融合對(duì)抗訓(xùn)練的端到端知識(shí)三元組聯(lián)合抽取
2019-12-18 07:22:20黃培馨朱慧明肖衛(wèi)東
計(jì)算機(jī)研究與發(fā)展 2019年12期
黃培馨 趙 翔,2 方 陽 朱慧明,3 肖衛(wèi)東,2
1(國防科技大學(xué)信息系統(tǒng)工程重點(diǎn)實(shí)驗(yàn)室 長沙 410073)2(地球空間信息技術(shù)協(xié)同創(chuàng)新中心(武漢大學(xué))武漢 430079)3(長沙商貿(mào)旅游職業(yè)技術(shù)學(xué)院經(jīng)濟(jì)貿(mào)易學(xué)院 長沙 410073)(huangpeixin15@nudt.edu.cn)
知識(shí)圖譜描述現(xiàn)實(shí)世界中客觀存在的實(shí)體以及實(shí)體之間的關(guān)系[1].在知識(shí)圖譜中,一般用節(jié)點(diǎn)表示實(shí)體(entities),如人名、物品、地名等,用邊即實(shí)體之間的連線表示關(guān)系(relations),如位于、擁有等.知識(shí)由1個(gè)實(shí)體關(guān)系的三元組(triplets),即(頭實(shí)體,關(guān)系,尾實(shí)體)來表示,它是知識(shí)圖譜的基本單元.
諸如WordNet[2]等的大型知識(shí)圖譜為存儲(chǔ)、分析和利用海量的網(wǎng)頁文本信息提供了嶄新思路,支撐機(jī)器理解自然語言,被廣泛應(yīng)用于智慧搜索、自動(dòng)問答等智能信息服務(wù).然而,現(xiàn)有知識(shí)圖譜雖已包含數(shù)以萬計(jì)的事實(shí)知識(shí)實(shí)例,卻仍無法滿足現(xiàn)實(shí)世界的需要.補(bǔ)全現(xiàn)有的知識(shí)圖譜以及構(gòu)建新的知識(shí)圖譜都是當(dāng)前需要解決的關(guān)鍵問題.工程上構(gòu)建知識(shí)圖譜,往往有2種方式:自頂向下——先構(gòu)建本體(通過本體編輯器);自底向上——直接從信息(結(jié)構(gòu)化Freebase或半結(jié)構(gòu)化Wikipedia)中抽取知識(shí)[3].本文所研究的知識(shí)三元組抽取屬于自底向上來構(gòu)建知識(shí)圖譜.其基本思路是從非結(jié)構(gòu)化文本中抽取實(shí)體關(guān)系實(shí)例,處理抽取出的知識(shí)三元組以符合知識(shí)庫(1)本文不區(qū)分“知識(shí)圖譜”和“知識(shí)庫”2個(gè)概念,“知識(shí)圖譜”本質(zhì)是“知識(shí)庫”的一種呈現(xiàn)方式.規(guī)范,然后將其添加到知識(shí)庫中.具體而言,給定網(wǎng)頁新聞文本“美國總統(tǒng)特朗普將訪問史蒂夫保羅喬布斯創(chuàng)辦的蘋果公司”,知識(shí)三元組抽取技術(shù)可以自動(dòng)抽取出(美國,國家—總統(tǒng),特朗普)和(蘋果公司,公司—?jiǎng)?chuàng)辦者,史蒂夫保羅喬布斯)這2個(gè)三元組.其中,“國家—總統(tǒng)”和“公司—?jiǎng)?chuàng)辦者”這2個(gè)關(guān)系屬于預(yù)先定義好的關(guān)系標(biāo)簽[4].
現(xiàn)有的知識(shí)三元組抽取方法可以分為兩大類:流水線式方法和聯(lián)合抽取方法.其中,傳統(tǒng)的流水線式方法先進(jìn)行命名實(shí)體識(shí)別(Nadeau等人[5])然后進(jìn)行關(guān)系分類(Rink等人[6]).但這種方法存在錯(cuò)誤傳播、信息冗余、忽視了2個(gè)子任務(wù)之間的聯(lián)系等問題.而現(xiàn)有的聯(lián)合抽取方法中,基于語法分析的方法依賴專家知識(shí)且工作量大,基于特征工程的方法依賴外部NLP工具且需要復(fù)雜的特征設(shè)計(jì),基于神經(jīng)網(wǎng)絡(luò)的方法雖克服了以上問題卻沒有充分利用實(shí)體與關(guān)系之間的聯(lián)系而做到真正的聯(lián)合.
本文的研究針對(duì)現(xiàn)有方法存在的問題建立聯(lián)合模型.首先提出一種標(biāo)注策略,以往常用的方法如BILOU(Li和Ji[7];Miwa和Bansal[8])只對(duì)實(shí)體進(jìn)行標(biāo)注,沒有將實(shí)體和關(guān)系進(jìn)行關(guān)聯(lián),而本文提出的策略通過3段式的標(biāo)注可以同時(shí)暗示分詞的實(shí)體和關(guān)系屬性,將聯(lián)合抽取問題完全轉(zhuǎn)化為端到端的序列標(biāo)注問題.為實(shí)現(xiàn)輸入文本的標(biāo)注,本文搭建了基于長短時(shí)記憶網(wǎng)絡(luò)LSTM的端到端模型框架,充分挖掘LSTM神經(jīng)網(wǎng)絡(luò)處理長序依賴問題的優(yōu)勢(shì).編碼層采用雙向LSTM(bidirectional LSTM,Bi-LSTM)循環(huán)處理文本,充分考慮序列的上下文關(guān)聯(lián),可以對(duì)歷史信息與未來信息進(jìn)行平等處理,從而對(duì)長句更具有魯棒性;解碼層采用LSTM產(chǎn)生標(biāo)簽表示.在編碼層與解碼層之間,添加自注意力層為實(shí)體標(biāo)簽賦予更大的權(quán)重,同時(shí)對(duì)輸入序列的遠(yuǎn)距離依賴關(guān)系建模,輔助模型對(duì)文本特征的綜合性建模.此外,在端到端模型中,增加了1個(gè)帶有偏置項(xiàng)的損失函數(shù),該偏置項(xiàng)用于捕捉相關(guān)實(shí)體之間的聯(lián)系.
盡管深度學(xué)習(xí)在很多計(jì)算機(jī)領(lǐng)域的任務(wù)上表現(xiàn)出色,Szegedy等人[9]發(fā)現(xiàn)深度神經(jīng)網(wǎng)絡(luò)存在的弱點(diǎn),他們證明了對(duì)模型的輸入做1個(gè)刻意的微小擾動(dòng)就可能導(dǎo)致具有高置信度的錯(cuò)誤決策,對(duì)模型的實(shí)際應(yīng)用造成威脅.Goodfellow等人[10]提出了一種用于圖像識(shí)別的對(duì)抗訓(xùn)練(adversarial training,AT)作為正則化方法,該方法將原樣本與對(duì)抗樣本混合輸入模型,以增強(qiáng)模型的魯棒性.本文嘗試在模型訓(xùn)練時(shí)加入擾動(dòng)作為對(duì)抗樣本,將對(duì)抗樣本和原有數(shù)據(jù)一起進(jìn)行訓(xùn)練,產(chǎn)生正則化的效果,增強(qiáng)模型的魯棒性,進(jìn)而提高模型整體性能.
模型在遠(yuǎn)程監(jiān)督產(chǎn)生的數(shù)據(jù)集NYT[11]上進(jìn)行綜合性的實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果表明本文的基于端到端標(biāo)注的模型在諸多性能指標(biāo)上優(yōu)于現(xiàn)有的知識(shí)三元組抽取模型,從而驗(yàn)證了所提方法的有效性和優(yōu)越性.
本文的主要貢獻(xiàn)有3個(gè)方面:
1)設(shè)計(jì)了一種標(biāo)注策略.通過模型標(biāo)注輸入序列得到分詞標(biāo)簽,將標(biāo)簽組合能夠直接得到三元組抽取結(jié)果.通過這種策略,知識(shí)三元組抽取問題能夠被完全轉(zhuǎn)化為端到端的序列標(biāo)注問題,從而做到了真正的聯(lián)合抽取.
2)搭建了基于LSTM的端到端框架用于輸入文本的標(biāo)注.采用雙向LSTM編碼、LSTM解碼的架構(gòu)處理文本,綜合句子的上下文信息對(duì)句子進(jìn)行標(biāo)注,組合標(biāo)注結(jié)果得到三元組信息.同時(shí),在框架中增加自注意力層提高建模長文本的能力,并設(shè)計(jì)帶偏置項(xiàng)的損失函數(shù)以充分利用相關(guān)聯(lián)實(shí)體之間的聯(lián)系.
3)引入對(duì)抗訓(xùn)練作為模型訓(xùn)練的拓展.通過在網(wǎng)絡(luò)底層添加擾動(dòng)生成對(duì)抗樣本,與原樣本混合訓(xùn)練模型以提高模型對(duì)輸入擾動(dòng)的魯棒性.
1 相關(guān)工作
知識(shí)三元組抽取是從純文本中得到三元組形式的知識(shí).本文用S表示句子文本,將三元組表示為(h,r,t),其中,h表示頭實(shí)體,t表示尾實(shí)體,而r表示h和t之間的關(guān)系[12].定義關(guān)系集合R={r1,r2,…},知識(shí)三元組抽取就是根據(jù)S和已定義的關(guān)系集合R,得到(h,r,t)的過程.知識(shí)三元組抽取的2個(gè)子任務(wù)是命名實(shí)體識(shí)別與關(guān)系分類,其研究有兩大主流方法:流水線式方法、聯(lián)合學(xué)習(xí)方法.
流水線式方法首先進(jìn)行命名實(shí)體識(shí)別(named entity recognition,NER),然后基于所識(shí)別的命名實(shí)體進(jìn)行實(shí)體之間的關(guān)系學(xué)習(xí),即關(guān)系抽取(relation extraction,RE).傳統(tǒng)的命名實(shí)體識(shí)別模型是基于統(tǒng)計(jì)的,如隱Markov模型(HMM)和條件隨機(jī)場模型(CRF)(Passos 等人[13]和Luo等人[14]).最近,一些深度學(xué)習(xí)模型(Lample等人[15]和Xu等人[16])被應(yīng)用到NER任務(wù)上,這些模型通常將實(shí)體識(shí)別任務(wù)視為對(duì)分詞的序列標(biāo)注任務(wù).對(duì)于實(shí)體關(guān)系學(xué)習(xí),現(xiàn)有方法可分為基于人工特征的方法(Hasegawa等人[17]和Kambhatla等人[18])和基于神經(jīng)網(wǎng)絡(luò)的方法(Xu等人[19-20]、Zheng等人[21]和Santos等人[22]).流水線式方法往往存在誤差傳播、實(shí)體對(duì)冗余和忽視2個(gè)子任務(wù)間聯(lián)系等弊端.
為克服以上弊端,聯(lián)合抽取方法被提出,它用1個(gè)模型同時(shí)抽取實(shí)體和關(guān)系.目前主流的聯(lián)合模型分為基于語法分析的模型(Roth等人[23]、Kate等人[24]和Finkel等人[25])、基于特征工程的模型(Li,Ji[7]和Ren等人[26])和基于神經(jīng)網(wǎng)絡(luò)的模型.與前兩種模型相比,基于神經(jīng)網(wǎng)絡(luò)的模型不依賴外部NLP工具,自動(dòng)進(jìn)行特征學(xué)習(xí)從而避免復(fù)雜的人工特征設(shè)計(jì),不僅模型復(fù)雜度降低,抽取效果也有所提升.目前,基于神經(jīng)網(wǎng)絡(luò)的聯(lián)合抽取方法主要分為基于參數(shù)共享的方法和基于標(biāo)注策略的方法.Zheng等人[27]提出了混合神經(jīng)網(wǎng)絡(luò)模型(hybrid neural network,HNN),HNN模型通過共享神經(jīng)網(wǎng)絡(luò)的底層表示來進(jìn)行聯(lián)合學(xué)習(xí).Miwa和Bansal[8]提出的SPTree模型也是類似的思想.但參數(shù)共享的方法本質(zhì)上還是分別進(jìn)行2個(gè)子任務(wù),仍會(huì)產(chǎn)生不存在確切關(guān)系的實(shí)體對(duì)這樣的冗余信息.針對(duì)此,Arzoo等人[28]提出了一種Gold standard標(biāo)注方案,并利用多層雙向循環(huán)網(wǎng)絡(luò)(multi-layer Bi-RNN)進(jìn)行知識(shí)三元組抽取.Zheng等人[29]則利用標(biāo)注策略將抽取問題轉(zhuǎn)化為序列標(biāo)注任務(wù),并設(shè)計(jì)了神經(jīng)網(wǎng)絡(luò)框架用于序列標(biāo)注,取得了更優(yōu)的效果.但是,與本文策略不同,上述標(biāo)注策略只關(guān)注實(shí)體標(biāo)注,忽視了實(shí)體與關(guān)系之間的關(guān)聯(lián),也就無法實(shí)現(xiàn)真正的實(shí)體關(guān)系聯(lián)合抽取.
對(duì)抗訓(xùn)練.盡管在知識(shí)三元組抽取任務(wù)上神經(jīng)網(wǎng)絡(luò)表現(xiàn)出色,但Szegedy等人[9]發(fā)現(xiàn)其存在弱點(diǎn).他們將刻意的微小擾動(dòng)輸入模型,導(dǎo)致模型產(chǎn)生了高置信度的錯(cuò)誤決策.Goodfellow等人[10]將這個(gè)微小的擾動(dòng)定義為對(duì)抗樣本,并提出了對(duì)抗訓(xùn)練(AT)作為正則化方法.與其他正則化方法如dropout(Srivastava等人[30])產(chǎn)生隨機(jī)噪聲不同,AT產(chǎn)生的擾動(dòng)是容易被模型誤分類的樣例的變種形式.最近對(duì)抗訓(xùn)練越來越多地被應(yīng)用于自然語言處理(NLP)任務(wù)如文本分類(Miyato等人[31])、關(guān)系抽取(Wu等人[32])、POS標(biāo)注(Yasunaga等人[33])等任務(wù).在知識(shí)三元組抽取任務(wù)上,Bekoulis等人[34]曾將對(duì)抗訓(xùn)練加入到他們的聯(lián)合學(xué)習(xí)模型中.實(shí)驗(yàn)表明,對(duì)抗訓(xùn)練的加入極大提升了模型的抽取效果.但本文是第1次將對(duì)抗訓(xùn)練用于端到端的序列標(biāo)注模型.
2 方法描述
本節(jié)介紹提出的端到端知識(shí)三元組聯(lián)合抽取的網(wǎng)絡(luò)模型,整體結(jié)構(gòu)如圖1所示.模型包括5層,分別是表示層、雙向LSTM編碼層、自注意力層、LSTM解碼層(也稱LSTMd層)、softmax分類層.
端到端知識(shí)三元組聯(lián)合抽取模型首先利用表示層將輸入文本轉(zhuǎn)換成句子序列的向量表示,然后通過雙向LSTM編碼層和自注意力層充分提取文本的上下文信息,之后上下文特征經(jīng)過LSTM解碼層產(chǎn)生標(biāo)簽的向量表示序列,最后softmax分類層根據(jù)向量對(duì)分詞進(jìn)行標(biāo)簽分類得到文本的標(biāo)簽序列.下面首先介紹本文采取的標(biāo)注策略,接著闡述模型細(xì)節(jié).
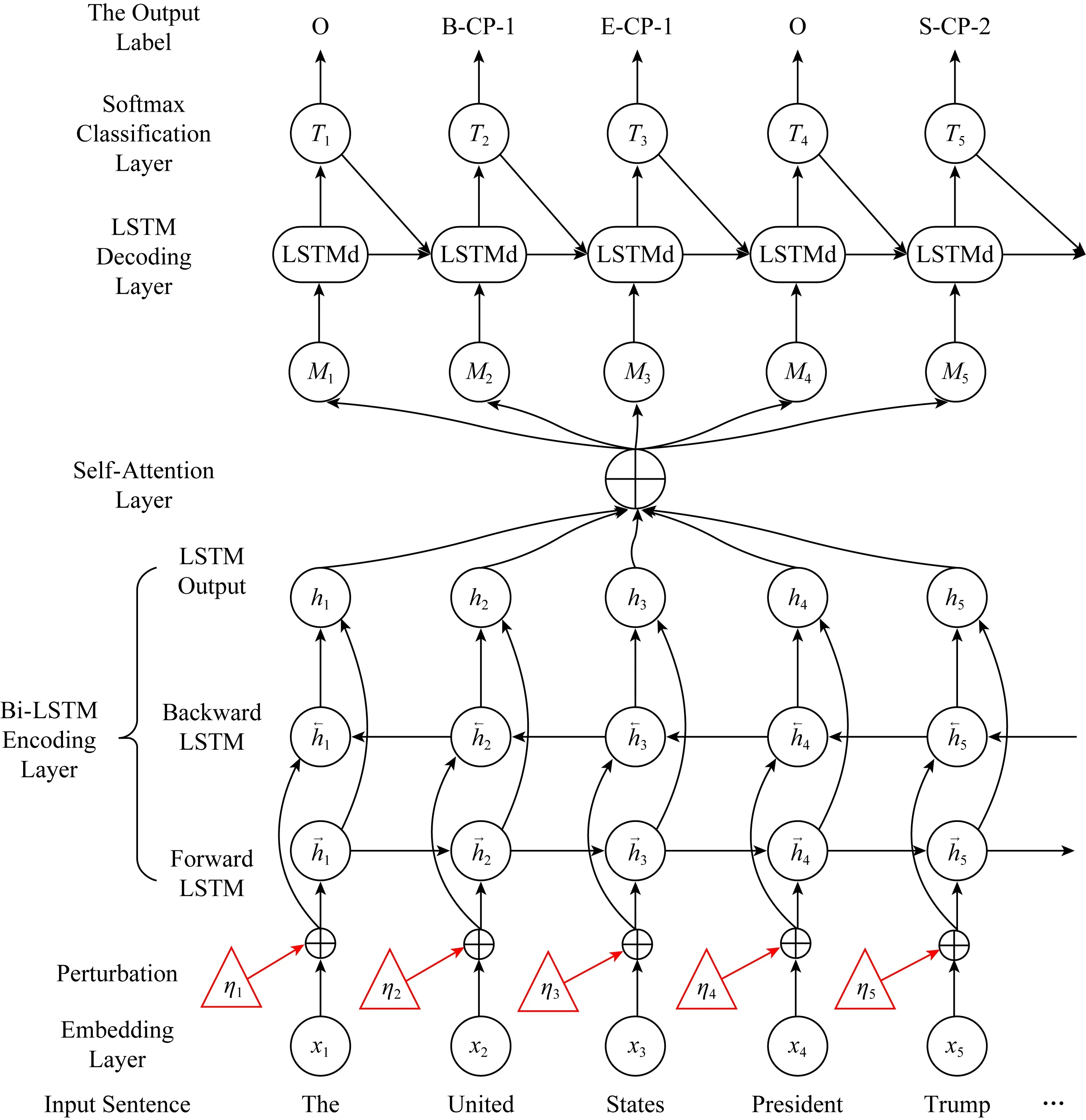
Fig.1 The structure of our end-to-end knowledge triplet extraction method combined with adversarial training圖1 融合對(duì)抗訓(xùn)練的端到端知識(shí)三元組聯(lián)合抽取模型結(jié)構(gòu)圖
2.1 標(biāo)注策略
本節(jié)介紹標(biāo)注策略以及如何通過標(biāo)注策略將知識(shí)三元組抽取問題轉(zhuǎn)化為序列標(biāo)注問題.如圖2展示了1個(gè)句子按照本文標(biāo)注策略被標(biāo)注的結(jié)果.
本文的每1個(gè)分詞都被賦予1個(gè)標(biāo)簽,這些標(biāo)簽暗示此分詞與要抽取的知識(shí)三元組的關(guān)系.
其中,標(biāo)簽“O”代表“其他(other)”,表示此分詞與被抽取的結(jié)果無關(guān),不是頭/尾實(shí)體.除了標(biāo)簽“O”,其他的標(biāo)簽都由3個(gè)分標(biāo)簽(如B-CP-2)組成,接下來分別對(duì)3個(gè)分標(biāo)簽進(jìn)行說明:
1)分詞在實(shí)體中的位置.本文考慮實(shí)體由1個(gè)或1個(gè)以上分詞構(gòu)成,使用“BIES”(開頭,內(nèi)部,結(jié)尾,單獨(dú))標(biāo)簽方案來表示1個(gè)分詞在實(shí)體中的位置信息.其中“B”即“開始(begin)”,表示此分詞是實(shí)體成分且位于實(shí)體的開頭位置;“I”即“內(nèi)部(inside)”,表示此分詞位于實(shí)體內(nèi)部;“E”即“結(jié)尾(end)”,表示分詞位于實(shí)體結(jié)尾;“S”即“單獨(dú)(single)”,表示此分詞單獨(dú)就是1個(gè)實(shí)體指稱.

Fig.2 Annotation of sample sentence based on our annotation strategy圖2 基于標(biāo)注策略對(duì)樣句的標(biāo)注
2)關(guān)系類型.分詞構(gòu)成的實(shí)體所屬的關(guān)系類型信息是預(yù)先定義好的.本文做實(shí)驗(yàn)時(shí)使用NYT數(shù)據(jù)集[11],數(shù)據(jù)集中關(guān)系集[4]是預(yù)定義的.
3)關(guān)系角色.分詞在關(guān)系中的角色信息由2個(gè)數(shù)字“1”和“2”表示.其中,“1”表示該分詞在此關(guān)系類型中屬于關(guān)系的頭實(shí)體,“2”則表示尾實(shí)體.
抽取結(jié)果由三元組(實(shí)體1,關(guān)系類型,實(shí)體2)表示,“1”表示此實(shí)體是三元組的頭實(shí)體,“2”是尾實(shí)體.因此總標(biāo)簽數(shù)是Nt=2×4×|R|+1,其中,|R|是預(yù)定義關(guān)系集規(guī)模.
圖2是1個(gè)展示了本文標(biāo)記策略的例子.輸入句包含三元組:(United States,Country-President,Franklin Delano Roosevelt),其中“Country-President”是預(yù)定義的關(guān)系類型.分詞“United”,“States”,“Franklin”,“Delano”,“Roosevelt”都與最終的抽取結(jié)果相關(guān),因此它們都基于特殊的標(biāo)記策略來標(biāo)記.例如,詞“United”是與關(guān)系“Country-President”相關(guān)的頭實(shí)體“United States”的第1個(gè)詞,因此被標(biāo)記為“B-CP-1”.與最終抽取結(jié)果無關(guān)的詞都被標(biāo)記為“O”.
與現(xiàn)有較常見的標(biāo)注策略BILOU(Li和Ji[7];Miwa和Bansal[8])不同,本文提出的三段式標(biāo)簽同時(shí)指示分詞所屬的實(shí)體屬性以及關(guān)系類型,在通過標(biāo)注模型標(biāo)注文本得到標(biāo)簽后,將有相同關(guān)系類型的2個(gè)實(shí)體標(biāo)簽與關(guān)系類型結(jié)合成1個(gè)三元組,再根據(jù)關(guān)系角色標(biāo)簽可知實(shí)體的位置(頭或者尾),從而可以得到抽取結(jié)果.通過上述步驟,知識(shí)三元組抽取問題能夠完全被轉(zhuǎn)化為端到端的序列標(biāo)注問題.
需要強(qiáng)調(diào)的是,如果1個(gè)句子包含2個(gè)或者多個(gè)具有相同關(guān)系類型的三元組,本文按照最鄰近原則將每2個(gè)實(shí)體結(jié)合,構(gòu)成1個(gè)三元組.同時(shí),本文僅考慮1個(gè)實(shí)體屬于1個(gè)三元組的情況.
下面講解模型如何實(shí)現(xiàn)上述標(biāo)注.
2.2 表示層
表示層的輸入是原始句子序列,通過詞向量表將其轉(zhuǎn)換成表示句子信息的低維向量輸入到下一層.
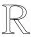
(1)
將S輸出到下一層作為輸入.
2.3 雙向LSTM編碼層
雙向LSTM編碼層由2個(gè)平行的LSTM層組成,即前向LSTM層和反向LSTM層.每層都是由1系列循環(huán)連接的子神經(jīng)網(wǎng)絡(luò)組成,稱為神經(jīng)元,對(duì)應(yīng)每個(gè)時(shí)間步長.雙向LSTM中前向網(wǎng)絡(luò)的神經(jīng)元結(jié)構(gòu)如圖3所示:
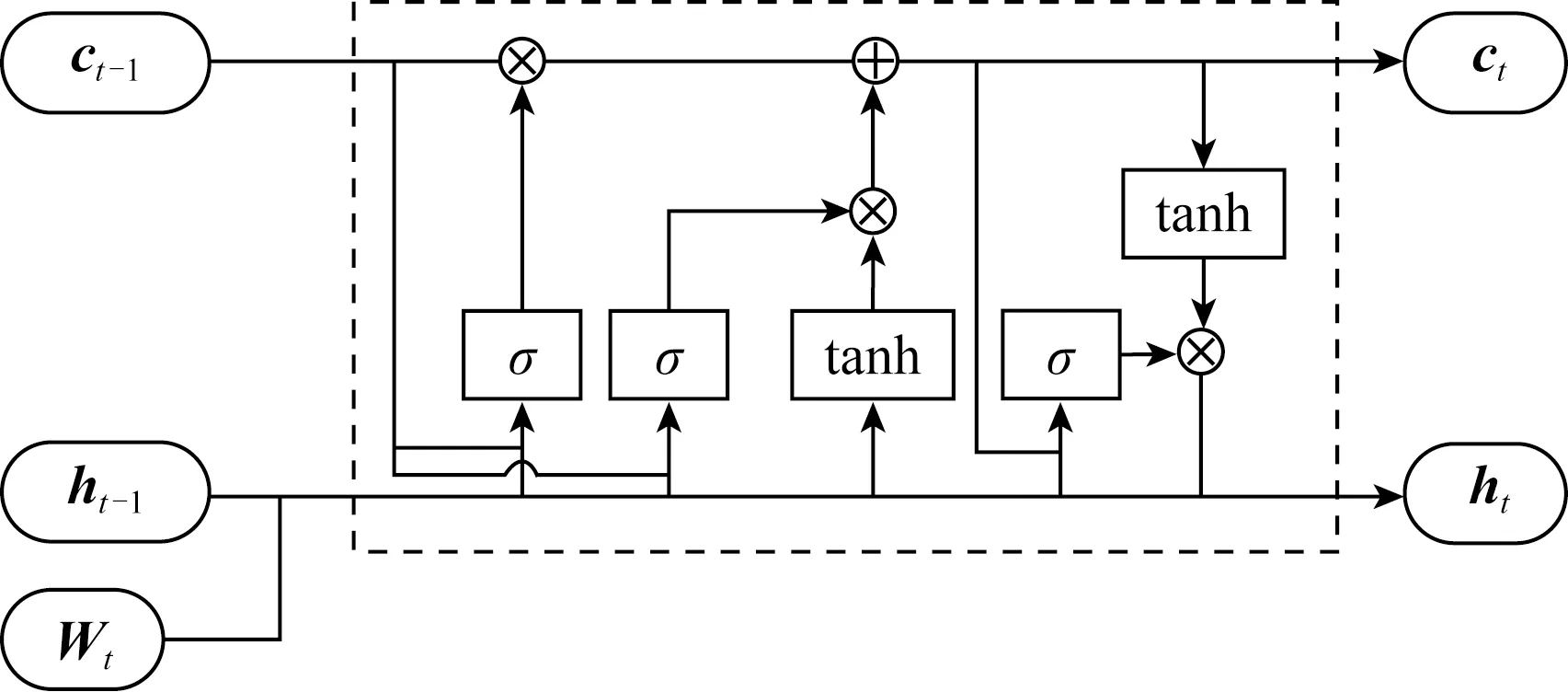
Fig.3 The structure of forward LSTM neuron圖3 前向LSTM神經(jīng)元結(jié)構(gòu)圖
LSTM通過遺忘門、輸入門和輸出門來對(duì)輸入信息進(jìn)行保護(hù)和控制.前向網(wǎng)絡(luò)中,每次新輸入1個(gè)分詞特征向量xt,并與上一時(shí)刻狀態(tài)ht-1共同產(chǎn)生下一時(shí)刻的狀態(tài)ht,其中t代表時(shí)間步長.隱藏狀態(tài)ht的計(jì)算:
it=δ(Wxixt+Whiht-1+Wcict-1+bi),
(2)
ft=δ(Wxfxt+Whfht-1+Wcfct-1+bf),
(3)
zt=tanh(Wxcxt+Whcht-1+bc),
(4)
ct=ftct-1+itzt,
(5)
ot=δ(Wxoxt+Whoht-1+Wcoct+bo),
(6)
ht=ottanh(ct),
(7)
其中,i,f,o分別為輸入門、遺忘門、輸出門,b是偏置項(xiàng),W(·)為參數(shù)矩陣.
前向LSTM層通過從分詞向量x1到xt考慮xt的前文信息來編碼xt,輸出記為ht.類似地,反向LSTM層從分詞向量xn到xt考慮xt的后文信息來編碼xt,輸出記為ht.最后,聯(lián)結(jié)ht和ht來表示第t個(gè)分詞編碼后的信息,表示為
(8)
其中,⊕表示向量聯(lián)結(jié),de為單向LSTM網(wǎng)絡(luò)維度.對(duì)于輸入的S,該層的輸出為
(9)
將h輸出到下一層作為輸入.
2.4 自注意力層
雙向LSTM神經(jīng)網(wǎng)絡(luò),由于信息傳遞的容量以及梯度消失問題,只能夠建模輸入信息的局部依賴關(guān)系.為了能夠增強(qiáng)模型建模長句的能力,本文增加自注意力層進(jìn)一步編碼輸入文本.自注意力機(jī)制能夠減少模型對(duì)外部信息的依賴,有助于捕捉文本內(nèi)部信息的相互關(guān)聯(lián).
f(h)=tanh(hWa1hT+ba1),
(10)
A=softmax(f(h)),
(11)
(12)
其中,Wa1為權(quán)重矩陣,ba1為偏置項(xiàng),f(h)表示輸入文本各個(gè)分詞之間的相關(guān)性分?jǐn)?shù),A代表分詞之間的注意力權(quán)重,M則是輸入文本的綜合編碼向量集合.接著將M輸入解碼層進(jìn)行標(biāo)簽解碼.
2.5 LSTM解碼層
得到綜合編碼了上下文信息的序列后,本文也采用LSTM結(jié)構(gòu)來產(chǎn)生標(biāo)簽序列,稱為解碼.解碼層采用1個(gè)單向的LSTM層,稱為LSTMd層,其結(jié)構(gòu)如圖4所示.
Fig.4 The structure of LSTMd neuron圖4 LSTMd層神經(jīng)元結(jié)構(gòu)圖
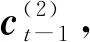

(13)
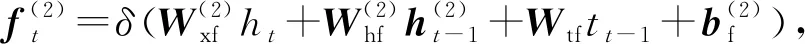
(14)
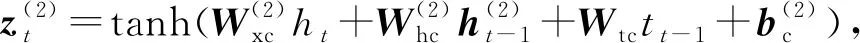
(15)
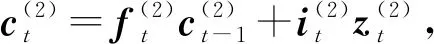
(16)
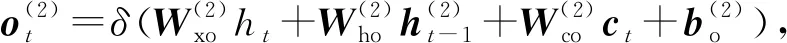
(17)
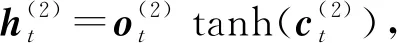
(18)
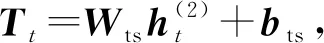
(19)
其中,i,f,o分別為輸入門、遺忘門、輸出門,b是偏置項(xiàng),W(·)均為參數(shù)矩陣.
對(duì)于輸入的M,該層的輸出為預(yù)測標(biāo)簽的向量序列
(20)
其中,dd為LSTMd網(wǎng)絡(luò)維度.
2.6 softmax分類層
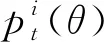
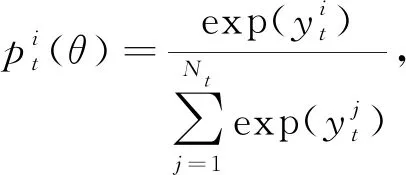
(21)
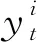
yt=WyTt+by,
(22)
在測試階段,所學(xué)習(xí)到的標(biāo)簽特征Tt乘以概率p得到Tt=pTt,用Tt進(jìn)行標(biāo)簽預(yù)測.
最終,得到分詞t具有標(biāo)簽:
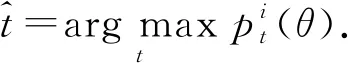
(23)
訓(xùn)練時(shí),本文最大化對(duì)數(shù)似然函數(shù):
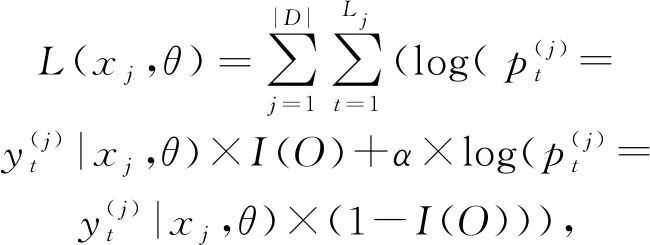
(24)
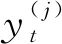
I(O)是1個(gè)門,用于區(qū)別“O”標(biāo)簽和其他標(biāo)簽的損失函數(shù)
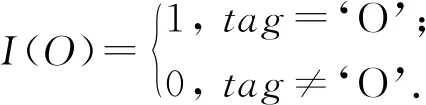
(25)
α為損失函數(shù)的偏置權(quán)重,偏置權(quán)重越大,關(guān)系標(biāo)簽對(duì)模型的影響越大,即模型將具有確定關(guān)系的實(shí)體對(duì)進(jìn)行組合的能力越強(qiáng),從而充分利用相關(guān)聯(lián)實(shí)體之間的聯(lián)系.
2.7 對(duì)抗訓(xùn)練
在模型訓(xùn)練時(shí),本文融合了對(duì)抗訓(xùn)練(AT)的思想.在這里,對(duì)抗訓(xùn)練用作一種正則化方法,使模型對(duì)輸入擾動(dòng)更具有魯棒性.
AT首先要生成對(duì)抗樣本,本文通過將擾動(dòng)ηAT添加到初始句子表示x來生成對(duì)抗樣本.通過最小化對(duì)數(shù)似然函數(shù),可以生成最差情況下的擾動(dòng)ηAT:
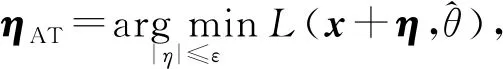
(26)
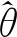
ηAT=εg/‖g‖,
(27)

(28)
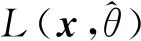
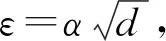
(29)
其中,d為輸入表示的維度.
進(jìn)行對(duì)抗訓(xùn)練時(shí),將對(duì)抗樣本和原樣本混合.因此,最終要最大化的似然函數(shù)為
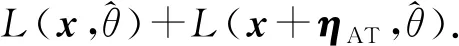
(30)
本文3.3節(jié)將對(duì)以上自注意力機(jī)制、偏置項(xiàng)、對(duì)抗訓(xùn)練3個(gè)部分進(jìn)行消融分析以量化說明各個(gè)部分在模型構(gòu)建中的作用.
3 實(shí) 驗(yàn)
本節(jié)介紹融合對(duì)抗訓(xùn)練的端到端知識(shí)三元組聯(lián)合抽取方法的先進(jìn)性實(shí)驗(yàn)驗(yàn)證.
3.1 實(shí)驗(yàn)準(zhǔn)備與實(shí)驗(yàn)背景
實(shí)驗(yàn)使用Riedel等人[11]基于遠(yuǎn)程監(jiān)督的假設(shè)構(gòu)造的NYT數(shù)據(jù)集(3)數(shù)據(jù)集可下載于:https://github.com/shanzhenren/CoType.有3個(gè)公共數(shù)據(jù)集可以選擇,本文選擇使用NYT數(shù)據(jù)集.本文使用的數(shù)據(jù)集的細(xì)節(jié)見Ren等人[26]的文章.,數(shù)據(jù)集劃分為訓(xùn)練集和測試集兩部分.訓(xùn)練集包含353×103個(gè)三元組,通過遠(yuǎn)程監(jiān)督方法獲得;測試集包含3 880個(gè)三元組,通過人工標(biāo)注獲得.數(shù)據(jù)集的關(guān)系集合中定義了24個(gè)關(guān)系,其中包括1個(gè)特殊關(guān)系“None”,表示2實(shí)體間不存在關(guān)系.對(duì)關(guān)系在集合中的順序依次編號(hào),其中,“None”的編號(hào)為0,其余的關(guān)系編號(hào)為1~23.
在訓(xùn)練好的向量詞典中,有114 042個(gè)詞向量,囊括了NYT數(shù)據(jù)集中的所有詞匯.詞典中還包含一些特殊的分詞,例如:“〈**END**〉”,“〈UNK〉”,“.”和“,”等.〈**END**〉表示句子結(jié)束的符號(hào),〈UNK〉表示未識(shí)別出的詞,“.”和“,”等是句子中常用的標(biāo)點(diǎn)符號(hào).
參考目前聯(lián)合抽取模型的評(píng)價(jià)指標(biāo),對(duì)模型抽取出的整個(gè)知識(shí)三元組結(jié)果進(jìn)行評(píng)價(jià),本文實(shí)驗(yàn)使用準(zhǔn)確率(Precision,P)、召回率(Recall,R)和F1值(F1)三個(gè)指標(biāo),F(xiàn)1是綜合性的評(píng)價(jià)指標(biāo).
模型需要設(shè)置的所有超參數(shù)如下.n為輸入網(wǎng)絡(luò)的最大句長,設(shè)置為50,若句子長度不夠,則使用空字符填充;本文使用Word2Vec算法訓(xùn)練詞向量,詞向量維度設(shè)為dw=300;每進(jìn)行1次訓(xùn)練或測試,輸入的句子集合數(shù)量為50;LSTM編碼層的神經(jīng)元數(shù)量設(shè)置為300,即該層維度de=300;LSTM解碼層維度dd=600;本文采用隨機(jī)梯度下降法迭代更新模型參數(shù),直至模型參數(shù)穩(wěn)定,學(xué)習(xí)率控制模型參數(shù)更新的速度,本文中設(shè)為η=0.001.
另外,模型引入偏置參數(shù)α來增強(qiáng)實(shí)體之間的聯(lián)系.本文通過實(shí)驗(yàn)確定參數(shù)α,α∈{1,5,10,15,20}.將除α參數(shù)外的其余超參數(shù)調(diào)整至最優(yōu),調(diào)整參數(shù)α的值,模型準(zhǔn)確率、召回率以及F1值的變化如圖5所示.當(dāng)α過大,會(huì)影響預(yù)測準(zhǔn)確率;α過小則召回率會(huì)降低.當(dāng)α=10時(shí),模型能夠獲得準(zhǔn)確率和召回率之間的平衡,從而得到最高的F1值.因此設(shè)置超參數(shù)α=10.
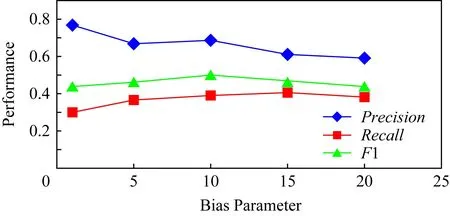
Fig.5 The results predicted by our model on different bias parameter α圖5 調(diào)整偏置參數(shù)α?xí)r的模型預(yù)測結(jié)果
3.2 與其他三元組抽取方法的比較
其他典型的三元組抽取模型可以分為兩大類:流水線方法和聯(lián)合抽取方法.
對(duì)于流水線方法,本文遵循了Ren等人[26]的設(shè)置,即通過CoType進(jìn)行命名實(shí)體識(shí)別,獲得實(shí)體;然后應(yīng)用了3種典型的關(guān)系分類方法來檢測實(shí)體間關(guān)系:
1)DS-logistic是Mintz等人[36]提出的一種基于特征的遠(yuǎn)程監(jiān)督的方法,它同時(shí)結(jié)合有監(jiān)督IE特征和無監(jiān)督IE特征的優(yōu)勢(shì);
2)LINE是Tang等人[37]提出的一種基于網(wǎng)絡(luò)表示的關(guān)系抽取方法,可被用于任何類型的信息網(wǎng)絡(luò);
3)FCM是Gormley等人[38]提出的將詞匯化語言上下文和詞向量結(jié)合用于關(guān)系抽取的復(fù)合模型.
對(duì)于聯(lián)合抽取方法,本文將模型與其他3種典型的聯(lián)合抽取方法進(jìn)行比較:
1)DS-Joint是Li和Ji[7]提出的監(jiān)督學(xué)習(xí)方法.它使用結(jié)構(gòu)化感知器聯(lián)合抽取人工標(biāo)注的數(shù)據(jù)語料上的實(shí)體和關(guān)系;
2)MultiR是Hoffmann等人[39]提出的遠(yuǎn)程監(jiān)督方法,它基于多實(shí)例學(xué)習(xí)算法,可以應(yīng)對(duì)嘈雜的訓(xùn)練數(shù)據(jù);
3)CoType是Ren等人[26]提出的通過將實(shí)體、關(guān)系、文本特征和類型標(biāo)簽進(jìn)行聯(lián)合表示來構(gòu)建域獨(dú)立的框架.
為進(jìn)一步說明本文端到端模型的優(yōu)勢(shì),將3種典型的但未被用于端到端的實(shí)體關(guān)系聯(lián)合抽取模型,應(yīng)用在本文所提標(biāo)注策略上,進(jìn)行三元組抽取任務(wù).這3種端到端模型分別為:
1)LSTM-CRF是Lample等人[15]提出的通過使用雙向LSTM編碼輸入語句,CRF預(yù)測實(shí)體標(biāo)簽序列進(jìn)行命名實(shí)體識(shí)別的框架;
2)LSTM-LSTM是Vaswani等人[40]提出,與LSTM-CRF不同,它使用LSTM層來解碼標(biāo)簽序列而不是CRF;
3)LSTM-LSTM-Bias是Zheng等人[29]所提出,在LSTM-LSTM的基礎(chǔ)上,使用了帶偏置項(xiàng)的損失函數(shù).
表1展示了不同模型在知識(shí)三元組抽取任務(wù)上的表現(xiàn).其中,行1~3是流水線式模型;行4~6是聯(lián)合抽取模型;基于本文標(biāo)注策略的端到端模型在行7~10,在這個(gè)部分不僅計(jì)算了準(zhǔn)確率、召回率和F1值,還分別計(jì)算了它們的標(biāo)準(zhǔn)差.分析表中數(shù)據(jù)可以得到3個(gè)結(jié)論:
1)本文的模型LSTM-LSTM-2AT-Bias在聯(lián)合抽取任務(wù)上的F1值為0.521±0.006,優(yōu)于其他較先進(jìn)的模型在此任務(wù)上的表現(xiàn).并且,它相較于之前效果最優(yōu)的模型CoType(Ren等人[26]),F(xiàn)1值有5.8%的提升,這也表明了本文所提方法的有效性.此外,從表1中還可以看出在三元組抽取任務(wù)上,聯(lián)合抽取方法優(yōu)于流水線式方法,而基于本文標(biāo)注策略的方法優(yōu)于大多數(shù)聯(lián)合抽取方法.這也證實(shí)了本文提出的標(biāo)注策略應(yīng)用于聯(lián)合抽取知識(shí)三元組任務(wù)的有效性.
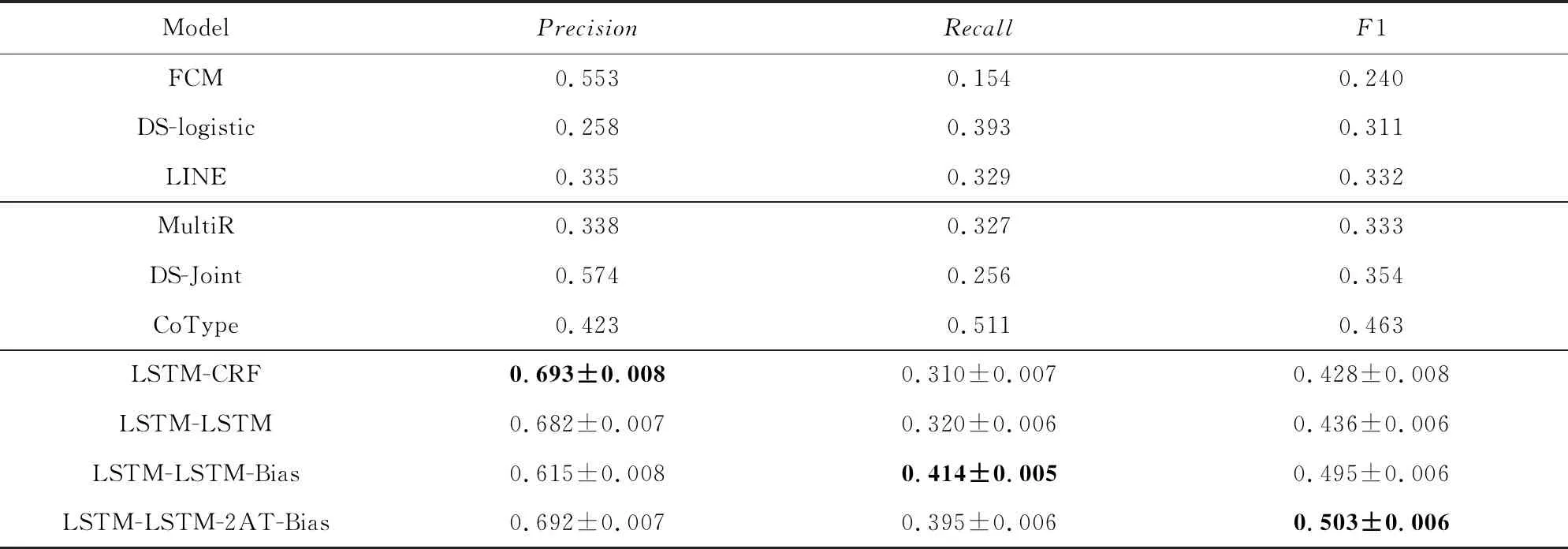
Table 1 The Predicted Results of Different Methods on Extracting Both Entities and Their Relations表1 不同模型在知識(shí)三元組抽取任務(wù)上的結(jié)果
Note:The bold numbers represent the highest performance among all models.
2)從準(zhǔn)確率數(shù)據(jù)可以看出,與傳統(tǒng)方法(流水線方法和傳統(tǒng)聯(lián)合抽取方法)相比,端到端模型的準(zhǔn)確率有了顯著提升.原因可能是端到端模型均使用雙向LSTM來編碼輸入文本,提升了對(duì)文本的處理與表示能力,然后使用不同的神經(jīng)網(wǎng)絡(luò)來解碼得到結(jié)果.然而,在所有端到端模型中,只有LSTM-LSTM-2AT-Bias能獲得更高的準(zhǔn)確率和召回率,得到最高的F1值.這說明其采取的添加自注意力層的網(wǎng)絡(luò)架構(gòu)對(duì)數(shù)據(jù)的適應(yīng)性較好,能夠很好地學(xué)習(xí)訓(xùn)練集的特征表示,采取對(duì)抗訓(xùn)練能夠獲得更高的準(zhǔn)確率,最終獲得了總體的F1值提升.
3)基于本文提出的標(biāo)注方案,LSTM-LSTM模型比LSTM-CRF模型在三元組抽取任務(wù)上表現(xiàn)更好.分析原因,LSTM神經(jīng)網(wǎng)絡(luò)能夠?qū)W習(xí)長距離依賴而CRF擅長捕捉整個(gè)標(biāo)簽序列的聯(lián)合概率.而輸入文本中,相關(guān)的實(shí)體標(biāo)簽互相之間可能距離很長.因此,LSTM解碼方式比CRF更優(yōu).通過與LSTM-LSTM模型的比較,LSTM-LSTM-Bias模型通過增加1個(gè)偏置權(quán)重可以加強(qiáng)實(shí)體標(biāo)簽的影響權(quán)重,減弱無關(guān)標(biāo)簽的影響權(quán)重,更有利于區(qū)分出實(shí)體標(biāo)簽.
3.3 消融學(xué)習(xí)
在本文模型中,核心部分是基于LSTM的編碼解碼層,加入了自注意力層和對(duì)抗訓(xùn)練,并且在目標(biāo)函數(shù)中添加了偏置項(xiàng).為保證這些輔助部分加入模型的必要性,將進(jìn)行這些部分的消融學(xué)習(xí),觀察其對(duì)模型抽取效果的改善作用.
原模型(LSTM-LSTM-2AT-Bias).原模型通過雙向LSTM編碼、LSTM解碼實(shí)現(xiàn)對(duì)文本的端到端標(biāo)注;使用帶偏置項(xiàng)(Bias)的目標(biāo)函數(shù)增加模型對(duì)相關(guān)聯(lián)實(shí)體的注意力;加入自注意力層(self-atten-tion)提高模型建模文本信息的能力;采用對(duì)抗訓(xùn)練(AT)增強(qiáng)模型對(duì)輸入擾動(dòng)的魯棒性,因此模型簡寫為LSTM-LSTM-2AT-Bias,2AT代表自注意力機(jī)制和對(duì)抗訓(xùn)練.
變種1.LSTM-LSTM-2AT.與很多現(xiàn)有端到端模型不同,針對(duì)知識(shí)三元組抽取任務(wù),本文的模型額外在目標(biāo)函數(shù)中添加了偏置權(quán)重,使得模型能夠更好地組合相關(guān)實(shí)體構(gòu)成三元組,是模型中很重要的一部分.變種1將Bias偏置項(xiàng)去掉,觀察模型性能的變化,因此變種1簡寫為LSTM-LSTM-2AT.
變種2.LSTM-LSTM-ATT-Bias.對(duì)抗訓(xùn)練在Bekoulis等人[34]的文章中被用來在BiLSTM-CRF框架上進(jìn)行聯(lián)合抽取任務(wù),實(shí)驗(yàn)證明,加入對(duì)抗訓(xùn)練使得模型在3個(gè)普遍使用的數(shù)據(jù)集上的抽取效果較現(xiàn)有模型均有一定幅度的提升.本文將對(duì)抗訓(xùn)練遷移至設(shè)計(jì)的特定目標(biāo)函數(shù)上,為驗(yàn)證對(duì)抗訓(xùn)練在本文模型中的作用,變種2不采用對(duì)抗訓(xùn)練,簡寫為LSTM-LSTM-ATT-Bias.
變種3.LSTM-LSTM-AT-Bias.自注意力機(jī)制在Tan等人[41]的文章中被應(yīng)用到了序列標(biāo)注任務(wù)中,將自注意力層嵌入到神經(jīng)網(wǎng)絡(luò)框架,實(shí)驗(yàn)證明,加入自注意力機(jī)制提升了模型學(xué)習(xí)文本語義的能力,使得標(biāo)注結(jié)果更好.本文在編碼文本序列后加入自注意力層充分表示文本,為驗(yàn)證自注意力層在本文模型中的作用,變種3將自注意力層去掉與原模型比較,因此變種3簡寫為LSTM-LSTM-AT-Bias.
上述4個(gè)模型的超參數(shù)以及實(shí)驗(yàn)數(shù)據(jù)集均按照3.1節(jié)中的設(shè)定,使用的詞向量編碼也均相同.
表2展示了本文模型與3個(gè)變種在本文任務(wù)上的抽取結(jié)果.從實(shí)驗(yàn)結(jié)果看,本文模型的F1值比3個(gè)變種的F1值分別高出了2.6%,1.7%和1.2%,說明每一部分的加入都對(duì)模型性能的提升有所貢獻(xiàn).
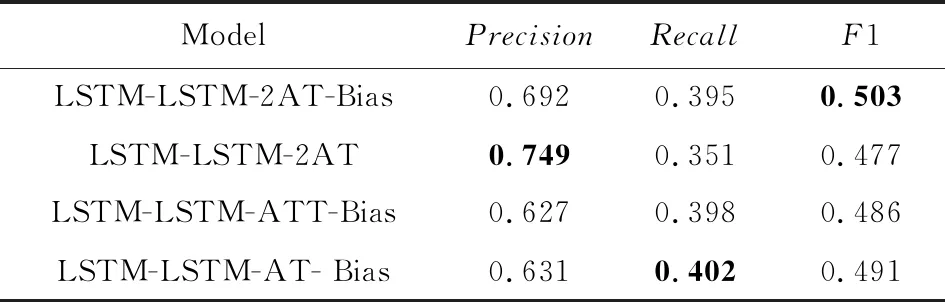
Table 2 The Predicted Results of our Model and Its Variants on the Knowledge Triplet Extraction Task表2 原模型與各變種在知識(shí)三元組抽取任務(wù)上的結(jié)果
Note:The bold numbers represent the highest performance among all models.
對(duì)于變種1,刪除了偏置項(xiàng),該變種在4個(gè)模型中表現(xiàn)最差,說明在3個(gè)部分中偏置項(xiàng)對(duì)該模型的性能提升最大.偏置項(xiàng)通過影響模型的目標(biāo)函數(shù),使其對(duì)關(guān)系標(biāo)簽更加敏感,提升了模型組合相關(guān)聯(lián)實(shí)體的能力.因此刪除偏置項(xiàng)后,模型準(zhǔn)確率雖有提升,但召回率和總體F1值均大為降低.
對(duì)于變種2,去掉了對(duì)抗訓(xùn)練,該變種使模型F1值降低了1.7%,影響也非常大.原因是原始輸入集合中本身就存在一些影響模型效果的擾動(dòng),對(duì)抗訓(xùn)練以及對(duì)抗樣本的加入使得模型對(duì)輸入擾動(dòng)的分辨能力提升.因此刪除對(duì)抗訓(xùn)練后,模型準(zhǔn)確率降低,雖然召回率略有提升,但總體F1值也降低.
對(duì)于變種3,由于缺少自注意力層,模型對(duì)輸入文本的表示能力下降,一定程度上影響了模型性能.自注意力機(jī)制能幫助模型有效地捕獲有重要作用的分詞(在本任務(wù)中即為被標(biāo)記為實(shí)體標(biāo)簽的分詞),能夠提升模型標(biāo)記的準(zhǔn)確率.因此刪除自注意力層后,模型準(zhǔn)確率降低,雖然召回率有提升,但總體F1值仍下降.
對(duì)于本文模型而言,偏置項(xiàng)的加入作用大于對(duì)抗訓(xùn)練的加入,大于自注意力機(jī)制的加入,但三者對(duì)模型在知識(shí)三元組抽取任務(wù)上F1值的提升都有較大貢獻(xiàn),因此這些部分的加入是必要的.
3.4 知識(shí)三元組抽取結(jié)果的誤差分析
本文要解決的任務(wù)是抽取由2個(gè)實(shí)體和它們之間的1個(gè)關(guān)系組成的知識(shí)三元組.表3展示了此任務(wù)上各種模型的抽取結(jié)果.在判斷三元組抽取結(jié)果正確與否時(shí),只有當(dāng)2個(gè)實(shí)體和對(duì)應(yīng)關(guān)系類型均正確的三元組才被認(rèn)定為正確.

Table 3 The Predicted Results of Triplet’s Elements Based on Our Tagging Scheme表3 不同端到端模型基于本文標(biāo)注策略對(duì)三元組元素的預(yù)測結(jié)果
Note:The bold numbers represent the highest performance among all models.
為了找出影響端到端模型表現(xiàn)效果的因素,本節(jié)分析了端到端模型對(duì)三元組所含元素的抽取表現(xiàn),表3展示了結(jié)果.E1和E2分別代表模型抽取的第1、第2個(gè)實(shí)體實(shí)例,(E1,E2)則表示實(shí)體對(duì)實(shí)例.
從表3可以看出,與元素E1和E2相比,模型對(duì)(E1,E2)實(shí)體對(duì)抽取的準(zhǔn)確率更高,但召回率略有降低,這意味著一些抽取出的實(shí)體沒有組成實(shí)體對(duì).原因可能是模型只抽取出了實(shí)體E1或E2而沒有找出其對(duì)應(yīng)的實(shí)體E2或E1,因此導(dǎo)致抽取出較多單實(shí)體E和較少實(shí)體對(duì)(E1,E2).實(shí)體對(duì)因此比單實(shí)體準(zhǔn)確率更高而召回率更低.
另外,表3中實(shí)體對(duì)(E1,E2)的抽取結(jié)果相比表1,LSTM-LSTM-2AT-Bias的三元組抽取結(jié)果有了2.7%的F1值提升,這也意味著抽取結(jié)果中有部分三元組是因?yàn)殛P(guān)系類型分類錯(cuò)誤而導(dǎo)致被錯(cuò)誤抽取.
3.5 對(duì)知識(shí)三元組抽取實(shí)例的分析
通過上述實(shí)驗(yàn)及分析,發(fā)現(xiàn)本文模型針對(duì)知識(shí)三元組抽取問題具有更好的性能.接著,本節(jié)觀察了幾種端到端模型對(duì)三元組的抽取結(jié)果,然后挑選了3個(gè)代表性的例句來進(jìn)一步說明模型優(yōu)缺點(diǎn),如表4所示.
表4中,黑體字為正確輸出結(jié)果,下劃線標(biāo)記出的是模型抽取錯(cuò)誤的結(jié)果.句中實(shí)體的下標(biāo)表示實(shí)體角色(頭實(shí)體/尾實(shí)體)以及實(shí)體構(gòu)成三元組所屬的關(guān)系,例如例句S1抽取出三元組(New York City,contain,Brooklyn),其中“[New York City]E1Contain”表明“New York City”屬于三元組中頭實(shí)體,且三元組關(guān)系類型為“Contain”.例句S3中E1CF則是E1Company-Founder的縮寫.
觀察分析表4中的例句以及抽取結(jié)果:
例句S1的抽取結(jié)果是本文模型的正例,同時(shí)它也代表一種源文本類型:文本中的2個(gè)相關(guān)實(shí)體彼此之間相距較遠(yuǎn),從而增大了檢測它們之間關(guān)系的難度.從抽取結(jié)果看,LSTM-LSTM-Bias與LSTM-LSTM-2AT-Bias模型均正確抽取出了結(jié)果,而LSTM-LSTM模型則因?qū)嶓w間距離過長,未能關(guān)聯(lián)起相關(guān)實(shí)體,僅僅抽取出了1個(gè)實(shí)體“New York City”,未能檢測出“Brooklyn”.這反映了本文模型增加偏置目標(biāo)函數(shù)的有效性.
例句S2的抽取結(jié)果是另一個(gè)正例,它代表另一種情況:文本中存在多個(gè)擾動(dòng)實(shí)體,加大模型分辨組合實(shí)體對(duì)的難度.例句中,實(shí)體“Silicon Valley”和“USA”之間并沒有指示性詞暗示2個(gè)實(shí)體的關(guān)系.另外,實(shí)體“USA”和“industry”的模式“the*of*”很容易誤導(dǎo)模型,使之認(rèn)為2個(gè)實(shí)體之間存在關(guān)系“Contain”,導(dǎo)致模型LSTM-LSTM與LSTM-LSTM-Bias均抽取錯(cuò)誤;而本文的模型由于加入了對(duì)抗訓(xùn)練,使其能夠分辨這種模式,從而抽取正確.
例句S3的抽取結(jié)果是1個(gè)負(fù)例,它代表一種情況:模型能夠正確抽取出實(shí)體,但實(shí)體的關(guān)系角色預(yù)測錯(cuò)誤.LSTM-LSTM和LSTM-LSTM-Bias模型抽取出實(shí)體“Jerry Moss”和“A&M Records”均為頭實(shí)體E1,未能抽取出對(duì)應(yīng)的尾實(shí)體E2.而LSTM-LSTM-2AT-Bias模型能夠發(fā)現(xiàn)實(shí)體對(duì)(E1,E2)存在,但實(shí)體“Jerry Moss”和“A&M Records”的實(shí)體角色被抽取反了.與LSTM-LSTM-Bias相比,本文模型由于加入了注意力機(jī)制,對(duì)文本語義把握更充分,檢測出相關(guān)聯(lián)實(shí)體對(duì)的能力更強(qiáng),但在區(qū)分兩實(shí)體具體關(guān)系上有待提升.

Table 4 Output from Different Models表4 不同端到端模型的輸出結(jié)果
Note:Standard Sirepresents the gold standard annotation of sentencei.The bold parts are the correct outputs,and the underlined parts are the wrong outputs.
4 結(jié)論和進(jìn)一步工作
本文主要提出了一種融合對(duì)抗訓(xùn)練的端到端知識(shí)三元組聯(lián)合抽取方法.傳統(tǒng)的流水線式抽取方法會(huì)導(dǎo)致誤差傳遞,而現(xiàn)有的聯(lián)合抽取沒有充分發(fā)掘?qū)嶓w識(shí)別與關(guān)系抽取2個(gè)子任務(wù)的聯(lián)系.針對(duì)現(xiàn)有方法的問題,本文模型提出一種標(biāo)注策略,能夠通過端到端標(biāo)注將知識(shí)三元組抽取問題完全轉(zhuǎn)化為序列標(biāo)注問題;然后設(shè)計(jì)了端到端的標(biāo)注網(wǎng)絡(luò),并加入自注意力層來充分表示文本,通過帶偏置項(xiàng)的損失函數(shù)提高模型組合實(shí)體對(duì)的能力,加入對(duì)抗訓(xùn)練以增強(qiáng)模型魯棒性.為驗(yàn)證方法有效性,在普遍使用的數(shù)據(jù)集上將模型與目前較先進(jìn)的模型以及一些變種在知識(shí)三元組抽取任務(wù)上的效果進(jìn)行對(duì)比,結(jié)果表明本文模型取得最優(yōu)性能;然后進(jìn)行消融分析,證實(shí)了模型各個(gè)部分的必要性;之后進(jìn)行了誤差分析,最后通過實(shí)例說明模型優(yōu)缺點(diǎn).
下一步,計(jì)劃對(duì)所提方法以及模型進(jìn)行進(jìn)一步改進(jìn),尋求模型的性能提升.注意到模型最后1層采用softmax進(jìn)行單分類,1個(gè)詞只能有1個(gè)標(biāo)簽.可考慮用多分類器替換softmax,1個(gè)詞可以有多個(gè)標(biāo)簽,能夠出現(xiàn)在多個(gè)三元組中從而使模型能夠識(shí)別重疊關(guān)系.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
