基于Char-RNN 的詩歌自動生成方法
2019-11-18 07:26:20劉俊利
現代計算機 2019年28期
劉俊利
(西南科技大學計算機科學與技術學院,綿陽621000)
0 引言
21 世紀,隨著中國國力的日漸強大,越來越多的人開始認可、學習中國傳統文化。而詩歌作為中國傳統文化重要構成之一,在中華文化復興的今天,也正獲得越來越多的關注。近年來,隨著自然語言處理的持續火熱,在文本自動生成領域,自動生成中國古典詩歌的研究逐漸成為技術熱點。由于詩歌生成需要考慮時間先后順序的問題,而RNN 之所以稱為循環神經網絡,是因為它具有記憶之前信息并利用記憶影響當前的輸出的特點。所以顯然RNN 很適合用于解決這一類問題。不過基本RNN 只有一個隱藏狀態,在模型迭代優化的過程中,梯度隨著傳播深度的增加越來越小,最終沒有變化,容易造成梯度彌散,對長距離的記憶效果不好。因此在Char-RNN 網絡搭建過程中選擇采用RNN的變形結構LSTM 作為基本的模型,最終實現詩歌的自動生。
1 LSTM網絡
LSTM[3]是一種RNN[4]的變體結構,是RNN 的改進版。從外部結構看,兩者的輸入和輸出都是一樣的,從內部結構來看RNN 和LSTM 的結構分別如圖1、圖2所示。其中,圖 1 的內容與 RNN 的公式:ht=f(U xt+Wht-1+b )相對應,激活函數f 采用tanh 函數;圖2 結構較為復雜,LSTM 的隱狀態相較于RNN 添加了Ct,圖中Ct-1到Ct的水平線是LSTM 的主干道,Ct在主干道的無障礙傳遞解決了在較長序列中梯度失效的問題。此外,圖中ft、it、ot分別為遺忘門、記憶門、輸出門的輸出,兩個tanh 層則分別對應記憶單元的輸入與輸出,向量由第一個tanh 層生成用于更新記憶單元狀態,σ 是Sigmoid 激活函數。
1.1 遺忘門
每一條進入LSTM 網絡的信息Ct-1,都要經過一個遺忘門來過濾掉Ct-1的部分內容。如果遺忘門輸出ft接近0 則遺忘該部分內容,如果接近1 則保留該部分內容,具體公式見(1)。公式中,xt和ht-1是遺忘門的輸入。

1.2 記憶門
不僅僅只是遺忘,LSTM 過濾內容的同時還需要記住新的東西。記憶門的輸出包括it和,it的值決定了當前輸入xt有多少將保存到記憶單元狀態Ct中,具體如式(2);由tanh 層生成,用來更新記憶單元狀態,具體如式(3)。最后將遺忘門和記憶門的結果組合在一起,形成新的單元狀態Ct,如式(4)。
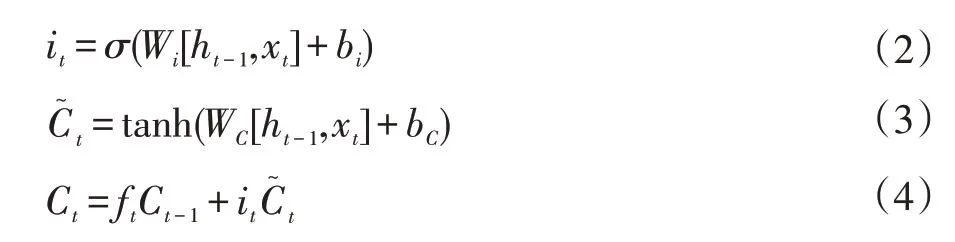

圖1 RNN結構

圖2 LSTM結構
1.3 輸出門
LSTM 的隱狀態包括Ct和ht。前面的遺忘門,記憶門完成了Ct的計算,輸出門需要完成ht的計算。它首先通過sigmoid 激活函數σ 得到一個數值在0~1 之間的初始輸出ot,如式(5),然后再用tanh 層把Ct值推到-1 和1 之間。最終通過ot*tanh(Ct)得到ht,如式(6),LSTM 最終的輸出由ht進一步變換得到。

2 Char-RNN原理
Char-RNN[5]是一種字符級循環神經網絡,其本質是序列數據的推測,即通過已知的字符,預測下一個字符出現的概率并選取概率最大者為下一個字符。它使用的是RNN 最經典的N vs N 模型,該模型具有輸入與輸出的序列長度相等的特點,其具體結構如圖3 所示。
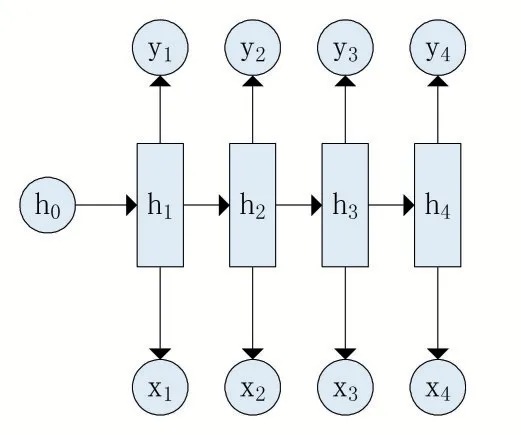
圖3 “N vs N”的經典RNN結構
在使用Char-RNN 測試生成序列時,其具體流程為:首先選擇一個x1作為起始字符,然后通過訓練好的模型得到下一個字符的概率,最后選取概率最大者為下一個字符并將該字符作為下一步的x2輸入模型。這只是一個單元,根據需要生成的文本長度選擇循環次數,可以生成任意長度的文字。
3 Python實現
3.1 網絡輸入
網絡的輸入包含兩部分:self.inputs 和self.lstm_inputs。其中,self.inputs 是外部傳入的一個batch 內的輸入數據;self.lstm_inputs,是embedding 的具體數值。此外,seIf.targets 是訓練目標,是self.inputs 每個字母對應的下一個字母。self.keep_prob 控制了Dropout 層所需要的概率。
def build_inputs(self):
with tf.name_scope('inputs'):
self.inputs=tf.placeholder(tf.int32,shape=(self.num_seqs,self.num_steps))
self.targets = tf.placeholder(tf.int32, shape=(self.num_seqs,self.num_steps))
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
#對于中文,需要使用embedding 層
#英文字母沒有必要用embedding 層
if self.use_embedding is False:
#對字字符進行onehot 編號
self.lstm_inputs=tf.one_hot(self.inputs,self.num_classes)
else:
with tf.device("/cpu:0"):
#嵌入維度層word2vec 和RNN 連接器;同時訓練作為模型的第一層
embedding = tf.get_variable('embedding', [self.num_classes,self.embedding_size])
self.lstm_inputs = tf.nn.embedding_lookup(embedding,self.inputs)
3.2 模型構建
首先,定義了一個多層的BasicLSTMCell 并對每個BasicLSTMCell 加入一層Dropout,減少過擬合。
lstm=tf.nn.rnn_cell.BasicLSTMCell(lstm_size)#state 并不是采用普通rnn 而是lstm。
drop = tf.nn.rnn_cell.DropoutWrapper (lstm, output_keep_prob=keep_prob)#對每個state 的節點數量進dropout
其次,定義了cell 后,使用tf.nn.dynamic_rnn 函數展開時間維度,其輸出為self.outputs 和self.final_state。
self.lstm_outputs,self.final_state=tf.nn.dynamic_rnn(cell,self.lstm_inputs,initial_state=self.initial_state)
然后,定義一層Softmax 層得到最后的分類概率。這里經過一次類似于Wx+b 的變換后得到self.logits,再做Softmax 處理,最終輸出self.proba_prediction。
#構建一個輸出層:softmax
with tf.variable_scope('softmax'):
#初始化輸出的權重,共享
softmax_w = tf.Variable(tf.truncated_normal([self.lstm_size,self.num_classes],stddev=0.1))
softmax_b=tf.Variable(tf.zeros(self.num_classes))
#定義輸出:softmax 歸一化
self.logits=tf.matmul(x,softmax_w)+softmax_b
self.proba_prediction=tf.nn.softmax(self.logits,name='predictions')
3.3 訓練模型與生成文字
訓練模型就是向構建好的模型里面不斷的加入數據,由于是生成五言詩歌,所以選取了大量的唐代五言詩作為數據樣本。然后將結果不斷保存。
def load(self,checkpoint)
self.session=tf.Session()
self.saver.restore(self.session,checkpoint)
print('Restored from:{}'.format(checkpoint))
完成模型訓練后,通過讀取保存好的模型即可實現網絡生成樣本:
def sample(self,n_samples,prime,vocab_size):
samples=[c for c in prime]
sess=self.session
new_state=sess.run(self.initial_state)
preds=np.ones((vocab_size,))#for prime=[]
for c in prime:
x=np.zeros((1,1))
x[0,0]=c#輸入單個字符
feed={self.inputs:x,self.keep_prob:1.,self.initial_state:new_state}
preds,new_state=sess.run([self.proba_prediction,self.final_state],feed_dict=feed)
c=pick_top_n(preds,vocab_size)
samples.append(c)#添加字符到samples
for i in range(n_samples):#不斷生成字符,直到達到指定數目
x=np.zeros((1,1))
x[0,0]=c
feed={self.inputs:x,
self.keep_prob:1.,
self.initial_state:new_state}
preds,new_state=sess.run([self.proba_prediction,self.final_state],feed_dict=feed)
c=pick_top_n(preds,vocab_size)
samples.append(c)
return np.array(samples)
4 運行結果
利用深度學習框架TensorFlow 搭建多層LSTM 網絡,進而完成Char-RNN 模型的創建,最終實現詩歌的自動生,運行效果如圖4 所示。運行效果非常直觀,利用Char-RNN 模型確實可以完成詩歌的自動生成且生成的詩歌具有一定程度的創作水平。

圖4 生成詩歌效果圖
5 結語
本文首先介紹了LSTM 網絡,之后給出了Char-RNN 模型的基本原理,然后利用TensorFlow[6]搭建多層LSTM 實現Char-RNN 模型,最后利用大量詩歌作為樣本訓練模型,完成了詩歌的自動生成且生成的詩歌具有一定的藝術水平。目前Char-RNN 由于其序列數據推測的特點在深度學習的“創作”領域應用廣泛并也取得了部分成果,不過該模型也存在部分缺陷:需要事先給定一部分數據,然后Char-RNN 才能順著往下預測。該缺陷容易導致生成文本隨機性大、主題模糊等問題。特別地,主題是詩歌的要素之一,所以Char-RNN 模型自動生成詩歌有待改進。Char-RNN 模型向我們展示了人工智能寫詩的可能性,雖然只是初級階段,但是未來,人工智能必將在文本創作領域取得令人滿意的成果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
