基于網格分解的東巴象形文字分類算法研究
2019-10-18 02:57:59楊玉婷康厚良
軟件導刊 2019年9期
楊玉婷 康厚良

摘 要:東巴文字作為人類早期的一種向象形文字、標音文字過渡的圖畫文字形式,既具有圖畫文字以圖表意特點,又具有現代文字使用簡單線條表達含義的特點。東巴文字本身的復雜性使其相關研究一直較少且連貫性不強。從東巴文字的構字要素入手,通過分析東巴文字的組成要素、結構特征及造字習慣,給出適用于東巴象形文字的預處理及基于網格分解的分類識別算法。該算法思路簡單、復雜度低、易于實現,能夠快速實現不同類型東巴文字的檢索和識別,具有較好的縮放和平移不變性,從而為東巴文字的造字研究提供強有力的技術支持,也為研究其它象形文字的檢索和識別技術提供重要參考。
關鍵詞:網格分解;分類識別算法;東巴象形文字
DOI:10. 11907/rjdk. 181810 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP317.4 文獻標識碼:A 文章編號:1672-7800(2019)009-0196-03
Dongba Hieroglyphic Classification Algorithm Based on Grid Resolution
YANG Yu-ting1, KANG Hou-liang2
(1. School of Computer Engineering, Suzhou Vocational University;
2. Sports Department, Suzhou Vocational University, Suzhou 215000, China)
Abstract: Dongba hieroglyph is a kind of very primitive picture hieroglyphs; it not only has a characteristic of pictograph to express meaning by using pictures, but also has a feature of modern word to express the meaning with simple strokes. Because of the complexity of the Dongba hieroglyph itself, the related research on has been limited. In the paper, we start with the structural elements of Dongba hieroglyphs. By analyzing the constituent elements, structural features and writing habits, we give a preprocessing and classification algorithm for Dongba hieroglyphs. The algorithm is simple, low in complexity and easy to implement. It can quickly retrieve and recognize different types of Dongba hieroglyph, and has better scale and translation invariance. The algorithm provides strong technical support for the study of glyphic formation in Dongba hieroglyph and also gives an important reference for the research on the retrieval and recognition of other pictographs.
Key Words: grid resolution; classification algorithm; Dongba hieroglyph
0 引言
東巴文是一種十分原始的圖畫象形文字,納西語稱“森究魯究”,直譯為“留在木石上的印跡”[1-2]。2003年,使用東巴文撰寫的東巴古籍被聯合國教科文組織列入世界記憶遺產名錄[3]。
東巴文字識別研究較少且連貫性不強[4-11],絕大多數研究都是基于已有算法的實現,很少從東巴字本身的形態特征入手。本文從東巴文字的構字要素入手,通過分析東巴文字的組成要素、結構特征及造字習慣,給出東巴象形文字預處理及基于網格分解的分類識別算法。
1 東巴文字特征分析及預處理
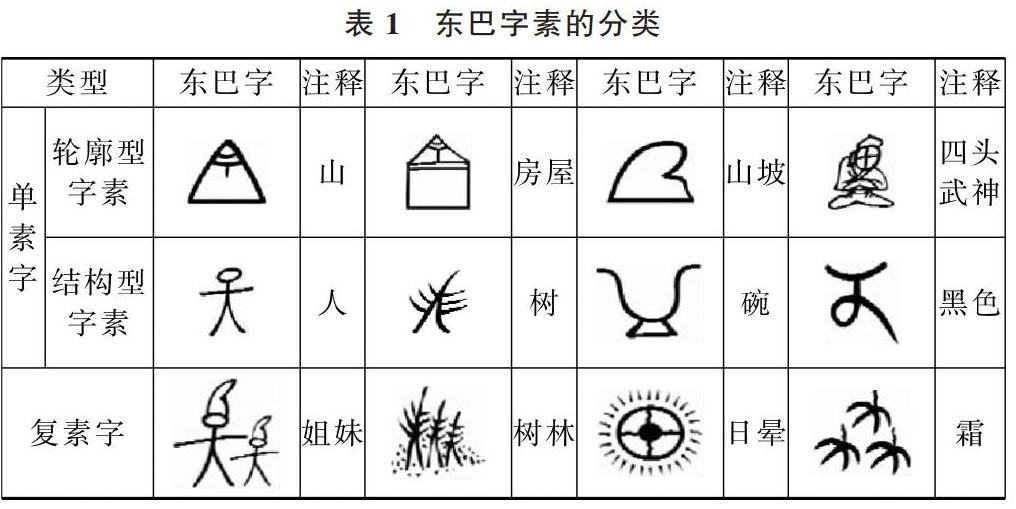
從構字結構要素分析,東巴文字可分為單素字和復素字[12-13]。單素字指能夠直接顯示音義的獨立文字,復素字指由兩個或兩個以上字素構成的文字,通過多個字素共同表示音義[14-15]。另外,在單素字中,可進一步分為輪廓型和結構型單素字,如表1所示。
1.1 東巴文字細化
東巴法師書寫東巴文一般使用竹筆。竹筆屬于硬筆的一種,使得東巴字的筆畫線條粗細基本一致[16]。因此,對東巴文字的線條細化可有效去除文字中潛在的干擾,使字符特征更加顯著,細化效果如圖1所示。顯然,細化處理不會對文字本身的結構、形態產生太大影響,完整保留了文字本身的線條特征。
1.2 復素字分割
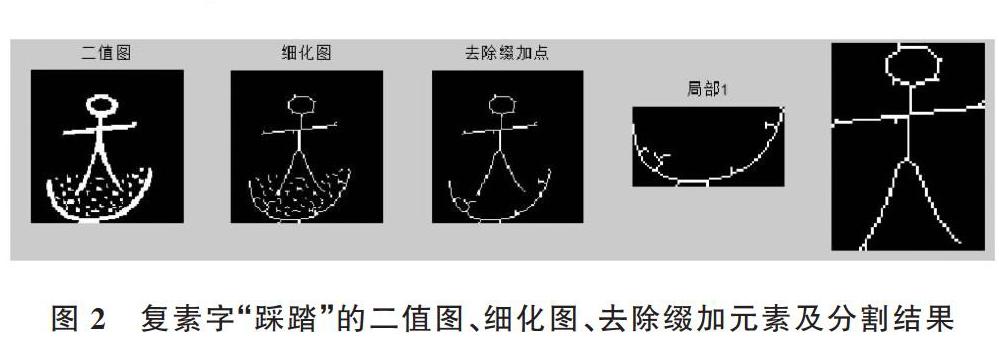
為表達更加豐富、復雜的含義,復素字一般采用若干具有獨立含義的字素,或者在單字素的基礎上增加綴加元素(包括綴加點、線或字塊)的方式 [17]。但是,這些輔助字素或綴加元素會對東巴文字的分類識別算法產生影響,因此在預處理階段,使用8-鄰域標記算法[18-20]去除復素字中的綴加元素,特別是復素字中的綴加點元素,保留復素字中的一個或多個獨立成份。在減少綴加點對文字本身干擾的同時,使分類檢索算法不但能用于具有相似形態的單素字,也能兼顧包含相似單素字的復素字。
處理步驟如下:首先細化復素字,突出字符筆劃特征,然后去除文字中的離散綴加點,減少綴加點元素對字符識別的干擾,最后使用8-領域標記算法實現對復素字各組成元素的分割,操作步驟如圖2所示。
2 基于網格分解的分類算法
適當的網格分解(Adaptive grid resolution,AGR)[21]指使用正方形網格覆蓋整個形狀。根據形狀綁定矩形大小,將形狀分解為大小相同的網格,計算對應網格中形狀像素點差值,并將差值的總和作為兩個形狀的相似性距離,如圖3所示。
由網格分解可知,對于具有相似形態特征的東巴文字,文字筆畫在網格中的分布情況也是相似的。因此,基于網格分解的東巴文字相似性計算方法如下:
若待比較東巴文字為[G1]和[G2],[G1]的綁定矩形長í寬為[L1×W1],[G2]綁定矩形的長í寬為[L2×W2],為保證相似性算法的縮放不變性,計算東巴文字綁定矩形的歸一化長和寬,其中,歸一化綁定矩形的寬度為100,則:
若使用[m×n]的粗網格分解字符的歸一化綁定矩形,且每一個網格中所包含的像素點為[Areai (i∈{1,2,3,?,][m×n})],則兩個東巴文字的相似性距離為:
3 實驗
人形字作為東巴象形文字的重要組成部分,反映了納西先民生產、生活的各個方面,因此將其作為結構型單素字的度量模板,檢索結果如圖4所示,以“人”型作為檢索模板時,返回的前100個字符的檢索正確率為94%。其中,錯誤檢索結果為5個,但是錯誤結果在形態上與人形字仍具有較多相似性,這從另一側面說明納西先民在造字初期,是先從自身出發,使用人的站立方式表示其它物體的站立或直立的。
對于輪廓型單素字,以
4 結語
本文通過分析東巴象形文字的圖畫特性,結合文字的結構特征和組合特性,給出了適用于東巴文字的預處理及基于網格分解的相似性度量算法。該算法思路簡單、實現快捷、算法復雜度很低,通過對字符綁定矩形的提取和歸一化處理,使該算法具有良好的縮放不變性和平移不變性,使用兩種完全不同結構的東巴單素字進行測試也得到了較高的檢索準確率,為東巴文字的造字研究提供了強有力的技術支持,也為研究其它象形文字的檢索和識別技術提供了重要參考。
參考文獻:
[1] 和力民. 試論東巴文化的傳承[J]. 云南社會科學, 2004 (1): 83-87.
[2] 和金光. 納西族東巴文化研究發展趨勢[J]. 云南民族大學學報:哲學社會科學版, 2007, 24(1): 81-84.
[3] 戈阿干. 東巴文化攬勝[J]. 民族藝術研究,1999 (2): 71-80.
[4] GUO H, ZHAO J Z, DA M J, et al. Naxi pictographs edge detection using lifting wavelet transform[J]. Journal of Convergence Information Technology, 2010, 5(5): 203-210.
[5]GUO H, ZHAO J Y. Research on feature extraction for character recognition of Naxi pictograph[J]. Journal of Computers, 2011, 6(5): 947-954.
[6] GUO H, YIN J H, ZHAO J Y. Feature dimension reduction of Naxi pictograph recognition based on LDA[J]. International Journal of Computer Science, 2012, 9(1): 90-96.
[7] GUO H, ZHAO J Y. Segmentation method for Naxi pictograph character recognition[J].Journal of Convergence Information Technology, 2010, 5(6):87-98.
[8] LI X, GUO H, ZHENG Z K, et al. The Design and Realization of Naxi Pictograph Character Recognition Preprocessing System[C]. Proceedings of CSEEE 2011, PartII, 2011:54-59.
[9] 楊萌, 徐小力, 吳國新,等. 東巴象形文字識別方法[J]. 北京信息科技大學學報, 2014, 29(3): 72-76.
[10] 王海燕, 王紅軍, 徐小力. 基于支持向量機的納西東巴象形文字符識別[J]. 云南大學學報:自然科學版, 2016, 38(5): 730-736.
[11] DA M J, ZHAO J Y, SUO G J, et al. Online handwritten Naxi pictograph digits recognition system using coarse grid[J]. CSEEEP artI, CCIS, 2011(158): 390-396.
[12] 方國瑜, 和志武. 納西象形文字譜[M]. 昆明: 云南人民出版社, 2005.
[13] 李霖燦. 納西族象形標音文字字典[M]. 昆明: 云南民族出版社, 2001.
[14] 鄭飛洲. 納西東巴文字字素研究[M]. 北京: 民族出版社, 2005: 1-230.
[15] 和麗鋒. 納西東巴文字字形構造及其國際標準[D]. 上海:上海師范大學, 2016.
[16] 鄭飛洲, 納西東巴文字字素研究[D].上海:華東師范大學, 2003.
[17] 王元鹿. 漢古文字與納西東巴文字研究[M]. 上海: 華東師范大學出版社, 1998.
[18] ONISHI J, ONO T. Contour pattern recognition through auditory labels of freeman chain codes for people with visual impairments[J]. Proceeding of IEEE International Conference on Systems, 2011, 32(14): 1088-1093.
[19] 陳士金, 湯漾平. 基于鏈碼的輪廓跟蹤技術在二值圖像中的應用[J]. 華中理工大學學報, 1998,12(26): 26-28
[20] 董春利, 董育寧, 王莉. 活動輪廓模型目標跟蹤算法綜述[J]. 計算機工程與應用, 2008, 44(34): 208-212
[21] YANG M, KPALMA K, RONSINA J. Survey of shape feature extraction techniques[J]. Pattern Recognition Techniques, Technology and Applications, 2007(11): 1-39.
(責任編輯:杜能鋼)
