依托百度搜索引擎的輿情信息搜索系統研究?
2019-11-29 05:14:06唐國維李井輝
計算機與數字工程 2019年11期
唐國維 趙 璨 李井輝 張 巖
(東北石油大學 大慶 163318)
1 引言
近10 年來中國互聯網取得了長足的發展,截至2016年底中國互聯網用戶人數已超過7.10億[1]。互聯網的方便、快捷的特點使得互聯網網站數量得到了快速增長,所包含的信息也越來越豐富,因此通過互聯網獲得信息來源已經成為人們最主要的一個方式。雖然互聯網給大家的生活帶來了很多好處,但是由于互聯網中的網站眾多,同時在互聯網上發布信息幾乎不受限制,也導致近年在互聯網中,出現的不利于國家發展、社會穩定的信息越來越多,事實真相被扭曲,其嚴重影響了社會的穩定發展。因此如何在互聯網中及時的發現和篩選出不良信息,避免負面事件的出現和擴大,已成為一項亟待解決的重要工作。
目前人們都很重視網絡輿情監控工作,網絡輿情系統通常包括數據采集、網頁信息抽取、數據統計分析、輿情數據處理和系統管理等,網頁信息抽取是網絡輿情系統中極其關鍵的部分[2]。但是目前網絡輿情監控工作存在很多的問題和困難。例如:開展輿情監控采取人工搜索方式,其手段簡單,目的性不強且所需人員較多,而信息相關的網站數量較多,信息量也非常大。面對海量復雜的信息,采用人工搜索方式,效率較低而且容易錯過消除或避免輿情信息擴散的最佳時機,容易造成不良影響[3]。
本文主要研究的是爬蟲、搜索引擎、文本信息挖掘等技術,以百度網站和某貼吧為例,應開展網絡輿情監控工作的應用需求而提出的一個完整的解決方案,可以大幅提高百度網站、百度貼吧輿情信息搜索的速度和獲取信息的準確度,有效縮短信息搜索時間,提高監控效率。
2 主要研究內容
本文主要針對目前輿情信息搜索采用人工方式效率低、易出現信息遺漏等問題而提出的一個可行解決方案,主要研究內容是依托百度搜索引擎,根據預設的關鍵字,向百度數據服務器發送請求并接收回傳的數據,同時抽取包含目標信息的文檔和鏈接地址;利用信息轉存技術,將服務器返回的數據轉存到本地[4];利用信息去冗技術,根據設置的冗余信息對比度來剔除冗余信息[5];根據分詞技術和相似篩選技術,把轉存后的數據按照相似度分類存儲,并實現本地數據的查詢和檢索[6];根據輿情級別制定相應的預警機制,將分級的輿情信息生成輿情報告并整合到電子郵件中,自動傳送給用戶,實現無人監管時輿情信息自動收發;根據輿情信息重要與否,利用信息推送技術,將輿情信息整合成輿情報告發送給指定人員,實現輿情信息郵件推送。
根據需求,依托百度搜索引擎對輿情信息爬行。為了實現獲取百度搜索引擎的服務器數據,經過研究和探討設計了多個思路,并在實踐中驗證這些思路的可靠性和穩定性。
主要從三個思路進行了驗證,分別為:1)Socket 通信方法,通過模擬客戶端和服務器之間的交互;2)獲取百度網站的XML文檔方法,只要對XML文檔進行分析處理即可以獲得需求信息;3)采用HTML 分析方法直接對百度網站的源碼字符串進行分析。最終經過比較研究確定了第三種方案,雖然不同網站的源碼標記具有特殊性,且不同網頁源碼分析技術存在未知難點,但是這種方案對于網頁目標信息的提取效果很明顯,其研究重點是分析不同網站的HTML 源碼標記結構,看能否找出網頁源碼標記的通用結構,同時按照此研究方案進行充實和完善。
3 系統總體設計
3.1 系統總體結構
結合系統的功能分析以及未來輿情發展的綜合考慮,實現系統與百度網站搜索引擎的鏈接,完成信息搜索。利用信息轉存、信息去冗以及相似篩選技術實現對在互聯網上發布的信息的抓取、轉存、去冗以及自動分類功能,針對輿情信息還具有自動生成輿情報告和輿情信息預警功能,同時利用電子郵件的形式向用戶提供信息呈報服務。同時,在系統管理中實現功能控制,包括關鍵詞的設置以及登錄用戶的增刪編輯等。
本系統應用B/S 網頁瀏覽模式,主要分為五個模塊:信息搜索模塊、定制信息模塊、信息推送模塊、信息匯總模塊和系統管理模塊[7]。五個模塊呈遞進關系,功能上相輔相成,實現本系統所需的所有需求,系統總體結構圖如圖1。
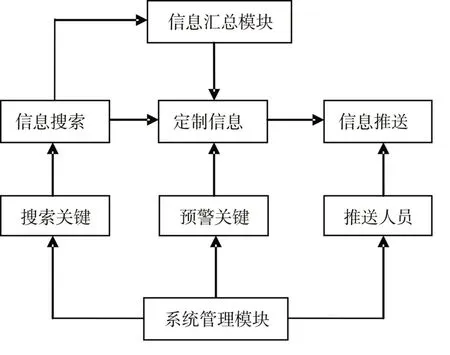
圖1 系統總體結構框圖
3.2 系統物理結構
3.3 系統數據結構
因考慮系統數據處理量較大,因此數據結構很復雜,不同類別網站的搜索信息需要存放在不同的數據表中,不同數據表數據格式和數據字段也不同,需要對數據進行大量操作,如轉存、分類、去冗等,本系統數據結構框圖如圖3。
4 系統功能
本系統包括五個功能模塊:信息搜索模塊、定制信息模塊、信息推送模塊、信息匯總模塊和系統管理模塊[8]。
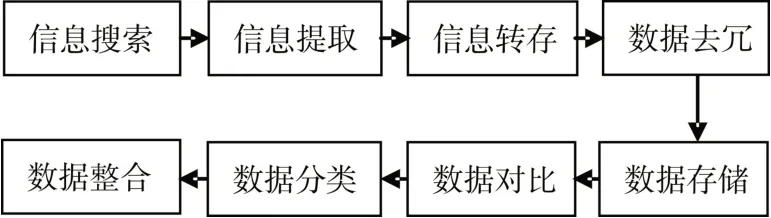
圖3 系統數據結構框圖
4.1 信息搜索模塊
系統的信息搜索模塊界面包括兩部分:關鍵詞選擇部分和信息顯示部分。關鍵詞選擇部分包括部分勾選和全選兩種方式,當選擇完關鍵詞以后在信息顯示部分就會把數據庫中的信息顯示出來,顯示的內容分為百度網站、貼吧兩個選項卡,當點擊相應的選項卡就會呈現出相應的內容。
百度網站、貼吧顯示出來的內容包括標題和日期,而標題是可以通過點擊進入到所對應網站和貼吧。網站和貼吧都擁有生成輿情報告的功能,當點擊生成輿情報告的時候,會把此條信息的詳細內容顯示出來。
對于百度網站、貼吧都有輿情信息checkbox復選框,當認為是輿情信息的時候,可以勾選將這條信息選中,選中的信息就會在后面的信息匯總模塊中展現出來。對于貼吧有重點信息checkbox 復選框,當認為此條帖子需要重點關注的時候,可以勾選這條信息,選中信息的標題就會展現在后面的定制信息模塊中重點輿情信息定制中。
4.2 定制信息模塊
定制信息模塊包括自主百度網站信息、自主貼吧信息、重點輿情信息定制、重點輿情信息四個部分,定制信息模塊界面圖默認的是自主百度網站信息界面圖。在系統管理中,點擊自主百度網站爬行鏈接,啟動自主爬行程序,在這個程序中設定相關信息后進行輿情信息爬行,并將爬行的信息顯示在自主百度網站信息欄中;點擊自主貼吧爬行鏈接,啟動自主爬行程序,在這個程序中設定相關信息后進行輿情信息爬行,并將爬行的信息顯示在自主貼吧信息欄中;點擊重點輿情信息定制按鈕,顯示的是重點輿情信息定制界面,主要功能是設定重點輿情信息的爬行條件。當在系統管理模塊中點擊打開重點爬行程序根據條件爬行,并將爬行的結果顯示在重點輿情信息欄中。自主百度網站信息、自主貼吧信息、重點輿情信息顯示的內容和信息搜索模塊中顯示的數據內容一樣,同樣包括標題和日期,以及生成輿情報告。
重點輿情信息定制包括關鍵詞和帖子名兩部分,當勾選出需要重點關注的帖子和關鍵詞,提交以后,就可以在系統管理中的通過點擊進行重點貼吧爬行。
仁宗即位以后,總計81人次出任首輔。其中有重復出任首輔的,最多的是四任首輔的李時和夏言。計有首輔61人,平均任期為3年7個月。超過10年的有:楊士奇19年6個月,嚴嵩15年8個月,萬安10年4個月,張居正10年。首輔任期較短的原因有二:皇帝頻繁地變動閣臣和首輔,例如崇禎年間;原首輔去職后新首輔尚未到職,次輔臨時接任首輔。
4.3 信息推送模塊
信息推送模塊包括手動郵件發送、自動郵件發送和推送記錄三項。手動郵件發送可以通過先勾選出收件人,然后依次填寫主題和添加附件,點擊發送即可實現輿情報告的推送。自動郵件發送先勾選出收件人,然后選擇自動發送郵件的開始日期、終止日期和時間,點擊確定,當到達預設時間后系統將自動發送郵件到收件人郵箱[9]。推送記錄顯示的是發送郵件的記錄,主要記錄了發件人、發件日期時間和是否發送成功。
4.4 信息匯總模塊
信息匯總模塊包括全部匯總、日期匯總、年度匯總三項。信息匯總模塊界面默認的是全部匯總里的百度網站界面,全部匯總分百度網站、貼吧兩個選項卡。信息匯總模塊中顯示的信息是通過信息搜索模塊中百度網站、貼吧中的輿情信息checkbox復選框勾選以后顯示的內容。
4.5 系統管理模塊
系統管理模塊包括用戶管理、關鍵詞管理、收件人管理、重點信息管理和爬行鏈接管理五部分。用戶管理是對于登錄用戶的信息進行編輯、刪除和添加[10]。關鍵詞管理是對于需要爬行的關鍵詞的編輯、刪除和添加[11]。收件人管理則是對于郵件推送模塊中的手動發送郵件和自動發送郵件的收件人進行編輯、刪除和添加。重點信息管理是對于定制信息模塊中重點輿情信息定制中的關鍵詞和貼子名進行編輯、刪除和添加。爬行鏈接管理是將常規爬行和定制信息模塊中的三個自主爬行和一個重點爬行對應的鏈接顯示其中。
5 關鍵技術
5.1 百度網站源代碼解析技術
網站的網頁頭標記就屬于無關信息的標記,可以直接忽略。而網頁體內容就是本網頁內容的標記集合,例如廣告信息、音頻信息和圖片信息和輿情信息等,由于標記中的信息量很大,標記結構復雜,尤其是嵌套的標記結構,因此分析起來很難。必須區分出圖片標記、音頻標記和輿情信息標記以及一些樣式表的信息。
為了把輿情信息提取出來,因此在分析HTML源代碼的時候需要剔除廣告信息、圖片信息、音頻信息等。通過標記類別忽略或者去除無關信息,留下所需要的目標信息所在的標記。
通過分析,我們發現所有搜索的信息都包含在<table></table>標記中,其中這個標記含有子標記<tr></tr><td></td>,其中子標記<tr></tr>表示表行,標記<td></td>表示表列。因此只要解析這個table標記,從這個標記中提取目標信息即可。
由于我們需要獲取目標信息的標題、摘要、網頁的真實鏈接和發布日期,因此需要針對這些個信息點在<table></table>標記進行查找。通過分析網頁源代碼,可以找到目標信息的標題、摘要、日期和真實網址所在的標記。
5.2 貼吧源代碼標記解析技術
通過對百度某貼吧的源代碼進行分析,發現貼吧與百度搜索引擎網站的源代碼結構是有很大的不同,大慶吧的每條信息都是以<div class=“s_post”>開始,以</div>結束。這個<div></div>標記中有5 個子標記,分別為1 個<span></span>標記,1 個<div></div>標記,2 個<a></a>標記和一個<font></font>標記[12]。而在<span></span>標記中有一個子標記<a></a>,該子標記<a></a>的屬性href對應的正是真實網址,同時標記<a></a>的子標記包含的也是所需要的標題,第二個<div></div>標記包含的是摘要,而<font></font>標記所包含的也是需要的最后一項——發布時間。
5.3 數據轉存技術
通過輿情信息爬行端獲取百度網站數據、貼吧數據,并從其數據庫轉存到本地數據庫。轉存技術主要是對數據庫進行數據插入操作,在本地數據庫中創建數據表,并根據獲取的信息建立數據表字段,這些數據庫操作完成后,就可以將數據轉存到本地數據庫了,通過編寫SQL語句將數據逐條插入到數據庫中。
5.4 數據去冗技術
本地數據庫數據量將會非常龐大,數據去冗將能節省一定的數據空間,減少數據服務器負載部分壓力,數據去冗主要是針對同一數據表內的數據和不同數據表之間的數據的去除重復冗余數據。同一數據表內的數據去冗可以通過對數據表內已有數據循環遍歷,如果有一個或多個字段數據重復,那就定義為冗余數據,需要去除。不同表之間的數據去冗工作量很大,且比較麻煩,為了減少數據大量對比操作,采用把不同表內的數據轉存到一個新的數據表。當一條新數據轉存到這個表內時循環遍歷一編,對比已存在的數據,如果數據不同就執行插入操作,相同則放棄此條數據執行下一條數據的插入對比操作,這樣最后這個表就是我們需要的數據匯總表。
5.5 郵件自動推送技術
電子郵件的推送也是一個重要的問題,不僅功能上有要求而且要求具有準確性和實時性,因此為了實現電子郵件推送,編寫郵件推送類庫,將電郵推送的代碼集成封裝到一個類庫,通過類庫生成DLL 文件,在系統平臺中只要調用這個類庫的DLL文件,后臺C#代碼中的變量經過實例化,就能繼承這個類庫中的所有函數、屬性和方法。
由起初的發送郵件C#代碼到將其封裝成類庫直接調用DLL 文件,是一個代碼設計架構的進步,不僅減少了后臺C#代碼的復雜,而且減少了網站運行的負載,同時整個網站的解決方案結構更具條理化,從復雜代碼轉變為封裝類庫這本身就是一種優化程序結構的編程思想,當大部分的代碼都轉變為類庫時,那這個程序的集成性好、可移植性高、運行負載低,這不僅是編程代碼的技術收獲,更是編程思維和程序設計的進步。
5.6 百度網站鏈接獲取和網址url傳值技術
百度網站鏈接技術是為了實現百度網站鏈接的獲取,真實網址的獲取是一個重點問題,起初獲取到的是偽真實網址,就是百度網站頁面顯示帶有省略號的假網址,這個網址不能真正定位到目標信息的網頁。為了獲取真實網址,采用網址信息加載前觸發事件函數提取網頁的真實網址,通過編程序將網頁的鏈接地址賦值給一個虛擬瀏覽器,然后在該網頁家在信息前觸發一個虛擬瀏覽器的事件函數,瞬間把這個網頁的真實網址提取出來,從而實現了真實網址的提取。
通過這種間接的方式獲取真實網址,雖然路線曲折但達到了獲取真實網址的需求,在這過程中,不僅對網頁源代碼的標記有了更深入的理解,同時對于HTML 源代碼解析技術的運用也更熟練,最重要的是這種實現功能的思想,既然不能直接獲取真實網址,那就轉變編程思維通過間接方式獲取所需要的信息。
網址url 傳值是通過keyword 鏈接到百度網站對應的關鍵詞的網頁,獲取需要的關鍵詞信息。
5.7 數據轉存excel表技術
在信息搜索模塊中常規爬行出來的百度網站、百度貼吧中生成輿情報告以后,為了能夠實現發送郵件功能,有導出excel表操作,同時在定制信息模塊中的自主百度網站、自主貼吧和重點貼吧中生成的輿情報告也同樣需要導出excel 表操作,最后的全部匯總模塊中所有的Gridview 也需要導出excel表操作,如此多的地方都涉及到excel表導出技術,在項目中導出excel表技術就顯得非常重要。
6 結語
輿情信息搜索系統的出現是時代發展的根本產物,完善輿情監測和搜索系統,做好輿情監測和引導工作,是解決網絡信息問題的基本方法。而本系統通過百度網站鏈接技術,實現百度網站鏈接的獲取;通過網址url傳值技術,實現通過關鍵詞搜索出相應的信息[13];通過運用HTMLParser 類庫的方法和函數,分析HTML 代碼中標記結構,截取目標信息所在的標記,實現獲取所需要的目標信息;通過數據轉存技術,將獲取的目標信息轉存至本地數據庫[14];通過數據去冗技術,剔除冗余和重復的數據[15];通過分詞技術和相似篩選技術,將數據庫中的數據按照相似度分類存儲,方便數據的查詢和更新;通過郵件發送技術,實現本地與郵箱服務器之間的數據流交互,從而完成電子郵件的發送;從而改變了目前輿情信息搜索花費大量時間以及人工搜索輿情信息易遺漏效率低的現狀,提高輿情監控效率和搜索速率。
本系統中的技術可以應用于其他網站進行輿情信息的搜索,如搜狗搜索引擎、谷歌搜索引擎、必應搜索引擎、愛問搜索引擎、騰訊新聞、新浪博客等,其具有很高的應用和推廣價值。本系統的推廣開發實現了對輿情信息進行數字化管理和信息化操作,從而擴大了輿情信息的搜索范圍,提高了輿情信息搜索的精確度,在一定程度上為網絡中輿情信息的管理和監控提供了技術支持,能夠有效地解決目前網絡輿情存在的問題。
猜你喜歡
Defence Technology(2020年4期)2020-07-02 03:16:58
青年與社會(2018年2期)2018-01-25 15:37:06
中華手工(2017年2期)2017-06-06 23:00:31
學周刊(2016年26期)2016-09-08 09:02:52
IT時代周刊(2015年8期)2015-11-11 05:50:22
中國醫學人文(2015年6期)2015-06-08 06:00:48
中外會展(2014年4期)2014-11-27 07:46:46
太空探索(2014年4期)2014-07-19 10:08:58
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
