基于神經網絡與注意力機制的中文文本校對方法①
2019-10-18 06:41:16郝亞男喬鋼柱
計算機系統應用 2019年10期
郝亞男,喬鋼柱,譚 瑛
(太原科技大學 計算機科學與技術學院,太原 030024)
自然語言OCR識別后文本錯誤自動校對,已經引起越來越多的關注.近年來,我國法治建設的快速發展,類型多樣的法律案件數量增多.由于實際情況所限制,我國司法機關處理的案件卷宗以紙質卷宗為主,想要在較短的時間內獲取有效的信息,較為困難.隨著信息技術的廣泛普及,我國已逐漸將電子卷宗應用輔助辦案系統中.為加快紙質卷宗電子化,電子化過程中采取OCR識別技術.但是由于紙質卷宗的打印質量低或掃描不當等原因,導致紙質卷宗OCR識別效果不好.因此,在電子卷宗應用于后續任務前,需要有效的校對器來幫助紙質卷宗OCR識別后的文本自動校對.
由于中文文本與英文文本特點不同,中文文本校對是在錯誤文本的字詞、語法或語義等來進行校對的.目前,針對字詞級的OCR識別后的中文文本校對研究相對比較充分,但在OCR識別后的中文文本還存在許多其他類型錯誤,這些錯誤從字詞級的角度來看,可能不存在問題,但是不符合當前文本中的上下文語義搭配,例如:“透過中間人向另一方表示無欠債關系.”.其中,“透過”就是不符合文本語義搭配,此處應表示為“通過”.因此,本文主要是研究如何結合語義校對中文文本中的錯誤.
1 相關工作
在20世紀60年代起,國外就開始對英文文本拼寫自動校對進行研究.在研究初期主要是建立語言模型與字典來進行字詞級[1-4]的校對.近年來,字詞級校對的研究已經較充分,但在真詞錯誤校對時,若不限制給定語境,那文本校對的可靠性就難以保證.因此,學者們在基于語義對文本校對展開進一步研究.
Hirst[5]等在文本校對的計算中加入語義信息,采用WordNet來計算詞與詞間的語義距離,若詞間語義距離較遠,則判斷這個詞是錯誤的,反之,若發現與上下文距離語義較近的詞就可能被作為正確的詞.Kissos等[6]是基于OCR識別后的阿拉伯語校對,其采取的方式是通過與混淆矩陣相結合的語料庫形成候選數據集;然后對每個單詞所提取的特征對單詞分類,將候選集中排名最高的單詞作為校對建議.Sikl[7]等將校對問題看作翻譯問題來解決,把錯誤文本作為被原語言,糾正文本作為目標語言進行文本拼寫糾錯.張仰森等[8]提出了一種基于語義搭配知識庫和證據理論的語義錯誤偵測模型,構建三層語義搭配知識庫以及介紹了基于該知識庫和證據理論的語義偵測算法,有效地進行語義級錯誤偵測.Konstantin等人[9]提出基于邊際分布和貝葉斯網絡計算的方法,在一定程度上提高了低質量圖像的文檔字段OCR識別后校對準確率.陶永才等[10]基于構建詞語搭配知識庫,綜合使用互信息和聚合度評價詞語關聯強度,進行詞語搭配關系校對.Liu等人[11]提出基于注意機制的神經語法檢錯模型,將解碼端視為二進制分類器進行語法檢錯.劉亮亮等人[12]面向非多字詞錯誤提出基于模糊分詞的自動校對方法.姜贏等人[13]提出基于描述邏輯本體推理的語義級中文校對方法,通過描述邏輯推理機來判斷提取的語義內容的邏輯一致性,并將檢測出的邏輯一致性錯誤映射為中文語義錯誤.Xie等人[14]通過具有注意機制的編碼器和解碼器的遞歸神經網絡來進行字級別的英文文本校對.Yu等人[15]通過語言模型、拼音及字形完成校對工作.
分析以上文獻發現,在以往中文文本自動校對的方法中均進行了大量知識的準備工作,知識庫的完善程度對校對結果有很大影響.為了減少知識庫等相關知識對校對效果的影響,采用深度學習模型的思路完成文本自動校對任務.通過模型的自學習獲取詞間相關性,來完成文本校對任務,在一定程度上減少了人為干預.模型采用端到端序列模型,在解碼端與編碼端構成成分的選擇上,主要是從時間方面考慮選取了門控循環網絡與注意力機制層結合構成,最后通過Dense層和Softmax層完成文本自動校對任務.
2 基于神經網絡與注意力機制的校對模型
2.1 門控循環神經網絡
長短期記憶網絡(Long Short-Term Memory,LSTM)在自然語言處理任務中有著廣發的應用,但LSTM在訓練耗時長、參數多等問題.研究人員在2014年對LSTM進行優化調整,提出了門控循環神經網絡(Gated Recurrent Unity,GRU).
GRU保持LSTM優點的同時又使得內部結構更加簡單.GRU由更新門和重置門兩個門組成,更新門用于控制前一時刻的隱層輸出對當前時刻的影響程度,更新門的值越大說明前一時刻的隱藏狀態對當前時刻隱層的影響越大;重置門用于控制前一時刻隱層狀態被忽略的程度,重置門值越小說明被忽略的越多.
GRU的結構如圖1所示.
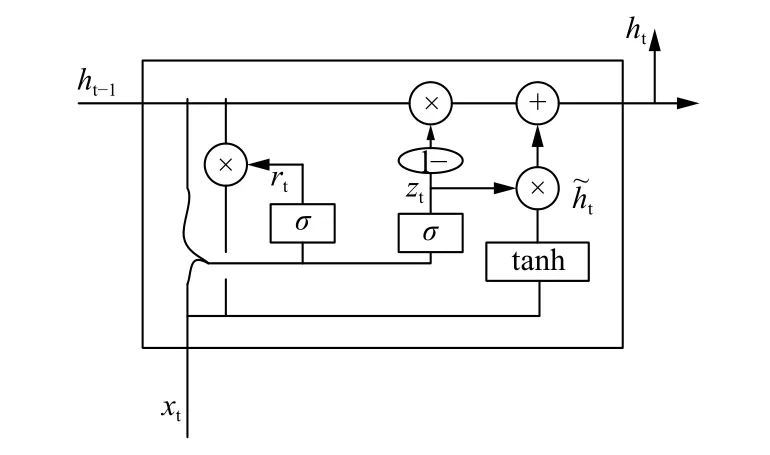
圖1 GRU神經元結構圖
GRU的更新方式如式(1)至式(5)所示:
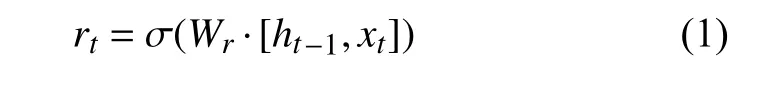

其中,rt和zt分布表示為t時刻的重置門和更新門,、分別表示t時刻的候選激活狀態、激活狀態.ht-1為(t-1)時刻的隱層狀態.
2.2 雙向門控循環神經網絡(BiGRU)
BiGRU能夠同時將當前時刻的輸出同前一個時刻的狀態與后一時刻的狀態產生聯系.BiGRU是由單向、方向相反、當前時刻的輸出由方向相反的兩個GRU輸出共同決定的神經網絡模型.BiGRU的結構模型如圖2所示.
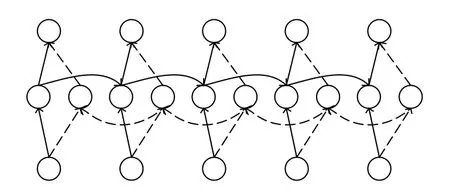
圖2 BiGRU結構模型圖
在t時刻BiGRU的隱層狀態計算公式如式(6)至式(8)所示:

其中,GRU()表示對輸入詞向量的非線性變換,將詞向量編碼為GRU隱層狀態.wt為t時刻前向隱層狀態對應的權重,vt為t時刻反向隱層狀態對應的權重,bt為t時刻隱層狀態對應的偏置.
2.3 注意力機制
注意力機制就是通過對關鍵部分加強關注、突然局部重要信息,簡單來說就是計算不同時刻數據的概率權重,突出重點詞語.多頭注意力機制[16]將序列分為key,values和query.多頭注意力機制通過尺度化的點積方式并行多次計算,每個注意力輸出是簡單拼接、線性轉換到指定的維度空間而生成的.多頭注意力機制結構如圖3所示.

圖3 多頭注意力機制結構圖
多頭注意力機制層可以視為一個序列編碼層,從初始隱層狀態到新隱層狀態z的計算公式如式(9)所示.
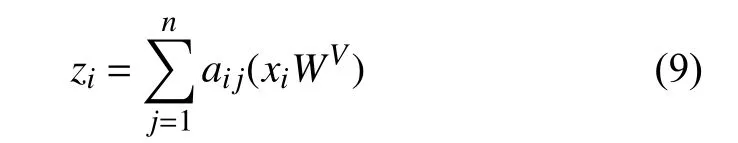
其中,權重系數aij的計算公式如式(10)所示.

其中,eij的計算公式如式(11)所示.
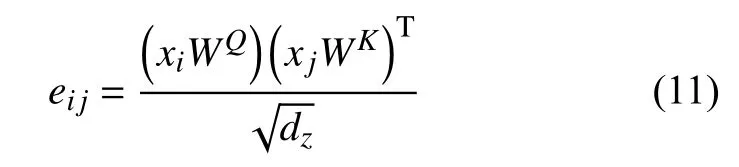
選擇了可擴展的點積來實現兼容性功能,從而實現高效的計算.輸入的線性變換增加了足夠的表達能力.是參數矩陣,.
2.4 基于神經網絡與注意力機制的校對模型
對于文本采用生成的方式進行校對,首先句子是由字、詞和標點組成的有序的序列,若對句中某個字詞進行糾正,則需要通過上下文信息進行推斷和生成.在中文文本校對的研究中,僅使用神經網絡抓取的上下文特征信息作為語義校對是不夠的.上下文信息對當前字詞的校對影響力不同,不能作為同一標準對當前字詞的校對產生作用.因此,本文構建了一個基于注意力機制的序列到序列的中文文本校對模型.模型引入基于注意力的神經網絡,以增強獲取詞與詞間的依賴性的能力.
整體模型架構如圖4所示.2.4.1 文本向量化
模型進行文本校對時,首先要將文本向量化.通過一個特定維度的向量代表詞,詞向量可以刻畫詞與詞在語義上的相關性,并將詞向量作為神經網絡的輸入.

圖4 模型架構
將訓練語料、測試語料集以及開始標志等所有字詞建立一個大小為N的詞字典矩陣,N表示字典的大小.建立一個詞到詞字典的映射關系查找表,將輸入的詞轉換為序號,之后將序號轉換為詞嵌入向量.
2.4.2 序列到序列端
模型的編碼端由BiGRU層構成,文本向量化后的詞向量作為BiGRU層的輸入.BiGRU層主要目的是對輸入的待校對文本進行特征提取.正向GRU通過從左向右的方式讀取{輸入的待校對}句子X,從而得到正向的隱層狀態序列.反向GRU是從右往左的方式讀取輸{入的待校對句}子X,同樣可以得到反向隱層狀態序列.將正向和方向隱層狀態序列進行連接得到編碼端的隱層狀態序列h,其中:

模型的解碼端是采用單向GRU,每一時刻的隱層狀態wi均由前一時刻的隱層狀態wi-1和上一時刻的輸出yi-1.

注意力機 制層通過計 算輸入序列x1,x2,x3,· · ·,xn每個字詞對于i時刻輸出值yi的影響權重加權求和所得.在生成校對結果時,解碼信息融合了輸入序列對輸出序列每個時刻的概率分布.
2.4.3 基于集束搜索的校對算法
采用集束搜索(beam search)求解校對位置的最優結果.基于集束搜索的校對算法如算法1所示.

算法1.基于集束搜索的校對算法#xi為待校對句子#proba用來記錄候選詞yi以及得分score,#beam的值設置為N# max_target_len為目標句子的最大長度for i in rang(max_target_len)#predict 根據xi預測所有可能的字詞及其得分proba=predict(xi)#生成對所有候選集排序for j in len(x):for yi,score in proba:if score>new_score:new_top=yi new_score=score else:t=[yi, score]new_beam.append(t)#取new_beam中最好的beam個候選集c c=get_max(new_beam)
3 實驗結果與分析
校對方法由兩個階段組成:訓練和校對.如圖5所示.

圖5 基本框架
3.1 實驗數據
實驗采用在網站中抓取的公開法律文書文本整理后的句子作為訓練集,樣本數據總量為10.7 MB,隨機抽取404句作為測試集.例如,“透過中間人向另一方表示無欠債關系.”應為“通過中間人向另一方表示無欠債關系.”.
3.2 建模過程及參數
使用基于Keras的深度學習框架進行模型實現.基于雙向門控循環神經網絡和注意力模型的方法已在第2節中介紹.首先,將輸入句子向量化,作為模型的輸入;其次,添加BiGRU和GRU層,并在GRU層后添加注意力機制層;然后,添加雙層Dense層,在Dense層采用ReLU激活函數.同Sigmoid激活函數相比,ReLU激活函數能實現單側抑制[17],能夠有效防止過擬合.因此,在實驗中選取ReLU激活函數;最后,構建Softmax層對文本進行校對,作用是將輸出轉變成概率,通過輸出的概率向量結合詞典反向映射獲得當前時刻的輸出詞.
在解碼時,“GO”表示一個句子的開始標志,“END”表示一個句子的結束標志,“PAD”為補充長度的符號.“GO”和“END”在解碼器端作為開始解碼和結束解碼的標志,并一次生成一個字詞直到遇到結束標志符號.
訓練模型使用Adam優化[18],詞向量維度為128,每層神經元個數設置為128,loss函數采用categorical_crossentropy.
3.3 實驗評價標準
本文采用準確率(P),召回率(R)以及F0.5值作為實驗的評價標準.準確率反應校對結果的準確程度,召回率表示校對結果的全面性,F0.5值為準確率和召回率的綜合評價的指標.

3.4 實驗結果分析
采用未加注意力機制的序列到序列模型做為基線模型(baseline),實驗將本文提出的模型(BiGRU-AGRU)與基線模型以及其他模型進行對比,在同一數據集上進行訓練和測試,得到的中文文本校對的實驗結果如表1所示.
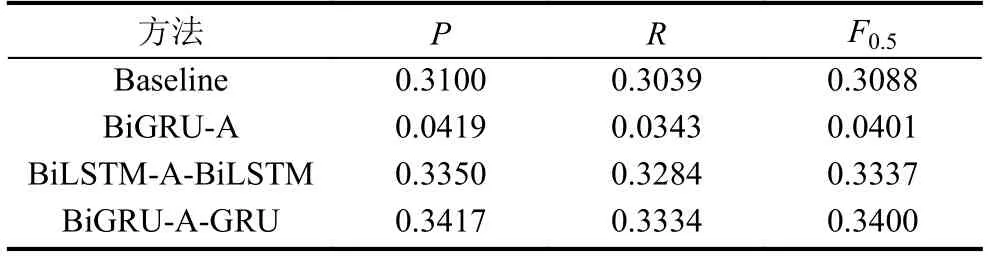
表1 基于不同校對方法的結果
從表1中可以得到,本文提出的模型在語義方面的中文文本校對的完成情況好于基線方法,其準確率、召回率、F0.5值均有一定的提高.這些文本校對效果的提升主要由于BiGRU-A-GRU模型增強了對詞間語義關系的捕捉能力,同時該模型減少了因錯誤偵測產生的影響.
測試集對應最高準確率時的迭代時間為模型的迭代時間,如表2所示.

表2 模型迭代時間對比
BiGRU-A-GRU模型與BiLSTM-A-LSTM模型相比較,均采用了Attention層,區別是一個采用了BiGRU層一個采用了BiLSTM層,表2可以看出在模型迭代時,BiLSTM-A-LSTM模型迭代用時更長.
總之,通過表1,表2及圖6可以得知:在本數據集上,BiGRU-A-GRU模型優于BiLSTM-A-LSTM模型,因為BiGRU相比BiLSTM收斂速度快,參數更少,在一定程度上降低了模型的訓練時間,Attention層在校對過程中能對句子中關鍵部分加強關注,突出相關聯的詞語完成校對任務.
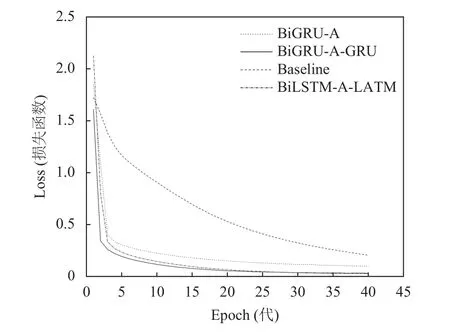
圖6 模型訓練損失率變化曲線
4 結束語
本文提出一種基于神經網絡與注意力機制的中文文本校對方法.將注意力機制引入文本校對任務中,捕捉詞間語義邏輯關系,提升了文本校對的準確性.實驗證明,深度學習模型中引入注意力機制能夠提高中文文本自動校對的準確性.
中文文本詞語含義的多樣性,對語義錯誤的文本校對的發展有一定的阻礙性.在未來工作中,將尋找能夠提高模型學習詞間語義關系的途徑,進而更好地完成文本自動校對任務,并且采用對系統的計算和開銷等影響較小的方法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
