中國水土流失研究熱點區的空間分布制圖
2019-10-14 07:40:20胡云鋒韓月琪張云芝
生態學報 2019年16期
胡云鋒, 韓月琪, 曹 巍, 張云芝
1 中國科學院地理科學與資源研究所,資源與環境信息系統國家重點實驗室,北京 100101 2 中國科學院大學,資源與環境學院,北京 100049
中國是全世界水土流失最為嚴重的國家之一。嚴重的水土流失是引發區域生態系統退化、水域環境質量惡化、經濟社會嚴重受損的重要過程[1]。據第一次全國水利普查水土保持情況公報顯示,我國土壤侵蝕總面積294.91萬km2,占普查范圍總面積的31.12%;其中,水力侵蝕129.32萬 km2,風力侵蝕165.59萬km2[2]。研究人員針對水土流失的空間分布格局、水土流失強度、水土流失的防范治理和生態恢復等問題展開了廣泛和深入的研究,積累了豐富的研究成果,具體包括專題報告、圖冊、研究論文、專利技術、應用系統等在內的多種知識展現形式。其中,公開出版的期刊研究論文是理解和掌握水土流失研究方向、研究地點、研究內容、研究方法和主要結論的最重要的信息載體。進入信息化時代,這些研究論文被進一步數字化,形成了結構化或者半結構化的文獻數據庫或者知識庫(如中國知網、萬方數據庫、WoS(Web of Science)等),并可以方便地為讀者通過國際互聯網進行檢索和下載。
隨著上述數據庫和網絡搜索技術的廣泛普及和深入使用,傳統的、依賴于人工閱讀紙質文獻的信息檢索和知識提取方法逐漸演變為基于網絡爬蟲、數據挖掘、機器學習、數據建模等技術,對文本信息進行檢索、專題信息抽取及時空分析的階段[3]。已經有許多研究人員針對互聯網文本開展地理信息的抽取和分析工作。如Sadilek等人通過有明確位置標記的推特(Twitter)數據對個體疾病情況進行分析,探測了疾病傳播過程[4];Dredze等對推特文本中隱性的地理信息進行抽取,開發了可對流感發病情況進行追蹤的Carmen系統[5]。Cameron等人開發了ESA-AWTM系統,用于監測社交網絡中隱含的社會公共危機事件信息[6]。在國內,也有一些研究從微博消息或者互聯網文本中檢測地名信息,進而開展一些簡單的面向事件的空間制圖研究[7-9]。此外,還有一些基于已發表論文成果、應用統計方法開展再分析、再確認“元分析”研究[10-11]。總的來看,目前的研究大多是應用社交媒體數據或者一般性的互聯網文本數據,針對特定事件或突發事件開展空間制圖和過程重繪的研究。基于海量的科技期刊論文,從論文中提取地理空間信息和論文研究主題信息,進而對特定自然、生態過程的空間分布規律、時間演化特征以及知識圖譜凝練研究[12-13],這一類的研究在國內外都還比較少見。在這一研究方向,重點需要解決地名信息的自動化提取和空間匹配、基于位置的自然地理和生態環境問題建模與分析、以及針對上述時空分析結果的知識凝練和應用實踐。
本文以水土流失為研究對象,基于中國知網學術期刊數據庫,通過網絡爬取、中文分詞、地名識別、空間關聯等技術方法,對1980—2017年間的中國水土流失研究論文中的摘要文本進行了行政區地名提取和研究熱點建模分析。進一步,基于同期歷史氣象觀測數據和自然地理背景數據,應用經典的RUSLE模型對中國水土流失進行模擬和分析。作者最后針對水土研究熱點地區制圖成果與水土流失強度模擬制圖成果的空間耦合關系開展了討論。希望解決如下科學和技術問題:
(1)建立一套從中文科技期刊論文提取行政區地名信息的方法,構建一個科學合理的研究熱度模型以及空間制圖流程;
(2)分析1980年代以來中國水土流失研究熱點地區的空間分布格局,闡明研究熱點地區隨時代演變的動態過程;
(3)對比分析水土流失研究熱點地區空間分布與土壤侵蝕強度空間分布地圖,對典型的空間耦合模式或空間差異進行機制解釋。
1 數據來源及預處理
研究中用于提取研究地區、分析研究熱度的文本數據來自于中國知網學術期刊數據庫(China Academic Journal Network Publishing Database,CAJD)。作者首先應用Java語言開發了CAJD爬蟲系統;而后以“水土流失”、“水力侵蝕”以及“水蝕”作為關鍵詞,對CAJD文獻庫進行了全面檢索,共獲得1980—2017年間相關文獻170301篇;最后,提取了文獻標題、摘要、關鍵詞、作者姓名等關鍵信息,并存儲于本地的SQLite數據庫中。
為了將文獻數據中的行政區地名正確匹配和關聯到空間數據庫中,首先依據中國地圖出版社提供的中國縣級行政區劃數據(2012年版)建立標準地名。而后,考慮到行政區劃名稱的歷史演變,依據國家基礎地理信息中心提供的1∶25萬基礎地理數據、科技部地球系統科學數據共享平臺提供的中國歷史時期縣級行政區劃數據,對部分地名進行了別名補充。
為應用RUSLE模型開展土壤侵蝕強度模擬,研究中還使用了如下長時序氣象數據和相關的自然環境背景數據。具體包括:(1)基于日降雨量擬合模型[14]及ANUSPLIN插值方法[15]計算得到的降雨侵蝕力空間數據集。其中,日降雨量等數據來自于中國氣象科學數據共享服務網(http://cdc.cma.gov.cn);(2)基于Nomo圖法[16]計算得到土壤可蝕性因子數據。其中,土壤數據為中國科學院南京土壤研究所提供的1∶100 萬中國土壤數據庫;(3)全國1 km分辨率數字高程模型(DEM)。由此計算得到坡長、坡度因子;(4)基于MODIS NDVI產品,應用像元二分模型計算得到全國植被蓋度產品[17]。由植被蓋度數據,可以進一步確定RUSLE模擬所需的土地管理因子[18];
為了分析導致研究水土流失研究熱點空間分布格局與土壤侵蝕強度空間分布格局之間空間差異的機制,還使用了基于第五次人口普查數據的2010年中國公里網格人口分布數據[19],以及基于1∶25萬基礎地理數據庫得到的中國縣道及縣道以上等級道路的路網密度數據。
2 研究方法
2.1 水土流失研究熱點建模
對于從CAJD中檢索和下載得到的170301篇文獻,首先調用自然語言處理開源平臺(HanLP)中的分詞模塊對文章題目、摘要及關鍵詞等文本內容進行分詞處理[20];接著應用實體詞識別模塊對全部分詞結果進行分析、遴選得到其中的地名詞匯[21];然后對上述地名詞匯中的行政區地名進行標準化,并對全部行政區地名出現的頻次進行統計分析。研究中,將標準行政區地名數據庫中的地名劃分為省域、市域、縣域三級,并構建了一個基于“逐級覆蓋、累加統計”原則的地名匹配算法,從而將不同級別的行政區地名、或者同一地名的不同表達形式(全稱、簡稱、別稱)進行準確識別、合理統計。
在定量評估研究熱點時,簡單地采用研究論文中的特定地名出現的絕對數量(Nwe)來表征水土流失研究的熱烈程度,這并不合理。中國作為一個幅員遼闊的大國,各省區市之間的經濟社會和科技發展水平并不相同,不同地區針對同一事物、過程的關注數量會存在較大的、甚至是數量級上的差異。類似的道理,采用某一地名在特定研究方向論文中出現頻次占其在全部研究方向論文中出現頻次的比例指標(Pwe)來表征研究熱度,則會由于相同或者相似經濟社會和科技發展水平的地區針對同一事物、過程具有大致相似的測度水平,因而同樣無法有效刻畫地區差異。為避免上述問題,本文作者將絕對數值指標與相對比率指標相結合,構建了如下的地區研究熱度模型:
(1)
式中,Q是水土流失研究熱度指數。Nwe為某一地名在水土流失主題論文中出現的頻次;Pwe為某一地名在水土流失主題論文中出現的頻次占該地區在全部主題論文中出現頻次的比值;Nall為某一地區不限定主題所得全部論文的數量。
本文研究中,為了方便在全國范圍內開展對比分析,作者還對公式(1)中的Q值進行了歸一化,并將歸一化計算所得結果用于后續的制圖和結果分析。其中,研究熱度分級方法采用自然分級法。
2.2 基于RUSLE模型的模擬
RUSLE 模型 (Revised Universal Soil Loss Equation),是對通用土壤流失模型USLE(Universal Soil Loss Equation)的改進和優化[22]。與USLE模型相比,RUSLE擴展了模型模擬所需的輸入數據的豐富程度,糾正了USLE模型中存在的少量錯誤,增加了模型的靈活性。自20世紀80年代以來,研究人員使用RUSLE 模型對不同氣候帶、不同地形地貌、不同耕作管理措施、以及不同空間尺度下的區域水土流失進行了廣泛、深入地模擬評估[23-25]。研究結果表明,RUSLE是一種適用于流域和區域尺度的、通用性很強的水土流失定量評價方法。RUSLE 模型基本方程是:
A=R×K×L×S×C×P
(2)
式中,A為土壤侵蝕模數,R為降雨侵蝕力因子、K為土壤可蝕性因子、L為坡長因子、S為坡度因子、C為覆蓋和管理因子,P為水土保持措施因子。
3 結果與分析
3.1 研究熱點區域
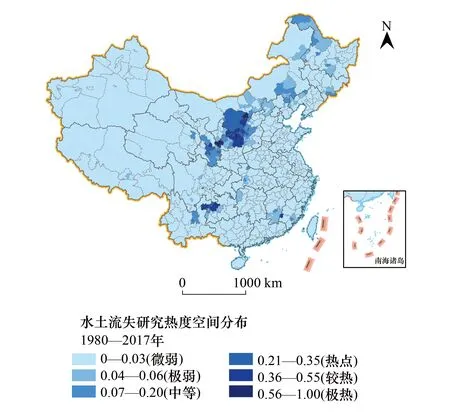
圖1 1980—2017年全國水土流失研究熱度空間分布圖 Fig.1 The spatial distribution of water erosion research hotness during 1980—2017
1980—2017年期間,中國水土流失研究熱點的空間分布如圖1所示。水土流失研究熱點區域主要分布在黃土高原及貴州高原,涉及陜西、寧夏、內蒙古、甘肅、貴州等省區。此外,在黑龍江大興安嶺北部、內蒙古東部的西遼河流域也有輕微的研究熱度。
統計表明:中等及以上熱度的縣(區、市)共171個,面積達到50.55萬km2,占全國國土總面積的5.33%。其中,研究熱度達到“較熱”及以上的區域主要分布在黃土高原和西南喀斯特地區,如:寧夏固原,陜西延安、榆林,內蒙古鄂爾多斯市,貴州畢節等地。研究熱度為“中等”的區域主要分布在大興安嶺地區、黃土高原周邊地區、西南喀斯特地區,具體為:內蒙古的呼倫貝爾、赤峰,甘肅的蘭州、天水、隴南、慶陽,青海的西寧,云南的昆明等地區。
針對1980—2017年各個年代水土流失研究熱度空間分布格局的時間變化過程(圖2)研究表明:1980—1989年間,中國水土流失研究的熱點集中分布在黃土高原區;1990—1999年間,黃土高原研究熱度持續上升;與此同時,貴州西部、內蒙古東部也逐步成為研究熱點;2000—2009年間,學者們關注的水土流失區域進一步擴大,內蒙古中部鄂爾多斯、烏蘭察布,黑龍江大興安嶺北部的部分縣(區、市),也逐步成為水土流失研究熱點區域;進入2010年后,水土流失研究熱點區域有所收縮,學者們的研究熱點區重新回到黃土高原及云貴高原。
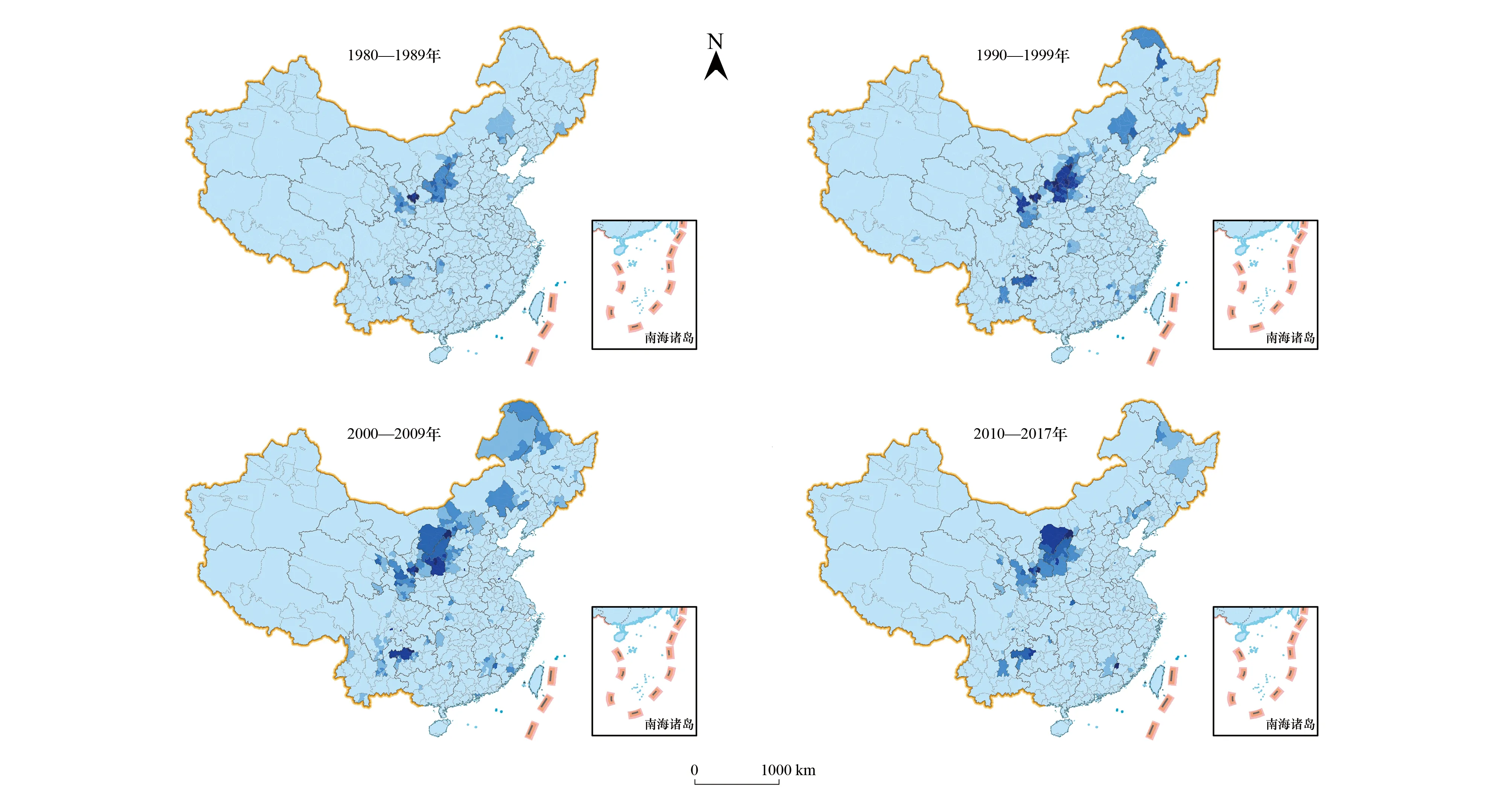
圖2 不同時代的全國水土流失研究熱度空間分布圖Fig.2 The spatial distribution of water erosion research hotness in 4 Eras
3.2 土壤侵蝕強度
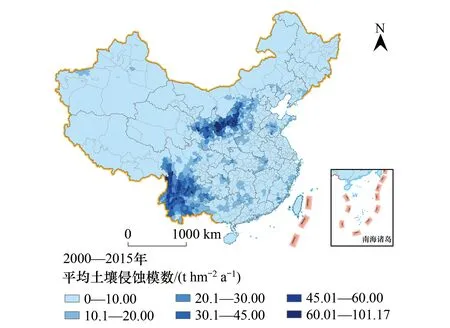
圖3 基于RUSLE模擬的土壤侵蝕模數空間分布圖 Fig.3 The Spatial Distribution of Water Erosion Modulus Simulated by RUSLE ModelRUSLE(Revised Universal Soil Loss Equation):通用土壤流失模型
基于2000—2015年多年氣象數據、植被數據以及地形、土壤數據等,應用RUSLE模型,可以模擬得到我國土壤侵蝕強度的空間分布(圖3)。模擬結果表明:嚴重的土壤侵蝕主要分布在黃土高原及云貴高原,涉及陜西、寧夏、甘肅、山西、貴州、云南、四川等省區;此外,遼寧、山東、重慶、湖南、江西等省區也有中、輕度的土壤侵蝕。
統計顯示:全國土壤侵蝕模數大于20 t hm-2a-1的縣(區、市)共251個,面積達66.78萬km2,占全國國土總面積的7.04%。其中,土壤侵蝕量在30 t hm-2a-1以上的區域主要位于在黃土高原核心區的陜西榆林東南部、延安北部,甘肅慶陽北部,以及位于云貴高原西部的云南迪慶藏族自治州、怒江傈僳族自治州、大理白族自治州、保山的部分縣(區、市)。在上述縣(區、市)的外圍地區,以及寧夏固原、中衛,甘肅平涼、定西,云南省臨滄、普洱、紅河哈尼族彝族自治州、楚雄彝族自治州,四川涼山彝族自治州、攀枝花以及西藏昌都地區南部,土壤侵蝕量也都超過了20 t hm-2a-1。
4 討論
4.1 空間耦合的模式及應用
對比水土流失研究熱點圖(圖2)與土壤侵蝕強度空間分布圖(圖3),兩者存在4種空間耦合模式,即:高研究熱度-高侵蝕強度(如黃土高原)、高研究熱度-低侵蝕強度(如云貴高原)、低研究熱度-高侵蝕強度(如滇西橫斷山區)、低研究熱度-低侵蝕強度(如中國東部廣大地區、青藏高原等)。對于上述典型空間耦合的形成機制,可以結合區域自然地理和經濟社會發展背景等予以解釋。
黃土高原是長期以來被公認為我國水土流失最為嚴重的區域。對該地區開展長期的水土流失觀測實驗、研究其治理和恢復措施,探討區域經濟-社會的可持續發展,這是政府主管部門和研究人員長期關注的重點問題[26-27]。黃土高原地區呈現的“高研究熱度-高侵蝕強度”組合,體現了科研界對我國水土流失重點地區判斷準確、研究重點突出的實際情況。但是,在云貴高原區與滇西橫斷山區,存在研究熱度與侵蝕強度等級“脫鉤”的情況。就云貴高原而言:一方面,云貴高原作為喀斯特巖溶地貌的典型區,由于水土流失導致的石漠化研究一直得到學界的重視[28-29];但另一方面,這一地區作為我國南方熱帶、亞熱帶氣候區,自2000年以來,在國家相關生態治理工程(如天然林保護工程、退耕還林還草)治理下,該地區陸地植被容易恢復、植被蓋度提升較快,土壤侵蝕狀況已經大為好轉[30]。因此,云貴高原地區所形成了“高研究熱度-低侵蝕強度”的格局也可以得到合理解釋的。在滇西橫斷山區,則呈現為 “低研究熱度-高侵蝕強度”的空間耦合模式。究其原因,是因為滇西橫斷山區地處偏遠,人口稀少,山脈與河谷依次貫列,人員也難以進入。因此,RUSLE模擬表明該區雖然存在較為嚴重水土流失,但由于水土流失對本地區經濟社會的危害性較小,因此這一地區的水土流失過程并沒有得到科研界的重視和深入研究。
在應用自然地理和經濟社會發展因子對上述空間耦合模式的形成機制予以解釋的同時,還可以針對不同的這種空間耦合模式評估研究項目投入、研究重點地區選擇的合理性、有效性。科學史研究已經表明,科學研究中總是存在追逐熱點的趨勢。其結果是科學研究會在領域方向上、研究地域上出現“富者愈富”的情況[31]。具體到本研究中,水土流失研究熱度與水力侵蝕強度等級“脫鉤”的地區,極有可能表明出現了一些研究人員盲目追求熱點、忽視重大問題區域的情況。因此政府和科研界需要采取必要的措施,將資金和人員優先投入到更加嚴重、更加關鍵的區域上。要做到這一點,一方面必須運用衛星遙感和模型模擬的方法,對水土流失強度及其空間分布有著更加準確、快速的量算;另一方面,也需要深化既有的互聯網文獻大數據繪制知識圖譜的研究方法,開展更全面、更精準、更快速的地名識別(包括行政區地名和非行政區地名)、專題信息建模等關鍵研究。
4.2 數據和模型的不確定性
在本文研究中,作者從特定主題的科技期刊論文中提取了行政區地名信息,進而用地名構造了研究熱度指標模型;繼而以研究熱度指標為基礎,進一步分析了水土流失研究熱點的空間分布格局和動態演變規律。總的來看,基于文獻大數據的科研熱點地區制圖方法能夠很好地展示科研工作者長期以來在水土保持研究領域研究的重點地帶和重點區域;文獻大數據科研熱點地區空間分布格局的動態演變過程,也體現了在不同歷史發展時期,水土流失研究在研究范圍、研究強度上的變化規律。
但需要指出的是:目前的技術路線和技術實現過程中,依然存在一些值得改進的地方。首先,目前提取的地名信息均為行政區地名(省、市、縣、區等)。對于論文中廣泛存在的自然地理區域地名(如秦嶺、太行山、淮河、塔里木河,等)、方位詞(南部、以西、上游、北麓,等)等,作者目前尚不能準確地在空間上予以標注和定位。毫無疑問,這種地名信息的漏提和不精確標注,將會影響研究熱點區域制圖的精確性。其次,在研究熱度建模中,本文作者雖然構建了一個綜合了絕對數值指標和相對比例指標優點的熱度指數模型。但毫無疑問,目前的熱度模型仍然是粗糙、不精確和缺乏嚴格數理統計學基礎的。從文獻大數據提取專題信息,并根據地學專業研究的性質和特點,構建科學合理、嚴謹可靠的測度模型、分析模型,依然是未來基于文獻大數據開展知識圖譜研究的一個關鍵環節。
5 結論
本文主要基于CAJD提供的文獻大數據,運用自然語言處理技術,對海量中文科技期刊論文所刻畫的1980年代以來中國水土流失研究熱點進行了信息提取和建模分析,并將相關結果與基于RUSLE模型的得到全國土壤侵蝕強度空間分布成果進行了對比和討論。主要結論有:(1)應用網絡爬蟲、文本解析、地名識別、空間關聯、熱度建模等方法,可以快速、有效地從海量期刊文獻數據中提取和標識全國水土流失研究的熱點區域,完成中國水土流失研究熱點區制圖。(2)1980年以來,我國的水土流失研究熱點地區主要分布在黃土高原、西南喀斯特地區,主要涉及寧夏南部、陜西北部、甘肅南部、內蒙古中部、貴州西部與云南東部等地,尤以寧夏固原、陜西延安、榆林的部分縣(區、市)、內蒙古鄂爾多斯、貴州畢節等地最為突出。(3)研究熱點地圖與水土流失強度模型模擬地圖之間存在差異。對于這些特定的空間耦合模式,不僅可以從自然地理和經濟社會發展背景等方面予以解釋,還可以用于評估科技資源投入的合理性和有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
