基于因子分解機的灰色產業服務網頁過濾方法
2019-10-18 02:57:59付強裴佩丁永剛
軟件導刊 2019年9期
付強 裴佩 丁永剛
摘 要:互聯網灰色產業服務日益泛濫,而傳統的網頁過濾算法無法準確高效地過濾掉灰色產業服務網頁。為解決這一問題,基于TF*IDF提出一種改進的網頁特征提取和權重計算方法,利用因子分解機模型對網頁進行分類,并以代孕網站為例進行實驗和評估。實驗結果表明,該方法精確率達到98.89%,召回率達到98.63%,且對海量網頁的過濾能夠在線性時間復雜度內完成,大大提高了灰色產業服務信息過濾精度和效率。
關鍵詞:灰色產業服務;網頁過濾;特征選擇;權重計算;因子分解機
DOI:10. 11907/rjdk. 191195 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP319文獻標識碼:A 文章編號:1672-7800(2019)009-0150-04
A Factorization Machine-based Filtering Approach
for Gloomy Industry Service Webpages
FU Qiang1,PEI Pei2,DING Yong-gang3
(1. Wuhan Marine Communication Institute,Wuhan 430072,China;
2. School of Computer, Central China Normal University, Wuhan 430079,China;
3. School of Education,Hubei University,Wuhan 430062,China)
Abstract: In recent years, Internet gray industry has become rampant. Unfortunately, traditional webpage filtering algorithms are not able to filter the webpages of the gray industry efficiently and accurately. To solve this problem, we first propose an improved method of webpage feature selection and weight calculation based on TF*IDF, and then classify webpages using Factorization Machines. Taking surrogacy website as an example, we conduct extensive experiments and evaluations in the real-world scenarios. The experiment results show that this method achieves a precision of 98.89% and a recall of 98.63%, and is able to filter gray industry webpages in linear time, which greatly improve the accuracy and efficiency of filtering.
Key Words:gray?industry service; webpage filtering; feature selection; weight calculation; factorization machines
0 引言
互聯網產業蓬勃發展,一些不符合國家法律法規的互聯網灰色產業也夾雜其中,如代孕、論文買賣等。這些灰色產業使用不正當手段非法盈利,不僅違背倫理道德,而且擾亂互聯網正常秩序。從海量網頁中迅速有效地過濾互聯網灰色服務信息,阻止其傳播,確保互聯網綠色產業有序發展,成為網絡內容安全研究的重要課題之一[1-3]。
在網頁文本過濾中,文本特征提取算法好壞直接關系到過濾效果優劣,而灰色服務信息文本過濾不同于普通文本過濾,其主要困難在于灰色服務信息文本特征的選擇需考慮多類特征詞與一般特征詞的區別以及在不同類別文檔中的重要性,因此本文首先基于TF*IDF提出一種改進的特征選擇與權重計算方法,以期獲得較好的灰色服務信息文本特征選擇與權重計算效果。
文本過濾一般采用近鄰法(KNN)[4]、貝葉斯分類(NB)[5]、支持向量機(SVM)[6-7]和神經網絡(BP)[8]等文本分類方法,這些方法效果較好,但KNN算法在樣本集較大的情況下,系統時間復雜度和空間復雜度都較高;NB算法在屬性個數較多或屬性之間相關性較大時,分類效率不理想;SVM算法雖然能解決高維問題,但對缺失數據敏感,且對非線性問題沒有通用解決方案; BP算法在高維數據和大數據量的情況下,算法開銷非常大。針對上述問題,本文基于因子分解機模型提出一種有效的分類算法,該算法在高維數據和數據稀疏情況下仍能在線性時間復雜度內獲得好的分類精度。實驗表明,將該算法應用于灰色服務信息過濾能取得滿意的效果。
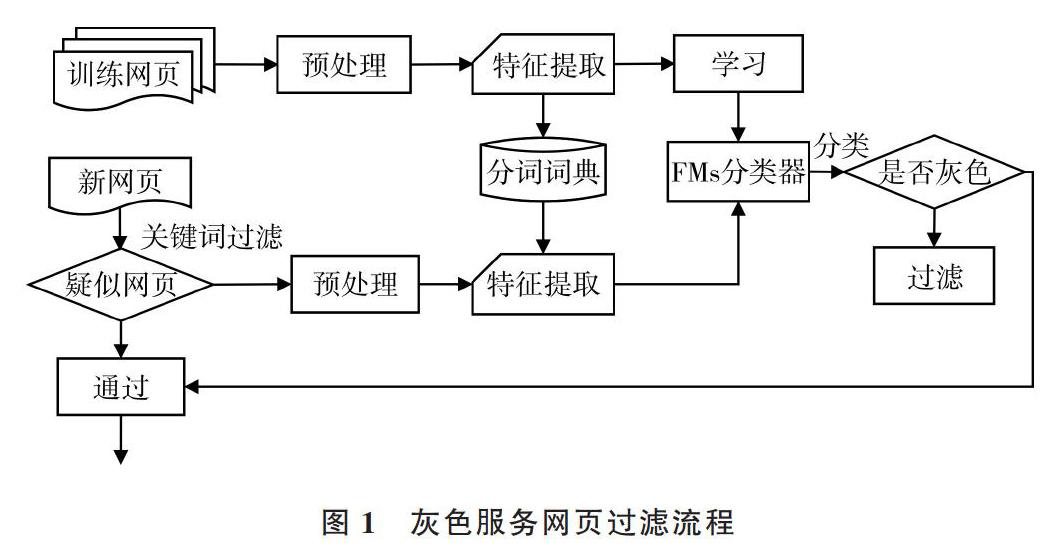
1 灰色產業服務網頁過濾流程
灰色產業服務網頁過濾流程分為訓練和過濾兩個階段,其流程如圖1所示。
訓練階段最重要的是建立灰色產業分詞詞典。首先收集大量灰色產業服務網頁,使用分詞軟件進行分詞,統計詞頻, 得到詞頻最高的k個詞,然后去除停用詞、平凡詞、稀有詞和詞頻小于3的詞,把剩下的詞作為關鍵詞;增加一些描述灰色產業的專有名詞,以代孕服務為例,增加如“試管嬰兒”、”捐卵”、“ 體外授精”和“借腹生子”等詞,以及反映產業服務網頁特征的重要詞,如“聯系電話”、 “在線咨詢”、“會員“、“報名”、“流程”、“服務”、“客服”、“價格”等詞。
在過濾階段,使用上述得到的灰色產業關鍵詞過濾掉與灰色服務完全無關的網頁,剩下的網頁為灰色服務網頁及相似網頁。以代孕服務為例,與之相似的網頁可能是介紹有關生育知識的合法醫學類網頁,或僅是報道代孕產業的相關新聞網頁。由于描述灰色服務的詞大多是專業詞匯,所以可使用訓練階段建立的分詞詞典進行機械式分詞和特征提取,最后使用因子分解機模型分類器進行分類過濾。
2 灰色產業網頁特征提取與權重改進算法
2.1 特征提取
網頁文本特征通常采用向量空間模型表示[9],其半結構化特點使其即使經過初始化處理后,仍會留下很多高維特征向量。不是所有特征對分類學習都有用,且向量的高維特性還會增加機器學習時間。因此,特征選擇用于排除特征空間中那些被認為無關或關聯性不大的特性,以降低向量空間維數,簡化計算,防止過分擬合。特征選擇好壞直接影響文本分類的準確率。
灰色服務網頁的特征提取不同于普通網頁的特征提取,其主要困難在于灰色服務網頁文本特征的選擇,除了要提取代表灰色產業服務的高頻詞外,還要考慮多類特征詞與一般特征詞的區別及其在不同類別文檔中的重要性。比如灰色產業最顯著的特點是它的交易特性,因此其網頁除了包含關于該灰色服務信息的高頻詞外,還會包含一些呈現交易特性的重要詞。以代孕網頁為例,除了出現 “代孕媽媽”、“嬰兒”和“胚胎”等高頻詞外,還會出現一些諸如“聯系電話”、“在線咨詢”、“會員“、“報名”、“流程”、“服務”、“客服”、“價格”等具有顯著交易特性的詞,而這些詞也可能出現在合法網頁中,即這些詞為多類特征詞。這類特征詞在灰色服務網頁中出現的頻度一般較高,能夠代表灰色服務網頁的特征。因為某一網頁即使出現了“代孕媽媽”、“嬰兒”和“胚胎”等高頻詞,如果沒有該類具有顯著交易特性的特征詞,則可認為這樣的網頁可能只是相似網頁而不是灰色服務網頁。因此,需要一種新的特征提取和權重計算方法,既能提取反映灰色服務信息的高頻特征詞,又能將多類特征詞與一般特征詞加以區別,還能體現其在不同文檔類別中的重要性。
2.2 權重改進算法
2.2.1 傳統TF*IDF 算法及不足
文本特征常用加權關鍵詞矢量的向量空間模型(VSM)表示。VSM將文本文檔視為由一組詞語[(t1,t2,?,tn)]構成,每一詞語都賦以一定的權值。這樣,一個文檔[di]可以表示成由一組詞語矢量組成的向量空間中的一個向量:[di=t1,w1;t2,w2;...;tk,wk;?;tn,wn],其中[tk]表示詞語,[wk]表示詞語[tk]在文檔[di]中的權重。文檔[di]中詞語[tj]的權重采用[tf-idf]公式計算如下:
其中,詞頻[tfij]是詞語[tj]在文檔[di]中出現的次數,逆文檔詞頻[idfij=lnN/n]是詞語[tj]在文檔集中分布情況的量化,[N]為文檔集的總文檔數,[n]為出現特征詞[t]的文檔數。
從公式(1)可以看出,[tf-idf]主要從詞頻和逆文檔詞頻兩方面考慮:如果某個詞在一個文檔中出現的頻率[tf]高,但在其它文檔中很少出現,則認為此詞具有很好的類別區分能力,適合用來分類;[idf]則表示為,如果包含某個詞語的文檔數較少,即[n]越小,[idf]越大,說明該詞語具有很好的類別區分能力。進一步分析發現, 如果一個文本中的某個詞語出現次數很多,即[tf]很大,則該詞語在另一個同類文本中出現次數也會很多,反之亦然。因此[tf]可以體現同類文本的特點,但還應考慮詞語區分不同類別文檔的能力。逆文檔詞頻[idf]認為一個詞語出現的頻率越小,區別不同類別的能力就越大,但如果其均勻分布在各個類間,這樣的詞語是不適合用來分類的;另一方面,如果一個詞語在某個類的文檔中頻繁出現,則說明該詞語能夠很好地代表這個類的文本特征,這樣的詞語應該賦予較高權重,并選作該類文本的特征詞以區別于其它類別文檔。顯然,[idf]沒有考慮詞語在不同類別中的區分能力,所以依據[tf-idf]得到的權值進行文本分類通常不能得到滿意效果。
2.2.2 改進的權重算法
為克服[idf]公式缺陷,本文從以下兩方面調整詞語權重:
(1)引入類別文檔頻數[cdf]。 ?文獻[10]把類別文檔頻數[cdf]定義為:
該公式表示特征詞[t]在類別[Cp]的文檔集中的[idf]值,其中[Kp]表示[t]在[Cp]中的類別文檔頻數。公式(2)不但能反映出多類特征詞和一般特征詞區別,而且能反映一個多類特征詞在不同類別文檔中的重要性。改進的詞語權重計算公式如下:
其中,[wij]表示特征詞[tj]在文檔[di]中的權值,[tf(ti)] 表示[ti]在[di]中出現的次數。假設[di]屬于類別[Cp(p=1,2,][?,m)],[Kp]表示[ti]在類[Cp]中的文檔頻數,[N]為文檔集中的總文檔數,[n]為出現特征項[t]的文檔數。
(2)引入信息增益調整權重。文獻[11-13]從信息論的角度出發,把信息增益公式引入到文檔集的類別間,即把文檔集看作一個符合某種規律分布的信息源,依靠訓練數據集的類別信息熵和文檔類別中詞語的條件熵之間信息量的增益關系,確定該詞語在文本分類中所能提供的信息量,并把這個信息量反映到詞語的權重中。公式如下:
其中,C為文檔的類別集合,[p(Cp)]表示類別[Cp]的概率,可基于文檔統計進行計算,也可基于詞頻計算,[(Cp/tj)]表示詞語[tj]在類別[Cp]中出現的概率。
當詞語[tj]在文檔集合的類別中分布不均時,即在某個類別中分布較高,其它類別中分布較少,詞語帶有較大的類別信息時,應用信息增益公式計算可得到較高的信息增益值,用公式(7)計算所得的權重值就會較高,從而提高詞語[tj]的權重;另一方面,如果詞語[tj]在文檔集合中的數量雖小,但如果其均勻分布在各個類別間,則其帶有的類別信息少,對系統的不確定性程度影響小,則由信息增益公式計算得到的信息增益值較小,用公式(7)計算詞語[tj]的權重也相對較低。因此,改進的權重公式能很好地反映詞語在類別間的分布情況。
3 基于因子分解機的灰色服務網頁過濾方法
3.1 因子分解機
因子分解機(Factorization Machines,FMs)是Steffen Rendle[14]提出的一種通用因子分解模型,它通過使用分解交互參數對具有目標值的所有成對變量進行維度為d的嵌套交互建模,用于解決各種分類和預測問題[15-18]。假設將預測問題的數據描述為二元組[(x,y)],其中[x∈?p]是一個特征向量,[y]是預測目標。當d=2時,因子分解機模型定義如下:
其中,[p]是輸入特征向量[x]的維度,[<?,?>]是兩個特征向量的內積,[β0∈?],[βi∈?P],[θ∈?p×k]是可以通過訓練集估計的模型參數,[β0]是一個全局偏置量,[βi]是特征變量[xi]的權重,[βi,j≈<θi,θj>]是成對變量[xixj]的權重。通過變換可以發現,FMs能夠在[O(kn)]線性時間內進行有效計算。
3.2 灰色服務網頁過濾建模
可將文本文檔視為由一組詞語[(t1,t2,?,tn)]構成,每一詞語都賦以一定的權值[w]。根據因子分解機定義,可將文檔的特征向量用其權重進行擴展[19],由此構造因子分解機的輸入特征向量如下:
3.3 過濾算法學習
使用下列目標函數訓練因子分解機分類器[20]:
4 實驗結果與分析
為驗證本文過濾方法的準確性與有效性,分別采用文獻[10]、文獻[11]和本文提出的權重計算公式計算詞語權重,然后分別采用KNN、SVM和FMs分類算法對3種權重計算方法的分類效果進行比較。實驗所用數據集來源于真實網絡環境,訓練數據由人工挑選,共挑選2 500個網頁,其中1 500個網頁為正常網頁,1 000個網頁為代孕網頁。測試數據通過網絡隨機爬取800個網頁。實驗結果選擇精確率、召回率作為指標評價,計算公式如下:
其中,[P]為精確度,[Tp]為正確分類的灰色網頁數量,[Fn]為將灰色網頁分類為非灰色網頁的數量。[R]為召回率,[Fp]為將非灰色網頁錯誤分類為灰色網頁的數量。
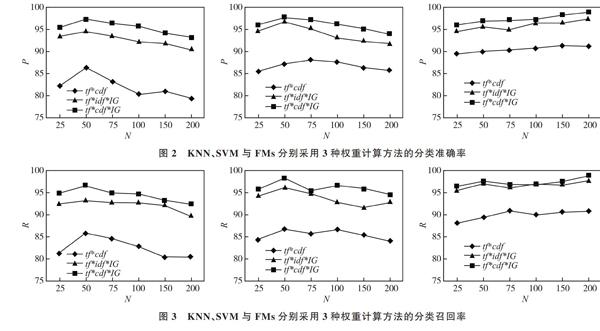
實驗參數設置:對于KNN分類算法,[K]=15;對于SVM分類算法,選用多項式核函數;對于FMs,[β0=1],[β1=2],[β2=2]。實驗結果分別如圖2、圖3所示。
從圖2和圖3可以看出,使用權重計算公式[tf*cdf*IG]計算權重,分類得到的精確率和召回率都比文獻[10]和文獻[11]高;同時可以看出,3種分類方法中,FMs的分類效果最好。值得注意的是,隨著特征向量的增加,KNN分類和SVM分類的精度有所下降,這可能是向量維數增加引入了噪音所致,而FMs的分類精度則隨著特征向量的增加而提高,這是因為FMs考慮了所有特征的成對交互作用,使得分類精度更高, 且其時間復雜度為O(kp),即它可以在線性時間復雜度內完成分類。
5 結語
本文針對互聯網灰色服務網頁特點,在TF*IDF特征選取與權重計算方法基礎上,提出了一種基于因子分解機的互聯網灰色服務網頁過濾方法。該方法克服了傳統方法中存在的高維文本分類困難和時間復雜度高的問題。以代孕網站為例,在真實環境中對該方法進行了大規模實驗和評估。實驗結果表明,該方法能有效表示灰色服務網頁特征,且對海量文本分類能夠在線性時間復雜度內完成,大大提高了灰色服務信息過濾的精度和速度。實際上,要判別一個網頁是否為灰色服務網頁,除了根據網頁文本進行判別外,還可從其鏈接結構、可視化特征等進行判別。如何將這些特征建模到向量空間,進一步提高FMs的分類精度,是下一步工作需要解決的問題。
參考文獻:
[1] 俞浩亮,王秋森,馮旭鵬,等. 基于特征加權的網絡不良內容識別方法[J]. 現代電子技術,2016(3):76-79.
[2] 王正琦,馮曉兵,張馳. 基于兩層分類器的惡意網頁快速檢測系統研究[J]. 網絡與信息安全學報,2017(8):48-64.
[3] 丁巖. 基于機器學習的釣魚網頁檢測方法研究[D]. 烏魯木齊:新疆大學,2018.
[4] 黃超. 基于Weka平臺的改進KNN中文網頁分類研究[D]. 上海:上海師范大學,2018.
[5] LIU P,ZHAO H H,TENG J Y,et al. Parallel naive Bayes algorithm for large-scale chinese text classification based on spark[J]. Journal of Central South University, 2019, 26(1):1-12.
[6] 張華鑫. 基于SVM的文本分類研究[J]. 情報探索,2015(5):133-135.
[7] 李村合,唐磊. 基于欠采樣支持向量機不平衡的網頁分類系統[J]. 計算機系統應用,2017(4):169-172.
[8] 火善棟. 用BP神經網絡實現中文文本分類[J].計算機時代,2015(11):58-61.
[9] 如先姑力·阿布都熱西提,亞森·艾則孜,郭文強. 維語網頁中n-gram模型結合類不平衡SVM的不良文本過濾方法[J]. 計算機應用研究,2019,36(12):214-218.
[10] 康進峰,王國營,梁春迎,等. 用于色情網頁過濾中的KNN算法改進[J]. 計算機安全,2009(9):17-22.
[11] 張玉芳,陳小莉,熊忠陽. 基于信息增益的特征詞權重調整算法研究[J]. 計算機工程與應用,2007,43(35):159-161.
[12] 李學明,李海瑞,薛亮,等. 基于信息增益與信息熵的TFIDF算法[J]. 計算機工程,2012,38(8):37-40.
[13] 李海瑞. 基于信息增益和信息熵的特征詞權重計算研究[D]. 重慶:重慶大學,2012.
[14] RENDLE S. Factorization machines[C]. IEEE International Conference on Data Mining. 2010: 995-1000.
[15] LIU X,ZHANG Y,LIU C. A nonlinear classifier based on factorization machines model[J]. Communications in Computer & Information Science,2014(483):1-10.
[16] HONG L J,AZIZ S,DOUMITH,et al. ACM international conference on web search and data mining[C]. Co-factorization machines: modeling user interests and predicting individual decisions in Twitter, 2014: 557-566.
[17] PAN Z,CHEN E,LIU Q,et al. Sparse factorization machines for click-through rate prediction[C]. IEEE ?International Conference on Data Mining, 2017:400-409.
[18] PAN J W,XU ?J,RUIZ,et al. Field-weighted?factorization?machines for click-through rate prediction?in?display?advertising[C]. Proceedings of the 2018 World Wide Web Conference:?2018:1349-1357.
[19] BABAK LONI,?YUE SHI,?MARTHA LARSON,?et al. ?Cross-domain collaborative filtering with factorization machines[C]. The 36th European Conference on IR Research, 2014:656-661
[20] RENDLE S. Factorization machines with LibFM[J]. ACM Transactions on Intelligent Systems & Technology, 2012, 3(3):1-22.
(責任編輯:杜能鋼)
