基于自動化測試的定向網絡爬蟲的設計與實現
2019-10-23 03:20:26朱麗英吳錦晶
微型電腦應用 2019年10期
關鍵詞:頁面
朱麗英, 吳錦晶
(公安部第三研究所 物聯網技術研發中心, 上海 201204)
0 引言
在過去幾年中,人工智能出現了爆炸式的發展,其在交通和治安領域中的應用場景越來越多元化,其中車輛品牌、款系和年代識別功能不僅有助于套牌車輛篩查,而且正逐步發展成為刑偵工作中的重要技術手段。為實現車輛品牌、款系和年代識別功能,需要人工標注大量的訓練樣本,而人工標注過程中需要相應的車輛品牌圖片進行參考。基于建立車輛品牌參考庫的迫切需求,本文提出了一種基于自動化測試的定向爬蟲程序的設計與實現。通過自動化測試技術模擬人瀏覽網頁的方式,自動化地采集指定網頁的車輛品牌外觀圖片,從而建立一個款系、年代分類別存儲的車輛品牌參考庫。
1 網絡爬蟲技術
網絡爬蟲技術[1]又被稱為網絡機器人、網路蜘蛛,是一種按照規則,自動抓取信息的程序或者腳本,是用戶從互聯網中獲取信息資源的有效工具。通用網絡爬蟲[2]從一個或若干初始網頁的URL開始, 獲得初始網頁上的URL列表;在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入待爬行隊列,直到滿足系統的停止條件。通用網絡爬蟲的目標就是盡可能多地采集信息頁面,而在這一過程中它并不太在意頁面采集的順序和被采集頁面的相關主題。
然隨著網絡的不斷普及,網絡上的海量信息呈爆炸式增長,用戶的需求也越來越個性化,定向網絡爬蟲應運而生。定向網絡爬蟲,顧名思義就是定向爬取目標網站,該種方法只對系統指定的網址進行數據采集,通過在系統中根據目標網站的特點設定的模板,可以使系統達到很高的數據精度。另外,對于網頁更新速度快的數據源,采用增量式的采集方法也是尤為必要的[3]。增量式網絡爬蟲是指對已下載網頁 采取增量式更新和只爬行新產生的或者已經發生變化網頁的爬蟲,它能夠在一定程度上保證所爬行的頁面是盡可能新的頁面,可有效減少數據下載量,減小時間和空間上的耗費。
本文聚焦車輛品牌外觀圖片的爬取,網絡爬蟲的過程是以一個URL為初始點,獲取該網頁上的多個URL,放入URL列表進行循環獲取,直到滿足停止條件。為提高工作效率,通用網絡爬蟲會采取一定的爬行策略,常用的爬行策略[4]有深度優先策略、廣度優先策略。本文采取深度優先策略,其基本方法是從根節點出發,依次訪問下一級葉子節點的網頁鏈接,直到不能再深入為止。爬蟲在完成一個爬行分支后返回到上一鏈接節點進一步搜索其它鏈接。當所有鏈接遍歷完后,爬行任務結束。URL爬行模型如圖1所示。
2 自動化測試工具Selenium
自動化測試[5]是基于手工測試而存在的,主要通過相應的軟件測試工具、腳本等來實現,具有較好的可操作性、可重復性和高效率等特點。Selenium是一個開源的、便攜式的自動化軟件測試工具,提供一套測試函數,用于支持Web應用程序的自動化測試,函數非常靈活,能夠完成界面元素定位、窗口跳轉、結果比較等,具體有如下特點:能在不同的瀏覽器進行測試,如IE、Mozilla Firefox、Mozilla Suite、Safari、Chrome、Android手機瀏覽器等;支持多種語言,如Java、Python、C#、Ruby等;支持多種操作系統,如Windows、Linux、IOS、Android等。
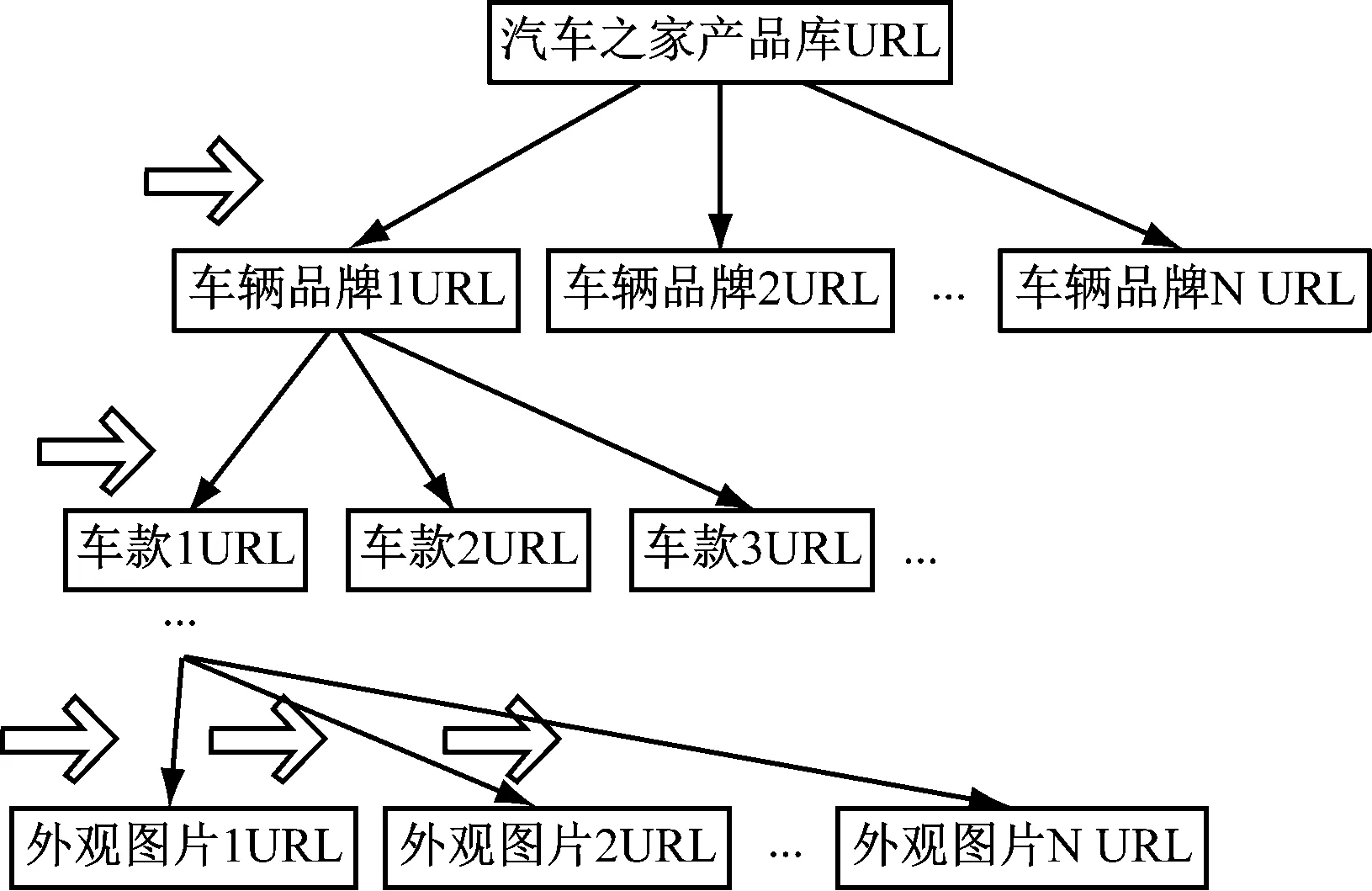
圖1 URL爬行模型
目前網頁廣泛采用JS加載、Ajax 異步傳輸、前端MVC等動態技術,這些技術對于以靜態頁面分析為主的傳統網頁爬蟲提出了新的挑戰,解決這種問題唯一的辦法是讓爬蟲自己變成一個沒有界面的瀏覽器。基于Selenium的網絡爬蟲能夠繞過某些頁面對于爬蟲的檢測和限制[6],它具有簡單、靈活、仿真性強等優點,且可進行基于無頭瀏覽器的數據抓取和捕獲,本文采用自動化測試框架Selenium,以Python語言編寫網絡爬蟲程序,模擬人操做瀏覽器的方式,采集車輛品牌外觀圖片。
3 系統的設計與實現
車輛品牌爬蟲的具體功能是對汽車之家品牌庫內的所有品牌對應的外觀圖片進行抓取,存儲到本地磁盤。圖片存儲時需按照圖片對應的品牌、款系、年份等分類別存儲,具體類別格式如“上汽大眾 凌渡 2014款 概念版”、“上汽大眾 凌渡 2015款 230TSI 手動風尚版”。另外,新車型不斷上市,汽車之家的品牌庫亦會不斷更新,為獲得新品牌圖片,需要具有對網站新變動的部分進行數據分析提取功能,達到增量式爬取的效果。
車輛品牌爬蟲整體流程如圖2所示。
啟動Selenium,以無頭方式打開Chrome瀏覽起器,并加載汽車之家品牌庫URL。
3.1 品牌款系URL提取
在頁面解析,品牌款系URL、圖片數量提取的過程中,利用了Selenium的如下特性。
1)元素查找
Selenium中元素查找共有八種方法,可通過id、name、className、tagName、linkText、partialLinkText、xpath、cssSelector定位元素,其中的xpath定位具有更大的靈活性,對于html文檔樹中某個節點既可以向前搜索,也可以向后搜索,且可采用絕對定位方式或相對定位方式。本系統中主要通過xpath、 id、linkText等方式尋找特定頁面元素,如下述方法獲取品牌樹下的所有品牌鏈接:driver.find_elements_by_xpath("http://div[@class='cartree']/ul/li/h3/a")。

圖2 整體流程
2)鼠標交互
通過Click操作頁面元素。進入子品牌頁面,“車身外觀”、“下一頁”、“查看停產車型”等的頁面切換都是通過模擬鼠標點擊操作完成。
3)異常處理
通過頁面元素查找失敗的異常捕獲,來判斷頁面上元素是否存在。
4)屬性獲取
通過元素屬性獲取方法get_attribute可獲得元素的各個屬性,如通過son_brand_ele.get_attribute('href')獲得品牌車款URL。
品牌款系URL提取的過程如圖3所示。

圖3 品牌款系URL提取過程
3.2 增量式爬取
市面上新的車型不斷上市,汽車之家網站的品牌庫亦頻繁更新,因此車輛品牌爬蟲需不定期地爬取這一網站。為避免重復數據爬取,提高爬取效率,系統增加了對網站新變動部分的數據分析提取功能,在重復爬取時,僅對變動部分進行爬取。
車輛品牌爬蟲系統在爬取過程中對品牌圖片數量進行了記錄。爬蟲啟動后,在車輛品牌款系URL提取時,同時提取了當前網站各車輛品牌款系存在的圖片數量,而上次爬取時各車輛品牌款系的圖片數量則從文件中讀取,比較兩者的一致性,當兩者不一致時,才將車輛品牌款系URL加入到URL隊列。
3.3 圖片下載存儲
每個車輛品牌的圖片數量多寡不一,每種車款對應的“車身外觀”頁面,元素“下一頁”、“查看停產車型”不一定存在,因此,通過頁面元素查找失敗的異常捕獲,來判斷頁面上上述元素是否存在。并且,每一圖片的URL是固定不變的,通過URL提取的圖片名稱也是固定不變的,因此,當重復爬取時,可通過與已抓取圖片的名稱比較,來判斷該圖片是否已被抓取,只有本地磁盤中不存在的圖片才進行抓取,圖片下載存儲流程如圖4所示。
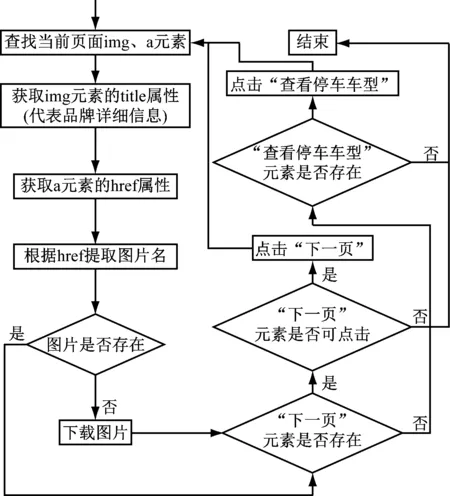
圖4 圖片下載存儲流程
4 總結
本文在充分觀察了汽車之家網頁結構之后,利用自動化測試工具Selenium,設計和實現了基于汽車之家品牌庫的定向網絡爬蟲。通過增量式的爬取,使得該爬蟲系統能夠非常高效地抓取目標數據。通過本爬蟲系統,為車輛品牌識別系統提供了相對完備的品牌參考庫。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
電腦愛好者(2022年3期)2022-05-30 10:48:04
工業設計(2016年1期)2016-05-04 03:58:09
通信技術(2012年4期)2012-02-15 07:10:35
電腦愛好者(2011年11期)2011-06-22 08:20:18
網絡安全技術與應用(2011年3期)2011-03-14 06:44:46
赤峰學院學報·自然科學版(2010年11期)2010-09-21 11:30:50
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
