基于GPU并行枚舉DES密鑰Bitslice方法的實現
2019-12-11 03:44:54
數字通信世界 2019年11期
關鍵詞:程序
(石化盈科信息技術有限責任公司,北京 100007)
1 研究背景
統一計算設備架構CUDA(Compute Unified Device Architecture),它是NVIDIA公司提出的一種通用并行計算平臺和編程模型。通過使用GPU高性能并行多線程能力,解決大數據計算的模型已被廣泛應用在密碼破譯[1-5]、模型分析[6-9]、圖形圖像[10-13]等領域。通過使用CUDA開發平臺可以開發在CPU和GPU上運行的通用計算程序。并行編程的中心思想是分組數據:將大數據劃分為一些小塊數據組,再把這些小塊數據組交給相應的處理單元并行處理。CUDA中的問題被粗粒度地劃分為若干子問題(塊Block),每個塊都由一些線程組成,線程是CUDA中最小的處理單元。子問題進一步劃分為若干更小的細粒度的線程問題以解決。CUDA線程數目通常能達到數千個甚至上萬個,通過不同的優化方法,劃分模型可以數十倍地提升計算性能。
GPU是由多個流處理器構成的,流處理器以塊(Block)為基本調度單元,因此,對于流處理器較多的GPU,它一次可以處理的塊(Block)更多,從而運算速度更快,時間更短。反之對于流處理器較少的GPU,其運算速度便會較慢[14]。這一原理可以通過圖1看出來:
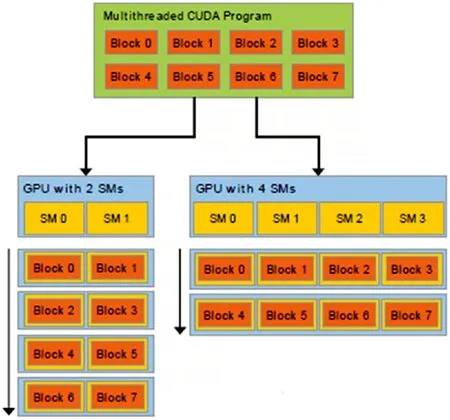
圖1 GPU流處理器處理性能的比較
對于浮點數操作能力,CPU與GPU的能力相差在GPU更適用于計算強度高、流程簡單的并行計算中。GPU擁有更多晶體管,而不是像CPU一樣具有數據Cache和流控制器。這樣的設計是因為并行計算的時候每個數據單元執行相同程序,不需要那么繁瑣的流程控制,而更需要高計算能力,從而也不需要大Cache來緩存數據。CPU架構與GPU架構的對比如圖2所示[15]。
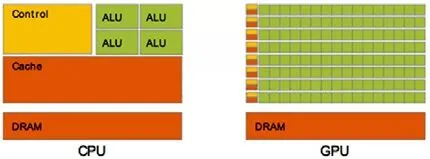
圖2 CPU架構與GPU架構的對比
隨著“三金”工程尤其是金卡工程的啟動,DES算法在POS、ATM、智能卡、收費站等領域被廣泛使用,例如持卡人的PIN碼保護加密算法、智能卡與設備交互之間的雙向認證、數據包的MAC效驗等均使用到了DES算法。DES算法的入口有3個參數:key、data、mode。其中key是一個8字節64位;data也是8字節64位;而key實際上的每一字節是7bit位,最后一位是奇偶效驗位。DES的算法框圖如圖3所示[16]。

圖3 DES算法框圖
本文開發的基于CPU和GPU枚舉DES密鑰的Bitslice程序所使用的開發環境為Microsoft Windows 10 Professional 64位,Intel Core i5-2300@2.8GHz,8GB內 存,GPU為 Geforce GTX Titan Z,GPU詳細的引擎規格如圖4所示。由于Geforce GTX Titan Z是GPU×2。為了對比研究僅使用一個GPU芯片單元,顯存大小也為原始的1/2即6GB。驅動程序版本號為344.11。CUDA開發環境為V6.5,SDK版本為4.2.9,CPU和GPU所使用的開發編譯環境為Visual Studio2013。
圖5為Geforce GTX Titan Z顯卡的CUDA詳細參數,每個處理器的最大線程數為2048個,每個block中的線程數為1024個。還包括Grid和不同維度上block塊的大小(維度上不對稱)。最重要的是memory pitch數據的大小為2147483647 Bytes,這個參數與復制的數組的容量有關。
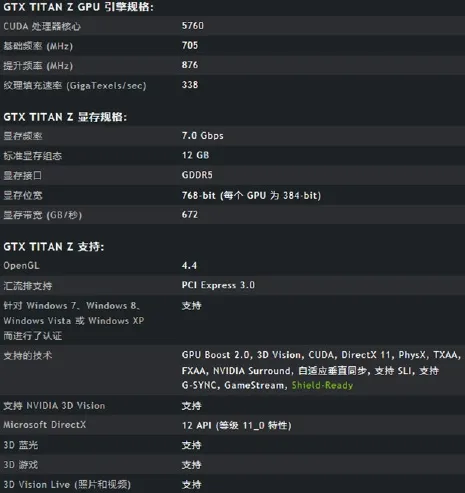
圖4 GPU詳細的引擎規格
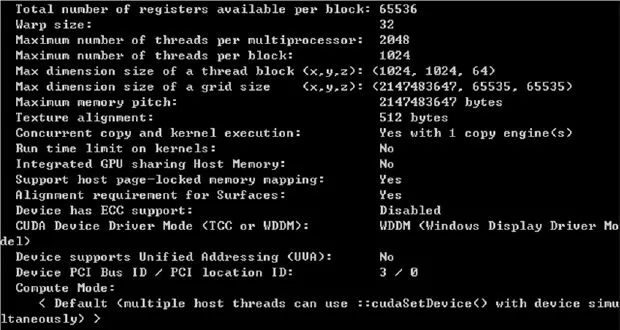
圖5 CUDA詳細參數
2 CUDA并行化的實現
GPU并行化程序的調試,首先實現在CPU上的單線程過程,通過單線程程序再改寫成GPU多線程并行化程序,這樣做的好處是能方便的計算出GPU相對于CPU的性能提升比。由于在支持超線程技術的單CPU上目前線程數一般不會超過48個線程。因此使用CPU進行多線程解決大數據問題并不具有可操作性。
2.1 CPU單線程Bitslice程序設計
單CPU端的單線程的Bitslice程序的流程如下:輸入兩個8字節的明文iv_p和pt_p這兩個數字按位做異或運算,運算后得到64位的明文并存在在ptext[64]中,每一個字節的最后一位與前七位進行與操作,判斷是否為非零,如果非零則輸出非零的無符號長整型,否則則輸出零。將這個數作為明文存在p[64]中。同樣的道理將密文和預輸入的key也存在c[64]和k[64]中。在32位系統中32bit為25,取位長的log值,使key的后五位與1或運算,如果這5位bit數與密文的相對應的bit位一致則進行另5bit位的比較,一次比較相當于進行了32次密鑰搜索,Bitslice程序相當于自身并行運行提高破解效率。CPU單線程Bitslice程序不對密鑰數據分組,會從高位一直向低位遍歷,每一字節為0~255的數,通過Bitslice程序和最后一位奇偶效驗位的簡化,0~255被分成1,3,5,7.....255的128個數,相當于每個字節搜索128個數。如表1所示,程序將key[56]的一維數組輸入到deseval函數中進行計算,如果對比發現為0,進行increment_key函數改變key的5個bit位之后的一位置為無符號的1,再進行deseval函數計算,以此類推直到所有的bit位全部對上才算找到key。

表1 CPU遍歷key的查詢函數
2.2 GPU多線程Bitslice程序設計
GPU多線程Bitslice程序設計的主要思想則是為了多線程的調用而優化的,它是將密鑰數據進行分組到每個block中,每個block中的線程又執行不同分組的數據密鑰,眾多的線程累加起來完成全部的密鑰空間。將密鑰分塊為若干個區域,每個區域作為一個流要執行的部分。再次使用與流數相關的第二個區域作為第二個流的數據區域,以此類推。
而對于每個數據分塊,直到線程為止。定義每個塊中含有256(ThreadN)個線程,含有BlockN個塊。因此,ThreadN×BlockN就是一共含有的線程數。將大數據分成ThreadN×BlockN個小模塊中處理,假設單步處理總時間為T,理想情況下所需時間應為T/ThreadN×BlockN,但是實際情況下顯卡處理器性能會對其產生限制。舉例說,顯卡處理器為W位,在ThreadN×BlockN>W的情況下,數據處理仍是位一組,提高時速應在W倍附近。數組的列即枚舉key的bit長度——56位長度。
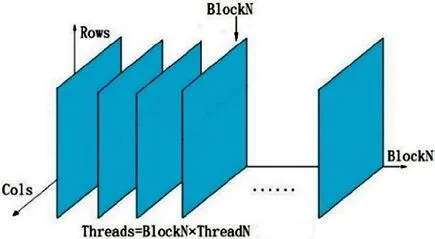
圖6 數據分組結構示意圖
數據分組結構的示意圖如圖6所示,假設形成標準的XYZ三軸坐標軸體系,那么X軸就為BlockN表示塊數。Z軸為Rows表示每塊數據的一個數據的首地址。Y軸為Cols表示為經過Bitslice轉換的56位密鑰的數據。由CPU端到GPU端涉及到線程關聯問題,即將現有問題或數據分成多塊,并將這樣的數據多塊與每一個線程關聯,得到一個與線程ID有關的函數。這樣每個線程ID與沒有數據塊進行關聯后進行計算可以得到每個線程計算的結果。如表2,GPU遍歷Key的查詢函數,但是數據塊ID與線程ID的關聯模型并不是惟一,不同關聯方式對性能的影響也不一樣。

表2 GPU遍歷key的查詢函數
在程序中Dsize的大小很重要,這個參數用于控制枚舉的數量。在GPU并行多線程中,有些線程會重復操作,因此以密鑰的一個字節為例:枚舉{255,0,0,0,0,0,0,0}時,Dsize的數量最小為 Threads×3+1。當枚舉 {255,255,0,0,0,0,0,0}時,Dsize的數量最小為 Threads×511+1。枚舉 {255,255,255,0,0,0,0,0}時,Dsize的數量最小為Threads×65535+1。
我們設計的程序分塊的思想為前3個字節都為0,讓GPU去累加,而從第4個字節開始使用Bitslice思想讓其分為128段(1,3,5,7...255)。以線程數的累加增加分塊的數量同時增加密鑰的累積長度,實現在同等時間內搜索密鑰的長度更長。Dsize與搜索時間的關系圖如圖7所示。
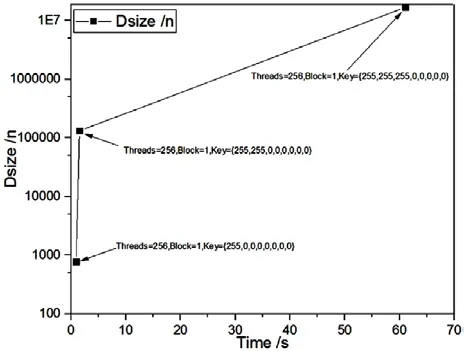
圖7 時間隨Dsize變化的趨勢圖
由于單粒GPU的并行量和計算速度都不可能獨立破解DES算法。因此,為了能驗證GPU并行化所帶來的優勢,在一定密鑰的長度下同時考驗GPU和CPU所花費的時間來計算GPU加速倍數,且這個密鑰的長度不能選擇太長,由于CPU計算時間過長而失去驗證的意義。選取密鑰長度為{255,255,255,255,255,1,1,1},即密鑰長度為2^36次方。使用GPU多線程計算設計線程為16384個線程,Dsize大小為:1073741824,窮舉出密鑰的時間為402秒,而通過CPU進行計算的Bitslice程序在計算同樣密鑰長度的時間為:15343秒。因此可以看出使用GPU數據分塊,并行計算的性能提升是使用CPU的38.2倍。由于在一個GPU中的一個Grid中最大的線程數只能是65536個。因此使用GPU單流的最大BlockN為:256個。無論如何優化這個程序在單核單網格的情況下窮舉DES的全部密鑰成為天方夜譚。必然會想到使用多網格計算或多核計算繼續優化并且擴大并行化操作。在使用多核計算之前,本文先介紹一種流技術的多網格優化方法。下面我們首先對使用CPU和GPU進行計算的性能差異進行簡單的分析,進而論述多網格優化的Stream技術。
3 性能分析及優化
3.1 SSE2 vs CUDA
采取Microsoft Windows 10 Professional 64bit操作系統,Intel(R) Core(R)i5-2300 @2.8GHz CPU8GB 內存,軟件則使用SSE2加速算法。當前的x86處理器采用亂序執行和緩存上下文讀取,使用CPU的軟SSE2指令集計算同樣的程序,事實是CPU的執行效率和速度明顯的優于GPU的單線程。使用不同的配置進行測試,SSE2優化代碼(基于位計數的查表法)通常會快很多,而使用矩陣換位變換的則速度完全相同。這一點在英特爾凌動處理器上的SSE2代碼更為突出,因此英特爾凌動處理器Atom的單指令多數據流(Single Instruction Multiple Data,SIMD)單元明顯是經過定制優化。Nehalem微架構實現了硬件POPCNT,所以應該會更快。但不幸的是,有證據表明它并沒有不執行POPCNT真正的SIMD128位版本,所以SSE+ POPCNT組合成為最后的選擇[17-21]。
數據組作為GPU不變參量傳入,常量內存交換速度快,但速度也就相當于CPU的Cache緩存速率。因此設定傳入GPU的常量數組或數據為share類型。但是通常share類型的數據存儲容量非常有限,一般的share類型的容量僅有16K。實現線程ID與數據結構ID的關聯時,則必須找到起始線程和寄存器之間復制關系代碼,且由于CUDA使用的是地址復制,一般在一維數組的復制上很容易編程,而在二維、三維數組的復制時,必須找到代碼與硬件調用之間的良好平衡。這也就是為什么CUDA的例子里很少有使用二維以上的數組。如表3所示為主機端到設備端的二維數組復制的方法。如果使用Stream流技術進行優化的話,需增加一維為流ID,則主機端(Host)到設備端(Device)的數據復制為三維數組復制。

表3 Host-to-Device多維數組復制

cudaMemcpyHostToDevice);hKo = (unsigned int**)malloc(ROWS*sizeof(unsigned int*));ho = (unsigned int*)malloc(ROWS*COLS*sizeof(unsigned int));cudaMalloc((void**)(&dKo),ROWS*sizeof(unsigned int*));cudaMalloc((void**)(&dco),ROWS*COLS*sizeof (unsigned int));hRes = (unsigned int*)malloc(8 * sizeof(unsigned int));cudaMalloc((void**)&dRes,sizeof(unsigned int) * 8);hbuf = (unsigned int**)malloc(ROWS * sizeof(unsigned int*));for (int i = 0;i < ROWS;i++){cudaMalloc((void **)&hbuf[i],ROWS * sizeof(unsigned int));}cudaMalloc((void**)(&dKK),ROWS*sizeof(unsigned int*));for (int i = 0;i < ROWS;i++){cudaMemcpyAsync(hbuf[i],KK[i],sizeof(unsigned int)*ROWS,cudaMemcpyHostToDevice);}cudaMemcpyAsync((void*)dKK,(void*)hbuf,ROWS *sizeof(unsigned int*),cudaMemcpyHostToDevice);hKo = (unsigned int**)malloc(ROWS*sizeof(unsigned int*));for (int r = 0;r < ROWS;r++){hKo[r] = dco + r*COLS;}cudaMemcpyAsync((void*)(dKo),(void*)(hKo),ROWS*sizeof(unsigned int*),cudaMemcpyHostToDevice);
頻繁進行host到device之間的上下文內存傳輸時,CUDA內核視調用內存上下文訪問為高延遲操作。這對于相對簡單的和高速整數運算尤為重要,這能提高計算程序調用硬件的效率。而對于需要頻繁進行內存操作交換數據的程序則不能通過GPU進行加速。顯卡沒有操作系統或者受控于自身的復雜任務規劃或調度,硬件的直接訪問可以很好地對任務進行擴展。允許將程序分割成不均勻子任務。但是,不能并行太多不同的任務異步。由于著色器可預見的復雜和脆弱的存在。CPU-GPU中間件復雜限于結合并行在GPU上執行的任務次數。
總之,CPU編程中使用SIMD矢量編程(SSE)是需要一定編程技巧的,這里的主要問題是當前一代SSE并不是完整的圖靈架構。從Michael Abrash[21]似乎看出LEBni(Larrabee的矢量指令集)將更好,Larabee有512位矢量寄存器。另外,Nvidia公司似乎并沒有重點發展異構計算架構,其麥克斯韋架構也沒有慢上下文切換。上下文切換計算可以使得GPU像CPU一樣,利用上下文切換來管理多任務,每一個任務都可以通過分時的方法利用計算機資源。隨著AMD公司的GCN異構計算架構(計算單元是基于新指令集的架構,拋棄了以往的VLIW(甚長指令字),而且每個計算單元都能同時從多個內核那里執行指令,單位周期單位面積的指令數也有所增加。這種架構相比以往利用率和吞吐量更高,多線程多任務并行執行的能力也大大增強)的發展,GCN架構的緩存體系也經過了完全重新設計,規模相當龐大而復雜。每四個計算單元共享16KB指令緩存和32KB標量數據緩存,并與二級緩存相連;每個計算單元都有自己的寄存器和本地數據共享,搭配16KB可讀寫一級緩存,每時鐘周期帶寬為64字節;二級緩存總容量768KB,可讀寫,對應每個顯存控制器分成六組,每組容量128KB,每時鐘周期帶寬也是64字節;全局數據共享則用于不同計算單元之間的同步輔助。因此通用計算平臺會成為GCN vs CUDA的對立格局。
3.2 Stream流技術優化
一些計算能力2.x或更高的設備可以同時并行執行多個內核函數。應用程序可以檢查設備屬性中的concurrentKernels項來確定設備是否支持這一功能,值為1代表支持。運算能力3.5的設備在同一時刻能夠并行執行的最大內核函數數量為32,運算能力小于3.5的硬件則最多支持同時啟動16個內核函數的執行。同時需要注意的是,在一個CUDA上下文中的內核函數不能與另一個CUDA上下文中的內核函數同時執行。使用很多紋理內存或者大量本地內存的內核函數也很可能無法與其他內核函數并行執行。為了并行化數據拷貝和內核執行,主機端內存必須分配為鎖頁(page-locked)內存其模塊結構如圖8所示[22-26]。
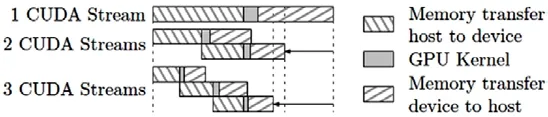
圖8 CUDA流技術加速原理示意圖
流的作用是任務之間的并行化,把要計算的數據分塊,讓不同的流執行不同的數據塊,這樣Stream1執行數據塊1的時候,Stream2把數據塊2從內存拷貝到顯存,這樣做不用等到所有數據拷貝完之后再計算從而提高并行力度。通過使用Stream流技術加速并擴大并行運算密鑰Key的長度后,可以實現240次方的密鑰長度計算時間為7.46小時。這個長度的密鑰在CPU上的實現是非常困難的。但是在GPU多線程并行加速的架構下,只需執行幾個小時即可完成。但是這個長度的密鑰離完全窮舉完全部密鑰還差很遠,以這樣的速度計算下去全部窮舉完的時間是無法接受的。
4 結束語
計算速率競爭的時代已經結束,現代的計算全面進入到并行時代。這意味著算法和系統的自適應性,并行架構的組織以滿足數以萬計的并行線程的現實,其中數據需要分塊、重組,減少沖突和適應并行訪問將成為并行計算的核心計算。GP-GPU計算的使用必須使用大量的計算資源,結合不斷增長的數據挖掘集群服務器才能提供高效的計算服務。結合目前發展的快速隨機訪問固態硬盤SSD、高速RAM驅動器、DDR4代內存以節省帶寬減緩可以提供更高效的上下文訪問機制。并行計算作為一種科學手段,隨著科研需求而迅猛發展,幫助學者們解決了很多復雜、冗余的問題。同時也給密碼計算帶來了前所未有的挑戰,傳統的CPU密碼計算逐步的轉向了分布式GPU陣列密碼破譯網絡。通過使用大量并行多線程技術,能有效的降低密碼在單線程任務上的計算容量,大量的線程任務同時工作提升了計算效率。雖然相比單CPU的Bitslice程序而言已有38.2倍的性能提升,但是其單個GPU的計算性能仍無法在可接受的時間內破解DES算法,因此,下一步的工作就是通過使用MPI多機技術將多塊GPU組建成集群多機計算陣列。從上述研究可以表明DES在GPU上的運算并不消耗過多的計算資源,因此,每一個GPU的性能并不需太強,可以降低集群計算陣列的整體成本,同時也實現解決問題的目的。
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
