荊門市竹皮河流域地表水污染預報研究
2019-11-22 14:39:17張云簧熊玨
綠色科技 2019年16期
張云簧 熊玨


摘要:指出了隨著經濟社會的高速發展,水資源安全問題日益凸顯。竹皮河及其支流作為荊門城區的納污河流,承接荊門中心城區90%以上工業廢水和生活污水,竹皮河及其支流的地表水情況關乎荊門市的經濟發展與社會民生。以竹皮河流域為研究對象,通過機器學習的方法對地表水水污染等級進行預報,對竹皮河肖家崗水質自動監測站的周度數據進行了分析,運用最小二乘支持向量機對8周的數據進行了測試。分析結果可知:只有第六個污染等級預報錯誤,其他的七個污染等級均預報正確。這可充分的說明,五個指標與水污染等級之間存在一種強烈的對應關系,也說明所使用的LS-SVM算法的正確性和有效性。同時為了對比說明,運用RBF神經網絡進行了預測。訓練數據和測試數據與LS-SVM預測法一致。對比預測結果發現:RBF神經網絡的預測結果與LS-SVM預測結果相比,存在預測精度不高的問題。同時,LS-SVM算法具有簡便的操作性。通過對竹皮河水質自動監測站評價和預報,可為將來的優化空間布局、調整產業結構和劃定重點生態保護區等措施提供理論支撐。
關鍵詞:竹皮河;水污染;最小二乘支持向量機
中圖分類號:X703文獻標識碼:A 文章編號:1674-9944(2019)16-0100-05
1研究意義
研究選定竹皮河為研究對象,評價各個監測站的優劣,并對水污染的等級進行實時預報,推進解決水污染共同治理機制建設。通過實時預報地表水水污染等級,為處理突發環保事件做好預警,并提供相應的應對措施,推動健全相關水域協調機制的運行。通過對湖北荊門市境內的各個監測站進行評價和預報,為未來的優化空間布局、調整產業結構和劃定重點生態保護區等措施提供行政支撐和保障。
2研究內容
通過機器學習的手段,對竹皮河肖家崗水質自動監測站的數據進行了深度挖掘。本文欲求得挖掘溶解氧、化學需氧量、氨氮、水溫和pH值五個指標與水污染等級之間的對應關系,通過最小二乘支持向量機(LSS-VM)對訓練數據進行訓練得到了指標與污染等級之間的關系模型,將測試數據導人該模型中,即可得到測試數據的污染等級。為了說明最小二乘支持向量機算法的有效性,利用神經網絡算法對數據進行了同樣的處理,并將結果進行了對比。
3基于LS-SVM的地表水污染等級預報機制
3.1數據分析與算法流程
3.1.1數據分析
通過荊門市環保局監測站獲得了竹皮河肖家崗水質自動監測站的2017年1月12日到2017年8月20日的31周的周度數據。數據內容包括:pH值、溶解氧(mg/L)、化學需氧量(mg/L)、氨氮(mg/L)、水溫(℃)和水污染等級。數值大小為一周之內的平均值。圖1為周數與各個指標的關系圖。
由圖1可知:水污染等級決定于pH值、溶解氧(mg/L)、化學需氧量(mg/L)、氨氮(mg/L)和水溫(℃)5個指標。本文通過機器學習中的最小二乘支持向量機來挖掘5個指標和水污染等級的關系。
3.1.2算法流程算法流程見圖2。
3.2主成分分析法
對各個監測站的數據進行提取后,可知樣本的特征變量間存在著某些程度的相關性,即變量間所對應的特征信息存在著一定程度的互相涵蓋。主成分分析(Principal Component,Analysis,PCA),這一分析方法有著對所挑選出的樣本特征其提取出的因子進行二次篩選的能力,繼而建立數量較小的全新的變量(理論上當提取的特征能夠表現總體特征的85%時,即可認為降維成功),使所得到的新變量之間的相關性更小,各個新變量更能有效地反映其所代表的特征,相比于原變量,極大地降低了特征間的信息冗余,從而成功地提高了對于樣本特征的有效信息和噪聲的有效性,同時也提高了向量機回歸時的精度。
假設某變量的樣本數據xo,x1,…,xp,運用PCA后篩選出m個新變量E1,E2,…,Ex,m
假設X是具有n個樣本點和p個變量的一個樣本數據矩陣,即:
3.3支持向量機
支持向量機(Support Vector Machines)開始出現于20世紀90年代,Vapnik等用于解決數據分類問題,隸屬機器學習方法。SVM的作用在于可憑借著有限的樣本信息,平衡著模型的復雜度和學習能力兩個不可調和的矛盾,尋求獲得最佳推廣能力。當支持向量線性可分時,SVM可以根據使用的支持向量將數據分開;當支持向量線性不可分時,SVM可以使用核函數來將數據映射到高維空間,從而將數據分開。SVM不僅進行二分類和多分類,也可以用于回歸。回歸和分類在本質上是一樣的。在回歸問題上,可以簡單的理解為將分類類別替換為回歸數值。圖3為支持向量機兩種分類情況。
求解式(6)可得最優分類超平面,其中支持矢量滿足距最優超平面最近的點λi>O,其余點滿足λi=O,即支持矢量可反映最多的分類信息,其數量同時可反映出超平面所依賴的獨立界面。決策函數表示如下:
3.4最小二乘支持向量機
在1999年Suykens和Vandewalle提出最小二乘支持向量機(LS-SVM),LS-SVM對于目標函數的表示,用誤差的平方來表示目標函數,用等式條件來表示其約束條件,則面臨的情況即為符合KKT(Karush-Kuhn-Tucker)時,算出一組N維線性方程組的解,最終得到所需的決策函數。綜上可知,相比SVM在解決大規模問題方面的表現,LS-SVM簡化了整個計算過程的復雜程度,同時提升了其訓練過程的工作效率。
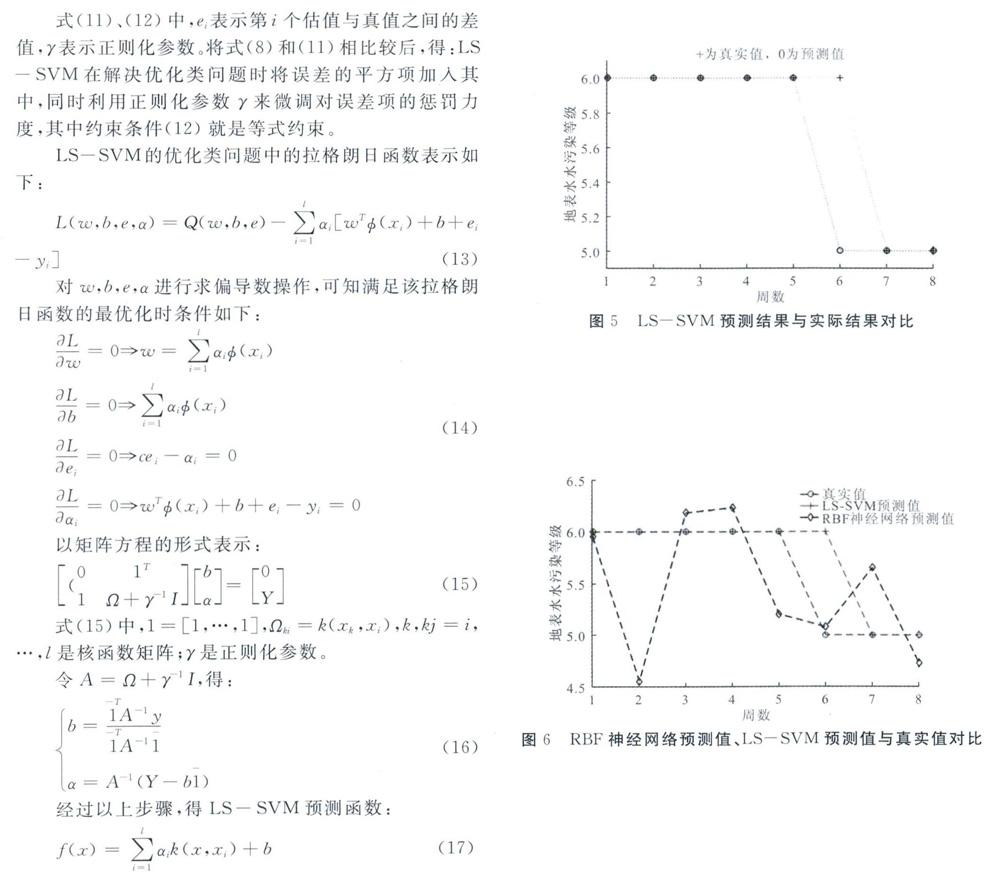
3.5預報結果分析及對比
經過主成分分析后,將數據分為23組訓練數據和8組預測數據。將23組訓練數據置入最小二乘支持向量機中,選擇RBF內核為核函數,并將參數gam設置為r1.038e+001 1.7435e+006]、sig2設置為[13.6777357]。經過訓練后,即可得到5個指標和水污染等級的對應關系模型。將8組測試數據置入得到的模型,即可得到預測的水污染等級大小,結果如圖5所示。
