基于MODIS與WOFOST模型同化的區域冬小麥成熟期預測
2019-10-10 02:45:24黃健熙高欣然馬鴻元朱德海
農業機械學報 2019年9期
關鍵詞:模型
黃健熙 高欣然 黃 海 馬鴻元 蘇 偉 朱德海
(1.中國農業大學土地科學與技術學院, 北京 100083; 2.農業農村部農業災害遙感重點實驗室, 北京 100083)
0 引言
作物收獲期對作物產量與品質影響顯著,收獲過早或過晚都不利于作物的豐產增收[1]。對于冬小麥而言,其主產區多采用冬小麥-夏玉米輪作的種植制度,收獲過晚將直接影響夏玉米的及時耕種。此外,隨著農村土地制度改革的不斷推進,傳統的以家庭為單位的小農經濟正向大規模的機械化農業轉型[2],優化收割次序、提前調度農機,以實現作物的準時收獲是機械化農業發展帶來的新問題,因此,在實際生產中迫切需要對作物成熟期進行大區域精準預報。
在農學意義上來說,成熟期是指作物的營養存貯器官成長到可收獲的階段。影響成熟期變化的因素較為多樣,形成了不同的研究方法。文獻[3-4]著重分析氣象因素(如溫度、光周期、降水等)與作物成熟期的相關性,通過在單點尺度上建立氣象因子與成熟期的統計模型估測實驗年份的成熟期。段金省[5]利用多年的氣象數據和某年份作物的成熟期數據建立查找表,認為氣候條件越相近的年份生長的作物成熟期也越接近,并以此為理論基礎估測成熟期。基于氣象因子的估測方法易于操作,在使用氣象預報數據或區域氣候模型[6]的情況下能夠較快進行成熟期的預報,但是該類統計方法難以在實驗區域外推廣,且無法應對年際間種植品種和田間管理措施等因素的變化。
另一類方法是通過分析生育期內作物生化參量的變化特征提取成熟期,這類方法多以遙感數據作為數據源,主要分為兩種技術路線:①分析生育期內植被指數的時間序列曲線,計算指數時序曲線的曲率、波峰等特征,提取成熟期[7-8],主要方法有:閾值法[9]、Logistic曲線擬合法[10]和滑動平均法[11]等。②監測生育期內作物水分[12]、葉綠素[13]、氮素[14]、干物質[15]等指標的變化,使用回歸分析等統計學方法建立成熟期估測模型,進而實時監測作物是否達到成熟所需指標。基于遙感數據監測作生化參量提取成熟期的方法能夠在大區域上提取作物的成熟期,但是無法進行預報。此外,由于云、雨天氣的影響,作物生育期內不可避免地會遇到遙感數據缺失或數據質量較差的問題,將給時間序列曲線和生化指標監測帶來誤差,影響成熟期提取精度,而且這類方法基于回歸分析構建模型,對于品種調整和氣候變化缺乏適應性,難以在實驗區域外推廣應用。
作物成熟期受到氣候條件、作物品種特性和耕種時間的共同影響[16],現有研究方法大多基于歷史數據對成熟期建模,不能很好地反映當年作物品種及耕種時間的變化。如果根據當年作物實際生長發育情況動態調整模型中與作物品種相關的參數,將能極大提高模型的適應性。因此,引入作物生長模型,并將遙感數據作為觀測數據,構建代價函數優化作物模型參數,不僅可以利用遙感數據大范圍、實時性強的優點,而且又能以氣象預報數據驅動機理過程模型,實現區域尺度的成熟期預測。
1 研究區與數據
1.1 研究區概況
選擇河南省冬小麥種植區作為研究區,其覆蓋范圍為31.38°~36.37°N, 110.35°~116.64°E,總面積約5.425×106hm2(中國國家統計局,2015年),地處黃淮海平原,屬暖溫帶季風氣候區,年平均降水量約650 mm,年平均日照時數約2 300 h,四季分明,雨熱同期,光照充足。冬小麥是該地區種植的主要糧食作物之一,通常在10—11月播種,2—3月返青,5—6月成熟。由于氣象條件、播種時間和種植品種的差異,研究區內冬小麥的成熟期在空間上和年際間也存在一定差異,適用于進行冬小麥成熟期的預測與驗證。本文所用冬小麥種植區通過隨機森林方法提取得到[17],空間分辨率為500 m,在研究區內包含35個國家級農業氣象觀測站(圖1)。

圖1 研究區與農業氣象站點分布Fig.1 Map of study area and agrometeorological sites
1.2 研究數據
1.2.1遙感數據
遙感數據來自2017—2018年MODIS LAI產品MCD15A3H (https:∥ladsweb.modaps.eosdis.nasa.gov/),其時間分辨率為4 d,空間分辨率為500 m,通過使用ArcGIS工具對影像進行投影轉換、鑲嵌和裁剪等處理,輸出覆蓋整個研究區的MODIS LAI數據。
1.2.2氣象數據
氣象數據來自2017—2018年歐洲中期天氣預報中心提供的氣象要素數據集以及集合預報格點數據集TIGGE(https:∥apps.ecmwf.int/datasets/data/tigge/levtype=sfc/type=cf/),包括近地面氣溫、近地面氣壓、露點溫度、近地面全風速、太陽輻射、降水量等要素,其時間分辨率為6 h,空間分辨率為0.25°,其中預報數據的時限為16 d。對原始氣象數據進行預處理得到時間分辨率為1 d,空間分辨率為500 m的數據,包括:日最高溫、日最低溫、日照輻射量、水汽壓、平均風速與降水量6個要素,目前在多個領域得到廣泛應用[18-20]。超出預報數據時限的氣象數據參照本課題組之前的研究方法[21],用歷史氣象數據代替。
1.2.3作物與土壤數據
作物和土壤數據分別來自農業氣象站記錄的《作物生育狀況觀測記錄年報表》和《土壤水分觀測記錄年報表》,作物數據具體包括站點的區站號、臺站名稱、作物名稱、品種名稱、品種類型、作物關鍵生育期、臺站經緯度、臺站海拔、株高、密度、田間管理措施等;土壤數據具體包括土壤質量含水率、土壤相對濕度、土壤容重、田間持水量、凋萎濕度等。部分站點還包括關鍵生育期葉面積、植株干質量等數據。
我國工程建設監理制度的推行雖然走過了20多年,但有序競爭的市場環境還沒有形成。2010年,中國水利工程協會組織開展了首批水利建設市場主體信用評價工作,但采取的是工程施工和監理市場主體自愿申請參加的方式,僅有137家水利建設市場主體自愿申報進行信用評級。其中監理市場主體只有67家自愿申報進行信用評級,信用評級是在市場主體申報材料的基礎上,由全國性行業自律組織——中國水利工程協會進行初審、復審和組織評審委員會終審,信用評價缺乏強制性和約束性,信用評價結果缺乏公信力,實際的信用監管效果還不夠理想,優勝劣汰的市場準入和清出機制沒有形成,制約監理活動良性發展的因素依然存在。
2 研究方法
2.1 WOFOST模型的本地化
WOFOST模型是由瓦赫寧根大學和瓦赫寧根研究中心共同開發的一種機理性作物生長模型,能夠模擬生育期內作物對氣象和其他環境因子的反應,實現不同類型作物發育階段的量化、生物量和作物產量的模擬[22],目前已經廣泛應用于指導農業生產和模擬作物長勢等多個方面[23-26]。為了使模型能夠準確地模擬研究區內冬小麥的生長發育過程,首先需要對模型參數進行標定,實現WOFOST模型的本地化,使用鄭州農業氣象試驗站的歷史觀測數據或查閱文獻[27-28]來確定模型的參數取值,部分參數校準值見表1。
2.2 MODIS LAI數據預處理
本文將研究區的MODIS LAI數據按照時間順序疊加,在各像元上生成對應的LAI時間序列曲線,使用Savitzky-Golay(S-G)濾波方法剔除MODIS LAI數據中由云、水汽、氣溶膠等帶來的噪聲。由于500 m分辨率影像受到混合像元因素的影響,且MODIS LAI數據的尺度低于WOFOST模型模擬LAI的尺度,為了減小系統誤差給同化造成的影響,采用歸一化的方法處理LAI數據,即把MODIS LAI和模型模擬LAI均映射到0~1內,在保留MODIS LAI趨勢信息的情況下使兩種LAI數據源尺度相同,公式為

表1 WOFOST模型中主要參數校準值Tab.1 Calibrated values of main parameters in WOFOST
注:表中DVS表示作物的發育階段。
LAIn=(LAIo-LAImin)/(LAImax-LAImin)
(1)
式中LAIo、LAIn——歸一化前、后葉面積指數
LAImax、LAImin——該時間序列上葉面積指數的最大值和最小值
2.3 待優化參數的選擇
由文獻[29-31]可得,對作物成熟期影響較大的作物參數有IDEM(出苗日期)、TBASEM(出苗下限溫度)、TSUMEM(從播種到出苗期有效積溫)、TSUM1(出苗期至開花期有效積溫)、TSUM2(開花期至成熟期有效積溫)等。由于TBASEM和TSUMEM均反映作物從播種期到出苗期的特性,而本文選擇LAI作為耦合變量,且遙感LAI數據只能反映作物出苗之后的生長狀況,因此無法有效地優化播種期相關參數。分析歷史數據發現,在研究區TSUM1、TSUM2、IDEM 3個參數沒有表現出明顯的空間規律,且年際間變化較大,因此將三者設為待優化參數,根據文獻[28-29]及歷史實測數據規定其初始值與上下限如表2所示。
2.4 SCE-UA算法與代價函數構建
優化算法采用復合形混合演化算法(Shuffled complex evolution-University of Arizona, SCE-UA)。該算法是DUAN等[32-33]在1993年提出的引入了復雜形分割、混合思想的全局優化算法,在樣本空間的搜索效率、計算速率和全局搜索最優的能力上表現突出且對待優化參數初始值不敏感[34],為遙感與作物生長模型同化的實際應用提供了可行的方法。

表2 待優化參數初始值及取值范圍Tab.2 Initial value and range of parameters for optimization
由于之前的研究發現,與順序同化算法相比,SCE-UA算法更易受到觀測數據誤差的影響,當觀測LAI偏低時同化后的LAI偏低較嚴重[35],因此在構建代價函數時,先將遙感觀測LAI和WOFOST模擬LAI歸一化,得到代價函數
(2)
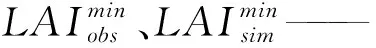

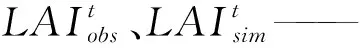
代價函數J為時間序列遙感觀測LAI與模型模擬LAI的誤差平方和。SCE-UA算法通過全局搜索,當滿足鄰近5個代價函數值均達到設定閾值或者迭代次數達到設定次數時停止運算并得到最優參數集,將所得最優參數集連同其他參數輸入WOFOST模型,實現模型模擬冬小麥生長發育過程和成熟期的預測。
3 結果與分析
3.1 WOFOST模型的標定
在本研究中,本地化的WOFOST模型是準確預測冬小麥成熟期的必要條件。耦合變量LAI是表征植被冠層結構的基本參數,在WOFOST模型中是直接影響作物的光合、呼吸等重要過程的狀態變量[36]。因此,采用2016年鄭州和泛區農業氣象站全生育期實測LAI數據對標定后的WOFOST模型模擬結果進行驗證。圖2是WOFOST模型模擬冬小麥LAI時間序列與實測LAI對比。

圖2 WOFOST模型模擬冬小麥LAI時間序列與實測LAI的對比Fig.2 Comparisons of WOFOST simulated time series LAI and field-measured LAI
冬小麥LAI在出苗期至越冬期前增長較緩慢,越冬期停止增長,返青期開始增長迅速,在開花期前達到最大值,開花期至成熟期逐漸降低,成熟期之后迅速降低。從圖2可以看出,標定后的WOFOST模型模擬的鄭州站和泛區站的LAI時間序列曲線的趨勢特征與實測值基本符合,經計算,模擬LAI和實測LAI間的RMSE為0.92 m2/m2,說明模擬值與實測值具有良好的一致性,WOFOST模型模擬的冬小麥LAI精度較高。此外,部分點的模擬產生了一些偏差,可能的原因有:①年際間冬小麥生育期的變化導致WOFOST模型用2018年的作物參數無法模擬出較為準確的開花期和成熟期,影響了LAI的模擬精度。②模型標定是以鄭州站的觀測數據為準,因此不一定適用于其他地區冬小麥的模擬。
3.2 單點同化結果分析
開花期和成熟期分別是冬小麥營養生長和生殖生長階段的結束日期,是評價模型模擬發育期合理的關鍵指標。因此本文使用研究區內農業氣象站的開花期和成熟期觀測日期共同檢驗實驗結果的精度,圖3為2018年滑縣站同化前后模型模擬LAI和MODIS LAI的時間序列曲線。

圖3 滑縣站同化前后模型輸出LAI和MODIS LAI的時間序列曲線Fig.3 Changing curves of WOFOST simulated LAI, assimilated LAI and MODIS LAI in Huaxian station
從圖3可以看出,滑縣站同化后WOFOST模型模擬的出苗期、開花期與成熟期略晚于同化前。從LAI時序曲線的趨勢分析,同化后LAI曲線的變化趨勢更接近于MODIS LAI,表明WOFOST模型優化TSUM1等參數能夠使其輸出的LAI曲線趨勢更接近遙感數據,而且并沒有受到遙感數據尺度較低的影響。相對應地,同化后LAI明顯高于同化前LAI和MODIS LAI。通過分析滑縣氣象數據和模型的逐日模擬結果,發現原因是同化前模型模擬的開花期在DOY110附近,由前文可知,冬小麥的快速生長時期發生在返青期至開花期之間,同化前返青期至開花期氣溫較低,光照不足,不利于冬小麥的快速生長;而同化后模擬的開花期較晚,為DOY122,該階段氣溫回升,使同化后的冬小麥在返青期至開花期期間長勢優于同化前。由此看出,準確地模擬開花期不僅是成熟期模擬的基礎,更對WOFOST模型生物量、產量等多方面的模擬精度有很大的影響。

圖4 開花期、成熟期的預測值與實測值的回歸分析Fig.4 Regression analysis diagrams of predicted and measured anthesis and maturity date
在表3中,同化前開花期、成熟期取值范圍分別為DOY97~108、DOY135~152,同化后兩者取值范圍變為DOY108~120、DOY141~156。可以看出,多數點同化前的開花期和成熟期均早于同化后,且同化后開花期、成熟期的時間變異性大于同化前。對比各站點同化前后參數值,發現部分開花、成熟較晚的站點同化前開花期、成熟期均提前,說明標定的作物參數并不符合這些站點的實際情況,導致樣本內部差異較小。同化前開花期、成熟期誤差較大也是因為在標定WOFOST模型時研究區內的TSUM1、TSUM2等作物參數是基于歷史數據計算取值,沒有考慮到年際間品種與播種時間等因素的變化,同化后誤差明顯減小,說明同化MODIS LAI和WOFOST模型的方法可以提高研究區冬小麥開花期、成熟期的預測精度。

表3 部分站點同化前后開花期、成熟期日期對比Tab.3 Comparison of simulated and assimilated anthesis and maturity date DOY
開花期、成熟期的預測值與實測值的回歸分析見圖4。從圖4可以看出,同化后的開花期、成熟期與對應觀測日期基本符合,所成散點的趨勢線斜率均在1左右,說明同化后的開花期、成熟期與觀測日期具有良好的一致性,且RMSE分別為2.10 d和2.48 d,預測精度較高。誤差的主要來源有:①遙感數據空間分辨率較低,同化混合像元可能導致開花期模擬出現誤差,隨著模型的運行誤差逐漸累積,進而影響成熟期的預測精度。②由于研究區內冬小麥品種和田間管理等方面存在差異,而大量參數在空間上的分布無法獲得,只能采用標定值,因此模型運行時其他參數取值相同也會帶來一定的誤差;使用SCE-UA算法最小化代價函數的過程中,可能很難準確地找到最接近實際情況的全局最優參數集,因此優化后的參數集也可能存在一定誤差。
3.3 開花期與成熟期空間分布
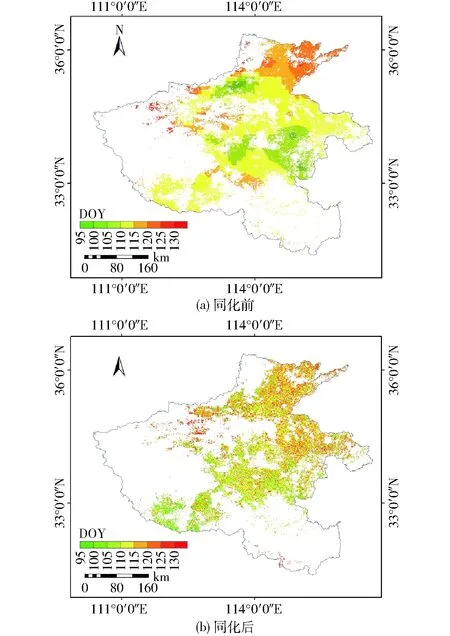
圖5 研究區同化前后開花期空間分布對比Fig.5 Comparison of anthesis date distribution before and after assimilation in study area
圖5、6分別為同化前后開花期、成熟期的空間分布圖。從圖5可見,由于只受氣象輸入數據的影響,同化前開花期模擬值呈較為明顯的區塊狀分布,相鄰的像元開花期時間十分接近。西北部和東部地區由于冬小麥播種時間較早且氣候適宜,因此開花期最早,南部、中部次之,而河南省西部海拔較高,北部緯度較高,因此氣溫相對較低,開花期最晚。同化后的開花期總體趨勢為從西南部向東北部逐漸推后,西部高海拔地區仍然最晚。同化前后開花期的空間分布變化主要表現在:①同化后研究區西南部開花期整體提前、研究區西北部和東部略有延后,原因是實際的IDEM、TSUM1數值與標定值相比發生了較大變化,導致同化后相應區域開花期普遍延后或提前。②同化后的開花期表現出了更詳細的空間變異性,在表現出開花期整體趨勢的前提下,可以看出相鄰冬小麥像元的開花期存在一定差異,說明用MODIS LAI優化WOFOST模型的參數后可以在一定程度上表現出較細空間尺度上種植品種等方面的差異。
對比圖5a和圖6a可以看出,研究區中部、東部和西南部地區成熟期相對提前(位于研究區內的先后順序),說明這些地區當年度夏季氣溫較高,光照充足,因此生育期提早結束。從圖6可以看出,同化后成熟期的空間分布除了增加空間細節之外,還可以看出,中北部地區成熟期大幅延后,研究區內成熟期整體趨勢為從西南部向東北部逐漸延遲,主要原因是優化后的TSUM2(開花期至成熟期有效積溫)大于標定值,更符合該地區的實際情況,提高了模型的預測精度。

圖6 研究區同化前后成熟期空間分布對比Fig.6 Comparison of maturity date distribution before and after assimilation in study area
4 討論
通過數據同化框架耦合遙感數據和作物生長模型,并結合氣象預報數據實現區域尺度作物成熟期的預報,雖然總體精度較高,但仍存在一定的誤差,誤差產生的原因有:①預報延伸期氣象驅動數據存在誤差,由于5月16日(DOY136)后的氣象數據是使用歷史相似年份的同期氣象數據替代的,因此與實際氣象數據有一定偏差,以后可以嘗試天氣發生器[37-38]、區域氣候模型[6]等多種中長期氣象預報方法。②本方法僅優化了WOFOST模型的3個輸入參數,其他參數取值在研究區內相同,在一定程度上也限制了模型的預測精度,可以考慮增加對LAI敏感性較高、在生育期不同階段波動較大的參數作為待優化參數,如AMAXTB(葉片最大CO2同化速率)、SLATB(比葉面積)等。
冬小麥開花期的模擬精度會直接影響其成熟期、LAI模擬的精度,誤差過大時甚至會影響LAI模擬的尺度,因此通過數據同化方法優化WOFOST模型參數進而提高開花期模擬精度對于成熟期預測具有重要意義。而本文使用的MODIS LAI數據存在混合像元效應且容易受到云的影響,使用濾波的方法平滑MODIS LAI也會導致一定的誤差,因此為進一步提高成熟期預測精度,可以考慮增加高分辨率遙感數據或非光學遙感數據(如SAR數據)進行多遙感數據同化。此外,可以考慮將量化開花期模擬的不確定性量化,在開花期模擬集合的基礎上進行同化,也可以加入作物參數擾動、多來源氣象預報數據分別構建預報集合[39-40],這些集合更有助于表征整個系統的不確定性,進而為決策者提供多維度的信息。
5 結論
(1) 與觀測數據相比,同化后WOFOST模型模擬的開花期RMSE為2.10 d,預測的成熟期RMSE為2.48 d,預測精度較高,說明基于MODIS LAI和WOFOST模型同化的方法在大區域作物成熟期預測方面可行。
(2) 基于歸一化思想構建LAI代價函數,能夠優化WOFOST模型的IDEM、TSUM1、TSUM2參數,優化后的LAI時間序列曲線尺度不受MODIS LAI數據尺度較低的影響。
(3) 冬小麥開花期的模擬誤差會傳遞到成熟期的模擬中,因此開花期的準確模擬對于成熟期的精準預測具有重要意義,為了提高預測精度,使用高分辨率遙感數據進行同化或使用SAR數據等進行多目標數據同化是可能的解決途徑。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
