關系數據庫的實體間關系提取方法的研究
2019-10-18 11:13:12王嘉慶楊衛東何亦征
計算機應用與軟件 2019年10期
王嘉慶 楊衛東 何亦征
1(復旦大學計算機科學與技術學院 上海 201203)2(中國航空無線電電子研究所 上海 200233)
0 引 言
關系數據庫作為一種物理模型,出于自身模式、軟件限制、數據庫設計考慮等多方面因素,普遍存在缺乏語義的問題。數據庫中存儲著大量數據,人工添加語義關系耗時耗力[1]。因此提出了各種從關系數據庫中自動提取語義信息,構建知識圖譜中RDF三元組的方法。
目前,眾多相關學者和機構已經關注于這一領域[2-3],W3C提出了直接映射法,定義了將關系數據庫映射為RDF圖的簡單映射規則,可將數據資源轉換為機讀格式。文獻[4]中的方法注重于映射的自動發現,使用基于上下文的方法,利用已有的本體網絡,構建起數據庫到本體的映射關系。D2R Map[5],以及在其基礎上進一步改進的DB2OWL[6]均利用了外部的SQL查詢語句,利用SQL中涉及的表格和屬性構建RDF。R2RML[7]、D2RQ[8]則在SQL語句之外加入了特殊映射語言,允許在構建的映射規則上進行人工修改和補充。Triplify[9]與數據庫發布后的網頁應用交互,將關系數據庫轉為連接數據發布。
上述基于規則的轉換方法主要考慮數據庫結構信息的轉換,較少研究數據庫實體間關系的發現,導致其轉換結果未能完全展現數據庫中蘊含的語義信息,最終生成的RDF中存在冗余實體,也缺失了部分實體間關系。基于規則的轉換方法對圖1中關系數據庫表的轉換結果如圖2所示。表示Movie表與Actor表間多對多關系的MovieActor屬性被轉換為MovieActor實體,造成了冗余,表示Director表與Movie表之間一對多關系的DirectorID屬性被轉換為Movie實體的屬性,缺失了對該關系的表達。
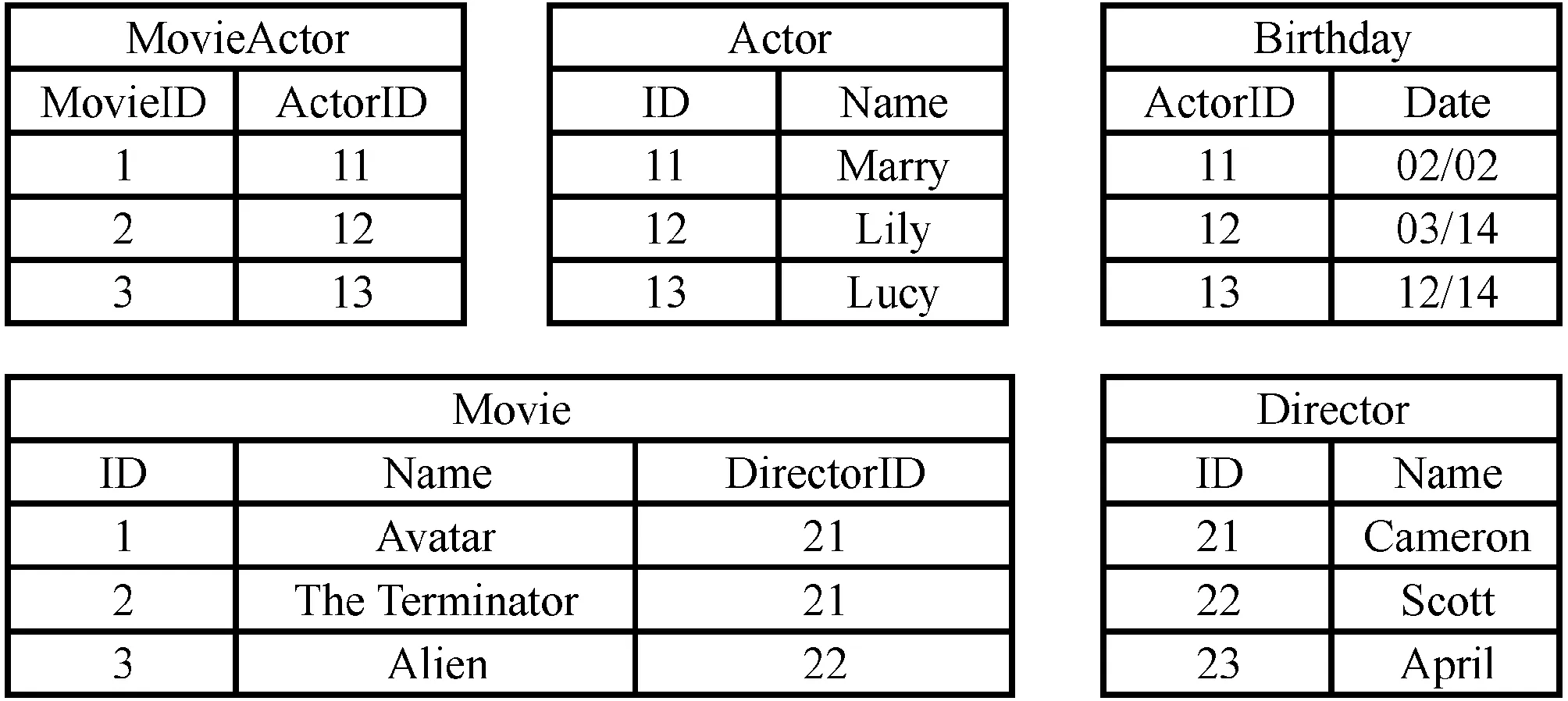
圖1 關系數據庫表示例
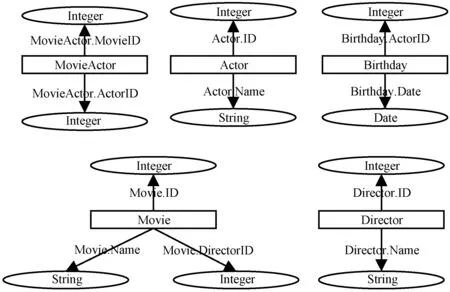
圖2 基于規則的轉換方法構造的實體關系圖
針對上述問題,本文提出了一種新的關系數據庫到RDF的構造方法,使用基于隨機森林算法發現和提取的實體間語義關系提升RDF結果的質量。該方法構建融合了數據庫模式和數據內容的特征向量,設計并實現了基于隨機森林的實體間語義關系發現算法,發現實體間潛在的語義關系,并基于發現的語義關系,提出了關系數據庫的一般轉換規則與多對多、一對多等實體語義關系的特殊轉換規則,完善了RDF中對關系的表達,減少了RDF中的冗余。
該方法對圖1中數據庫轉換結果如圖3所示。虛線代表發現的實體間語義關系。圖1中表示多對多關系的MovieActor表被轉換為Movie實體與Actor實體間的Movie-has-Actor關系,Movie中表示一對多關系的DirectorID屬性被轉換為Movie實體與Director實體間的Director-of-Movie的一對多關系。與圖2對比可以看出,圖3中發現的實體間多對多、一對多等語義關系有效地連接了各個實體,減少了最終結果的冗余。
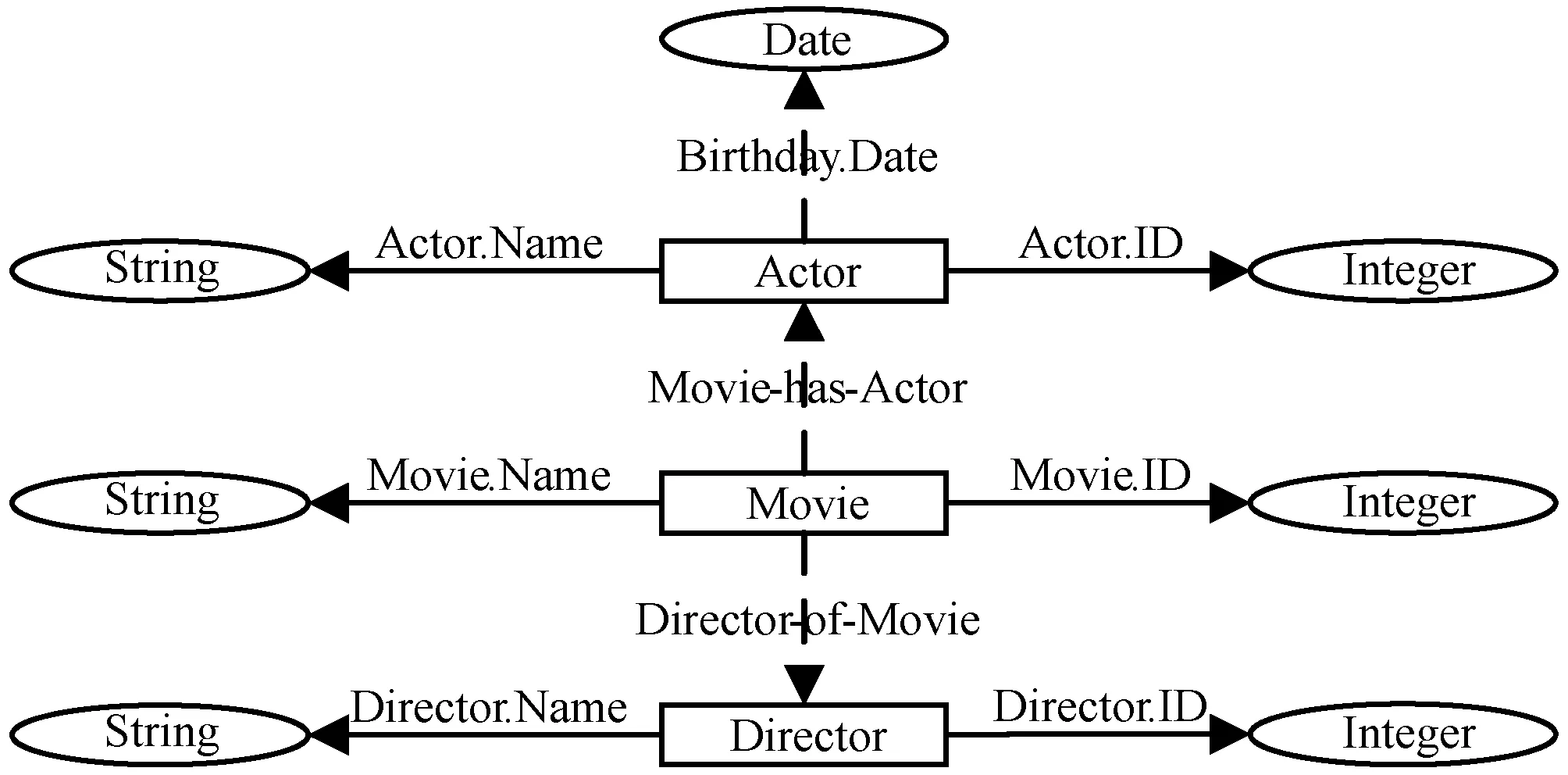
圖3 實體間關系提取方法構造的實體關系圖
1 整體流程
本文提出的實體間關系發現與轉換方法的基本流程如圖4所示。
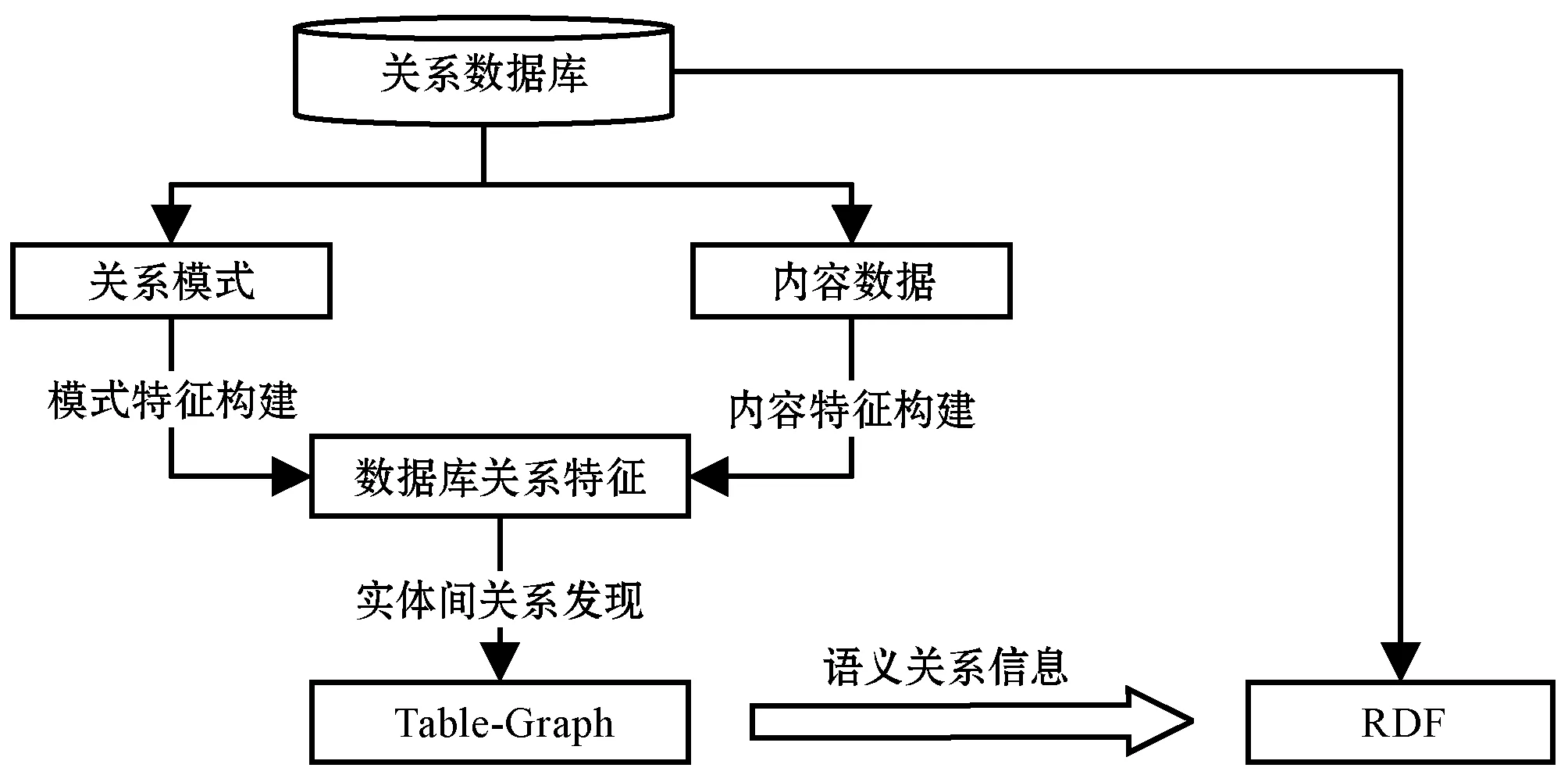
圖4 實體間關系發現轉換方法的流程圖
整個構建過程可被分為實體間語義關系發現和實體間語義關系轉換兩部分。
在語義關系發現部分,主要發現了數據庫中可以表示為實體的表,以及實體間的潛在語義關系。首先,從關系數據庫中抽取關系模式和內容數據,利用模式特征構建和內容特征構建,組成數據庫關系特征向量。然后,利用數據庫內已有的關系,使用隨機森林算法對特征向量進行訓練獲得模型。最后,使用模型對潛在語義關系進行判斷,其判斷結果被存儲為Table-Graph。Table-Graph是本文定義的用于描述數據庫語義關系的圖。關系數據庫模型主要由一系列關系模式及關系模式間的引用關系組成,若將關系模式作為節點,將關系模式之間的引用關系作為圖中的有向線段,這樣的圖即可用于對關系數據庫模型的描述。
在語義關系轉換部分,通過對Table-Graph的分析,區分出數據庫中用于表示關系的表和表示實體的表,對多對多、一對多等關系進行轉換,并給出一系列規則來描述如何將數據庫中的實體、屬性、關系及數據轉換到RDF中。
本方法側重于數據庫內實體間語義關系的發現工作,因此將關系模式信息和RDF轉換分離進行,使用Table-Graph作為中間結果。這樣的好處是可以更好地評估整個關系數據庫內部的實體關系,同時,若實體間關系發現部分加入了新的規則,不會影響到實體間關系的轉換部分。
2 實體間關系發現
在關系數據庫中,由于數據庫軟件自身的限制,或者是設計人員在構建時缺乏數據庫相關知識,數據庫模型存在缺乏語義的問題[10]。因此在實體間關系轉換之前,先要發現關系數據庫模型中的潛在語義關系。
潛在語義關系可由數據庫模式推斷而來,例如圖1中Movie表中有DirectorID字段,而Director表中存在ID字段,那么這兩個字段之間很有可能有語義關系。但是,僅僅通過數據庫模式判斷常常存在大量的假陽性問題。例如圖1中Movie表有ID字段,Actor表亦有ID字段,僅通過數據庫模式判定,會認為二者間具有語義關系,但事實上這兩者并不相關。因此引入內容數據進行判斷,Actor的ID字段內容與Movie的ID字段內容差異較大,判斷二者并無語義關系,從而減少判斷的假陽性問題。本文融合了數據庫模式和數據內容構建特征向量,用于發現潛在的語義關系。
從關系數據庫到Table-Graph的步驟如下:1) 根據數據庫模式和數據庫內容實例構建特征向量;2) 使用分類算法對特征進行學習訓練;3) 使用訓練出的模型對所有語義關系進行判定,檢測其是否成立,構成最終的Table-Graph。
為了方便討論,將數據庫表記為T,數據庫表的屬性記為a,待判定的語義關系記為IND(a1,a2),其中a1∈T1,a2∈T2且T1≠T2。如果IND(a1,a2)成立,將a1稱為依賴屬性,將a2稱為引用屬性。
2.1 實體間關系特征構建
2.1.1屬性名稱相近度特征
由于數據庫屬性名稱命名存在不規范現象,為了提高評判的精準性,本文對屬性名稱進行規范化后構建詞集,使用詞集判定IND(a1,a2)中屬性名稱的相近度。該算法偽碼描述如算法1所示。
算法1屬性名稱相似度特征
Input:屬性名稱a1、a2,表名T1,T2
Output:詞集相似度特征R1、R2
1S1←split(a1),S2←split(a2),R1←1.0,R2←1.0
2 ifS1equalS2then
3 returnR1,R2
4 end if
5S1←S1∪split(T1),S2←S2∪split(T2)
6S1←S1∪headof(T1),S2←S2∪headof(T2)
7S1←S1-stopWord,S2←S2-stopWord
8R1=length(S1∩S2)/length(S1)
9 R2=length(S1∩S2)/length(S2)
10 returnR1,R2
該算法包括以下步驟:
1) 復合詞組拆分,使用符號分析器split函數,將屬性名稱字符串根據連接符、大小寫、數字等將復合詞組拆成單獨的單詞集合。若拆分后的詞集相同,則直接返回屬性A1到屬性A2,屬性A2到屬性A1的詞集相似度均為1.0。
2) 將表名歸入單詞集合,對表名進行同樣的復合詞組拆分,使用用headof函數,取表名首字母組成表名縮寫,將拆分后的表名詞組和表名首字母縮寫一并歸入詞集,然后從詞集中去除id、key等常見stopWord。
3) 計算詞集的交集對(a1,a2)各自詞集的覆蓋情況,作為一項特征歸入接下來的計算。
2.1.2數據類型匹配特征
同一數據在不同表格中可能有多種存儲形式,例如電話號碼,在一個數據庫表格中存儲為vchar類型,而在另一數據庫表格中存儲為Integer類型。為了提高語義關系發現的召回率,本文結合文獻[11]中提到的方法,根據數據類型之間相互轉換的情況定義了相似度表格判定屬性間的數據類型匹配程度。表1展示了部分數據類型間的匹配特征矩陣。
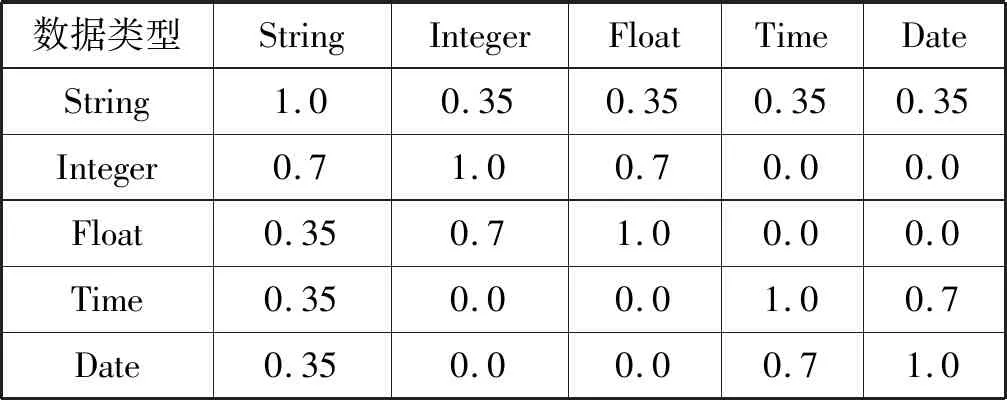
表1 數據類型相似度表
2.1.3數據庫關系特征
在數據庫中已經存在的語義關系IND(ai,aj)包含了數據庫所涉及領域的語義,因此可以對潛在的IND(a1,a2)的推斷提供信息,主要有以下三種情況:
1) 被引用中的依賴:該特征計算IND(ai,a1)已經成立的次數。通常,一個依賴屬性不會在其他IND中作為引用屬性出現,即不會出現依賴傳遞的情況。IND(ai,a1)出現的次數越多,IND(a1,a2)成立的可能性越小。
2) 多重引用:該特征計算IND(ai,a2)已經成立的次數。從對現有數據庫的分析中得知,引用屬性通常被多個屬性依賴著。IND(ai,a2)出現的次數越多,IND(a1,a2)成立的可能性越大。
3) 多重依賴:該特征計算IND(a1,ai)已經成立的次數。根據現有的實驗分析,同一屬性通常不會出現多重依賴關系。若已有IND(a1,ai)成立,則IND(a1,a2)成立的可能性下降。
2.1.4數據庫內容交集特征
在絕大多數情況下,引用屬性覆蓋了依賴屬性的大部分取值,而依賴屬性是引用屬性的一個隨機取樣。這里使用屬性a1、a2的值交集情況作為判定IND(a1,a2)成立的特征。設d1、d2是屬性a1、a2的中獨特值的集合,使用文獻[12]中的Jaccard系數進行判定:
2.1.5數據庫內容實例特征
描述同一實體的屬性的數據內容通常有相似的分布情況,這里使用屬性a1、a2的值的分布情況作為判定IND(a1,a2)成立的特征。使用Wilcoxon rank-sum算法[16]進行隨機性測試,判定屬性a1、a2的值的分布情況是否相同。該算法不要求對比的屬性具有相同數量的值,適合計算IND(a1,a2)屬性值的分布相似特征。
2.2 實體關系發現模型訓練
在獲取特征之后,需要對每個特征進行估值,以決定其在對新數據集進行處理時所占的權重。本文從已有IND的數據庫中構建數據庫模式特征和內容特征,組成特征向量,使用了scikit-learn[13]提供的隨機森林算法對特征進行有監督的學習,訓練相應的模型,以獲得特征的權重。在訓練好模型后,對需要進行轉換的數據庫中所有的IND(ai,aj)進行判定,分離出成立的IND(a1,a2),構建Table-Graph。其中特別處理了以下情況:
1) 空表格。若已有的IND(a1,a2)中的a1或a2中沒有內容,因為無法從屬性中提取實體,所以該IND(a1,a2)視為不成立。
2) 被引用的依賴屬性。該情況中的特征已在2.1節中剔除,但存在例外情況,當已有的IND(a1,a2)和IND(a2,a3)均成立時,則IND(a1,a3)視為成立。
3) 一對一關系。當兩個主鍵一一對應時,則IND(a1,a2)和IND(a2,a1)均視為成立。
2.3 生成Table-Graph
為了表示數據庫中各個表之間的關聯,發掘出數據庫內蘊含的語義信息,本文提出Table-Graph。Table-Graph是用于描述數據庫語義關系的有向圖,將數據庫表作為圖中的元素,數據庫表間引用關系作為圖中的邊,從而表示數據庫表間的關聯,為接下來的實體間關系轉換提供指導。
若將原關系數據庫模型形式化地表示為T(A,D,F),其中T為數據庫表;A為組成該表的屬性集合;D為屬性域的集合;F代表屬性間的約束關系,包括主鍵、外鍵及其他完整性約束。為了方便,給定以下函數:
PK(T):表示T的主鍵,為一屬性組。
FK(T):表示T的外鍵,為一屬性組。
IND(a1,a2):當其為真時,表示來自T1表的a1屬性,引用了來自T2表中的a2屬性。
那么,將Table-Graph所有元素的集合記為V,所有有向邊的集合記為E。假設有兩個元素a1∈T1,a2∈T2,且IND(a1,a2)為真,則a1∈V,a2∈V,且(a1,a2)∈E。
在分辨出所有成立的IND(a1,a2)后,可以按以下步驟自動生成Table-Graph:
1) 將所有T(A,D,F)構成元組,作為元素加入圖中。元組內容為T中所有屬性A,元素命名使用T的名稱。
2) 對所有為真的IND(a1,a2),在圖中將a1和a2這兩個元素連接起來,由a1指向a2。
對圖1中數據庫生成的Table-Graph如圖5所示。
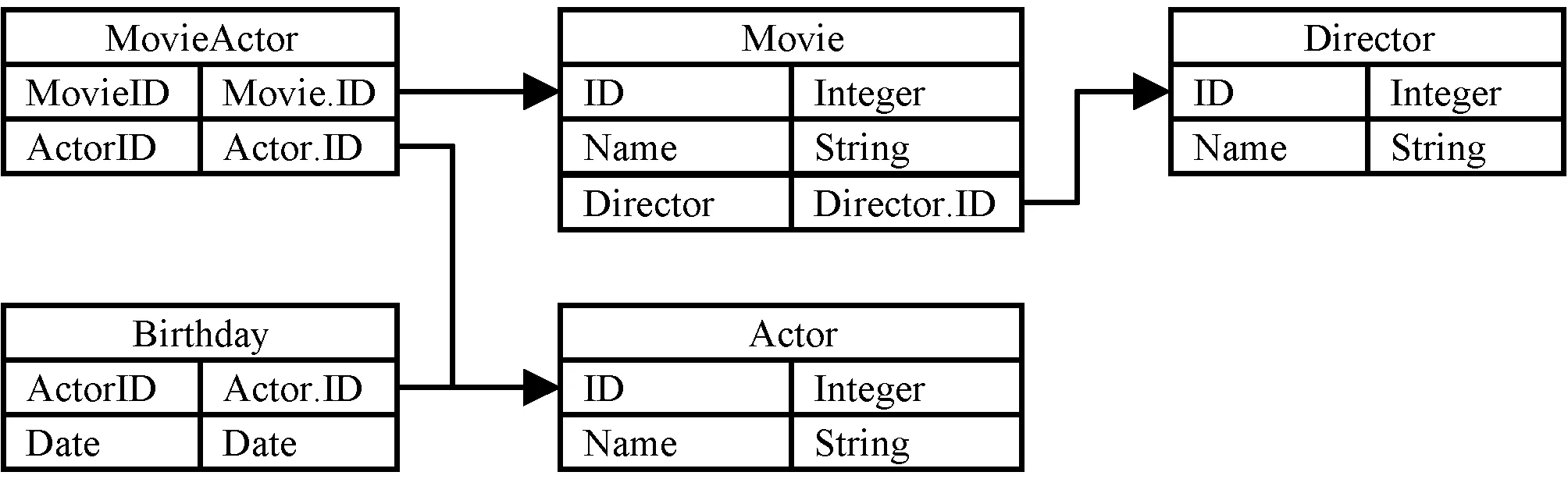
圖5 Table-Graph示例
3 實體間關系轉換
在獲得了Table-Graph后,可利用一些著名且普遍出現的關系數據庫模式,例如經常出現的多對多關系、一對多關系,為轉換結果提供額外的轉換信息。接下來介紹Table-Graph的一般轉換規則以及這幾類關系的特殊轉換規則。
3.1 一般轉換規則
根據W3C的直接映射規則規定,本文針對Table-Graph的一般轉換規則如下:
1) 利用2.1節中提到的屬性名稱詞集構建方法,去除Table-Graph中各屬性的冗余部分,如數據庫表名縮寫、連接符等。但若數據庫屬性詞集只含有常見后綴,則不去除。例如:若屬性名為DirectorID,則將其化簡為Director;若屬性名為ID,則保持屬性名仍為ID。
2) 對Table-Graph中每一元素的主鍵生成一個RDF實體,其URI由表格名稱和主鍵名稱組成,用符號“=”連接主鍵名稱和主鍵內容。例如在Actor表中,屬性ID值為11的條目將被轉換為實體
3) 為上面的每一個實體增加一個rdf:type,它的值來自數據庫庫關系圖元素的名稱。例:
4) 對Table-Graph元素的各個非主鍵屬性生成RDF三元組。用符號“#”連接數據庫元素名和屬性名作為這一關系的名稱,它的值來自Table-Graph該屬性的值。如上述的Actor表中有Name屬性,則會生成三元組
5) 對一般的實體間關系,根據上面的第一步生成兩個實體,使用依賴屬性的Table-Graph元素名加-rel-加依賴屬性名的方法作為這一關系的名稱。若Actor表有一age屬性,依賴于另一張Date表中屬性year,則這一關系轉換的RDF三元組為:
3.2 特殊轉換規則
在關系數據庫模型中,有時一些表格并不代表實體,而是作為鄰接表存在,屬于對關系的一種表示,因此在最終的RDF結果中不應轉為實體。與文獻[14]不同,本文對這些關系的轉換無需現有的本體網絡參與,而是利用Table-Graph,提出了針對實體間關系的特殊轉換規則:
1) 多對多關系。在Table-Graph中,若有v∈V,v中僅包含屬性e1和e2,且(e1,ei)∈E,(e2,ej)∈E,ei∈PK(vi),ej∈PK(vj),則v只是用來描述vi和vj之間的多對多關系。對屬性e1和e2無需提取RDF三元組,而是根據v中的每一元素內容構建一條RDF,其主體和客體分別是ei和ej對應的實體,而關系的命名法是v1-has-v2。例如圖5中的MovieActor表,在轉換為RDF可表示為:
2) 一對多關系。若有v1∈V,v2∈V,e1為v1中屬性,e2為v2中屬性,有(e1,e2)∈E,e1?PK(v1),e2∈PK(v2),則存在e1到e2的多對一關系。這種多對一關系將被轉換為RDF中的屬性。這一RDF屬性的命名法是v2-of-v1,RDF屬性的domian為e2屬性,RDF屬性的range為v1中除e1外的其他屬性。該屬性轉換后的客體將是v1對應的實體。例如圖5中的Movie表中的DirectorID屬性,則會轉換為:
4 實驗評估
4.1 實驗評價指標
本節通過實驗驗證本文所提方法的有效性,使用綜合評價指標(F-Measure)進行評估。假設方法返回的所有相關關系中正確的為TP,錯誤的為FP,所有領域專家人工發現正確的關系數為R,則綜合評價指標定義如下:
4.2 實驗分析
在實驗數據方面,選用TPC-H、TPC-DS、MovieLens和AdventureWorks這四個數據集。表2列出了這些數據的表格數量、屬性數量、元組數量和實體間關系數量等數據特征。
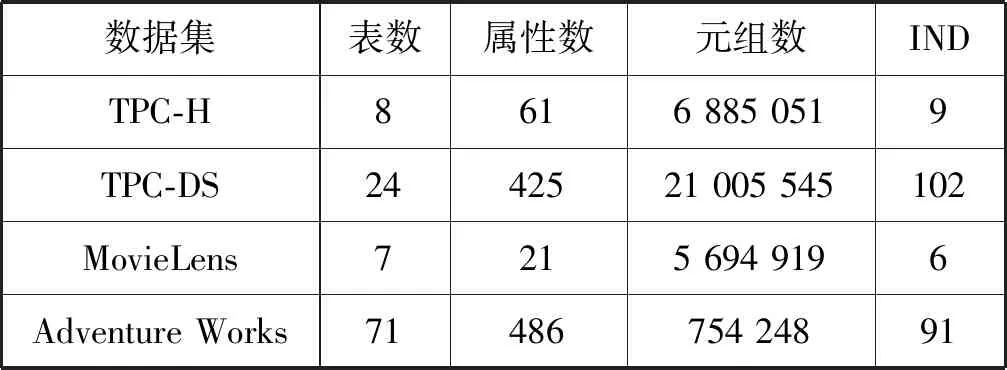
表2 實驗數據特征
由于這些數據庫沒有標準的RDF轉換后結果,因此采用去除數據庫表間已有實體間關系構成新的數據集。在該數據集進行挖掘,將挖掘出的實體間關系與原數據集的實體間關系進行對照,以評估算法。
在實驗部分,首先構建如表3所示的4個訓練/測試集。保證來自同一數據庫的實體間關系不會被用在同一數據庫的驗證過程中。
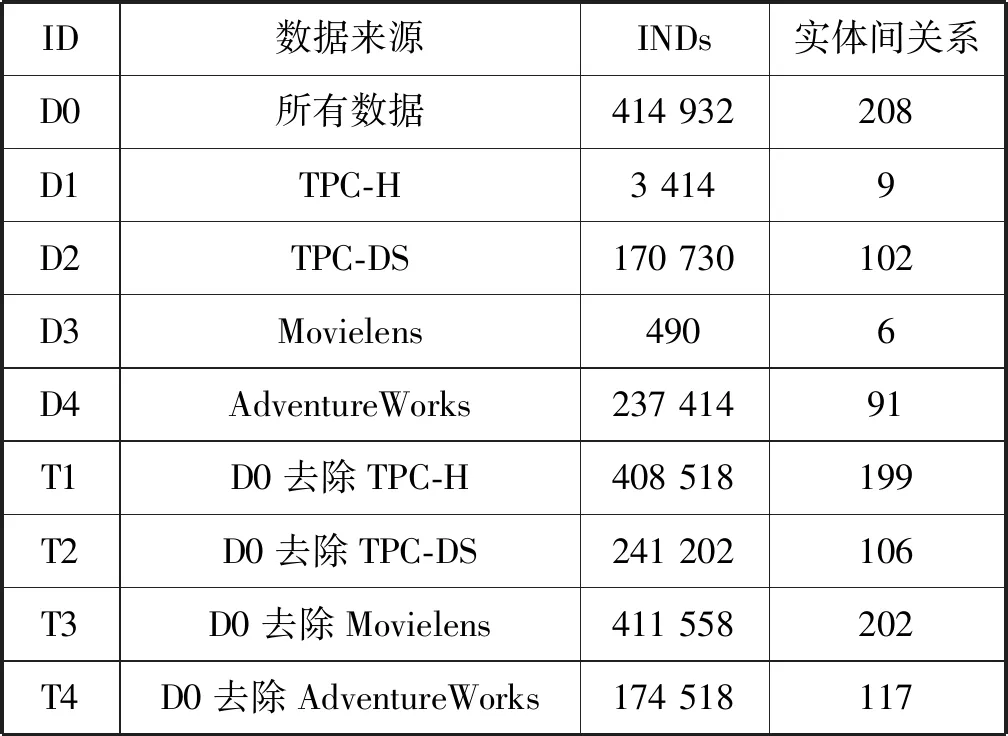
表3 訓練/測試數據特征
然后使用文獻[15]中的實體間關系預測辦法(MLA),對數據集進行提取,其對比結果如圖6所示。接著使用本文的算法,對同一數據集進行提取,并對比提取結果。在MLA中提到了四種算法,這里選擇與其中表現效果最好的J48進行對比。
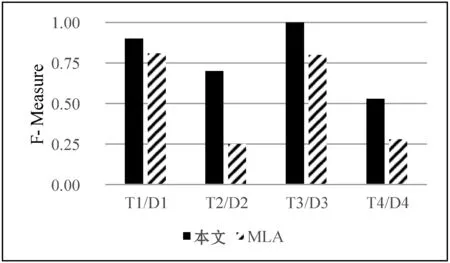
圖6 MLA與本文的提取結果的對比
可以看出,本文的方法在四個數據集上均獲得了優于前者的效果,足以證明所提方法的有效性。特別的,在T2/D2和T4/D4這兩個數據集上,由于這兩個測試數據集中的關系數據庫屬性存在命名不規范現象,MLA的表現較明顯地弱于本文所使用的方法,而本文使用詞集構建的名稱特征以及內容特征處理這一問題,獲得了更好的效果。
此外,本文還對數據庫內已存在實體間關系的情況進行了實驗。不使用已有實體間關系,基于數據庫劃分數據集的實驗結果如表4所示。而利用了數據庫內已有實體間關系,使用交叉驗證方法進行預測的實驗結果如表5所示。平均預測準確度從0.78上升到0.87,可見引入同一數據庫內的實體間關系能有效提升潛在實體間關系的預測效果,印證了數據庫內可使用已有約束特征對實體間關系的預測效果這一假設。
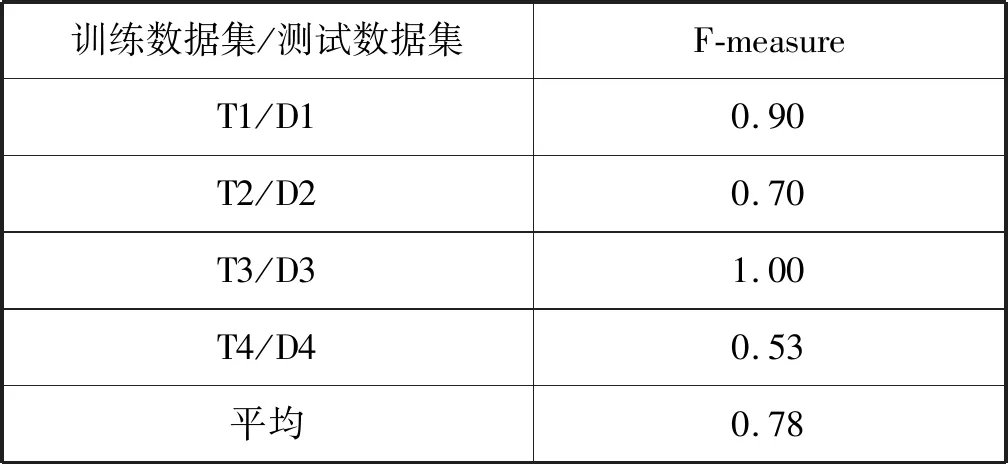
表4 基于數據庫層級的實驗結果
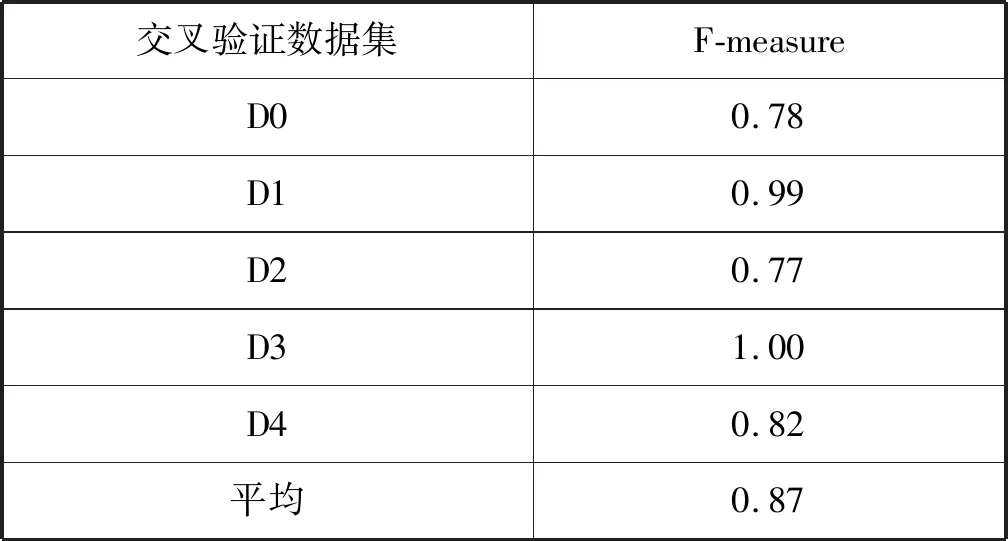
表5 基于交叉驗證的實驗結果
在完成上述的外鍵發現后,本文按照2.3節中的方法構建Table-Graph,用鄰接矩陣保存Table-Graph。根據3節中的數據庫設計模式,分析Table-Graph,發現其中的實體間關系,并完成到RDF的轉換。針對這一部分的測試,本文使用W3C RDB2RDF工作組提供的直接映射測試樣例進行實驗。該測試樣例中提供了使用直接映射方法構建的三元組,因此適合進行評估對比。該文使用測試集D011進行展示,該測試樣例不使用實體間關系發現的轉換結果如圖7所示,使用本文方法發現實體間多對多關系轉換結果如圖8所示。可以看出,發現的實體間關系減少了最終生成實體的數量,明確了其中潛含的語義關系,提升了最終生成RDF的質量。

圖7 未發現實體間關系的轉換結果示例

圖8 發現多對多關系的轉換結果示例
5 結 語
本文針對關系數據庫到RDF的轉換問題,在已有研究的基礎上,提出了一種利用數據庫中實體間關系發現與提取的方法。利用數據庫模式和數據庫內容構建特征,基于特征利用隨機森林算法搜索潛在實體間關系,利用實體間關系的相互結構構建數據庫到RDF的轉換。經實驗證明,該方法提升了發現數據庫中各屬性間的潛在關系的準確度,使用這些實體關系帶來的數據庫常見設計模式,發現其中潛藏的語義關系,能有效地減少最終生成RDF的冗余,提升了后續知識圖譜構建的質量。
當然,本文還有一些可以改進與擴展之處。比如,可以考慮提取更多種類的實體間關系,如繼承關系的提取,以進一步豐富最終結果的語義;另外,數據庫查詢的SQL語句中也存在一定的實體間關系,利用這些信息,亦可對實體間關系的提取問題產生積極的影響。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
大連民族大學學報(2015年2期)2015-02-27 08:28:11
