基于統計矢量的多傳感器精度估計方法?
2019-11-12 06:38:32李立英陳世友
計算機與數字工程 2019年10期
李立英 陳世友
(武漢數字工程研究所 武漢 430205)
1 引言
在信息化的推動下,面向復雜應用背景的多傳感器數據融合系統應運而生,并作為一個新興學科迅速發展起來。多傳感器數據融合過程中,很多數據合成算法以目標數據的精度信息為依據確定各傳感器目標數據合成的權重[1],因此,準確掌握傳感器的探測精度至關重要。通常情況下,數據融合系統使用傳感器的標稱精度代替實際探測精度。但傳感器的實際探測精度易受環境影響,往往與標稱精度差別較大。在沒有目標真值或者更高精度測量值的情況下,傳感器很難根據自身探測信息準確評估其探測精度。如果在作戰系統中存在精度嚴重喪失的傳感器,而又不能獲取傳感器對目標的實際探測精度,將對整個數據融合系統的目標相關正確率和數據融合精度等造成嚴重影響[2]。
為了解決傳感器實際工作精度未知或未確知的問題,學者們提出了許多方法。當無高精度探測值可用時,黃友澎將各傳感器輸出數據的中心點即均值作為真值的參考點,輸出數據與參考點的偏差看作測量誤差,利用極大似然估計方法估計方差[3],計算簡單,易于實現,但當傳感器數目較少時,把中心點作為真值參考點可信度不高。另一類常用的估計傳感器精度的方法是濾波算法,其中,較為經典的是基于小波變換的濾波算法和自適應卡爾曼濾波方法。Lijun Xu 根據Weierstrass 逼近定理,用低階多項式擬合長度為L 的區間內的觀測序列,并對其進行小波變換分離噪聲,從而得到噪聲的標準差[4],但估計結果的好壞受窗長L 的影響比較大。Mehra 把自適應卡爾曼方法概括為貝葉斯估計法、極大似然估計法、相關法及協方差匹配法四類[5]。貝葉斯法和極大似然法計算效率低下,且估計結果與未知噪聲協方差的先驗設定范圍有關;相關法和協方差匹配法都是對量測噪聲協方差和狀態噪聲協方差進行分步估計,增大了二者的耦合性,從而造成估計結果精度不高。Odelson 提出了自協方差最小二乘估計算法,構造基于新息的狀態空間模型,建立新息序列自相關函數矩陣與兩噪聲協方差矩陣之間的函數關系,用最小二乘法同時估計觀測噪聲和狀態噪聲的協方差[6],估計精度得到提升,但解算過程復雜。基于統計理論,Lou R C 提出了通過定義置信概率距離來構造衡量傳感器間觀測數據一致性的距離矩陣及關系矩陣,在線確定數據融合的加權系數[7](與傳感器的測量精度正比例相關),類似地,還有后續提出的采用支持度[8]、模糊量貼近度[9]、一致性測度[10]等概念反映觀測數據一致性的方法,易于理解和實現,但只能得到精度的相對值。譚秋玥等提出利用多傳感器對共同目標探測信息的內在冗余性,通過構造觀測方程來估計各傳感器的探測精度[11],該方法理論依據明確,計算方法簡單,但在多平臺下,傳感器間的相互運動使協方差無法看作常量而帶來較大誤差。
本文基于統計理論和隨機優化方法,提出在多平臺多傳感器系統中,沒有目標狀態真值或高精度狀態信息可供利用的情況下,依靠多傳感器對共同目標探測信息的內在冗余性,構造統計矢量,并根據統計矢量的統計特性確定目標函數,通過遺傳算法對傳感器的探測精度進行實時估計,理論依據充分,估計誤差較小,適用性較強。
2 基本原理
2.1 系統模型描述
假設有兩部傳感器SA、SB(以二維雷達為例)分別對被測量目標Tk進行獨立測量,將其投影到同一公共的二維直角坐標系中,如圖1所示。
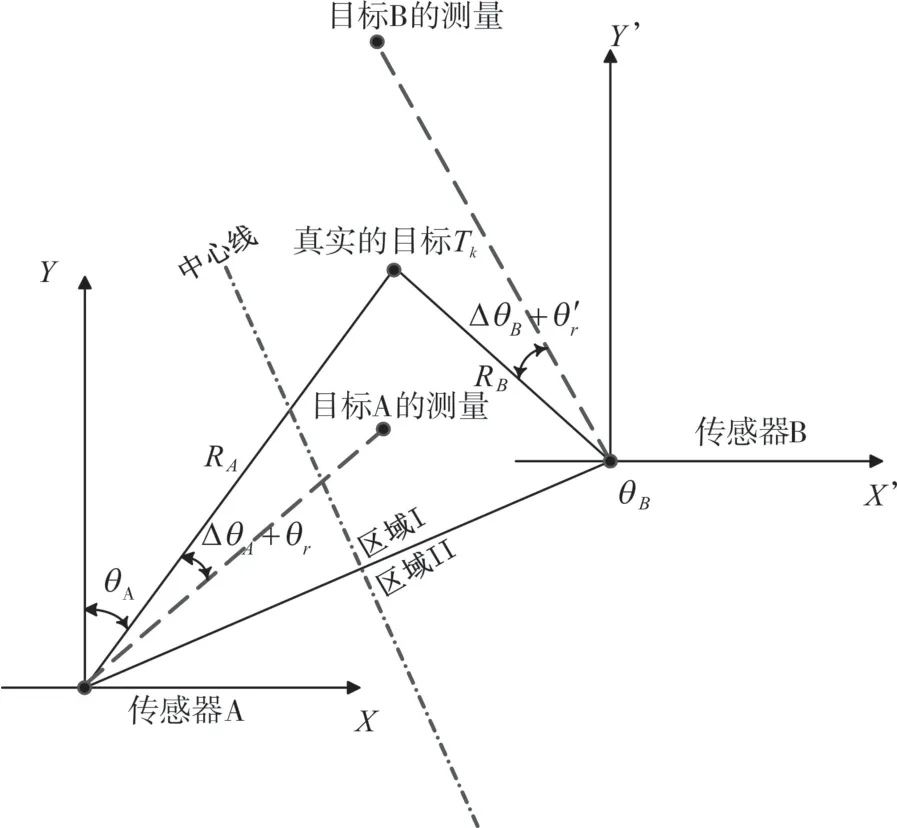
圖1 二維雷達對共同目標的測量DθB+θ′r
設兩傳感器在公共坐標系下的坐標分為(xSA,ySA)和(xSB,ySB)。在分別以兩傳感器為坐標原點的局部坐標系中,(RA,θA)和(RB,θB)表示目標Tk距兩傳感器的真實距離和方位。兩傳感器對目標Tk進行測量,得到的觀測誤差有兩個成分:距離誤差和方位誤差,即β=[DRA,DRB,DθA,DθB]'。假設其測量誤差序列均為零均值高斯平穩隨機序列,方差分別為D(DRA) 、D(DRB) 、D(DθA) 、D(DθB) 。(xA',yA')和(xB',yB')表示目標Tk在兩傳感器局部坐標系下的量測,由傳感器測量的距離和方位值轉換求得,轉換關系如下(以傳感器A為例):
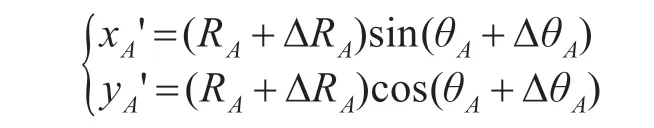
因為DRA、DθA是微量,若忽略二階微量式,則上式可簡化為
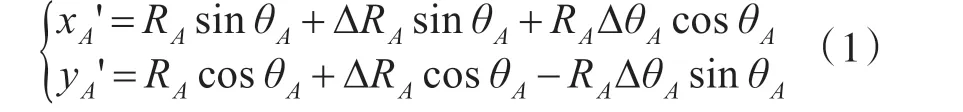
令(xA,yA)和(xB,yB)表示兩部雷達對目標Tk在公共坐標系下的量測坐標,則觀測誤差矩陣為
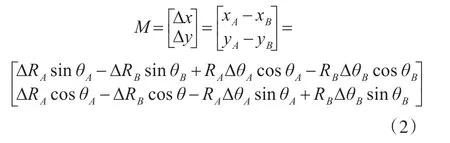
此時,M的誤差協方差矩陣為
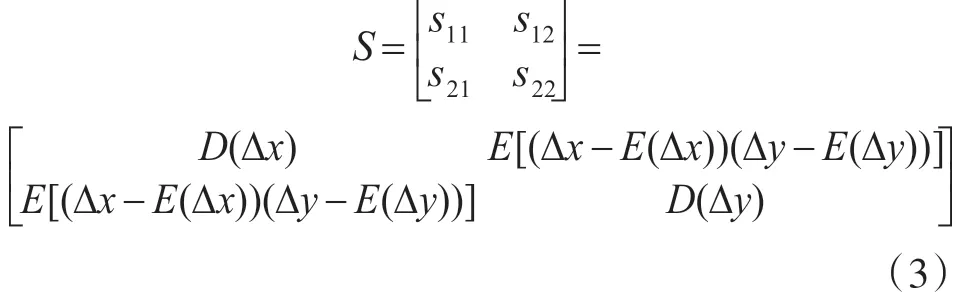
2.2 統計矢量的正態性
在多源數據的相關判別中,常常依據歸一化統計距離的統計特性,來判斷點跡是否落入關聯門中。本文利用了相近的原理,將統計距離進一步分解為統計矢量,將統計矢量的統計特性作為優化準則。假設空間和時間校準后,兩個觀測點跡的歸一化統計距離[12]為
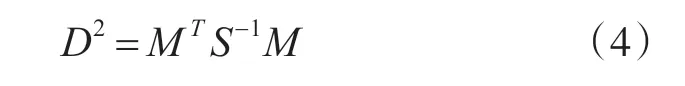
其中,M 為上述式(2)中的觀測誤差矩陣,S 為式(3)表示的誤差協方差矩陣,則S的逆為
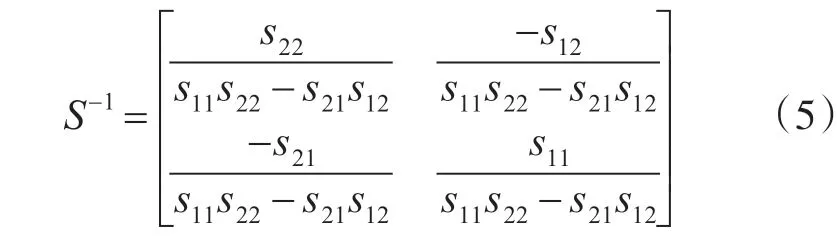
根 據cholesky 分 解 定 理[13],S-1可 分 解 為S-1=WTW ,則可定義統計矢量為
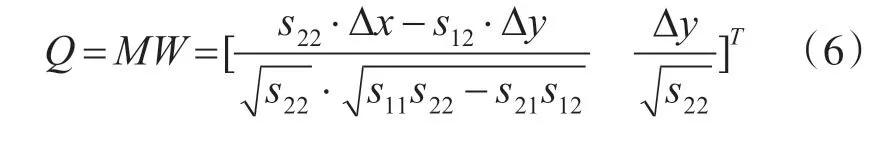
對Q 的兩個分量分別進行分析。令z=s22?Dx-s12?Dy ,可 推 導 出z 的 期 望E(z) =0 ,方 差。 故, 因 為, 所 以,符合標準正態分布。同理,,符合標準正態分布。
可見,在準確掌握傳感器精度參數的情況下,即協方差矩陣S 的取值與傳感器的精度一致的情況下,統計矢量Q 的兩分量均符合標準正態分布,與目標、傳感器的相對位置、相對運動無關。反之,若S 與傳感器精度不一致,當目標的相對位置發生變化,統計矢量Q 一般不再服從標準正態分布,這為估計傳感器精度參數提供了線索。
2.3 正態性檢驗的方法
由于統計矢量的兩分量均符合標準正態分布,可分別對其產生的數據進行一維的Kolmogrov-Smirnov檢驗[14](簡稱K-S檢驗)。
若總體的分布函數G(x)未知,但有樣本觀測值(x1,x2,…,xn) ,把它按由小到大的順序排列成x(1)≤x(2)≤…x(n),得到經驗分布函數:
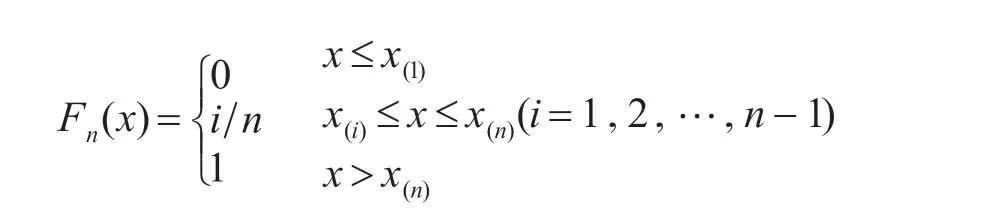
根據Dilvenko 定理,當n 很大時,Fn(x)是G(x)的良好近似。經驗分布函數檢驗法的原理是先假設總體服從某一特定的分布G(x)(此處應為標準正態分布),再根據樣本數據得出其經驗分布函數Fn(x),通過計算經驗分布函數與總體分布函數的偏差的某種形式來確定原假設是否成立。
假設:原假設為H0:Fn(x)=G(x),備擇假設為H1:Fn(x)≠G(x);
統計量為Dn=sup|Fn(x)-G(x)|,sup 表示上確界,或者集合的最大值。該統計量表示兩個分布函數之差的最大值。對于大小為n 的單個樣本,以及給定的顯著性水平α,根據Dn的極限分布(n →∞時的分布)確定統計量關于是否接受零假設的數量界限。K-S檢驗一般在大樣本檢測中準確率更高。
可見,在多平臺、不掌握被測量目標真值的情況下,統計矢量的正態性可作為評判準則來對參數進行估計。由于正態性的檢驗使用的是適于大樣本的K-S 檢驗,所以樣本數量越多,得到的結果越可靠。
3 多傳感器精度估計方法
以統計矢量的統計特性作為評估準則,多傳感器的精度估計可轉化為優化過程。最優化問題[15]可用下述數學規劃的方式來表述:
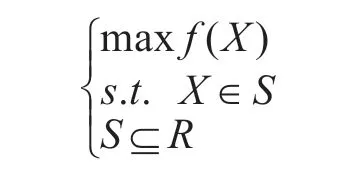
式中,X=[x1,x2,…,xn]T為決策變量,f(X)為目標函數,R 是基本空間,S 是R 的一個子集,它表示由所有滿足約束條件的解所組成的集合——可行解集。本文選取被廣泛應用的遺傳算法來估計傳感器精度。
遺傳算法模擬生物的進化過程,基本思想就是通過選擇、交叉、變異得到下一代群體,不斷重復,直到獲得滿意解或者最優解。核心是使適應度高的個體具有較大的概率被選擇留在下一代,進行交叉、變異等操作,保持優秀個體的優越性,從而收斂至最優解[16]。當遺傳算法應用到傳感器精度估計時,流程如圖2所示。
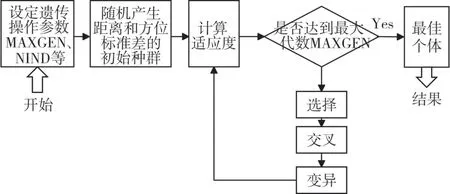
圖2 遺傳算法流程圖
其中,適應度函數的構造十分重要。以兩部二維傳感器為例,估計參數為兩部傳感器的距離精度和方位精度D(DRA) 、D(DRB) 、D(DθA) 、D(DθB) ,共4 個。將章節2.1 中的式(2)代入式(3),可得協方差矩陣的各元素與估計參數間的關系:
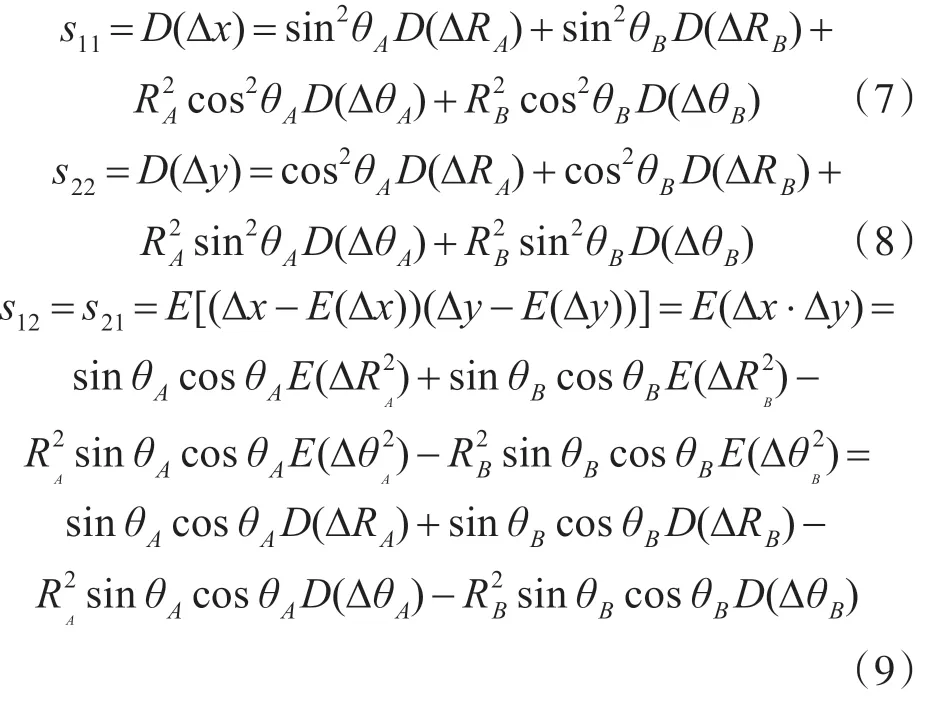
將關系式(7)、(8)和(9)代入式(6),可得該時刻的統計矢量。多個時刻的統計矢量形成樣本序列,對其進行顯著性水平為α 的K-S 檢驗,得到統計量D 對應的p 值[12]。p 的取值范圍為[0,1],當p <α,則樣本的總體不服從標準正態分布,拒絕零假設;當p >α,則樣本的總體服從正態分布,不拒絕零假設。所以,適應度函數Fit(x)應與obj(X)=p-α 的大小成正比。同時考慮個體適應度的非負性要求,Fit(x)具體設計為
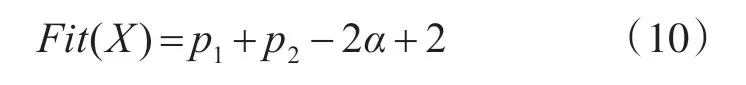
在遺傳算法中,適應度較高的個體遺傳到下一代的概率較大;而適應度較低的個體遺傳到下一代的概率就相對小一些。
4 仿真實驗
在兩個平臺上分別配置一部雷達,雷達的初始位置分別為(-21,21)、(21,-21),單位為km。兩雷達均做勻速直線運動,速度分別為(18m/s,13m/s)、(22m/s,-15m/s)。兩雷達距離探測的標準差分別為95m、80m,方位探測的標準差分別為0.35h(弧度表示為0.0061rad)、0.3h(弧度表示為0.0052rad)。在共同探測區域內,有1 個目標,初始位置為(0,60),單位為km,同樣做勻速直線運動,速度為(16m/s,-25m/s)。雷達的探測時間間隔取2s。
用遺傳算法進行參數估計,遺傳算法的初始種群數設為100,迭代次數設為50。時間周期設為1000時的進化過程如圖3所示,得到的估計值如表1 所示。可見,所得結果精度較高,相對誤差均在10%以內,最小相對誤差甚至達到1.6%,最大相對誤差為6.5%,除去最大相對誤差,其他3 個參數的相對估計值在5%以內。
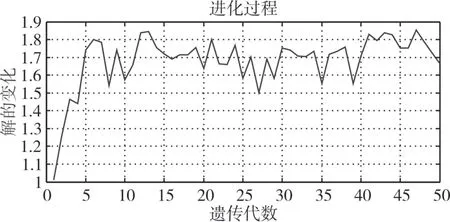
圖3 周期為1000時的進化過程
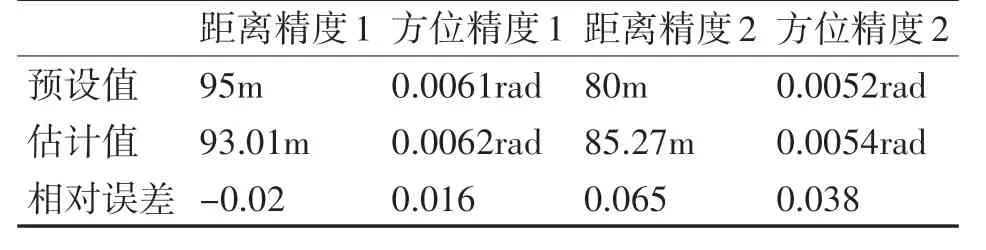
表1 運行1次的距離精度及方位精度估計結果
為了驗證數據量對精度估計結果的影響,比較目標的測量周期分別取10、100、500、1000 時,500次傳感器精度估計仿真實驗的統計結果。由于估計的參數較多,以傳感器2 的方位標準差的估計值的統計圖為例進行闡述。傳感器2 的方位標準差預設值為0.3h,也可表示為0.0052rad。圖4、5、6、7分別顯示的是測量周期取10、100、500 和1000 時,500 次仿真實驗中傳感器2的方位標準差的估計值的統計圖,其中,曲線為按正態分布擬合出的曲線。表2 為測量周期分別取10、100、500 和1000時,500次估計值的統計特征的比較。
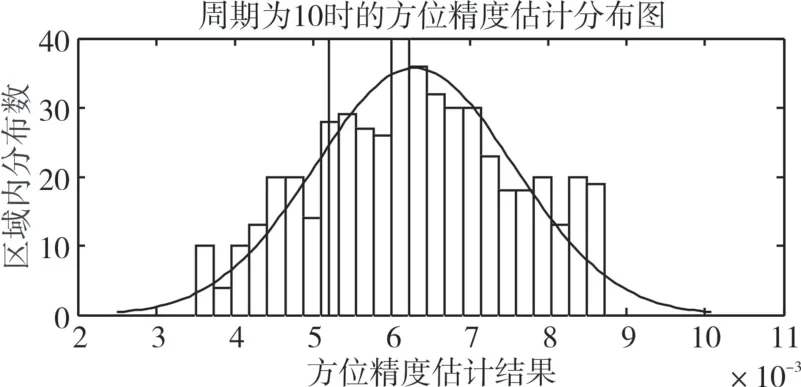
圖4 周期為10,傳感器2的方位標準差的估計值的統計
可見,論文提出的方法能夠估計多平臺情況下多傳感器的探測精度,估計值是隨機變化的。而且,隨著數據量的增多,估計值越接近零均值、正態分布的隨機變量,估計值的方差也越來越小。而且,估計值的相對誤差范圍也隨著周期增大而逐漸減小,當數據量達到1000 時,估計值的相對誤差范圍在10%以內。
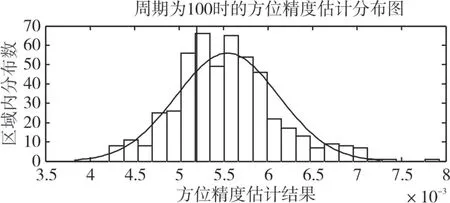
圖5 周期為100,傳感器2的方位標準差的估計值的統計圖
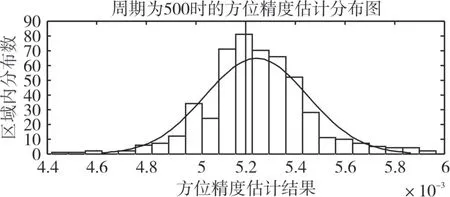
圖6 周期為500,傳感器2的方位標準差的估計值的統計圖
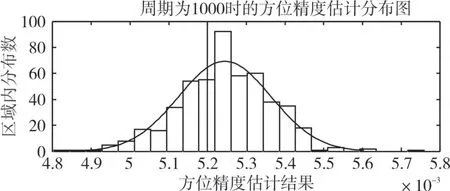
圖7 周期為1000,傳感器2的方位標準差的估計值的統計圖
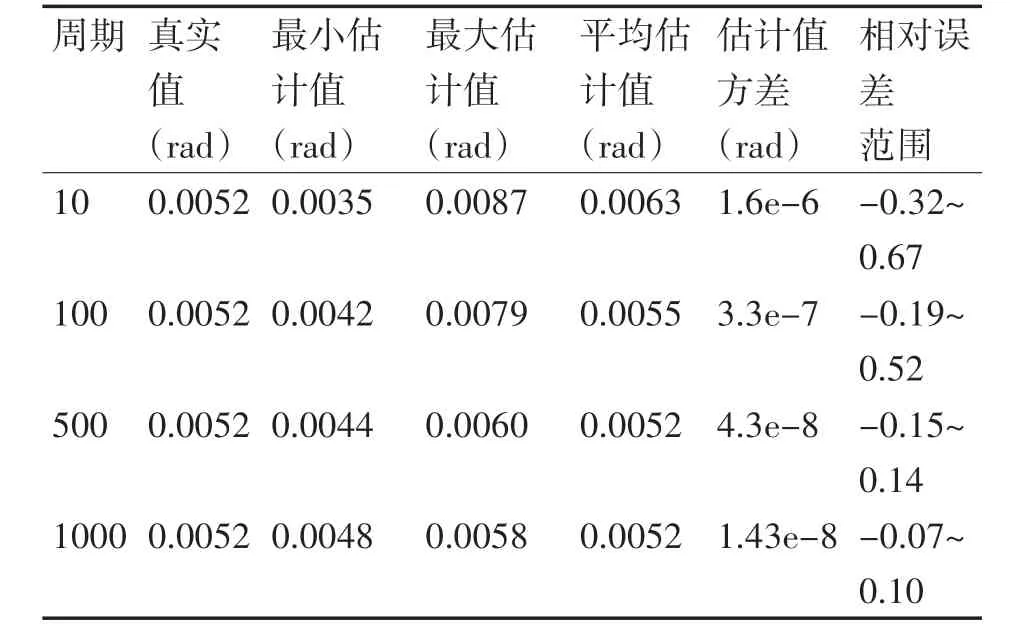
表2 500次運行結果的統計特征
5 結語
在多平臺的多傳感器數據融合系統中,能夠在目標位置真值未知的情況下,利用多傳感器對共同目標測量信息的冗余性,構造出符合標準正態分布的統計矢量,并將其統計特性作為評估準則,采用遺傳算法進行優化,估計出各傳感器的工作精度。本文給出的傳感器精度的估計方法,主要受正態性檢驗方法的影響。當使用K-S檢驗時,傳感器對目標測量數據的數量越大,傳感器精度的估計值的精度越高。當相對運動的兩傳感器對共同目標進行探測,數據量達到1000 時,估計值相對誤差的范圍穩定在10%以內。
