Web應用程序搜索功能的組合測試*
2019-11-12 05:41:04呂成成曾凡平
計算機與生活 2019年11期
關鍵詞:方法
呂成成,張 龍,鄧 茜,曾凡平,3+,嚴 俊,張 健
1.中國科學技術大學 計算機科學與技術系,合肥 230026
2.中國科學院 軟件研究所 計算機科學國家重點實驗室,北京 100190
3.安徽省計算與通訊軟件重點實驗室,合肥 230026
1 引言
隨著互聯網的快速發展,Web應用程序迅速進入普通用戶的視野[1]。為了方便用戶查詢感興趣的資源,許多Web 應用程序會提供搜索功能。瀏覽器將用戶輸入的關鍵詞提交給服務器,然后服務器處理該請求并將查詢結果返回給用戶。如果開發者在實現該功能的時候,對用戶輸入的合法性沒有進行充分的驗證,可能會帶來安全隱患。如果用戶輸入的數據中含有某些特殊字符,使得服務器程序無法正常執行,就會產生錯誤響應,并將異常代碼拋到前端瀏覽器中或者直接在前端顯示服務器錯誤等信息。
例如,圖1(a)是某市疾控中心的主頁,當搜索關鍵詞“占比%1”時,服務器不會返回正常的搜索結果,而是返回一個只包含錯誤信息的頁面,如圖1(b)所示,顯示服務器遇到內部錯誤,服務端的java 程序遇到了“java.lang.NullPointerException”的異常,無法完成此請求。Web應用程序中存在很多這樣的錯誤,圖2 是4 種不同的出錯頁面,都是因為搜索某些特殊字符導致的。這些應用程序錯誤會導致服務器無法返回正常的搜索結果,同時有些錯誤頁面也會暴露敏感信息,如服務器物理路徑、堆棧調用信息、數據庫信息等。
此類故障的存在不但會影響用戶體驗,而且極有可能成為安全問題。比如,攻擊者在尋找SQL(structured query language)注入點時,通常會輸入某些特殊字符,如果服務器返回錯誤,很可能可以進行SQL 注入,因為這表明Web 應用程序中對用戶提交的數據未進行合理的驗證或過濾[2-3]。同時,錯誤頁面暴露的敏感信息會為攻擊者提供極大的便利[4]。因此,對搜索功能的充分測試是非常有必要的。
對于Web 應用程序的搜索功能,覆蓋全空間測試用例的完全測試幾乎是不可能完成的任務,因為搜索空間巨大,無法在有限時間內完全覆蓋。而只考慮搜索那些常見內容的測試場景是很難滿足測試要求的,因為在實際操作中,用戶很可能不小心輸錯內容,也有很多惡意用戶會嘗試搜索一些危險且不常用的字符。因此,測試用例要充分考慮各種常用和不常用字符及它們的組合。可以將組合測試的方法應用到Web程序搜索功能上。

Fig.1 Search function display圖1 搜索功能展示

Fig.2 Web page error message圖2 網頁錯誤信息
在系統測試中,檢查系統參數的所有取值組合來進行充分的測試需要花費很高的代價,因為隨著參數數量的增加,測試用例的數量呈指數增長。組合測試[5]是一種有效的黑盒測試方法,其充分考慮到系統中各參數之間的交互作用,進而生成高質量的測試用例。很多應用程序錯誤是由少數幾個參數的相互作用導致的[5],例如Kuhn 和Reilly[6]分析了Mozilla瀏覽器的錯誤報告記錄,發現超過70%的錯誤是由某兩個參數的相互作用觸發的,超過90%的錯誤是由3個以內的參數互相作用觸發的。組合測試(CT)[5]的方法就是選擇部分測試用例,可以覆蓋任意t(t是一個正整數,且t≥2)個參數可能取值的全部組合。
如果執行完測試用例后,有部分測試用例會引起服務器錯誤響應,可以使用組合測試錯誤定位的方法來找到這些字符組合。傳統的錯誤定位是想找到錯誤的根本原因以及錯誤在源碼中的位置,而本文這里的定位是想找到程序輸入中哪些參數及其取值組合會引起系統錯誤,本文提到的錯誤定位和錯誤組合定位都指后者。本文在已有的研究基礎上,結合搜索功能測試的特點,提出一種組合測試錯誤定位方法,可以有效地找到會引起錯誤組合。
對搜索功能的充分測試可以暴露出服務端程序在處理特殊字符組合時潛在的問題。而錯誤定位可以幫助開發者修復這些故障,提升網站的形象,提高用戶體驗,避免惡意用戶的攻擊。因此,對搜索功能的充分測試是非常有意義的。
總的來說,這篇文章主要有以下三點貢獻:
(1)在Raunak 等人[7]的基礎上,實現了一個使用組合測試方法測試Web應用程序的搜索功能原型工具,并提出一種組合測試錯誤定位方法,可以有效地找到會引起服務器錯誤響應的字符組合。
(2)測試了96 個學校、政府和事業單位類網站,發現其中23 個網站的搜索功能存在問題,當用戶搜索某些特殊字符組合時,會引起服務器的錯誤響應。
(3)對存在問題的網站的錯誤定位結果進行分析,發現56%的服務器錯誤響應是由“%”“<”“’”“”和其他字符的組合引起的。
本文的組織結構如下:第2章介紹組合測試的背景知識;第3 章介紹本文提出的方法;第4 章介紹實驗結果和評估;第5 章介紹相關的研究工作;第6 章是本文的總結與展望。
2 背景介紹
關于組合測試和錯誤定位,相關定義[8]如下:
定義1(SUT(software under testing)模型)一個SUT(k,s)模型有k個參數p1,p2,…,pk。s是一個長度為k的向量,可表示為,其中sj表示參數pi可能取值的個數,pi的定義域為Di={di1,di2,…,disj}。
定義2(測試用例)一個測試用例t是一個長度為k的向量,可表示為,其中v1∈D1,v2∈D2,…,vk∈Dk,表示為SUT 中每個參數賦予一個確定的值,p1=v1,p2=v2,…,pk=vk。
定義3(測試用例集)一個測試用例集T是一組測試用例集合{t1,t2,…,tm}。
定義4(combinatorial interaction,CI)一個交互組合CI是一個長度為k的向量,其中t個參數賦予特定的值,剩下的k-t個參數未確定(未確定的值用-表示)。這里t表示CI 的大小。例如,長度為k的向量可表示一個大小為1 的CI,其中v1∈D1,它表示參數p1=v1,剩下的k-1個參數未確定。
定義5(CI 包含關系)一個CIP1被另一CIP2包含(contain),當且僅當P1的所有賦值的參數在P2中也被賦值,并且這些參數在P1和P2中被賦予了相同的值。一個CIP被測試用例T包含,當且僅當P中的所有賦值的參數具有與T中相同的值。
定義6(faulty combinatorial interaction,FCI)一個錯誤交互組合FCI是一種特殊的CI,所有包含它的測試用例都會失敗。
如果Pi是FCI,其他任何包含Pi的CI也是FCI。比如P1是一個FCI,且P2包含P1,所有包含P2的測試用例也都將包含P1,因此這些測試用例都會失敗,即P2也是FCI。組合測試的錯誤定位是想找到那些最小FCI(minimal FCI),最小FCI不包含任何比它小的FCI。
組合測試的錯誤定位主要可以分為兩種,非自適應方法和自適應方法。非自適應的方法是指所有的測試用例可以并行執行,不依賴于先前測試用例的執行結果。Colbourn和McClary[9]提出了一種錯誤定位方法,他們通過構造Locating Array 的方法來找到系統中的最小出錯組合。Zhang等[8]提出了一種基于約束求解和優化技術的方法,無需生成額外的測試用例就可以找到最小出錯組合。自適應的方法是指部分測試用例的選擇是基于先前測試用例的執行結果。Zeller和Hildebrandt[10]提出了一種典型的自適應方法。這種方法的主要思想是通過修改輸入參數來找到最小出錯組合。對于失敗的測試用例,修改其中部分參數的值;如果修改后的測試用例仍然是失敗的,則修改的參數與系統錯誤無關;否則,修改的參數與系統錯誤有關。
3 研究方法
圖3 是整體方法的流程圖。主要分成測試用例生成、測試用例執行和錯誤組合定位三部分。下面詳細介紹各部分內容。
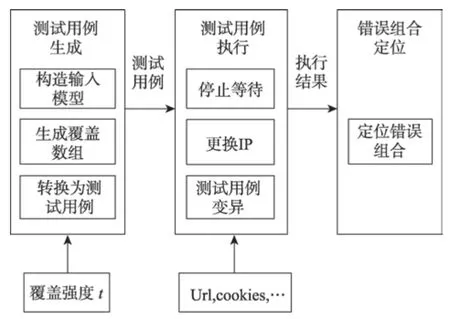
Fig.3 Workflow of method in this paper圖3 方法流程圖
3.1 測試用例生成
本文使用組合測試的方法來生成測試用例。組合測試是一種有效的測試方法,可以應用于網站搜索功能的測試。可以根據組合覆蓋率生成測試用例,測試強度為t(t為正整數,且t≥2)的組合測試可以保證任何參數值的t組合至少被一個測試用例覆蓋。組合測試用例的構造方法,多數是基于覆蓋數組的。組合測試設計過程可簡要描述如下:
(1)建立輸入模型(input model),模型包括有哪些參數以及每個參數的可能取值。
(2)根據輸入模型,生成覆蓋數組。
(3)將生成的覆蓋數組轉化為測試用例,覆蓋數組的每一行表示一個測試用例。
步驟(1)的輸入模型將在下面詳細介紹。步驟(2)使用組合測試用例生成工具ACTS[11](advanced combinatorial testing system)來生成覆蓋數組。ACTS由NIST(National Institute of Standards and Technology)和UTA(University of Texas at Arlington)聯合開發,實驗表明,與類似工具相比,在覆蓋度t相同的情況下,ACTS生成的測試集較小,并且比其他類似工具更快,比如AETG(http://aetgweb.argreenhouse.com/)。步驟(3)將覆蓋數組轉化為測試用例并執行,覆蓋數組中每一行是一個測試用例,每一個測試用例是一個由特殊字符組成的字符串。最后,通過組合測試錯誤定位的方法來找到是哪些特殊字符的組合引起的服務器錯誤響應。各部分方法的詳細介紹如下。
從用戶提交輸入到得到返回頁面服務端程序對用戶輸入可能的處理操作有:
(1)數據的編碼和解碼操作,如果用戶的輸入不滿足特定的參數格式,可能會引起錯誤(如URL(uniform resoure locator)解碼,可以考慮%與其他字符的組合)。
(2)過濾轉義操作:考慮到XSS(cascading style sheets)、SQL 注入等安全問題,很多網站會對用戶輸入進行過濾和轉義,因此需要在輸入模型中加入部分XSS、SQL元素。
(3)查詢操作:服務端程序可能會將用戶的輸入拼接成數據庫查詢語句,當存在某些特殊字符時,可能會改變查詢語句的語義從而引起錯誤。
可以構造輸入模型如表1 所示,共有7 個參數。參數的選擇和取值并不是唯一的,開發者可以根據實際的需求來構造模型。這里借鑒Bozic等[12-13]構造XSS攻擊向量的方法,取7個參數,各參數分別表示為:
參數1模擬輸入標簽的結束符號。比如SQL查詢中,待比較的字符串應該填充在兩個單引號之間,參數1 選擇單引號可以模擬SQL 語句中單引號作用區間的結束,使后面的字符組合可以當作代碼被執行。
參數2表示打開一個作用區間,比如“{”等,可以與后面的關閉標記“}”組成一個作用區間。
參數3、4、5表示在參數2 和參數6 構成的作用區間中特殊字符組合,比如英文字母“aBcD”、數字“22”、標點符號“?”、運算符號“+”、其他特殊字符“&”等。
參數6關閉由參數2打開的作用區間,比如“}”,可以與前面的打開標記“{”組成一個作用區間。
參數7表示在輸入末尾有特殊作用的關鍵詞,比如在SQL語句中有注釋作用的“#”。
該模型可表示為一個SUT(7,<7,9,9,8,6,6,5>)。從每個參數的取值范圍中選擇一個值組成一個用于搜索的字符串,每個參數分別有7、9、9、8、6、6、5個可能取值,這樣一共有816 480 種不同的字符串,而使用ACTS 構造的覆蓋強度為2 的測試集只需要81 個測試用例。

Table 1 Input model表1 輸入模型
在這個輸入模型中,space代表空格,NULL表示不取一個空字符。其中,數字和字母組合有aBcD、script、11 等;特殊字符有(、)、[、]、{、}、<、>、”、’、、%、!、?、~、/、|、&、-、、,、.、^、+、=、*、#,包括運算符號、標點符號等。
3.2 測試用例執行
通過組合測試工具生成測試用例,每一個測試用例是一個由特殊字符組成的字符串。對于每一個測試用例,通過構造URL來模擬查詢字符串,如果返回正常的頁面,則認為此測試用例的執行結果為通過,如果服務端直接將異常代碼拋到前端瀏覽器,或者在前端瀏覽器顯示服務器錯誤,就認為此測試用例的執行結果為失敗。
在實際測試中,可能遇到以下兩種情況。(1)IP限制,即如果檢測到同一IP 在短時間內發送大量請求,則限制該IP的訪問;(2)存在部分無效測試用例,可能的原因之一是Web 應用程序內部的防御機制。如果用戶的輸入滿足防御機制內置的安全規則,則重置鏈接或拒絕執行此請求[14]。
對于第一種情況,采用停止等待或者更換IP 的方法,同時這也要求本文的測試用例規模不能太大。
第二種情況中,部分測試用例可以得到執行結果,而部分測試用例無法得到執行結果,是無效的。無效測試用例中所包含的字符組合會因為測試用例無效而無法被覆蓋到,這種行為在組合測試中稱為masking effect[15]。造成部分測試用例無效的原因是由于包含了部分字符及其組合,可以生成額外的測試用例來解決這個問題。
發現一個測試用例t=是無效的,使用Simplified-One-Factor-One-Time[16]的方法對測試用例進行變異,構造k個額外的測試用例,,其中*表示一個隨機的并且和原測試用例不相同的值。這樣因為原測試用例無效而無法被覆蓋到的組合可以重新被覆蓋到。
比如,對于一個目標網站,有測試用例“’{script|^>#”,在執行該測試用例時,因為“’”的出現該字符串滿足此網站的安全規則,服務器拒絕執行該請求,則該測試用例無效。此時,無法確定其他字符及組合是否會引起服務器內部錯誤,實際上,“{script”是會引起服務器錯誤的。此時,可以使用一階變異的方法額外生成7個測試用例,“{script|^>#”“’script|^>#”“’{|^>#”“’{script^>#”“’{script|>#”“’{script|^#”“’{script|^>”。執行這7個測試用例,其中“{script|^>#”這個字符串會引起服務器內部錯誤。這樣,就不會因為該測試用例無效而使錯誤組合“{script”無法被發現。
3.3 錯誤組合定位
對于存在錯誤的Web 應用,通過組合測試錯誤定位的方法來找到是哪些特殊字符的組合引起的服務器錯誤響應。使用組合測試生成字符串進行測試時不需要全部參數,只使用部分參數,也能構造一個測試用例,可以將這個特點應用到錯誤定位中。
Raunak 等[7]使用了Colbourn 和McClary[9]提出的一種非自適應的組合測試錯誤定位方法。在該方法的基礎上,提出一種新的錯誤定位方法。該方法的算法過程如算法1所示。
算法的第一步是得到一組可疑的CI集合。算法的輸入是一組測試用例的執行結果,Fail_T表示失敗測試用例集,Pass_T表示通過測試用例集,輸出是FCI集合(出錯組合)。算法的第一行將Minimal_FCI設置為空集,它將用來保存找到的FCI。算法的第2行,是找出可疑CI集合。如果一個CI出現在失敗測試用例中,它可能是一個FCI,如果一個CI出現在通過的測試用例中,它一定不是FCI。這樣,那些出現在失敗測試用例中,但沒出現在通過測試用例集中的CI就是可疑CI。用Fail_T包含的全部CI減去Pass_T中包含的全部CI,則會刪除一定不可能是FCI的CI,但剩下的CI不一定就是FCI,Susp_CI_Set表示這些可疑的CI集合。
算法的第二步是從可疑CI集合中得到最小出錯組合(minimal FCI)。本文和Raunak 等[7]的方法有所不同。Raunak 的方法假設Pi,Pj∈Susp_CI_Set,且Pi包含Pj。Pi和Pj都能引起錯誤,但Pi不是最小出錯組合(minimal FCI),需要將Pi刪除。因此Raunak將Susp_CI_Set包含其他CI的CI刪除,得到的就是最終結果。這種方法的有效性不高,因為會存在部分CI雖然只出現在了失敗測試用例中,但并不能導致服務器錯誤,不能將其當作FCI,因此也就不能將包含此CI的其他CI直接刪除。
為提高定位的有效性,本文從算法的第3行到第11行,確認Susp_CI_Set中可疑的CI是否為FCI。因為希望找出最小出錯組合,所以從大小為1 的CI開始確認,如果這個CI構成的測試用例執行結果為失敗,它就是FCI,將其加入到Minimal_FCI,如算法的第7行所示。因為包含此CI的其他CI也是FCI,但不是最小出錯組合,在算法的第8 行,將Susp_CI_Set中包含此FCI的其他CI刪除。確認完大小為k的FCI后,返回Minimal_FCI。此時,Minimal_FCI就是錯誤定位到的最終結果。
算法1組合測試錯誤定位
輸入:失敗測試用例集Fail_T,通過測試用例集Pass_T。
輸出:FCI集合。


4 實驗結果與分析
在python 3.5.4 環境下實現了一個原型工具,可以實現本文提到的全部方法。使用該工具測試實際中的Web應用程序。
360 發表的《2017 中國網站安全形勢分析報告》(http://zt.360.cn/1101061855.php?dtid=1101062368&did=490995546)顯示,教育培訓、政府機構和事業單位這3個行業的網站是檢測出網站漏洞最多的行業。搜索功能的測試和網站的安全關系密切,而且政府、學校等網站是面向大眾的,具有特定權威、嚴肅等屬性,這些網站出現故障將極大影響公共安全和其公信力。從安徽、北京、陜西等地的學校,政府機構和事業單位網站中收集了96 個提供搜索功能的網站,其中有:48個學校類網站,包括12個研究生院網站,3個大學網站和5個中學網站;40個政府機構網站,包括13個省政府網站和27個市政府網站;8個事業單位類網站。在這96個網站中,有76個使用get方法發送http請求,有20個網站使用post方法發送http請求。
4.1 實驗結果
使用組合測試的方法測試了這96 個網站,實驗結果發現,96 個網站中共有23 個網站的搜索功能存在問題,實驗結果如表2所示。其中在8個事業單位類的網站中,有3 個網站存在錯誤,占比最高為37.5%;48 個學校類的網站中存在錯誤的網站有15個,占為31.25%,有50%的研究生院網站存在錯誤,相比于大學和中學網站,研究生院的網站更容易檢測到錯誤;40 個政府機構網站中存在錯誤網站有5個,占比最小,為12.5%,市政府網站比省政府網站更容易檢測出錯誤。
在這96 個網站中,使用get 方法的76 個網站中,有14個網站存在錯誤,占比為18.4%。使用post方法的20個網站中,有9個網站存在錯誤,占比為45.0%。在本次實驗中,使用post方法發送http請求的網站更容易檢測出錯誤。

Table 2 Results of Website testing表2 網站測試結果
對搜索功能存在錯誤的22個網站進行錯誤定位(剩下的一個網站,雖然檢測到了錯誤,但因為它對ip的限制嚴格而無法錯誤定位),來確定是哪些字符組合引起的服務器錯誤。共發現112 種不同的FCI,對應著112 種不同的會引起網站服務器錯誤的字符組合。這112種FCI的大小的分布圖如圖4,可見大小為2的FCI共有65種,占比最大,93.75%的FCI值小于3。

Fig.4 FCI size distribution圖4 FCI大小分布圖
根據這些會引起服務器錯誤的字符組合的頻數進行了統計,統計結果如表3所示。頻數最多字符組合共出現了11次,是“%!”“%?”“%/”“%~”,并且56%的服務器錯誤都是由“%”“<”“’”“”和其他字符的組合引起的。根據部分網站的應用程序錯誤信息,分析這些字符組合引起服務器錯誤的可能原因如下:
“%”:“%”通常會用來做URL 編碼,Web 程序將用戶提交的輸入直接通過get或post方法提交到服務器,服務器程序會先對輸入做URL 解碼,此時包含“%”并且不符合URL編碼規則的輸入就會引起程序崩潰,造成服務器錯誤響應。

Table 3 Result of fault location表3 錯誤定位結果
“<”:“<”是一個常見的html標簽,和XSS注入關系密切。在asp.net 程序中,如果檢測到用戶提交的輸入中含有“
“’”:SQL 查詢中,待比較的字符串應該填充在兩個單引號之間,如果用戶提交的輸入中含有“’”,且服務端程序直接將用戶輸入拼接成SQL語句進行查詢,就會導致SQL查詢的異常,從而造成服務器的錯誤響應。一般來說,如果含有“’”的字符組合可以引起服務器的錯誤響應,則該網站有很大的可能存在SQL注入的漏洞[2-3]。
“”:在正則表達式中以及SQL 語句中表示轉義字符,表示下一個字符為特殊字符。服務端程序在處理含有“”的輸入(比如java 程序中的replaceAll()方法)或者進行SQL查詢時,沒有考慮到“”的特殊含義,可能會引起服務器的錯誤響應。
4.2 錯誤網站案例
同時,也將本文的測試方法應用到部分商業網站的測試中。在一個招聘網站的測試中檢測到了問題,下面詳細介紹本文的測試過程。分別執行覆蓋強度為2、3、4的測試用例,執行結果如表4所示。使用錯誤定位的方法來找到引起系統錯誤的字符組合,定位結果如表5所示。

Table 4 Results of test case execution表4 測試用例執行結果

Table 5 Results of fault location of recruitment Website表5 招聘網站的錯誤定位結果
可以發現,覆蓋強度2、3、4生成的測試用例中失敗測試用例的比例基本相似,覆蓋強度3、4的錯誤定位結果是相同的,這些錯誤組合主要是由%和其他字符的組合引起的。可能的一個原因是包含特殊字符組合(比如“%!”“%?”)的輸入會因為不符合URL解碼函數的輸入而引起了“Internal Server Error”的響應。
4.3 測試用例變異方法評估
在實際情況中,部分Web 應用程序在測試時存在masking effect 情況。此時,采用Simplified-One-Factor-One-Time的測試用例變異的方法生成額外的測試用例來解決這個問題。在96 個測試網站中,檢測到有26 個網站存在這樣的情況,其中有3 個網站存在錯誤。無效測試用例的存在使得某些錯誤組合無法被覆蓋到。比較3 個存在無效測試用例且搜索功能存在錯誤的網站的錯誤定位結果,發現有兩個網站在執行完變異測試用例后定位到的錯誤組合數比不執行變異測試用例定位到的錯誤組合數多1。由此可見,使用測試用例變異的方法可以使錯誤定位得到的結果更全面。
4.4 錯誤定位方法評估
Raunak 等[7]使用Colbourn 和McClary[9]提出的組合測試錯誤定位方法,將這種方法記作Method_A。本文的方法記作Method_B。主要考慮兩方面:(1)錯誤定位方法是否可以找到所有的錯誤組合;(2)錯誤定位方法找到的結果是否準確。從“查全率”和“查準率”兩方面來分析兩種組合測試錯誤定位方法在Web應用程序搜索功能測試上的有效性。在15個存在錯誤的學校類網站中,有6個網站存在IP限制和無效測試用例,以剩下的9個學校類網站為測試對象。
“查全率”是指錯誤定位方法能不能找到所有的錯誤組合。可以將定位到的FCI 轉換為約束加入到輸入模型中,重新生成測試用例,使得生成的測試用例不包含任何定位到的FCI。例如,有SUT,它的3 個參數為p1{0,1}、p2{0,1}、p3{0,1},定位得到的FCI為此時可以生成約束(約束定義方式使用ACTS[10]工具的定義標準)如下:
[Constraint]
!(p1=0&&p2=1)
!(p1=0&&p3=1)
!(p2=0&&p3=0)

兩種錯誤定位方法的“查全率”執行結果如表6所示。可以看到,在9 個被測Web 應用中,有8 個Web應用在將Method_A定位得到的FCI以約束的形式加入到模型后生成的測試用例的執行結果為全部通過,7 個Web 應用在將Method_B 定位得到的FCI以約束的形式加入到模型后生成的測試用例的執行結果為全部通過。將覆蓋強度增加到4時,其余兩個Web 應用的執行結果也全部為正確。這說明兩種定位方法可以全面地找到被測系統中的錯誤組合。
“查準率”是指定位得到的字符組合中確定會引起服務器錯誤的字符組合所占的比例。每次從定位結果中取出一個FCI,在輸入模型中加入約束,使得重新生成測試用例全都包含此FCI而不包含任何其他的FCI。例如,有,它的3個參數為p1{0,1}、p2{0,1}、p3{0,1},定位得到的FCI 為對于可以生成約束如下:
[Constraint]
(p1=0&&p2=1)
!(p1=0&&p3=1)
!(p2=0&&p3=0)
[Constraint]
(p1=0&&p3=1)
!(p1=0&&p2=1)
!(p2=0&&p3=0)
對于選中的FCI,使用這種方法重新生成的所有測試用例都將包含此FCI 且不包含任何定位到的其他FCI。如果所有的測試用例執行結果都引起服務器的錯誤響應,就認為此FCI為有效的FCI,否則是無效的。將定位得到的所有FCI 中有效的FCI 所占的比例記作“查準率”。
兩種錯誤定位方法的“查準率”執行結果如表7所示。使用Method_A 定位得到的錯誤組合的數量比較多,但平均只有7.4%的錯誤組合是有效的。使用Method_B 定位得到的錯誤組合中,平均有77.2%的錯誤組合是有效的,而且有5個網站的定位結果是100%有效的。這說明相比于Method_A,Method_B能夠更為準確地找到被測網站中的錯誤組合。

Table 6 “recall”of fault location method表6 錯誤定位方法“查全率”
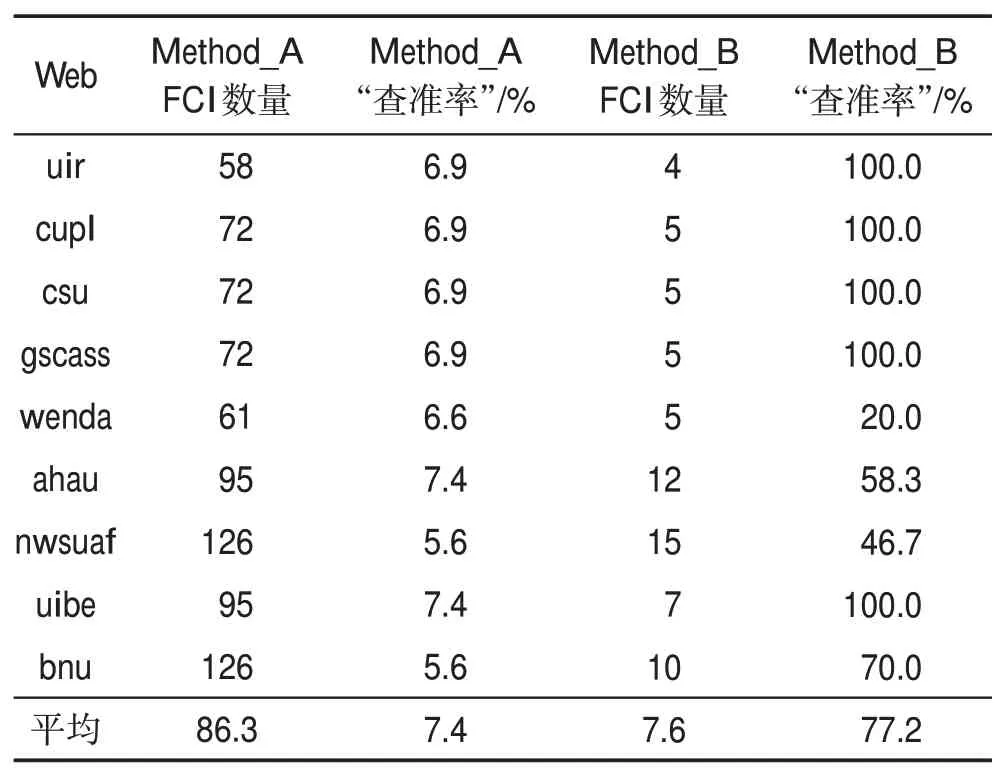
Table 7 “precision”of fault location method表7 錯誤定位方法“查準率”
同時注意到,有一些網站,它們執行相同覆蓋強度生成的測試用例的結果相同,比如csu和cupl,uibe和buct,雖然它們的前端顯示頁面不同,但后端處理程序很可能是相同的。
實驗結果表明,本文的方法實現的工具可以有效地測試Web 應用程序的搜索功能,本文的錯誤定位方法可以準確地找到出錯字符組合。但測試的方法仍有不足,有些網站可能并不會讓錯誤信息在前端瀏覽器上顯示,因此無法判斷本文的測試用例是否會引起服務器內部錯誤。開發者可以通過讀取系統日志來解決此問題。
5 相關工作
對于許多復雜的軟件系統,通常有不同的組件、選項或參數相互作用。對于這樣的系統,組合測試是一種非常有效的黑盒測試技術,它可以應用于不同的測試級別,如單元測試、集成測試和系統測試。最近,有不少研究者將這種測試方法應用到Web測試和安全測試。
使用組合測試來檢測Web應用程序的搜索功能是否存在錯誤,而Bozic 和Simos 等[12-13,17]則將組合測試以及組合測試錯誤定位的方法應用到XSS攻擊檢測上。Bozic使用不同組合強度生成的字符串測試用例對3個Web程序進行測試,結果顯示組合測試的方法十分有效。在接下來的研究中,他們將約束條件加入到組合測試模型中,能顯著提高測試用例的質量。Simos 等[17]在Bozic 的基礎上,繼續研究組合測試在XSS攻擊上的應用。他們使用組合測試錯誤定位的方法來識別XSS 誘導組合,XSS 誘導組合是輸入參數值的組合,任何包含此誘導組合的測試用例一定會在運行時成功觸發XSS漏洞。XSS誘導組合的識別有助于更好地理解XSS 漏洞的根本原因,幫助安全人員設計有效的過濾函數來避免這些漏洞。
Raunak 等[7]將組合測試的方法應用到Web 應用程序的搜索功能測試上。在國家漏洞庫(National Vulnerability Database,NVD)網站開發實現新功能后,開發人員發現某些特殊字符會導致“服務器錯誤”響應。然而,不清楚哪些特殊字符的特定組合觸發了這種響應,以及還存在多少這樣的問題。他們使用組合測試的方法生成測試用例,并用錯誤定位的方法找到出錯組合,最后發現了49個輸入會引起“服務器錯誤”響應。但是,使用該錯誤定位方法找到的字符組合中有很多是無效的。本文的錯誤定位方法將每個可疑組合轉化成測試用例執行,這樣可以更有效地找到出錯字符組合。
Qi等[18]提出了一種帶約束的成對測試(覆蓋強度為2 的組合測試)算法,稱為PTC(pairwise testing with constraints),以充分測試網站的表單交互過程。PTC算法使用組合測試生成需要提交的表單數據,并能夠通過增加約束的方式處理語義約束和非法值的問題。根據算法實現了一個原型工具ComjaxTest,它能夠系統地探索Web應用程序的狀態空間。實驗結果表明,采用PTC 算法配置的ComjaxTest 實現了動態網頁的高覆蓋率,并在一定時間內能檢測出更多的錯誤。他們的測試用例是基于表單數據生成的,目的是達到高的網頁覆蓋率,而本文的測試用例是基于搜索的關鍵字生成的,目的是為了引起更多的服務器錯誤響應。
Wang等[19]基于組合測試提出了一種新的用于檢測緩沖區溢出漏洞的黑盒測試方法。他們根據程序的外部參數生成測試用例,模擬攻擊者利用緩沖區溢出漏洞的過程來檢測漏洞。他們將這種方法應用到5個開源程序上,可以有效地檢測這些程序中的緩沖區溢出漏洞。他們利用組合測試通常能達到高代碼覆蓋率的事實,可以讓程序能夠到達攻擊點,而本文使用組合測試是因為組合測試生成的測試用例可以覆蓋更多的字符組合。
相比于組合測試,模糊測試在Web 程序安全測試方面有著更多的應用。Tripp等[20]提出一種Web應用程序安全測試工具XSS Analyzer。XSS Analyzer根據語法規則生成XSS 攻擊向量,并從未成功注入的攻擊向量中學習語法規則中的約束,即攻擊向量中不能包含哪些單詞,從而繞過Web 應用程序的檢測。XSS Analyzer定位攻擊向量中的無效元素的方法與本文方法不同,XSS Analyzer首先將攻擊向量分解成一組單詞,并將每個單詞發送到目標Web程序,確認哪些單詞是無效的。這種做法的有效性不高,無法解決多個單詞組合出現時才會無效的情況,而且將每個單詞都發送到目標Web程序會造成大量的http請求。
Appelt等[14]將機器學習和進化算法相結合,提出一種算法ML-Driven,可以繞過防火墻進而注入SQL語句。該方法可以自動生成測試用例并發送到防火墻,檢測它們是否可以成功繞過防火墻。根據測試用例的執行結果,使用機器學習的算法來選擇最有可能繞過的測試用例進行測試和變異。在實際測試中也會遇到防火墻的情況,但與ML-Driven 方法不同,本文的目的是為了能覆蓋到更多的字符組合,因此選擇生成額外的測試用例來解決這個問題。
通過構造URL并動態執行的方法來判斷該URL的執行結果,同時也可以通過分析這些URL 的特征來做出判斷。Sheykhkanloo[21]則使用深度學習的方法來判斷。他們將SQL 標簽加入到正常的URL 中,使之成為一個惡意的SQL 注入的URL,并根據這些正常的URL 和惡意的URL 訓練深度學習模型,該模型可以有效地檢測URL 為正常的或惡意的,并可以識別URL的注入類型。Rathore等[22]則提出一種基于機器學習的檢測SNS(social networking services)XSS漏洞的方法。他們在選擇特征時不只考慮到了URL的特點,同時也考慮到了生成的網頁中html 元素以及SNS特征的影響。
6 總結與展望
將組合測試的方法應用到Web應用程序的搜索功能,并結合搜索功能測試的特點,提出一種組合測試錯誤定位方法來找到具體是哪些特殊字符的組合會引起系統錯誤。實現了一個原型工具,并對學校、政府類和事業單位的96 個網站進行了測試,其中23個網站在搜索某些特殊字符組合時,會引起服務器錯誤響應。錯誤定位的結果表明,56%的服務器錯誤響應是由“%”“<”“’”“”和其他字符的組合引起的。實驗結果表明,本文的方法可以有效地測試Web 應用程序的搜索功能,該錯誤定位方法可以準確地找到出錯字符組合。
未來工作中,主要考慮兩方面的工作:一是完成一個Web 應用程序輸入參數的自動化的測試工具,并將其應用到更多的網站測試中;二是把組合測試應用在Web應用程序安全測試上。搜索功能存在錯誤的網站有很大可能存在可注入代碼的漏洞。組合測試的方法可以生成高質量的測試用例來測試這些Web應用程序的安全問題。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
