基于MobileNet的移動端城管案件目標識別算法
2019-10-23 12:23:56楊輝華張天宇李靈巧潘細朋
計算機應用 2019年8期
楊輝華 張天宇 李靈巧 潘細朋


摘 要:針對目前大量安裝的固定監控攝像頭存在監控死角,以及移動設備硬件性能較低等問題,提出一種可在較低性能的IOS移動設備上運行的城市管理案件目標識別算法。首先,在MobileNet中增加新的超參數,優化輸入輸出圖像的通道數與每個通道所產生的特征圖數量;隨后,將改進后的MobileNet與SSD目標識別框架相結合構成一種新的識別算法,并移植到IOS移動端設備上;最后,該算法利用移動端設備自帶的攝像頭拍攝案發現場視頻,實現對8種特定城管案件目標的準確檢測。該算法檢測結果的平均精度均值(mAP)與原型YOLO和原型SSD相比,分別提升了15.5個百分點和10.4個百分點。實驗結果表明,所提算法可以在低性能IOS移動設備上流暢運行,減少了監控死角,為城管隊員加速案件分類與處理提供了技術支撐。
關鍵詞:智慧城管;目標識別;MobileNet;移動設備;視頻監控
中圖分類號:?TP391.41
文獻標志碼:A
Target recognition algorithm for urban management cases by mobile devices based on MobileNet
YANG Huihua1,2, ZHANG Tianyu3*, LI Lingqiao1,2, PAN Xipeng2
1.School of Computer Science and Information Security, Guilin University of Electronic Technology, Guilin Guangxi 541004, China ;
2.School of Automation, Beijing University of Posts and Telecommunications, Beijing 100876, China ;
3.School of Electronic Engineering and Automation,Guilin University of Electronic Technology,Guilin Guangxi 541004, China
Abstract:?For the monitoring dead angles of fixed surveillance cameras installed in large quantities and low hardware performance of mobile devices, an urban management case target recognition algorithm that can run on IOS mobile devices with low performance was proposed. Firstly, the number of channels of input and output images and the number of feature maps generated by each channel were optimized by adding new hyperparameters to MobileNet. Secondly, a new recognition algorithm was formed by combining the improved MobileNet with the SSD recognition framework and was transplanted to the IOS mobile devices. Finally, the accurate detection of the common 8 specific urban management case targets was achieved by the proposed algorithm, in which the camera provided by the mobile device was used to capture the scene video. The mean Average Precision (mAP) of the proposed algorithm was 15.5 percentage points and 10.4 percentage points higher than that of the prototype YOLO and the prototype SSD, respectively. Experimental results show that the proposed algorithm can run smoothly on low-performance IOS mobile devices, reduce the dead angles of monitoring, and provide technical support for urban management team to speed up the classification and processing of cases.
Key words:?intelligent urban management; target recognition; MobileNet; mobile device; video surveillance
0 引言
隨著國內城鎮化的進程加快,城市面積的快速增大,城市管理的難度大大增加。視頻監控是城市管理的重要手段之一,尤其隨著手機等移動平臺的發展,視頻監控技術有了新的應用平臺。但基于人工進行監控來查看案件視頻,不僅耗時,且效率低[1]。因此開發一種能快速智能識別視頻中關鍵目標的實用算法,對于案件的分類、審核十分必要。
傳統的城市監控主要依賴固定監控攝像頭,可是安裝攝像頭要耗費大量的人力、物力。并且城管案件中的常見目標如被人遺棄的共享單車、垃圾桶等目標常出現在道路邊緣,甚至背街小巷,處于監控探頭的拍攝死角,因此,移動設備可以很好地彌補固定攝像頭視角有限的缺點。目前常用的深度學習目標識別方法主要有兩大類:一類是Girshick等[2-3]提出的R-CNN(Region-based Convolution Neural Network)、Fast R-CNN以及Ren等[4]提出的Faster R-CNN。此類方法檢測精度高,但運行速度慢,并且對硬件設備要求較高,很難部署到移動端設備上。第二類是Redmon等[5-7]提出的YOLO檢測框架及其后續改進YOLO9000、YOLOv3,Liu等[8]提出的SSD(Single Shot MultiBox Detector)檢測框架等。此類方法檢測速度快、實時性好,但是檢測精度欠缺。針對上述方法的缺點和固定攝像頭的監控視角缺陷,本文以IOS移動端為平臺,依靠移動設備的攝像頭拍攝案件畫面,優化了MobileNet(Efficient CNN for Mobile Vision Applications)[9],以SSD算法為基礎,將內部的VGG-16[10]基礎網絡換為可大幅降低計算量的網絡改進型MobileNet(Improved MobileNet, ImMbnet),提出一種新的識別算法。該目標識別算法能充分兼顧運算量與性能,可以在手機等硬件性能較差的移動設備上流暢運行,主要針對共享單車、窨井蓋、小廣告、垃圾桶等經常處于監控死角的城管案件高發目標。
1 移動端目標識別
圖1為手機移動端在日常工作中識別特定城管目標的流程,將訓練好的模型載入手機后,城管隊員們使用智慧城市管理系統中的公務App(Appliciation),利用手機攝像頭實時拍攝案件畫面,手機端識別出特定目標、輸出結果,并將畫面實時傳送回監控中心。
2 改進型MobileNet
2.1 基礎網絡MobileNet
MobileNet是google提出的新一代移動端卷積神經網絡 (Convolutional Neural Network,CNN)[11]模型。該模型結構較簡單,平衡了性能與流暢性,非常適合部署在手機等硬件配置不高、運算能力相對較差的移動平臺上。MobileNet的基本單元是深度可分離卷積(Depthwise Separable Convolution, DSC)[12],其改進之處在于使用分步卷積替代了經典3D卷積,減少了卷積核的冗余表達,大幅度降低了計算量。
在輸入與輸出圖像尺寸一致的情況下,如果采用DK×DK尺寸的卷積核,則傳統卷積的計算量C1是:
C1=DK×DK×M×N×DF×DF
(1)
其中:DF表示輸入與輸出特征圖的寬度與高度, M表示輸入特征圖的通道數,N表示輸出特征圖的通道數,DK 表示卷積核的長和寬。相比之下,深度可分離卷積的總計算量C2為:
C2=DK×DK×M×DF×DF+M×N×DF×DF
(2)
將兩者的乘法計算量相對比:
DK×DK×M×DF×DF+M×N×DF×DF DK×DK×M×N×DF×DF = 1 N + 1 D2K
(3)
從上式可得,深度可分離卷積與傳統卷積計算量的比值為 ?1 N + 1 D2K 。MobileNet作為基礎網絡,提取圖片特征,可以在盡可能保證性能的情況下,極大地減少運算量,因此該網絡非常適用于移動設備。
2.2 網絡參數優化
假定給定輸入圖像為3通道的224×224的圖像,VGG16網絡的第3個卷積層輸入的是尺寸為112的特征圖,通道數為64,卷積核尺寸為3,卷積核個數為128,將此傳統卷積層替換為深度可分離卷積后,由式(2)可知,深度可分離卷積的計算量為:
3×3×64×112×112+128×64×112×112=109985792
從以上結果可以看出,深度可分離卷積雖然相比傳統卷積計算量大幅減少,但其計算量對于性能較差的移動設備依然巨大。為了讓MobilNet網絡能在手機上更加流暢地運行,本文加入新的超參數,對原網絡進行優化。
首先按比例減少輸入、輸出圖像的通道數,假設輸入圖像為未經處理的RGB(Red,Green,Blue)三通道自然圖像,將每一層的輸入、輸出的通道數減少為 M′、N′。
在M′/M和N′/N的比值范圍是(0 1]的情況下,深度可分離卷積的總計算量C2可減少為:
C2= DK×DK×M′×DF×DF+M′×N′×DF×DF
(4)
但是可以明顯看出,由于去掉了圖像的部分通道,減少了圖片的特征量,會在很大程度上影響識別效果。
為了解決減少通道后識別效果變差的問題,本文在MobileNet網絡中新增加一個比例參數γ來增強識別效果。加入新參數γ 后,將每一個通道所產生的特征圖數量擴充,與原先特征圖數量的比值為 γ。圖2表示γ =2時,將每一個通道經過深度卷積后產生的特征圖復制,每一個通道經卷積生成的特征圖數量與原數量的比值為2。
此時深度可分離卷積的輸出通道數與原通道數之比為γ(γ為≥1的正整數)。特征圖的增加可以增大特征量,加強識別效果,但也會增加參數量和運算量,此時的深度卷積(depthwise Convolution, Conv dw)的計算量C3為:
C3=DK×DK×(M×γ)×DF×DF
(5)
同理逐點卷積(pointwise convolution)的計算量C4為:
C4=(M×γ)×N×DF×DF
(6)
本文采用減少圖像通道與比例參數相配合的方式,綜合運算量與性能,此時深度卷積的計算量C3是:
C3=DK×DK×(M′×γ)×DF×DF
(7)
逐點卷積的計算量C4是:
C4=(M′×γ)×N′×DF×DF
(8)
可以看出減少圖像通道,并加入比例參數項,可以在一定程度上減少計算量,并維持識別效果。令 M′ M = N′ N =α,對比原型MobileNet,運算量的對比如下:
DK×DK×(M′×γ)×DF×DF+(M′×γ)×N′×DF×DF DK×DK×M×DF×DF+M×N×DF×DF =? (αD2K+α2N)×γ D2K+N ≈α2×γ
(9)
假設所用的數據為:DF=224, DK=3,M=3, N=32。在設定α=0.5,γ=2的情況下,根據式(9),可得運算量與原型MobileNet之比為0.53。因此經過參數調整的改進型MobileNet在維持性能的同時,更加適合在低性能的移動設備上運行。表1為改進型MobileNet具體網絡結構,其中Conv表示普通卷積,Conv dw表示深度卷積,classnum表示類別數,FC表示全連接層(Full Connected,FC),Avg Pool表示平均池化(Average Pooling),本文采用全局平均池化[13](Global average Pool),s1表示步長為1,s2表示步長為2。
3 改進型MobileNet+SSD識別方法
3.1 原型SSD識別框架
SSD使用VGG-16網絡作為基礎網絡,并在網絡后添加特征提取層。這些增加的卷積層逐層減小,可以提取不同尺寸的特征圖來作檢測,尺寸較大的特征圖用于檢測物理體積比較小的目標物,尺寸較小的特征圖用于檢測物理體積較大的目標物。在每一張不同大小的特征圖上,都直接使用較小的卷積核直接卷積提取檢測結果。為了降低訓練難度,減少運算時間和所需硬件性能,SSD參考了Faster R-CNN的錨點(anchor)概念,在每個劃分好的單元,設置長寬比不同的先驗框(default bounding box)。當卷積核通過這些劃分好的單元時,預先設定的每個先驗框都輸出一套檢測值。這套檢測值包含兩部分信息:每個類別的置信度和邊界框的位置信息。
3.2 SSD框架改進
本文研究和用于訓練模型的圖像數據來源于城管隊員們在日常工作中用手機拍攝的真實案件圖片以及菜市場、街道口等城市管理案件高發區域的監控視頻。由于案件發生地不同,案件類型多樣,使得圖像的背景較為復雜,待識別的目標較多,如果使用傳統的卷積神經網絡模型,不僅訓練時間較長,而且需要性能較高的硬件設備。因此本文以SSD檢測框架為基礎,將經典的基礎網絡VGG-16換為本文的改進型MobileNet。利用改進型MobileNet模型小巧、運行參數少、運算量遠小于傳統卷積神經網絡的優勢,減少識別模型的訓練時長,降低硬件需求,使其能在手機等性能較弱的移動端設備上部署。
輸入的視頻流圖像首先進入改進型MobileNet網絡,而后進入本文在基礎網絡后添加的輔助結構。這些輔助卷積層也采用深度可分離卷積,其尺寸也是逐漸減小的。本文依然參考原本的SSD框架,除了在最終的特征圖上作檢測外,還在之前輔助層產生的特征圖上作目標檢測,同時為了確保小目標的檢測效果,檢測過程也在改進型MobileNet的第12層上作檢測,能取得較好的識別準確度。經過改進的結構如圖3所示,將VGG-16換為改進型MobileNet,后部的特征提取層換成深度可分離卷積,結構與原型SSD類似,其中DSC表示深度可分離卷積,Conv表示普通卷積。
4 實驗及結果分析
4.1 數據來源
本文用于訓練和測試的所有圖片和視頻均取自日常城市管理案件。城管隊員們使用本實驗室與南寧市青秀區合作研發的智慧城市管理系統(“城管通系統”)的手機客戶端拍攝案發現場圖片或視頻。實驗訓練采用的是英偉達DGX-1服務器,軟件系統為Ubantu14.04,移動平臺為搭載IOS(IPhone OS)系統的設備(IOS9—IOS12),使用Tensorflow1.9深度學習框架輔助訓練。本文針對不同的案件類型將待識別的目標一共分為8類:共享單車(bike,Bi)、機動車(car,Ca)、小廣告(lzt)、電動車(motor scooter,Ms)、垃圾桶(ashcan,Ac)、道路柵欄(trafficbarrier,Tb)、窨井蓋(manhole,Mh)、泄水口(raingate,Rg),構建了城市管理案件圖片數據集(City Management,citymg)。每類各取1000張圖片并標注,部分樣例圖片如圖4所示。
4.2 評價指標及結果
檢測效果的評價指標參考原型SSD的平均精度(Average Precision,AP)和平均精度均值(mean Average Precision,mAP)。
令TruePositives表示圖像中當前類的正確檢測次數,TotalObjectives表示圖像中當前類的實際目標數量,Classes表示需要識別目標的總類別數,則上述指標的計算公式如下所示:
Precision=TruePositives/TotalObjectives
(10)
AP=∑Precision / TotalObjectives
(11)
mAP=∑AP / Classes
(12)
圖5為算法在IOS移動端和PC端的識別效果,表2為本文改進框架與原型SSD和YOLO對8種城管案件目標的檢測效果。可以看出,
本文方法耗費訓練時間較少,所需硬件成本較小,即使在使用普通電腦配置(酷睿 i7,8GB內存,Tensorflow1.9),無GPU(Graphic Processing Unit)加速的情況下,使用本文的城管數據集,訓練一步所需時間為5s左右,總訓練時長為8h左右,相比之下,Faster-RCNN等傳統網絡的單步訓練時長為22s左右,總訓練時長為36h左右。因此本文方法在低性能設備上也可以訓練,相比Faster-RCNN等傳統模型,可以極大地減少訓練時間,降低設備的性能需求,非常適合于本文所應用的城市管理案件識別或其他中小型應用場景。訓練采用的損失函數與原型SSD一致,利用Tensorflow訓練,網絡訓練的收斂曲線如圖6。
從表2可以看出,經過本文改進的識別框架,對城管案件中常出現的8類目標:共享單車(Bike, Bi)、機動車(Car, Ca)、小廣告(lzt)、電動車(Motor Scooter, Ms)、垃圾桶(Ashcan, Ac)、道路柵欄(Trafficbarrier, Tb)、窨井蓋(Manhole, Mh)、泄水口(Raingate, Rg)有較好的識別效果,mAp值均超過了原型YOLO與SSD。
如圖7所示,使用iPhone6s(內存32GB,運行內存2GB,A9處理器)作為搭載平臺,城管隊員們在手機端登錄城管系統后點擊交叉拍攝按鈕,隨后點下方的案發地點按鈕,在手機全球定位系統(Global Positioning System,GPS)模塊的幫助下確定案發位置后,可以點擊相機按鈕,利用手機攝像頭拍攝案件現場實時視頻,在點擊開始拍攝的按鈕后,視頻畫面傳入識別框架,識別框架識別出類別后,將識別結果實時地輸出在屏幕上。隊員們可以將識別結果保存到手機本地,并上傳到城管通系統中,作為日后案件處理的依據,加速案件的分類與審核。
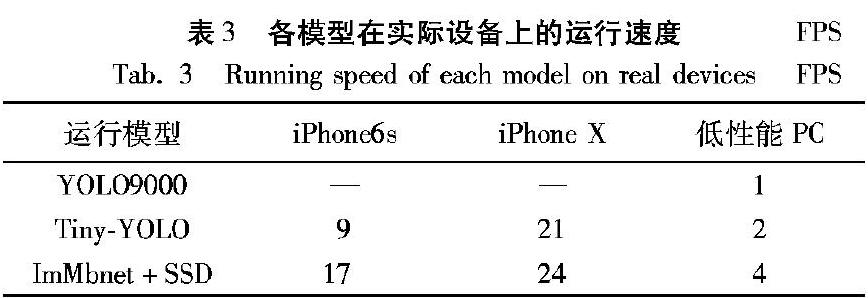
還在iPhone6s、iPhone X和低性能PC上對比了幾種識別模型的每秒傳輸幀數(Frames Per Second, FPS),結果如表3所示。可以看出,原型YOLO9000無法直接在手機設備上運行,本文改進的ImMbnet+SSD模型在運算速度上明顯優于Tiny-YOLO,并且在低性能設備如iPhone6s、低性能PC上優勢明顯。由上述實驗可以看出本文算法可以滿足實際應用需求。
5 結語
本文改進的識別算法在性能和運行成本上作了較好的平衡,可以在手機等移動端平臺或者其他硬件性能稍差的平臺上運行。通過實驗驗證,該算法對城管案件中的高發目標,有較高的檢測精度,可以輔助城管隊員對案件進行分類與處理,實現了城市管理的智能化。同時仍有大量的工作需要進一步開展來完善算法,例如:針對一些復雜的案件場景,如畫面中出現多個目標且相互重疊,如何去除遮擋物、如何快速識別在畫面中短暫出現的目標等。未來還可用手機為搭載平臺,實現路面交通線破損檢測[14],定位視頻中特定目標[15],以及對目標進行檢索[16]。
參考文獻
[1]?黃凱奇,陳曉棠,康運鋒,等.智能視頻監控技術綜述[J].計算機學報,2015,38(6):1093-1118. (HUANG K Q, CHEN X T, KANG Y F,et al. Intelligent visual surveillance: a review [J]. Chinese Journal of Computers, 2015, 38(6): 1093-1118.)
[2]?GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC:IEEE Computer Society, 2014:580-587.
[3]?GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 1440-1448.
[4]?REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks [C]// Proceedings of 28th Annual Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 91-99.
[5]??REDMON J, DIVVALA S, GIRSHICK R, et al. You only look? once: unified, real-time object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 779-788.
[6]??REDMON J, FARHADI A. YOLO9000: better, faster, stronger? [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 6517-6525.
[7]?REDMON J, FARHADI A. YOLOv3: an incremental improvement [J]. arXiv E-print, 2018: arXiv:1804.02767.
[EB/OL]. [2018-03-06]. https://arxiv.org/pdf/1804.02767.pdf.
[8]?LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 2016 European conference on computer vision, LNCS 9905. Cham: Springer, 2016: 21-37.
[9]?HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [J]. arXiv E-print, 2017: arXiv:1704.04861.
[EB/OL]. [2017-04-17]. https://arxiv.org/pdf/1704.04861.pdf.
[10]?SERCU T, PUHRSCH C, KINGSBURY B, et al. Very deep multilingual convolutional neural networks for LVCSR [C]// Proceedings of the 2016 IEEE Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2016: 4955-4959.
[11]?KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2012:1097-1105.
[12]?CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 1800-1807.
[13]?SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1-9.
[14]?陳新波,蔣崢.路面交通線破損圖像智能檢測優化研究[J].計算機仿真,2016,33(5):161-165,234. (CHEN X B, JIANG Z. Intelligent detection of damaged image for road traffic line [J]. Computer Simulation, 2016, 33(5): 161-165,234.)
[15]?杜麗娟,路曉亞.視頻監控中多視角目標智能定位追蹤方法研究[J].科學技術與工程, 2017, 17(16):270-274. (DU L J, LU X Y. Multiple points of view in the goal of intelligent video monitoring location tracking method [J]. Science Technology and Engineering, 2017, 17(16):270-274.)
[16]?付偉,王金橋,滕可振.基于深度學習的監控視頻目標檢索[J].無線電工程,2015,45(12):16-20.(FU W, WANG J Q, TENG K Z. Deep learning for object retrieval in surveillance videos [J]. Radio Engineering, 2015, 45(12): 16-20.)
