大數據時代下乳品行業數據分析
2019-10-23 03:20:26李壘郝倩
微型電腦應用 2019年10期
李壘, 郝倩
(河南工業職業技術學院 電子信息工程學院, 南陽 473009)
0 引言
隨著互聯網、物聯網、云計算技術的不斷發展,大數據成為當下最熱門的技術之一。互聯網上的信息稱為大數據的重要來源,智能終端的普及給大數據帶來了豐富、鮮活的數據,云計算是大數據誕生的前提和必要條件,大數據的出現是歷史的必然,它具有數據量大、速度快、類型多、價值高的特點[1]。 “大數據”與“小數據”的區別不在于“大”,而在于“有用”,在于是否有邊界。大數據是沒有邊界的,重點是“分享思維”“整體思維”,小數據是有邊界的,主要是“局部思維”“盲人摸象思維”。大數據時代的到來[2], 促使各行業也紛紛從自身出發,創造本行業與大數據技術深度結合的契機,尋求產業升級路徑。
國內經濟持續發展,居民收入逐步提高,帶動人們對乳制品的需求不斷增長。全球主要液體乳品消費國人均水平為23-102公斤,而我國人均乳品消費約20公斤,不足世界水平的1/5,人口老齡化的到來以及居民健康意識的增強,也將促進乳品需求的增加[3]。目前,城市乳制品銷量占到全國乳制品總銷量的90%,廣大農村乳品市場潛力巨大,有待挖掘,隨著農村乳制品消費量的逐步增長,我國乳制品行業將會迎來更加廣闊的發展空間,這也為國內的乳制品企業創造了發展的大好機遇。與此同時,對于乳業來說,每天的交易都會產生非常龐大的數據,如企業股份財務報表、品牌指數、區域崗位招聘信息等。我們需要根據數據模型,對這些數據通過進行整合、分析,挖掘出隱含在其中的有價值的信息,研判乳品行業的健康狀況及發展趨勢,進而有效地助力企業科學決策,規避風險,創造更大的持續發展優勢。
1 大數據分析流程
1.1 大數據分析概述
道德經的一句話“有道無術,術尚可求;有術無道,止于術。”闡明了數據分析的本質。數據分析就是一門“明道優術”的學科。而大數據時代的數據分析是指對規模巨大的數據進行分析[4]。大數據分析流程主要包括數據采集、數據預處理、數據分析以及數據展現幾個部分。
1.2 數據采集
大數據的采集是指利用多個數據庫來接收發自客戶端的數據,并且用戶可以通過這些數據庫來進行簡單的查詢和處理工作[5]。大數據的采集需要有龐大的數據庫的支撐,有的時候也會利用多個數據庫同時進行大數據的采集。因此對于數據庫的負載以及每個數據庫之間進行切換都存在著挑戰。數據采集的性能將會直接決定在一個給定的時間段內大數據系統能夠處理的數據量的能力。
1.3 數據預處理
由于數據獲得的方式多種多樣,數據規模也十分龐大,導致實際得到的大數據往往存在著不完整、重復、不一致性,無法直接進行數據挖掘與預測,或達不到滿意的分析結果。因此,如何對數據進行有效的清理和轉換,使之成為符合數據分析要求的數據源,是影響數據分析準確性的關鍵因素。為了提高數據分析與挖掘的質量,有必要在之前先進行數據預處理。在一個完整的數據挖掘過程中,數據預處理要花費60%左右的時間。數據預處理主要通過數據清洗、數據集成、數據變換和數據規約等方式來完成。
1.4 大數據分析
大數據時代,數據分析與挖掘是大數據處理與應用的關鍵環節,它是從大量數據中提取或“挖掘”知識,發現規律,該環節決定了大數據集合的價值性和可用性,以及分析預測結果的準確性[6]。在進行大數據分析時,應根據大數據應用情境與決策需求,選擇合適的數據分析技術,提高大數據分析結果的可用性、價值性和準確性質量。數據分析與挖掘的任務和功能一般可以分為兩大類:描述和預測。描述類挖掘主要是展現數據集中數據的一般特征。聚類分析是指將物理或抽象對象的集合分組為由類似的對象組成的多個類的分析過程。
預測類挖掘是是利用數據挖掘工具建立連續值函數模型,對已有數據進行研究得出預測結論。從技術上可分為定性預測和定量預測。定性預測是指使用者根據掌握的經驗及判斷力對將要預測的對象作出定性化的分析過程;定量預測是使用數學模型,對歷史統計數據使用數學方法得到變量間規律關系。
1.5 數據展現
數據展現是指將大數據分析與預測結果以計算機圖形或圖像的直觀方式顯示給用戶的過程,并可與用戶進行交互式處理。數據展現的目的是將分析所得的數據進行可視化,以便運營決策人員能更方便地獲取數據,更快更簡單地發現大量業務數據中隱含的規律性信息,以支持管理決策。數據展現是影響大數據可用性和易于理解性質量的關鍵因素。
2 乳業大數據分析
要得到好的大數據分析成果往往需要大量的數據規模、快速的數據處理、精確的數據分析與預測、優秀的可視化圖表以及簡練易懂的結果解釋。
以某乳品行業數據為例,采用大數據可視化分析平臺“魔鏡”為分析工具,采用大數據思維,通過分析乳品行業公司財務運營情況,品牌熱度,人員招聘等信息,對乳品行業企業的發展狀況進行多方位的分析評估,對企業實際運營管理提供有價值的數據支撐,指導企業發現問題,并提出相應的對策方案。
2.1 數據預處理
將數據源導入分析平臺,分析發現數據中存在缺失性、一致性和錯誤性數據,對這些影響分析結果的數據進行預處理。
(1)缺失數據處理
數據的缺失包括記錄的缺失和某個字段的缺失,通過對源數據處理發現,港股中大慶乳業營業收入項,銷售成本項,毛利項等都為零,進行數據清洗,如圖1(a)所示。
企業港股財報中的每股收益和員工薪酬全部為0,很明顯的數據缺失,與現實中實際情況不符,判斷為缺失值,將其刪除,如圖1(b)和(c)所示。
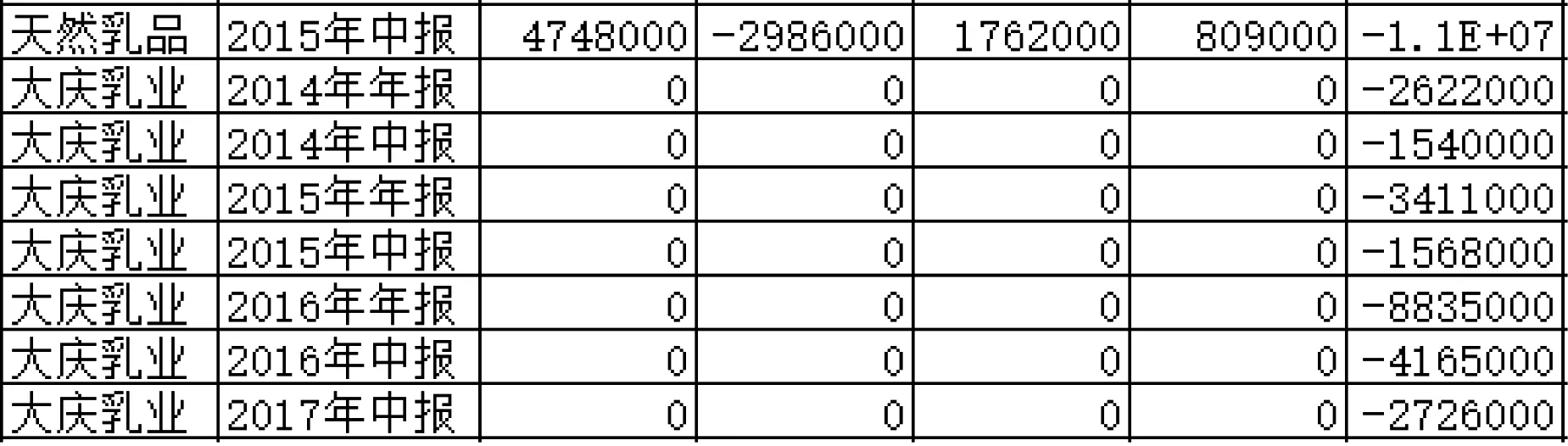
(a)
(b)

(c)
(2)重復數據處理
數據庫中屬性值相同的記錄被認為是重復記錄,通過判斷記錄間的屬性值是否相等來檢測記錄是否相等,相等的記錄合并為一條記錄(即合并/清除)。根據分析,清除數據源中的重復數據,如圖2所示。

圖2 去除重復數據
(3)數據一致性處理
由于乳企招聘信息中“學歷”字段中的“學歷大專”、“學歷:大專”和“大專”三種表達形式意思相同,而且影響分析,所以我們選擇將其統一合并為“大專”。其他學歷有同樣問題的字段我們也進行了一致性的操作。如圖3所示。

圖3 一致性處理
(4)異常值處理
港股中成本都是支出,實際應按照負數算。但是財務成本字段中存在數據為正的情況,為了不影響財務成本有關數據,將其判定為異常值予以剔除。如圖4所示。
圖4 異常值處理
2.2 數據分析及展現
(1)統計分析
利用數據分析平臺對各個乳業的乳品品牌進行分析(根據乳業近三個月的數據來進行分析),主要從整體指數、移動指數和PC指數等方面進行分析,可視化結果如圖5所示。
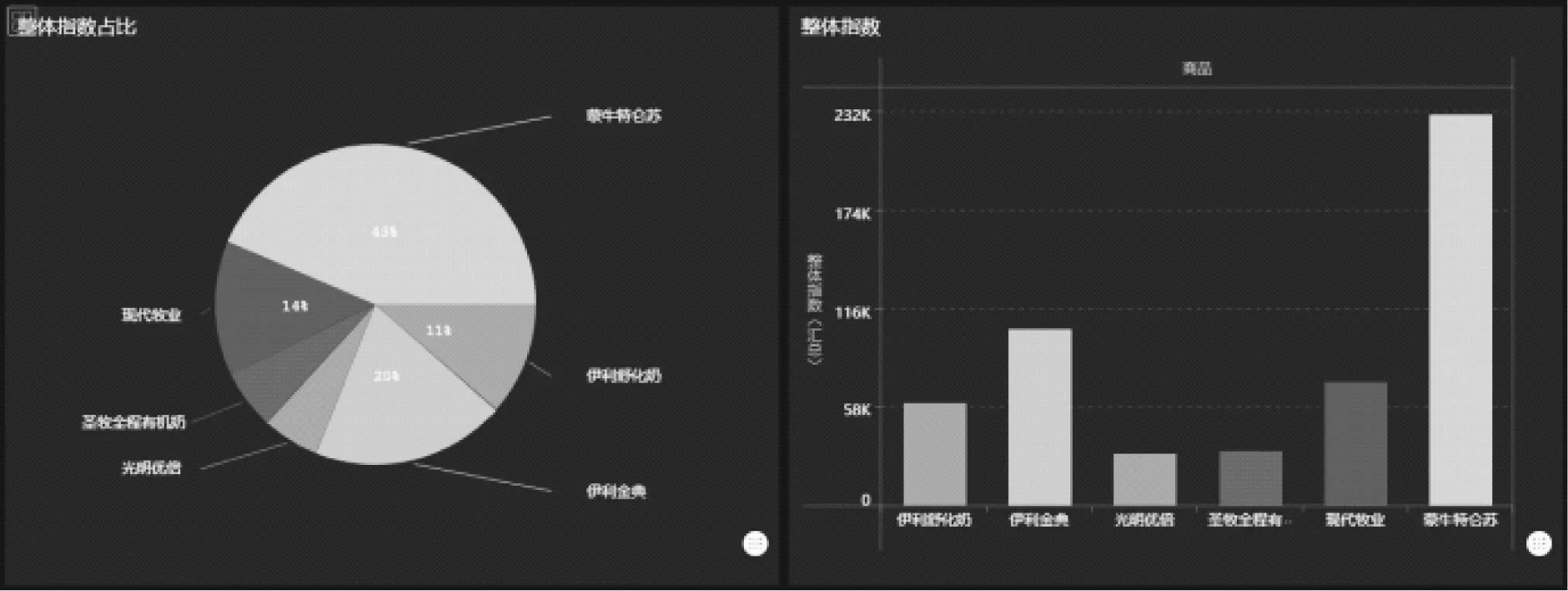
圖5 整體指數分析
整體指數代表了一個企業的整體發展水品。使用數據分析平臺對各企業商品品牌的整體指數(匯總)和各品牌整體指數占比進行分析,如圖所示。從分析結果可以看出,各商品整體指數最高的是蒙牛的特侖蘇品牌,達到了43%,所有企業中整體指數占比最為明顯。
移動指數是指在移動端搜索關鍵字的搜索量,PC指數是指在電腦端的搜索關鍵字的搜索量。將各企業品牌的移動指數和pc指數進行對比,如圖6所示。
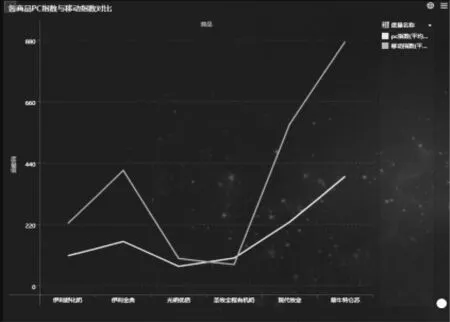
圖6 移動指數和PC指數分析
還發現除圣牧全程有機奶的pc端搜索量比移動端搜索量高之外,其他品牌都是移動端搜索量高于pc端。其中指數對比最明顯的是蒙牛特侖蘇,可以得出我國居民的搜索習慣,大部分是通過移動端來搜索。因此,對于品牌關注度高的企業繼續嚴把產品質量關,以獲得更好的口碑,關注度稍低的品牌在提高產品質量的同時,還需加強對品牌的推廣、加大對產品的宣傳力度。
創建“企業A股收入分析”儀表盤,對各乳企經營狀況,“A股收入”進行分析。如圖7所示。
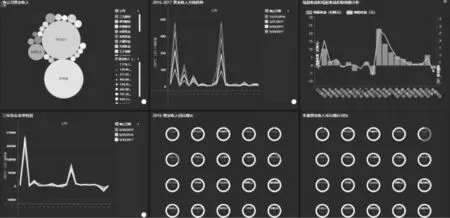
圖7 “企業A股收入分析”儀表盤
從分析結果中可以看出,乳品行業里營業收入最多的分別是伊利、新希望和光明乳業。另外,乳業產品的營業收入隨各季度會有一些變化,春秋季節光明乳業環比占到92%,然而冬夏季節環比占比為0,華資實業在冬夏季節環比占到60%,在春秋卻下降到-10%,所以需要企業在各季節經營方式做些調整。先鋒新材、新希望、燕塘乳業、皇氏集團、科迪乳業、貝因美、金健米業這些企業在春秋季節卻出現了環比負增長,這說明了企業經營狀況呈下滑趨勢。從2016的營業收入同比增長對比,可以看出與2015年同期相比大部分企業是呈上升趨勢,部分企業并無明顯增長,個別企業出現負增長,表明乳企行業近年來發展整體呈上升趨勢。
(2)數據挖掘
聚類分析按照某種相近程度度量方法,將用戶數據分成一系列有意義的子集合,每個集合中的數據性質相近,不同集合之間的數據性質相差較大。它在相似的基礎上收集數據來分類。
根據各乳業的營業收入數據,利用“魔鏡”平臺分析工具的“數據挖掘”中的聚類分析,得出分析結果,如圖8所示。
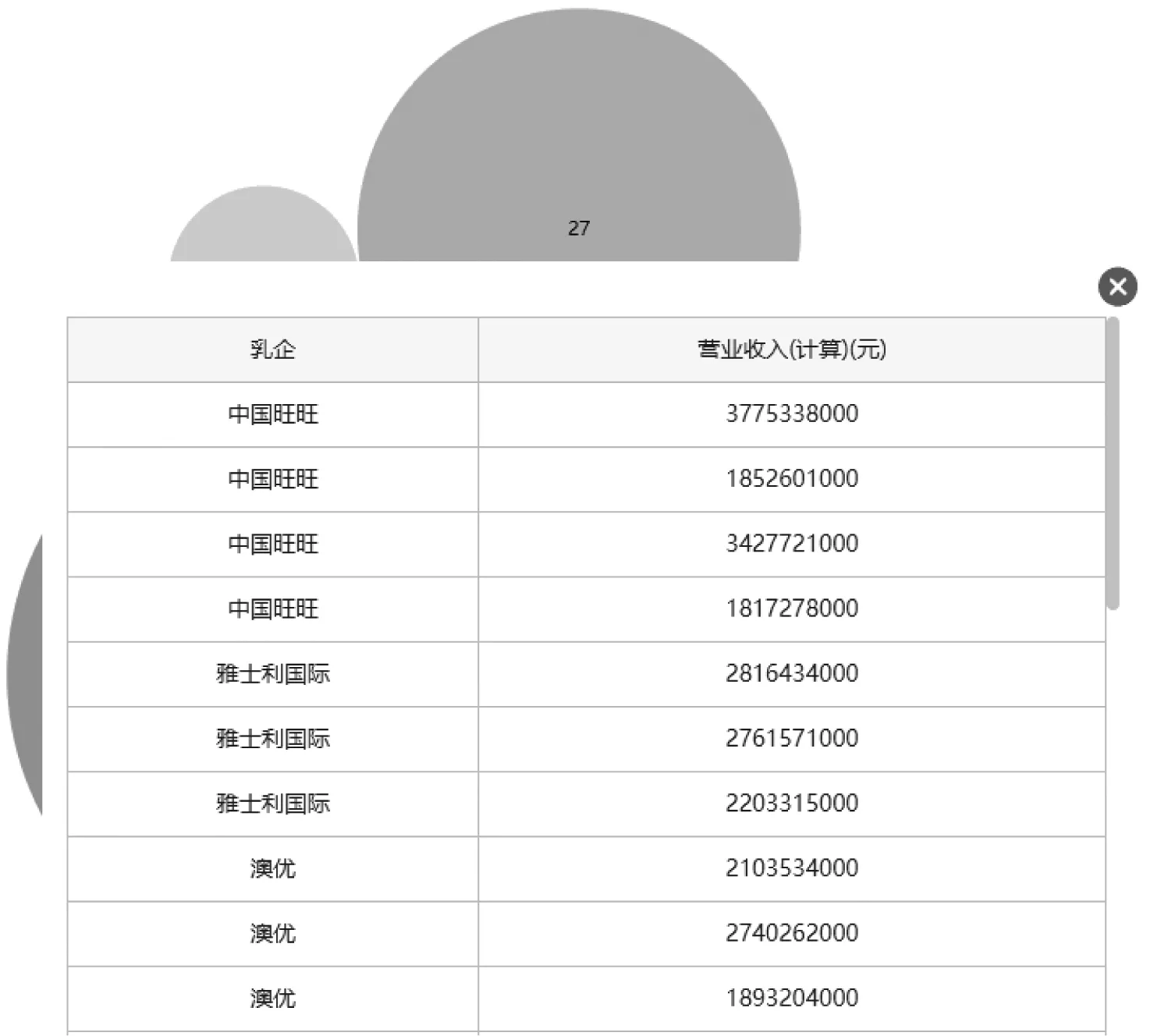
圖8 乳企營業收入聚類分析
據調查,公司的營業收入水平表現了該公司的發展前景,通過聚類把乳企營業收入進行可視化區分,對整個乳品行業的營業能力進行總覽。
相關性分析是指對兩個或多個具備相關性的變量元素進行分析,用來衡量兩個變量因素的相關密切程度。根據移動指數與pc指數數據,根據移動指數與pc指數數據,利用“魔鏡”平臺分析工具的“數據挖掘”中的相關性分析,得出移動指數與pc指數的相關性,如圖9所示。
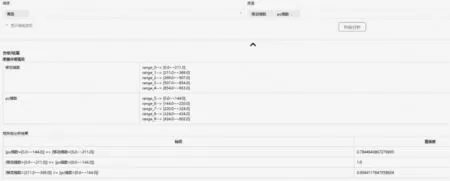
圖9 移動指數與pc指數相關性分析
從結果中可以看出,pc指數數據落入移動指數空間的置信度是0.78,屬于中度相關,而移動指數落入pc指數空間的置信度分別是0.90和1.0,屬于高度相關。
(3)對策建議
各乳企通過“互聯網+”,大數據等先進技術,對企業相關數據進行分析,有利于充分了解國內市場的需求重點,緊跟國際市場,加大產品研發投入,注重產品的升級換代。另外,在智能時代,各乳企應該加大低端崗位員工的培訓力度,提高他們轉崗和再就業的能力。而新進乳企應該提供更具特色的產品,強化自身品牌的區分度,在市場中為自己贏得一席之地。
3 總結
大數據是在互聯網時代,信息儲存和處理能力飛躍發展之后得到的一個成果,也是人工智能的基礎技術。大數據是任何企業都繞不過去的一個具有決定性意義的重要技術,必然對所有企業都造成不可忽視的影響。大數據分析為企業帶來有價值的信息,助力企業做出合理預測和科學決策。
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
云南畫報(2020年9期)2020-10-27 02:03:26
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
