多步前進同步并行模型?
2019-10-26 18:05:02張尉東
軟件學報 2019年12期
關鍵詞:模型
張尉東,崔 唱
1(北京大學 信息科學技術學院,北京 100871)2(北京大學 元培學院,北京 100871)
在過去的十幾年中,各種用途的處理框架相繼被開發出來,如為通用數據處理而開發的Hadoop/Spark/Dryad[1?3],為蛋白質折疊而開發的GROMACS[4],為海洋、氣象氣候科學而開發的CORSIKA[5]以及為材料工程科學、天文天體物理和社會科學開發的NAMD[6]、FLASH[7]和Swarm[8]等.
無論是并行計算框架還是并行算法,并行化都需要一種或多種并行計算模型來指導其實現.常見的并行計算模型包括大同步并行(bulk synchronous parallel,簡稱BSP)[9]、異步并行(asynchronous iterative algorithm,簡稱AiA)[10]、時間并行(parallel in time,簡稱PiT)[11]、logP[12]和輪回并行(samsara parallel,簡稱SP)[13]等.然而,所有這些并行計算模型都采用無差別的方式來處理稀疏和稠密數據集,這就忽略了數據集內部所蘊涵的獨特性(如局部性分布、依賴關系密度等).這不僅導致了大量的無用計算和迭代步,還導致計算時間和收斂結果不受控制.一個經典的例子是使用通用計算機集群(commodity machine cluster)在兩個稀疏程度不同但直徑相同的圖上執行BSP模型并行化的單源最短路算法,其所耗時間幾乎相等.原因是它們使用了相同的迭代輪數,而每輪迭代的時間基本都消耗在全局同步上.
為了追求更快的收斂速度,各種應用的異步算法相繼被設計出來.異步算法可以在時間上重疊計算和通信,從而實現更靈活地利用數據內部的局部性,達到加速算法收斂的目的.異步算法的缺點也比較明顯.除了需要針對單個問題單獨設計相應的算法和終止條件外,還會比同步算法耗費更多的通信和計算.SP與BSP和AiA相比,其每次向前投機地計算多步,再將多步計算結果統一打包并交換.在將交換的數據校驗后,若發現某步結果不對,則將所有進程跳回最早出錯的一步重新計算.盡管SP可能進行更多的無用計算,但每次大同步卻可以投機地前進多步,且每步都能和BSP的迭代步一一對應.
就我們所知,目前還沒有一個模型可以在不修改算法的前提下,以不同的方式處理稀疏程度不同的數據集.要進行有區別的處理,首先需要挖掘數據中存在依賴關系和局部性分布,即使先不討論依賴關系和局部性,如何構造出根據不同的數據集產生不同并行行為的并行程序也缺乏相應的理論指導.在日常數據處理工作中,我們發現大量并行算法僅在滿足弱一致性條件時即可收斂;同時,大多數數據都是相當稀疏的.結合這兩方面,我們認為可以通過進一步挖掘和利用數據分區中的局部性,首先加速局部收斂進而促進全局的收斂.
通過數學建模和形式化推導,我們發現本文提出的多步前進同步并行(delta-stepping synchronous parallel,簡稱DSP)模型是一種比BSP更一般的同步并行模型.它可以更充分地挖掘和利用隱藏在數據中的局部性來加速算法的收斂.進一步的實驗同樣驗證了這個結論.DSP與BSP唯一的不同點在于:在每個超級計算步內,DSP執行Δ步局部計算(Δ≥1);而BSP僅執行1步局部計算.引入更多局部計算的目的在于進一步挖掘和利用蘊含在數據分區內的局部性,進而加速局部收斂、減少迭代輪數和通信開銷.在通用計算集群中,對于計算量少但迭代步數多的算法,迭代輪數的減少直接意味著收斂時間的減少.原因是這種類型的算法將大部分執行時間都消耗在全局同步上.在表1中,我們將DSP與幾種常見的并行計算模型進行了比較:(i) 同步方式——同步、異步;(ii)迭代次數;(iii) 與BSP每步結果是否能對應上,結果是否收斂.

Table 1 Comparison between common parallel models and DSP表1 常見的并行計算模型和DSP的比較
本文有如下貢獻.
1) DSP并行計算模型:本文提出了一種新的并行計算模型,可用于加速一大類并行迭代算法.
2) 并行計算模型的形式化表示方法:本文提出了一種形式化表示方法,可以很好地表示各種并行計算模型及其迭代過程.
3) 正確性和適用性證明:利用貢獻2)中給出的形式化方法,推導并證明了DSP的適用性及收斂條件.
4) 編程指導:為指導用戶將BSP程序改寫或直接構造DSP程序,給出了具體的實施步驟.
本文首先介紹若干相關工作,包括BSP、參數服務器等模型.為了對DSP建立一個初步映像,第2節列舉DSP的幾個應用場景.第3節描述并行模型的形式化表示方法,并使用該種方法表示BSP和DSP的迭代過程,推導和證明BSP和DSP的等價收斂條件.第4節使用真實數據集和實際應用驗證并評估DSP模型的加速性能.第5節是總結和工作展望.
1 相關工作
1.1 大同步并行模型(BSP)
Leslie Valiant于1990年在牛津大學提出了著名的BSP并行計算模型.該模型主要用于指導同步并行算法或程序的設計.一個典型的 BSP算法或程序由如下 3部分組成:局部計算(local computation);通信(communication);阻塞同步(barrier synchronization).
BSP算法的一個超級計算步(superstep)可以描述為圖1所示的過程.

Fig.1 BSP pattern[14]圖1 BSP算法執行流程[14]
與BSP相比,DSP簡單地將單步局部計算變為Δ步局部計算(Δ≥1),新增加的局部計算步只是簡單地重復執行之前的計算.DSP算法的一個超級計算步可以描述為圖2所示的過程(DSP將局部計算步數變為Δ步.局部計算時,只更新本地變量,不進行節點間通信).同時,我們將額外增加的(Δ≥1)步局部計算稱為投機計算步(speculative computation step,簡稱SCStep),其定義如下.
投機計算步(SCStep).BSP局部計算的簡單重復,期間只做局部數據更新,計算節點間無數據通信發生.
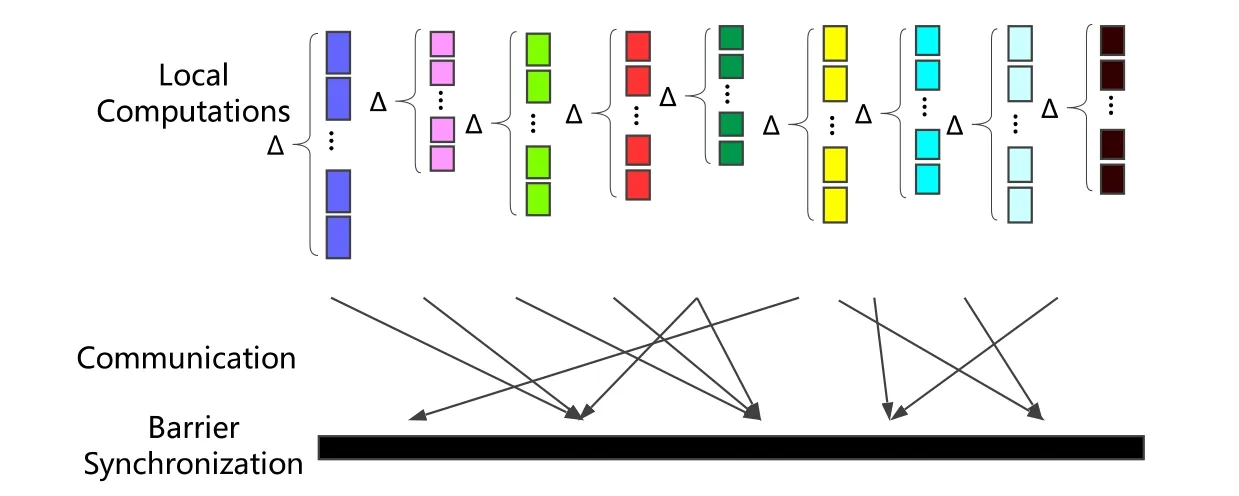
Fig.2 DSP executing pattern圖2 DSP算法執行模型
1.2 參數服務器
為了解決大規模分布式機器學習中數以百萬計參數頻繁更新的問題,Google在2012年提出了參數服務器的方案[15].參數服務器允許各個模型副本在一個很小的時間間隔內,異步地更新和下載中心參數服務器中最新的參數.這樣一來,各個模型副本就可以減少使用參數服務器時互斥等待的時間.雖然在允許的時間間隔內,各個模型副本從參數服務器上獲取的數據并不一致,但算法最后卻能收斂.Google的論文[15]中展現了參數服務器驚人的加速潛能,同時也表達了對加速原理的疑惑.進一步工作[15?19]分別將參數服務器用于加速不同的應用,并分別給出了收斂性證明.然而到目前為止,還沒有一個正確性的一般性證明.與參數服務器不同的是,DSP算法除了支持一大類機器學習的優化算法以外,從根本上是針對并行迭代計算提出的,因而幾乎可以適用于所有的并行迭代計算.針對其適用性和正確性,本文給出了一個一般性證明及適用約束條件.
另外,參數服務器的相關工作并沒有解釋其加速原理,本文中對DSP加速原理的解釋同樣適用于解釋參數服務器加速的原理.
1.3 其他工作
(1) KLA:K層異步算法(K-level asynchronous,簡稱KLA)[20].DSP與KLA的不同主要體現在以下幾點.
· DSP僅僅在大同步時才進行節點間通信,而KLA在局部計算時也會進行節點間通信.因而,DSP比KLA更簡潔,同時也具備比KLA更好的擴展性和更廣的適用范圍.實驗中我們發現,通信的開銷不僅僅與通信的次數相關,而且還受到消息長度的極大影響.
· DSP的應用不限于KLA所局限的圖計算領域.
· DSP不是KLA的特例,KLA也不是DSP的特例.
(2) 多步并行最短路算法(Δ-stepping:A parallelizable shortest path algorithm)[21,22]:通過維護一個待選頂點的列表,每次向前嘗試性地進行Δ步迭代.DSP并不需要顯示地維護這樣一個列表和待選數據集,只需在數據分區中簡單重復地執行相同的操作并更新局部數據,就可以達到與該算法相同的效果.DSP用于加速單源最短路算法的示意圖如圖3所示.虛線界定的網格代表一個計算節點,每個計算節點負責計算圖中部分頂點的最短路.由于DSP每個超級計算步可以執行Δ次局部計算和局部更新,而BSP卻只能執行1次,所以著相同顏色的頂點可以在同一輪大同步求得最短路.求得圖3(a)中所有頂點的最短路僅需5輪全局大同步,求得圖3(b)中所有頂點的最短路則需要13輪全局大同步.
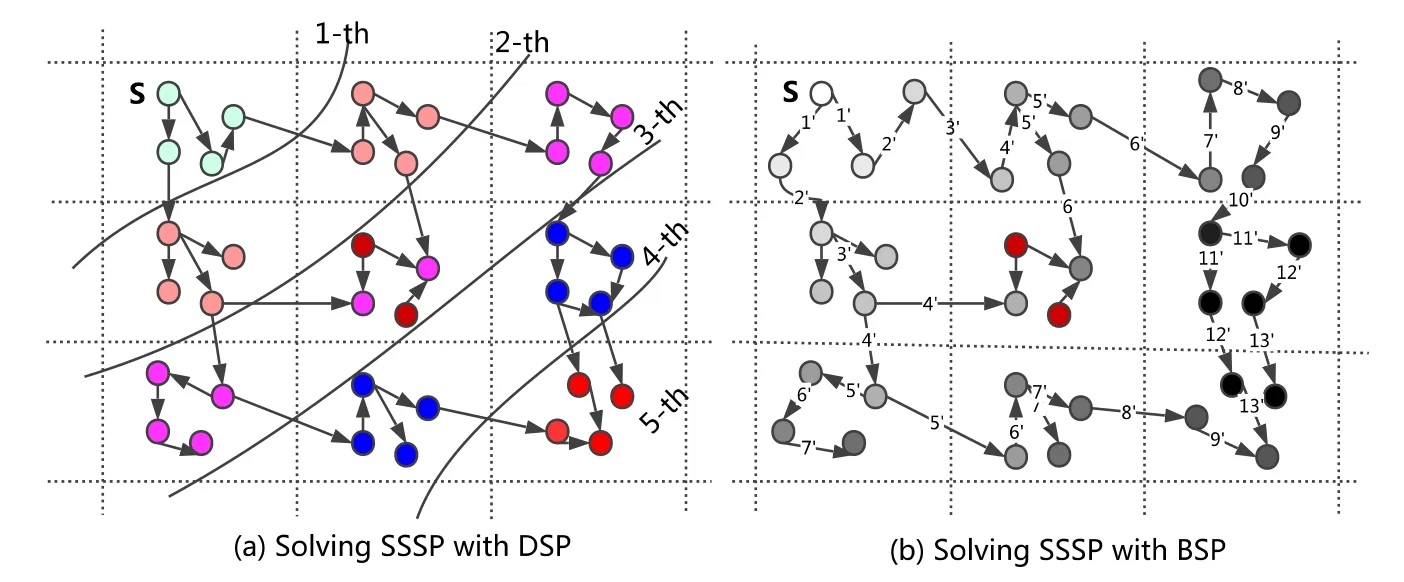
Fig.3 Solving procedures of single source shortest path (SSSP) from all other vertices to vertex S with DSP and BSP model respectively圖3 分別使用DSP和BSP模型求解圖中所有頂點到S 點的單源最短路
2 應用舉例
正式描述模型之前,為對DSP建立一個初步的映像,首先介紹幾個簡單的例子.
· 圖并行算法
將DSP用于加速圖并行算法時,可以很好地解釋DSP的工作流程及原理.如圖3所示,將DSP用于加速單源最短路(SSSP)算法,圖中每個虛線界定的網格表示一個計算節點,每個計算節點負責圖中一部分圖頂點最短路的計算.BSP模式下,每個超級計算步每次計算僅向前推進1步,而DSP每次卻可以前進多步,甚至將最短路在一個超級計算步就傳遞給相鄰的下一個網格.對其他圖算法如PageRank等,多步局部計算同樣可以通過更充分利用數據分區內的局部性加速子圖內的局部收斂,進而促進算法的全局收斂.
· 求解線性方程組
在某些工程和科研應用中,部分線性方程組的系數矩陣如此稀疏,以致于可以將未知數向量X分為多段,分別進行獨立求解.并行求解這類型方程組實際上只需很少的通信,即可達到較高精度的收斂.因此,DSP模型十分適合用于加速稀疏線性方程組的求解.
· 機器學習
機器學習的訓練數據通常由數10億級的高維向量組成,同時,學習模型的參數也由數百甚至上千維的向量組成.然而,由于數據和模型的稀疏特性,分布于不同計算節點上的參數之間的嚴格同步并非必備條件,甚至部分節點的數據之間并不存在相互依賴,因此,分布式優化算法十分適合采用DSP進行加速.
3 模型及其收斂性保證
DSP模型的目標是在不影響算法收斂的前提下,通過減少算法的迭代輪數來減少算法在通信上的開銷,進而加速算法的收斂.為了實現這個目標,我們發現,不同于稠密數據集上的迭代計算,稀疏數據集上的迭代計算擁有更小的計算通信比:Tcomputation/Tcommunication,即迭代時間主要耗費在通信上,而非計算.因此,通信開銷的減少可以有效地加速并行算法的收斂.此外我們還發現,僅僅1步局部計算很難充分挖掘和利用數據分區內的局部性.對于一大類圖并行算法,1次局部計算對應著1次局部值傳遞,那么多步局部計算意味著多步局部值傳遞.然而,投機計算步并非越多越好,因為投機計算步是以增加計算量為代價,當集群節點間初始負載不均時,太多的投機計算步甚至會加劇這種不均衡.
分析表明,投機計算步具備如下兩個特征:(i) 嘗試在數據分區內通過更充分地挖掘和利用空間局部性,實現空間局部性最優;(ii) 嘗試在一個超級計算步內通過更多的執行投機計算步實現超級計算步內的時間局部性最優.簡而言之,DSP通過執行合理數量的投機計算步實現空間和時間上的局部最優.如果這里的空間和時間局部最優正好發生在某些適合的算法或作用于稀疏數據集上,那么它極有可能轉化為最終和全局的最優.
此外,DSP還具備一些其他優點.如:(i) 當應用于值傳遞算法時,可同時適用于稠密和稀疏數據集;(ii) 當用于加速雅各比迭代時,展現出了類似于超松弛(successive over-relaxation,簡稱SOR)[21]的加速效果,即同時減少了局部計算步和全局同步輪數.
3.1 形式化表示
為了統一表示和比較不同的并行計算模型,本文提出了一種類似于“矩陣乘法”的轉換:Xk+1=Xk?Fn×m,其中,Xk,Xk+1分別為第k輪迭代的輸入和輸出變量,Fn×m為迭代計算進行的操作.不同于代數中的矩陣乘法,Fn×m中的每個元素Fi,j表示輸入向量Xk的分量xi與xj之間進行的計算,其結果返回給xj.得到xj所有依賴的分量與xj運算后的結果,再將這些結果進行聚合,聚合的結果將作為xj本輪計算的輸出.直觀上理解,xj下一輪的新值實質上是將它依賴的每個分量對它產生的影響或改變進行聚合的結果.類似的表示方法也在文獻[23,24]中出現,不同的是,我們進一步推導出了輸入變量X隨迭代進行的演變形式.
為使下文更簡潔地表達和推導,首先定義如下變量和符號.
1)X0:迭代計算的初始輸入變量.
其向量表示為(x0,x1,...,xn).xi可以表示各種類型的數據,如圖計算中頂點信息、線性方程組中的未知數等.
2)Xk:迭代計算的第k輪輸出.
并行化時,變量Xk被切分為多段并分布在不同的計算節點上進行計算,X(p,q)k表示某個計算節點僅負責計算從xp到xq一段的分量.
3)F:關系矩陣.
Fi,j定義xi與xj之間的運算,函數形式為Fi,j(xi,xj),簡寫為Fi,j(xi).其運算結果返回給xj供其進一步與其他所依賴的變量計算產生的結果進行聚合(具體實現時,Fi,j通常被表達為一個數學公式、函數、過程或方法).
F(p,q)表示對輸入變量進行一次部分轉換.F(p,q)僅計算和更新xp到xq之間的變量.其定義如下.

使用向量與矩陣相乘的規則,X的分量被投射到Fi,j上進行運算,最終只有xp到xq之間的變量進行了運算和更新,其余分量保持不變.
此運算符將{Fi,j(xi)|i=0,1,2,...,n}中所有運算結果進行聚合,聚合得到的值將作為xj本輪迭代計算的輸出.公式為

常見的聚合操作有min(?),max(?),average(?),Σ,Π等.
5) ?:轉換運算符.
該運算符將關系矩陣在輸入變量上作用1次.
表2中列舉了幾種常見算法的關系函數和聚合函數.

Table 2 Common algoriths and corresponding relation/aggregation functions表2 常見算法及其對應的關系函數和聚合函數
使用如上定義的變量和符號,BSP模型的迭代過程可推導如下.

通過如上推導,我們發現,k輪BSP迭代可由k次關系矩陣的轉換來表示.
類似地,對X0進行l輪DSP迭代,可得到對應的XlΔ(每輪DSP大同步對應進行Δ步局部計算,詳細推導過程見https://github.com/wdfnst/DSP_Proof/blob/master/dsp_proof.pdf):

直觀上理解,公式(2)中的參數解釋如下.
·g(αp,βp):將BSP中一次局部計算變為兩次局部計算后產生的新算法.
·αp:聚合xp所有依賴的變量對其作用的結果.
·βp:聚合xp所依賴的且位于不同計算節點上的變量對其作用的結果.βp也可視為xp對其他分區數據的依賴程度.
·γp(=αp?βp):聚合xp所依賴的且位于相同計算節點上的變量對其作用的結果.γp也可視為xp對分區內數據的依賴程度.
要使用DSP加速BSP,即在迭代中用公式(2)表示的計算替換公式(1)表示的計算,首先需要證明它們可以收斂到相同的最終狀態.然而公式(2)并不能保證收斂到與公式(1)相同的最終狀態.但對于凸優化問題或只要求收斂到局部最優點的算法,達到收斂就足夠了.第3.2節將使用數學歸納法證明DSP的收斂條件.
3.2 DSP模型的收斂性保證
包括參數服務器和DSP模型在內的許多模型或算法[22?25]都使用了投機計算的思想,然而,其中僅部分模型或算法給出了正確性解釋或適用條件說明.在沒有正確性保證的前提下,用戶在選用這些方法時始終保持著謹慎的態度.本節將給出BSP和DSP的關系,并推導出DSP的收斂條件.
定理1.如果算法在BSP模式下收斂,那么,當且僅當滿足如下條件時,算法在DSP模式下也收斂:

直觀上理解,定理1描述了在BSP模式下收斂的算法,若增加一次局部計算后得到的新算法仍然收斂,那么增加任意數量的局部計算得到的新算法都將收斂.
證明:當Δ=1時,DSP模型退化為BSP模型.故Δ=1時,結論成立.假設當Δ=k(k≥1)時,結論仍然成立,即

收斂.
那么當Δ=k+1時,得到如下左式,并變形為右式:

對比公式(4)、公式(5),在BSP模式下,因為αp收斂,所以公式(4)收斂.從而,公式(5)收斂的條件是:

在滿足條件(6)時,定理1對Δ=k+1成立.
由數學歸納法原理可知:在滿足條件(6)時,定理1對所有Δ∈Ν+成立.□
3.3 DSP加速因素分析
由公式gΔ?1(αp,βp)可知,DSP算法的收斂速度主要依賴于3個因素:Δ,αp和βp(其中,p=0,1,2,…,n),并存在如下關系.
· 當βp=0時(可理解為xp的收斂不依賴任何位于其他計算節點上的變量),xp在不需要任何全局數據同步的前提下即可收斂.這時,額外的(Δ?1)步投機計算可以獲得非常顯著的加速,以至于當Δ充分大時,xp可以在不需要任何全局同步的情況下直接收斂.圖4(a)示例了這種情況,每個數據分區被分配到不同的計算節點,彼此之間不存在任何依賴關系,這個圖上的并行迭代計算可以在不需要任何全局數據同步的情況下收斂.
· 當γp=0時(可理解為xp的收斂完全依賴于位于其他節點上的變量),因為xp所依賴的變量在Δ步局部計算中并不會更新,所以Δ次局部計算產生的新值也不會有任何變化.圖4(c)示例了這種情況,圖中每個分區中的頂點所依賴的變量全部位于其他計算節點內,這種情況下,額外的(Δ?1)次局部計算不會產生任何加速效果.
· 當γp>0時(即xp所依賴的變量部分位于和自己相同的節點內),額外的(Δ?1)步計算會促進xp更快地收斂,且加速效果與γp成正比.
· 當βp>0時(即xp所依賴的變量部分位于其他節點),第1次局部計算之后,βp并沒有及時從其他節點獲取最新值進行更新,剩下的(Δ?1)步局部計算仍然使用上次全局同步的變量計算產生的βp.過期的βp對xp的收斂其起副作用,DSP的加速效果與βp成反比.圖4(b)示例了這種情況,每個分區內的頂點所依賴的變量既有來自本節點的,也有來自其他節點上的.
某種意義上,γp和βp可分別用數據分區內和數據分區間的依賴關系密度來解釋.若能通過適當的數據劃分增加分區內依賴關系密度(即增大γp),同時減小分區間依賴關系密度(即減小βp),那么算法的收斂極有可能得到加速.然而,完美的數據切分(如圖劃分)通常都是NP難問題.盡管增大γp比較困難,足夠小的βp卻十分普遍.因為稀疏數據集劃分之后得到的βp通常都會非常小,這就為我們使用DSP加速迭代計算創造了條件.
為了驗證βp,γp與加速效果之間的關系,我們使用PageRank算法在隨機圖上進行了兩組實驗:(i) 固定子圖內的連接度,變化子圖之間的連接度;(ii) 固定子圖間的連接度,變化子圖內部的連接度.實驗結果如圖5所示,圖5(a)顯示,加速比#Iterationbsp/#Iterationdsp隨著增加的β而下降,即子圖間連接增加后,DSP的加速性能下降了.圖5(b)顯示,加速比#Iterationbsp/#Iterationdsp隨著增加的γ而上升,即子圖內連接增加后,DSP的加速性能上升了.這一結果進一步驗證了我們上面的分析.
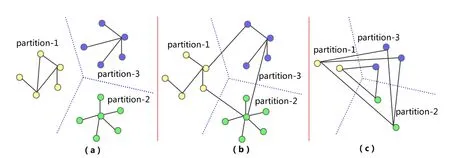
Fig.4 圖4

Fig.5 Acceleration of DSP on PageRank圖5 DSP對PageRank的加速
3.4 DSP并行算法的構造
對比算法1、算法2,將BSP算法改造為DSP算法或直接構造DSP算法只需在進行全局通信前增加一個條件測試(測試是否執行了指定步數的局部計算).構造DSP程序時,可按如下幾步進行.
1) 若BSP算法收斂,則檢驗擁有兩步局部計算的新算法是否收斂,若收斂則轉至第2)步.
2) 篩選合適的參數Δ.
3) 調整代碼.增加條件測試,使得每執行1次DataExchange(?)對應執行Δ次Computing(?).
算法1.BSP并行算法模板.

算法2.DSP并行算法模板.


對于各種算法,并沒有普遍適用的Δ值.根據第3.3節中的分析可知:當數據集比較稀疏或采用較好的數據劃分算法時,可以選用適當大的Δ;反之,適當小的Δ加速效果可能更好.除此之外,非線性是導致變量變化快慢的主要因素之一.當算法非線性較強時,重用劇烈變化的變量值會引入較大的誤差,致使收斂速度減慢.所以,非線性強的算法適合選用較小的Δ,反之適于選用較大的Δ.
4 實驗與評估
實驗中用到的設備主要包括20臺高性能服務器及連接它們的高速以太網(40GB/s或換算為3.2GB/s)和InfiniBand網絡(6.8GB/s).每臺服務器由兩片Intel Xeon E5520處理器(4核×2.27GHz)和48G內存以及其他外設組成.除GMRES和SGD外,其他算法都采用C++和MPI通信接口實現.默認情況下,MPI優先使用InfiniBand進行通信,所以這里實現的算法實際上都優先使用InfiniBand進行通信.因為DSP加速的原理是通過減少迭代輪進而減少通信開銷實現的,而在高速網絡中,由于通信延遲低,DSP的加速性能并沒有得到充分的展示.在由TCP/IP網絡連接的通用計算集群中,DSP的加速性能會比下面列出的結果更加卓越.
4.1 圖算法應用
1) PageRank.PageRank算法通過賦予web網絡中每個頁面一個權重,并以此來衡量每個頁面的相對重要程度.其計算既可通過代數方法求解也可通過迭代法求解,迭代公式為
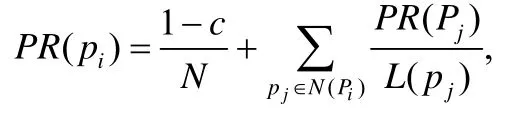
其中,p1,p2,...,pn表示需要計算PageRank值的網頁,N(pi)表示所有連接指向pi的網頁集合,L(pj)表示網頁pj的出度,N表示所有網頁的數目.常數(1?c)/N表示網頁瀏覽者隨機打開一個網頁的概率,這個機制用來解決和防止終止點問題和陷阱問題.
我們收集了3份真實Web圖數據,并對其基本信息進行了統計.如表3所示,指標包括頂點數、邊數、平均出度、最大出度和最小出度.從其平均出度來看,這些Web圖并不稀疏.并且Web圖的入度分布一般都高度畸形,即其頂點的入度懸殊非常大.

Table 3 Statistics of real world Web graphs表3 真實Web圖及其基本統計信息
將表3中的Web圖按頂點近似等分劃分,并分發到不同的計算節點.在每個計算節點上每執行Δ步局部計算再進行一次全局大同步.圖5(a)~圖5(c)展示了DSP的加速效果.數字顯示,DSP可以顯著減少BSP的迭代輪數,進而減少算法的收斂時間.在這組實驗中,我們采用了Metis工具包[26]進行圖劃分(Metis工具包中實現的算法可以在保證子圖間頂點數量均衡的前提下,最大限度地減少子圖間割邊的數量,從而降低子圖間的依賴性;而隨機圖劃分算法僅能保證子圖間頂點數量的均衡,不能減少子圖間割邊的數量,也不能降低子圖間依賴的程度).與此同時,我們還在隨機劃分的子圖上進行了相同的測試,結果顯示:除Δ=2有少許加速外,DSP算法的收斂速度甚至還不如BSP.這個結果也驗證了我們在第3.3節中的分析,即DSP的加速效果十分依賴于β和γ.
圖6使用真實Web圖和路圖,測試DSP對PageRank和SSSP算法的加速性能.圖6(a)~圖6(c)展示在使用Metis工具包切分的子圖上,DSP對PageRank加速性能;圖6(d)~圖6(f)展示在使用Metis工具包切分的子圖上,DSP對SSSP的加速性能;圖6(h)~圖6(g)展示在使用隨機劃分的子圖上,DSP對SSSP的加速性能.PageRank算法的收斂精度設為10?10.

Fig.6 Performance comparison between DSP and BSP working on PageRank and SSSP with the real Web graph圖6 使用真實Web圖和路圖,測試DSP對PageRank和SSSP算法的加速性能
2) SSSP.給定一個有向賦權圖G(V,E),SSSP算法用來尋找圖中所有點到指定源點的最短距離.
為了方便說明,圖3中示例了一個簡單的單源最短路求解的例子,以說明DSP加速單源最短路這類圖算法的原理.圖中每個虛線界定的網格表示一個計算節點,分別負責計算圖中部分頂點的最短路.圖3(a)、圖3(b)中隨著著色的變化(或加深),分別展示了DSP和BSP迭代的過程.由于DSP在一個超級計算步中可執行多次局部計算,從而可以將最短路向前傳遞多步,而BSP每次只能前進1步.圖3(a)中使用DSP加速,整個計算過程僅需5次全局大同步即可收斂,而圖3(b)使用BSP迭代,則需要13次大同步.在這個例子中,DSP的加速比為2.6倍.
為了驗證DSP在實際路圖中的加速性能,采用美國若干州的路圖進行了實驗.同樣,為了驗證第3.3節中的分析,如下兩種圖劃方法被用于圖劃分:(i) 隨機劃分;(ii) Metis劃分.路圖的的基本信息及統計信息見表4,可以看出,路圖是比Web圖稀疏得多的自然圖.

Table 4 Statistics of real world road networks表4 真實路圖及統計信息信息
如圖6所示,圖6(d)~圖6(f)、圖6(g)~圖6(i)分別展示了在采用不同圖劃分方法得到的子圖上進行實驗的結果.數字顯示,算法在Metis劃分的子圖上的性能是在隨機劃分的子圖上的性能的數倍.這一結果進一步驗證了我們在第3.3節中的分析.同時,僅采用隨機分圖,DSP對BSP的加速也可高達10倍.
4.2 線性方程組求解
設AX=b表示一個由n個線性方程組成的線性方程組,其中,

當系數矩陣A為低階非稠密矩陣時,使用高斯主元消元法可以進行非常高效的求解.但當系數矩陣為稀疏矩陣時,迭代法則更加高效,它能更充分地利用系數矩陣中出現的大量零元,進而避免大量不必要的計算.Jacobi迭代法求線性方程組的迭代公式為

超松弛法(successive over-relaxation,簡稱SOR)[21]是Jacobi迭代法的一種改進算法,可以實現比Jacobi迭代更快的收斂.其迭代公式為
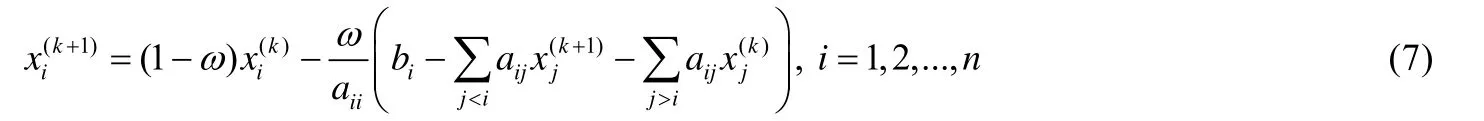
其中,常數ω>1稱為松弛因子.
為了比較DSP和SOR加速Jacobi迭代的原理,我們將執行一步局部計算對xl所做的操作進行如下表示和變形:首先,使用分別表示xi和xl在第(k+1)步局部計算時得到的最新值.
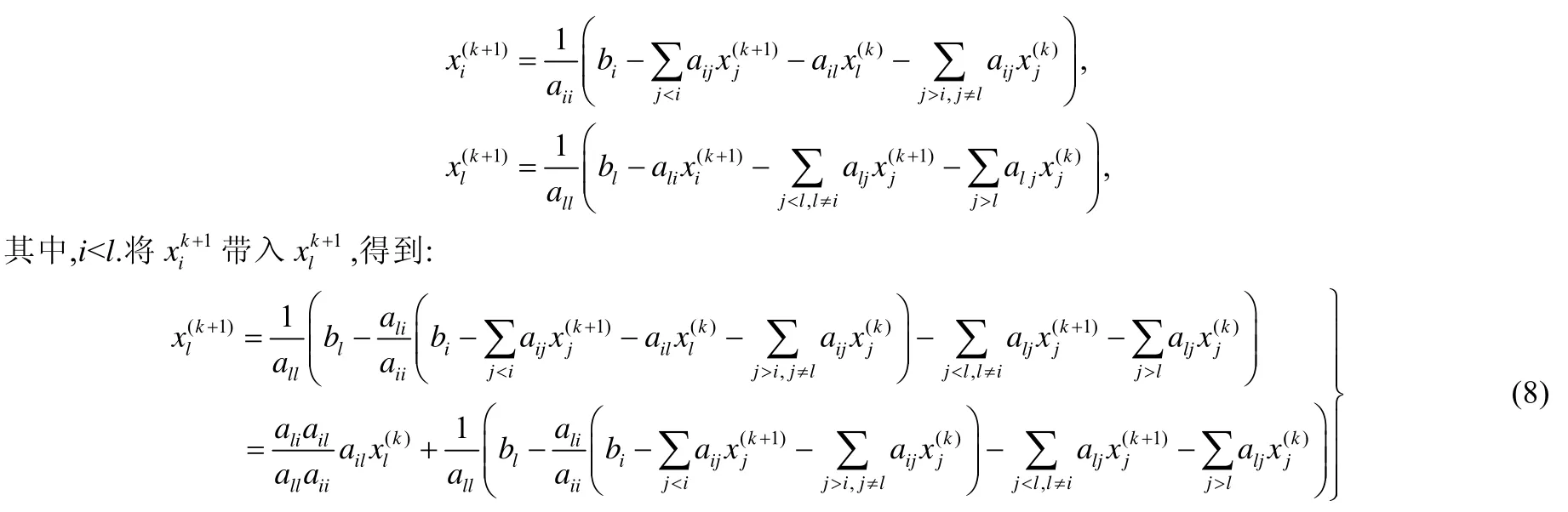
比較公式(7)和公式(8)不難發現,DSP的迭代遞推公式和SOR的遞推公式有著類似的形式,這進一步驗證了實驗中的發現,即DSP和SOR可以同時減少計算量和通信量.
實驗采用了由10 000個線性方程組成的線性方程組.將未知數向量X等分為20份,并分發到不同的服務器中.每臺服務器每進行Δ步局部計算,對應進行一次全局大同步.實驗結果如圖7所示(收斂精度設為10?14):迭代的步數首先隨著Δ的增加而減少,隨后穩定在一個值周圍.收斂時間隨著Δ的增加,先減少再增加.收斂時間下降后再增加是因為投機計算步并非越多越好,它同時也會增加計算負擔,進而抵消減少通信帶來的好處.
廣義最小殘差算法(generalized minimal residual method,簡稱GMRES)[27]是一種被廣泛應用的線性方程組迭代求解算法,為了評估DSP的加速性能和擴展性,我們將其與GMRES算法的速度進行了比較.在求解一個由10 000個線性方程組成的線性方程組時,GMRES耗時0.0373 18s和71輪迭代.DSP的性能如圖8所示(收斂精度設為10?14),當Δ=100時,DSP僅耗時0.0187 14s和2輪迭代就達到了和GMRES同樣的收斂精度.這一結果顯示,DSP在加速Jacobi迭代法時具有比肩最好算法的性能.

Fig.7 Acceleration of DSP working on Jacobi iterative method圖7 DSP對 Jacobi迭代算法的加速性能

Fig.8 Performance comparison between DSP and GMRES圖8 DSP與GMRES性能的比較
4.3 加速分布式優化算法
隨機梯度下降(stochastic gradient descent,簡稱SGD)[28]是梯度下降優化算法的一種近似算法.它通過迭代來求解目標函數的最大或最小值.大量經典機器學習算法的訓練過程都可以用 SGD來進行優化,如Perceptron[29]、Adaline[30]、k-Means[31]和SVM[32].
為了驗證DSP模型對SGD算法的加速性能,我們進行了一組簡單的驗證實驗.通過分布式的SGD算法來訓練一個簡單的線性分類器.樣本集合由維度為100的稀疏向量組成,所有的樣本點被標記為4類,其類別為非零元的位置模4運算的結果所決定.
實驗結果如圖9所示(全局同步輪數的對數先隨Δ的增加呈指數下降趨勢,隨后穩定在一個數字周圍),全局同步輪數的對數首先隨著增加的Δ呈指數級下降趨勢,隨后穩定在一個值的周圍.

Fig.9 Performance of DSP working on SGD圖9 DSP對SGD的加速性能
當Δ足夠大時,我們發現參數的收斂僅僅需要數輪同步就可以完成.也就是說,在參數收斂的過程中,大部分數據同步都是不必要的.分析其原因,我們認為模型的參數之間的關系也是相對稀疏的,這才導致所有參數之間并不需要嚴格的一致也能使模型收斂.
5 總結和工作展望
本文提出了一種并行計算模型,它可以顯著地減少迭代計算的輪數.對于瓶頸為通信的算法,迭代輪數的減少直接意味著通信開銷的減少,算法的收斂速度也能因此得到相應的提升.除此之外,本文還提出了一種迭代算法的形式化表示方法.使用這種方法,我們表示了BSP和DSP并行計算模型及其迭代過程,發現DSP是一種比BSP更一般的計算模型.在此基礎之上,本文進一步給出了DSP的適用條件和收斂性證明.
為了保證第3.1節中推導和證明的一般性,其中出現的符號可用于表示任意關系函數和聚合函數.我們沒有提供具體函數的收斂性證明,但通過數值分析的不動點迭代或級數的收斂推導,都可以得到與第3節中相同的結論.通過形式化的表示和推導,我們發現,DSP中增加的局部計算步可以更充分地挖掘和利用數據分區內部的局部性,加速局部收斂,進而促進全局收斂.
實驗評估部分展示了若干有趣的發現,比如,加速Jacobi迭代時,DSP模型的執行過程實際上模擬了超松弛的計算;分布式SGD的計算過程實際上只需少量的同步即可實現收斂.在通用計算集群上,DSP可以貢獻更好的性能,原因是通用計算集群的通信延遲通常會大得多.
因為DSP加速的原理是“計算換通信”,所以過多的局部計算不僅會增加節點的計算負擔,而且當迭代計算的初始負載不均衡時,負載不均衡也可能被加劇.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
