基于爬蟲技術的社會化觀測數據獲取及應用
2019-11-15 06:15:48王書欣陳元昭張舒婷
王書欣 陳元昭 張舒婷
(作者單位:深圳市氣象局)
如何獲取及利用網絡中蘊含的大量社會觀測數據成為新媒體時代氣象觀測發展的重點。深圳市氣象局利用爬蟲技術獲取數據,并通過機器學習方法對數據進行篩選過濾,建立了一套高擴展性、高效性和低成本的氣象社會觀測數據的采集系統,快速獲取、篩選、分析和提取有價值的、多樣化的氣象相關的社會觀測數據,并對數據加以分析應用,為預報員進行公眾服務、大城市氣象災害風險預警提供支撐。
傳統地面綜合氣象觀測是當前對天氣進行預測的一種重要手段,但隨著社會經濟的快速發展及計算機網絡技術的不斷完善,各大領域的數據量都飛速增加,使人們進入到大數據社會時代,移動網絡成為公眾獲取天氣信息的主要渠道,同時也成為信息發布的參與者之一,微博則是最具影響力的傳播途徑。在這一背景下,為使微博中大量社會數據更好地為氣象部門提供服務,就必須完善社會化觀測數據獲取方法。因此探討基于爬蟲技術基礎之上的社會化觀測數據與獲取具有重要意義。
目前,盡管國內氣象部門尚未有基于爬蟲技術的數據獲取技術,但國內外大量專家學者針對網絡爬蟲技術開展了大量的研究工作。基于以往研究,深圳市氣象局首度嘗試建立基于爬蟲技術的社會化觀測數據獲取平臺。本文將著重基于爬蟲技術探討社會化觀測數據獲取及應用,以打破傳統氣象觀測壁壘,開展多源觀測數據的在線融合并推進氣象觀測的社會化,彌補觀測空缺,利用獲取數據分析熱度和情感,使社會化數據可以在天氣預報服務中得以利用。
1 社會化觀測數據獲取平臺建設
隨著大數據時代的到來,氣象部門需建設一套高擴展性、高效性和低成本的氣象社會觀測數據的采集系統,通過快速獲取、處理、分析和提取有價值的、多樣化的氣象相關的社會觀測數據,以滿足當今大數據環境下對于文本、圖片等數據的采集、存儲、分析及可視化需求,為社會提供更優質的服務。
為此,搭建基于爬蟲技術的社會化觀測數據獲取平臺,可以完成數據獲取,數據過濾以及數據分析三部分工作。通過爬蟲技術獲取包括冰雹、龍卷等現有探測設備無法精準捕捉的中小尺度天氣現象,其形式包括文字、圖片、視頻等。由于爬取到的數據有大量的重復、過時甚至是虛假信息,需要對其進行過濾,最終將可用的數據進行氣象實況監控和公共服務輿論情感分析,后文將詳細闡述這部分工作。
平臺包含數據獲取模塊、數據存儲模塊和結果分析展示模塊(圖1)。基于氣象社會觀測信息的特點,采用分布式數據采集技術,并存儲在數據庫中,通過建立機器學習、深度學習的模型對數據進行計算和分析,得到統計信息,最終通過可視化的界面展示。三個模塊分工明確,下層向上層提供可靠服務,最終構成整個完整的平臺。
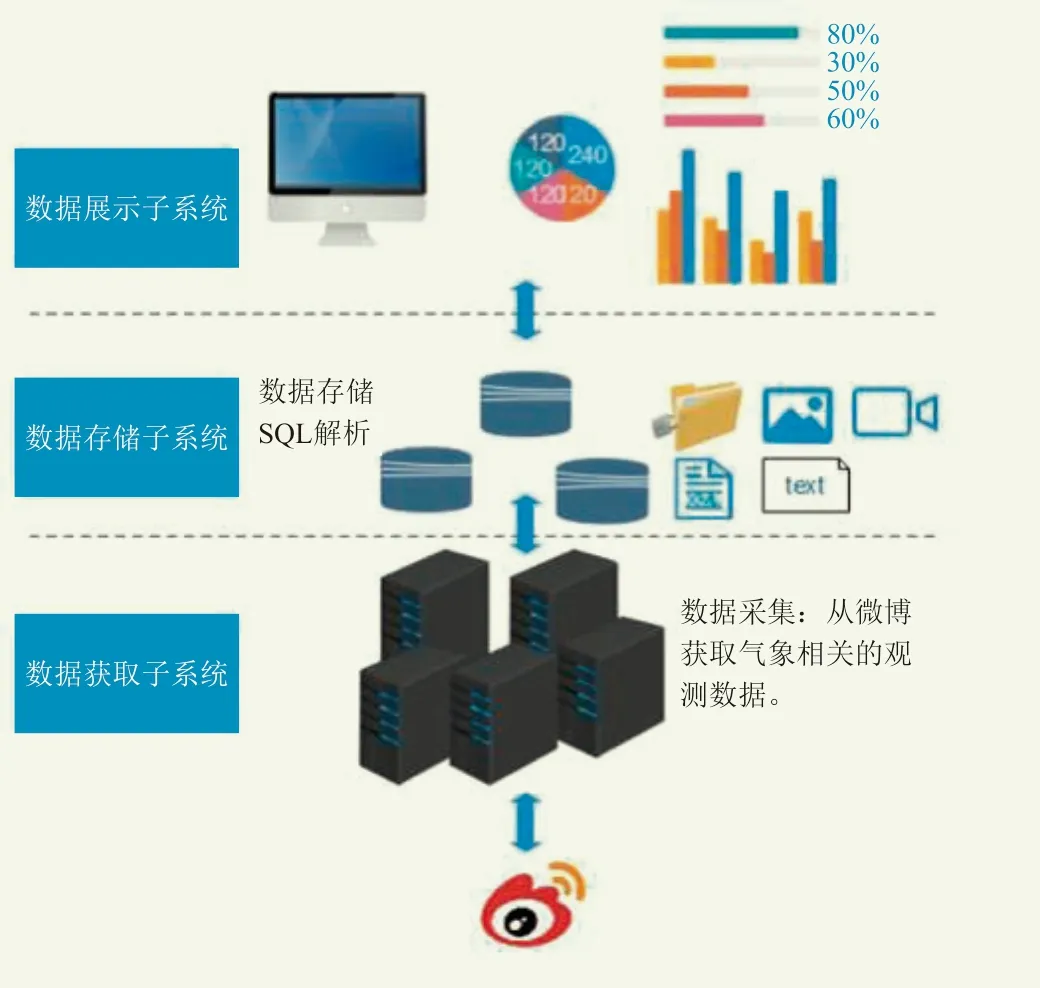
圖1 社會化觀測數據獲取平臺設計模型
2 社會化觀測數據來源
深圳天氣微博建立8年,截至2018年11月,粉絲187萬人,僅2018年閱讀量達10億次,轉評次數超過50萬次,超強臺風山竹話題討論量過100萬次,在如此龐大的信息庫中存在著海量的社會自發上傳至社交媒體的觀測信息,與傳統氣象監測如自動站、雷達、衛星數據不同,社會觀測數據雖不能精確測量各種氣象要素,但可以監測到包含冰雹、龍卷等罕見無法監測的天氣現象,以及積水、滑坡等氣象部門無法掌握的衍生災害實況,這些數據有效地對傳統氣象觀測數據進行補充,通過收集該信息的發布時間、發布地點以及相關內容包括圖片、視頻等信息,擴大氣象數據觀測網,共實現爬取冰雹、大風、暴雨、雷電、龍卷5種氣象類信息,以及積水、洪澇、滑坡3種災害影響類信息。
目前平臺數據主要來源于新浪微博,但此技術同樣可應用于微信、各大門戶、新聞網站以及各政府部門網站,從而獲取氣象信息和其影響信息,此項工作未來將逐步開展。
3 社會化觀測數據獲取、篩選與分析
3.1 基于爬蟲技術的社會化觀測數據獲取
網絡爬蟲技術是互聯網搜索功能中一項基本技術,其在中國最成功的應用就是百度搜索引擎,通過一傳十、十傳百的裂變搜索方式,實現信息的網狀獲取,該技術的優點在于信息獲取速度快、內容全。為此引入網絡爬蟲技術來獲取新浪微博中社會觀測數據,并按照一定的預設關鍵詞、地域、時間等閾值進行自動識別、抓取氣象相關信息的程序和腳本。
基于網絡爬蟲技術獲取社會化觀測數據的方法主要包括:基于第三方軟件或者第三方微博數據集的方法、基于新浪公開API的方法和網絡爬蟲抓取的方法。通過使用爬蟲技術中通用的Scrapy爬取方式,可以同時發送多條爬取請求,同步進行信息爬取,最大化增進爬取效率。由于采集到的微博數據并非都是描述冰雹、龍卷風、大風等發生信息的數據,需要采用文本分類技術,將實際含有上述關鍵詞的文本識別出來,同時記錄其相關的圖片、視頻、網頁鏈接等信息。
所獲取的信息同時需判斷以下幾個條件以便進行后期分析:1)記錄的信息與災害性天氣相關;2)如果與災害性天氣相關,有明確的發生氣象現象的位置或時間;3)記錄的信息與輿情是否相關。
目前,基于新浪微博平臺的數據進行爬取的數據可在5 min內完成,但結合深圳實際天氣情況以及工作需要將爬取頻率保持1次/h,鑒于目前雷達數據的更新頻率為6 min,在惡劣天氣下,也可后臺更改爬取頻率為1次/6 min。
3.2 無效數據過濾篩選
通過爬蟲技術獲取的文本信息存在大量失真、失效、無用甚至是廣告數據,為保證數據的可用性,需對其進行過濾篩選。通過機器學習方式,使用支持向量機(SVM)模式進行數據分類與回歸分析,由預報員人工判別給定的多組社會數據訓練實例,將訓練實例分類標記為有效、無效兩類,通過機器不斷學習,使SVM模型成為非概率的二元線性分類器。當出現新的實例時,SVM模型將其進行分類為有效或無效其中一類。經過大量數據訓練,機器將過濾篩選后的數據推送至前段展示,預報員仍可手動調整信息類別,通過不斷增加訓練實例,形成正反饋機制,不斷優化篩選模型。
3.3 重復微博數據過濾
利用爬蟲技術采集篩選后的微博數據仍存在大量的重復數據從而影響分析結果,選用simhash算法去重可以高效地將爬蟲系統每日數以千萬級的數據進行去重合并,通過對文檔關鍵詞進行拆分并整理成關鍵詞集合,對比不同文檔關鍵詞集合相似度,去除重復數據。
目前對廣東省范圍內的冰雹、大風、暴雨、雷電、龍卷5種氣象類信息,以及積水、洪澇、滑坡3種災害影響類信息進行爬取,共獲取到53900條數據,其中氣象類數據48538條,災害影響類5362條,由圖2逐日數據結果展示可以直觀獲知深圳4—9月重大災害天氣發生時間,如8月底持續季風低壓降水和9月15—16日超強臺風山竹影響,對于4月前汛期深圳無強對流、回南天等高影響天氣這種反例也有明顯表現。同時可以獲知社會數據獲取強度,對強天氣過程、衍生災害進行準確識別。
4 主題詞熱度分析和情感分析應用
4.1 主題詞熱度分析
氣象中所關注的熱度,是市民在一段時間內所關注的某一天氣類型、災害信息或是相關話題,我們提取其關鍵字作為熱度的主題詞。傳統的基于詞頻分析的主題模型不能從語義中進行分析,而將微博熱度作為計算基數的LDA主題模型則是將評論數、轉發數納入計算,獲取微博主題熱度分布,得到真實的高關注度數據信息,可供預報員更有針對性進行服務或是發現并處理輿情。
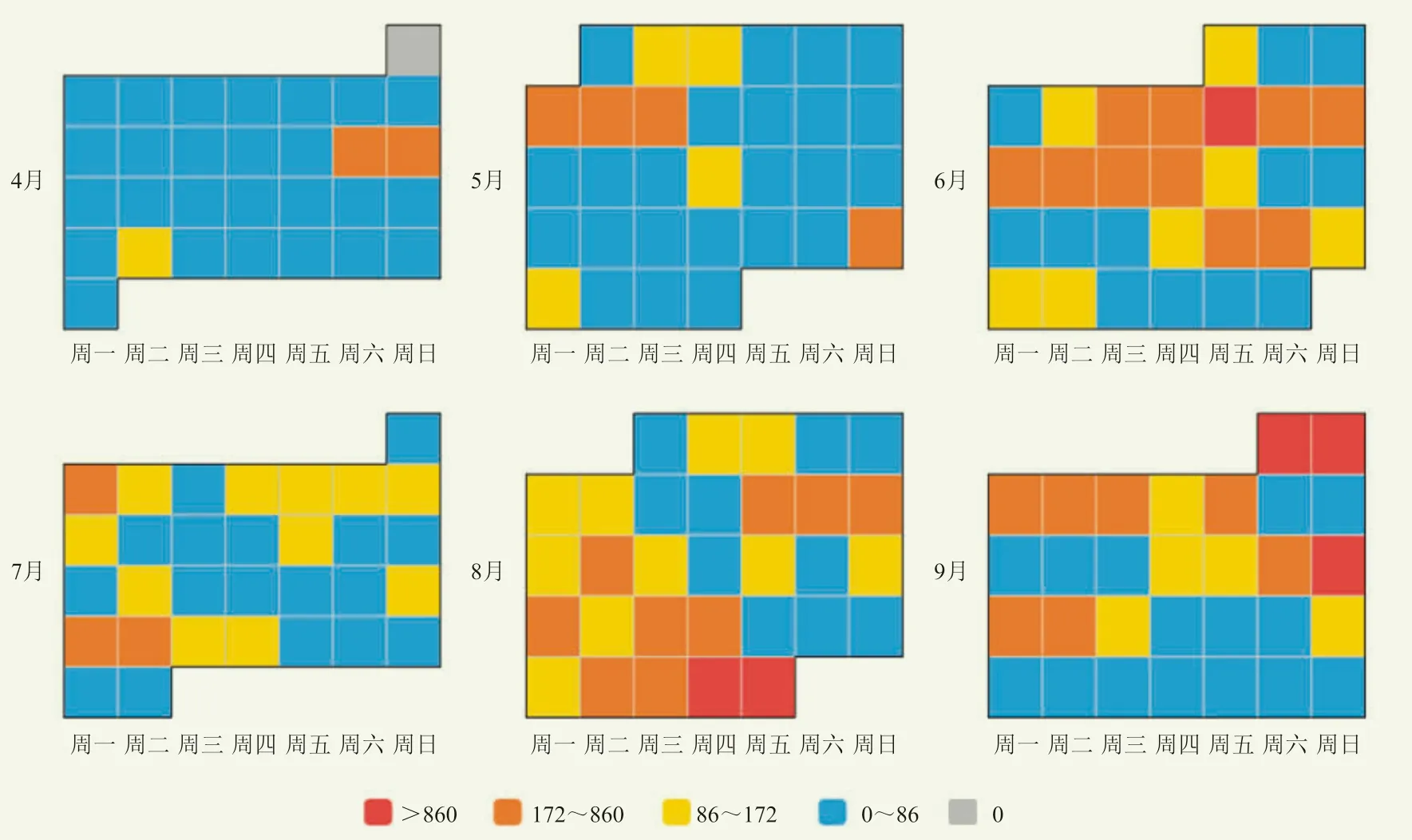
圖2 2018年4—9月逐日獲取數據結果展示(條)
對于微博氣象信息的挖掘,由于微博用戶之間具有關注與被關注、轉發與評論的關系,社會關系網龐大而復雜,常規的分析方法無法勝任。“深圳天氣”微博信息構成的文本矩陣的稀疏性和高維度性,選擇使用潛在狄利克雷分布的主題生成模型(LDA)來完成基于潛在語義分析的文本挖掘方法進行的微博主題的挖掘。

圖3 2018年6月5—9日主題詞熱度分析結果展示
2018年6月6—8日受南海熱帶低壓影響,廣東大部出現大暴雨。通過統計2018年6月5—9日微博中社會化數據得出主題詞熱度如圖3所示,經與天氣實況以及預報員輿情監控對比看來,此次記錄為真實有效。統計顯示最受網友關注的天氣現象為臺風、暴雨和大暴雨,深圳、江門和廣州則為受影響關注度最高的地區,說明本次過程對珠三角地區的高密度人群影響更為顯著;同時天氣預警信息和高考信息也同樣備受關注,在進行公眾服務時應將其與其他高熱度主題結合共同服務。
經過未來的長期主題詞熱度數據積累,可以總結出公眾所真實關心、討論的天氣現象,從而根據需求,加大該天氣條件下的氣象服務力度。
4.2 情感分析
氣象服務由于其必然存在的不準確性以及目前與公眾所期望的精細化預報間的差距,氣象部門經常陷入輿論風波,由于輿情信息的不能及時獲取,往往不能正確地化解輿情。而基于爬蟲技術獲取到的數據中除大量的社會觀測數據,其中還包含著社會的情感狀態,包括正面積極鼓勵的言語或是負面批評的指責,分析數據中的情感走向有助于更好掌握輿情動態,引導大眾評論走向,為氣象服務做出正面回應。
目前爬取3萬條微博,84萬條深圳天氣微博的評論,人工對其中1萬條評論進行情感定性,分為積極評價(pos)和消極評價(neg)以及中性,根據多元伯努利事件模型(NB)、支持向量機(SVM)、卷積神經網絡(CNN)、循環神經網絡(RNN)、霍普菲爾網絡(HN)、深度霍普菲爾網絡(Att+HN)、AVG函數、時間敏感網絡(TSN) 8種機器學習方法對3萬條評論進行分析實驗,通過計算情感定性準確率、相關系數以及方差確定學習方法,結果如圖4。

圖4 微博評論數據的對比試驗結果
統計表明,RNN、Att+HN 、AVG三種方法的分析結果更為準確,其中AVG方法的方差結果更優,準確率和相關性結果也名列前茅,綜合考慮AVG方法更穩定更適合進行情感分析。
同樣,對6月5—9日降雨過程進行情感分析,共獲取15060條數據(表1),發現大部分評論感情色彩以中性為主,其中大部分是提出咨詢,惡劣天氣來臨或正在影響時人們關注度大幅提高,過程結束關注度急劇下降,9日數據量僅為7日的1/10;惡劣天氣下消極評價量、比例同步上升,而在惡劣天氣最初影響時人們更愿意發表有感情色彩的言論,6日積極和消極評價占比總評價數為22.3%,相較其他日期上升3%~5%。預報員根據以上情感分析數據及時引導輿論。
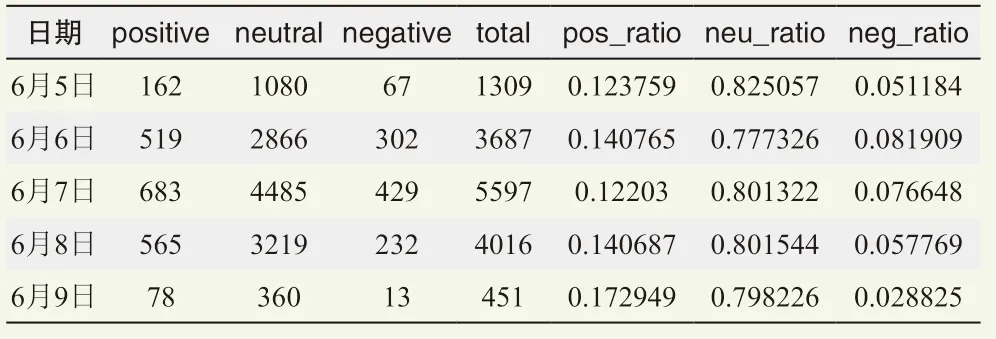
表1 2018年6月5—9日情感分析結果展示
5 結論及展望
根據過去一年的平臺建設與數據獲取分析發現,基于爬蟲技術來獲取社會化觀測數據可以有效地補充常規氣象觀測的不足,尤其是在冰雹、大風、暴雨等氣象災害發生時可以快速獲取大量信息,并獲取其帶來的影響,加大輿情監控,為預報員進行公眾與決策服務進行數據支撐。通過爬蟲技術獲取到的數據我們可以清楚獲知災害發生的種類、時間、時長與地點,并進行記錄統計,為預報和決策服務提供支持;通過主題詞熱度分析,預報員可以清晰感知公眾關注熱點,并有針對性地開展公眾服務;情感分析幫助預報員實時監控輿情,在惡劣天氣或預報失誤時,及時化解輿情。
未來爬蟲技術在社會化觀測數據將結合雷達與自動站實況進一步優化數據篩選結果,加大其真實可用性,并且獲取途徑將不僅限于新浪微博平臺,深圳天氣微信同樣具有100萬粉絲,年閱讀量超過1000萬次,各大新聞客戶端如騰訊、網易、今日頭條也具有極高的互動性,在上述平臺開展社會化觀測數據獲取工作,可以進一步擴大數據來源。該技術也可運用到政府網站及其他類型網站中,以用于獲取如河道、水位、浪潮等基礎信息的更細,使決策服務技術得到更多數據支撐。
深入閱讀
楊富蓮, 2017. 地面綜合氣象觀測能力提升對策. 科技與創新, 9:47-48.
姜青山, 2018. 淺談氣象服務App的開發與應用. 科技風, (1): 124-124.王杰, 2017. 基于微博大數據的輿情監測系統的設計與實現. 天津:中國民航大學.
劉慶華, 覃茹芊, 2013. 探索區域氣象觀測站社會化保障的新模式.氣象研究與應用, 34(z2): 170-171, 173.
石磊, 2013. 新浪API與網絡爬蟲結合獲取數據的研究與應用. 中國電子商務, (22): 58-59.
毛夏, 李磊, 江崟, 等, 2017. 深圳超大城市氣象探測數據在科學研究中的應用. 廣東氣象, (6): 2-5.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
山東工業技術(2016年15期)2016-12-01 05:31:22
中外會展(2014年4期)2014-11-27 07:46:46
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
 Advances in Meteorological Science and Technology2019年3期
Advances in Meteorological Science and Technology2019年3期
- Advances in Meteorological Science and Technology的其它文章
- 讀圖
- 榜單
- 媒體掃描
- 兩岸聚力 共建華夏氣象前沿陣地
- 深圳市防雷安全管理信息系統的建設
- 從SCI收錄情況看大氣科學期刊發展態勢