基于語義擴展的多關鍵詞可搜索加密算法
2019-10-21 05:44:14徐光偉史春紅王文濤
計算機研究與發展 2019年10期
徐光偉 史春紅 王文濤 潘 喬 李 鋒
(東華大學計算機科學與技術學院 上海 201620)
現今,云存儲給數據用戶(個人和企業)提供了一個第三方服務平臺.為了節省本地存儲成本和管理成本,用戶可以將自己的數據外包到云服務器[1].但是,將數據(特別是敏感數據)直接上傳到云服務器中,使得數據擁有者將數據的管理權限完全給予云服務提供商,數據安全性不能得到保證[2].為了保證上傳數據的隱私性,目前最常用的方法是數據擁有者將數據加密后再上傳到云服務器,這帶來了新的問題:傳統的檢索技術不再適用[3].為了能夠使用戶有效地獲取加密數據,研究人員提出了可搜索加密技術(searchable encryption, SE)[4].首先,數據擁有者在上傳數據文件之前,根據數據文件來抽取關鍵詞,并建立索引.然后,將索引和數據文件加密并上傳到云服務器.當數據使用者想要獲取加密文件時,數據使用者輸入相關關鍵詞并使用相應的加密算法進行加密生成安全陷門,然后將安全陷門發送給云服務器,云服務器接收安全陷門并和索引進行匹配,最后返回相關加密文件給用戶,用戶在本地進行解密,獲得所需文件.
最近,許多研究者提出了一系列的可搜索加密算法.Song等人[4]提出了一種實現密文搜索的可搜索加密算法,但是他的算法只支持單關鍵詞搜索;Li等人[5]確定了有效模糊關鍵詞搜索加密數據的問題,利用編輯距離和通配符的方法構建模糊關鍵詞集;隨后,Cao等人[6]提出了一種安全的多關鍵詞可搜索加密算法(multi-keyword ranked search over encrypted cloud data, MRSE),利用空間向量模型和向量內積實現高效檢索;Wang等人[7]將局部敏感Hash(locally sensitive Hash, LSH)和布隆過濾器結合解決了基于多關鍵詞的模糊搜索問題;沿著這個方向,文獻[8-9]研究者提出了驗證返回結果正確性的算法.這些算法提出了不同的搜索功能,例如單關鍵詞搜索、多關鍵詞搜索和模糊搜索等;除了在功能上多樣化之外,還有一些研究者[10-11]從提高檢索密文文件的效率和準確性出發提出了基于TF-IDF算法的可搜索加密算法,并為了節省傳輸成本只返回top-k個文檔.
雖然上述算法有效解決了可搜索加密問題,但它們也存在一定的局限性.1)現有工作中大多將搜索關鍵詞視為同等重要,忽略了關鍵詞的差異性,導致關鍵詞擴展后返回的結果不能滿足用戶的搜索意圖;2)現有工作沒有考慮索引之間的關聯性,關鍵詞搜索必須遍歷所有索引,使得搜索效率較低.
因此,為了解決上述問題,我們研究了關鍵詞之間的關系,提出一種基于語義擴展的多關鍵詞可搜索加密算法(multi-keyword searchable encryption algorithm based on semantic extension, SEMSE),以搜索出滿足用戶意圖的數據文檔.此外,在搜索階段,利用凝聚層次聚類和關鍵詞平衡二叉樹的思想將相似度高的索引聚類在同一個子樹下,從而構建了一個新的索引樹結構,并通過引入剪枝參數和相關性得分閾值對索引樹進行剪枝來過濾掉大量不相關的子樹,從而大大減少了搜索時間.最后,所提算法可抵御2種不同的安全威脅.本文的主要貢獻有3個方面:
1) 考慮不同搜索關鍵詞之間的關系,提出一種關鍵詞權重算法,以區分不同搜索關鍵詞之間的重要性,利用關鍵詞權重來選出需要擴展的關鍵詞,而不是查詢中的所有關鍵詞來進行多關鍵詞排序搜索;
2) 利用凝聚層次聚類和關鍵詞平衡二叉樹思想將相似索引聚類在同一個子樹下,從而構建一種新的索引結構.然后設置剪枝參數和相關性得分閾值對索引樹進行剪枝來過濾掉大量不相關的子樹,從而大大減少搜索時間;
3) 應用真實數據集的實驗表明,與現有算法相比,我們所提的算法在保證隱私的前提下,提高了搜索效率和準確性.
1 相關工作
近些年,可搜索加密算法獲得了長足的發展,許多算法都在基于文檔的可搜索加密中提供了豐富的搜索功能.此外,可搜索加密算法分為2類:1)非對稱可搜索加密(asymmetric searchable encryption, ASE);2)可搜索對稱加密(searchable symmetric encryption, SSE).這里,我們只關注后者.
Song等人[4]第1次提出了對稱可搜索加密算法,該算法使用順序掃描密文文檔,這是首次定義了對稱可搜索加密問題并給出了解決算法,對后續研究起到極大的推動作用.但是,該算法只接收固定長度的關鍵詞且存儲復雜度比較高.Goh[12]定義了一種安全索引結構,并為自適應選擇攻擊的語義安全性建立了一種安全模型;Curtmola等人[13]針對對稱可搜索加密算法給出了安全性定義,并基于倒排索引結構提出了一種新的與文檔相關聯的索引結構;Cash等人[14]提出了一種新的支持大型數據庫的動態SSE算法;Stefanov等人[15]首次針對動態搜索加密問題提出了一種在次線性時間進行更新和搜索的解決算法,雖然該算法搜索時間是非線性的,但是隨著索引數量的增加,實際搜索時間還是非常大;通過陷門置換的方式,Bost[16]首次實現了支持前向隱私的可搜索加密算法,并推廣到任意基于索引的SSE算法中;Kim等人[17]提出了一種稱為雙字典的數據結構,該字典是一種包含前向和倒置索引的鏈接字典.為了實現前向安全性,該算法采用與前向搜索令牌無關的新密鑰來加密新添加的數據文件;文獻[17-18]提出了一些支持前向和后向安全的SSE算法,然而這些算法都支持單關鍵詞搜索.
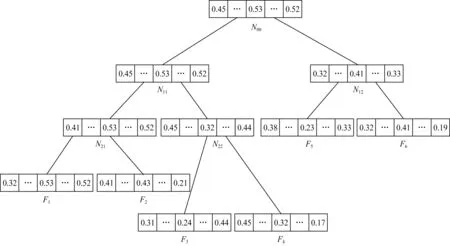
Fig. 1 Keyword balanced binary tree圖1 關鍵詞平衡二叉樹
另一方面,為了豐富搜索表達,大量研究工作集中在設計多關鍵詞可搜索加密算法.文獻[19-21]中提出的解決算法著重于如何在提供隱私保護的同時對加密數據進行多關鍵詞聯合搜索,這些算法的時間開銷和文件集的大小成線性關系.Cash等人[22]提出了一種具有可擴展性的對稱搜索加密算法,該算法將計算開銷減少到子線性,并將搜索模式擴展到布爾查詢.Cao等人[6]基于文獻[23]提出的安全kNN技術解決了支持搜索結果排序的多關鍵詞搜索問題,提出了基于向量空間模型和向量內積計算的可搜索加密算法,該算法支持2種安全威脅.為了解決多關鍵詞搜索和搜索結果排序問題,Sun等人[24]提出了一種基于詞頻的索引和余弦相似度建立的向量空間模型,以提高搜索的準確性.為了消除預定義字典的存儲開銷,Wang等人[25]通過在Bloom Filter中使用局部敏感Hash構建文件索引,并實現了文件更新,Fu等人[26]提出了支持并行計算的加密云數據的多關鍵詞排序搜索算法.Xia等人[27]在文獻[6]的基礎上提出了一種支持多關鍵詞排序搜索和動態更新的加密搜索算法,該算法利用向量空間模型和TF-IDF來實現多關鍵詞排序搜索并構建了基于樹的特殊索引結構來降低搜索的時間復雜度.
在算法中,未考慮搜索關鍵詞之間的關系和索引之間的關聯性,導致搜索結果不能滿足用戶需求,搜索的效率還有待改善.
2 預備知識
2.1 安全kNN
為了安全高效地獲得索引向量和搜索陷門之間的相關性得分,在2009年Wong等人[23]提出了一種迄今為止使用最廣泛的安全kNN算法.安全kNN的目標是將數據集中的k個最近點進行安全地識別、匹配給定的點,而不需要使用服務器來獲取數據集的內容.該算法通過計算2個向量之間的向量內積來獲得它們之間的相關性得分.文獻[6]提出了基于安全kNN算法的多關鍵詞排序搜索加密算法,并給出了安全性證明.在安全kNN算法中,首先,需要設置一個用來加密向量的安全密鑰(S,M1,M2).其中S是m位的二進制向量,由{0,1}組成,用于將向量分割成2部分,M1和M2是2個用于加密向量的可逆矩陣.
2.2 關鍵詞平衡二叉樹
2015年Xia等人[27]設計了一種基于關鍵詞平衡二叉樹索引結構(keyword balanced binary tree, KBB-Tree)的多關鍵詞排序搜索算法,并設計了一種貪婪深度優先遍歷算法,其算法的時間復雜度基本上保持為對數級,能夠實現高效的多關鍵詞排序搜索.關鍵詞平衡二叉樹的索引結構采用TF-IDF表示文檔關鍵詞的權重值,并采用向量空間模型構造一個索引向量,最后通過安全kNN算法進行加密計算相關性得分,從而返回top-k個排序結果.
如圖1所示為基于關鍵詞平衡二叉樹的索引結構.KBB-Tree的節點標識為u=(ID,I,Pl,Pr,FID).其中,ID表示節點的唯一編碼;I表示文檔向量;Pl和Pr分別表示節點u指向左孩子的節點和指向右孩子的節點;對于FID來說,如果節點是葉子節點,則FID表示文檔編號,如果節點是中間節點,則FID為空.在構建關鍵詞平衡二叉樹時,從葉子節點進行構建生成中間節點,比較2個葉子節點中的文檔向量I,將向量中取值較大的值作為中間節點中I對應向量的取值.根據這一原則逐步構建中間節點,直到生成根節點為止.
其中,N表示索引樹的中間節點,F表示文檔所在的葉子節點,中間節點的向量值為其左右孩子節點對應位向量的最大值.在搜索過程中,通過基于KBB-Tree的索引結構和貪婪深度優先遍歷算法能夠極大地節省搜索的時間開銷,提高搜索效率.但是當輸入關鍵詞字典中不存在關鍵詞時,該索引結構會線性地執行遍歷操作,致使搜索效率大大降低.
2.3 依存句法
依存句法(dependency grammar)的主要用途是分析句子的句法結構,從而更好地理解句子的含義[28].依存句法具有一個一般性的假設,即句法結構本質上包含詞和詞的關系,這種關系被稱為依存關系(dependency relations)[29].在依存句法中,能夠準確識別出關鍵詞的詞性以及句子中關鍵詞之間的支配和從屬的關系,其中屬于支配地位的關鍵詞稱為支配詞(head),處于被支配地位的關鍵詞稱為從屬詞(dependency)[28].句子中各關鍵詞之間的關系是單向的,并通過語義弧鏈接它們之間的依賴關系.對于句子中關鍵詞的依存關系,需符合4條公理.
1) 句子中有且僅有一個關鍵詞是獨立的;
2) 其他關鍵詞必須依存于另一個關鍵詞;
3) 任何關鍵詞不能同時與2個關鍵詞之間存在依存關系;
4) 如果2個關鍵詞A和B之間存在依存關系,而這2個關鍵詞之間還有其他關鍵詞C,則該關鍵詞C只能依存于關鍵詞A或B,或者依存于A和B之間的其他關鍵詞.
與短語結構句法不同,依存句法中不存在短語節點,只考慮句子各成分之間的依賴關系,如圖2所示為以“Information security is very important”為例的依存句法結構依賴關系圖.
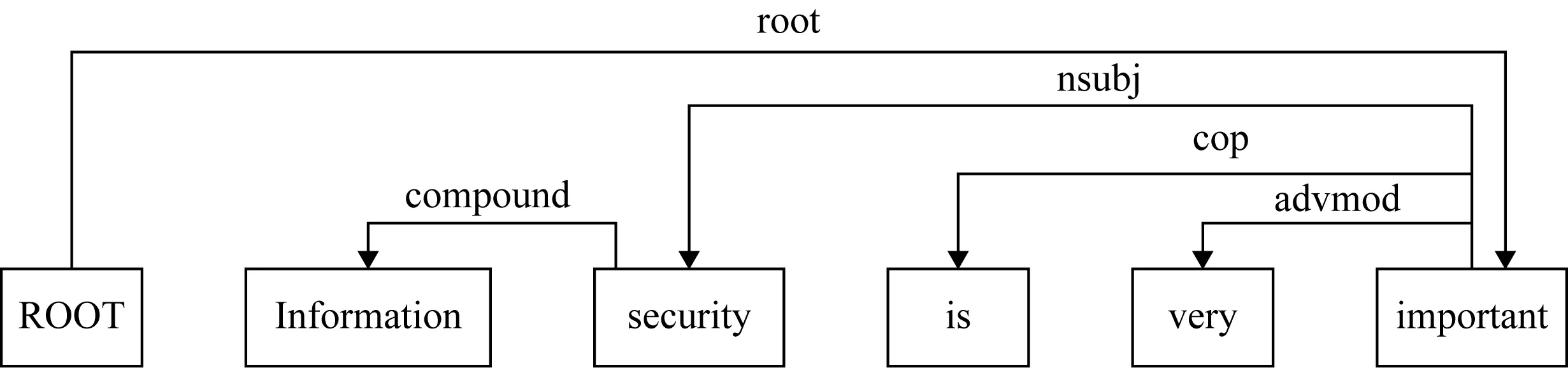
Fig. 2 Dependency grammar structure圖2 依存句法結構
其中,root表示根節點關系,compound表示補語關系,nsubj表示名詞主語關系,cop表示系動詞關系,advmod表示狀語關系.
3 模型與問題描述
3.1 系統模型
如圖3所示,本系統模型主要分為3個不同實體:數據擁有者、數據使用者和云服務器.
1) 數據擁有者.在數據文檔F={F1,F2,…,Fn}外包給云服務器之前,首先對數據文件提取關鍵詞W={w1,w2,…,wm} 并采用安全密鑰SK加密關鍵詞構建安全索引I={I1,I2,…,Im}.然后,采用對稱加密算法加密數據文檔生成加密數據集C={c1,c2,…,cn}.最后,將加密數據集C和安全索引I一同上傳至云服務器并將對稱密鑰sk和安全密鑰SK發送給數據使用者.
2) 數據使用者.首先,接收從數據擁有者發送的對稱密鑰和安全密鑰;然后,在本地輸入一定的關鍵詞進行搜索,使用安全密鑰生成安全陷門T并將安全陷門T發送給云服務器;最后,獲取云服務器返回的加密數據文件,并利用對稱密鑰進行解密.
3) 云服務器.云服務器存儲數據擁有者發送的加密數據集和安全索引,并為數據使用者提供數據搜索服務等.當數據使用者發送安全陷門給云服務器時,云服務器利用指定算法將安全陷門和安全索引進行匹配,并返回top-k個密文給數據使用者.
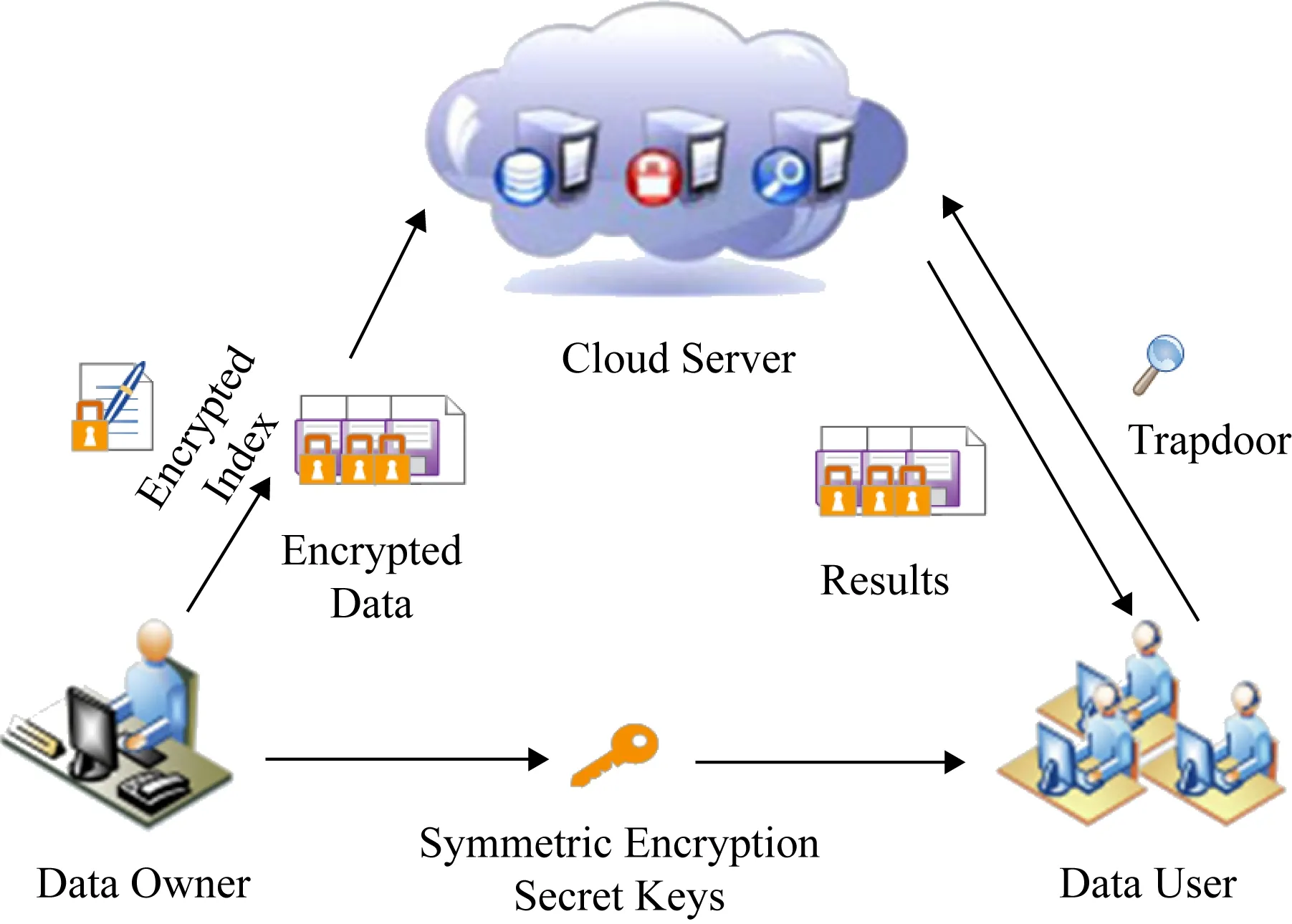
Fig. 3 System model圖3 系統模型
為了便于描述多關鍵詞可搜索加密算法,表1給出本文使用到的符號定義.
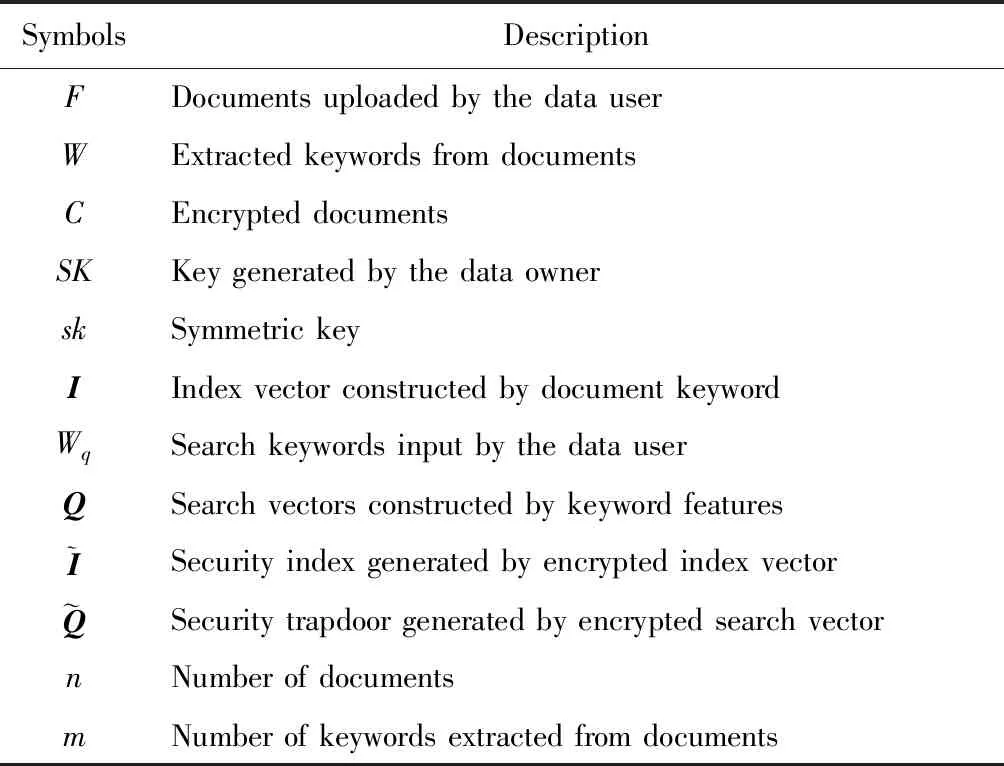
Table 1 Symbol Definition表1 符號定義
系統模型包括5個多項式時間算法SSE={KeyGen,BuildIndex,TrapdoorGen,Search,Decrypt},具體過程為:
1) 初始化KenGen(1λ)→(SK,sk).是一個由數據擁有者執行的概率密鑰生成算法,該算法將安全參數λ作為輸入,然后輸出密鑰SK={S,M1,M2}和對稱密鑰sk.
2) 索引構建BuildIndex(sk,SK,F)→(I,C).是一個概率算法,將密鑰SK和外包文檔集F作為輸入,對文檔集進行關鍵詞提取,生成關鍵詞字典W,并構建關鍵詞索引,然后使用密鑰SK加密索引向量和使用對稱密鑰sk加密文檔集F.算法輸出安全索引I和密文集C.
3) 陷門生成TrapdoorGen(Wq,SK)→T.是一個概率算法,該算法將密鑰SK和搜索關鍵詞Wq作為輸入,利用密鑰SK對搜索關鍵詞進行加密生成安全陷門T,算法返回安全陷門T.
4) 搜索Search(I,T,k)→Ck.是一個由云服務器執行的確定性算法,該算法將安全索引I、安全陷門T和需要返回文檔的個數k作為輸入,計算安全陷門和安全索引的向量內積作為相關性得分,并對相關性得分進行排序.云服務器返回包含top-k個密文的文檔集Ck給數據使用者.
5) 解密Decrypt(Ck,sk)→Fk.是一個確定性算法,該算法將密文文檔Ck和密鑰sk作為輸入,數據使用者通過對稱密鑰sk對加密文檔集Ck進行解密,算法返回明文數據集Fk.
3.2 安全威脅
采用文獻[6,25,27]中提出的安全威脅,假設數據擁有者和數據使用者是可靠的,而云服務器是“誠實且好奇的”,即它會“誠實地”根據算法的指定協議存儲數據擁有者的數據文檔,但對存儲的數據“感到好奇”,即云服務器想通過推斷或分析加密數據和安全陷門信息來獲取數據所有者的數據信息.

2) 已知背景模型.在已知背景模型中,云服務器能夠獲取比已知密文模型更多的數據信息,比如與安全陷門相關的信息或者數據集之間的統計信息等.因此,云服務器具有更強的攻擊能力.云服務器可以根據已知的陷門信息,并借助一些統計信息來推斷,分析上傳的安全陷門、安全索引和搜索結果等來確定搜索中的某些關鍵詞的明文信息.
3.3 問題描述
1) 現有的算法都是將搜索關鍵詞彼此之間視為同等重要,忽略了關鍵詞的重要性的不同,導致關鍵詞擴展后搜索準確率較低.
2) 現有多關鍵詞可搜索加密算法在構建索引的過程中沒有考慮索引之間的關聯性,關鍵詞搜索必須遍歷所有索引,使得搜索效率較低.
4 基于語義擴展的多關鍵詞可搜索加密
本文提出一種多關鍵詞陷門生成方法,以區分不同關鍵詞權重,然后詳細描述了多關鍵詞排序搜索過程,最后給出了SEMRS算法的具體實現.
4.1 多關鍵詞陷門生成
1) 關鍵詞權重計算
用戶進行搜索時,輸入的關鍵詞存在一定的句法關系,即關鍵詞之間存在修飾和被修飾的關系.因此,關鍵詞之間的句法關系一定程度上反映出關鍵詞的重要性.此外,如果一個關鍵詞和不止一個關鍵詞之間具有句法關系,則該關鍵詞具有更大的重要性.
因此,將搜索關鍵詞之間的句法關系視為關鍵詞重要性的表現形式.對搜索關鍵詞之間的句法關系進行分析,如果存在句法關系,則增加關鍵詞權重.
定義1.關鍵詞關系.對于每個關鍵詞來說,設初始關鍵詞關系為1,如果該關鍵詞和其他關鍵詞之間具有句法關系,則其權重變為1+R,其中R表示2個關鍵詞之間的句法關系.
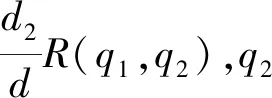
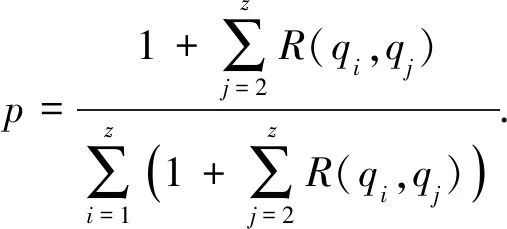
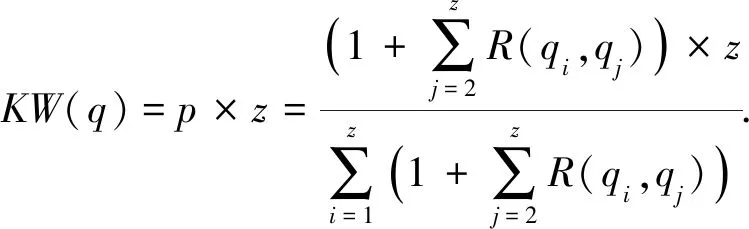
(1)
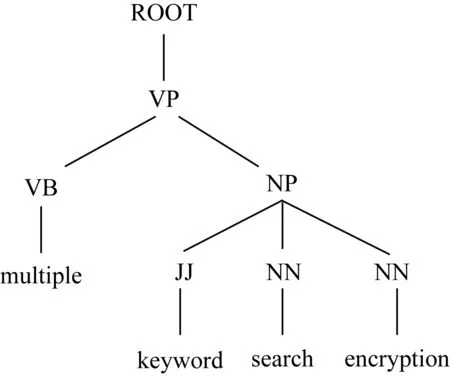
Fig. 4 Keyword phrase structure tree圖4 關鍵詞短語結構樹
然后將結構樹轉換為依存句法結構,獲取關鍵詞之間的句法關系,如圖5所示:
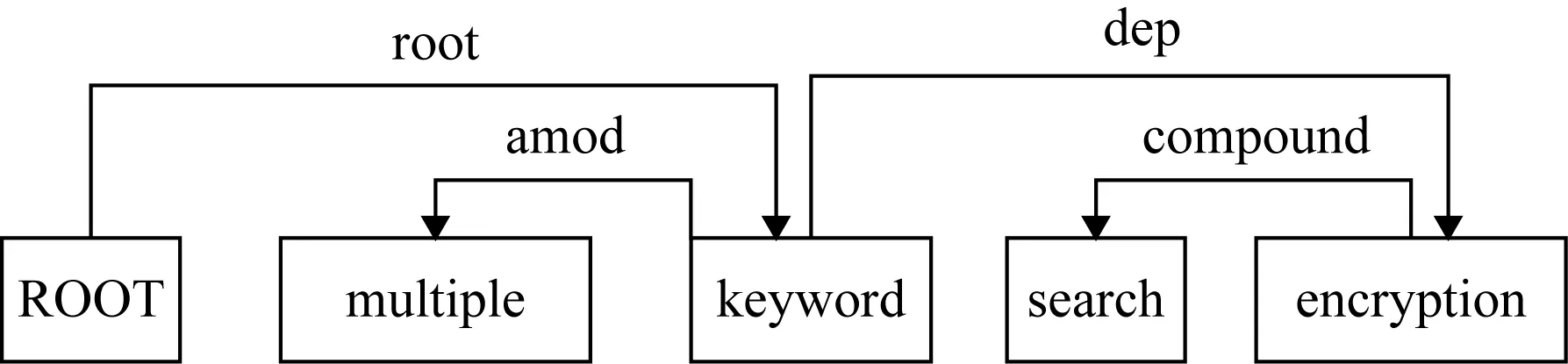
Fig. 5 Keyword dependence relations圖5 關鍵詞句法關系
其中,“root”表示依存句法結構的根節點關系,“amod”表示形容詞修飾語,“compound”表示名詞復合修飾語,“dep”表示依賴關系,“NP”表示名詞短語,“NN”表示常用名詞單數形式,“JJ”表示形容詞、數字和序號等.我們采用關鍵詞之間的句法關系和短語結構樹中關鍵詞之間的距離來衡量關鍵詞的權重,例如“encryption”和“multiple”的距離為5,則它們之間的句法關系為R(amod)=1ln 5.根據上述規則,可以得出總的關鍵詞關系為4+1ln 4+1ln 4+1ln 4+1ln 5=6.785,而“multiple”的關系為1+1ln 4+35ln 5=2.094,然后利用關鍵詞權重式(1)可知,“multiple”的關鍵詞權重為KW(multiple)=1.23.同理,其他關鍵詞的權重分別為KW(search)=0.81,KW(keyword)=1.01,KW(encryption)=0.95.
2) 多關鍵詞的語義擴展
對關鍵詞進行擴展,不是對所有關鍵詞進行擴展,而是通過關鍵詞權重計算方法選出權重最大的關鍵詞作為待擴展關鍵詞,然后根據WordNet[31]獲取關鍵詞的同義詞,這樣對于每個待擴展的關鍵詞都構建了一個同義詞集,最后通過2個關鍵詞概念之間的最大語義相似度近似2個關鍵詞的語義相似度,即:
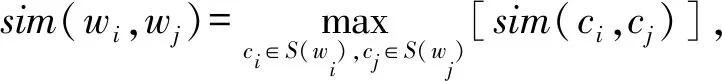
(2)
其中,S(wi),S(wj)是關鍵詞wi和wj所包含概念的集合.這里,采用基于信息內容(IC)的David算法[32]來衡量2個概念之間的相似度.
3) 陷門生成
為了更好地反映關鍵詞和文檔的關系,在關鍵詞權重中引入了TF-IDF技術,對于每個文檔關鍵詞w,如果其在關鍵詞詞典中,則將關鍵詞權重設置為關鍵詞權重值和該關鍵詞在文檔中的逆文本頻率IDF的乘積,即KW×IDF,代替基于原關鍵詞權重值,將擴展關鍵詞的權重值設置為其語義相似度得分、對應的搜索關鍵詞的權重和逆文本頻率IDF三者的乘積,即KW×sim×IDF.
4.2 多關鍵詞排序搜索
1) 基于凝聚層次聚類的索引構建
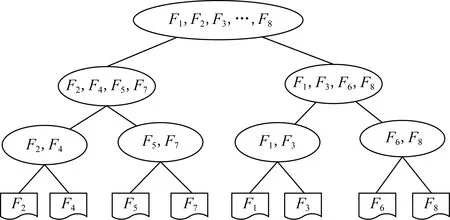
Fig. 6 Index tree construction process圖6 索引樹構建過程
在對文檔加密之前,需要構建文檔的索引,Xia等人[27]提出了基于KBB-Tree的索引結構,相比于線性掃描的MRSE算法[6],通過構建索引樹的方式確實大幅提升了搜索效率,但是該算法沒有考慮索引之間的關聯性,使得相似度高的索引隨機分布在索引樹的各個子樹中,導致多關鍵詞搜索必須遍歷所有索引才能最終確定搜索結果.因此,基于凝聚層次聚類(agglomerative hierarchical clustering)[32]的思想將相似索引進行聚類為一個平衡二叉樹索引結構.凝聚層次聚類通常是指將每個對象都作為一個單獨的聚類簇,然后每一次聚類最相關的2個簇,直至將所有簇聚類為一個簇為止.由于每次僅聚類2個最相關的簇,使得構成樹的高度非常大,不利于遍歷整棵樹.因此,在每一輪的聚類操作中,根據簇集合中簇中心向量的歐幾里德距離兩兩合并,從而構成平衡二叉樹形式,其中簇中心向量指簇集合中各節點的均值,如圖6所示為索引樹構建過程.為了便于描述索引樹的構建,先給出了索引樹節點的數據結構.
定義2.索引樹節點的數據結構.設索引樹節點的數據結構由四元組FID,NV,NL,NR組成.其中,FID表示文檔的唯一標識符,NV表示該節點的節點向量,NL表示該節點的左孩子,NR表示該節點的右孩子.如果節點u是葉子節點,則FID是文檔的唯一標識,NV是文檔的索引向量,NL和NR為空;如果節點u是中間節點,則FID為空,NL和NR表示節點的左孩子和右孩子,左孩子NL和右孩子NR的簇向量最大值為
NVi=max{NL.NVi,NR.NVi}.
(3)
如圖6所示為索引樹構建過程,索引樹的構建的基本思想是:首先,根據定義4索引樹節點的數據結構,創建葉子節點;然后根據凝聚層次聚類生成中間節點直至根節點,具體過程為:
假設8個文檔向量{F1,F2,…,F8},根據定義4構建索引樹的葉子節點{u4,1,u4,2,…,u4,8},SV表示簇中心,N表示節點u包含的節點個數,則簇中心為
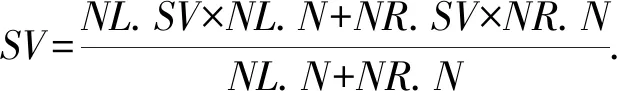
(4)
(1) 計算葉子節點簇中心之間的歐幾里德距離為
(5)
將歐幾里德距離最小的2個節點進行聚類生成一個簇,該節點的節點向量NV的計算如式(3),簇中心的計算如式(4).然后再計算剩余節點簇中心的歐幾里德距離,并聚類最小的2個簇,直至聚類所有節點.聚類后的簇為Cu3,1={F2,F4},Cu3,2={F5,F7},Cu3,3={F1,F3}和Cu3,4={F6,F8}.
(2) 根據步驟1的過程,依次對階段1生成的簇進行聚類,聚類之后的簇為Cu2,1={F2,F4,F5,F7}和Cu2,2={F1,F3,F6,F8}.
(3) 根據步驟2的過程,對階段2生成的簇進行聚類,生成索引樹的根節點.

2) 多關鍵詞的排序搜索
由于通過凝聚層次聚類構建索引樹使得相關的索引位于同一個子樹中,在索引遍歷過程中只需根據搜索關鍵詞和索引的相關性得分找出對應的簇就能實現整個遍歷過程,而無需遍歷整個索引樹.因此,設置一個剪枝參數PT和一個相關性得分閾值sysp來過濾不相關的子樹,其中剪枝參數可以根據用戶不同偏好設置,相關性得分閾值是結果集中相關性得分最小的取值.通過索引樹的構建可知,中間節點的節點向量是該節點的左孩子和右孩子的節點向量的最大值,即如果中間節點的節點向量和搜索關鍵詞的相關性得分小于剪枝參數PT和相關性得分閾值sysp,則以該節點為根節點的索引樹的所有節點與搜索關鍵詞的相關性得分都小于剪枝參數PT和相關性得分閾值sysp,對該索引樹進行剪枝.
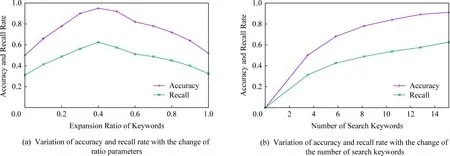
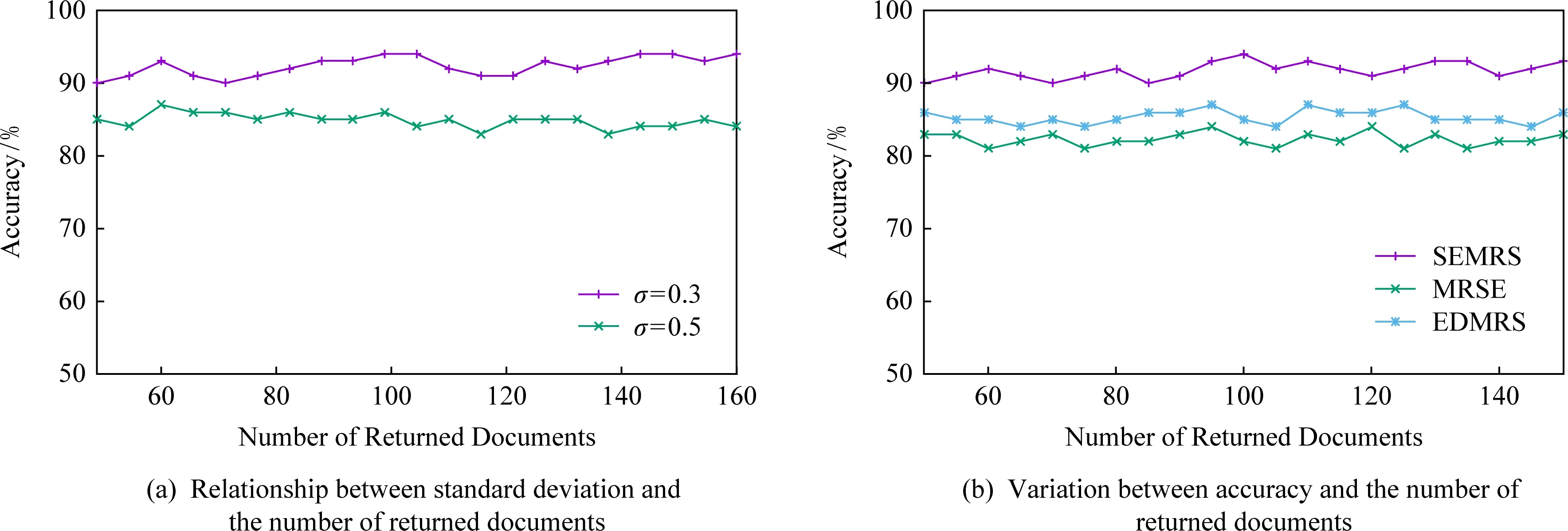
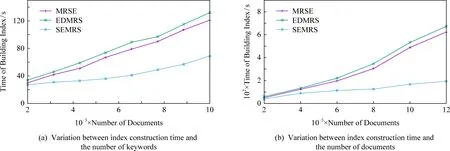
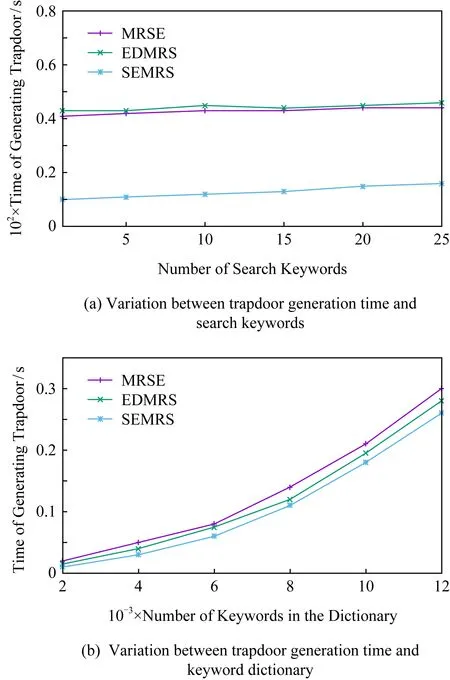
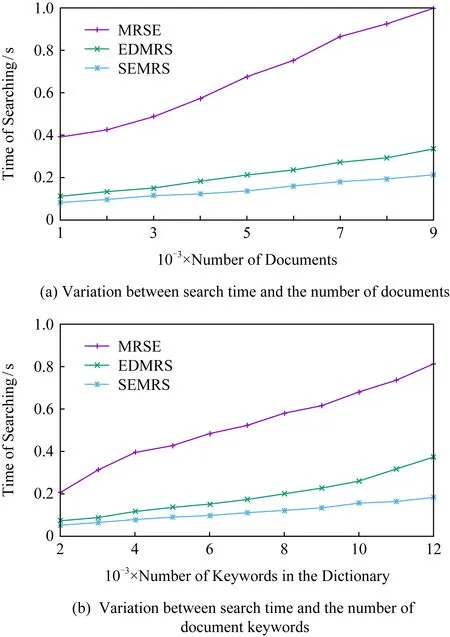
如圖7所示為關鍵詞搜索過程,設索引樹包含8個文檔,返回的文檔個數為5,搜索向量為Q=(0.3,0.6,0,0.1),關鍵詞搜索路徑為虛線箭頭所指方向.首先,搜索葉子節點u4,1,并計算搜索向量Q和葉子節點簇向量的相關性得分.然后判斷相關性得分Score(Q,u4,1.NV) 是否大于剪枝參數PT,如果大于剪枝參數,則F2插入結果集中.繼續遍歷葉子節點u4,2,相關性得分Score(Q,u4,1.NV)>PT,將F4插入結果集Rlist中.繼續遍歷其他子樹,當結果集Rlist={u4,1,u4,2,u4,3,u4,4}時,結果集中節點個數為4,小于需要返回的文檔數,繼續判斷剩余節點得出Score(Q,u4,1.NV) Fig. 7 Keyword search圖7 關鍵詞搜索過程 由于剪枝參數和相關性得分閾值的設置并沒有返回數據使用者想要返回的5個文檔而是返回了最為相關的4個文檔,且在進行關鍵詞搜索過程中并沒有遍歷所有節點,而是對于中間節點的相關性得分較小的子樹進行剪枝,這樣極大地節省了遍歷時間. 本節基于語義擴展的多關鍵詞排序搜索算法主要包括6個部分:GenKey,BuildIndexTree,Query-Extension,GenTrapdoor,Search和Decrypt. 1) 初始化GenKey(k)→(SK,sk) 3) 關鍵詞擴展QueryExtension→We 首先,根據關鍵詞權重計算方法計算搜索關鍵詞Wq的權重,并選出需要擴展的關鍵詞.然后,根據基于語義相似度的關鍵詞擴展算法提取關鍵詞的同義詞集,將關鍵詞轉換為概念,并構建概念層次樹,計算關鍵詞之間的語義相似度.最后,選出相似度最大的若干關鍵詞作為擴展關鍵詞,并將擴展關鍵詞和搜索關鍵詞一起作為搜索關鍵詞We. Score=·=(MT1I′)TM-11Q′+ 6) 解密Decrypt(C,sk)→F 數據使用者接收到云服務器返回的密文文件,使用對稱密鑰sk對密文文件C進行解密來恢復原文件的內容. 基于語義擴展的多關鍵詞排序搜索算法具體如算法1所示. 算法1.SEMRS算法. 輸入:剪枝閾值PT、相關性得分閾值sysn、需要返回的文檔個數k; 輸出:明文F. ① 初始化密鑰參數x; ②SK,sk←Getkey(x); ③ fori=1;i≤n;i++ do ④u←createNode(Fi,SK); ⑥ end for ⑦We←queryExtension(Q); ⑨ for the nodeudo 在算法1中,行①是生成密鑰的過程,行②~⑤是構建索引的過程,行⑥~⑦是生成安全陷門,行⑧~是多關鍵詞搜索,如果中間節點的相關性得分小于剪枝參數和得分閾值,則進行剪枝,行~是對服務器返回的結果集進行解密. 本節將分別從已知密文模型和已知背景模型來分析所提算法的安全性. 1) 已知密文模型中的安全性 (7) 其中,Ip包含2×n×|Ip|個未知數,可逆矩陣M1和M2分別包含n×n個未知數.通過式(7)可以得出方程組中僅包含2×n×|Ip|個方程式.根據行列式的性質可知,當未知數的數量大于方程式的數量時,不能計算出方程式的解,即根據式(7)得不到可逆矩陣M1和M2.同理,通過安全陷門也得不到可逆矩陣M1和M2.因此,本算法采用的拆分索引和搜索向量的加密機制能夠保證數據的隱私性. 2) 已知背景模型中的安全性 在已知背景模型中,數據加密和索引及陷門的加密使用的是相同的加密方法.此外,在已知背景模型中引入了虛擬關鍵詞.因此,SEMRS算法保證了數據的安全性與索引和陷門的安全性. 為了進一步驗證算法的性能,本節分別從算法的各主要階段:1)系統初始化;2)索引構建;3)陷門生成;4)搜索等方面進行分析.假設加密算法采用傳統的對稱加密算法,文檔關鍵詞的數量為n,文檔集中包含文檔的個數為m,搜索關鍵詞個數為x,擴展的關鍵詞個數為y,分析: 系統初始化階段,僅進行密鑰生成,因此該階段的時間復雜度為O(1). 索引構建階段,主要時間消耗為索引加密,先采用的安全kNN算法對索引進行分割,然后使用2個可逆矩陣相乘進行加密,其安全索引構建的時間復雜度為O(me2),其中e是關鍵詞向量的長度. 陷門生成階段,安全陷門的生成與安全索引構建過程相似,主要時間消耗都是關鍵詞加密和關鍵詞擴展,其時間復雜度也是O((x+y)e2). 此外,由于擴展關鍵詞個數y應小于搜索關鍵詞個數x,且x+y?m.在陷門生成時,無論搜索關鍵詞集合中有多少關鍵詞,陷門長度始終等于所提取文檔關鍵詞字典長度.算法主要的網絡通信開銷是傳輸安全陷門T到云服務器的開銷,由于在本地無論輸入多少關鍵詞,使用安全密鑰生成陷門T的大小|T|始終是固定的,因此,即使面對大規模數據集合,陷門傳輸的通信開銷始終為|T|. 實驗采用Java語言編寫,并在AMD5 CPU 2.0 GHz的Windows 10環境執行.數據集為聯邦能源監管委員會發布的包含517 000多條郵件的Enron email dataset[33]. 為了表現擴展關鍵詞數量的影響,設擴展關鍵詞和原搜索關鍵詞之間的比率參數為ρ,其中ρ∈[0,1].即最少關鍵詞擴展數量為0,最多關鍵詞擴展為原關鍵詞的個數.如圖8(a)所示,橫坐標為擴展關鍵詞和原搜索關鍵詞之間的比率參數ρ,步長為0.1,縱坐標為搜索準確率.設返回的文檔數為50,數據使用者搜索相關的文檔數量為80,則從圖8(a)中,可以得出隨著比率參數ρ的增加,搜索準確率逐漸上升,直至比率參數為0.4時,準確率和召回率達到最大值,隨后準確率和召回率開始逐漸降低,即在基于多關鍵詞擴展的排序搜索算法中當比率參數為0.4時,搜索性能達到最優. Fig. 8 Accuracy and recall圖8 準確率和召回率 圖8(b)所示為隨著搜索關鍵詞的變化,準確率和召回率的變化趨勢.隨著搜索關鍵詞的不斷增加,SEMRS的準確率和召回率也不斷提高,即搜索關鍵詞的數量越多,則搜索結果越能夠滿足需求. Fig. 9 Precision change under standard deviation圖9 在不標準差下準確率變化趨勢 Fig. 10 Index building time comparison圖10 索引構建時間比較 索引構建階段主要執行索引構建和索引加密.其中索引構建的計算成本主要取決于數據集中的文檔個數,而索引加密又與關鍵詞字典包含的關鍵詞數量有關.此外,索引構建過程是一個一次性過程,即只在初始階段進行索引構建,除非后續對數據集進行了更新操作,才重新構建索引.圖10(a)顯示了本算法和EDMRS算法[27]在給定不同文檔數量情況下,索引構建時間開銷的變化趨勢.由于關鍵詞數量越大,則索引向量的維度也就越大,因此通過觀察可以發現,隨著關鍵詞數量的增加,索引構建時間也越來越大.圖10(b)為在給定關鍵詞數量的情況下,索引構建時間隨著文檔數量的變化趨勢.隨著文檔數量的不斷增加,索引構建時間也在增加,但SEMRS采用將索引向量分塊的方式減少計算復雜性,大大減少了索引加密時間和索引創建時間. Fig. 11 Trapdoor generation time圖11 陷門生成時間 陷門生成是關鍵詞搜索的重要步驟,如圖11所示為陷門生成關鍵詞數量的變化趨勢.不難發現,陷門生成時間趨向于一個常數,不會隨著搜索關鍵詞的數量增長而增長,這是因為陷門生成時間主要取決于字典中關鍵詞的數量,算法中陷門生成操作的主要耗時是搜索向量的加密.由于本文采用分塊的方式加密搜索向量,因此總的陷門生成時間要小于MRSE算法和EDMRS算法的時間.通過圖11(b)可以看出,生成陷門的時間成本主要取決于關鍵詞字典中包含的關鍵詞數量,并隨著關鍵詞數量的增大而變大. 搜索時間是權衡算法性能的重要指標.圖12(a)所示為在給定文檔關鍵詞數量的情況下,搜索時間隨文檔個數的變化趨勢,由于文檔向量和索引向量的計算時間相同,因此,搜索時間隨文檔數量的增加而增加.圖12(b)為給定文檔數量的情況下,搜索時間隨文檔關鍵詞數量的變化趨勢,通過上文可知,文檔關鍵詞數量越大,則索引向量和陷門向量的維度也越大,因此,隨著文檔關鍵詞數量的增加,搜索時間也越來越多.此外,SEMRS算法基于凝聚層次聚類構建索引樹結構,該索引樹是平衡二叉樹,并設計了一種高效的索引遍歷算法,因此,SEMRS的搜索時間要小于MRSE和EDMRS算法的搜索時間. Fig. 12 Search time圖12 搜索時間 在分析查詢關鍵詞之間的關系基礎上,提出了一種安全高效的支持語義擴展的多關鍵詞排序搜索算法,解決可搜索加密中的語義檢索問題.我們設計了一種基于語義關系的關鍵詞權重算法,并對權重較大的關鍵詞進行語義擴展.為提高查詢效率,構造了一種關鍵詞平衡二叉樹作為文檔的索引結構,并在查詢時,根據查詢向量和樹節點的向量內積,進行“剪枝”操作.此外,為更好地表達查詢關鍵詞和文檔之間的相關性,在構建索引和陷門時引入了TF-IDF算法,并在陷門中加入關鍵詞權重值.最后,通過使用安全kNN,使得所提算法能夠對抗2種不同安全威脅.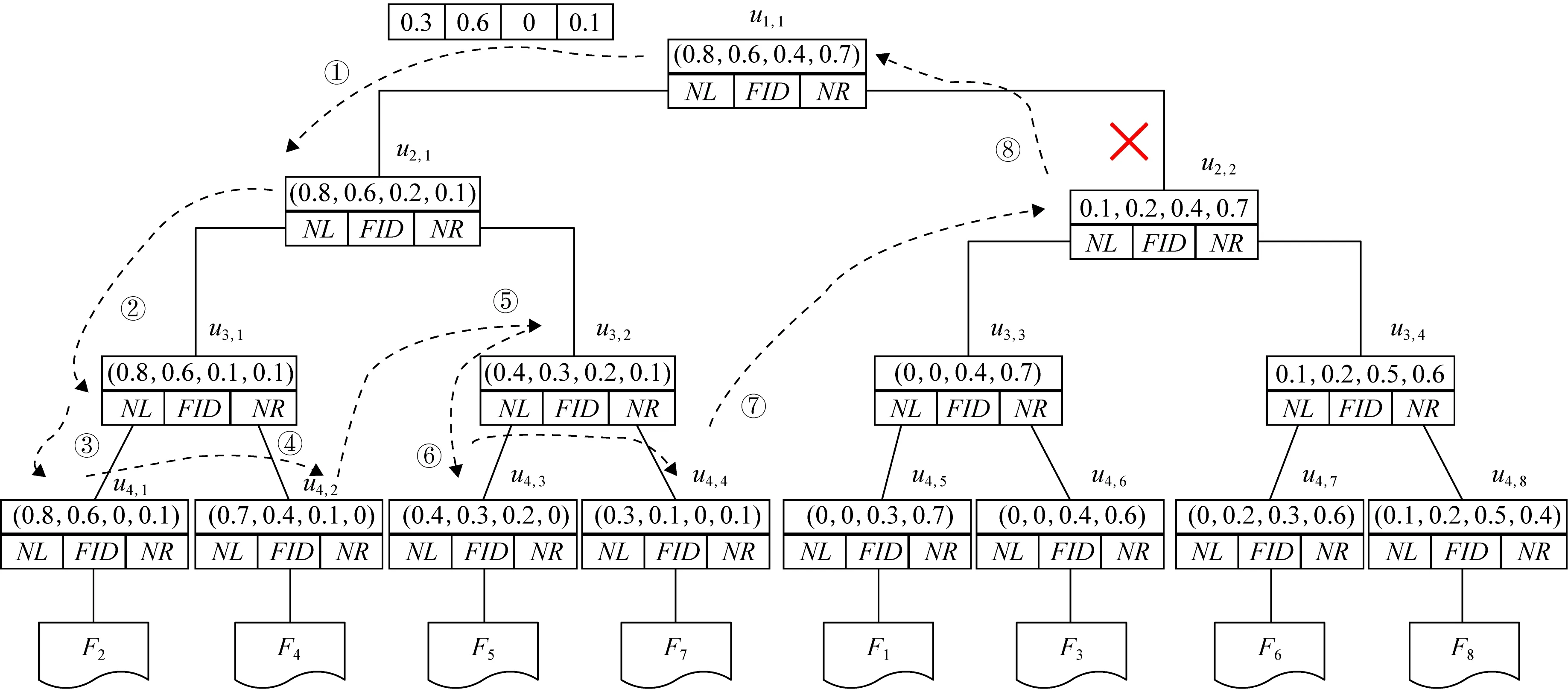
4.3 算法具體實現
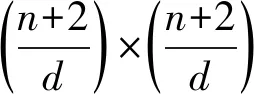
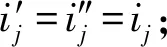
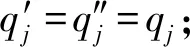
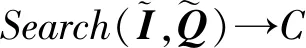
(MT2I″)TM-12Q″=I′Q′+I″Q″=
(I′,I″)(Q′,Q″)=rI·Q+Σεvi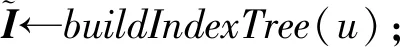
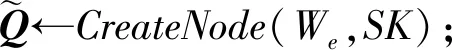
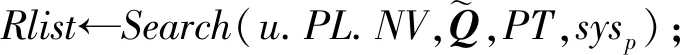
5 安全性和性能分析
5.1 安全性分析
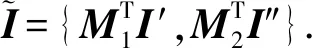
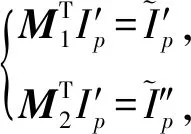
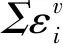
5.2 性能分析

6 實驗分析
6.1 準確率和召回率
6.2 索引創建時間
6.3 陷門生成時間
6.4 搜索時間
7 總 結
