關于AI算力問題的思考
2019-10-18 09:43:57胡劍浩陳杰男
移動通信 2019年8期
胡劍浩 陳杰男
【摘? 要】人工智能技術已經成為國家發展戰略。目前人工智能技術對算力需求與集成電路所能提供支持的差距日益加大,人工智能信息處理平臺需要在處理速度、復雜度和功耗等方面有數量級的改善,才能滿足人工智能技術在軍民領域的應用,因而需要尋求新穎的技術路線解決人工智能的算力問題。介紹了一種顛覆性的技術——概率計算方法,該技術采用了一種類腦的非精確的模糊計算模式。相關研究工作表明,在現有工藝條件下該技術能夠滿足人工智能系統對處理速度、復雜度和功耗的要求,可以支持未來人工智能系統應用的要求。
【關鍵詞】人工智能;計算能力;概率計算
doi:10.3969/j.issn.1006-1010.2019.08.001? ? ? 中圖分類號:TN929.5
文獻標志碼:A? ? ? 文章編號:1006-1010(2019)08-0002-06
引用格式:胡劍浩,陳杰男. 關于AI算力問題的思考[J]. 移動通信, 2019,43(8): 2-7.
Artificial intelligence (AI) technology is an important support of national development strategy. At present, the gap between the computing demand of AI technology and the capability of integrated circuits is increasing. The information processing platform based on AI technology should be improved by orders of magnitude in terms of the processing speed, complexity and power consumption for meeting future military and civilian application requirements. Hence, it is necessary to seek a novel technology roadmap to solve the problem of computing power of AI. This paper introduces a subversive technique, i.e., probability calculation method, which adopts a brain-like inaccurate fuzzy computing model. Relevant research shows that it can meet the requirements of processing speed, complexity and power consumption of AI systems under the current technological conditions, and can support the requirements of future applications of AI systems.
artificial intelligence; computation power; stochastic computation
1? ?引言
人類世界的信息業務量正在呈爆發式的增長,傳統的數字信號處理和統計方式已經難以滿足未來的數據和信息處理的需求[1]。在此背景下,出現了一批以機器學習算法為代表的處理算法和系統,來協助人類處理“大數據”時代下的海量信息與數據[2]。同時,隨著機器算法的不斷發展優化,計算機處理能力的突飛猛進,機器學習算法的能力越來越強,完成的功能越來越強大。最近有關機器學習最出名的案例就是Google的AlphaGo與人類進行的圍棋人機大戰,AlphaGo完勝了人類頂尖棋手,展現出了機器學習算法和系統的強大分析和處理能力[3-4]。因此,將機器學習算法應用到目前的數字信號處理系統中,這將是未來重要的一個發展和研究方向[5-6],有很高的實用價值和戰略價值。
而基于機器學習的大數據處理算法和系統需要極高的計算復雜度,因此對后摩爾時代的計算處理器和芯片提出了巨大的挑戰。當前,隨著集成電路工藝的發展,芯片的特征尺寸已經接近1 nm的界限[7]。這個界限在工業界看來是基于硅工藝的芯片發展的極限,如若不能突破這個極限,未來的芯片生產和制造將舉步維艱。同時一些新興的技術,如量子計算、碳納米管等,真正進入實用還有很長的路需要探索[8]。
推動AI技術發展和應用的三大助力是:大數據、算法和算力。很多企業和高校的研究重點都集中在大數據和算法上面,只有Intel、Nvidia等芯片供應商和HP、浪潮等服務器供應商在對算力問題進行研究。本文將簡單分析一下對AI算力研究的思考。
2? ?算力問題目前的技術路線
近年來深度學習的處理芯片蓬勃發展。大致來看可以分為以下幾種:
(1)GPU:英偉達以其大規模的[23]并行GPU和專用GPU編程框架CUDA主導著當前的深度學習市場[24]。GPU在處理圖形的時候,從最初的設計就能夠執行并行指令,從一個GPU核心收到一組多邊形數據,到完成所有處理并輸出圖像可以做到完全獨立[25]。由于最初GPU就采用了大量的執行單元,這些執行單元可以輕松地加載并行處理,而不像CPU那樣的單線程處理。另外,現代的GPU也可以在每個指令周期執行更多的單一指令。所以GPU比CPU更適合深度學習的大量矩陣、卷積運算的需求[26]。
(2)NPU:中科院研制的人工智能芯片——寒武紀1號(DianNao,面向神經網絡的原型處理器結構)、寒武紀2號(DaDianNao,面向大規模神經網絡)、寒武紀3號(PuDianNao,面向多種機器學習算法)[27]。CPU、GPU與NPU相比,會有百倍以上的性能或能耗比差距,以寒武紀團隊和Inria聯合發表的DianNao論文為例,DianNao為單核處理器,主頻為0.98 GHz,峰值性能達每秒4 520億次神經網絡基本運算,65 nm工藝下功耗為0.485 W,面積3.02 mm2。在若干代表性神經網絡上的實驗結果表明[28]:DianNao的平均性能超過主流CPU核的100倍,但是面積和功耗僅為1/10,效能提升可達三個數量級;DianNao的平均性能與主流GPU相當,但面積和功耗僅為主流GPU百分之一量級。另有IBM主導的SyNAPSE巨型神經網絡芯片(類人腦芯片)TrueNorth,在70 mW的功率上提供100萬個神經元內核、2.56億個突觸內核以及4 096個神經突觸內核,神經網絡和機器學習負載超越了馮·諾依曼架構[29]。
(3)TPU:張量處理單元(Tensor Processing Unit, TPU)。這是一款由Google開發的,為了機器學習而定制的ASIC,并且經過了TensorFlow的調教。TPU已經在Google數據中心運行了一年多,實踐表明它可以為機器學習帶來相當出色的每瓦特性能表現。TPU是專為機器學習應用而定制的,它的寬容度更高,可以降低計算的精度(所需的晶體管操作也更少)[30]。
(4)FPGA:在2017現場可編程門陣列國際大會(ISFPGA)上,來自英特爾加速器架構實驗室(AAL)的Eriko Nurvitadhi博士展示了有關“在加速新一代深度神經網絡方面,FPGA可否擊敗GPU”的研究。該項研究使用最新的DNN算法在兩代英特爾FPGA(Arria 10與Stratix 10)與目前最高性能的英偉達Titan X Pascal GPU之間做了對比評估。和高端GPU相比,FPGA的能量效率(性能/功率)會更好,而且它們還可以提供頂級的浮點運算性能(Floating-Point Performance)。FPGA技術正在快速發展。即將上市的Intel Stratix 10 FPGA能提供超過5 000個硬浮點單元(DSP),超過28 MB的片上內存(M20K),同時整合了高帶寬內存(最高可達4×250 GB/s/stack或1 TB/s),以及由新的HyperFlex技術改善了的頻率。英特爾FPGA能提供全面的軟件生態系統——從低級硬件描述語言到OpenCL、C和C++的高級軟件開發環境。使用MKL-DNN庫,英特爾將進一步將FPGA與英特爾機器學習生態系統和諸如Caffe這樣的傳統架構結合起來。Intel Stratix 10基于英特爾的14 nm技術開發,擁有FP32吞吐量上9.2 TFLOP/s的峰值速度。相比之下,最新的Titan X Pascal GPU提供FP32吞吐量11 TLOP/s的速度[31]。
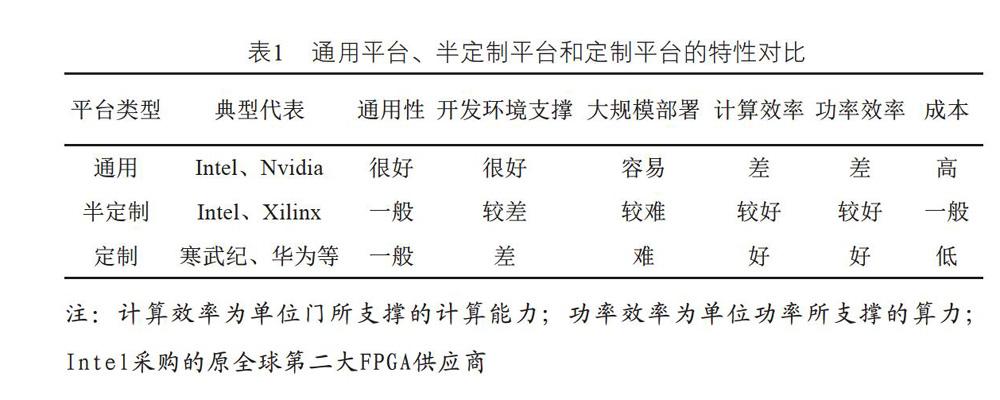
綜上所述,目前工業界解決AI算力有三個方法,通用平臺、半定制平臺和定制平臺。這三種平臺的特性對比如表1所示。
從表1可以看出,通用平臺在開發軟件環境支撐和大規模部署方面有得天獨厚的優勢,成為AI應用落地和云端部署的主力。因此,當今絕大多數的AI示范工程和云端部署都采用GPU和CPU服務器或服務器陣列完成。然而通用平臺在計算效率和功率效率與半定制平臺、定制平臺有數量級的差距。面向嵌入式應用、移動設備應用,通用平臺則難以支撐。對于云端應用,當越來越多的AI應用被部署到云端,功率保障可能會成為其瓶頸。如正在研發的“天河3”超算平臺(該平臺依然采用CPU+GPU架構),其功率可能達到百萬千瓦量級。CMOS工藝已經接近理論極限,而以量子計算為代表的新型計算平臺距實際應用還有很長的道路。因此,通過工藝和計算介質進步解決目前通用平臺功率效率問題不是十分現實,未來可能會出現發電量不足以支持全社會大規模AI應用的困境。
半定制和定制平臺對于嵌入式應用和移動設備應用非常友好,可以成為未來在嵌入式或移動設備實現本地AI應用的主力。由于這些平臺在功率效率和計算效率方面的優勢,在大規模云端部署也有一定的空間。如阿里云和亞馬遜都采用了以FPGA陣列為核心的計算平臺。面向半定制和定制平臺的大規模部署需要解決軟件開發環境支持的問題。現在的AI應用開發已經形成以開源的開發環境為主流的情況,而且這些開發環境支持GPU、CPU平臺以及陣列平臺。因此,需要解決通用開發環境面向FPGA陣列部署的軟件中間件問題,即利用Python設計的AI應用可以一鍵部署到FPGA陣列平臺上,而不需要AI設計者面對硬件描述語言的開發問題。這樣才能夠很好地解決AI應用在以FPGA陣列為代表的半定制平臺上大規模部署的問題。
3? ?基于概率計算方法的解決方法
計算效率和功率效率是AI算力面臨的永恒的挑戰,AI應用對算力的需求每3.5個月增加一倍,而基礎電路工藝已經進入后摩爾時代,AI系統應用在算力上的“鴻溝”將越來越大。隨著集成電路工藝的發展,芯片的特征尺寸已經接近1 nm的界限,如若突破這個極限,未來的芯片生產和制造將舉步維艱。同時一些新興的技術,如量子計算、碳納米管等,真正進入實用還有很長的路需要探索。因此,目前迫切需求一種新穎數值系統,即數的表征和計算模式來打破傳統密集計算的不足,同時該方法可以在現有的集成電路工藝條件下實現且兼容未來的集成電路工藝。
在此背景下,基于概率計算的新型計算方式應運而生。2010年,當基于概率計算的圖像處理芯片橫空出世后,概率計算的發展就開始突飛猛進了,并且于當年被《美國科技評述》評為未來十大最有前景的技術。此后,MIT的研究團隊更是提出了概率計算是繼云計算之后最有潛力的一項技術。概率計算中最基本的運算單元采取一種非精確的近似計算的模式打破了傳統電路的實現方式,可以對傳統的算法進行向概率域的重新映射,使其符合滿足概率計算的模式。概率計算再通過誤差分析和建模,設計各種系統參數,使其滿足系統的需求,最后根據設計的算法映射到實際的電路架構中,完成算法的最終實現。其基本的原理就是利用大量的非精確計算模擬出復雜的系統功能,這其實和人類強大的大腦工作原理不謀而合。人類大腦就是基于大量的直觀和非精確的計算方式來處理當今信息社會的海量數據。而AI的算法也是模擬人類的大腦,在此環境下概率計算應運而生,因此概率計算能夠非常好地乘載復雜的AI算法。據悉,Google AlphaGo所使用的處理器就是基于一種非精確的概率計算模式。相信基于概率計算和AI的結合能夠使得未來的數據處理和信息分析達到一個新的高度。如今人工智能的一個關鍵障礙是——給計算機提供的自然數據大多是非結構化和“嘈雜”的數據。Intel公司認為,概率計算可以使計算機在處理大規模的概率時更有效率,這是將當前系統和應用程序從先進的計算輔助工具轉變為理解和決策的智能合作伙伴的關鍵。
2018年5月,英特爾人工智能實驗室決定對概率計算(Probabilistic Computing)方面的研究增加投資,并呼吁學術界與產業界與其合作,將概率計算從實驗室引入現實應用,包括基準程序測試(Benchmark Applications)、概率框架(Probabilistic Frameworks)以及軟硬件優化(Software and Hardware Optimization)等[13]。英特爾的人工智能實驗負責人Mayberry在接受IEEE Spectrum的采訪中提到了MIT的概率計算研究團隊,MIT的概率計算團隊正在構建新一代概率計算系統,將概率和隨機性集成到軟件和硬件的基本構建模塊中,MIT的PC研究團隊,近些年來致力于概率程序語言(Probabilistic Programming)與系統的開發[18]。概率程序語言或稱為概率編程為人工智能提供了一個編程語言,并提供了知識如何表示的基礎方法,可以對不確定性建模,為不同研究領域的人提供一個工具,在這基礎上進行自動推理。國內外各大高校和公司也推出概率編程的工具和庫,達到應對不同領域下的智能化與通用化建模與推理。
電子科技大學研究團隊從2010年開始嘗試利用這種顛覆性的技術,將概率計算方法應用于通信信號處理系統的電路實現上,設計了基于概率計算方法的濾波器、信道譯碼器、MIMO信號檢測器、非正交接入信號檢測器等單元模塊,在保證這些模塊的信號處理性能的前提下,大幅度降低了電路的復雜度。電子科技大學研究團隊目前正在探索基于概率計算方法的新型數值表征和計算技術在人工智能系統中應用的特點,研究典型人工智能算法到概率計算空間的算法映射方法,設計關鍵模塊及其電路架構,突破可配置概率計算人工智能硬件加速器設計方法和集成電路實現技術。目前利用FPGA完成的支持100維的支持向量機(SVM)特征分類器實現,其速度較GPU服務器提高30倍,同時功耗降低了100倍。這表明概率計算方法在解決AI應用算力問題是有前途的。
4? ?基于概率計算方法的AI芯片面臨的挑戰
隨著信息技術的發展,人們對數據的需求也日益增長,人類將逐步跨入大數據時代,而作為大數據時代的一個重要支撐就是人工智能技術(AI)。然而隨著AI算法的復雜度呈指數增加,這會對基于AI的系統帶來巨大的壓力,因此必須利用顛覆性的方案來設計和實現面向未來的AI芯片,以使得其所帶來的巨大優勢能夠真正得以實現和應用。概率計算方法是解決這一技術難題的途徑之一,同時面臨如下的技術挑戰:
(1)基于AI算法的概率計算基本計算單元設計與實現
當前的人工智能算法主要利用了類腦的計算,而這種計算的概率性質允許數量級的加速和減少電力的大量消耗。計算以偏離而不是采用直接的方式來建模,隨后可以通過嘈雜自然數據(異同甚至相互矛盾的信息)分析技術提高計算精度,其目的是在需要高智能、認知等場景中協助人類的選擇行為達到期望的水平,同時將能源的成本節省到忽略不計的程度。其核心思想是基本算子映射、概率框架、軟件和硬件優化。因此,需要研究一種適用于AI芯片設計的基本計算單元設計與實現方法。
(2)基于人工智能的概率計算算法映射方法
首先將AI算法映射到概率域中,稱之為規則的映射,其次將構建概率算子并使其能夠產生所需的結果稱之為目標的映射,最后將信號處理與學習搜索網絡相對應和加工,使得其能夠高效完成所指定的目標。由此可得在傳統AI中,物理參數模型都是人為構建的,這在特定場景設計下的AI芯片必定是最優的。但如前面所述,隨著AI算法的發展,這種模式將難以為繼。因此只要基于概率計算將映射規則和基本算子等定義清楚,就能輔助完成AI芯片的設計。為了適應AI算法快速變化的需求,本項目采用的認知計算的模型和算法具有高效和快速收斂的特征;同時該方法具有低復雜度的特點,從而可以保障在工程實踐中的應用。前期的研究表明,在典型的AI算法環境中,基于概率計算的AI設計法可以在保證檢測性能的條件下滿足“在線”實時處理的要求,且硬件實現效率優于傳統檢測方法。因此,需要研究一種基于人工智能的概率計算算法映射方法。
(3)高性能的概率AI芯片的實現設計方法
對AI的概率計算基本運算模塊進行硬件架構設計,并且針對當前的工藝,給出設計和實現方案。根據之前形成的映射方法和基本單元的設計,形成一套完整的芯片架構設計和實現方案。最后制作一套針對所設計人工智能芯片的測試平臺,來驗證所設計芯片的正確性。
5? ?結束語
滿足未來的新型人工智能裝備及產業的需求,不能簡單地認為僅僅依靠硬件平臺就可以解決所有問題。原來依賴集成電路技術進步來適應系統需求增長的“老路”已經走到頭了。而系統和裝備依然需要不斷的更新和升級,因此需要從算法、算法架構、算法的表征和實現技術、系統優化等方面開展深入的研究,才能在新的時代條件下,支持人工智能裝備及產業快速發展的需求。因此,概率計算將為人工智能爆發式的增長提供有力的支持;需要研究以概率計算方法在人工智能系統應用為核心,研究面向人工智能系統的概率計算方法及其集成電路的實現技術,為未來人工智能系統應用提供新穎的技術路線和保障。
參考文獻:
[1] Glorol X, Bonles A, Bengio Y. Deep sparee rectifier neural networks[C]//International Conference on Artificial Intelligence and Statistics. Piscalaway, NJ, USA: IEEE, 2011: 315-323.
[2] Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2009.
[3] 張榮,李偉平,莫同. 深度學習研究綜述[J]. 信息與控制, 2018,47(4).
[4] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015,521(7553): 436.
[5] Ghahramani, Zoubin. Probabilistic machine learning and artificial intelligence[Z].
[6] Wang S, Zhang X, Li Y, et al. Accelerating Markov Random Field Inference Using Molecular Optical Gibbs Sampling Units[C]//ACM IEEE International Symposium on Computer Architecture. IEEE, 2016.
[7] Zhang X, Bashizade R, Laboda C, et al. Architecting a Stochastic Computing Unit with Molecular Optical Devices[C]//ACM IEEE International Symposium on Computer Architecture. IEEE Computer Society, 2018.
[8] Cusumano Towner, M F, Mansinghka, et al. A design proposal for Gen: Probabilistic programming with fast custom inference via code generation[C]//In Workshop on Machine Learning and Programming Languages (MAPL, co-located with PLDI). 2018: 52-57.
[9] Cusumano Towner, M F, Mansinghka, et al. Using probabilistic programs as proposals[C]//Workshop on Probabilistic Programming Languages, Semantics, and Systems (PPS, co-located with POPL). 2018.
[10] Cusumano Towner, M F, Bichsel, et al. Incremental inference for probabilistic programs[C]//Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). ACM, 2018: 571-585.
[11] Saeedi A, Kulkarni T D, Mansinghka V K, et al. Variational particle approximations[J]. Journal of Machine Learning Research, 2014.
[12] Cusumano Towner M F, Mansinghka V K. AIDE: An algorithm for measuring the accuracy of probabilistic inference algorithms[Z]. 2017.
[13] Nepal K, Hashemi S, Tann H, et al. Automated High-Level Generation of Low-Power Approximate Computing Circuits[J]. IEEE Transactions on Emerging Topics in Computing, 2019(1): 18-30.
[14] Cusumano Towner M F, Radul A, Wingate D, et al. Probabilistic programs for inferring the goals of autonomous agents[Z]. 2017.
[15] Schaechtle U, Saad F, Radul A, et al. Time Series Structure Discovery via Probabilistic Program Synthesis[Z]. 2017.
[16] Saad F, Casarsa L, Mansinghka V. Probabilistic Search for Structured Data via Probabilistic Programming and Nonparametric Bayes[J]. 2017.
[17] Saad F, Mansinghka V. Detecting Dependencies in Sparse, Multivariate Databases Using Probabilistic Programming and Non-parametric Bayes[J]. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, 2017(54): 632-641.
[18] Chien C, Longinotti L, Steimer A, et al. Hardware Implementation of an Event-Based Message Passing Graphical Model Network[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2018,65(9): 2739-2752.
[19] Yi Wu, Lei Li, Stuart Russell, et al. Swift: Compiled Inference for Probabilistic Programming Languages[Z]. 2016.
[20] Shi J, Chen J, Zhu J, et al. ZhuSuan: A Library for Bayesian Deep Learning[Z]. 2017.
[21] Tran D, Hoffman M D, Saurous R A, et al. Deep Probabilistic Programming[Z]. 2017.
[22] Bingham E, Chen J P, Jankowiak M, et al. Pyro: Deep Universal Probabilistic Programming[Z].
[23] Coyle P. Probabilistic Programming and PyMC3[Z]. 2016.
[24] Rejimon T, Bhanja S. Scalable probabilistic computing models using Bayesian networks[C]//Symposium on Circuits & Systems. IEEE, 2005.
[25] Davies M, Srinivasa N, Lin T H, et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning[J]. IEEE Micro, 2018: 1.
[26]? Sze V, Chen Y, Yang T, et al. Efficient Processing of Deep Neural Networks: A Tutorial and Survey[J]. Proceedings of the IEEE, 2017(12): 2295-2329.
[27] Xu J, Huan Y, Yang K, et al. Optimized Near-Zero Quantization Method for Flexible Memristor Based Neural Network[J]. IEEE Access, 2018: 29320-29331.
[28] Ren L, Fletcher C W, A Kwon, et al. Design and Implementation of the Ascend Secure Processor[J]. IEEE Transactions on Dependable and Secure Computing, 2019,16(2): 204-216.
[29] Knag P, Kim J K, Chen T, et al. A Sparse Coding Neural Network ASIC With On-Chip Learning for Feature Extraction and Encoding[J]. IEEE Journal of Solid-State Circuits, 2015,50(4): 1070-1079.
[30] Shin D, Lee J, Yoo H. DNPU: An Energy-Efficient Deep-Learning Processor with Heterogeneous Multi-Core Architecture[J]. IEEE Microwave, 2018,38(5): 85-93.
[31] Lee J, Kim C, Kang S, et al. UNPU: An Energy-Efficient Deep Neural Network Accelerator With Fully Variable Weight Bit Precision[J]. IEEE Journal of Solid-State Circuits, 2019,54(1): 173-185.★
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
理科愛好者(教育教學版)(2022年2期)2022-05-05 00:24:02
快樂學習報·教育周刊(2022年13期)2022-04-13 21:33:18
甘肅教育(2021年10期)2021-11-02 06:14:02
甘肅教育(2020年18期)2020-10-28 09:07:06
甘肅教育(2020年21期)2020-04-13 08:08:42
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
數學大世界(2018年1期)2018-04-12 05:39:02
小康(2017年16期)2017-06-07 09:00:59
