基于知識蒸餾的超分辨率卷積神經網絡壓縮方法
2019-11-15 04:49:03高欽泉趙巖李根童同
計算機應用 2019年10期
高欽泉 趙巖 李根 童同

摘 要:針對目前用于超分辨率圖像重建的深度學習網絡模型結構深且計算復雜度高,以及存儲網絡模型所需空間大,進而導致其無法在資源受限的設備上有效運行的問題,提出一種基于知識蒸餾的超分辨率卷積神經網絡的壓縮方法。該方法使用一個參數多、重建效果好的教師網絡和一個參數少、重建效果較差的學生網絡。首先訓練好教師網絡,然后使用知識蒸餾的方法將知識從教師網絡轉移到學生網絡,最后在不改變學生網絡的網絡結構及參數量的前提下提升學生網絡的重建效果。實驗使用峰值信噪比(PSNR)評估重建質量的結果,使用知識蒸餾方法的學生網絡與不使用知識蒸餾方法的學生網絡相比,在放大倍數為3時,在4個公開測試集上的PSNR提升量分別為0.53dB、
中圖分類號:TP391
文獻標志碼:A
Abstract: Aiming at the deep structure and high computational complexity of current network models based on deep learning for super-resolution image reconstruction, as well as the problem that the networks can not operate effectively on resource-constrained devices caused by the high storage space requirement for the network models, a super-resolution convolutional neural network compression method based on knowledge distillation was proposed. This method utilizes a teacher network with large parameters and good reconstruction effect as well as a student network with few parameters and poor reconstruction effect. Firstly the teacher network was trained; then knowledge distillation method was used to transfer knowledge from teacher network to student network; finally the reconstruction effect of the student network was improved without changing the network structure and the parameters of the student network. The Peak Signal-to-Noise Ratio (PSNR) was used to evaluate the quality of reconstruction in the experiments. Compared to the student network without knowledge distillation method, the student network using the knowledge distillation method has the PSNR increased by 0.53dB, 0.37dB, 0.24dB and 0.45dB respectively on four public test sets when the magnification times is 3. Without changing the structure of student network, the proposed method significantly improves the super-resolution reconstruction effect of the student network.
Key words:? super-resolution; knowledge distillation; convolutional neural network compression; teacher network; student network
0 引言
超分辨率(Super Resolution, SR)是計算機視覺中的經典問題,在監控設備、衛星圖像、醫學成像和其他許多領域都具有重要的應用價值。單張圖像超分辨率(Single-Image SR, SISR)的目的是從單個低分辨率(Low Resolution, LR)圖像中恢復出與其對應的高分辨率(High Resolution, HR)圖像。SR是一種病態問題,可以從給定的低分辨率圖像獲得多個高分辨率圖像。在例如雙線性(bilinear)插值、雙三次(bicubic)插值等傳統插值方法中,使用固定的公式來對輸入的低分辨率圖像內的鄰域像素的信息執行加權平均,來計算放大的高分辨率圖像中所丟失的信息。然而,這種插值方法不能產生足夠的高頻細節來產生清晰的高分辨率圖像。
近年來,由于GPU和深度學習(Deep Learning)技術的快速發展,卷積神經網絡(Convolutional Neural Network, CNN)被廣泛用于解決超分辨率問題,并且在超分辨率圖像的重建中得到了顯著的效果。Dong等[1]提出的超分辨率卷積神經網絡(Super-Resolution CNN, SRCNN)算法首次將卷積神經網絡應用在超分辨率問題中,它直接學習輸入低分辨率圖像與其對應的高分辨率圖像之間的端到端映射。SRCNN的結構非常簡單,僅使用了三個卷積層。它的成功說明使用卷積神經網絡來解決超分辨率問題是一種有效的方法,并且可以重建高分辨率圖像的大量高頻細節。Kim等[2]受VGG-net[3]的啟發提出了非常深的超分辨率卷積神經網絡(image SR using Very Deep convolution network, VDSR)。VDSR的網絡由20個卷積層組成。VDSR中使用了大量卷積層,它的應用效果也表明在超分辨率中“網絡越深,效果越好”。
Lim等[4]提出超分辨率的增強型深度殘差網絡(Enhanced Deep residual networks for SR, EDSR)是基于SRResNet[5]的結構,并去除了其中不必要的模塊來優化它,以簡化網絡結構。該文指出,原始的ResNet[6]最初提出是為解決圖像分類和檢測等更高級的計算機視覺問題,直接把ResNet的體系結構應用到像超分辨率重建這樣的低級計算機視覺問題時,并不能達到最理想的結果。由于批量標準化(Batch Normalization, BN)層消耗了與它前面的卷積層相同大小的內存,在去掉這一步操作后,相同的計算資源下,EDSR就可以堆疊更多的網絡層或者使每層提取更多的特征,從而得到更好的重建效果。
此外,RDN(Residual Dense Network)[7]和RIR(Residual In Residual)[8]分別提出了更深的SR網絡,進一步提高了SR重建效果。
先前的研究表明,通過增加卷積神經網絡的深度可以顯著改善超分辨率重建效果;但是,其計算時間和內存消耗也同時增加。在低功率的嵌入式終端設備的實際應用場景中,計算資源和存儲資源是部署深度CNN模型的約束條件。在實際應用中部署這些先進的SR模型仍然是一個巨大的挑戰。這促進了對神經網絡的加速和壓縮[9]的研究。
Hinton等[10]提出的知識蒸餾(Knowledge Distillation, KD)技術,使用教師學生網絡的方法簡化深度網絡的訓練。
該框架將知識從深層網絡(稱為教師網絡)轉移到較小的網絡(稱為學生網絡)中,訓練學生網絡使學生網絡能夠學習教師網絡的輸出。Remero等[11]用強大的教師網絡訓練一個窄而深的學生網絡,以便改善網絡訓練的過程。在文獻[11]中,不僅使用教師網絡的分類概率作為學習目標,而且也使用教師網絡的中間特征圖作為訓練期間的學習目標。
本文提出使用一種新穎的策略,該策略使用教師學生網絡來改善圖像超分辨率效果。其中的學生網絡使用基于MobileNet[12]的結構,在不改變學生網絡的模型結構、不增加計算時間的約束條件下,使用知識蒸餾來提高超分辨率學生網絡(Student Net for SR, SNSR)模型的重建效果。把超分辨率教師網絡(Teacher Net for SR, TNSR)的中間特征圖的統計特征值作為知識傳遞到超分辨率學生網絡。與未使用知識蒸餾的學生網絡相比,網絡的重建效果得到了提升,使得低功率的嵌入式終端設備能夠有效地運行圖像超分辨率模型。綜上所述,本文的主要工作如下:
1)將知識蒸餾方法用在超分辨率問題中。利用知識蒸餾將知識從超分辨率教師網絡轉移到超分辨率學生網絡,在不改變其網絡結構的前提下,大幅提高了學生網絡的超分辨率重建性能。
2)為了確定從教師網絡到學生網絡的有效知識傳遞方法,本文評估并比較了多種不同的特征圖統計值提取方法,并選擇最佳方式將教師網絡的知識傳遞到學生網絡。
3)將MobileNet用于超分辨率學生網絡。與超分辨率教師網絡相比,超分辨率學生模型需要較少的計算資源,并且可以在低功耗嵌入式設備上有效運行,因此提供了一種在計算受限的設備上實時部署超分辨率重建模型的有效方式。
1 本文方法
1.1 教師網絡的結構本文的教師網絡的結構如圖1所示,教師網絡的結構由三個部分組成:
1)特征提取和表示,由一個卷積層和一個非線性激活層組成。第一部分的操作F1(X)可表示為:
其中:W1和B1分別表示第一個卷積層中的權重和偏差,卷積核大小為k1×k1;“*”表示卷積操作;X是輸入的低分辨率圖像圖像。
2)非線性映射,由10個殘差塊組成[6]。每個殘差塊中有兩個卷積層,如圖1所示。
每個卷積層后面都有一個非線性激活層ReLU。跳躍連接用于連接每個殘差塊的輸入和輸出特征。通過這種方式,僅學習每個殘差塊的輸入和信息,它可以解決訓練非常深的網絡中的梯度消失問題[6]。
3)使用反卷積層重建HR輸出圖像。在先前的研究中,如SRCNN[1]和VDSR[2],使用雙三次插值將低分辨率圖像重建成超分辨率圖像,然后將其作為卷積神經網絡的輸入。由于所有卷積運算都是在高分辨率空間中執行的,因此計算復雜度非常高。另外,插值預處理步驟會影響超分辨率重建效果。針對這一問題,FSRCNN(Fast Super-Resolution Convolutional Neural Network)[13]中采用反卷積層來代替插值操作,學習低分辨率圖像和高分辨率圖像之間的放大映射。
最近的研究成果例如LapSRN[14]和SRDenseNet[15]也采用了反卷積層來重建超分辨率圖像。反卷積層可以被認為是卷積層的逆操作,并且通常堆疊在超分辨率網絡的末端[13]。使用反卷積層進行放大有兩個優點:第一,它可以加速超分辨率的重建過程,由于在網絡的末端進行放大操作,所以僅在低分辨率空間中進行所有卷積操作。
如果放大倍數是r,則它將大致降低至計算成本的1/r2。
第二,因為通過在超分辨率網絡的末端添加反卷積層來接收大的感受野,模型能夠根據低分辨率圖像的上下文信息推斷更多高頻細節。
1.2 學生網絡的結構
學生網絡的結構如圖2所示。
學生網絡包括三個部分:
第一部分是特征提取層,該部分與教師網絡相同。MobileNet采用深度可分離卷積(Depthwise Separable Convolution)塊在取得較好結果的情況下,能大幅降低模型的參數規模。受此啟發,學生網絡的第二部分的非線性映射使用了三個深度可分離卷積塊。每個模塊由深度卷積(Depthwise Convolution)層和逐點卷積層組成,逐點卷積是卷積核大小為1×1的卷積。深度卷積層將單個濾波器應用于每個輸入通道,而逐點卷積應用1×1的卷積來組合深度卷積的輸出。與MobileNet不同,本文沒有使用批量標準化層,因為它會消耗大量的內存[4]。深度可分離卷積和逐點卷積之后都是非線性激活層,深度卷積可以表述為:
如果使用卷積核大小為3×3的濾波器,則深度可分離卷積塊的計算量為標準卷積塊的1/9到1/8這可以顯著節省大量的計算資源,但會降低少許精度[12]。學生網絡的第三部分是用于重建的反卷積層,這部分也與教師網絡相同。
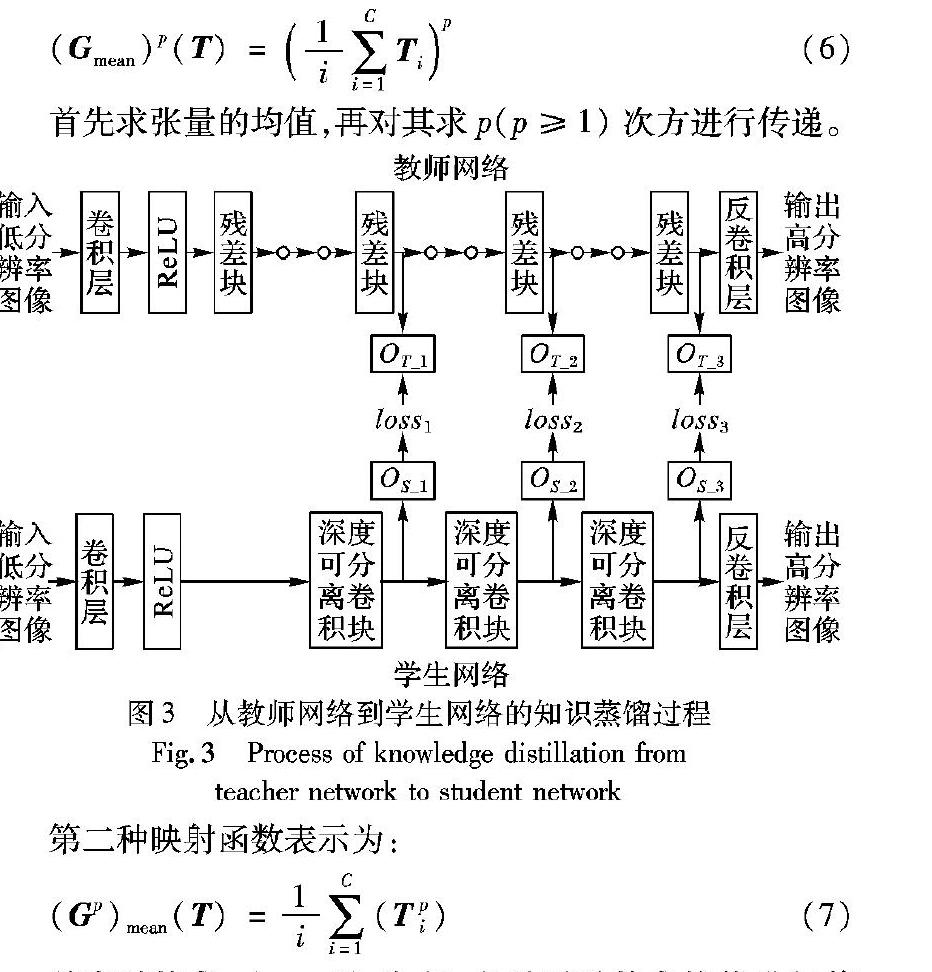
1.3 知識蒸餾與傳遞為了將有用的知識從教師網絡傳遞到學生網絡,分別從教師網絡和學生網絡提取統計圖。如圖3所示,使用教師網絡的第4、第7和第10個殘差塊的輸出計算統計特征圖,并分別表示為OT_1、OT_2和OT_3,用來描述低級、中級、高級視覺信息。在學生網絡中,本文使用第1、第2和第3個深度可分離卷積塊的輸出提取相應級別的統計特征圖,分別表示為OS_1、OS_2和OS_3。之后,使用教師網絡中OT_1、OT_2和OT_3的信息來指導訓練學生網絡中OS_1、OS_2和OS_3的信息。傳遞的統計特征是從網絡的中間輸出計算的,而不是直接使用網絡的輸出。在圖像分類問題中已經證明了傳遞網絡中間的特征圖會比傳遞網絡的輸出效果更好[16]。網絡的中間特征圖輸出可以表示為張量T∈RC×H×L,它由空間大小為H×L的C個特征通道組成。然后從張量T計算統計特征圖S:
其中:G是將張量T映射到統計特征圖S∈RH×W的函數。
本文用4種類型的映射函數來計算統計特征圖:
第一種映射函數表示為:
首先求張量的均值,再對其求p(p≥1)次方進行傳遞。
第二種映射函數表示為:
首先對其求p(p≥1)次方,之后再對其求均值進行傳遞。最后兩種映射函數分別將張量T特征圖的最大值以及最小值作為統計特征圖進行傳遞:
在訓練學生網絡期間,從學生網絡提取的統計特征圖S1、S2和S3學習從教師網絡提取的統計特征圖T1、T2和T3的內容。另外,重建超分辨率圖像同時學習訓練目標圖像的內容。因此,訓練學生網絡的總損失函數可以表示為:其中:λi是損失的權重系數;loss0為計算重建圖像Y′和訓練目標圖像Y之間的損失函數;loss1、loss2和loss3分別代表學生網絡和教師網絡不同級別統計特征圖之間的損失函數。本文使用Charbonnier函數[13]作為損失函數,并將其定義為:其中ε2設定為0.001。Charbonnier損失函數用于計算式(10)中的所有損失。
2 實驗設置
2.1 數據集和評價指標
本文使用公開的基準數據集進行訓練和測試,其中DIV2K數據集[17]和Flickr2K數據集作為訓練集。DIV2K數據集由800張圖像組成,Flickr2K數據集由2650張圖像組成。 在測試階段,Set5數據集[18]、Set14數據集[19]、BSDS100數據集[20]和Urban100數據集[21]用于SR基準測試。本文使用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和結構相似性(Structural SIMilarity index, SSIM)來評估超分辨率重建結果。峰值信噪比經常用作測量圖像退化等領域中圖像重建質量的方法,是目前使用最廣泛的客觀圖像質量評價標準,峰值信噪比的值越高表示超分辨率的重建效果越好。結構相似性對亮度、對比度和結構這三個因素進行整合來衡量兩張圖像之間的相似性,范圍在[0, 1],當結構相似性的值為1時,說明兩張圖像是一致的。由于超分辨率模型是在YCbCr空間中的亮度通道Y進行訓練的,因此本文僅在亮度通道Y上計算峰值信噪比和結構相似性。
2.2 參數設置
對于訓練數據集,首先用雙三次降采樣方法對其分別進行2倍、3倍、4倍的下采樣,得到其對應的低分辨率圖像,再把低分辨率圖像裁剪成尺寸為40×40的非重疊圖像塊作為網絡的輸入,把其對應的高分辨率圖像塊作為訓練目標。每個圖像塊都轉換到YCbCr空間,并提取其中的Y通道進行訓練。在教師網絡中,卷積核大小設置為3×3,每層卷積的通道數設置為64。在學生網絡中,深度卷積層的卷積核大小設置為3×3,并且輸出通道的數量設置為64。當放大倍數為2時,教師網絡和學生網絡末端的反卷積層的卷積核大小設置為4×4,步長設置為2,輸出通道設置為1;當放大倍數為3時,教師網絡和學生網絡末端的反卷積層的卷積核大小設置為3×3,步長設置為3,輸出通道設置為1;當放大倍數為4時,需要在網絡末端放置兩個反卷積層,每一個反卷積層對特征圖進行2倍放大,其中:第一個反卷積層的卷積核大小設置為4×4,步長設置為2,輸出通道設置為32;第二個反卷積層的卷積核大小設置為4×4,步長設置為2,輸出通道設置為1。在訓練期間,所有實驗都使用Adam[22]進行優化,并使用其默認參數β1=0.9, β2=0.999。學習率設定為固定值0.0001,批量大小(batch size)設置為32。每組實驗在NVIDIA Titan X GPU上使用Tensorflow進行500000次訓練迭代后進行測試。
3 實驗結果分析
首先將單獨訓練教師網絡和學生網絡,訓練教師網絡的作用是在接下來的實驗中對學生網絡進行指導,訓練學生網絡的目的是與經過教師網絡指導后的學生網絡進行對比。在利用教師網絡指導學生網絡的訓練過程中,利用測試集選取出教師網絡最好的迭代次數,將低分辨率圖像分別輸入教師網絡和學生網絡,但教師網絡的參數保持不變,經教師網絡指導的學生網絡不使用已經訓練好的學生網絡的參數,從第0次迭代次數開始訓練。本文實驗均采用峰值信噪比和結構相似性作為評價指標。
3.1 不同級別的特征圖的重要性
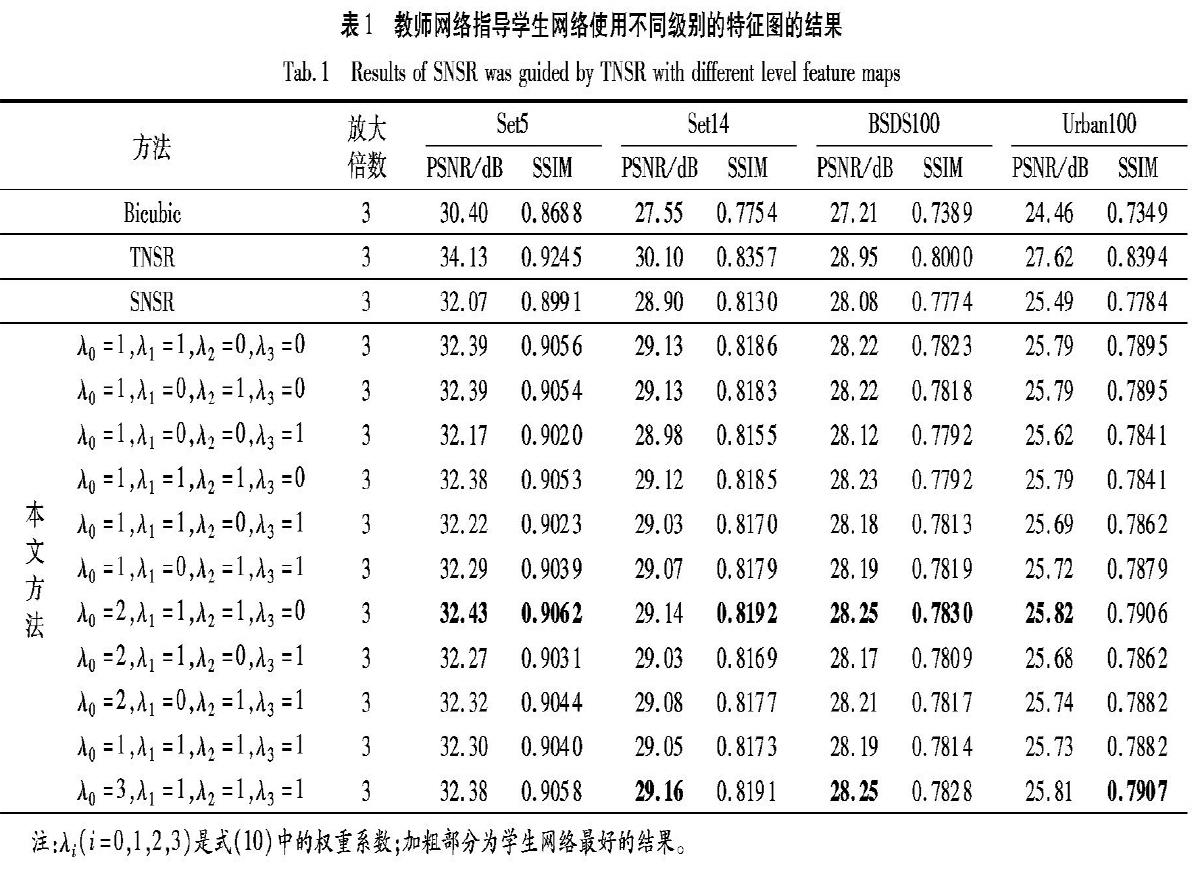
本文分析了不同級別的特征圖在知識蒸餾過程中的重要性,本節在低分辨率放大倍數為3的情況下進行對比實驗。在式(10)中設置不同的權重進行比較,其對比結果如表1所示。從表1可以看出,傳遞第一級別和第二級別的特征圖信息顯著改善了超分辨率重建效果。這表明高級特征(第三級別的特征圖)在低級計算機視覺任務(在本文的例子中是超分辨率)中用處較小。因此,本文的后續比較實驗中,僅使用第一級別和第二級別的特征圖作為知識蒸餾過程所傳遞的特征圖。
3.2 不同知識蒸餾方式的比較
本節對使用不同知識蒸餾方式的統計特征圖性能在低分辨率放大倍數為3的情況下進行對比實驗。使用式(6)計算4個統計特征圖,其中系數分別設置為1、2、3和4。這些統計特征圖在本文的工作中表示為Gmean、(Gmean)2、(Gmean)3和(Gmean)4。使用式(7)~(9)計算另外3個統計特征圖,并分別表示為(G2)mean、Gmax和Gmin。從教師網絡和學生網絡中提取相同蒸餾方法的統計圖進行傳遞。在訓練學生網絡期間,學生網絡的統計特征圖學習教師網絡的統計特征圖。圖4顯示了學生網絡使用了不同的知識蒸餾方式在峰值信噪比的表現。
學生網絡利用到了特征圖的所有信息,其重建效果要顯著優于僅使用了張量通道中的部分值Gmax和Gmin的方法。在訓練過程中,本文將訓練數據集歸一化為[0,1],在使用知識蒸餾訓練學生網絡的過程中,使用(Gmean)3和(Gmean)4作為統計特征圖進行傳遞時,對[0,1]內的值求3次方或者4次方時,其計算結果極小,使用這兩種方法的特征圖間的損失函數在計算總損失函數時無法提供很多有用的信息。同時,使用(Gmean)2作為統計特征圖進行傳遞獲得了最高的峰值信噪比。因此,本章的后續實驗最終選擇了(Gmean)2來計算統計特征圖。
3.3 知識蒸餾在超分辨率中的有效性
本文在表2對有教師網絡指導的學生網絡(表示為SNSR(Gmean)2)和沒有教師網絡指導的學生網絡(表示為SNSR)的超分辨率重建效果在不同放大倍數的情況下進行了比較,并且在表中給出了Urban100測試集在iPhone X運行所需要的時間,同時將本文的結果與移動設備中的非深度學習快速超分辨率(Rapid and Accurate Super Image Resolution, RAISR)算法[23]進行比較。
如表2所示,學生網絡的重建效果在所有測試數據集上都有了提升:峰值信噪比在放大倍數為2的情況下的提升范圍為0.24~0.52dB;在放大倍數為3的情況下的提升范圍為0.24~0.53dB;在放大倍數為4的情況下的提升范圍為0.10~0.25dB,并且它們的每秒浮點運算次數(Flops)和參數量(Params)也沒有改變。使用SNSR和SNSR(Gmean)2的結果的視覺比較如圖5所示,可以明顯地看出超分辨率重建效果的顯著提升。
本文將該高分辨率圖像先縮小到原來的1/3后得到低分辨率圖像;
圖(b)是將該低分辨率圖像經過雙三次插值放大3倍的圖像;圖(c)是將低分辨率圖像經過不使用知識蒸餾方法時的學生網絡所得到的結果;圖(d)是將低分辨率圖像經過使用知識蒸餾方法時的學生網絡所得到的結果。圖(b)為使用傳統的插值方法對低分辨圖像進行放大,該方法所生成的圖像在比較圖中最模糊,視覺效果最差。圖(c)與圖(d)相比,線條的波紋感較重,圖(d)重建的圖像與原圖最相似,說明用知識蒸餾方法可以有效地提升該小型網絡的超分辨率重建效果。
同時改變教師網絡中卷積的通道數和學生網絡中深度級卷積的通道數進行對比實驗,來驗證知識蒸餾在超分辨率問題中的可行性。對于其通道數c=64,進行了通道數分別為c=32,c=128和c=256的三組對比實驗,其余參數設置以及實驗條件不變。在放大倍數為3時,學生網絡不同通道數的比較結果如表3所示。
從表3可以看出:當通道數發生改變時,學生網絡的峰值信噪比會隨著通道數的增加而增加,而經過教師網絡指導的學生網絡也可以從相應的教師網絡中進行知識蒸餾,并從中受益獲得更高的峰值信噪比。但是當通道數減少時,教師網絡的特征圖提供的知識信息較少,所以學習效果較為一般,而當通道數越來越大時,學生網絡與教師網絡的差距會逐漸變小,所以從教師網絡可以學到的知識也逐漸減少,峰值信噪比的提升值逐漸降低。
4 結語
本文采用知識蒸餾將知識從教師網絡轉移到學生網絡,在不改變其結構、不增加計算成本的前提下,大幅提高了學生網絡的圖像超分辨率重建效果,滿足終端設備實時計算的要求。為了確定在教師網絡和學生網絡之間傳遞信息的有效方式,從兩個網絡中提取不同的統計圖并進行比較。此外,學生網絡利用深度可分離卷積來降低SR的計算成本,從而可以在低功率設備上部署超分辨率重建模型。但是學生網絡未能完全學習到教師網絡的知識,學生網絡的重建效果與教師網絡的重建效果依舊有明顯的差距。在將來研究工作中,將研究構建更小、更高效的超分辨率神經網絡。
參考文獻(References)
[1] DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Berlin: Springer, 2014: 184-199.
[2] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1646-1654.
[3] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1409.1556.pdf.
[4] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1132-1140.
[5] LEDIG C, THEIS L, HUSZR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 105-114.
[6] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[7] ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2472-2481.
[8] ZHANG Y, LI K, LI K, et al. Image super-resolution using very deep residual channel attention networks[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Berlin: Springer, 2018: 294-310.
[9] 陳偉杰. 卷積神經網絡的加速及壓縮[D]. 廣州: 華南理工大學, 2017:1-7. (CHEN W J. The acceleration and compression of convolutional neural networks[D]. Guangzhou: South China University of Technology, 2017: 1-7.)
[10] HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1503.02531.pdf.
[11] REMERO A, BALLAS N, KAHOU S E, et al. FitNets: hints for thin deep nets[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1412.6550v2.pdf.
[12] HORWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1704.04861.pdf.
[13] DONG C, LOY C C, TANG X. Accelerating the super-resolution convolutional neural network[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Berlin: Springer, 2016: 391-407.
[14] LAI W, HUANG J, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5835-5843.
[15] TONG T, LI G, LIU X, et al. Image super-resolution using dense skip connections [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 4809-4817.
[16] ZAGORUYKO S, KOMODAKIS N. Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1612.03928.pdf.
[17] AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1122-1131.
[18] BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single image super-resolution based on nonnegative neighbor embedding[EB/OL]. [2019-01-10]. http://people.rennes.inria.fr/Aline.Roumy/publi/12bmvc_Bevilacqua_lowComplexitySR.pdf.
[19] ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[C]// Proceedings of the 2010 International Conference on Curves and Surfaces, LNCS 6920. Berlin: Springer, 2010: 711-730.
[20] MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]// Proceedings of the 8th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2001: 416-423.
[21] HUANG J, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 5197-5206.
[22] KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1412.6980.pdf.
[23] ROMANO Y, ISIDORO J, MILANFAR P. RAISR: rapid and accurate image super resolution[J]. IEEE Transactions on Computational Imaging, 2017, 3(1): 110-125.
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
快樂語文(2021年27期)2021-11-24 01:29:04
甘肅教育(2020年22期)2020-04-13 08:11:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年8期)2016-10-09 02:11:50
