基于融合信息技術的圖書館數字資源運行監測平臺的設計
2019-11-02 01:44:48喻志娟
邵陽學院學報(社會科學版) 2019年5期
喻志娟, 張 穎, 徐 瓊
(長沙理工大學 圖書館, 湖南 長沙 410114)
隨著計算機技術、網絡技術的發展,數字資源已成為文獻信息的主要表現形式。在圖書館界,數字資源取代傳統紙質文獻成為圖書館文獻資源檢測建設最重要的組成部分。與此同時,數字資源購置費用在圖書館資源購置總經費中所占比例逐年攀升。高校圖書館正向著數字化、智慧化方向轉型發展。因此,無論是采購新的數字資源,還是續訂、維護已有的數字資源,都面臨著一系列新的問題:怎樣對數字資源進行采購前的遴選以及使用后的評價?怎樣通過對數字資源的評價來引導數字資源合理化、科學化配置?怎樣通過大數據的分析更好地為教學和科研服務,更好地為學校的學科建設、雙一流大學建設提供信息資源保障,以此實現學校資金使用效益最大化?
圖書館對數字資源的監測需求由來已久,以前都是靠廠商提供訪問量、下載量、檢索量的數據,反饋給圖書館匯總,圖書館領導拍拍腦袋簽上大名,最后遞交給采購部門,該方式獲得的數字資源數據不夠客觀,可信度不高,缺乏依據,缺少監管,師生對這種采購流程頗有微辭。隨著互聯網技術和大數據分析技術的發展,統計和分析工作可以利用技術的手段來實現,這樣使得統計數據更加客觀、合理、科學、精準。目前,在數字圖書館行業中,國外進行大數據分析和資源評價的研究已有報道,而在國內進行大數據分析和評價的理論成果也有不少,但實用成果還很稀少。可以預計在不遠的將來,國內外數字圖書行業,各數據提供商之間將會呈現出以平臺為載體,以學科為對象,以內容為靈魂,以服務為根本的競爭格局。迫切需要對各種數字資源進行大數據的挖掘,建立起以學校為單位、以學科為縱軸、以各種內容數據、評價數據和運行數據等業務數據為維度的混合復雜數據模型。在數學模型的基礎上,通過搭建網絡平臺自動完成數據采集、智能分析和實時展現的任務。
一、平臺的架構設計
搭建云服務平臺,實現跨網段的數據異步交互,實現各個客戶端和云服務端的數據交互,并對各項數據的核心價值,各個學校購買情況、評價數據、運維狀態以及數字資源的學科屬性進行大數據挖掘和分析。云服務平臺必須能支持200個(及以上)的數字資源網站監測(基于對一個省內高校數量的考慮)。能實現交換機端口10 Gbps的校園網絡的數據采集和數據提取。
數字圖書館運行監測服務云平臺包含云服務端和學校客戶端兩個部分。總體架構設計如圖1所示。
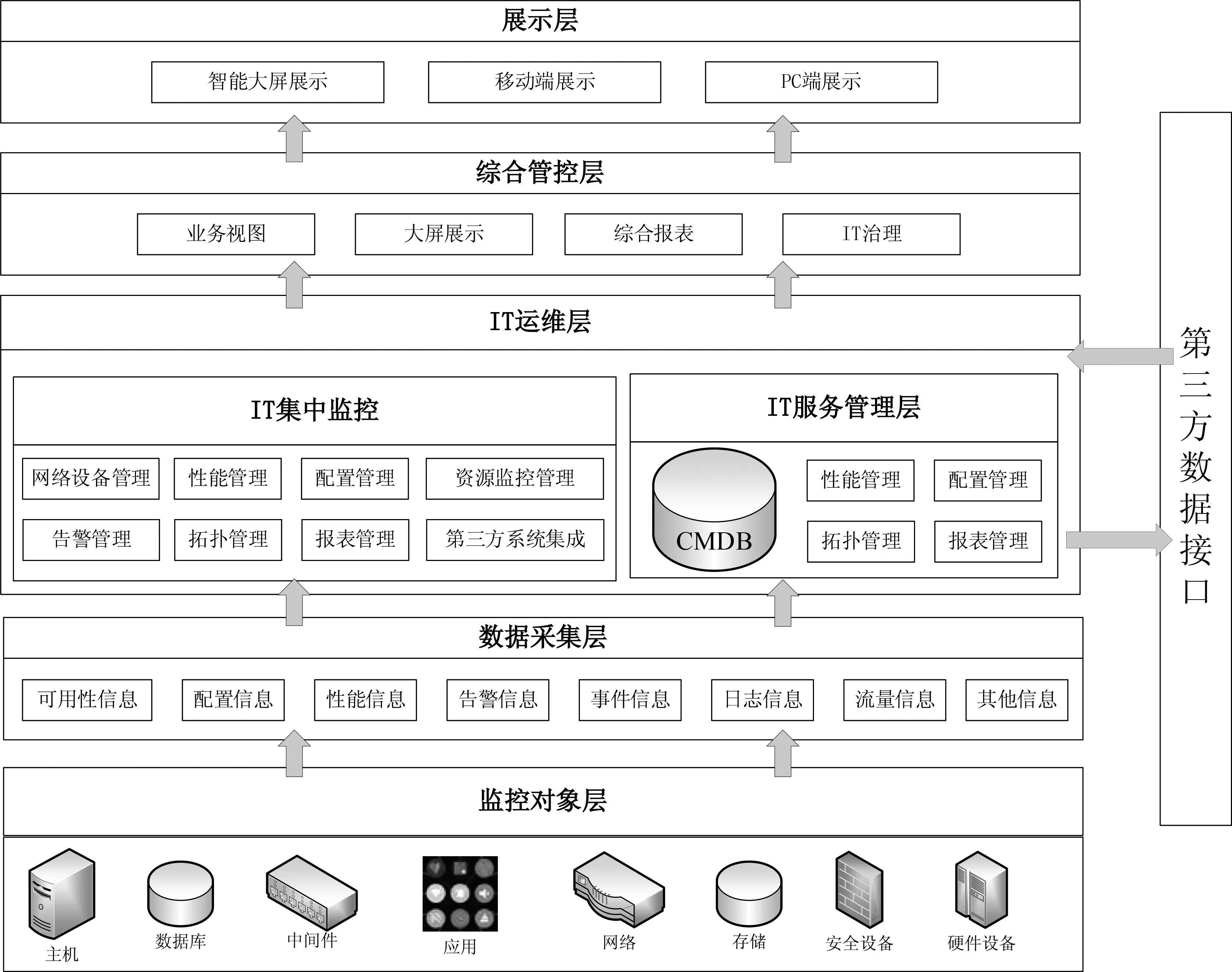
圖1 平臺總體架構設計圖
平臺包含6層結構。云端服務器,實現數據的收集和分析,為各學科、資源等有價值的數據進行分析和展示。
二、平臺客戶端
平臺客戶端主要包含數字資源實時監測預警、資源統計與分析系統、數字資源評價報表系統、數字資源售后服務等子系統,其目的是為了實現對圖書館的已購數據庫或試用數據庫進行監測、統計、售后服務、績效評價等功能,并完成對本地各項元數據的收集。平臺客戶端結構圖如圖2所示:
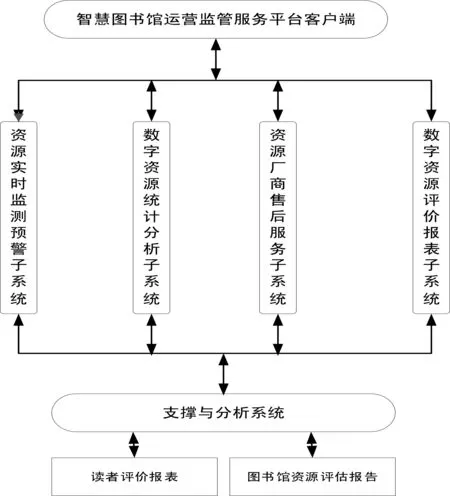
圖2 平臺客戶端的架構
(一)數字資源實時監測預警子系統
數字資源的實時監測預警系統采用爬蟲技術,實時探測各個B/S數字資源系統的運行情況,及時反饋運行結果,并通過短信和郵件的方式告知相關管理人員。有效提高了數字資源的運維和服務水平,讓大量的數字資源服務器更加可靠穩定地運行。
(二)數字資源統計和分析子系統
圖書館資源統計與分析系統基于Redhat-Linux采用PFRING技術路線,通過端口鏡像抓包分析技術,對核心交換機進出端口的數據進行高速采集,并提取相關TCP、HTTP協議的元數據。再采用JAVA多線程技術,對采集的數字資源元數據進行清洗,對清洗過的數據進行數據結構的建模,滿足統計分析的要求。基于統計分析的元數據,可以生成圖書館按照時間維度、學科維度、資源類別的訪問下載量和檢索量等主要的指標性數據,為圖書館的各項資源服務提供可靠的依據。
(三)資源廠商售后服務子系統
通過對資源廠商售后服務子系統的搭建,可以為圖書館用戶提供更加便捷的售后服務在線通道。以下幾個方面將得到較好的改善:管理人員發生變化后第一時間通過平臺進行資料更新,避免溝通脫節;數據資源的數據一旦發生變動,無論變動大小,第一時間通過平臺更新相關信息,既不增加管理人員的負擔,又更新了第一手資料;系統對數字資源廠商的每一次更新都有詳細記錄,并據此出具售后服務質量報告;圖書館的任何部門都能隨時查閱相關信息,不再需要在多個部門之間來回協調。
(四)數字資源評價報表子系統
數字資源評價報表子系統基于以上4個子系統產生和收集到的大量元數據而生成,可以為圖書館管理人員和館領導提供針對圖書館各個數字資源運行和使用情況的績效評價報告。
三、技術創新點
圖書館運維系統的后臺支撐服務基于J2EE體系架構開發;采用Quartz多線程技術、爬蟲技術、Cache緩存技術、瀏覽器識別和模擬登陸技術,準確、高效地定位和發現各個數字資源是否正常、硬件設備運行是否正常。系統通過移動網絡運行于Android、IOS等系統通信終端及時反饋故障信息給用戶。后臺還采用多種精密算法,其結果通過短信、郵件、微信等預警方式快捷告知用戶,以免形成騷擾。系統采用了嚴謹合理的架構支撐體系,如圖3所示:
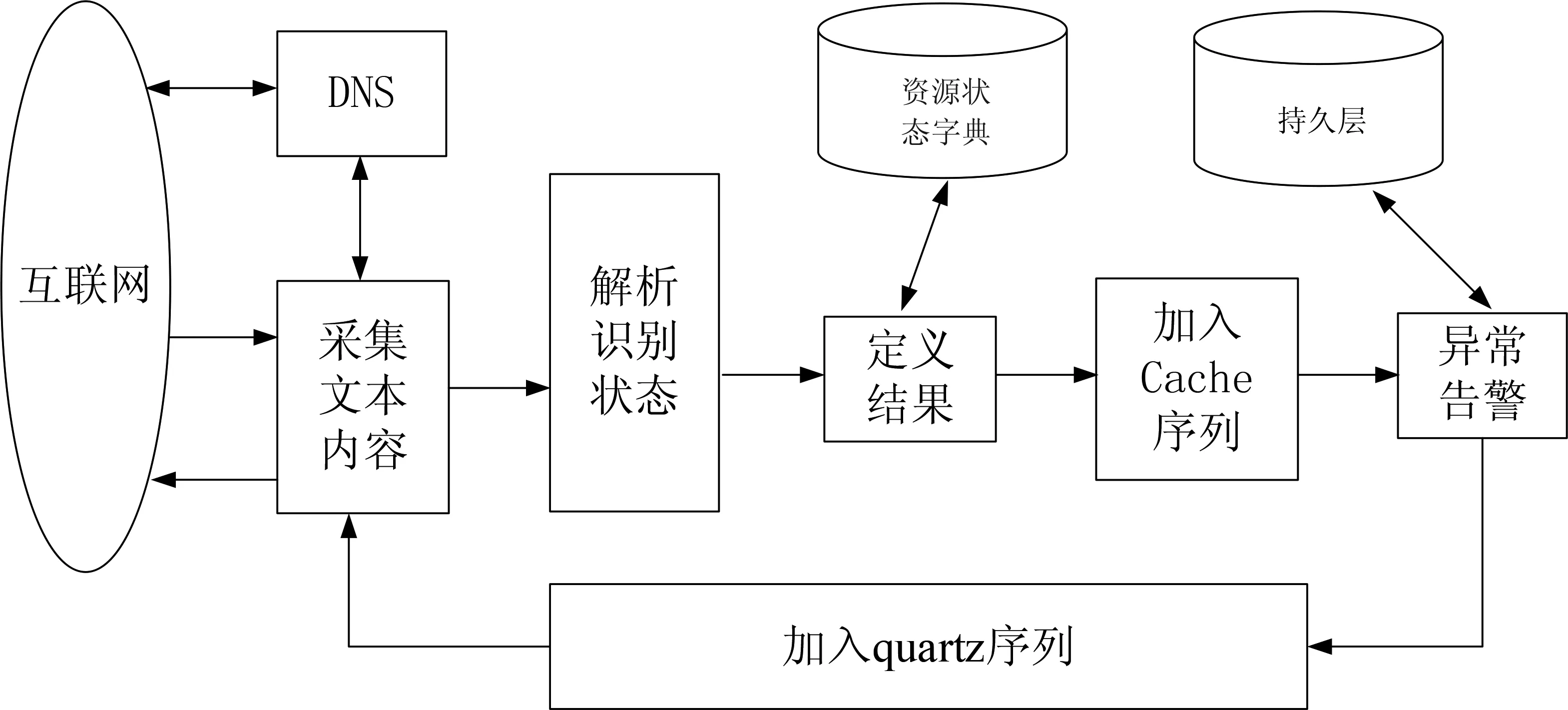
圖3 平臺的架構支撐體系
上述流程實現過程中,從以下幾個方面實現了技術上的創新和突破:(1)對爬蟲技術進行了優化和合理的配置。不僅可以正常地識別各個資源的狀態,而且需要把每一次的探測網絡的流量控制到10 KB/s之內(只有這樣才能支撐起幾百個資源的并發探測)。(2)為保證后臺多線程支撐程序7×24小時不間斷的運行,對quartz框架作優化和重寫。(3)由于某些數字資源采用的是https協議,爬蟲程序采集的結果狀態兼容https的資源網站。(4)后臺支撐程序不僅支持資源網站,還兼容了服務器、交換機等硬件設備的性能監控。
四、平臺運行結果
平臺采用了多種信息技術,特別是利用網絡爬蟲技術,精確識別數字資源或者B/S系統是否正常訪問、響應和下載等狀態,有效實現了基于應用層的資源監控,解決了長期以來困擾圖書館的網絡運維問題(目前國內公司運維系統是基于物理層或者網絡鏈路層的監控)。
(一)較為全面地反映圖書館數字資源使用狀況
該平臺能記錄某一個時間段內各個學院的客觀下載量、訪問量、檢索量、訪問入口等,以及最新資源介紹、最新數字資源學術價值、最新數字資源特點、最新數字資源培訓資料、最新售后服務跟進情況等指標和屬性數據。
(二)將大數據技術應用于圖書館數字資源監測
采用端口鏡像的方式對數字資源進行高速線性采集,然后對數據進行還原和分析,分析出各個不同角色、不同院系使用數字資源的情況,最后進行統計和匯總。這樣就解決了圖書館的數字資源統計問題。該技術路線在數字圖書館行業中的運用,結合了數字圖書館大數據分析技術,在國際與國內均屬領先地位。平臺采用云平臺的方式分布式部署,對不同學校、圖書館的監測數據、資源訪問數據以及評價數據等海量數據進行多線程處理,然后匯總到云平臺存儲,再橫向挖掘出有價值的數據結果,使大數據技術在數字圖書館界變成了現實。
(三)能快速生成不同維度的分析報告
平臺通過不同維度的數據的收集,然后根據圖書館的業務流程和算法,生成各種對圖書館有價值的分析報告。
五、結論
該平臺通過對圖書館各種業務流程和網絡運行數據進行客觀、公正的采集和分析,對高校圖書館的數字資源利用情況和數據資源提供商的服務質量進行實時跟蹤和展現,為圖書館數字資源遴選、采購和續訂提供決策參考。特別是運用分析結果,可以督促廠商改善服務質量,提高圖書館經費使用效率,改善圖書館數字資源的使用效果,為提升圖書館運行管理和服務水平提供重要參考,為當今圖書館轉型發展提供決策依據。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
電子制作(2018年18期)2018-11-14 01:48:24
小太陽畫報(2018年1期)2018-05-14 17:19:25
資源再生(2017年3期)2017-06-01 12:20:59
山東工業技術(2016年15期)2016-12-01 05:31:22
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
