稱ti和tj滿足二級語義親和力L2-SA.
定義8.三級語義親和力L3-SA.給定2個三元組:〈hi,ri,ti〉,〈hi,rj,tj〉∈G,?hi→ri→ti∩hi→rj→tj,如圖6(c)所示,則稱ti和tj滿足三級語義親和力L3-SA.
定義9.四級語義親和力L4-SA.給定一個三元組:〈hi,ri,ti〉∈G,?hi→ri→ti,如圖6(d)所示,則稱hi和ti滿足四級語義親和力L4-SA.
定義10.五級語義親和力L5-SA.給定2個三元組:〈hi,ri,ti〉,〈hj,rj,tj〉∈G,?hi→ri→ti∩hj→rj→tj,hi≠hj,ri≠rj,ti≠tj,如圖6(e)所示,則稱ti和tj滿足五級語義親和力L5-SA.
由于實體之間存在語義距離,同一關系鏈接的頭或尾實體只能屬于特定的語義域.當替換的實體來自其他語義域時,模型很容易導致事實三元組和替換的三元組之間產生較大的能量差距.當超過能量間隔上限時,該替換的三元組將得不到訓練信號.相比之下,如果替換的實體來自相同的語義域,則情況會好一些.為此,替換的實體優先選擇具有強語義親和力的實體,這個方法叫做基于語義親和力的負例采樣,記為SA.這樣做可以替代語義投影和卷積計算實現實體的語義交互.然后評分函數僅使用輕量級的平移原理:
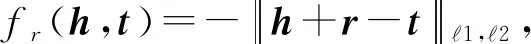
(1)
式(1)的原理如圖5所示.我們命名這個表示學習方法為SAL.
為了學習這個模型,我們將式(1)轉化為最優化問題,并在訓練集上使用基于邊界的對排序損失進行訓練:
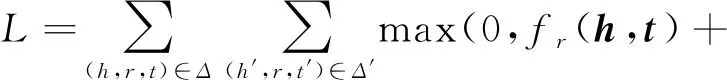
(2)
采用SGD[29]可以很容易地優化求解式(2).其中,γ是邊界,Δ和Δ′分別是正例集合和負例集合,Δ中的每個事實三元組〈h,r,t〉都來自訓練數據集,Δ′中的負例是由SA采樣策略從正例集合Δ中采樣產生:
Δ′={(h′,r,t)|h′∈E∪(h,r,t′)|t′∈E},
(3)
3.2 集成鄰居的解釋學習
TransNS使用鄰居增強表示學習的可解釋性和適應開放知識圖譜.實體e的鄰居是以e為頭實體的(關系,尾實體)對,形式化為定義11.
定義11.實體的鄰居.給定KGG={〈h,r,t〉|h,t∈E,r∈R},實體e∈E的鄰居是與其直接鏈接的(r,t)對的集合,記為N(e)={(r,t)|r∈NR(e),t∈NE(e),〈e,r,t〉∈G}.NE(e)是鄰居實體的集合,NR(e)是鄰居關系的集合,r是e的(出邊)關系,t是通過r與e直接相連的實體,即鄰居實體.
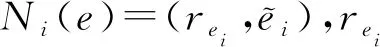
給定三元組〈h,r,t〉對,實體h的第i個鄰居的NCAαtti定義為
(4)
其中,Corr((r,t),Ni(h))是度量(r,t)和N(h)相關性的函數:
Corr((r,t),Ni(h))∝P((r,t)|Ni(h))(rTrhi),
(5)
P((r,t)|Ni(h))用于度量(r,t)和Ni(h)的相關性,rTrhi表示r和rhi的相關性.
在此基礎上,給出實體h通過鄰居學習向量表示的計算為
(6)
類似的方法可以獲得實體t的嵌入表示.接下來,使用從鄰居學習到的h,t和等待訓練的r一起進行培訓(如式(1)),以測量三元組〈h,r,t〉的可能性.
TransNS的整體訓練目標:
Loverall=Lneg+Ltri,
(7)
其中,Lneg與鄰居相關,由式(7)代替式(2)中的fr(h,t)得到,Ltri與三元組〈h,r,t〉相關,由式(2)得到,為了降低計算代價,這里借鑒負采樣法[30]對式(4)進行了合理的逼近.TransNS部署如算法1所示:
算法1.知識圖譜表示學習算法TransNS.
輸入:訓練集Δ、實體集E、關系集R、嵌入維度n、邊界γ和學習率α;
輸出:實體和關系的向量表示h,r,t.
② while not reach at loop number or optimal MR value do
③Δbatch←sample(Δ,b);/*采樣一個最小批量大小b*/
④Tbatch←?;/*初始化三元組對*/
⑤ for 〈h,r,t〉∈Δbatchdo;

/*通過SA采樣策略對三元組進行損壞采樣*/
⑦Tbatch←Tbatch∪{〈(h,r,t〉),(h′,r,t′)}
⑧N(e)←{(r,t)|r∈NR(e),t∈NE(e),〈e,r,t〉∈G}
/*構建實體e的鄰居*/
⑨ end for
⑩ Update embeddings w.r.t.
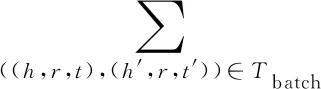
fr(h′,t′)]+;
算法2.SA:基于語義親和力的負例采樣策略.
/*以替換尾實體為例,替換頭實體類似*/
輸入:訓練集Δ、實體集E、關系集R、嵌入維度n、邊界γ和學習率α;
輸出:實體的嵌入表示t.
① for 〈h,r,t〉∈Δbatchdo;
② Givenh→r
③ ifL1-SA(t|h→r)≠? then
④corr_t=rand_max(L1-SA(t|h→r))
⑤ else if thenL2-SA(t|h→r)≠? then
⑥corr_t=rand_max(L2-SA(t|h→r))
⑦ else ifL3-SA(t|h→r)≠? then
⑧corr_t=rand_max(L3-SA(t|h→r))
⑨ else ifL4-SA(t|h→r)≠? then
⑩corr_t=rand_max(L4-SA(t|h→r))
/*對稱關系*/
corr_t=rand_max(entityTotal)
3.3 討 論
與其他代表性的KG表示學習模型相比,我們的SAL和TransNS有很多優勢.我們從7個方面對比各種典型模型,如表3所示.
在實體語義、關系鏈接實體的數量以及實體之間的鏈接結構等方面,TransE[5]和ComplEx[6]都沒有考慮其中的任何一個.TransD[11]考慮了L2-SA.ConvE[7]認為任何實體都是相互關聯的.TranSpars[14]在建模時會考慮到L4-SA和數量特性.我們的SAL和TransNS在訓練中使用了5級SA,取代了TransD[11],TranSparse[14]和ConvE[7]的語義投影和卷積.TransNS還利用鄰居來增強嵌入式學習的可解釋性.
就復雜性而言,TransE[5]和SAL最簡單,兩者都只有向量加法和減法.TranSparse[14],ComplEx[6]和ConvE[7]要復雜得多,它們具有矩陣向量乘法,尤其是ConvE[7]具有2D卷積運算.盡管TransD[11]沒有矩陣向量乘法,但它的每個實體都有一個投影向量.因此,它的復雜性與實體數量成正比.當然,最復雜的是TransNS,畢竟使用鏈接結構.但是,它對新實體的可解釋性和適應性是前所未有的.總的來說,SAL是平移表示學習的突破,TransNS有望將嵌入式學習推向現實世界.

Table 3 Comparison of Various Models From 7 Aspects表3 從7個方面對比各種模型
4 實驗與結果
我們通過在5個傳統數據集和8個新數據集(表3)上執行鏈接預測[5]、三元組分類[13]和鄰居選擇可視化任務評估我們的SAL和TransNS.選擇TransE[5],TransD[11],TransSparse(separate,US)[14],ComplEx[6]和ConvE[7]作為基準對比方法.
表4中#Rel,#Ent和#New分別表示關系、實體和新實體的數量.#Train、#Valid和#Test分別代表訓練集、驗證集和測試集.WN11,WN11-K,WN18,WN18RR來自于WordNet[31];FB15k,FB15K-K,FB15k-237來自于Freebase[32].WN11-K是WN11的子集;WN18RR是WN18的子集;FB15k-237和FB15K-K是FB15k的子集.WN18RR和FB15k-237從原始數據集中刪除了反向關系.
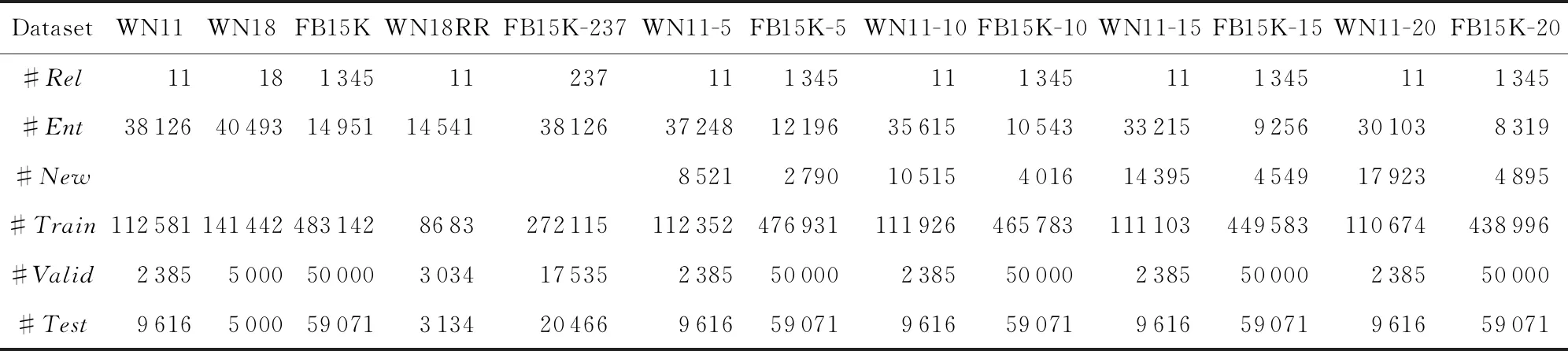
Table 4 Experimental Dataset Description表4 實驗數據集描述
在新數據集中,隨機抽樣原始測試集的5%,10%,15%,20%的樣例以形成新的測試集NewT.在NewT中,三元組的頭尾實體有且僅有一個實體不在訓練數據集中,并且頭尾中的新實體的比例相等.此外,過濾訓練數據集中沒有鄰居的實體.
4.1 部署和度量標準
對于所有數據集,采用小批量SGD[29]最多迭代訓練3 000次,嵌入空間維數d={50,100,200,250},學習率λ={0.0001,0.001,0.01},邊界γ∈[1,6]步長0.5,最小批量處理容量B={1,100,200},相似度用d={1,2}測量.我們采用3種常見的評估指標:平均排名(MR)、平均倒數排名(MRR)和Hits@10(即有效測試三元組在前10名中的比例)與過濾設置協議,即不考慮任何KG中出現的采用三元組.較低的MR、較高的MRR或較高的Hits@10表示更好的性能.最佳配置由驗證集上的MR值決定.
令T={x1,x2,…,x|T|}表示測試集.像TransE[5]一樣,對于T中第i個測試三元組xi,采用SA策略替換它的頭實體或者尾實體來生成所有可能的負例三元組Δh(xi)(或者Δt(xi)).并以此來檢查模型是否分配更高的得分給xi,低的得分給其負例三元組.如果KG中存在已替換的三元組,則該三元組也是正確的,因此在原始三元組之前對其進行排序并沒有錯.在獲得每個測試三元組的排序之前,我們刪除出現在訓練集、驗證集或測試集中所有替換的三元組.這在TransE[5]中稱為過濾設置.第i個待測三元組xi的頭尾排序分別與依據評分函數fr()替換的頭或尾實體相關:
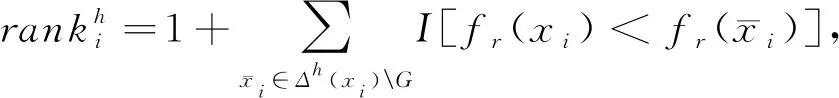
(8)
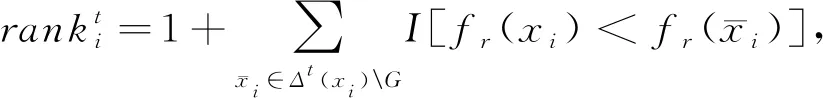
(9)
其中,I[P]=1當且僅當條件P為真,否則為0.評價指標平均排序(MR)、平均倒數排序(MRR)和Hits@k被定義為

(10)
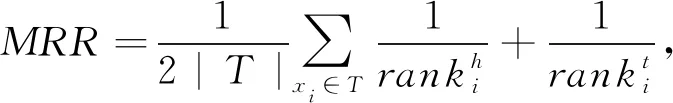
(11)
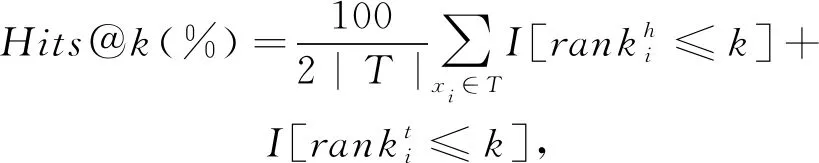
(12)
4.2 鏈接預測
鏈接預測的目的是預測一個給定事實三元組〈h,r,t〉丟失的頭實體h或尾實體t.此任務不需要一個最佳答案,而更多地強調對一組來自KG的候選實體進行排序.在傳統數據集上的結果如表5所示、新數據集的結果如表6所示.在表5中,由于實驗數據和設置是一致的,所以一些結果為原文發布的結果.Sparse表示TranSparse(separate,US).
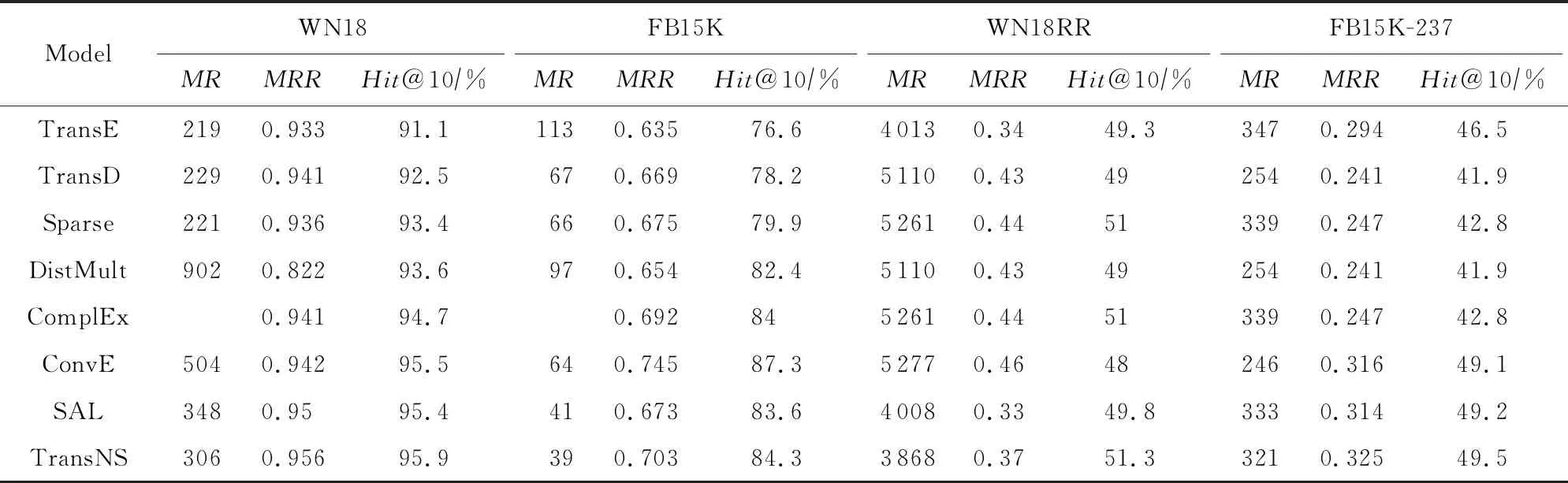
Table 5 The Results of Link Prediction on Traditional Datasets表5 傳統數據集的鏈接預測結果
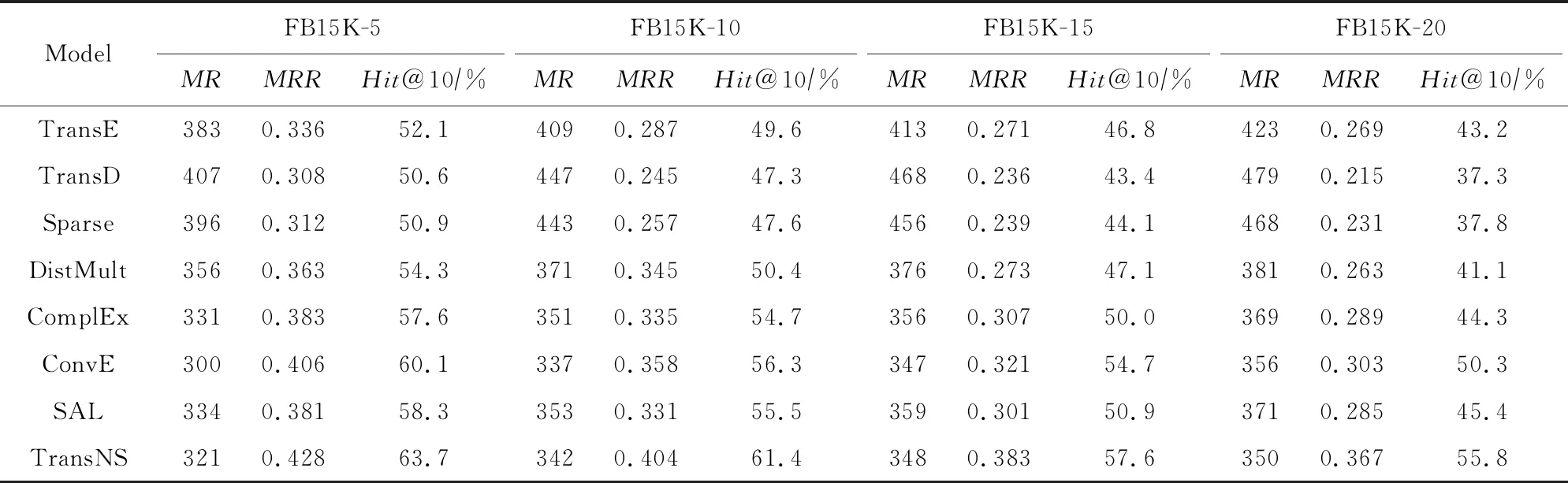
Table 6 Link Prediction Results for TransNS on New Datasets Containing New Entity表6 TransNS在包含新實體的新數據集上的鏈接預測結果
從表5中觀察到結論:SAL的準確性有了一定的提升.在這2個實驗數據集中,特別是在WN 18上,SAL接近或優于ConvE[7].在WN 18上,SAL獲得最高的MRR分數,在Hits@10上接近ConvE[7](低0.01%),且遠好于TransE[5]和TranSparse[14].而在MR上獲得了156的顯著改善.在FB15K上,SAL得到了最好的MR,我們可以在WN18RR和FB15K-237上得出同樣的結論.但也觀察到了一些變化.個別指標除外,SAL在幾乎所有指標中都得到最佳值.在這4種數據集上,SAL的預測準確性均優于TranSparse[14]和ConvE[7],可以解釋語義親和力的優勢.研究還表明,基于語義親和力的負例采樣在功能上與語義交互中的投影或卷積等價.
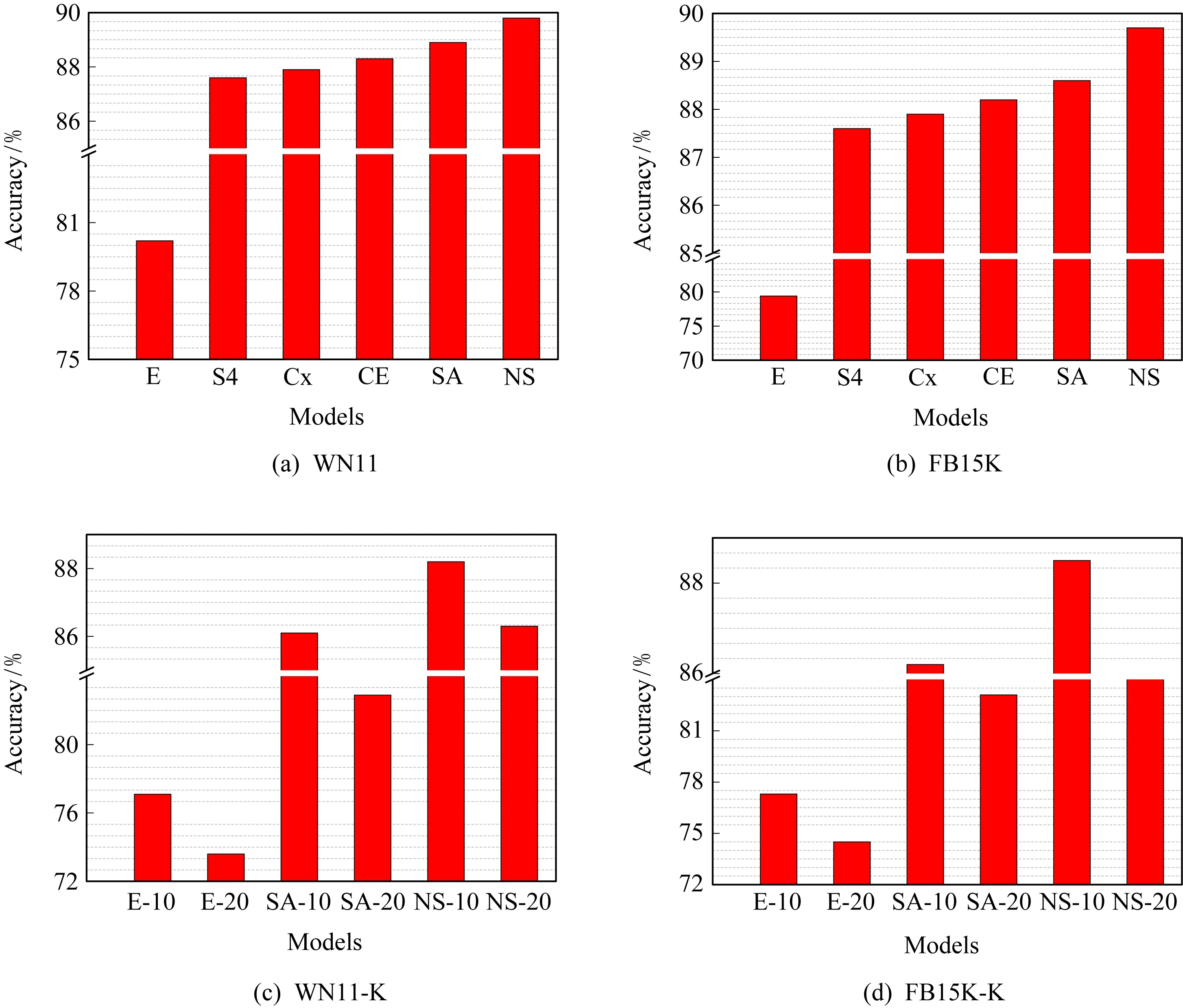
Fig.7 Triples classification accuracies (Prefix Trans is omitted from each model name)圖7 三元組分類結果(每個模型名稱中省略前綴Trans)
從表5和表6也可以看出TransNS的改善效果,尤其是表6.TransNS的Hits@10評分在WN 18上增加了0.4%~4.8%,在FB15K上MR值提高了2~64.在WN18RR上,TransNS的MR值最小,至少減少140.TransNS的MRR和Hits@10在FB15K-237上最高.就SAL而言,它在8個數據集的每個評價指標方面都有不同程度的改進.特別是在包含新實體的新數據集中,TransNS改進更為明顯.結果表明:鄰居不僅可以提高表示學習能力,而且可以適應新的實體,即可以很好地用于開放KG.
4.3 三元組分類
三元組分類屬于二元分類,其目的是判斷給定的三元組〈h,r,t〉是否正確.我們采用WN11,FB15K和它們的變種WN11-K和FB15K-K作為實驗數據集來評估模型的準確性.WN11-K和FB15K-K包含新的實體,因此它們只用于測試TransNS的準確性.TransE[5]提供的WN11的測試數據集包含正例和負例三元組.而其他數據集的測試集只包含正例三元組,這里采用文獻[14]的方法產生負例.對于驗證集,我們用SA策略替換尾(或者頭)實體來產生負例三元組.同時,替換后的三元組不能出現在驗證集中,否則重新按照SA采樣方法選擇替換實體.測試數據也進行同樣的操作.接下來,基于打分函數計算每個三元組的得分,并由閾值θ區分正確與否.θ由驗證數據集中正例與負例之間的距離最大得分決定.最后,如果一個三元組〈h,r,t〉的得分高于θ,則視為正確,否則視為錯誤.實驗結果如圖7所示.
圖7顯示了三元組分類結果,模型名稱采用縮寫形式.E和S4分別表示TransE[5]和TranSparse(separate,US)[14].Cx,CE,SA和NS分別表示ComplEx[6],ConvE[7],SAL和TransNS.圖7表明TransNS在所有數據集上具有明顯的優勢.例如,與所有基準方法相比,TransNS在WN11上增加0.9%~9.6%,在FB15K上增加0.9%~10.3%,在WN11-K上增加2.3%~11.5%,在FB15K-K上增加2.1%~12.7%,這證明了它采用的5級語義親和力和實體的鄰居是明智的.此外,就新實體的適應性而言,隨著新實體的增加,TransE[5]和SAL的表現將迅速下降,但TransNS則不會.這主要是因為新實體未經過訓練,仍然保留了TransE[5]和SAL的初始值.
除了TransNS和SAL,ConvE[7]是所有數據集中最好的.這是因為2D卷積相當于增加訓練迭代次數,而卷積運算以隱含的形式捕獲各種語義.它不如SAL好,因為實驗數據不是全連通的.此外,SAL屬于與TransE[5]和TranSparse[14]相同的類型(都屬于基于平移原理的嵌入表示),特別是與TransE[5]非常相似.實驗結果表明:TranSparse[14]在模型上的實體語義投影操作可以被基于語義親和力的負例三元組采樣方法所取代.與TransE[5]相比,SAL在3個數據集上的性能平均提高了9.93%.所有這些結果都可以證明我們論證的正確性.
4.4 基于關系感知的鄰居選擇案例研究
此實驗旨在確認鄰居相關性在預測三元組中的重要性,并可視化TransNS如何通過感知關系為鄰居指定權重.因此,從新數據集FB15K-K中選擇3個傳統方法不易準確預測的示例,如表7所示:
Table 7 The Visualization Result of Neighbors Selection Based on Relation Awareness
表7 基于關系感知的鄰居選擇的可視化結果
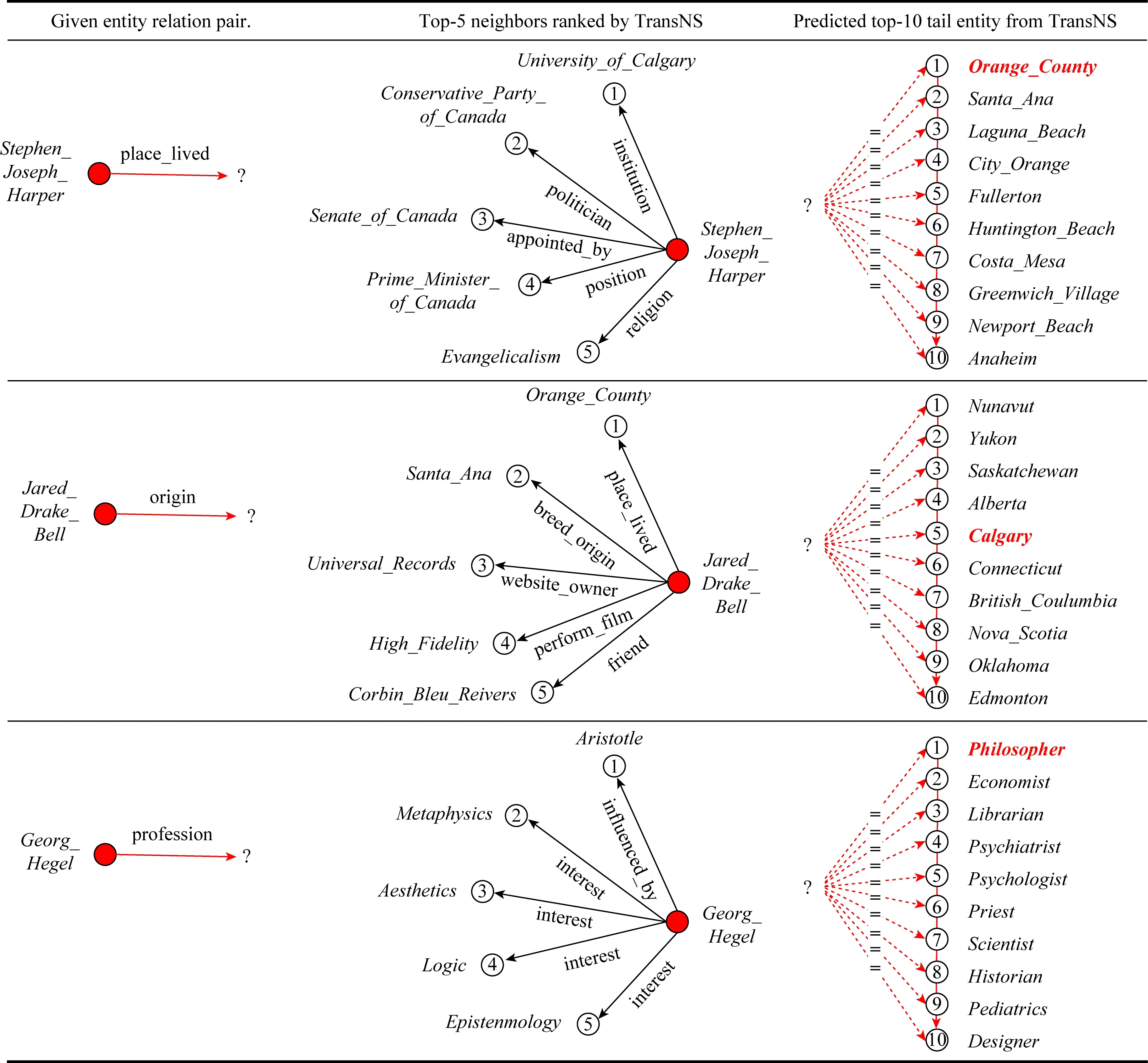
從表7所示的結果中,我們觀察到2個結論:
1)基于給定(關系,實體)對中的關系感知,TransNS可以給予更高相關性鄰居更大的權重.在第1種情況下,當給定關系place_lived時,只有一個鄰居與位置相關,但是這個鄰居在top-10中做出正確的結果也發揮了重要作用.在第2種情況下,當給定的關系是profession時,它的5個鄰居都表明它的職業是philosophy,它們有助于暗示關系來源.在第3種情況下,當給定的關系是origin時,它的前2個鄰居是(place_lived,Orange_County)和(breed_origin,Santa_Ana),它們也有助于暗示關系來源.但它的鄰居(friend,Corbin_Bleu_Reivers)獲得的權重最低,因為它們對于給定的關系來源沒有任何暗示.
2)TransNS可以將更大的權重分配給具有更多信息的鄰居實體.當給定的關系是profession時,最有影響力的鄰居是(influenced_by,Aristotle),比其他鄰居,如Metaphysics和Aesthetics與答案Philosopher更相關.在其他情況下,我們也觀察到類似的情況.其中,案例2和案例3中權重最大的鄰居分別是(institution,University_of_Calgary)和(place_lived,Orange_County),因為給定的place_lived和origin可以幫助TransNS聚焦于鄰居關系institution和place_lived,然后鄰居實體University_of_Calgary和Orange_County進一步確定了答案Orange_County.
5 總結與未來工作
本文針對開放KG提出了一種新的表示學習模型TransNS和SAL.SAL采用基于語義親和力的負例采樣方法捕獲KG中實體之間的語義,它將語義交互嵌入到訓練中,而不增加任何復雜性.TransNS集成集成了實體鄰居,可以適應開放KG.實驗結果表明:我們的模型優于其他模型.本文中的語義親和力僅通過實體之間的直接鏈接來識別.通常,不僅實體的直接鄰居可以幫助識別新實體,KG中還有許多間接鏈接,這些間接鄰居也可以起到輔助作用[33].未來工作中可以考慮在語義親和力測量中引入間接鏈接關系.此外,本文只考慮僅有新實體本身不在KG中的情況,其實還有2類情況:1)在一個三元組中新實體不在KG中,關系和另外一個實體有且僅有一個不在KG中;2)新實體所在的三元組中的3個元素都不在KG中,如何高效地解決后2種問題也是值得研究的.
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
開放教育研究(2020年2期)2020-03-31 01:54:14
現代語文(2016年21期)2016-05-25 13:13:44
山東青年(2016年1期)2016-02-28 14:25:25
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
