融合短語知識的神經機器翻譯方法
2019-10-21 05:59:56劉璐葉娜
中文信息 2019年10期
劉璐 葉娜

摘 要:神經機器翻譯是直接利用神經網絡實現源語言文本到目標語言文本映射的一種機器翻譯方法,翻譯過程中不再需要人工設計特征。但神經機器翻譯研究單元以詞為基礎,導致神經機器翻譯的翻譯模型對短語建模不充分。針對以上問題,本文提出融合短語知識的方法,利用傳統機器翻譯訓練所得的短語表和句法分析結果,對翻譯文本進行短語對抽取,將抽取的目標語言短語以后綴的形式添加到源語言端末尾。通過改變翻譯語料的知識表示方式,使編碼產生的句向量中包含更多有利于生成正確譯文的信息,從而提升最終的翻譯效果。實驗結果表明,本文提出的方法相較于基線系統,BLEU值得到了提升。
關鍵詞:神經機器翻譯 短語知識 句法分析
Abstract: Neural machine translation is a kind of machine translation method that directly uses neural network to realize text mapping from source language to target language, and arti?cial design features are no longer needed in the translation process. However, the Neural machine Translation Research Unit is based on words, which leads to the translation model of Neural machine translation, which is not fully modeled on phrases. In view of the above problems, this paper proposes a method to fuse the knowledge of phrases, using the phrase table and syntactic analysis results obtained from traditional machine translation training, to extract the phrase pairs of translated text, and to add the form of the extracted target language phrase to the end of the source language end. By changing the knowledge representation of the translation corpus, the sentence vectors produced by the encoding contain more information which is conducive to generating the correct translation, thus improving the ?nal translation effect. Experimental results show that the BLEU value of the proposed method is improved compared with that of the baseline system.
中圖分類號:TP391文獻標識碼:A文章編號:1003-9082(2019)10-0200-02
一、引言
神經機器翻譯方法作為近年來受到廣泛關注與運用的新型機器翻譯方法,通常由編碼器、解碼器構成,編碼器將源語句編碼為實數向量表示,解碼器基于源語言表示逐詞生成對應的目標語言句子,在平行語料翻譯任務上可以實現端到端的訓練,大量實驗數據顯示其在機器翻譯領域的極大優勢。與傳統的統計機器翻譯相比,神經機器翻譯通常會產生更流利的翻譯譯文,但由于神經機器翻譯對短語建模效果不佳,會導致部分短語的翻譯結果存在不足。針對神經機器翻譯對短語建模效果不理想的問題,目前研究人員大多從解碼角度提出改進方式,但這些方法均存在著原理復雜、實現困難的問題。本文嘗試將神經機器翻譯與短語知識的優勢結合,提出一種融合短語知識的神經機器翻譯方法。
二、相關研究
針對神經機器翻譯對短語建模效果不理想的問題。大多研究人員嘗試從解碼器增強神經機器翻譯的短語建模效果。
Shonosuke Ishiwatar等人提出了基于塊的神經機器翻譯解碼器[8],將經典神經機器翻譯解碼器改進為短語解碼器和字解碼器共同組成的新型解碼器,短語解碼器模擬全局依賴性,字解碼器決定短語中字的順序。翻譯效果在WAT16英語-日語翻譯任務上得到驗證。
Jingyi Zhang等人提出了通過基于短語的強制解碼方式改進神經機器翻譯方法[9],利用現有的短語統計機器翻譯模型來計算基于短語的神經機器翻譯輸出的解碼成本,然后使用該成本來重新排列n個最佳神經機器翻譯輸出,這種方法充分發揮了統計機器翻譯和神經機器翻譯的優勢。
Leonard等研究人員提出了在混合搜索中利用短語模型的神經機器翻譯[10],該方使用統計機器翻譯短語表中的短語翻譯假設擴充了標準神經機器翻譯搜索的范圍,根據神經機器翻譯模型的注意機制,決定短語翻譯的使用,所有短語翻譯都使用神經機器翻譯解碼器打分。
可以看出,目前在神經機器翻譯系統中整合短語知識的方法主要集中于對解碼器的改進,在解碼器中集成短語生成模塊。本文則是從知識表示方面著手,不需要改變解碼器結構,且能將短語的翻譯知識有效地編碼和整合入神經機器翻譯系統。
三、融合短語知識的神經機器翻譯方法
目前的神經機器翻譯方法研究單元以詞為基礎,并未顯式地利用短語知識指導機器翻譯的翻譯過程,因此神經機器翻譯的短語建模效果不佳。針對上述問題,本文提出一種融合短語知識的神經機器翻譯方法。該方法主要基于神經機器翻譯框架,對語料采用先抽取再后綴表示的方式重新構建雙語文本,旨在使用更簡便快捷的方式將更多的短語知識反映于編碼過程中,生成知識更為豐富的向量,約束特定目標詞的產生,從而達到提升譯文質量的目的。
1.短語表生成
基于短語的統計機器翻譯方法的主要優勢之一在于對短語翻譯的建模,該模型是反映統計機器翻譯短語建模情況的概率模型。短語表的生成主要包括短語抽取和概率翻譯估計兩部分。
首先進行短語抽取,其算法的主要思想是遍歷所有可能的目標語言短語,搜索與其相匹配的最小源語言短語。在匹配過程中需要注意目標短語為空時,則不能在源語言端找到與之對應的源語言短語;目標語言匹配的最小源語言短語中存在超出目標語言短語之外的對齊點,則不能進行短語對的抽取;與目標短語匹配的最小源語言短語和其詞拓展,都可以視為對目標短語的一種翻譯。經過抽取短語獲得互譯短語對后需要進行短語翻譯概率估計,它的作用是對翻譯短語對的正確性進行合理的評估。短語表中存在著四種翻譯概率計算方法,分別是正向短語翻譯概率、正向詞匯化翻譯概率、逆向短語翻譯概率、逆向詞匯化翻譯概率。短語翻譯表中,雙語短語的翻譯概率為以上4項概率的加權和。對于同一個源語言短語存在多個目標語言短語的情況,根據翻譯概率進行排序。
2.融合短語知識的句子表示
2.1文本預處理
雙語平行語料的獲取與構建作為機器翻譯過程的首步處理流程,其質量優劣對機器翻譯質量有著不可忽視的影響。因此對于已經獲取的雙語平行語料還需要進行一些預處理,才能真正運用于翻譯模型的訓練。語料預處理過程包括分詞、文本編碼轉換、刪除過長或過短的句對。
2.2句法分析
句法結構分析是判斷給定語句是否符合語法,并分析該語句句法結構的自然語言處理技術。常用的句法分析技術分為短語結構分析和依存關系分析兩種。短語結構分析獲取整個句子的短語構成及相關的句法結構。依存句法分析則通過分析語句內成分之間的關系解釋其句法結構。
由于短語結構文法能夠清晰地刻畫出具有相對完整的語言學意義的短語成分邊界,因此本文選擇短語結構文法作為抽取雙語短語的依據。
2.3雙語短語的匹配與抽取
句法分析器的分析結果提供了源語句中各類短語的邊界信息。本文基于短語結構句法分析樹,從源語句中抽取候選短語,并與已有的短語翻譯表進行匹配后獲得具有較高概率的目標語言短語片段。
源語言短語的抽取過程為,首先遍歷句法分析樹,列舉出其中的全部短語,然后根據以下條件對短語進行過濾:
(1)為避免短語過長,設置了最大短語長度閾值10,所有超出閾值的源語言短語將被丟棄。
(2)當短語長度在合理范圍內時,對嵌套短語的處理方式是取最外層的短語。
源語言短語對應譯文的抽取過程為,遍歷所有保留下來的源語言短語,提取短語翻譯表中相應的候選譯文,從中選擇最有可能的譯文片段。篩選原則如下:
(1) 當抽取到的短語中存在禁用字符時,直接將其刪除。保證抽取的短語盡量是語言學意義上的短語,如果包含這些字符,則該短語有很大可能不是正確的譯文。
(2) 在余下的候選目標短語中,選擇概率最高的短語,作為提供給神經機器翻譯編碼器的短語翻譯指導信息。
2.4基于后綴的短語知識表示方法
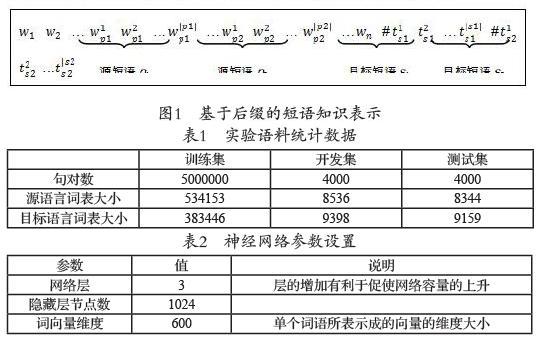
本文借鑒片段約束和短語知識在機器翻譯中存在的優勢,將概率較高的目標短語片段顯式地添加到源語句的末尾,改變源語言的語句表示方式,使神經機器翻譯解碼過程能接收到部分短語在統計機器翻譯的短語翻譯模型中的高概率譯文。圖1給出了該表示方法的示意圖。
在上圖中,wi為源語句中的第i個詞,#為原始語句和后綴的分隔符,圖中共識別和抽取出兩個雙語短語片段{p1, s1}和{p2, s2},其中pi為源語言短語,si為對應的目標語言短語。本文將目標語言端的譯文片段以后綴形式依次添加在源語句的結尾,告知神經機器翻譯系統,分隔符“#”后是譯文中應包含的短語片段。
四、實驗結果與分析
1.實驗設置
1.1語料設置
本實驗語料數據來自于聯合國公開語料庫中英雙語平行語料。獲取的原始語料包括訓練數據集15886041句,開發數據集和測試數據集均為4000句。
對原始訓練語料進行清洗、去重、限制句長,再采用隨機抽取的方式進行處理,獲取5000000中英平行語句作為最終訓練集;開發數據集與測試數據集保留原始結果,各個語料集的統計情況如表1所示。
1.2系統設置
本文的翻譯系統,建立在基于注意力的神經機器翻譯模型基礎上,以Python作為開發語言。采用的操作系統環境為Linux系統,采用的深度框架為Theano框架,模型的構建使用的是紐約大學Cho實驗室公布的開源代碼dl4mt-master。表2給出了實驗中神經網絡的主要參數設置及部分說明。
本文實驗系統采用的優化算法是隨機梯度下降算法,測試方法使用的是束搜索方法且束大小設置為10,同時在編碼器和解碼器端均使用GRU門控機制,來緩解神經網絡在訓練過程中可能會面臨的“梯度消失”問題,減少時空成本消耗。
2.對比實驗結果
本文采用的基線系統為編碼器-解碼器框架的神經機器翻譯系統,其中采用雙向GRU進行編碼,并帶有注意力機制。Ch-enp為本文提出的方法。模型1和模型2分別為不同的隨機初始化矩陣條件下的測試結果。
為了驗證本文方法的有效性,我們在長度為20個詞以下的句子上進行了對比實驗。表3給出了實驗結果。
可以看出,在融合了短語知識后,系統的翻譯效果能夠得到顯著提升。由于句長較短,匹配上的雙語短語比例相對較高,因此性能提升的幅度較大。該實驗表明基于后綴的短語知識表示方法能夠有效地指導神經機器翻譯的編碼和解碼,并能夠在訓練過程中被模型充分學習,即模型能夠理解源語句中提供的信息是目標譯文中應該包含的翻譯概率較高的片段。
五、總結與展望
本文提出了一種融合短語知識的神經機器翻譯方法,從統計機器翻譯生成的大規模雙語短語表中,獲取短語翻譯知識,進行相應的表示后,融入編碼器-解碼器神經機器翻譯框架,作為神經機器翻譯譯文生成的指導信息。該方法通過擴充源語言語句的知識表達方式,影響神經機器翻譯的編碼過程。在漢英雙語語料庫上進行的對比實驗驗證了所提出的方法的有效性。后續實驗可以從加入其他語言學知識或短語之間的句法信息進行比較分析。
參考文獻
[1]He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]. Computer Vision and Pattern Recognition, 2016:770-778.
[2]Ghemawat S, Gobioff H, Leung S T. The Google file system[J]. Acm Sigops Operating Systems Review, 2003, 37(5):29-43.
[3]Schmidhuber J. Deep Learning in Neural Networks: An Overview[J]. Neural Networks, 2015:61-85.
[4]Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[C]. International Conference on Neural Information Processing Systems, 2012:1097-1105.
[5]Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
[6]Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2015:1-9.
[7]Xiong W, Droppo J, Huang X, et al. Achieving Human Parity in Conversational Speech Recognition[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2016:99.
[8]Shonosuke I, Jing T Y, et al. Chunk-based Decoder for Neural Machine Translation[J]. 2017.
[9]Jing Y Z, ,Masao U, et al. Improving Neural Machine Translation through Phrase-based Forced Decoding[J]. 2017.
[10]Leonard D, Evgeny M, et al. Neural Machine Translation with External PhraseMemory [J]. 2017.
