基于深度學習的醫療問答系統的開發
2019-12-12 07:31:02姚智
中國醫療設備 2019年12期
姚智
江蘇省南通市第一人民醫院 信息科,江蘇 南通 226001
引言
深度學習的歷史可以追溯至20世紀40年代對控制論的理論研究,而自從21世紀初Hinton研究并提出“深度信念網絡”的概念以及計算機硬件技術的發展后,研究人員已經具備了訓練較深神經網絡的能力,使機器學習在社會上的關注熱度越來越高、應用范圍越來越廣。就目前來看,深度學習在醫療衛生方面中的應用研究成果主要集中于腫瘤學、病理學、罕見疾病診斷等方面[1]。作為人工智能的一個重要研究領域,問答系統在醫療方面具有不可忽視的應用潛力,然而,起步較晚各項技術還不夠成熟。早期的醫療問答系統主要是利用信息檢索、數據庫等技術,如國外研究人員開發的MedQA[2]、MiPACQ[3]和AskHERMES[4]等系統。目前的醫療問答系統一般是基于知識圖譜技術,將醫療知識信息以實體-關系的形式存儲到非關系型數據庫中[5],然后通過檢索與推理的形式提供醫療建議,例如Izcovich等[6]設計了基于圖譜化GRADE的醫療問答系統 Oyelade等[7]通過患者癥狀提取過程中的語義,收集信息,用于專家初步診斷。另外,近年來國內在這一方面也有不少研究成果,如顏昕[8]通過自然語言處理技術與多項機器學習算法所構建的社區健康問答系統,李超[9]利用大數據分析、深度學習技術構建的疾病導診系統,有效地解決了患者的就診引導問題。然而,由于漢語自然語言處理的復雜性、相關理論與工業化成果不足以及醫療類問題對錯誤的低容忍性,目前對醫療問答系統的研究尚待發展[10]。基于此,本文設計并實現了一種基于深度學習的醫療問答系統,通過深度長短期記憶(Long Short Term Memory,LSTM)構建了序列到序列(Seq2Seq)模型,并結合考慮了檢索式回復策略建立醫療知識庫以便提高回復的準確性。本文旨在推動醫療信息化相關研究及產業的發展,助力我國醫療衛生行業與人工智能技術的深度融合。
1 醫療問答系統的總體設計
本文所設計與實現的醫療問答系統選擇分層風格作為體系結構,總共包括4層,自底向上依次為:數據持久層、語義層、業務功能層和前端表示層。選擇分層風格體系結構的原因在于:該任務能夠在不同抽象層次上進行分解、本身不存在逆向與跨層調用、良好的可復用性與內部可修改性[11]。基于深度學習的智能醫療問答系統體系結構,如圖1。
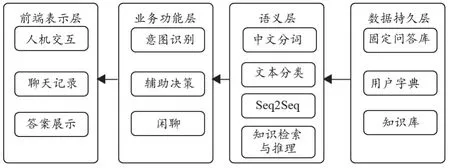
圖1 智能醫療問答系統體系結構
數據持久層主要用于管理語料和知識庫,為語義層提供數據檢索和數據存儲服務,是整個系統運行的基礎。該層主要是知識庫模塊,封裝語料存儲的細節,并實現系統的數據管理。
語義層使用數據層所提供的數據管理服務,完成對語料的初步處理,實現分詞、同義詞擴展、相似度計算等基礎性的功能。該層封裝了自然語言處理中語義層面的常規操作,以便于完成高層更復雜的處理。但在該層實現的功能尚不具備業務價值。
業務功能層使用語義層提供的基礎性自然語言處理(Natural Language Processing,NLP)服務,實現了智能醫療問答系統的意圖識別、輔助決策、閑聊等功能,并且從該層起體現了系統的業務價值。
前端表示層通過對低層模塊的逐層調用來實現系統功能,從而滿足用戶需求。該層主要包括系統的前端界面與人機交互等模塊,它封裝了用戶交互,為用戶提供系統前端展現并接收用戶的交互行為。前端表示層是系統的最高層,也是唯一一個用戶所能直接接觸的層次。
2 醫療問答系統的關鍵技術
2.1 深度LSTM算法
神經語言模型是基于人工神經網絡的自然語言處理模型,在NLP問題的研究和應用上取得了顯著成果[12]。尤其是Gao等[13]提出使用遞歸神經網絡來理解文本后,該模型在經歷了不斷改進之后已成為了一項成熟的自然語言處理技術。
語言信息實際上是一組序列數據,因為在文本中前一部分在一定程度上可以決定后一部分。最初研究人員使用循環神經網絡(Recurrent Neural Network,RNN)來處理這種序列數據,其特點是引入了循環機制,從而實現模型不同部分之間參數在時間上的共享:

ht表示t時刻的系統狀態;xt表示t時刻的輸入,θ表示不變的參數。可見,某個時刻的輸入被當成了下一時刻的部分參數,并在下一時刻接收新的輸入,具體步驟可表示為:
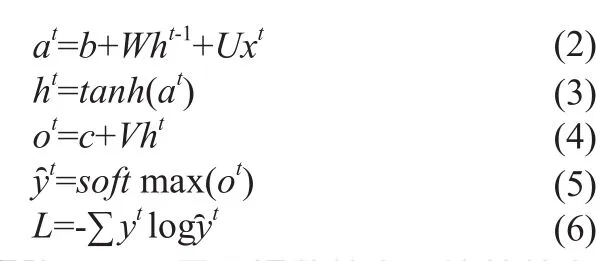
其中,向量b與矩陣W、U用于調整輸入,連接輸入與隱藏層;向量c與矩陣V作為隱藏層中一個結點不同狀態之間的連接;激活函數softmax將輸出ot歸一化;L是損失函數,用交叉熵來計算。
LSTM則是RNN的一種改進模型。其改進之處在于通過引入狀態屬性與門限機制來避免避免梯度消失或彌散的問題。而狀態屬性又代替了激活層為模型引入非線性,具體計算方式為式(7)。
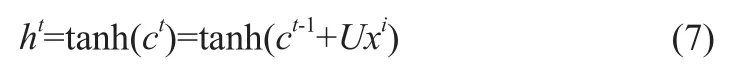
式中,tanh為雙曲正切型激活函數;h表示神經網絡模型中的隱藏層;c代表新引入的狀態屬性;x表示輸入向量;U是系數矩陣;t是時間步。LSTM的神經元結構以及門限機制如圖2所示。
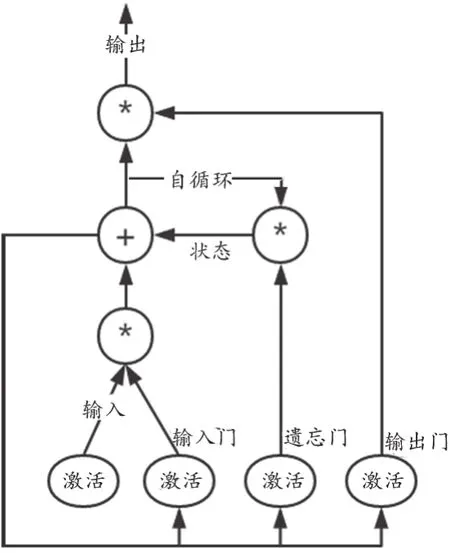
圖2 長短期記憶的神經元結構與門限機制
而根據有關實驗,在使用上述結構的LSTM模型時引入深度,即把較低層的原始輸入轉換為更適合更高層的形式[14]。本文也是采用了這種方法,將深度LSTM作為基礎以構建用于醫療問答任務的序列到序列模型。
2.2 問答系統構建策略
2.2.1 基于Seq2Seq模型的生成式回復策略
本文所設計并實現的智能醫療問答系統主要使用基于LSTM的Seq2Seq模型來為患者提供回答。Seq2Seq模型實際上是一個編碼-解碼器結構:編碼器將長度可變的數據序列轉換為固定長度的向量;解碼器將這個定長向量轉化為變長的數據序列。不定長的序列數據被映射至高維空間后,模型的編碼器將其進行規范化操作并壓縮數據大小,其結果為LSTM中最后一個隱藏結點或多個隱藏層結點的加權總和。Seq2Seq模型的工作流程,如圖3。
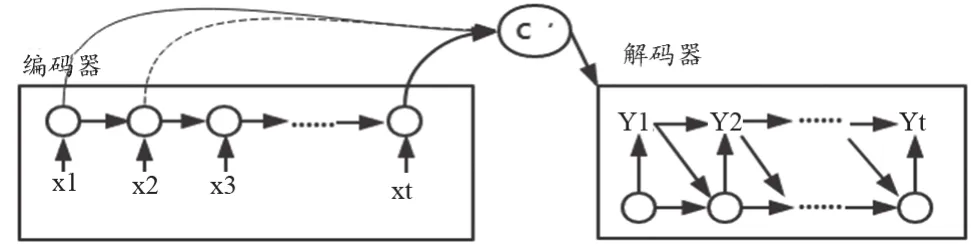
圖3 Seq2Seq模型的工作流程
在實驗時首先通過Web爬蟲技術從各大醫療咨詢網站中爬取醫療問答數據,在進行適當的清洗、切分后得到21652條問答記錄作為模型的訓練語料,然后通過word2index等方法實現文字向量化編碼與保存,以便于訓練模型。
構建該模型時使用了谷歌公司開發的Tensor flow框架來完成Seq2Seq模型的編寫。該模型基于深度為4層的LSTM結構,每層包含512個神經元。使用上述處理后的語料數據進行100輪次的訓練,訓練過程如圖4所示。

圖4 Seq2Seq模型的訓練過程
2.2.2 基于知識庫的檢索式回復策略
實際上,良好的客戶服務離不開知識庫的支持。基于深度學習的醫療問答系統,在生成式回復模型的基礎上使用知識庫可以有效提高回答的準確度。目前知識庫的最新形式是智能知識庫,具有結構化存儲、自主學習功能和圖譜化的特點[15]。建立面向醫療問答系統的知識庫可以將分散于各疾病種類、醫護人員、醫療資訊網站中的知識集中起來統一管理,便于用戶通過知識地圖和搜索引擎進行查詢。
實驗時使用Web爬蟲技術從醫療咨詢網站、百科詞條等收集了大量醫療類相關信息,并將其按疾病種類、所屬科室進行分類整理。為了保證知識庫中信息的準確性,實驗中采用人工審核的方式對其進行驗證,確認無誤后組織成JSON格式。以疾病“中耳炎”的JSON格式為例,總共包含18個鍵值對:疾病編號、疾病名稱、疾病描述、標簽、預防措施、疾病癥狀、醫保狀態、患病概率、易患病人群、伴隨癥、所屬科室、治療方式、治愈周期、治愈概率、常規概率、治療花費、檢查項目、飲食推薦,以及其對應數據。具體過程如下:{ “_id” : “5bb578cc831b973a137e47ec” ,“name” : “中耳炎”, “desc” : “中耳炎是指...”, “category” :[ “疾病百科”, “五官科”, “耳鼻喉科” ], “prevent” : “1、注意休息,保證睡眠時間...”, “symptom” : [ “耳后疼痛”,“耳痛”, “發燒”, ... ], “yibao_status” : “否”, “get_prob” :“0.9%”, “easy_get” : “無特定人群”, “get_way” : “無傳染性”, “acompany” : [ “慢性中耳炎” ], “cure_department” :[“五官科”,“耳鼻喉科”],“cure_way”:[“藥物治療”,“手術治療”],“cure_lasttime”:“7-90天”,“cured_prob”:“95%”,“common_drug”:[“阿奇霉素片”,“頭孢克洛顆粒”],“cost_money”:“市三甲醫院約(500~5000元)”,“check”:[“耳鼻咽喉CT檢查”,“...],“do_eat”:[“鴨肝”, .. ],“not_eat”:[“田螺”,.. ],“recommand_drug”:[“當歸龍薈片”,.. ]}。
傳統關系型數據庫可以通過使用觸發器來實現知識的表示與推理[16],但這種方法需要建立和維護大量觸發器,并且只能實現簡單的知識表示和推理過程。而非關系型數據庫則具有存儲方式靈活、適當增加冗余等特點,適合于存儲非結構化數據。因此本文使用了圖形數據庫NEO4J來構建醫療問答系統所需的醫療知識庫,存儲醫療信息實體以及實體之間的關系。對上述所有數據進行整理后總共得到8808個知識條目,每個條目包含的鍵值對數量大致在15~25對。將所有數據批量導入NEO4J圖形數據庫后,形成的圖譜化知識庫結果(圖5)。
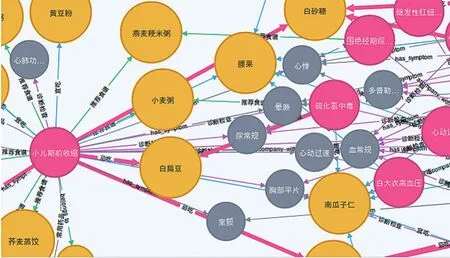
圖5 醫療知識庫圖譜化結構
3 應用效果和數據分析
在完成系統的設計、實現以及部署等工作之后,需要對系統相關業務功能最后的實現效果以及部署上線之后用戶的滿意程度進行考察。首先,它作為一種問答系統應當具備使用自然語言同人類進行聊天的能力。本系統主要使用生成式以及檢索式回復策略,前者是通過從大量的訓練語料中學習自然語言的語法、聊天方式等特征信息,后者則是依照知識庫中的實體關系進行檢索與推理性回復。對此本文收集了大量醫療問答系統(測試版)在上線之后的實際問答數據,并對其進行比較分析。這些問答數據總體上可分為3個類別:閑聊類問答、知識檢索類問答以及知識推理類問答(圖6),以下將對其進行分析從而驗證系統能否與用戶進行有效交流。
(1)知識檢索類問題。此時在知識庫保存有能夠直接回答它的相關知識數據,例如根據上文對醫療知識庫建設的闡述中可知,氣胸的形成原因、所屬科室信息都是直接存儲于知識庫中。系統面對此類問題可以通過知識檢索向用戶提供準確的答復。
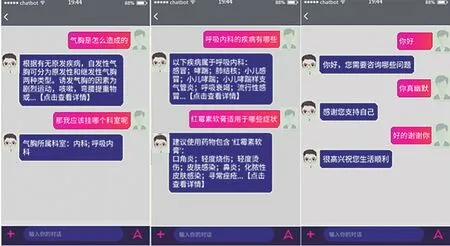
圖6 系統實際應用中的三種問答類型
(2)知識推理類問題。在知識庫中間接地保存有能夠回答它的相關知識數據,例如在系統的知識庫中沒有直接存儲某一種藥物能夠治療的疾病種類,在面對此類問題時,可以通過知識圖譜中的推理功能整合出所有推薦藥物中包含紅霉素軟膏的全部疾病。
(3)閑聊類問題。用戶并沒有向系統提出醫療類的相關資訊,而是輸入了其他聊天類的信息。這一類問題無法通過系統的醫療知識庫來得出答案,而是通過上文提到的生成式回復策略來產生一個輸出,而這種輸出的準確性、通順性與Seq2Seq模型的訓練語料質量、訓練輪次直接相關。例如當用戶輸入“謝謝你”時,系統將反饋“祝您生活順利”,這樣的答復具有典型的醫療咨詢網站風格。
由于系統對用戶的所有醫療方案建議都是來源于醫療知識庫,而該知識庫經過了嚴格的人工審核,因此其回答具有準確性保證。更重要的是,系統在無法向用戶提供經過人工審核的信息時將以閑聊的形式與用戶進行交流,這種交流并不會輸出醫療方案,所以不會向用戶提供錯誤的醫療建議,避免造成嚴重后果。該系統的這一特性使其在上線后得到了較好的用戶評價,系統后臺對于用戶訪問量、使用反饋等信息的統計界面如圖7所示。
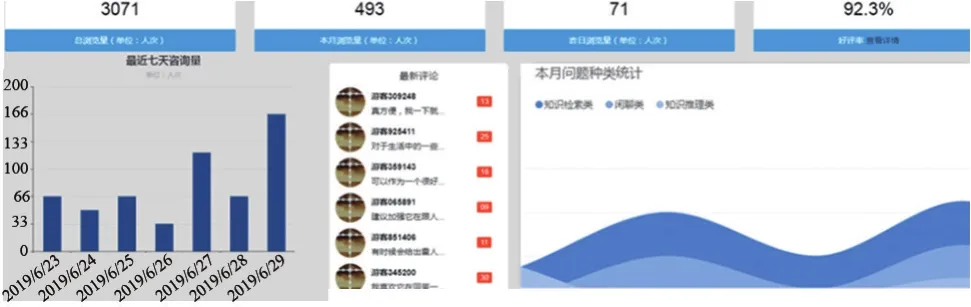
圖7 系統后臺流量監控界面
由圖7可見,系統上線兩個月后總共獲得了3071人次的訪問量,且個人的訪問次數呈上升趨勢。根據用戶的反饋數據,系統的好評率為92.3%,不少用戶表示使用本系統能夠足不出戶地享受醫療咨詢服務,方便了他們的生活。
4 總結和展望
本文基于深度學習技術設計了一款智能醫療問答系統。使用基于LSTM的Seq2Seq模型實現了問答系統的生成式回復策略,從互聯網上收集相關語料來完成模型訓練。此外,還使用NEO4J圖形數據庫構建了醫療類知識庫,爬取多個醫療咨詢網站、百科詞條等作為知識來源,從而實現了問答系統的檢索式回復策略。實驗結果表明,該系統能夠與用戶進行有效交流,為用戶所遇到的醫療類問題提供相關知識介紹以及初步解決方案,為人工智能技術與醫療行業的深度融合提供了助力。
本系統在實驗驗證、實際使用中取得了較好的結果,然而,系統在使用過程中需要對知識庫中的數據進行定期維護,這是一項較為繁瑣的工作。此外,由于訓練語料的質量與針對性,醫療問答系統在與用戶進行交流時的語言表述能力顯得較為生硬。因此,本課題在未來工作中的方向應當著力于解決上述兩點問題,即改進系統的自主學習能力,并收集、編制更具有針對性的高質量訓練語料。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
