基于支持向量機(jī)的改進(jìn)分類算法①
2019-10-18 06:41:08李亦滔
計(jì)算機(jī)系統(tǒng)應(yīng)用 2019年10期
關(guān)鍵詞:分類
李亦滔
(寧德海關(guān),寧德 352100)
引言
支持向量機(jī)(Support Vector Machine,SVM)是建立在統(tǒng)計(jì)學(xué)習(xí)理論的VC維理論和結(jié)構(gòu)風(fēng)險(xiǎn)最小原理基礎(chǔ)上的,根據(jù)有限的樣本信息在模型的復(fù)雜性(即對(duì)特定訓(xùn)練樣本的學(xué)習(xí)精度)和學(xué)習(xí)能力(即無(wú)錯(cuò)誤地識(shí)別任意樣本的能力)之間尋求最佳折中,以期獲得最好的推廣能力.目前,支持向量機(jī)分類技術(shù)已經(jīng)廣泛應(yīng)用于機(jī)器學(xué)習(xí)、模式識(shí)別、模式分類、計(jì)算機(jī)視覺(jué)、工業(yè)工程應(yīng)用、航空應(yīng)用等各個(gè)領(lǐng)域中,其分類效果可觀,具有很好的發(fā)展前景[1].
SVM最初在線性可分情況下尋求最優(yōu)分類面,為解決二類分類問(wèn)題而提出來(lái)的,不能直接運(yùn)用于多類分類.業(yè)內(nèi)專家提出One-Versus-Rest (1-v-r)[2],One-Versus-One (1-v-1)[3],Directed Acyclic Graph (DAG)[4,5],決策樹(shù)[6-8]等方法能夠?qū)⑺鼣U(kuò)展到多分類問(wèn)題,取得較好的分類精度,但是這些方法尚存在“決策盲區(qū)”、“不平衡類”等缺陷,分類器性能的優(yōu)劣主要由分類精度和分類速度來(lái)確定,其推廣能力受到一定影響.隨著分類問(wèn)題復(fù)雜性的增加,類別數(shù)量、訓(xùn)練樣本、特征維數(shù)均有所增加,分類速度也越來(lái)越受到重視,學(xué)者不斷深入研究改進(jìn)二叉樹(shù)算法,取得了較顯著成果,陳柏志等[9]通過(guò)帕累托原則建立類間差異性估計(jì)策略對(duì)二叉樹(shù)分類算法進(jìn)行了改進(jìn),在一定程度上縮減了分類盲區(qū);趙海洋等[10]則從類型間距方面對(duì)BT-SVM的層次結(jié)構(gòu)進(jìn)行改進(jìn),提高了BT-SVM的分類精度;權(quán)文等[11]為改善分類效果采用了聚類算法對(duì)BT-SVM進(jìn)行了改進(jìn),提高分類精度;冷強(qiáng)奎等[12]提出通過(guò)計(jì)算兩個(gè)距離最遠(yuǎn)的類的質(zhì)心獲得超平面,建立混合二叉樹(shù)結(jié)構(gòu),取得較好效果.因此提高SVM多類分類的快速性和準(zhǔn)確性成為機(jī)器學(xué)習(xí)領(lǐng)域研究的熱點(diǎn)和難點(diǎn)[13].
本文在對(duì)現(xiàn)有主要的SVM多類分類算法作簡(jiǎn)單介紹和分析的基礎(chǔ)上,提出一種改進(jìn)的二叉樹(shù)多類分類算法,達(dá)到又快又好地解決多類分類問(wèn)題的預(yù)期.在二叉樹(shù)結(jié)構(gòu)的基礎(chǔ)上,根據(jù)訓(xùn)練樣本對(duì)最優(yōu)分類超平面的貢獻(xiàn)程度,引入概率計(jì)算方法,為每個(gè)二類分類器賦值不同的權(quán)重系數(shù),從而建立一個(gè)推廣性較高的多類SVM分類模型.通過(guò)采用標(biāo)準(zhǔn)數(shù)據(jù)集對(duì)比分析各種算法的性能,結(jié)果表明基于二叉樹(shù)的改進(jìn)分類算法有效,提高分類精度,擴(kuò)大推廣能力.
1 支持向量機(jī)理論簡(jiǎn)介[14]
Vapnik[15]等人根據(jù)統(tǒng)計(jì)學(xué)習(xí)理論提出的一種新的學(xué)習(xí)方法——支持向量機(jī),堅(jiān)持結(jié)構(gòu)風(fēng)險(xiǎn)最小化原則,盡量提高學(xué)習(xí)機(jī)器的泛化能力,即由有限的訓(xùn)練集樣本得到小的誤差能夠保證對(duì)獨(dú)立的測(cè)試集仍保持小的誤差.在線性可分的情況下,定義分類超平面f(x)

當(dāng)輸入的樣本值x屬于正類時(shí),f(x)≥0;當(dāng)輸入的樣本值x屬于負(fù)類時(shí),f(x)<0.

式中,W是分類面的權(quán)系數(shù)向量;b為分類的域值.W·X是W和X的內(nèi)積.如果要求得到W和b的值,通過(guò)樣本與最佳超平面的最近距離為1/‖W‖,W和b的優(yōu)化條件應(yīng)是使兩類樣本到超平面最小的距離之和2/‖W‖為最大.因此最佳超平面應(yīng)滿足約束:

假設(shè)a的最優(yōu)解為a*,然后W和b的最優(yōu)解分別為w*和b*,這樣可以得到:
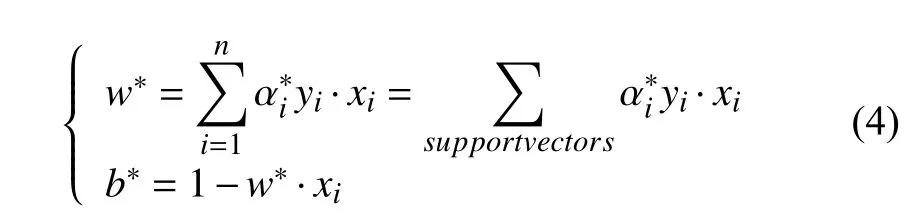
式中,sgn(·)代表符號(hào)函數(shù),w*表示權(quán)值,是最優(yōu)拉格朗日系數(shù),b*為最優(yōu)閾值.通過(guò)求解,可得最優(yōu)分類決策函數(shù)為:

核函數(shù)是一種特定的高維特征空間的線性學(xué)習(xí)算法,實(shí)現(xiàn)非線性映射的目的.典型的核函數(shù)有三種:多項(xiàng)式核函數(shù)、徑向基核函數(shù)、Sigmoid核函數(shù).
SVM在解決小樣本、非線性及高維數(shù)等模式識(shí)別問(wèn)題中表現(xiàn)出許多特有的優(yōu)勢(shì),克服人工神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)結(jié)構(gòu)難以確定和存在局部最優(yōu)等缺點(diǎn),這些優(yōu)勢(shì)能夠被推廣應(yīng)用到分類預(yù)測(cè)等問(wèn)題中,這使它成為機(jī)器學(xué)習(xí)領(lǐng)域的研究熱點(diǎn),并被成功應(yīng)用到很多領(lǐng)域.但是經(jīng)典的SVM算法只能解決二類分類問(wèn)題,如何有效地?cái)U(kuò)展到多分類問(wèn)題仍未很好的解決,特別是標(biāo)準(zhǔn)SVM的判決輸出為硬判決,在多分類中更需要一個(gè)具有軟判決輸出的SVM.利用標(biāo)準(zhǔn)SVM的判決輸出與類后驗(yàn)概率的映射關(guān)系[16],即將SVM的判決輸出f(x)通過(guò)Sigmoid函數(shù)映射到0與1之間,構(gòu)造概率輸出的數(shù)學(xué)表達(dá)式,其簡(jiǎn)化形式如下:

式中,參數(shù)A和B控制Sigmoid函數(shù)的形態(tài),A和B是通過(guò)最小化已知的訓(xùn)練數(shù)據(jù)和它們的決策值f的負(fù)的對(duì)數(shù)似然函數(shù)得到.
2 多類分類器算法[17]
在實(shí)際應(yīng)用中的分類問(wèn)題都是多類的,經(jīng)典SVM無(wú)法直接解決,為將支持向量機(jī)技術(shù)更好應(yīng)用于實(shí)際中,目前國(guó)內(nèi)外學(xué)者提出了許多途徑,歸納為兩類[18]:一是構(gòu)造多類分類數(shù)學(xué)模型,考慮所有情況,這種方法在經(jīng)典SVM分類的基礎(chǔ)上,優(yōu)化SVM的目標(biāo)函數(shù)和參數(shù),通過(guò)決策實(shí)現(xiàn)多類分類.但是這種方法目標(biāo)函數(shù)的表達(dá)式十分復(fù)雜,難于求解,在工程應(yīng)用領(lǐng)域很少被采用;二是按照將多類問(wèn)題歸結(jié)為多個(gè)兩類問(wèn)題的思路,通過(guò)優(yōu)化組合多個(gè)二分類支持向量機(jī)實(shí)現(xiàn)多類分類,即將一個(gè)復(fù)雜問(wèn)題轉(zhuǎn)化若干個(gè)簡(jiǎn)單問(wèn)題,得到較好推廣.基于第二種算法思想,經(jīng)典方法有:One-Versus-Rest (1-v-r),One-Versus-One (1-v-1),Directed Acyclic Graph (DAG),二叉樹(shù)等.
2.1 1-v-r算法
基本思想[19]:構(gòu)造一個(gè)二類分類器,將其中的一類作為一大類,其余各類作為另外一大類,分類時(shí)把那一類同其他類中分開(kāi).對(duì)于N(N≥2)類的分類問(wèn)題,需構(gòu)造N個(gè)二類分類器,采用“比較法”.對(duì)測(cè)試樣本x進(jìn)行識(shí)別.將樣本輸入到已構(gòu)造的N個(gè)二類分類器,得到相應(yīng)的N個(gè)輸出結(jié)果,綜合比較這些結(jié)果,明確輸出最大的那一類,其分類器的序號(hào)就是樣本所屬的類別號(hào),如圖1所示.

圖1 1-v-r構(gòu)造示意圖
決策函數(shù)中輸出最大值的類別為x的類別,判定規(guī)則的公式

1 -v-r算法的優(yōu)點(diǎn)是簡(jiǎn)單、直接.主要缺點(diǎn)是:1)訓(xùn)練樣本需要先通過(guò)構(gòu)造的每個(gè)二類分類器進(jìn)行訓(xùn)練;而已構(gòu)造的所有二類分類器都要對(duì)測(cè)試樣本進(jìn)行分類后,才能確定測(cè)試樣本的類別,所以,一旦訓(xùn)練樣本數(shù)和類別數(shù)較大,那么訓(xùn)練和測(cè)試分類的速度就會(huì)比較慢;2)假如N類中所有的類型沒(méi)有測(cè)試樣本的類型,這樣就找不到正確的類別,按照“比較法”的方法,表明N個(gè)輸出結(jié)果中總有輸出最大的一個(gè),就會(huì)將本來(lái)找不到類別的測(cè)試樣本誤判為N類中的一類,出現(xiàn)分類的錯(cuò)誤.
2.2 1-v-1算法
基本思想:構(gòu)造N(N≥2)個(gè)類別中所有存在的二類分類器,一共建立N(N-1)/2個(gè),如圖2所示.采用“投票法”對(duì)測(cè)試樣本進(jìn)行識(shí)別,將樣本輸入到已構(gòu)造的任何一個(gè)二類分類器,當(dāng)所有的分類器都對(duì)測(cè)試樣本進(jìn)行分類后,最后確定哪一類的票數(shù)最多,那么該測(cè)試樣本就屬于這一類別.

圖2 1-v-1構(gòu)造示意圖
假設(shè)已有第i類和第j類訓(xùn)練樣本構(gòu)造的二類分類器,算法解決如下優(yōu)化問(wèn)題:

構(gòu)造N(N-1)/2個(gè)二類分類器的決策函數(shù),“投票法”判決 max((wij)TΦ(xi)+bij),若屬于i類,則i的票數(shù)增加一,否則j的票數(shù)增加一,哪類統(tǒng)計(jì)得票最多,即為所屬類別.
1 -v-1算法的優(yōu)點(diǎn)是每個(gè)SVM只考慮兩類樣本,易訓(xùn)練,且其訓(xùn)練速度較“1-v-r算法”方法快,其分類精度也較“1-v-r算法”方法高.主要缺點(diǎn)是:1)二類分類器的數(shù)目N(N-1)/2隨著類別數(shù)N的增加而增加,運(yùn)算量也隨之變得很大,導(dǎo)致訓(xùn)練和測(cè)試分類的速度變得非常慢.2)測(cè)試分類的結(jié)果,一旦出現(xiàn)某兩類的得票相同時(shí),無(wú)法找到正確的類別,可能出現(xiàn)分類的錯(cuò)誤.3)假如N類中所有的類型沒(méi)有測(cè)試樣本的類型,這樣就找不到正確的類別,按照“投票法”的方法,N類中總有某一類得票最多,表明N類中總有某一類所得的票數(shù)最多,就會(huì)將本來(lái)找不到類別的測(cè)試樣本誤分為N類中的一類,造成分類的錯(cuò)誤.
2.3 有向無(wú)環(huán)圖(DAG)算法
基本思想[20]:構(gòu)造所有的二類分類器,作為一種雙向的有向無(wú)環(huán)圖的節(jié)點(diǎn),底層的“葉”是由N個(gè)類別組成的,最底層含有N個(gè)葉節(jié)點(diǎn),如圖3所示.按照“自上而下”的原則,分類時(shí)從頂部分類器開(kāi)始,依據(jù)頂部的分類器分類結(jié)果,判定采用下一層的左節(jié)點(diǎn)還是右節(jié)點(diǎn)進(jìn)行分類,直到底層的某個(gè)“葉”為止,對(duì)樣本所屬的類別進(jìn)行編號(hào),對(duì)應(yīng)該“葉”的序號(hào).采用“排除法”對(duì)測(cè)試樣本進(jìn)行識(shí)別,將樣本輸入到已構(gòu)造的子二類分類器中,每通過(guò)一個(gè),都能排除掉最不可能的類別,最終得到底層的某個(gè)“葉”所對(duì)應(yīng)的類別.

圖3 DAG構(gòu)造示意圖
DAG算法的優(yōu)點(diǎn)是在訓(xùn)練階段,雖然與1-v-1算法相同,但在分類階段時(shí),僅用N-1個(gè)分類器,分類效率明顯高于1-v-1算法和1-v-r算法,重復(fù)訓(xùn)練樣本少,分類精度較高.采用“排除法”進(jìn)行分類,降低誤分的可能性.主要缺點(diǎn)是:DAG結(jié)構(gòu)相對(duì)于二叉樹(shù),它具有冗余性,同一類別的分類個(gè)體,分類路徑可能不同,影響分類精度.
2.4 二叉樹(shù)分類算法
基本思想[21]:將N(N≥2)類中N/2(或(N+1)/2)類作為一大類,剩余的類看作另一大類,建立第一個(gè)二類分類器.然后再分別對(duì)那兩個(gè)多類單獨(dú)分類,各取出最相近的N/2-1類作為一大類,將那N/2類中余下的一類看作另一大類,再建立一個(gè)二類分類器.往下同理建立二類分類器,依次往下采取“直接法”直至完全分類,如圖4所示.

圖4 完全二叉樹(shù)構(gòu)造示意圖
二叉樹(shù)分類算法的優(yōu)點(diǎn)是簡(jiǎn)單、直觀,重復(fù)訓(xùn)練樣本少.對(duì)于N類,測(cè)試時(shí)僅需建立log2N二類分類器,都比前面的三種算法數(shù)量少,克服上面算法存在的無(wú)法識(shí)別的陰影區(qū)域,而且重復(fù)訓(xùn)練的樣本量少,訓(xùn)練和分類的時(shí)間可以減少.主要缺點(diǎn)是初始分類錯(cuò)誤具有遺傳性,各子節(jié)點(diǎn)的劃分方法對(duì)結(jié)果有較大影響,在某個(gè)節(jié)點(diǎn)出現(xiàn)誤分類后,將無(wú)法糾正到正確的結(jié)果,因此具有較低的容錯(cuò)率.
以上介紹4種常用的多類分類算法.其中,前3種方法在樣本數(shù)目及類別數(shù)目較多時(shí),訓(xùn)練和分類速度都比較慢,而且前兩種方法還存在不可分區(qū)域.二叉樹(shù)多類分類方法在識(shí)別速度上具有一定的優(yōu)勢(shì),不過(guò),二叉樹(shù)分類器存在著“錯(cuò)誤積累”的問(wèn)題,對(duì)于N類分類問(wèn)題,4種算法的對(duì)比見(jiàn)表1.

表1 4種算法的對(duì)比
3 改進(jìn)的二叉樹(shù)多類分類算法
在多分類問(wèn)題中,二叉樹(shù)分類算法表現(xiàn)出許多優(yōu)良的性能,不僅可以有效解決了不可分問(wèn)題,還能減少分類器的數(shù)量,但是也存在較突出問(wèn)題:可能會(huì)導(dǎo)致“錯(cuò)誤累積”現(xiàn)象,即若在上層節(jié)點(diǎn)處分類一旦錯(cuò)誤分類,則這種錯(cuò)誤會(huì)傳遞下去,后續(xù)節(jié)點(diǎn)將失去分類的意義,因此二叉樹(shù)分類算法越上層節(jié)點(diǎn)的分類性能對(duì)整個(gè)分類模型的推廣性影響越大.為了獲得最佳的分類效果,必須根據(jù)實(shí)際情況來(lái)構(gòu)造二叉樹(shù)各內(nèi)節(jié)點(diǎn)的最優(yōu)超平面,在生成二叉樹(shù)的過(guò)程中,應(yīng)該讓最易分割的類最早分割出來(lái),即在二叉樹(shù)的上層節(jié)點(diǎn)處分割.但考慮到不同的訓(xùn)練樣本對(duì)最優(yōu)分類超平面的貢獻(xiàn)程度不同,為綜合考慮樣本信息,參考郭亞琴等人[22]提出的樣本分布度量方法,利用類間散布度量與類內(nèi)散布度量的比值作為樣本分布情況的度量,構(gòu)造樣本間的映射關(guān)系.在二叉樹(shù)分類的基礎(chǔ)上,構(gòu)建SVM輸出模型,為二類分類器賦值不同的權(quán)重系數(shù),求得各分類器的可信度.具體算法流程圖如圖5所示.
(1)將訓(xùn)練樣本集輸入到支持向量機(jī)中學(xué)習(xí),求得最優(yōu)的參數(shù)w*、ai*、b*、A、B等,從而得到式(6),式(7)中的SVM輸出模型Si.
(2)假設(shè) Θ 為識(shí)別框架,且 Θ ={q1,q2,···,qK},通過(guò)二叉樹(shù)分類,構(gòu)造n=K-1個(gè)二類分類器,表示為 {c1,c2,···,cn}.
(3)將訓(xùn)練樣本集輸入到SVM輸出模型進(jìn)行訓(xùn)練,求出分類器 {c1,c2,···,cn}所對(duì)應(yīng)的權(quán)值p1,p2,···,pn(i=1,···,n),作為各分類器分類判定的可信度,可信度區(qū)間在0~1之間,“1”代表完全可信,即屬于該類;“0”代表完全不可信,即不屬于該類,可信度越接近1,說(shuō)明分類判定的準(zhǔn)確性越高.
(4)計(jì)算測(cè)試樣本分布情況的度量,采用類間分布度量與類內(nèi)分布度量的比值作為分類依據(jù),將比值相近的作為一大類,剩余的類看作另一大類,再根據(jù)分類器的可信度,將屬于第i類的樣本盡快從樣本集中識(shí)別出,屬于第i類別的樣本標(biāo)記為正,而其它樣本標(biāo)記為負(fù).往下依次,直至完成分類.
該改進(jìn)分類算法為解決二叉樹(shù)的“錯(cuò)誤累積”問(wèn)題,根據(jù)樣本對(duì)最優(yōu)分類超平面的貢獻(xiàn)程度不同,通過(guò)計(jì)算樣本分布情況的度量,利用有限樣本數(shù)據(jù)的分布來(lái)對(duì)真實(shí)分布做近似估計(jì),同時(shí)根據(jù)SVM輸出模型計(jì)算分類器分類可信度,避免在上層節(jié)點(diǎn)處分類出現(xiàn)錯(cuò)誤分類,繼續(xù)傳遞錯(cuò)誤;同時(shí)搭建較優(yōu)的二叉樹(shù)結(jié)構(gòu),如圖6所示,能讓最易分割的類最早分割出來(lái),即在二叉樹(shù)的上層節(jié)點(diǎn)處分割,提高分類效果.

圖5 改進(jìn)分類算法流程圖

圖6 改進(jìn)二叉樹(shù)結(jié)構(gòu)示意圖
4 實(shí)驗(yàn)驗(yàn)證
實(shí)驗(yàn)仿真采用UCI機(jī)器學(xué)習(xí)公用數(shù)據(jù)庫(kù)[23]中Iris和Wine Quality Red數(shù)據(jù)集的實(shí)驗(yàn)數(shù)據(jù).為了驗(yàn)證支持向量機(jī)的分類決策性能,首先利用Iris數(shù)據(jù)集:3種不同類型的花(Setosa、Versicolour和Virginica),以及Iris花的4種特征屬性:花瓣長(zhǎng)度、花瓣寬度、萼片長(zhǎng)度、萼片寬度,共150組數(shù)據(jù),每種花50組數(shù)據(jù),每組數(shù)據(jù)包含4種屬性,在Matlab上進(jìn)行了仿真試驗(yàn).任取部分?jǐn)?shù)據(jù)作為實(shí)驗(yàn)樣本進(jìn)行測(cè)試和分類,得到Fisher Iris數(shù)據(jù)集樣本分布圖和分類結(jié)果,可知支持向量機(jī)具有較好的分類性能,如圖7所示.

圖7 樣本分布圖
為了測(cè)試支持向量機(jī)多類分類器的準(zhǔn)確性和快速性,再利用Wine Quality Red數(shù)據(jù)集:11種不同質(zhì)量等級(jí)的葡萄酒,共1599組樣本,每組樣本含有11種葡萄酒的有效化學(xué)度量值(固定酸度、揮發(fā)酸度、檸檬酸、殘?zhí)恰⒙然铩⒂坞x二氧化硫、總二氧化硫、密度、pH值、硫酸鹽、酒精),選取與質(zhì)量等級(jí)相關(guān)性較大的5種量值(檸檬酸、pH值、酒精度、揮發(fā)酸以及硫酸鹽)作為特征屬性,支持向量機(jī)的結(jié)構(gòu)是5個(gè)輸入變量,11個(gè)輸出變量.任取150組樣本,作為實(shí)驗(yàn)樣本,1/2作為訓(xùn)練樣本,其余1/2作為測(cè)試樣本,通過(guò)多類分類算法(1-vs-r、1-vs-1、DAG、二叉樹(shù)及改進(jìn)的二叉樹(shù))對(duì)樣本進(jìn)行仿真試驗(yàn).分類測(cè)試對(duì)比結(jié)果見(jiàn)表3.
從表2,表3實(shí)驗(yàn)結(jié)果來(lái)看:表2是針對(duì)類別數(shù)為3的多類分類實(shí)驗(yàn)結(jié)果,表3是針對(duì)類別數(shù)為11的多類分類實(shí)驗(yàn)結(jié)果,兩組實(shí)驗(yàn)結(jié)果得到類似結(jié)果,說(shuō)明改進(jìn)二叉樹(shù)算法分類方法具有明顯的優(yōu)勢(shì).
從時(shí)間角度,時(shí)間與決策分類器的數(shù)量、求解分類參數(shù)的計(jì)算量相關(guān),五種多類分類算法中,改進(jìn)的二叉樹(shù)算法的訓(xùn)練時(shí)間稍長(zhǎng)于二叉樹(shù)算法,由于引入權(quán)值計(jì)算,優(yōu)化問(wèn)題求解計(jì)算量變大,但是分類器數(shù)量最少,得到分類最優(yōu)參數(shù)后測(cè)試時(shí)間最短;而明顯短于其它3種算法,由于搭建分類器的數(shù)量少于其它3種算法.

表2 3種類別分類結(jié)果

表3 11種類別分類結(jié)果
從分類精度角度,分類精度與求解決策最優(yōu)超平面的準(zhǔn)確性、是否對(duì)樣本進(jìn)行預(yù)處理有關(guān),求解最優(yōu)分類平面和有針對(duì)性地分類可以減少“誤分”、“錯(cuò)分”、“不可分”等,提高了分類精度,改進(jìn)的二叉樹(shù)算法的分類精度最高,對(duì)樣本進(jìn)行預(yù)處理,為分類器賦值不同的權(quán)重,更具針對(duì)性,做到“能分先分,應(yīng)分盡分,難分賦值分”,分類精度明顯高于其它四種算法.
綜上,改進(jìn)二叉樹(shù)算法具有較明顯的時(shí)間優(yōu)勢(shì),較高的分類精度.驗(yàn)證了改進(jìn)二叉樹(shù)算法分類器的準(zhǔn)確性和快速性,且整體性能稍優(yōu)于其他4種算法.如果分類類別多時(shí),從表1中可知分類器的數(shù)量遞增,除二叉樹(shù)外其他3種算法的分類時(shí)間會(huì)明顯增加,從表2、表3中可知改進(jìn)二叉樹(shù)的分類精度明顯高于其他4種算法,并且類別越多優(yōu)勢(shì)更凸顯.因此改進(jìn)二叉樹(shù)算法分類方法適用于類別數(shù)較多,分類實(shí)時(shí)性要求較高的場(chǎng)合.
5 結(jié)論
本文從支持向量機(jī)的基本理論出發(fā),通過(guò)對(duì)比分析了4種常見(jiàn)多分類器分類算法的構(gòu)造原理和特點(diǎn),為改進(jìn)支持向量機(jī)的多類分類問(wèn)題提供依據(jù),引入二類分類器的權(quán)值,提出基于二叉樹(shù)的改進(jìn)分類算法,實(shí)驗(yàn)結(jié)果表明該算法可提高多類SVM分類器的效率,并有助于分類準(zhǔn)確率的提升,使多類支持向量機(jī)能夠更好地解決工程實(shí)際問(wèn)題.筆者認(rèn)為改進(jìn)二叉樹(shù)算法的分類器適用于類別數(shù)較多,分類實(shí)時(shí)性要求較高的場(chǎng)合,將發(fā)揮其優(yōu)勢(shì).再采用最大化樣本類間幾何距離的方法劃分各類別,可能會(huì)取得更好的效果,還有待于進(jìn)一步的研究驗(yàn)證.
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
