提高fuzzing 邊覆蓋率的改進方法
2019-12-03 07:54:10賈春福嚴盛博王志武辰璐黎航
通信學報 2019年11期
關鍵詞:實驗
賈春福,嚴盛博,王志,武辰璐,黎航
(1.南開大學網絡空間安全學院,天津 300350;2.南開大學人工智能學院,天津 300350)
1 引言
fuzzing[1]是一種有效的漏洞挖掘技術,它通過生成大量的測試用例來對目標程序進行測試,同時監視目標程序的運行過程,發現程序暴露出的缺陷。傳統的fuzzing 工具由于生成測試用例時過于隨機,其測試存在盲目性,雖然測試速度很快,但效率很低。針對fuzzing 存在的問題,研究者提出了很多新的技術和方法,結合覆蓋引導、靜態分析、動態符號執行、語法表示、動態污點分析和機器學習等多種技術,大大提高了fuzzing 的效率,并且在現實的軟件中發現了大量漏洞[2]。
覆蓋引導的fuzzing 策略被廣泛使用,并且已被證明是非常有效的。它盡可能地測試更多的代碼分支,使程序的代碼覆蓋率實現最大化。目前,代碼覆蓋率有2種基本的測量方式。一種是計算基本塊(BBL,basic block)覆蓋數,Libfuzzer、honggfuzzy和VUzzer[3]都是通過程序插樁來跟蹤BBL 的覆蓋信息。另一種是計算邊覆蓋數,AFL(American fuzzy lop)是第一個將邊覆蓋引入fuzzing 的工具,其通過編譯時靜態插樁,當程序運行時可獲取邊覆蓋信息,提供了比BBL 覆蓋更加精確的信息。
最近幾年發表了大量基于AFL 的研究。一類研究是定向fuzzing。例如,AFLGo[4]和Hawkeye[5]通過對程序的靜態分析來調整種子排序和種子的測試次數,逐步引導程序到達目標點。另一類研究結合了符號執行技術。Driller[6]使用選擇性的混合符號執行技術,當AFL 被“卡住”時,調用 Angr[7]來生成合法輸入,從而有效地分析大規模程序。WildFire[8]先通過單獨測試程序中的函數來發現漏洞,再使用KLEE[9]來校驗這些漏洞的可行性。還有一類研究結合了人工智能技術。孫鴻宇等[10]分析了人工智能技術在安全漏洞領域的應用。Godefroid等[11]基于神經網絡的統計機器學習,生成富含格式的文件作為AFL 的初始種子。Skyfire[12]從樣本中學習一種概率上下文敏感語法(PCSG,probabilistic context sensitive grammar)來描述語法特征和語義規則,利用PCSG 生成具有不同語法結構的種子輸入,從而為處理高度結構化輸入的程序生成正確、多樣和不常見的種子。
然而,AFL 本身也存在一些缺陷,通過對這些缺陷的修復,可以優化上述方法的效果。例如,CollAFL[13]針對AFL 邊覆蓋記錄存在沖突的問題,通過靜態分析生成新的hash 計算式,把沖突率降低到接近0,大大增加了覆蓋信息的準確率,提升了AFL 的效果。
此外,本文研究團隊也發掘出AFL 中隱藏的幾個缺陷和可以進一步改進的地方,主要有以下幾個方面。1)AFL 的種子選擇算法存在缺陷。其進行選擇時,實際隱含了一個固定順序,使隊列中排在越后面的種子被選中的概率越低。更嚴重的問題是,執行完一輪循環后,被選中的種子可能并沒有覆蓋到所有的邊。2)AFL 對每個選中的種子執行的變異次數幾乎一樣,沒有考慮到每條邊的熱度(即這條邊被覆蓋到的次數)。3)AFL 會記錄哪些字節變化時會產生新的狀態轉移,但是這些記錄信息未被有效利用,并且在從進程中無法使用這些記錄信息。
針對上述問題,本文著眼于AFL 算法的缺陷,同時對一些功能進行了改進,具體包括以下幾個方面。
1)提出了完全覆蓋種子選擇算法。該算法隨機打亂邊的順序,以打亂后的順序進行種子選擇,且只選擇隊列中位于當前位置之后的種子,最后對覆蓋情況進行檢查并修復覆蓋不全的問題。本文所提算法避免了按固定順序選擇優先種子集,同時也避免了對邊覆蓋不完全的情況。
2)提出了基于邊覆蓋熱度的能量調度算法。根據路徑中邊的覆蓋熱度,對每條路徑進行評分,以此為依據動態調整每個種子文件的變異次數。
3)增加對有效字節的利用。在進行隨機性變異時,更多地對有效字節部分進行變異。同時加快了有效字節的產生,并在主進程和從進程之間同步有效字節信息。
基于上述方法,本文在開源的AFL 工具上,設計和實現了新的fuzzing 工具—efuzz,并按照Klees等[14]提出的測試思想進行實驗,實驗結果表明efuzz的邊覆蓋和漏洞發現能力都超過了 AFL 和AFLFast。使用常用軟件測試24 h 后,efuzz 的平均邊覆蓋數相比AFL 和AFLFast 分別提升了5%和9%,某些情況下甚至達到20%以上。使用LAVA-M[15]測試7天后,efuzz 發現的漏洞總數超過了AFL。在常用軟件中,efuzz 發現了3個新的CVE漏洞,其中一個是 binutils 工具包中的漏洞CVE-2018-20671,該漏洞從2001年起就已存在。
2 相關知識和技術概述
2.1 AFL 概述
AFL 是一個覆蓋率引導的灰盒測試工具。它基于遺傳算法,采用編譯時插樁的方式,通過獲取被測試程序運行時的覆蓋信息反饋,來判斷是否觸發了目標程序新的內部狀態,從而發現感興趣的測試用例,以此引導fuzzing 策略,這大大提高了測試工具的覆蓋率。
圖1展示了AFL 的簡易流程,具體步驟如下。
步驟1提供一個初始輸入集加入種子隊列。
步驟2按照種子選擇算法從種子隊列中選擇優先種子集。
步驟3按預設概率,順序從種子隊列中選擇一個種子文件。
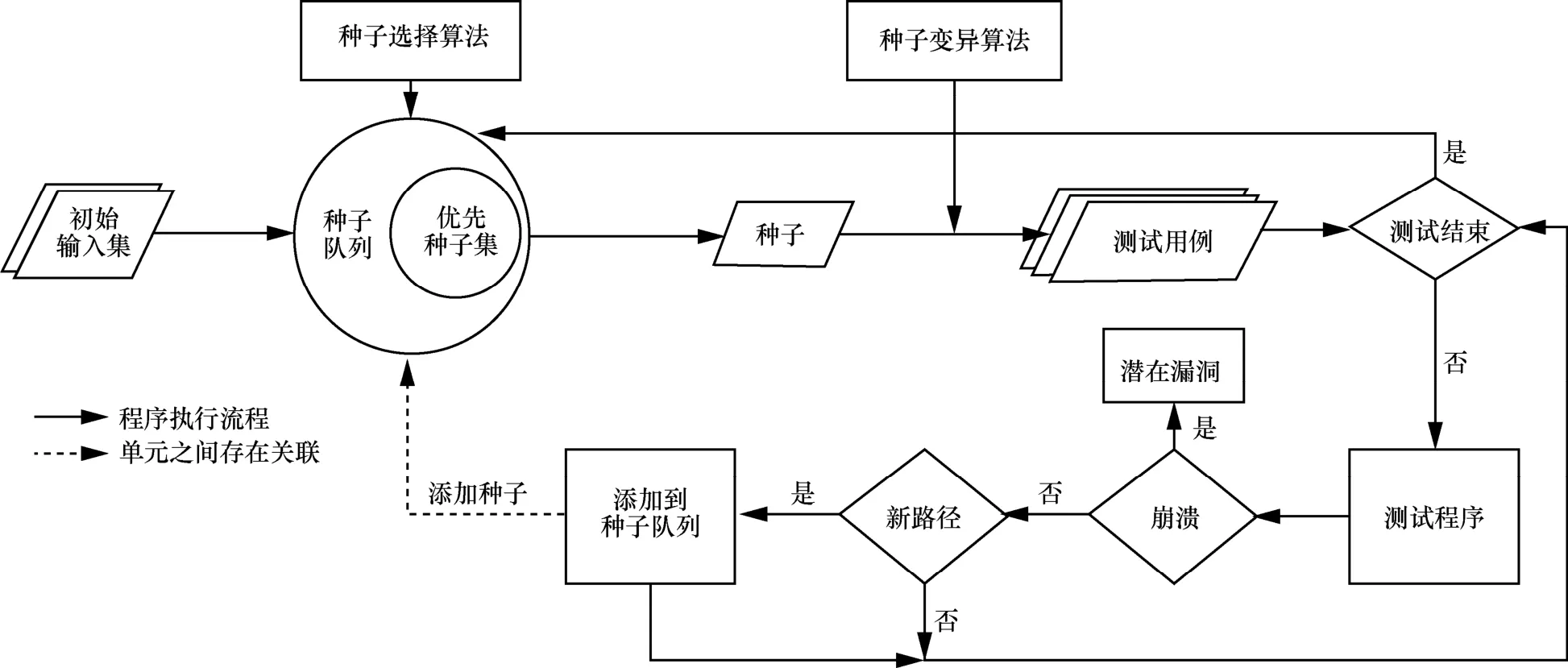
圖1 AFL 簡易流程
步驟4使用多種變異算法對種子文件進行變異,循環生成大量測試用例進行測試。
步驟5如果發現程序崩潰,那么這可能是一個潛在的漏洞。
步驟6如果發現了新的路徑,那么把生成該路徑的測試用例加到種子隊列。
步驟7對該種子生成的所有測試用例,如果測試結束,回到步驟3。
整個測試是一個無限循環過程,直到人工終止。
2.2 邊覆蓋記錄
AFL 記錄的邊覆蓋信息包括邊的hash 以及這個邊被命中的次數。邊覆蓋信息使用規模為216的數組記錄,邊hash 作為數組的索引,數組中的值是邊被覆蓋的次數。為了加快處理速度,AFL 在每個BBL 中插入了一個0~65535的隨機數,邊hash 是由邊的首尾2個BBL 中的隨機數通過簡單hash 算法生成的,記錄覆蓋信息的算法偽代碼如下。
1)edge_hash=cur_bbl ^(last_bbl >>1)
2)shared_mem [ edge_ hash ]++
很顯然步驟1)中的hash 算法會存在沖突問題,但這不是本文的研究重點。本文把一個hash 記錄直接對應為一條邊覆蓋記錄。
2.3 種子選擇算法
fuzzing 中如何從種子隊列中選擇種子是一個非常關鍵的問題。之前的工作已經證明,良好的種子選擇策略可以顯著提高模糊效率,更快地發現更多的bug[16]。
為了理解AFL 的種子選擇算法,首先介紹以下2個概念。
優先種子。覆蓋到某一條邊的最好種子稱為該邊的優先種子。最好種子就是所有能夠覆蓋到該邊的種子中,對其進行一次完整測試所消耗時間最短的種子。
優先種子集。可以覆蓋當前已經發現的所有邊的優先種子集合,即優先種子集的覆蓋面等價于當前所有種子的覆蓋面。
AFL 調用種子選擇算法從整個種子隊列中選出優先種子集,隨后按概率優先選擇其中的種子來進行測試。該算法本質上是一個貪婪算法,如算法1所示。
算法1AFL 的種子選擇算法
輸入每條邊對應的優先種子T[65536]、種子隊列Q
輸出選擇結果S

算法1按照邊的hash 值,在0~65535范圍內按從小到大的順序選擇該邊的優先種子,直到覆蓋所有已發現的邊。由于被測試程序編譯生成后,所有邊的hash 值就已經確定了,因此這實際上是一個固定的選擇順序。
2.4 能量調度
B?hme 等[17]提出了能量的概念,能量指一個種子被選中后的測試次數。能量調度即按照一定算法對能量進行控制。AFL 給每個種子分配相同的能量,這忽略了對路徑稀有度的考量,可能將過多的能量分配給高密度區域[18]。AFLFast 使用馬爾可夫模型,給低頻路徑分配了更多的能量。但是,AFLFast 總是朝著低頻路徑,可能會錯失對一些邊的探索,導致代碼覆蓋率不高。Klees 等[14]也指出了AFLFast 的這個問題。
2.5 有效字節信息
如果對種子文件中某個字節進行翻轉后產生了與原種子對應路徑不同的新路徑,那么這個字節就是有效字節。下面具體解釋相關概念。
確定性階段和隨機性階段。AFL 分為確定性測試和隨機性測試兩大類。確定性測試階段對種子的變異方式是高度確定的,且每個種子只會經歷一次確定性測試,而隨機性階段會調用一些隨機算法對種子進行變異。
主進程和從進程。AFL 可以有多個進程并行工作,主進程對每個選中的種子先進行確定性測試,再進行隨機性測試;從進程只進行隨機性測試。同時,主進程和從進程之間定期進行種子同步。
AFL 使用如下方法來記錄有效字節信息。當一個種子經過確定性階段的字節翻轉子階段時,觀察種子文件中某個字節的翻轉對執行路徑是否有影響。如果對這個字節翻轉后,產生了與種子對應路徑不同的新路徑,則使用 eff_map(effector maps)來記錄這個字節,在確定性測試的剩余子階段中只對eff_map 中記錄的字節進行變異。這樣一般可以將測試的執行次數減少10%~40%左右,而不會顯著降低覆蓋率。在極端情況下,例如塊對齊的tar 文件,執行次數可能減少高達90%。
3 fuzzing 改進方法
3.1 完全覆蓋種子選擇算法
AFL 的種子算法本身基于如下完全覆蓋性約束:選出的優先種子集必須能完全覆蓋所有已經發現的邊。通過2.3節的介紹以及實驗測試,發現算法1存在以下缺點。
1)按照邊的hash 值以0~65535的固定順序選擇,導致種子被選中的概率相差太多,hash 較小的邊對應的優先種子總是被先選擇。舉個極端的例子:按照算法1,假設hash 值為0的優先種子T[0]被選中,而T[0]對應的種子為s0,如果s0生成的路徑剛好覆蓋了所有已發現的邊,那么每次都只會選擇s0這一個種子,其他種子永遠無法被選到優先集合。在實驗中記錄每次選出的優先種子集也發現,每次選擇出的優先種子集變化極小。如果采用隨機的順序進行種子選擇,可以緩解這個問題。
2)AFL 每測試一個種子后,如果種子隊列發生了變化,就會調用一次算法1,這可能導致執行一輪循環后,有的邊沒有被覆蓋,這種情況違背了完全覆蓋性約束。出現這個問題的根本原因在于選擇了隊列中位于當前位置之前的種子,具體以代碼1為例進行說明。
代碼1AFL 種子選擇算法缺陷示例代碼

代碼1編譯后對應的控制流程如圖2所示。
圖2中每條邊上的數字代表該邊的編號,以ei表示邊i,只有順序通過邊e2、e6、e14的路徑才會觸發bug。
以qj表示第j條路徑,假設初始發現的6條路徑如表1所示。
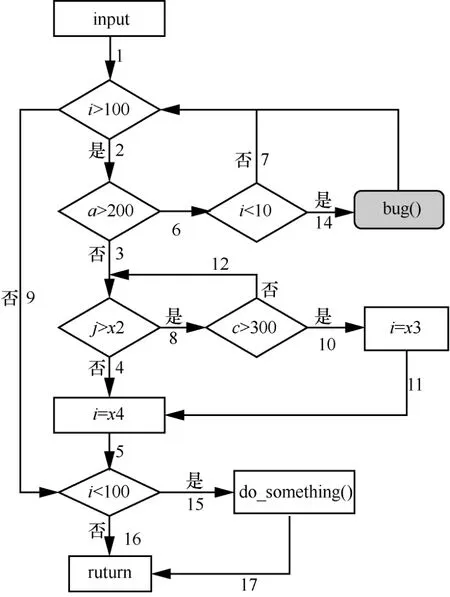
圖2 AFL 種子選擇算法缺陷示例

表1 路徑說明
假設這些邊經過hash 運算后的值,從小到大的順序為(e9,e8,e17,e6,…),且測試按照以下步驟進行。
步驟1測試q1,發現新路徑{q2,q3,q4},這時覆蓋的所有邊集合為{e1,e2,e3,e4,e5,e6,e7,e9,e15,e16,e17}。調用算法1選擇優先種子集,按照邊hash順序(e9,e17,e6),先選擇e9對應的優先種子q4,再選e17對應的優先種子q3,這時已經覆蓋了所有邊,選擇結束,優先種子集的結果為{q3,q4}。
步驟2q2不在優先種子集中,被跳過。
步驟3測試q3,發現新路徑{q5,q6},這時覆蓋的所有邊集合為{e1,e2,e3,e4,e5,e6,e7,e8,e9,e12,e15,e16,e17}。再次調用算法1,按邊hash 順序(e9,e8,e17,e6),先選擇e9對應的優先種子q5,再選擇e8對應的優先種子q6,由于e17已經被q6覆蓋,對其跳過處理,最后選e6對應的優先種子q2,選擇結束,結果為{p5,q6,q2}。
步驟4q4不在優先種子集中,被跳過。
步驟5測試q5。
步驟6測試q6。
整個測試過程中,按照種子隊列從前向后的順序判斷是否選擇該種子,沒有對可到達e6的q2和q4進行測試。雖然AFL 存在隨機性變異,也有可能通過其他種子變異出到達e6的測試用例,但是隨機性變異過于盲目,概率過低,導致很難到達e14,從而無法觸發bug。
上述例子說明了AFL 在一輪循環中,雖然每次選擇的優先種子集能覆蓋所有已發現的邊,但是真正測試的種子卻可能會漏掉某些邊。上述情況看似概率很小,但是本文通過實驗發現這種情況大量存在。
針對上述2個問題,本文提出了完全覆蓋種子選擇算法,如算法2所示。
算法2完全覆蓋種子選擇算法
輸入每條邊對應的最好種子T[65536]、種子隊列Q、當前位置queue_cur
輸出選擇結果S

算法2共分為4個步驟,具體如下。
步驟1把本次循環中已經測試過的種子文件直接加入S并更新C。
步驟2生成0~65535的亂序排列。
步驟3按照步驟2生成的序列從T中挑選種子加入S,并更新C。只有當前位置之后的種子才會被加入S。
步驟4檢查每條邊是否被覆蓋,如果沒有覆蓋,從當前位置向后找到一個可以覆蓋該邊的種子文件,添加到S并更新C。
下面使用數學歸納法對上述算法的覆蓋完整性進行證明。
1)測試開始時第一次選擇的優先種子集顯然可以覆蓋到所有已經發現的邊。
2)假設第n次選擇的優先種子集Qn能夠覆蓋到所有已經發現的邊。當第n+1次選擇時,當前位置把Qn切分為兩部分,一部分是在當前位置之前(不包含當前位置)的集合Q1,另一部分是當前位置之后(包含當前位置)的集合Q2。如果出現了新的邊,這些邊對應的種子文件會被增加到隊列尾部,這些新種子文件的集合記為Q3。根據假設,可推導出Q1∪Q2∪Q3能夠完全覆蓋當前所有的邊。按照算法2,在步驟1中Q1全部被選中,而步驟4是檢查步驟,當發現某條邊e尚未被覆蓋時,則e?Q1,那么必然有e∈Q2∪Q3,這說明從當前位置向后查找,一定可以找到一個種子文件對應的路徑包含e。因此,步驟4完成后可保證對邊的完全覆蓋。
上述證明說明算法2滿足完全覆蓋性約束,同時算法2采用亂序選擇,且從當前位置開始選擇新的優先種子,可以有效避免出現算法1的2個缺點。
3.2 基于邊覆蓋熱度的能量調度算法
王志等[19]分析僵尸網絡控制命令時,提出了BBL 覆蓋率的概念,用來描述一個BBL 被執行路徑覆蓋的頻繁程度。受此思想啟發,本文用邊的熱度來描述一條邊被所有路徑覆蓋的次數,結合2.4節的分析,提出了一個新的能量調度算法。
用N(e)表示邊e的熱度,計算式為
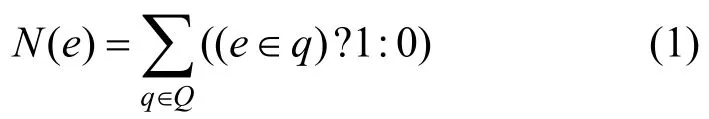
邊的評分與該邊的熱度成反比,即這條邊被覆蓋的次數越多,評分越低。每個種子文件對應一條執行路徑,一條執行路徑由多條邊組成。路徑評分為該路徑中邊的評分之和,p(q)為路徑q的評分,定義為
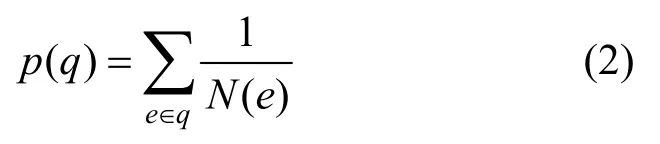
將上述評分進行歸一化,得到路徑q的調整系數,定義為
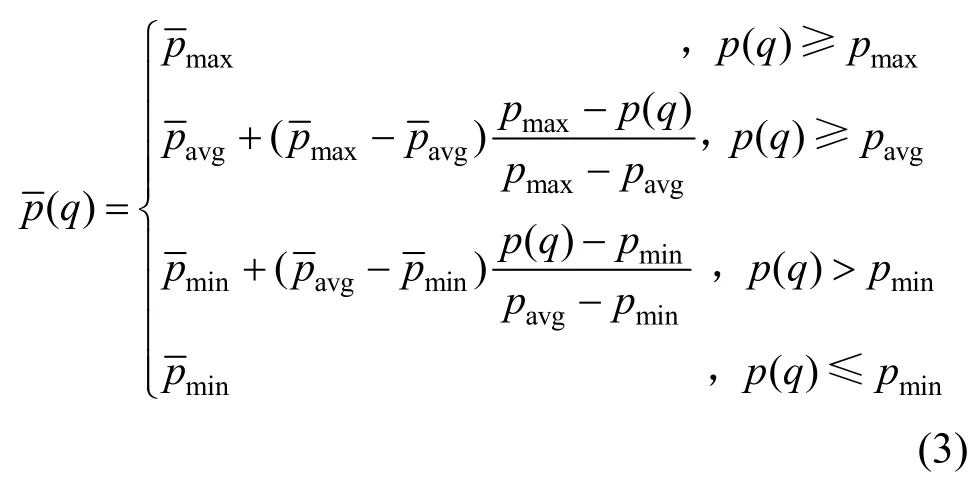
其中,pavg為所有種子對應路徑評分的均值,pmin為最小值,pmax為最大值。分別為預定義的調整系數。
1)熱度越低的邊,被給予越高的權重,有可能得到越多的執行機會。
2)fuzzing 往往難以到達很深的代碼塊,該算法對邊評分采用加法,較長路徑的評分會有更多的優勢,有利于覆蓋更深的邊。但這也可能導致路徑探索被局限在某一些分支上,針對這個問題,在具體實現中可通過對系數的調整來達到一定的平衡。
AFLFast 通過路徑覆蓋頻率來選擇種子,而本文方法則是通過邊覆蓋熱度來選擇種子,通過實驗分析,本文方法在邊覆蓋上比AFLFast 更優。
3.3 有效字節信息的進一步利用
2.5節中提到的有效字節機制非常可靠,并且很容易實現,但是也存在如下問題。
1)只有確定性階段使用了有效字節信息,隨機性階段并沒有使用,未能充分發揮其效果。
2)有效字節信息由主進程產生,但主進程速度很慢。在實驗中發現,有時主進程用一周時間都無法執行完一次循環,這會導致可利用信息非常少。
本文提出了3種進一步利用有效字節信息的方法。
1)在隨機性階段使用有效字節信息引導變異。在應用隨機性算法時,按一定概率只對有效字節進行變異。
2)在從進程中也使用有效字節信息。保存主進程中記錄的信息,供從進程使用。
3)當存在從進程時,主進程去掉隨機性階段,只處理確定性階段,可加快有效字節信息的產生。
針對以上方法,需要在確定性階段把eff_map信息記錄到文件,當從進程對這個種子進行測試時,直接加載這個文件。
AFL 中共有16種變異方法,如表2所示。這些方法中,變異位置都是隨機選擇的。efuzz 中對此進行了改進,按一定概率只選擇eff_map 中記錄的位置進行變異,不再是完全隨機選擇變異位置。

表2 隨機性階段的變異方法
隨機性階段會對文件進行多次變異。除了12、13、16這3種方法可能改變種子文件長度外,其他方法不會改變種子文件的長度。一旦變異過程中文件長度發生變化,eff_map 記錄信息將不再準確。因此,efuzz 把隨機性階段又分成了2個子階段:第一個子階段不采用12、13、16這3種方法;第二個子階段采用所有16種方法,一旦文件長度發生了變化,就立即恢復到AFL 原有的方式。
4 系統設計和實現
AFL 的最新開源版本是2.52b,efuzz 擴展了這個版本,共添加了不到1000行的C 代碼,實現了第3節中描述的技術。
在算法2中對每個種子進行順序編號,相比原來的算法,僅增加了種子選取順序的隨機化處理和最后的檢查,因此整體增加的CPU 消耗幾乎可以忽略不計。
在能量調度算法中,對路徑的評分實際上是很難準確定義的,本文采用了比較保守的策略,設置3個調整系統的值分別為0.2、0.8、4,且只有在發現的總路徑數超過200時,才啟用這一策略。因為該算法中都是浮點計算,為降低計算量,每增加20條以上的新路徑才重新計算一次評分。其次,該算法中所有種子對應的覆蓋信息都要記錄下來,每個種子需要占用8 KB 的內存空間。在本文的實驗中,總路徑很少有超過12000的,因此,總計算次數不會超過600,單個進程的內存增長數不會超過100 MB,對計算機資源的整體消耗非常小。
在確定性階段測試過的種子,需要把它的有效字節信息記錄到一個對應的以.eff 為后綴的文件。eff 文件中每一位表示該種子的1 B 是否是有效,因此eff 文件大小只有種子文件的,對存儲資源的消耗也非常小。
5 實驗與分析
Klees 等[14]指出了當前fuzzing 實驗中普遍存在的一些問題,并給出建議的測試方法,希望能建立統一的測試標準。本文中的實驗按照他們提出的測試思想,以如下方式進行測試。
1)共選擇了5個常用的目標程序,分別是binutils 程序集中的objdump、nm、readelf,以及libtiff和tcpdump。
2)對每個測試程序選擇了5個有代表性的初始輸入,輸入分別來源于空種子、隨機種子、公開的測試樣本、漏洞的POC(proof of concept),表3是實驗中具體使用的輸入文件。由于有些程序使用空種子和隨機種子無法測試,因此本文使用其他種子代替這2個種子的實驗。
3)涉及對邊覆蓋數進行比較的實驗,每個實驗都測試30次,每次測試時間為25 h。由于實驗數據并不是實時更新的,選取第24 h 這個時間點的數據來進行評估。最終結果取30次的平均值。
4)每次實驗使用一個主進程和一個從進程共同測試,更加接近真實使用環境。
5)以AFL 和AFLFast 作為比較對象。AFLFast和efuzz 一樣,也是針對AFL 本身算法的改進,且是開源軟件,方便進行實驗。
6)Stephens 等[6]指出使用唯一狀態轉換的數量作為邊覆蓋的度量是合理的,本文實驗也使用狀態轉換的數量作為邊覆蓋的度量。

表3 實驗使用測試程序和種子文件
實驗共使用了3臺服務器,都是64位Ubuntu 16.04 LTS系統,CPU為Intel(R)Xeon(R)E5-2620 v4@2.10 GHz,內存64 GB,硬盤12 TB。
5.1 邊覆蓋的完整性測試
為了對AFL 和efuzz 的種子選擇算法進行測試,在它們的算法中添加了檢查代碼,每次算法執行完時,都對優先種子集的邊覆蓋情況進行校驗,檢查本輪循環中已測試過的優先種子和當前位置之后還未測試的優先種子是否覆蓋了所有已經發現的邊,如果出現覆蓋不全的情況,則進行日志記錄,并記下每次選擇最多有多少邊未被覆蓋。
實驗用表3中各測試程序對應的5個文件共同作為該程序的初始化種子,只運行1 h。由于efuzz采用了新的種子選擇算法,保證了覆蓋的完整性,結果中并未出現覆蓋不全的情況。而AFL 中出現了大量覆蓋不全的情況,如表4所示。
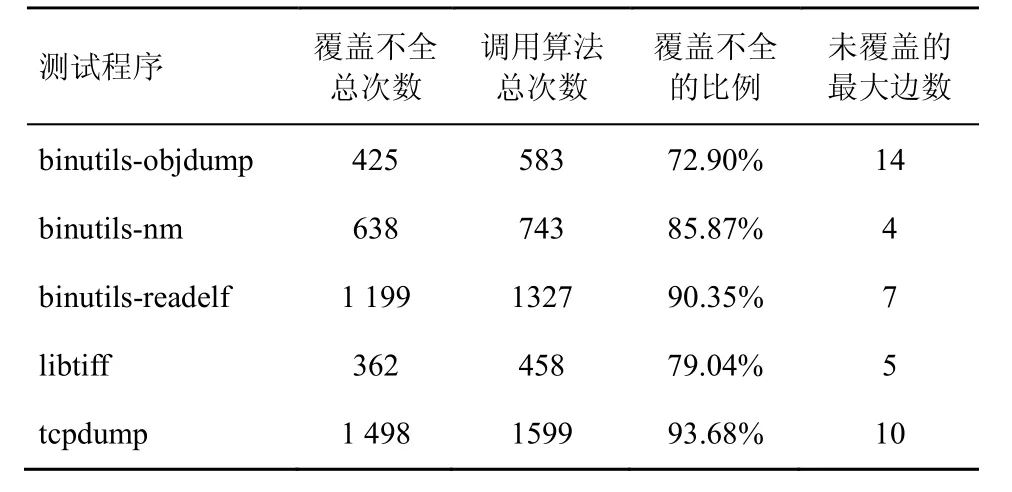
表4 AFL 邊覆蓋不全的記錄
由表4可知,AFL 覆蓋不全的比例非常大,雖然每次未覆蓋的邊數非常少,但依然說明了AFL 的種子選擇算法在一輪循環中并未滿足完全覆蓋性約束。
5.2 能量調度算法和有效字節信息改進的效果驗證
實驗中開發了僅啟用能量調度算法的程序efuzz-Enery 和僅啟用有效字節信息改進的程序efuzz-Bytes,用于單獨測試這2個改進的有效性。每個改進的測試選擇了5個實驗,每個實驗進行30次,結果如表5所示。
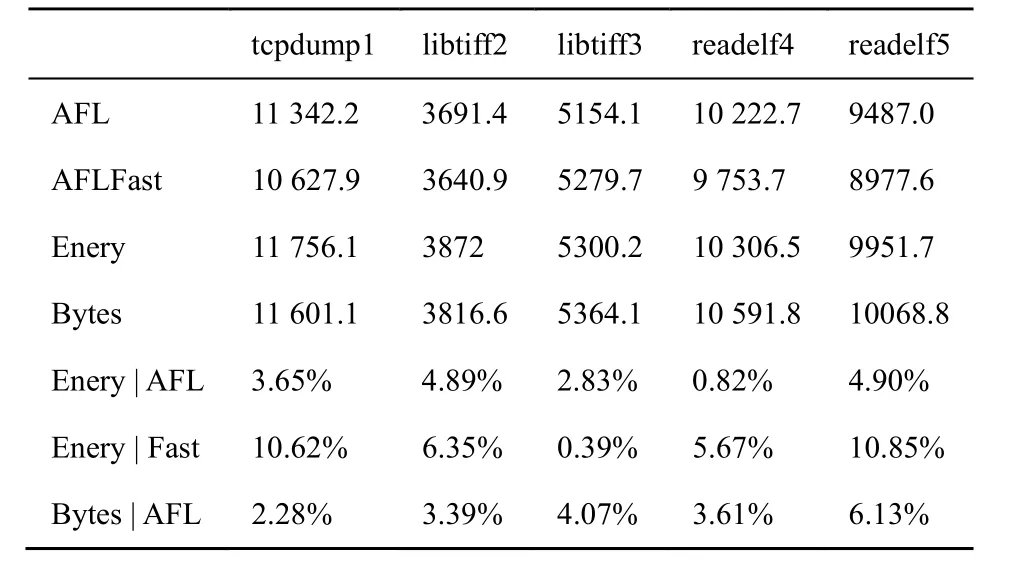
表5 單獨測量的邊覆蓋數
從比較結果來看,efuzz-Enery 相對AFLFast 有比較大的提高,同時比AFL 也有一定提高,證明了本文的能量調度算法比AFLFast 在邊覆蓋率上更有優勢。
通過比較efuzz-Bytes 與AFL 可以看到,efuzz-Bytes 相對AFL 也有少量的提高,說明有效字節信息的合理利用可以在一定程度上提升AFL 的效果。
5.3 efuzz 與其他工具的比較
實驗對比efuzz、AFL 和AFLFast,使用5個程序,并把每個程序對應的5個種子文件分別作為初始輸入,共25組實驗。進行該測試的資源要求非常高,總開銷為25×30×25×2×3=112500核·小時=4687.5核·天。表6是24 h 的平均邊覆蓋數結果,從整體來看,efuzz 在覆蓋數上優于AFL 和AFLFast。同時也發現,AFLFast 在平均覆蓋數上要略差于AFL。
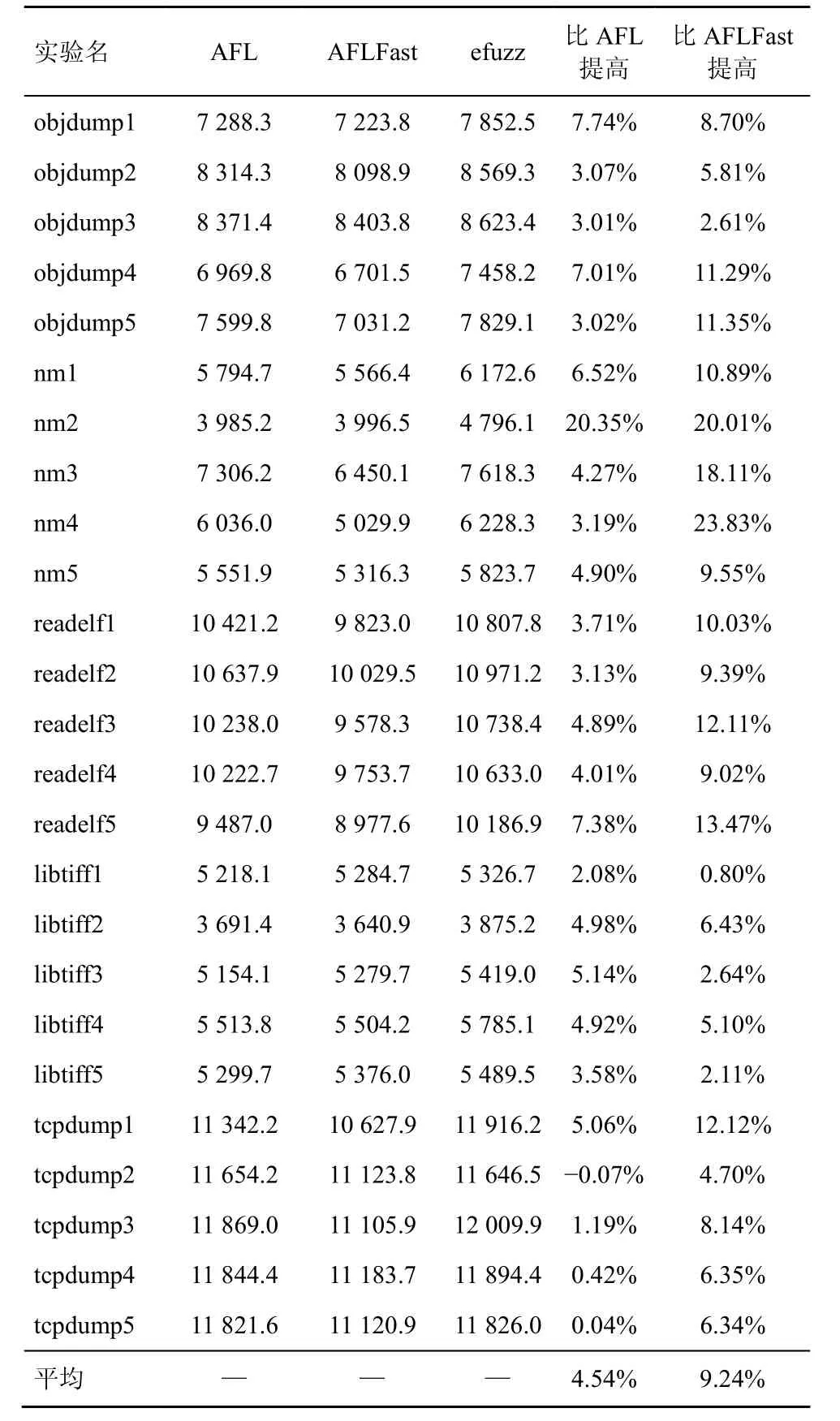
表6 25組實驗的平均邊覆蓋數
單獨分析每一組實驗,efuzz 幾乎在所有情況下都優于AFL 和AFLFast。在nm2中,efuzz 的邊覆蓋數甚至提高超過20%,但在tcpdump 實驗中,efuzz 表現一般,僅僅略好于AFL,tcpdump2中甚至比AFL 低0.07%。這說明本文的改進方法在絕大多數情況下提高了邊覆蓋率,但是在極少數情況下也引入了一些限制。這也進一步說明了Klees 等[14]提出的評估方法的合理性,只有通過大量不同條件下的實驗,才能比較全面地評估fuzzing 工具的有效性。
5.4 LAVA-M 測試
對LAVA-M 中的4個程序,使用其提供的默認種子文件進行測試,每個程序各運行7天。表7中數據顯示,AFL 在base64和uniq 中發現的漏洞數超過了efuzz,但efuzz 在who 中發現的漏洞數遠超AFL,且在4個程序中發現的漏洞總數也超過了AFL。
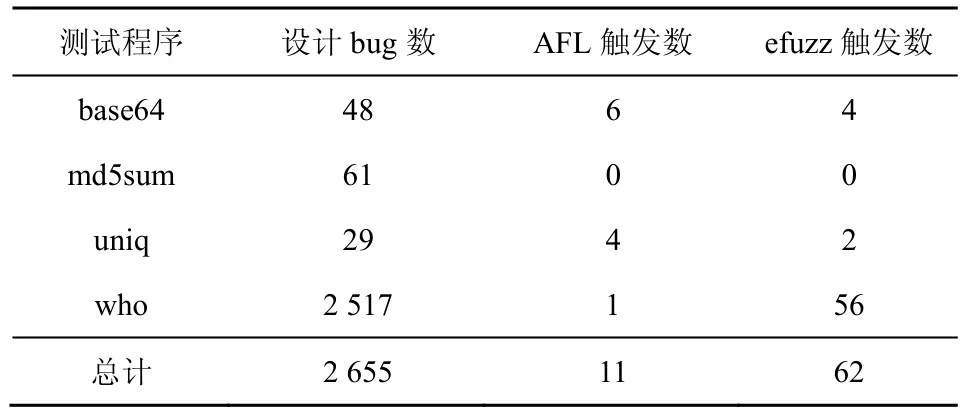
表7 LAVA-M 測試發現漏洞數
LAVA-M 在測試程序中插入了許多字符串比較和整數校驗代碼來阻礙fuzzing 工具,而AFL 的變異算法很難產生適當的輸入繞過這些代碼,導致無法到達新的代碼塊,因此AFL 和efuzz 在LAVA-M上的效果都很差。雖然efuzz 在who 上的表現超過了AFL,但發現的漏洞數也僅占總漏洞數的2%。efuzz 在base64和uniq 上差于AFL,再次說明了efuzz 的改進方法在有些情況下反而效果更差,且同樣對校驗性的代碼無法達到很好的繞過效果。
5.5 新的CVE 漏洞
表8是使用efuzz 發現的3個新的CVE 漏洞,CVE-2018-20671是binutils 中的一個整型溢出漏洞,最終會觸發堆溢出。CVE-2018-20467是ImageMagick 中的一個拒絕服務漏洞,會造成CPU和內存資源的耗盡。CVE-2019-6988是openjpeg 中的一個拒絕服務漏洞,由于其邏輯問題,會長時間占用大量CPU 資源。本文研究團隊向相關廠商反饋了這些問題,現在這3個漏洞都已經得到修復。

表8 efuzz 發現的漏洞
表8中CVE-2018-20671最早存在于binutils 2.11中的objdump 程序,該版本的發布時間是2001年。從那時起,絕大多數的版本都存在這個漏洞。objdump 是一個廣泛使用的二進制工具,也是很多相關論文中的測試目標程序,大量的研究者對其進行fuzzing,都沒有發現這個漏洞。本文使用收集整理的種子文件,用一個進程進行30次測試,efuzz平均只需要519 s 就能發現這個漏洞,而AFL 和AFLFast 在相同時間內都無法發現這個漏洞。這進一步證明了efuzz 的有效性。
6 結束語
目前,fuzzing 是軟件漏洞挖掘領域最有效的方式之一,覆蓋率的提高一直是研究的重要方向。本文首先基于fuzzing 中邊的完全覆蓋性約束,設計了完全覆蓋種子選擇算法,并基于邊覆蓋熱度提出了新的能量調度算法,最后進一步利用了AFL 中的有效字節信息。上述改進方法也可推廣到其他fuzzing 工具中。從實驗結果來看,本文實現的efuzz 相對AFL 和AFLFast 在邊覆蓋率和漏洞發現能力上都有提高,并在常用軟件中發現了新的漏洞。但efuzz 依然存在很多改進空間,比如在tcpdump 上的效果并不明顯,在tcpdump-2、base64、uniq 上的實驗結果還要略差于AFL。同時在不知道被測程序結構的情況下進行fuzzing 依然存在盲目性,如何結合程序分析來獲取更多被測程序信息,以及結合其他方法進一步提高邊覆蓋率,還需要在接下來的工作中進行更深入的研究。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
