基于識別和多重分類的反洗錢系統
2019-11-09 06:51:24張桂剛
小型微型計算機系統 2019年10期
肖 琨,王 云,張桂剛
1(湖北經濟學院 信息與通信工程學院,武漢 430205) 2(中國科學院自動化研究所,北京 100190)E-mail:guigang.zhang@ia.ac.cn
1 引 言
洗錢(ML)是指通過商業銀行、投資銀行、保險公司等金融機構,對黑錢的來源和性質進行偽裝和清洗,使非法所得合法化的行為.幾十年來,洗錢幾乎對所有國家都構成嚴重的危害.這不僅是因為洗錢涉及的金額巨大,可能嚴重破壞一個國家的金融體系,并且助長了其他類型犯罪的發生.而且還因為其結構復雜、發展迅速,使得檢測工作很難進行.幸運的是,人工智能技術的發展為提高反洗錢檢測系統的效率提供了機會,并且可以及時發現新出現的反洗錢模式和交易規則,從而應對這些威脅.
反洗錢一般分為三個階段:預防階段、檢測與報告階段和處罰階段.預防策略包括對反洗錢的公眾教育、開戶和交易所需的綜合信息、頒布諸如《金融機構反洗錢條例》等法律.檢測與報告是指利用人工智能和數據挖掘技術對可疑的金融交易進行檢測,這也是本文研究的重點.處罰階段是指對被偵查出來的洗錢犯罪分子的經濟和刑事處罰.
對于檢測與報告部分,一般通過在線監測系統進行可疑檢測,之后發送有關目標群體的報告,以便分析員進一步調查和判斷.目前對反洗錢可疑行為檢測的研究主要集中在開發算法上,以便將潛在的非法交易與合法交易區分開來.但就目前而言,開發一個能夠識別非法交易的系統,為分析人員提供可靠的參考,可在一定程度上降低勞動成本,并且有利于反洗錢工作的發展.該系統能根據交易模式的特征,對非法交易行為與哪種犯罪有著可靠的預測.這也是本文主要的研究目的.
2 相關工作
信息技術在反洗錢工作中的應用最早提出于20世紀90年代.[1]中詳細介紹了FAI(FinCEN美國金融犯罪執法網絡的人工智能系統),該系統采用基于規則的方法對各類金融業務進行評估,以識別反洗錢和其他犯罪行為.這些規則主要是通過專家的知識和經驗來設定的,這使得它的準確性高,缺點是它不足以匹配快速發展的洗錢方法.因此在此基礎上,通過進一步研究提出了改進的檢測系統,提高了檢測系統的精度、自動化程度、靈活性等.例如,[2]提出了一種基于支持向量機(SVM)的檢測算法,代替了預先設定的規則,其結果表明該算法降低了誤報率.
檢測系統的改進是通過兩種方式來實現的.第一種是開發先進的算法,以便根據客戶的個人信息更好地分析客戶情況.例如,[3]提出了一種用于洗錢的決策樹方法,其結果證明了該模型的有效性.該方法的是基于從企業客戶檔案中提取的四個屬性(行業、位置、業務規模和客戶購買的產品)來實現的.[4]提出基于每個銀行賬戶的交易行為,建立一個多維自適應概率矩陣,并根據每個銀行賬戶自身的行為模式進行判斷.但由于突發性并不等于可疑性或違法性,該系統對AML的檢測并不總是有所幫助.[5]引入小波分析(Haar 以及 bior3.7),根據交易的時間和數量序列來衡量客戶的可疑程度.
另一種方式主要在團體規模上改進異常檢測算法.該方法確實提供了有用的信息,因為ML操作總是涉及三個以上賬戶.[6]介紹了聯系分析的概念,這意味著要找到個人之間的關系,并將他們分為不同的群體,以便于調查.進行分類的方法稱為聚類,包括BIRCH[7,8],k-means[9],GDBSCAN[10,11]介紹了使用(半)超監視和無監督方法進行基于圖的異常檢測的詳細和結構化知識.此外,還有一些其它的方法直接應用在AML.[12]針對洗錢犯罪開發了一種新的解決方案“CORAL for LDCA”(基于相關性分析的鏈路發現).[13]提出了CELOF算法(基于聚類的局部異常因子),取得了較好的效果.[14]對ML檢測領域中應用的典型聚類算法進行了全面總結.另外一些算法也很有效.[15]采用near-k-step neighborhoods方法進行網絡分析.[16]提出了使用從用戶專業文件和自適應模糊系統中提取的特征.[17]引入了SARDBN,它是聚類和DBN的組合.[18]用于為合法和非法比特幣交易用戶建立社區.此外,今年還出現了一些新的工具.例如,[19]指出自然語言處理(NLP)在新聞文章、社交媒體等各種信息來源上的有效性,其所提取的信息有助于AML減少30%的調查時間和成本.[20]對檢測方法進行了綜述,驗證了可伸縮圖卷積神經網絡的有效性.
3 研究框架
由于目前我國90%以上的洗錢[21,22]活動和涉案金額都是通過金融機構,特別是商業銀行,已經成為反洗錢的主要戰場,因此銀行賬戶之間的交易是該研究的重點.準備工作包括兩個部分:根據交易過程中顯示的不同特征對犯罪進行分類,以及從第一手資料中提取特征.然后基于結合的特征數據,開發了兩個模型.一個是可疑交易監控模型.另一個模型經過培訓,以確定每一條欺詐(或被認定為欺詐)交易信息所涉及的最接近的犯罪類型.模型均在監督學習下訓練,并經歷了技術的變化.最后,將這兩個模型串聯起來,對可疑行為進行檢測和分類,并對其性能進行了測試.
4 反洗錢算法
反洗錢系統的算法如圖1所示.需要注意的一點是,單獨使用模型2評估其性能時,數據A的80%用于訓練,其余的20%用于測試.
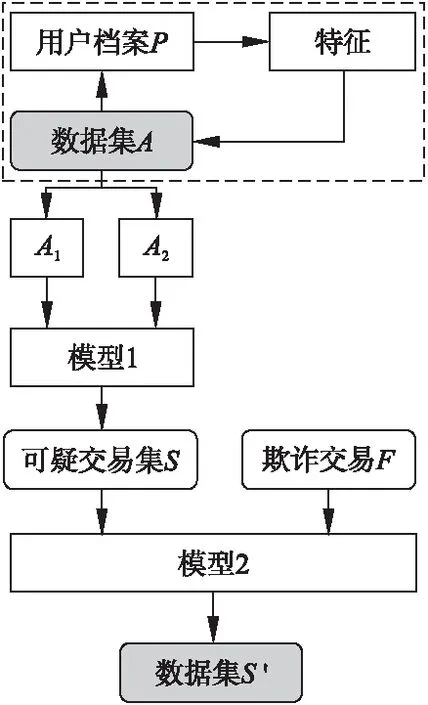
圖1 反洗錢系統流程圖Fig.1 Flow chart of AML system
系統算法架構:
輸入:交易信息數據集A,所有欺詐交易數據集F;
輸出:S′,A的測試集A2上可疑交易的識別和犯罪類別的分類;
步驟:
1.基于數據集A創建用戶檔案P;
2.從P中提取關于每個事務的發起者和接收者的附加特征,并將它們添加到原始數據集A中;
3.將A分為訓練組A1(80%)和測試組A2(20%);
4.在模型1上分別采用邏輯回歸,多層感知和梯度增強等方法對A1進行訓練,并在A2上進行測試,獲得可疑交易集S;
5.在F-S上訓練模型2并在S上進行測試,獲得標有相關犯罪類別的可疑交易集S′;
6.返回S′.
5 實驗準備
5.1 樣本數據
出于隱私保護,公共可用數據集的缺乏在金融服務中很常見,特別是在貨幣交易領域.幸運的是,為了模擬事務的正常運行,目前有幾種基于真實數據生成合成數據集的模擬器.在本文采用了Paysim模擬器創建的貨幣交易數據.它所依賴的樣本是從一家跨國公司提供的非洲國家的一個月財務日志中提取的真實交易.為了使它更真實可靠,改進了一些數據.財務日志中提取的真實交易.為了使它更真實可靠,改進了一些數據.
5.2 犯罪分類
洗錢與販毒、走私、恐怖主義、腐敗等其他有組織犯罪有著密切的關系.根據他們的交易性質,罪行分為五類,如表1所示.當對第二種模型進行訓練時,分類結果將起到標簽的作用.

表1 與洗錢有關的五大類犯罪Table 1 Five main categories of crimes related with money laundering
5.3 特征收集
第一手交易數據的特征包括每筆交易的簡單信息,如表2所示.對于現實商業銀行信息存儲的真實模式,為了提取更有用的潛在數據并提高模型訓練的準確性,基于交易信息建立了用戶檔案,如表3所示.
用戶檔案文件有助于提取客戶的特征.除了個別參與方,網絡效應可能是反洗錢檢測的一個重要因素,因為交易總是發生在網絡上.擁有非零cheat_time的個體更有可能進行另一筆欺詐交易,而與擁有非零cheat_time有聯系的個體也會產生懷疑,但交易邊緣等因素削弱了犯罪的可能性.為了量化地度量這種效果,我們應用了一個名為suspic_cheat的變量,并如公式(1)計算.

表2 第一手數據的特征Table 2 Features for the first-hand data

表3 用戶檔案樣本Table 3 User profile example
對于給定客戶a與交易對象[b1,b2,…,bn],n具有非零cheat_time,并且每個bi具有交易對象[a,c1,c2,…,cni],(ni+1)具有非零cheat_time,suspic_cheat如公式(1)所示:
suspic_cheat= 2×m+ 1 × Σmi
(1)
特征suspic_cheat_org和suspic_cheat_dest代表一個事務中兩個帳戶的suspic_cheat.下面列出了從用戶配置文件派生的其他特征:
frequency_org:交易的頻率,計算為開始交易的客戶的交易總次數.
frequency_dest:交易頻率,計算為作為交易接收方的客戶的交易總次數.
part_num_org:開始交易的人的貿易伙伴數量.
part_num_dest:接收交易的人員的貿易伙伴數量.
Prct_org:計算為金額除以old_balance_org.
Prct_dest:計算為金額除以new_balance_dest.
在舊特征和新特征相結合之后,交易的最終版本的特征包括:type,amount,old_balance_org,new_balance_dest,is_foreign,suspic_cheat_org,suspic_cheat_dest,frequency_org,frequency_dest,part_num_org,part_num_dest,prct_org,prct_dest和標簽:is_fruad(用于ML檢測模型),fraud_catg(用于ML分類模型).
6 可疑交易監控模型
6.1 訓練模型
由于金融體系日益復雜,金融衍生品層出不窮,洗錢手段正在迅速發生變化.因此,高水平的檢測模型將受益于其靈活性.本文采用了三種監督學習模型:邏輯回歸(LR)、多層感知(MLP)、梯度增強(GB).
被用于訓練和測試的交易信息有168,599條,其中涉及洗錢的1047條.本文將其中80%的樣本用于訓練,20%的樣本進行測試.為了對模型性能進行魯棒性評估,采用k-fold cross validation,其中k=10.指標包括混淆矩陣、準確率、召回率、F1和AUC.
樣本類別(0:167552,1:1047)的不對稱性是反洗錢研究的一個常見問題,如果處理不當會降低模型的準確性.LR最容易受到這里采用的三種算法之間的不平衡的影響.如果沒有采取補救措施,那么將趨向于將所有類別歸類為類別0以最小化損失函數.為了克服這一問題,人們開發了幾種方法,如過度抽樣、抽樣不足、重量變化等.本文應用第三種方法,即調整損失函數中正樣本和負樣本的權重,以平衡兩類樣本.結果表明這是有效的.
6.2 結果以及評估
測試集的混淆矩陣如表4-表6所示.精確率,召回率,F1,cross validation scores和AUC如表7所示.圖2顯示了使用LR預測的欺詐概率.
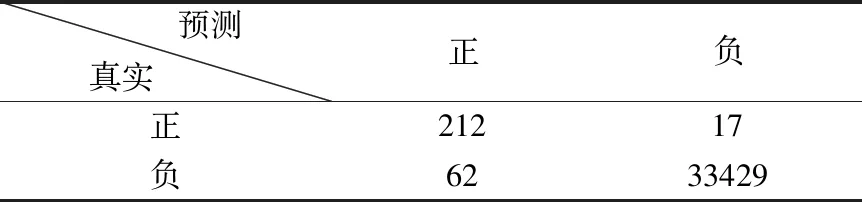
表4 邏輯回歸模型的混淆矩陣Table 4 Confusion matrix for logistic regression model
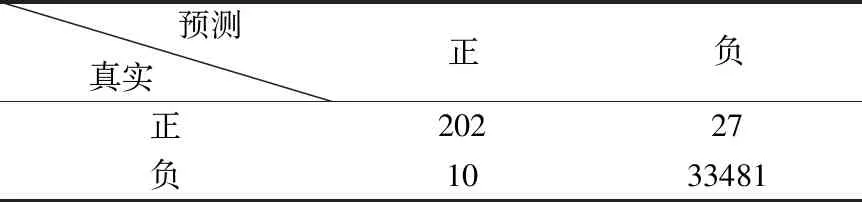
表5 MLP模型的混淆矩陣Table 5 Confusion matrix for MLP model
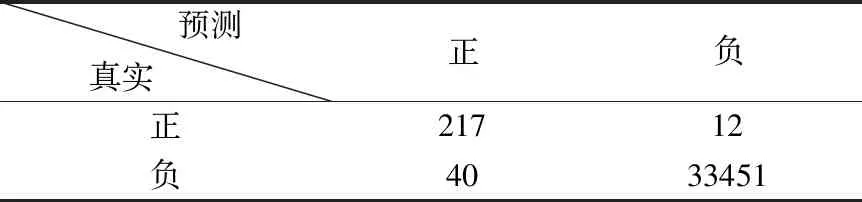
表6 梯度增強模型的混淆矩陣Table 6 Confusion matrix for gradient boosting model

圖2 使用LR預測欺詐概率Fig.2 Predicted probability of fraud using LR
三種型號的主要參數如下:
LR:C=50,class_weight={0:0.06,1:0.94},solver=′liblinear′,penalty=′l1′.
MLP:activation=′relu′,max_iter=200,hidden_layer_size=(50,).
GB:max_depth=2,n_estimator=100.
上述結果表明,該模型在訓練數據集和測試數據集上都具有良好的功能,基本上適用于實際應用.在參數優化過程中,目標設定為最大化F1分數.但在實際情況下可能會發生變化.在大多數情況下,在線監控系統判斷并鎖定目標群體之后,人工分析師將根據他們的經驗進行進一步調查.通過表7對3種算法的性能對比,可以發現MLP算法的精確率高于LR以及GB.其Train和Test數據集的精確率分別達到了93.90%和95.28%.并且MLP在F1值,Cross validation score,以及AUC的表現均優于其它兩個算法.綜合以上分析,MLP應被選作模型一的算法.
7 多分類模型
7.1 單模型訓練
為了使該系統更有效和實用,進行了進一步的研究.
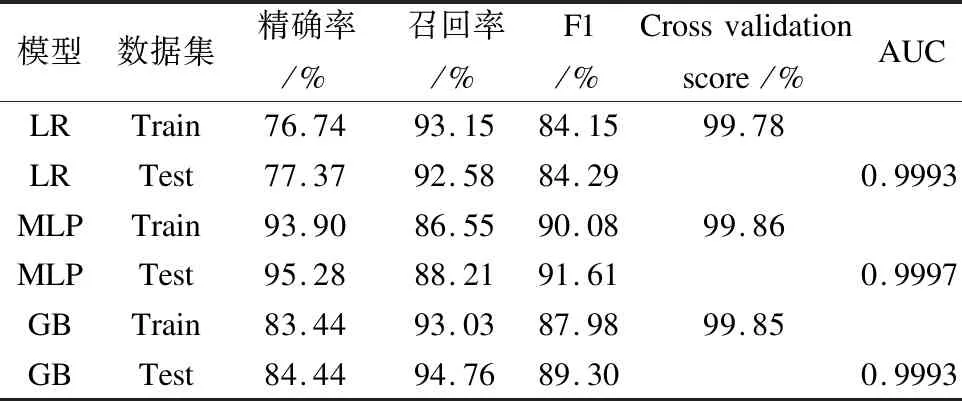
表7 性能指標Table 7 Performance indicators
建立了第二個模型來預測欺詐交易的最可能犯罪類別.用于模型訓練的特征與可疑檢測模型部分相同,標簽改為fraud_catg.
對于多分類,這里使用了另外三種有監督的學習技術:支持向量機(SVM)、LR和MLP.培訓和測試過程中使用了1047項欺詐交易.其中80%用于訓練集,20%用于測試集.第1,2,3,4,5類犯罪的數量分別為302,214,282,203和46.指標包括混淆矩陣,精確率,召回率和F1.
混淆矩陣如等式(2)-式(4)所示.精確率,召回率,F1見表8.
(2)
(3)
(4)
三種型號的主要參數如下:
SVM:kernel=′rbf′,decision_function_shape=′ovo′,C=100.
LR:C=100,multi_class=′multinomial′,solver=′sag′.
MLP:activation=′relu′,max_iter=500,hidden_layer_size=(100,).
該模型在訓練和測試數據集上表現良好.研究結果表明,犯罪分類對于模型訓練是合理可行的,并且是反洗錢系統研究多分類問題的良好開端.由表8性能指標分析可得出,MLP在精確率、召回率和F1的性能表現優于SVM以及LR.因此,模型二選用MLP為多分類算法.目前的一個局限是,隨著經濟和犯罪技術的發展,為了保持對犯罪類型預測的良好準確性,對犯罪類型的分類應該經常變化.
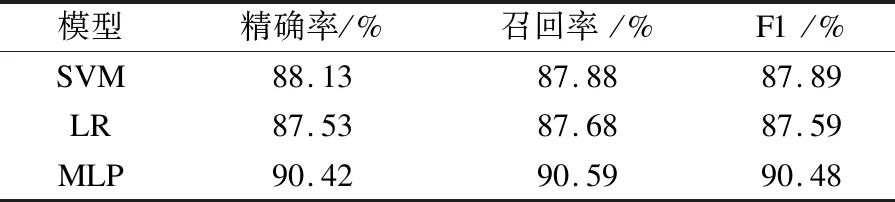
表8 性能指標Table 8 Performance indicators
7.2 串聯模型
在分別評估了兩種模型的精度后,我們對模型的性能進行了串聯測試.圖3顯示了系統的概述.在提取和結合特征之后,模型1用于從測試集鎖定可疑交易集S.然后,在欺詐交易集F上訓練模型2(這里排除已經由模型1檢測到的欺詐交易,以使模型2的預測更有說服力).然后利用模型2對集合S上的犯罪類型進行分類,最后將結果報告給情報分析人員,以便進一步調查和判斷.
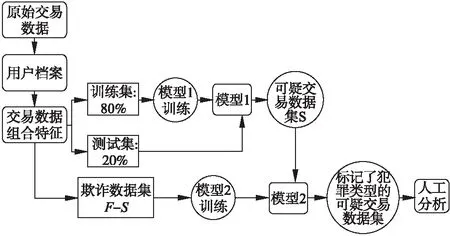
圖3 系統運行框架Fig.3 System framework
基于對模型一以及模型二的單獨分析,應用MLP來訓練模型1和2的系列.每個模型的主要參數如下.
模型1:MLP:activation=′tanh′,max_iter=200,hidden_layer_size=(100,).
模型 2:MLP:activation=′tanh′,max_iter=500,hidden_layer_size=(200,).
混淆矩陣如等式(5)所示.召回率為78.61%,準確率為74.63%,F1為76.56%.
(5)
結果表明,性能比較滿意,雖然這兩種模型單獨使用時效果都不理想(只有對詐騙罪的判斷和對犯罪的分類同時正確時,預測才是正確的,這是一個更嚴格的要求),它仍然為實際應用和未來研究具有積極的意義.
8 結論和未來的工作
本文采用監督學習的方法,建立了一個基于交易數據的洗錢檢測和犯罪類別分類兩種模型的系統.結果表明,每個模型對于樣本數據都非常有用,并且對不同的訓練方法表現出良好的魯棒性.當模型組合在一起時,可以為手工檢查提供有價值的參考.用戶可以根據不同的用途選擇使用哪種模型(或兩者),但在實踐中需要對提取的數據特征和模型參數進行微調.本文的不足之處在于缺乏真實的多維數據.考慮到信息研究需求的高度隱私性,這是該領域的一個很難解決的問題.然而,添加客戶信息(如性別,年齡,工作,位置)的模擬數據是可能的,而且會有很大的貢獻.另一個局限性是缺乏對各種因素的評估.例如,可疑水平與個體的時間和數量序列有關,這些交易可以借助于小波分析進行測量.同時,未來應考慮無監督學習(例如聚類).此外,如何提取適當的特征部分依賴于人類對ML過程的經驗和理解,并且在一定程度上顯著影響最終結果.就研究的局限性而言,需要進一步的工作來改進系統的算法和穩健性.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
