基于Windows的離線關鍵詞語音識別系統設計與實現
2019-10-18 02:57:59孫林超秦會斌崔佳冬
軟件導刊 2019年9期
孫林超 秦會斌 崔佳冬
摘 要:由于傳統人機交互大多使用鍵盤、鼠標等交互方式,速度較慢,因此語音識別開始受到越來越多人的青睞。但語音識別也存在如擴展性太差、可復制性不好造成單個產品價格過高、過于依賴外部條件導致對自身使用有所限制等問題。設計并實現一種基于本地的語音識別系統,通過構建抽象語法樹,實現語音控制操作。實驗結果表明,該系統的離線識別準確率可達70%以上,可以在局域網內實現語音操作。
關鍵詞:語音識別;離線識別;XML文件;語法樹
DOI:10. 11907/rjdk. 192017 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP319文獻標識碼:A 文章編號:1672-7800(2019)009-0116-05
Design and Implementation of Offline Keyword Recognition Based on Windows
SUN Lin-chao,QIN Hui-bin,CUI Jia-dong
(Institute of Electron Devices & Application, Hangzhou Dianzi University,Hangzhou 310018, China)
Abstract:In view of the shortcomings of the keyboard and mouse interaction methods used in the traditional human-computer interaction mode, such as slow speed and easy travel, voice recognition is increasingly favored by everyone. Nowadays, there are different problems in the speech recognition, such as extremely poor expansion, poor reproducibility of individual products, and relatively limited dependence on external conditions. We have designed and implemented a local speech recognition system in which an abstract grammar tree is constructed to realize operation controlled by speech. The experimental results show that the accuracy of the design is over 70%, and the effective speech recognition is realized. By setting off-line keywords with good extensibility and reproducibility, we can achieve the independence of speech recognition and the desired voice operation in the LAN.
Key Words:speech recognition;offline recognition;XML file;grammar tree
0 引言
語言是人們最常使用的交流方式之一,因此語音識別技術也成為人們關注的焦點。語音識別是將語音信號轉化為機器可理解信號的技術[1],涉及概率論、人工智能、信號論等多學科知識。語音識別始于上世紀50年代,當時主要實現了針對特定說話人的數字識別[2]以及對10個單音節詞的識別[3]。之后蘇聯學者Vintsyuk[4]以及日本的Itakura[5]、Sakoe[6]提出動態時間規劃與線性預測編碼技術,對于特定人與特定詞的語音識別取得了較好效果;1973年,美國的卡耐基梅隆大學和貝爾實驗室等研究單位構造了Harpy[7]等系統,為之后語音識別技術的快速發展奠定了基礎;進入80年代后,語音識別技術進入高速發展期,工具包HTK(Hidden Markov Toolkit)[8]等開源開發包與卡耐基梅隆大學搭建的SPHINX[9]的出現極大降低了語音識別技術的研究門檻,引發了語音識別技術新的研究熱潮;90年代之后,隨著技術的不斷進步,尤其是新聲學模型[10]的出現,例如線性動態模型(Linear Dynamic Model,LDM)[11]、隱藏動態模型(Hidden Dynamic Model,HDM)[12]等,語音識別技術開始從實驗室走向實際應用。近年來隨著運算與存儲技術的不斷成熟,語音識別技術開始大規模商用,國內外公司都紛紛推出自己的語音識別系統,如國外的微軟和蘋果,國內的百度、科大訊飛等公司,可以預見未來語音識別的商業應用范圍將會更廣[13]。
語音識別一般分為3類:孤立詞語音識別、連續語音識別與關鍵詞語音識別[14]。用于語音識別的技術手段較多,主要分為基于語音芯片與基于云平臺語音接口兩種方法。基于語音芯片的方法利用微處理器芯片上的嵌入式系統實現語音識別,但是存儲容量有限,給以后的二次開發帶來了較大困難[15];基于云平臺語音接口的方法因為其將語音片段存儲于云端,可節省本地內存,降低二次開發難度,但是同樣存在因網絡不穩定導致的問題,限制了其在部分局域網內的語音識別應用。
因此,針對以上問題,本文設計了基于Windows操作系統的離線關鍵詞識別軟件,可解決因存儲容量有限造成二次開發難度較高,以及網絡通信不暢時語音識別效果差等問題,同時充分考慮對語音要素的識別,在關鍵詞設置上充分考慮關鍵詞的通用識別性,以提高離線識別率。
1 語音識別基本流程與應用場景設計
1.1 語音識別基本流程
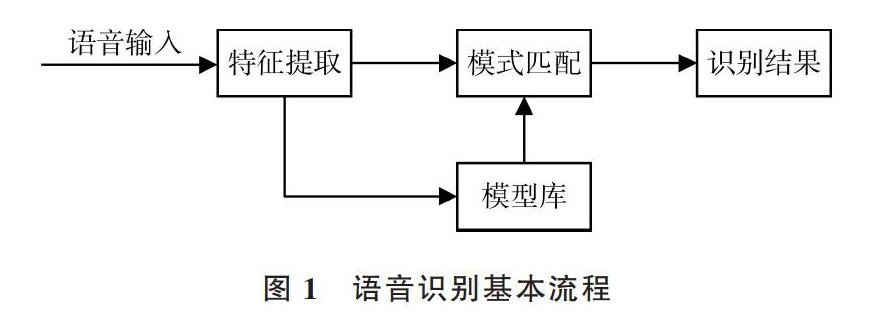
語音識別(SR)的本質是將輸入的音頻流信號借助訓練好的聲學模型轉變為文本信息的過程。該過程是一個搜索匹配過程,對存儲空間與系統計算能力有一定要求,也可以看成一個前端(Client)和后端(Server)的處理與通訊過程。語音識別基本流程如圖1所示。
前端過程為:將獲取到的錄音按照訓練的聲學模型進行切片處理,然后從每個單獨切片中獲取可能表示某個字詞的發音單元,然后將其轉換成該音頻信號中表示的數值。所以麥克風采樣率越高,對錄音的識別也越準確。
從技術層面上看,語音識別的后端處理更像是一個專門的搜索引擎,其接收前端產生的輸出并搜索3個數據庫:聲學模型、詞典及語言模型[16]。主要分為3部分:①聲學模型可以訓練識別特定用戶的語音模式與聲學環境特征;②詞典列出該語言中的大量單詞,并提供每個單詞如何發音的信息;③語言模型表示單詞組合方式。
對于任意給定的聲音片段,語音識別質量取決于搜索改進情況,以消除不良匹配,并選擇更可能的匹配。無論是處理聲音還是搜索模型,在很大程度上都取決于語言與聲學模型質量及其算法的有效性。
雖然識別器的內置語言模型旨在表示綜合語言域(如英語口語),但語音應用程序通常僅需處理對該應用程序具有特定語義的某些語言。 應用程序不應使用通用語言模型,而應使用限制識別的語法,以僅偵聽對應用程序有意義的語音。該方式具有以下優點:①提高識別準確性;②保證所有識別結果對應用程序都有意義;③使識別引擎能夠識別文本中固有的語義值。
1.2 離線關鍵詞語音識別設計應用場景
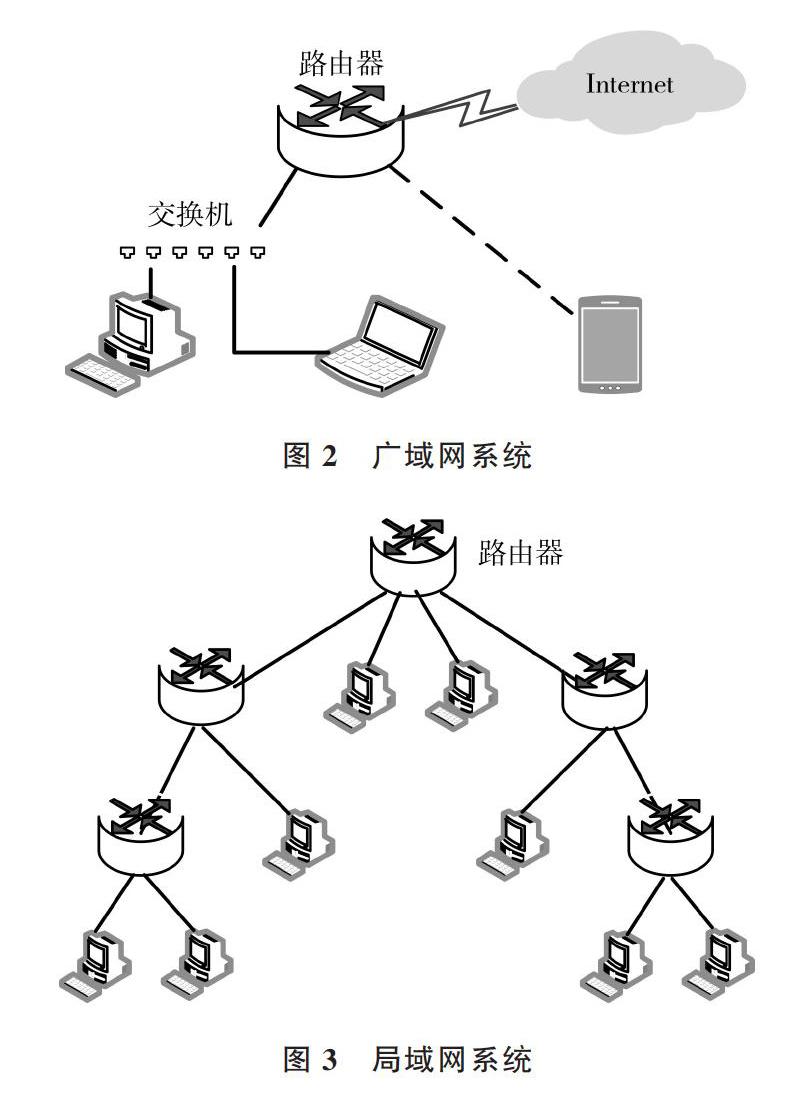
現有網絡系統主要分為兩類:廣域網與局域網。廣域網網絡連接外網系統,優點是易于擴展、系統處理能力強,但缺點是其嚴重依賴外網,如果外網出現問題,整個系統則難以運行,而且連接外網也會帶來一定安全風險;局域網不連接外網,在處理能力上不如廣域網系統,但不會面臨外網攻擊的危險,因此在使用過程中可靠性較高。廣域網系統與局域網系統分別如圖2、圖3所示。
對于語音識別開發而言,語音識別分為在線識別與離線識別兩類。因為在線語音識別的主要識別過程位于云服務器上,所以在線語音識別又稱為云語音識別。由于云服務器強大的存儲與計算能力[17],在線語音識別方法對長語音的識別準確率較高,但其缺點也很明顯,由于廣域網系統嚴重依賴于網絡連接,可能會產生網絡延遲等問題。在一些特殊場景下,如在局域網內或外網連接環境較差時,則要考慮采用離線語音識別方法。離線語音識別受限于系統自身條件,識別語句相對較短,準確率也較低,但其相對在線語音識別更加穩定可靠。
語音識別本質上是一個搜索匹配過程,離線語音識別要提高匹配準確率,需要在開發前為想要識別的語音設計專門的語法結構,以提高語音識別度。離線語音識別通過注冊特定詞匯,實現對特定聲紋的識別[18],比較適合于命令型場景,例如打開瀏覽器等。對于大型、復雜的軟件,由于交互界面按鈕較多,操作十分繁瑣,導致用戶體驗不佳,因此可以設定命令詞,在說出需要的關鍵詞后即可直接跳轉到對應頁面,并完成相應功能。
1.3 離線關鍵詞語音識別設計與實現
本設計是基于微軟的Windows系統平臺實現的,可將復雜的控制操作轉變為簡單的語音命令,并實現離線情況下對命令詞的識別,以及對語音命令的文本輸出。具體包括以下幾個步驟:①設計語音識別具體流程;②對關鍵的語法樹構建原則進行分析;③設置測試用例;④性能測試;⑤總結。
2 語音識別具體流程
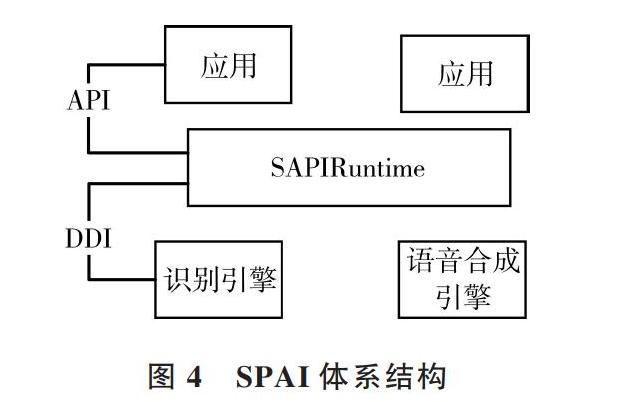
對于Windows系統而言,語音應用程序需要VC++ Runtime Library和.Net Framework 4兩個運行時庫,本質是構建基于SR與語音轉換(TTS)引擎上語音識別API(即SAPI)的語音應用程序。在Windows系統底層原理中,將SAPI Runtime作為提供語音技術支持(SR和TTS)的服務器,而每一個Application相當于訪問服務器接口的客戶端,因此需要安裝相關類庫。SPAI體系結構如圖4所示。
對于通用的語言識別有通用語言模型,但本文不使用通用語言模型,而使用限制識別的語法,以僅偵聽對應用程序有意義的語音。
在開發過程中主要遵循以下流程:①初始化語音識別器;②創建要識別的內建語法;③將創建的語法載入語音識別器;④注冊語音識別事件;⑤為注冊的語音識別事件創建對應處理程序。主要代碼如下:
首先需要設置相關的語音識別引擎。因為語音識別引擎只能根據具體某個國家、地區文化的語法、詞匯表、發音、意群等進行識別,所以當設置識別時,第一步需要指定要識別的國家語言發音庫、語法詞法結構等。例如設置識別的語言信息是中文,之后為音頻輸入添加相關配置,并添加系統音頻采樣設備參數。如麥克風采樣參數需要設置采樣率在8 000Hz 以上,一般設置為 16kHz ,可確保音頻信號不失真。采樣率是指 A/D 轉換過程中單位時間內的采樣次數,采樣頻率越高,則信號失真越小,對語音信號的識別越準確;麥克風聲道數一般設置簡單的單聲道即可,但為了應用于嘈雜的環境中,本文使用雙聲道,因為雙聲道降噪效果更好[19];位深度是指單次采樣精度,深度越深則精度越高。其它參數包括:語句間隔停頓時間、是否使用喚醒詞觸發等。
然后創建并加載語音識別語法,這也是其中最重要的。對于智能語音識別,需要充分考慮用戶可能表達的多種詞組,然后結合語音開發規范構建語法樹與詞典,以確保盡可能地識別含義相近的輸入。主要在SRGS xml文件中自定義語法,例如將以打開瀏覽器為目的的語法設置為“打開瀏覽器”,之后將語法文件載入程序中,作為語音識別分析與對比的對象;接下來注冊并添加識別之后的處理程序,以決定識別后的結果如何輸出,是以靜態文本形式輸出,還是以彈框形式輸出;識別完成后,最后卸載語法、關閉音頻輸入接口、卸載語音識別引擎,完成一次語音識別過程。具體流程如圖5所示。
3 語法樹構建原則
在執行識別任務時,語音識別引擎將識別結果返回到語音應用,包括語音輸入的語義信息,以及識別的單詞和短語文本。識別結果中包含的語義信息對于應用程序而言通常比識別的文本更具有意義。通過編寫語義內容,以及從識別結果中檢索語義代碼,為應用程序提供可操作的信息。
語音識別語法由結構化的規則列表組成,該規則列表是語音識別引擎應嘗試在語音輸入中識別的單詞或短語。語法規則可以識別簡單的單字命令,例如“打開”或“打印”,以及更復雜的句子結構,例如“我想預訂從廣州飛往上海的航班,下周二出發”。語法通常定義有限的詞匯表,其關注于用戶希望完成的特定任務或任務集上。
語法必須定義適用于特定情況的結構化邏輯語音語句。同時,語法必須足夠靈活,以包容語音輸入的細微變化,以實現更為自然的說話風格,提供更好的用戶體驗。以咖啡訂購為例:①“一會兒我想要一個拿鐵咖啡”;②“你可以給我一杯咖啡嗎?謝謝”。
上述語言語法,包括主謂賓的陳述表達形式、祈使句形式和禮貌用語的提問形式等。但事實上,一家咖啡店絕不僅只有拿鐵咖啡一種類型,可能還包含卡布奇諾等其它種類咖啡,因而還涉及到選擇。又例如:①“我打開電燈”;②“我打開空調”;③“你關閉電燈”;④“你關閉空調”。
該陳述句也涉及到選擇,如圖6所示。
當選擇結構出現時,每個語法結構中的語法單元(主語、謂語、賓語)都是一種新狀態的開始,選擇結束后則會轉至下一狀態,語音識別應能很好地應對具體用語范圍內表達相同含義的不同語法結構與同義詞組選擇。
4 抽象語法實現
因用例識別以實現命令為主,而不需要考慮主語是誰,所以根據語法樹構建原則,只需考慮謂語及賓語變化。用例主要分為以下幾類命令:①控制類命令,如 “打開”、“關閉”;②改變屬性類命令,如“增大”、“減小”。這些命令的作用對象主要根據具體命令類型進行確定,例如:①具體設備。如:“電燈”、“空調”、“攝像頭”;②具體屬性。不同設備有不同屬性,例如:“亮度”之于“電燈”,“溫度”之于“空調”。
但用戶使用時,又會存在不同表達方式,例如:①“打開電燈”和“把電燈打開”;②“電燈”的同義詞組,如“電燈”、“燈”、“智能燈”等,“打開”的同義詞組,如“開”、“打開”、“開啟”等。
因此,將語音識別核心處理邏輯分為兩部分:①語法構建;②注冊的語音識別程序處理業務邏輯。
語法構建調用CreateGrammar()函數,使用基于靜態的SrgsDocument文檔加載方法,因為該方法可以通過替換生成的靜態SrgsDocument文檔,有效應對語料庫不斷變更(如刪減或擴充)的情況,并且無需重新編譯整個語音程序。
調用CreateGrammar()函數后,則在內存中創建了語法樹。調用GenerateGrammar(srgsDoc)函數后,便通過DOM技術將內存中的語法樹寫入類xml風格文件中,并編譯生成性能更好、體積更小,但不易擴展與維護的擴展名為 ? ? ?“.cfg”的二進制語法樹格式文件。不論是裝載類xml風格的語法樹文件,還是裝載類xml風格編譯后生成的二進制語法樹格式文件,語音識別引擎都能識別出構建的語料庫,區別僅在于:①“.cfg”文件需要通過編譯“.xml”生成;②替換與裝載“.xml”文件,或者“.cfg”文件。
5 系統性能測試
為了驗證開發的語音識別系統是否可以較為準確地識別出預定義的語音指令,下面進行語音測試實驗。測試環境選擇較為安靜的大學教室,試驗設備如表1所示。選擇A、B、C 3人分別讀出“打開電燈”、“打開空調”、“關閉電燈”、“關上電燈”,每人平均讀100次,然后統計成功率。
其中,“打開電燈”的成功率為71%,“打開空調”的成功率為72.3%,雖然低于在線識別方法90%的成功率,但仍達到了比較滿意的效果[20]。對比表4、表5可以看出,在相同環境下,針對3人語音的平均識別率因命令詞不同而有很大差別,一個高達71.7%,一個只有34%。其中的主要差別是“閉”與“上”,雖然語義目的相同,但是語音語調不同[21]。“上”中包含了翹舌與后鼻音,有些地方方言較重,無法區分前鼻音和后鼻音或者翹平舌,有些地方方言較輕則讀音較準。但“關上”動作在系統操作中是不可或缺的,所以設計命令詞時,需要回避一些難以識別的詞,以增強系統可靠性。
6 結語
本文設計并實現了一個基于Windows的關鍵詞離線語音識別系統,可根據實際應用需要設置控制詞,方法較為簡單,在語音識別中不需要花費大量時間與精力設計聲學模型,且不依賴于網絡連接。經過測試,該方法可以有效識別出文本結果,且成功率較高。由于實驗條件的限制,本設計還有許多需要改進的地方,例如對一些長句識別的靈活性尚有待提高,并且需要進一步實現與移動端的結合。
參考文獻:
[1] 詹新明,黃南山,楊燦. 語音識別技術研究進展[J]. 現代計算機:專業版,2008(9):43-45,50
[2] DAVIS K H,BIDDULPH R,BALASHEK S. Automatic recognition of spoken digits[J]. The Journal of the Acoustical Society of America, 2005, 24(7):669.
[3] OLSON H F,BELAR H. Phonetic typewriter[J]. IRE Transactions on Audio, 1957, 5(4):90-95.
[4] VINTSYUK T K. Speech discrimination by dynamic programming[J]. ?Cybernetics, 1968, 4(1):52-57.
[5] ITAKURA F. Minimum prediction residual principle applied to speech recognition[J]. IEEE Trans. Acoust. Speech Signal Process,1975.
[6] SAKOE H,CHIBA S. Dynamic programming algorithm optimization for spoken word recognition[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing,1978, 26(1):43-49.
[7] LOWERRE B. THE harpy speech understanding system[M]. Readings in Speech Recognition, 1990:576-586.
[8] AL-QATAB B A Q,AINON R N. Arabic speech recognition using hidden Markov model toolkit(HTK)[C]. Information Technology (ITSim), 2010 International Symposium in. IEEE, 2010.
[9] LEE K F,HON H W,REDDY R. ?An overview of the SPHINX speech recognition system[J]. IEEE Transactions on Acoustics, Speech and Signal Processing, 1990, 38(1):35-45.
[10] 劉聰. 聲學模型區分性訓練及其在LVCSR系統的應用[D]. 合肥:中國科學技術大學, 2010.
[11] FRANKEL J F J,KING S K S. Speech recognition using linear dynamic models[J]. IEEE Transactions on Audio Speech and Lanuage Processing,2007,15(1):246-256.
[12] DENG L. Dynamic speech models—theory, algorithms, and applications[J]. IEEE Transactions on Neural Networks,2009,20(3):545-546.
[13] 孫晶,凌云峰. 語音識別系統技術及市場前景探析[J]. ?科技資訊,2011(20):1.
[14] 張帥林. 基于HMM的關鍵詞語音識別技術在智能家居中的應用研究[D]. 蘭州:蘭州交通大學,2017.
[15] 陳哲. 智能家居語音控制系統的設計與實現[D]. 成都:電子科技大學,2013.
[16] 馬志欣,王宏,李鑫. 語音識別技術綜述[J]. 昌吉學院學報,2006(3):93-97.
[17] 吳吉義,平玲娣,潘雪增,等. 云計算:從概念到平臺[J]. 電信科學,2009,25(12):1-11.
[18] 鄭方. 聲紋識別技術及其應用現狀[J]. 信息安全研究,2016,2(1):44-57.
[19] 李曉雪. 基于麥克風陣列的語音增強與識別研究[D]. 杭州:浙江大學,2010.
[20] 茍鵬程. 基于Android的語音識別設計及應用[D]. 天津:天津大學,2017.
[21] 李如龍.論漢語方言語音的演變[J]. 語言研究,1999(1):102-113.
(責任編輯:黃 健)
